论文解读:检索越多越好?SELF-RAG给大模型装上了反思开关
大模型在"一本正经地胡说八道"这件事上,已经有相当悠久的历史。
你问它谁发明了电话,它告诉你亚历山大·格雷厄姆·贝尔——好,这次对了。你再问它某个冷门的学术数据,它给你一个听起来完全正确、实际上胡编乱造的答案。这种现象有个专有名词,叫幻觉(Hallucination)——模型基于训练时封存在参数里的"静态知识"生成文字,而不是真正"查到了"事实。
过去几年,解决幻觉问题的主流方案叫做检索增强生成(Retrieval-Augmented Generation,RAG)。思路极其朴素:生成答案前,先从外部知识库检索几段相关文档,然后让模型"参考"这些文档来回答。就像开卷考试——给你资料,再答题。
确实有效。但一个更根本的问题,从没有被真正解决。
1. 开卷考试的致命缺陷
RAG的逻辑表面上无懈可击,但它有一个藏得很深的假设——无论什么问题,检索一下总有帮助。
现实并非如此。
"2+2等于多少?"——不需要检索。"帮我写一首描述夏天的诗"——检索能带来什么?大概只是噪声。但传统RAG会无差别地从数据库里拉出几段文档,不管有没有用,全部喂给模型。
这还只是第一层问题。
第二层更致命:模型拿到了文档,但不一定"忠实"使用。文档里明明写着A,模型照样可能输出B。RAG提供了证据,但无法强制模型遵循证据。引用了,却不支持——这种情况不是例外,而是常态。
Shi et al.(2023)的研究直接验证了这一点:不相关的上下文会显著降低大模型的表现。不是中立,而是有害。
于是问题变得很清晰——现有RAG框架有两个核心缺陷:一,不该查的时候也在查;二,查到了也不一定用得好。
两个问题叠加,没有一个现有方案能同时处理。
在这样的背景下,SELF-RAG出现了。
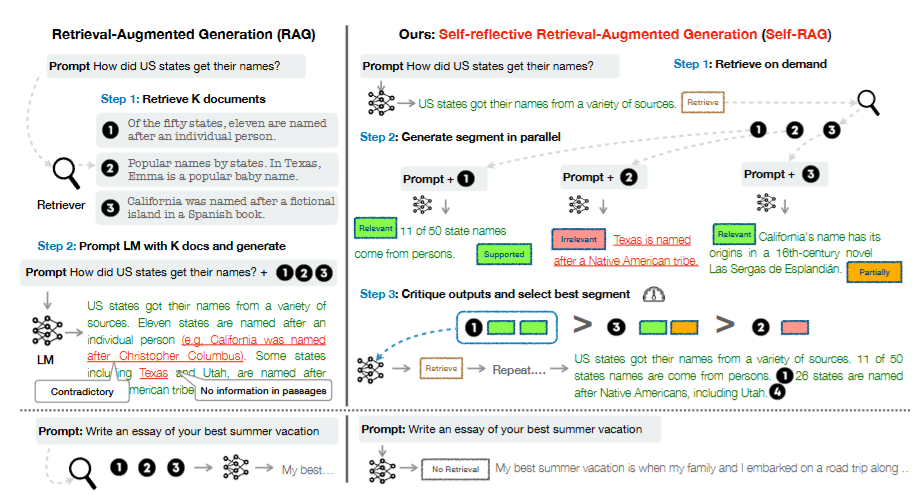
图1
图1是传统RAG(左)与SELF-RAG(右)工作流程对比。传统RAG对所有问题一律检索;SELF-RAG分三步——按需触发检索、并行评估文档、批评筛选最优输出
2. 反思标记:把"元认知"变成模型的内置能力
SELF-RAG——自反思检索增强生成(Self-Reflective Retrieval-Augmented Generation)——由华盛顿大学、AI2(Allen Institute for AI)和IBM Research AI联合推出。
核心团队由第一作者Akari Asai和Zeqiu Wu,以及Yizhong Wang(通讯作者之一)和Hannaneh Hajishirzi(通讯作者)组成,均来自华盛顿大学;Avirup Sil来自IBM Research AI。Hajishirzi在NLP与开放域问答领域有深厚积累,Yizhong Wang是指令跟随(Instruction Following)方向的核心推动者。这支队伍横跨学术机构与工业研究院,几乎覆盖了这个问题所需的全部技术方向。
SELF-RAG的核心设计,用一句话概括就是——把"检索决策"和"质量评估"都变成模型自身的生成能力,而不是外部系统的固定流程。
怎么做到的?
答案是:反思标记(Reflection Tokens)。
SELF-RAG在原有词汇表基础上增加了一组特殊标记——这些标记不代表普通单词,而是模型对自身行为和输出质量的实时"元评估"信号。
具体定义了四种类型:
-
Retrieve(检索决策):输出 yes / no / continue,决定此刻是否触发检索器。
-
ISREL(相关性判断):输出 relevant / irrelevant,评估检索到的文档对当前问题是否有价值。
-
ISSUP(支持度判断):输出 fully supported / partially supported / no support,评估模型生成的内容是否有文档的实际依据。
-
ISUSE(整体效用评分):输出1-5分,对整段回复的综合质量打分。

图2
图2是SELF-RAG的四种反思标记定义,包含输入、输出值和含义说明
翻译成人话——模型在生成每一段文字的过程中,会同时输出四个"旁白":需要查资料吗?查到的资料有用吗?我写的内容有没有依据?整体回答质量怎样?
这就把过去"检索器→语言模型"的外挂式流水线,变成了一个统一的自主决策体系。
这是一个本质性的改变——不是工程优化,而是架构逻辑的重构。
3. 训练的两步走:先训"批评家",再训"创作者"
SELF-RAG的训练涉及两个模型,分工非常清晰:批评模型(Critic Model,C)是训练阶段的数据标注员;生成模型(Generator Model,M)是最终部署的智能体。
推理时,你只需要M,C已经完成使命退出舞台。
第一步:训练批评模型C。
反思标记需要大量带标注的训练数据——每一段文本,都需要有人判断:这里需要检索吗?检索到的文档相关吗?回答有依据吗?
手动标注太贵,SELF-RAG的解法是用GPT-4生成这些标注。研究团队为不同类型的反思标记分别构造了指令提示,让GPT-4判断并生成标注(每类4k-20k条),然后以Llama2-7B为基础,在这批数据上训练批评模型C。
验证结果令人信服:C在大多数反思标记类别上,与GPT-4的判断一致率超过90%。
用一个轻量的开源模型,以90%+的精度复现了GPT-4的判断能力——这本身就已经是一个值得关注的信号。
第二步:训练生成模型M。
有了批评模型C,就可以自动构建生成模型的训练语料。
对于每一条输入-输出对(x, y),C会逐段判断:这里需要检索吗?检索到的文档相关吗?当前输出有依据吗?这些判断作为反思标记插入原始文本,形成带"自反思标注"的扩充训练集Dgen。
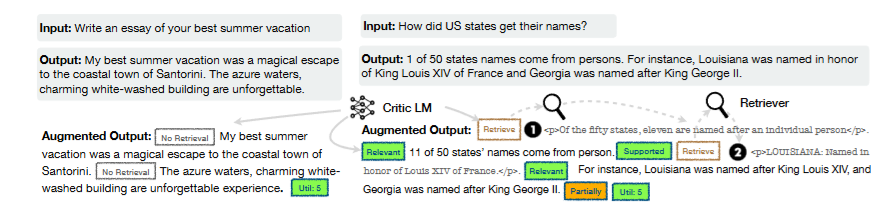
图3
图3展示的是SELF-RAG训练数据示例。左侧问题需要检索,批评模型插入Retrieve标记和相关性/支持度评估;右侧问题无需检索,直接生成并评分
生成模型M在这个语料上,用标准的下一个词预测目标进行训练:
其中x是输入,y是文本输出,r是反思标记序列——模型同时学习生成文字和生成反思标记。
有一个细节值得特别注意:训练时,检索到的文档片段在计算损失时被遮蔽,不参与梯度更新。模型真正学习的,是在正确的位置插入正确的反思标记,以及根据文档生成高质量的文本段落。
这个设计彻底消除了训练时对批评模型的依赖。训练完成后,M是一个完全独立的系统——它把"何时检索、如何评估"的能力,内化成了自身权重的一部分。
4. 推理的三步舞:按需触发、并行筛选、加权决策
SELF-RAG的推理过程,比传统RAG复杂,也远比传统RAG灵活。
第一步:按需触发检索。
模型在生成每一段文字之前,先预测Retrieve标记。如果是Yes,才调用检索器;如果是No,直接继续生成。
这解决了"无差别检索"的问题。面对创意写作、简单计算、日常对话,SELF-RAG不会去数据库里乱翻——它知道这些时刻根本不需要外部知识。
检索,是一个决策,不是一个习惯。
第二步:并行处理多个文档,主动过滤噪声。
触发检索后,检索器返回K个候选文档(默认5-10个)。SELF-RAG会并行处理每一个:
-
预测ISREL:这个文档相关吗?
-
基于文档生成对应的文本段落候选
-
预测ISSUP:我写的内容有这个文档的实际支持吗?
被判断为ISREL=Irrelevant的文档,直接被过滤掉。
这就像让模型同时阅读10份参考资料,自己判断哪些有价值、哪些是噪声——而不是一股脑全部塞进上下文窗口。
第三步:分段束搜索,选出最优继续。
每个候选文档对应一个候选文本段落。怎么选最好的?SELF-RAG引入分段束搜索(Segment-level Beam Search),对每个候选计算综合评分:
其中p(yt)是语言模型的生成概率,后面三项是各反思标记的加权分数。
更重要的是——这三个权重wG可以在推理时手动调整,不需要重新训练。
想要更高的事实准确率?调高wISSUP,让"内容有依据"的权重更大。想要更流畅自然的输出?调高wISUSE,让整体效用分更重要。
这是传统RAG做不到的事——训练完后,行为基本固定。SELF-RAG把模型行为的控制权,交还给了使用者。
5. 和现有方案的根本区别在哪里
在理解SELF-RAG之前,有必要先梳理一下它在研究版图上的定位。
路线一:标准RAG。 检索器拉文档,语言模型生成答案。简单高效,但检索是盲目的——不管需不需要、文档相不相关,一律检索,一律喂进去。本质上,检索和生成是两个独立的模块,没有交互。
路线二:迭代式提示工程(以CoVE为代表)。 用更复杂的提示让模型多次修正输出,不依赖外部检索。但这类方法推理开销极大,每次修正都要额外调用一次大模型,运行成本随质量要求指数上升。
路线三:训练时固定增强检索(以SAIL为代表)。 在指令微调数据中,始终在输入前拼接检索到的文档。模型被训练成"习惯了有文档陪伴",但没有学会判断文档是否有用,也没有学会在不需要的时候忽略它。
三条路都没有真正触及核心问题:模型对自身生成过程的元认知能力。
SELF-RAG的定位正是在这三者之间找到一个新的平衡——检索是按需触发的(不是路线一的无差别),质量评估是训练内化的(不是路线二的运行时开销),检索与生成是深度耦合的(不是路线三的简单拼接)。
一路太松散,一路太昂贵,一路太浅层。SELF-RAG的逻辑正好填补了这个空白。
6. 实验数据:7B打败ChatGPT,不是偶然
SELF-RAG在六个任务上进行了系统评测,覆盖短文本问答、事实核查、推理选择题和长文本生成等多个维度:
-
PopQA(开放域问答,长尾罕见实体查询,1399条)
-
TriviaQA(常识问答,11313条测试用例)
-
PubHealth(公共卫生事实核查)
-
ARC-Challenge(科学推理多选题)
-
Biography生成(人物传记,用FactScore衡量事实准确率)
-
ASQA(带引用的长文问答,同时评估准确率、流畅性和引用精度)
一句话总结:SELF-RAG 7B和13B在所有任务上,均优于同规模或更大规模的开源模型,并在多个任务上超过ChatGPT。
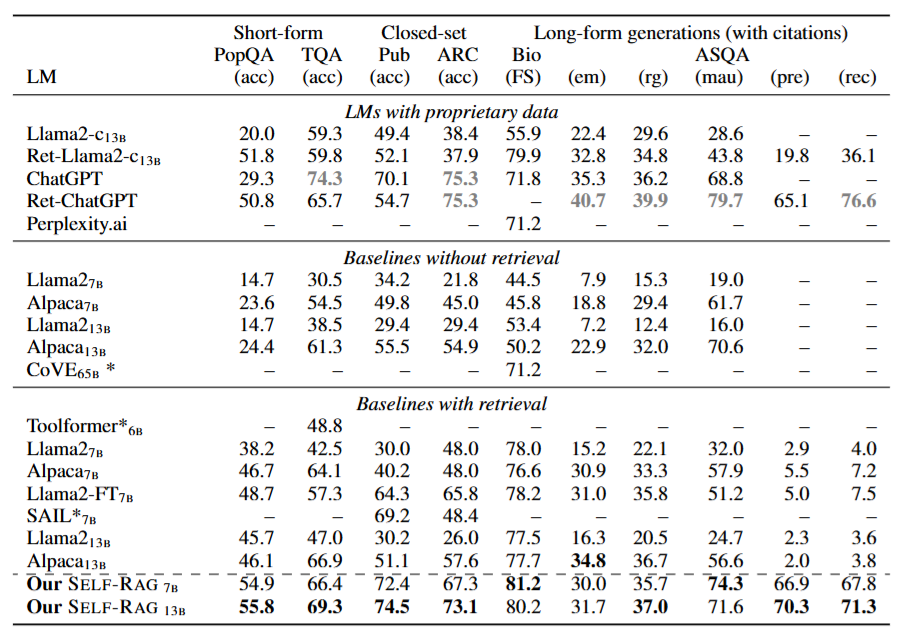
图4
图4是六项任务的完整实验对比结果。加粗为非专有数据模型中的最优值,灰色加粗为专有模型最优值
重点拆解几个关键数字:
PubHealth(事实核查):SELF-RAG 7B是72.4%,SELF-RAG 13B是74.5%——而ChatGPT是70.1%。7B的参数量,打败了体量大得多的ChatGPT。这不是运气,而是自反思带来的结构性优势。
PopQA(开放域问答):SELF-RAG 7B达到54.9%,远高于ChatGPT的29.3%,也高于检索增强ChatGPT(Ret-ChatGPT)的50.8%。连"ChatGPT+检索"的组合都被比下去了。
Biography生成(FactScore事实准确率):SELF-RAG 7B是81.2,SELF-RAG 13B是80.2——而Ret-Llama2-chat13B是79.9,ChatGPT是71.8,CoVE(65B参数,复杂迭代提示工程方案)仅有71.2。
ASQA引用精度(Citation Precision):SELF-RAG 13B达到70.3,超过Ret-ChatGPT的65.1。这意味着SELF-RAG生成的内容,有更高比例真正被引用文档支持——而其他检索增强基线,大多数引用精度只有个位数。
更重要的是什么?是对照组Llama2-FT7B的数据。这个模型用和SELF-RAG完全相同的训练数据微调,唯一区别是:没有反思标记,没有自我批评。它在几乎所有任务上的表现,都明显落后于SELF-RAG。
这说明SELF-RAG的增益不是来自数据,而是来自框架本身。
7. 消融实验:每个零件都不是装饰
研究团队在PopQA、PubHealth和ASQA三个数据集上做了系统性消融,精确定位了每个组件的贡献。
训练层面的消融:
去掉检索器(No Retriever)→ ASQA从32.1降至31.0,PopQA从45.5降至43.6。检索有用,但损失相对温和——说明自反思的价值不只是"查到了文档"本身。
去掉批评模型(No Critic)→ ASQA从32.1暴跌至18.1。这是所有消融里最大的跌幅。说明自我批评能力——尤其是ISSUP对支持度的精细判断——是引用质量的核心支柱。这不是锦上添花,而是系统能力的地基。
推理层面的消融:
完全禁用检索(No retrieval)→ PopQA从45.5降至24.7。大幅下滑,符合预期。
始终检索top1文档(Retrieve top1,类似传统RAG)→ PopQA从45.5降至41.8,ASQA从32.1降至28.6。无差别检索不如自适应检索——这直接验证了SELF-RAG按需触发的设计价值。
移除ISSUP评分(Remove ISSUP)→ ASQA从32.1降至30.6,引用质量下滑。说明支持度评估在生成阶段的实时纠偏作用是真实存在的。
消融结论用一句话概括:框架里每一个组件,都在做别人做不了的事。
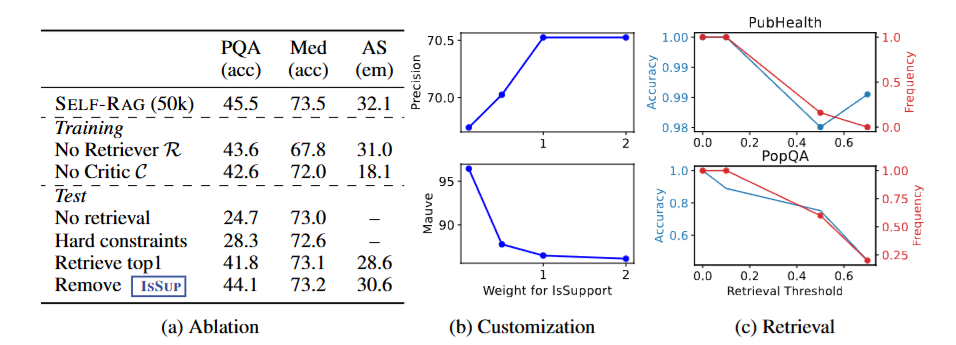
图5
图5是SELF-RAG分析实验。(a) 训练与推理消融结果;(b) 调整ISSUP权重对ASQA引用精度和MAUVE流畅性的影响;(c) 不同检索阈值下的检索频率与准确率变化
8. 总结与展望
SELF-RAG解决的,不只是一个工程问题——它解决的是大模型与外部知识之间关系的根本性矛盾。
旧范式里,检索是输入端的预处理步骤,生成是输出端的独立行为。SELF-RAG把检索变成了模型内部决策的一部分,把质量评估编织进了生成的每一步。
这让大模型第一次真正拥有了一种"自知之明"——知道自己什么时候需要帮助,知道拿到的帮助有没有价值,知道自己说的话有没有依据。
未来有几个值得关注的演化方向:
第一,反思标记的扩展。SELF-RAG目前定义了四种反思标记,涵盖检索、相关性、支持度和效用。未来可以引入更细粒度的维度——比如推理链的一致性、信息的时效性、来源的可信度。
第二,多步自反思。当前SELF-RAG在单轮生成中进行实时自反思;对于需要多步推理的复杂任务,迭代自反思的潜力尚未被充分挖掘。
第三,与更强检索器的协同。SELF-RAG目前搭配Contriever-MSMARCO;随着更高精度的稀疏-密集混合检索器涌现,"更强的自反思 × 更准的检索器"的协同效应,是个值得期待的研究方向。
如果说传统RAG是"给模型配了一个图书馆",那么SELF-RAG展示的是:模型第一次学会了独立判断——我现在需不需要去图书馆,去了该查哪本书,查到的内容算不算数。,这是一个重要的信号。
论文地址:https://arxiv.org/pdf/2310.11511

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)