Self Forcing:解决自回归视频扩散曝光偏差,单 GPU 实现 17FPS 实时生成
本文基于 Adobe Research 与德克萨斯大学奥斯汀分校发表于 NeurIPS 2025 的论文《Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion》,结合核心图表深度拆解这一视频生成领域的里程碑式技术。
一、引言:视频生成的两难困境
近年来,视频生成技术取得了惊人的进步,以 Wan2.1、Sora 为代表的双向扩散 Transformer(DiT)模型能够生成高度逼真、具有复杂动态的视频内容。然而,这些模型都存在一个致命的缺陷:它们需要同时去噪所有帧,生成时必须一次性输出完整视频,完全无法支持实时流式应用。
为了解决实时性问题,研究者们将目光转向了自回归(AR)模型。自回归模型按顺序逐帧生成视频,天然符合时间因果性,理论上可以实现低延迟流式生成。但传统自回归模型一直被一个顽疾困扰 ——曝光偏差(Exposure Bias):
- 训练时:模型基于干净的真实帧预测下一帧
- 推理时:模型只能基于自己生成的不完美帧预测下一帧
这种训练与推理的分布不匹配,会导致误差随生成时间指数级累积,视频越长质量越差。此前的 Teacher Forcing 和 Diffusion Forcing 两种训练范式都未能从根本上解决这个问题。
直到 Self Forcing 的出现,它通过一个极其简单却颠覆性的思路:让模型在训练时就完全模拟推理过程,自己生成上下文并学习修正自己的错误,彻底消除了曝光偏差。在单张 H100 GPU 上,Self Forcing 实现了17 FPS 的实时视频生成和0.45 秒的超低延迟,同时 VBench 总分达到 84.31,超越了包括 Wan2.1 在内的多个主流双向扩散模型。
二、核心痛点:曝光偏差 —— 自回归模型的 "阿喀琉斯之踵"
要理解 Self Forcing 的伟大之处,我们首先要搞清楚为什么之前的方法都解决不了曝光偏差。
2.1 Teacher Forcing:看似完美的 "填鸭式教学"
Teacher Forcing 是序列建模中最经典的训练范式,它的核心思想是:训练时永远给模型提供正确的上下文。
在视频扩散中,Teacher Forcing 的具体做法是:
- 对一个视频的所有帧同时加相同水平的噪声
- 使用块稀疏因果注意力掩码(也就是大家常说的 "块间因果块内双向注意力")并行训练所有帧
- 优化目标是逐帧 MSE 损失,即预测噪声与真实噪声的均方误差
如果把模型比作学生,Teacher Forcing 就像是老师全程拿着标准答案,让学生一步一步照着抄。学生永远不会遇到自己的错误,自然也不会学会如何修正错误。一旦到了考试(推理)的时候,没有了标准答案,学生只要写错一步,后面就会越错越离谱。
2.2 Diffusion Forcing:治标不治本的 "改进版"
为了缓解 Teacher Forcing 的问题,研究者们提出了 Diffusion Forcing。它的核心思路是:既然推理时上下文有噪声,那训练时也给上下文加噪声。
Diffusion Forcing 的具体做法是:
- 对一个视频的每一帧独立采样不同的噪声水平
- 同样使用因果注意力掩码并行训练
- 优化目标仍然是逐帧 MSE 损失
这就像是老师给学生一份带点小错误的答案,让学生在有干扰的情况下做题。但本质上,这些错误还是老师加的,不是学生自己犯的。学生依然没有学会如何修正自己的错误,考试的时候还是会一错再错。
CausVid 就是典型的 Diffusion Forcing+DMD 模型,虽然它实现了 17 FPS 的速度,但由于训练分布与推理分布不匹配,生成的视频会随着时间推移出现严重的颜色饱和和内容崩坏。
2.3 一张图看懂三种范式的本质区别
论文中的图 1 用三个数学公式,一针见血地指出了三种训练范式的核心差异: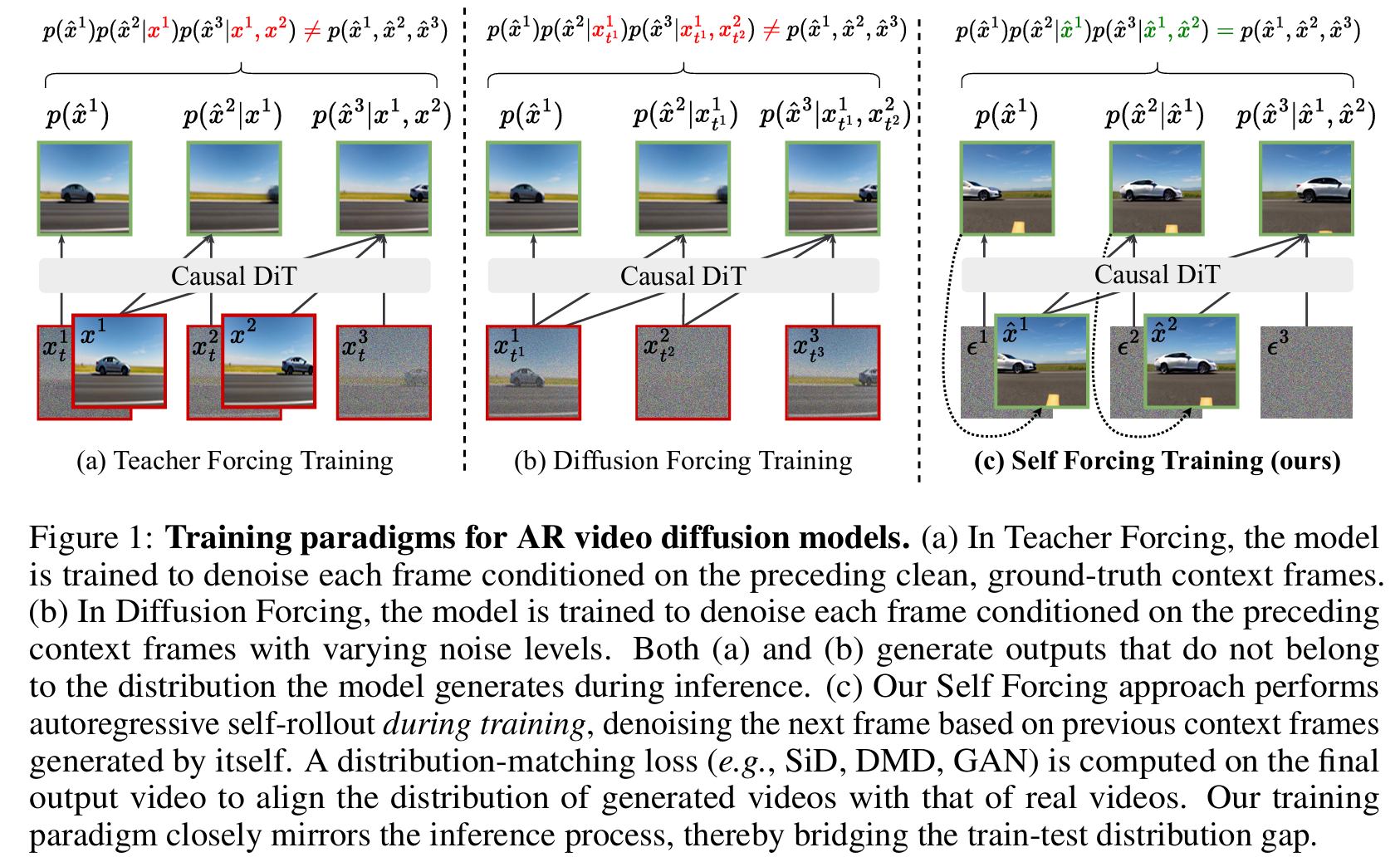
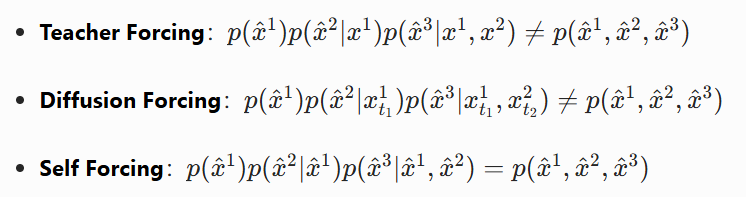
前两者的训练联合分布与推理联合分布不相等,而 Self Forcing 的训练联合分布与推理联合分布完全相等。这就是为什么只有 Self Forcing 能从根本上解决曝光偏差。
三、Self Forcing:让模型在训练中 "自己做题"
Self Forcing 的核心思想简单到令人惊讶:既然推理时模型要基于自己生成的帧预测下一帧,那训练时也这么做不就行了?
3.1 核心思想:训练 = 推理,从根本上消除分布差距
Self Forcing 不是从头训练一个新模型,而是一个后训练(Post-Training)算法。它基于已经预训练好的双向视频扩散模型(论文中使用 Wan2.1-T2V-1.3B),通过两个步骤将其转换为高质量的自回归模型:
- 因果注意力微调:将预训练的双向 DiT 的注意力改为因果注意力,用 16k 个 ODE 解对微调,让模型具备自回归生成的基础能力
- Self Forcing 后训练:用自回归自展开 + 视频级分布匹配损失进行短时间的后训练(DMD 仅需 1.5 小时)
在 Self Forcing 训练过程中:
- 模型从高斯噪声开始,逐帧生成完整视频
- 每生成一帧,就将其 KV 缓存起来,作为下一帧的上下文
- 等整个视频生成完成后,对最终输出视频计算视频级整体分布匹配损失
- 用这个损失更新模型参数,让模型学会生成更接近真实视频的内容
这就像是让学生自己完整地做一遍卷子,然后老师根据整张卷子的整体质量打分,让学生自己发现并修正错误。经过这样的训练,学生在考试的时候自然就能从容应对自己的错误,不会出现一错到底的情况。
3.2 效率突破:少步扩散 + 随机梯度截断
看到这里,你可能会有一个疑问:自回归自展开是顺序过程,无法并行,训练起来岂不是会非常慢?
这正是 Self Forcing 最令人惊喜的地方:它不仅质量更高,而且训练效率也超过了 Teacher Forcing 和 Diffusion Forcing。这主要得益于两个关键技术:
1. 4 少步扩散
传统扩散模型需要数百步去噪,而 Self Forcing 采用4 步扩散替代。这里需要特别澄清:
- 前向加噪过程:仍然使用完整的 1000 步加噪
- 反向去噪过程:只采样 4 个关键时间点 [1000, 750, 500, 250] 进行去噪
通过分布匹配蒸馏技术,可以将多步扩散模型的能力几乎无损地蒸馏到 4 步模型中,大幅降低了计算量。
2. 随机梯度截断
即使是 4 步扩散,如果对整个自回归过程进行完整的反向传播,内存消耗仍然会非常大。Self Forcing 提出了一个巧妙的解决方案:仅对每帧的最后一个去噪步骤进行反向传播。
同时,为了确保所有中间去噪步骤都能获得监督信号,Self Forcing 会随机采样一个去噪步骤 s(1~4),将第 s 步的去噪结果作为该帧的最终输出。
实验结果表明,Self Forcing 的单轮训练时间与 Teacher Forcing 和 Diffusion Forcing 相当,而且在相同的墙钟训练时间内,Self Forcing 能获得更高的视频质量。
四、三大关键技术详解
4.1 视频级分布匹配损失:DMD vs SiD vs GAN
Self Forcing 使用视频级整体分布匹配损失替代了传统的逐帧 MSE 损失。论文中对比了三种主流的分布匹配损失:
| 损失函数 | 优化目标 | 核心特点 | 训练时间 | 数据需求 |
|---|---|---|---|---|
| DMD(分布匹配蒸馏) | 反向 KL 散度 | 需要更大的教师模型(Wan2.1-14B),效果最好 | 1.5 小时 | 数据 - free |
| SiD(分数恒等蒸馏) | Fisher 散度 | 可以用相同大小的模型作为教师,训练稳定 | 2-3 小时 | 数据 - free |
| GAN(生成对抗网络) | Jensen-Shannon 散度 | 需要额外训练判别器,细节质量更好 | 2-3 小时 | 需要真实数据 |
论文实验表明,三种损失在 Self Forcing 框架下都能取得很好的效果,其中 DMD 在速度和性能上取得了最佳平衡。
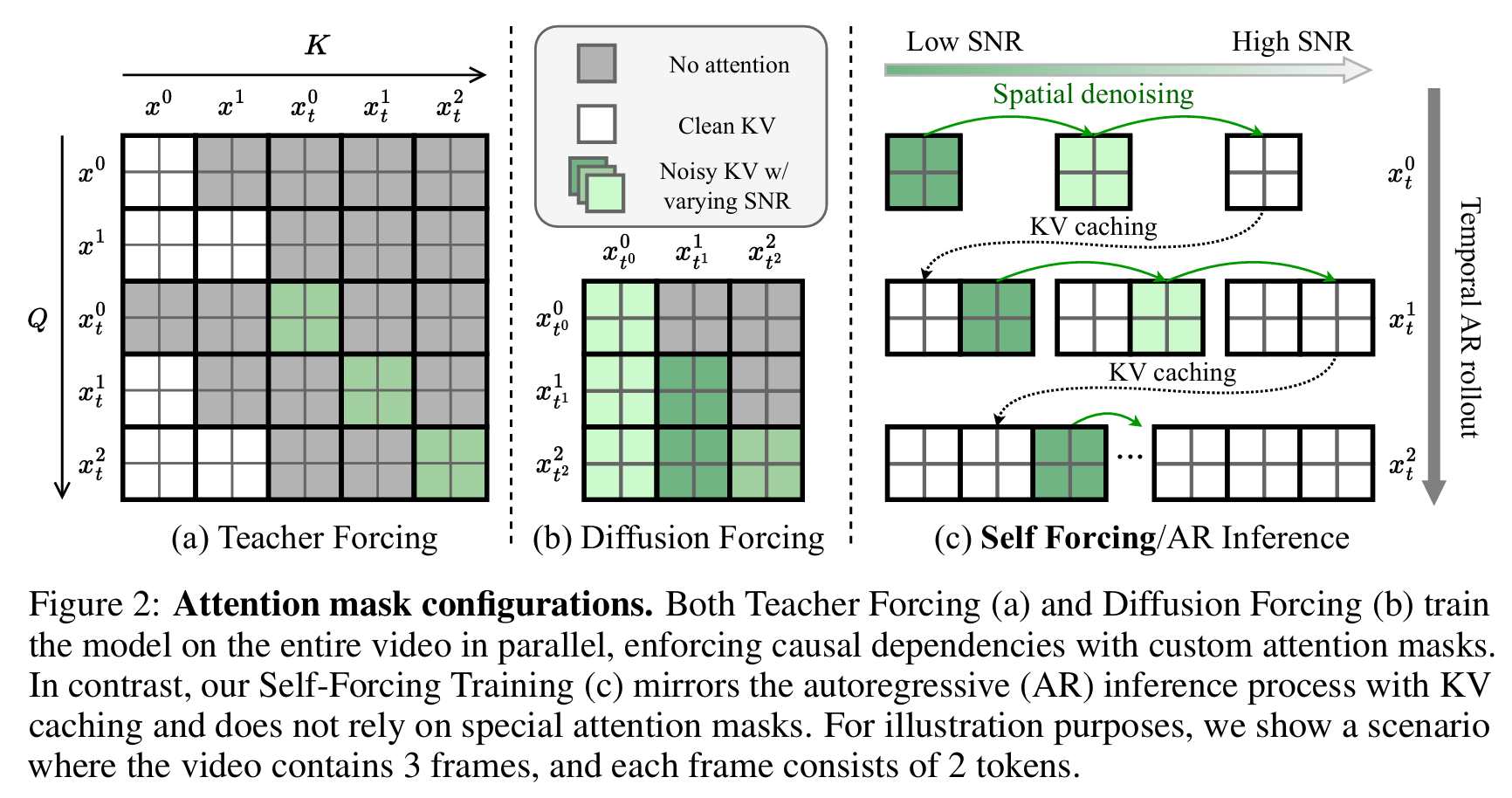
4.2 滚动 KV 缓存:真正的无限长视频生成
自回归模型的一大优势是理论上可以生成无限长的视频,但此前的自回归扩散模型在生成长视频时都会遇到严重的效率问题。
论文中的图 3 对比了三种滑动窗口推理方案的效率:
1. 双向滑动窗口(Wan2.1 等)
- 不支持 KV 缓存,每次滑动窗口都要重新计算整个窗口的注意力矩阵
- 时间复杂度:O(TL2),随窗口大小平方级增长
- 生成 10 秒视频时,吞吐量不足 1 FPS
2. 带 KV 重计算的因果滑动窗口(CausVid、MAGI-1)
- 支持 KV 缓存,但每次滑动窗口都要重新计算所有重叠帧的 KV 缓存
- 时间复杂度:O(L2+TL),仍然包含平方级项
- 生成 10 秒视频时,吞吐量从 17 FPS 暴跌到 4.6 FPS
3. 带滚动 KV 缓存的因果滑动窗口(Self Forcing)
- 维护固定大小的 KV 缓存,生成新帧时直接移除最旧的缓存条目,不需要重新计算任何内容
- 时间复杂度:O(TL),与生成的视频总长度无关
- 生成 10 秒视频时,吞吐量仍然保持 16.1 FPS
为什么 CausVid 不能用滚动 KV 缓存?因为滚动 KV 缓存会将初始帧移出缓存,而 CausVid 在训练时永远能看到初始帧,当分布发生变化时,模型就会出现严重的闪烁和崩坏。
Self Forcing 通过局部注意力窗口训练解决了这个问题:训练时限制模型在去噪最后一帧时不关注第一帧,模拟了推理时缓存淘汰的情况。这不是单纯的工程优化,而是训练范式的胜利。
五、实验结果:速度与质量的双重碾压
论文基于 Wan2.1-T2V-1.3B 模型进行了全面的实验,所有测试都在单张 NVIDIA H100 GPU 上完成。
5.1 性能对比
| 模型 | 参数规模 | 分辨率 | 吞吐量 (FPS) | 延迟 (s) | VBench 总分 |
|---|---|---|---|---|---|
| Wan2.1(双向) | 1.3B | 832×480 | 0.78 | 103 | 84.26 |
| CausVid(自回归) | 1.3B | 832×480 | 17.0 | 0.69 | 81.20 |
| Self Forcing(块级) | 1.3B | 832×480 | 17.0 | 0.69 | 84.31 |
| Self Forcing(帧级) | 1.3B | 832×480 | 8.9 | 0.45 | 84.26 |
- 块级 Self Forcing:同时生成 3 个潜在帧,吞吐量最高,VBench 总分超过了原始的双向 Wan2.1 模型
- 帧级 Self Forcing:逐帧生成,延迟低至 0.45 秒,适合对延迟敏感的实时应用
5.2 用户偏好研究
在与 CausVid、Wan2.1、SkyReels-V2、MAGI-1 的对比中,Self Forcing 获得了 **54.2%~66.1%** 的用户偏好率,全面超越了所有基线模型。
5.3 消融研究
- 不同分布匹配损失效果接近,DMD 在训练速度和性能上取得最佳平衡
- 与基线方法相比,Self Forcing 在从块级切换到帧级自回归时,性能几乎没有下降,证明其有效解决了误差累积问题
六、总结与展望
6.1 核心贡献
Self Forcing 的提出,标志着视频生成领域进入了一个新的时代。它的核心贡献可以总结为三点:
- 范式创新:提出了 "并行预训练 + 顺序后训练" 的新范式,从根本上解决了自回归序列生成中的曝光偏差问题
- 效率突破:通过少步扩散和随机梯度截断,证明了自回归自展开训练不仅可行,而且效率更高
- 工程创新:提出了滚动 KV 缓存机制,实现了真正的无限长高效视频生成
6.2 局限性
- 当生成视频长度显著超过训练上下文长度时,质量仍会下降
- 梯度截断策略可能限制模型学习长程依赖的能力
6.3 未来方向
- 探索更优的长视频外推技术
- 结合状态空间模型(如 Mamba)等更适合长上下文建模的架构
- 将 Self Forcing 推广到其他连续序列生成任务,如音频、机器人控制等
Self Forcing 首次在单 GPU 上实现了高质量的实时视频生成,为实时直播、游戏模拟、机器人学习、交互式内容创作等应用打开了大门。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)