RoboClaw:一种用于可扩展长期机器人任务的智体框架
26年3月来自智元机器人、新加坡国立、上海交大和上海交大教育部AI重点实验室的论文“RoboClaw: An Agentic Framework for Scalable Long-Horizon Robotic Tasks”。
视觉-语言-动作(VLA)系统在语言驱动的机器人操作方面展现出巨大的潜力。然而,将其扩展到长时域任务仍然面临挑战。现有的流程通常将数据采集、策略学习和部署分离,导致对手动环境重置的依赖性过高,以及多策略执行的脆弱性。本文提出RoboClaw,一个将数据采集、策略学习和任务执行统一在单个VLM驱动控制器下的智体机器人框架。在策略层面,RoboClaw引入耦合动作对(EAP),它将正向操作行为与反向恢复动作耦合起来,形成用于自主数据采集的自重置循环。这种机制能够以最小的人工干预实现持续的策略内数据采集和迭代策略优化。在部署阶段,同一个智体执行高级推理,并动态地协调学习的策略原语来完成长时域任务。 RoboClaw 通过在收集和执行过程中保持一致的上下文语义,减少两个阶段之间的不匹配,提高多策略鲁棒性。
如图所示,RoboClaw 是一种用于长时域机器人操作的统一智体架构。RoboClaw 遵循简单的交互范式:用户发送任务指令,机器人自主推理并执行任务。在该框架中,视觉-语言模型 (VLM) 作为元控制器,通过上下文学习 (ICL) [7] 进行高级决策,推理过程基于环境观测和结构化记忆。与依赖人工监督或预定义规划器的传统系统不同,RoboClaw 将数据采集、策略学习和任务执行统一在一个智体循环中,从而在整个系统生命周期中保持一致的任务语义和决策逻辑,并将机器人操作从人为控制的操作转变为智体控制的操作。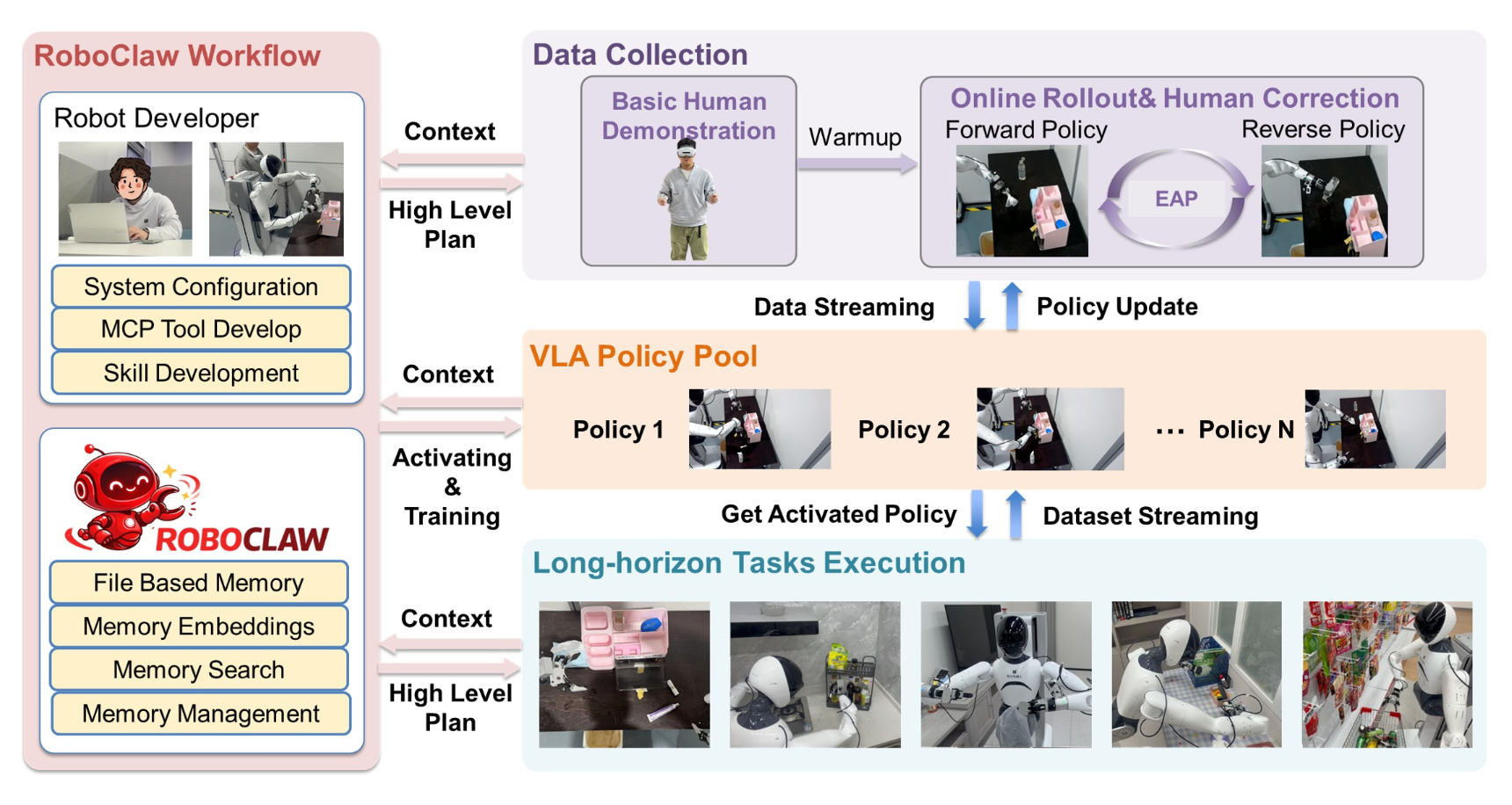
在数据采集阶段,RoboClaw 引入耦合动作对 (EAP) 机制,该机制显著减少手动重置环境的需要。对于每一种操作策略,将正向执行行为与互补的反向恢复行为配对,形成一个自重置循环,使机器人能够反复返回到可重用的前提条件区域。在智体控制下,这些配对动作交替执行,无需频繁的人工干预即可实现持续的在线数据采集。与依赖手动重置或演示的传统流程相比,这种机制显著减少人工投入,同时保持采集数据与执行条件的一致性。
RoboClaw 系统在一个闭环智体交互循环中运行。基于观测数据和结构化记忆,视觉-语言模型 (VLM) 执行思维链推理 (CoT),以解释当前任务状态、评估进度并确定下一步动作。
RoboClaw 将结构化记忆与 OpenClaw 风格的模块化技能库集成,使智体能够组合可重用的功能,以执行复杂的工作流程,例如数据收集和任务执行。系统构建为三个层次的抽象层级:技能、工具和策略,其中较高层级调用较低层级来完成任务。将按相反的顺序介绍这三个组件。策略(Policies)指的是一个机器人基础模型,它生成底层运动动作,在系统中以视觉-语言-动作 (VLA) 模型实现。工具(Tools)是可调用的系统接口(例如,启动策略Start Policy、终止策略Terminate Policy、环境摘要Env Summary),允许智体执行策略或通过模型上下文协议 (MCP) 查询环境。技能(SKills)表示可重用的程序,用于协调工具,例如,“长-期-执行”技能可以调用环境摘要,然后调用启动策略来执行操作策略。
基于 RoboClaw 智体框架的自主机器人任务执行与数据采集
基于上述分层设计,引入 RoboClaw 的总体执行框架,该框架使 RoboClaw 能够执行自主任务执行和数据采集。
如图所示,RoboClaw 将智体的感知、推理和行动组织成一个闭环决策过程,该过程迭代更新内存并与环境交互。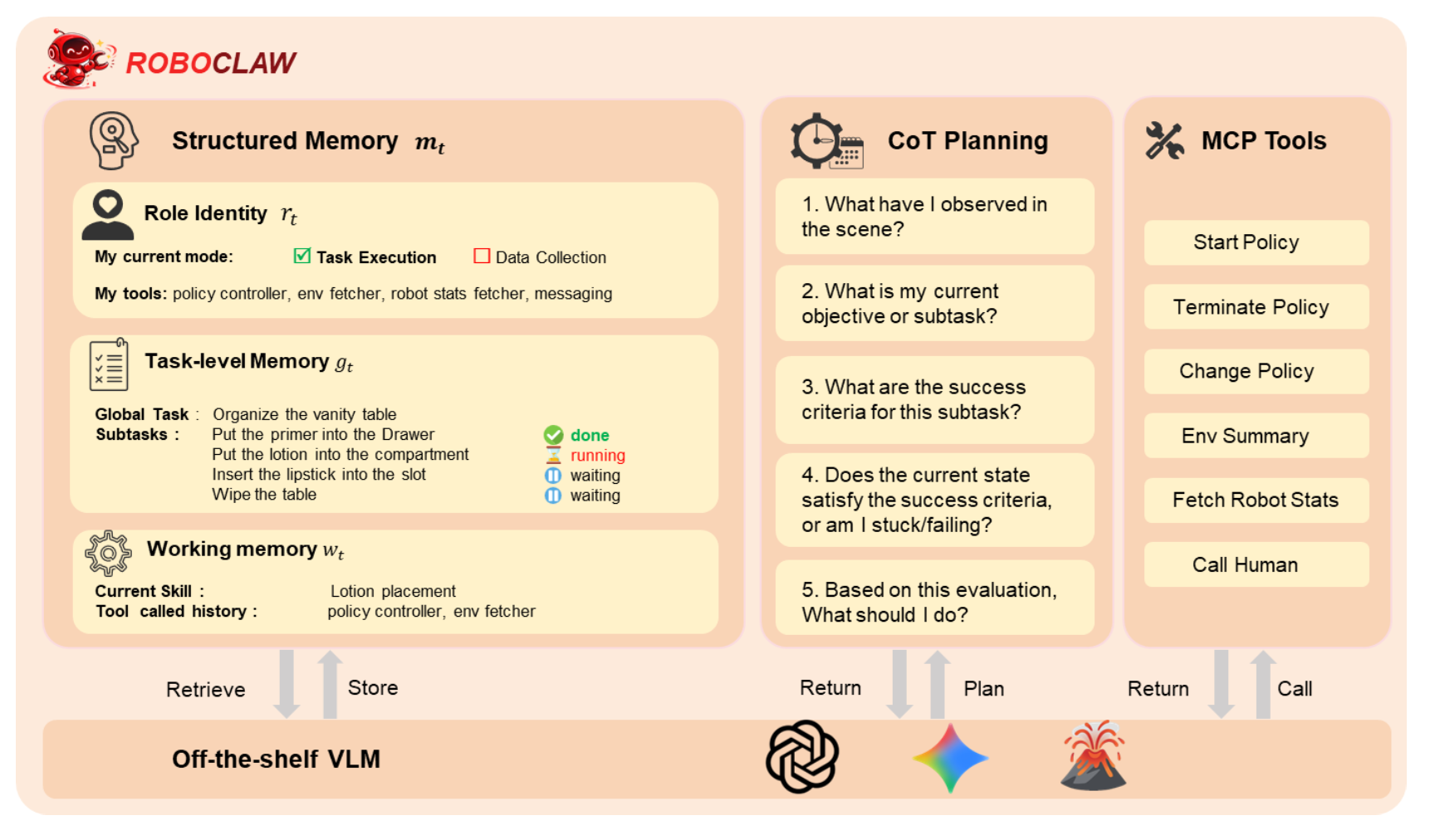
在每个时间步 t,智体维护一个结构化的记忆状态 m_t,该状态提供用于推理和规划的上下文信息。该记忆由三个部分组成。角色标识 rt 指定智能体的当前操作模式和可用工具集。任务级记忆 g_t 记录全局任务及其分解的子任务及其执行状态,使智体能够跟踪长期任务进度。工作记忆 w_t 存储短期执行上下文,例如当前激活的技能和工具调用历史记录。在执行过程中,智体会持续检索并更新结构化记忆 m_t,其中r_t 表示 RoboClaw 的角色标识,g_t 是任务级记忆,用于记录全局任务和子任务的进度,w_t 是工作记忆,用于存储当前激活的技能和工具调用历史记录。通过观察和记忆,智体可以推断当前场景和任务执行状态。
智体从候选子任务集 Z 中选择下一个子任务 z_t。智体评估子任务是否已成功完成,并据此更新任务记忆 g_t。
RoboClaw 中的底层操作策略采用视觉-语言-动作 (VLA) 模型 π0.5 [2] 实现。VLA 策略联合处理视觉观察、语言指令和机器人本体感觉状态,以生成可执行的机器人动作。
如图所示RoboClaw 的自动数据采集工作流。在系统中,语言指令并非由人类操作员直接提供,而是由 RoboClaw 智体在 MCP 工具调用期间动态生成。当 RoboClaw 决定执行一项技能时,它会生成一条描述当前子任务的结构化指令,该指令用于指导策略的制定。
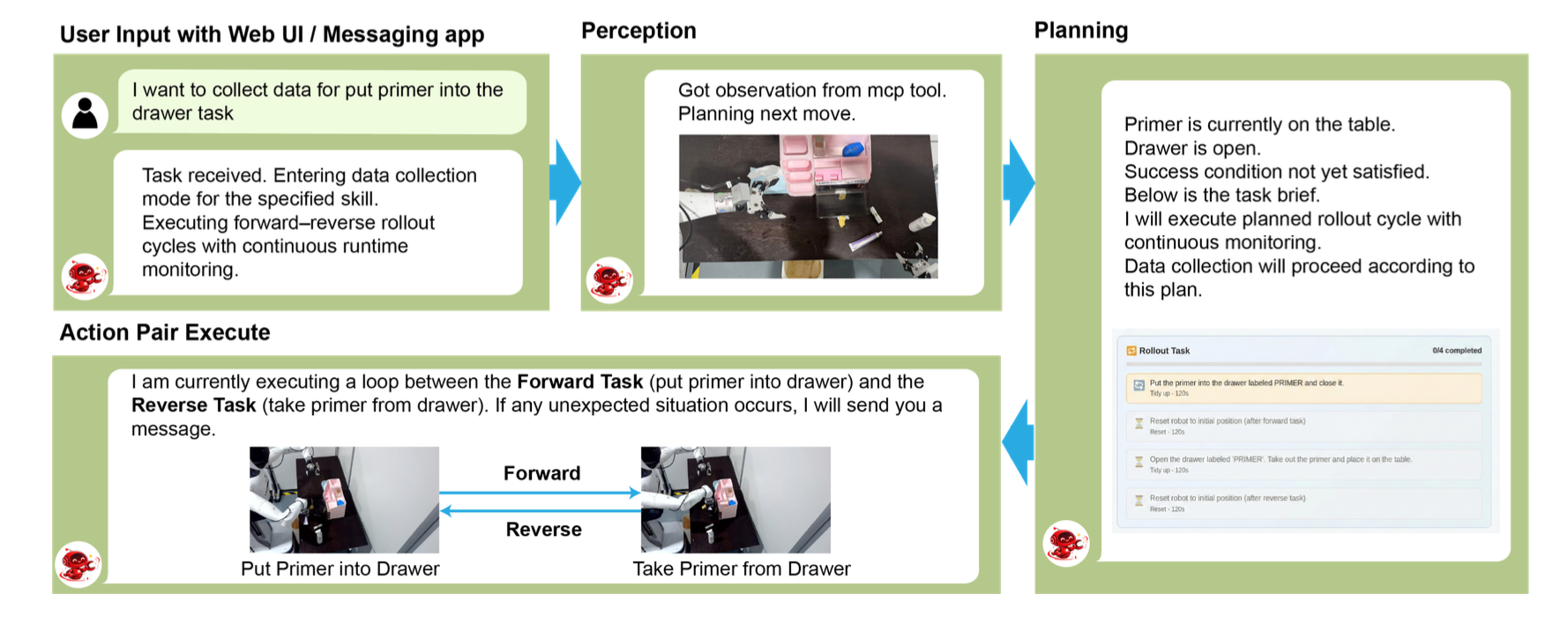
形式上,该策略预测一个短期动作序列 A_t,其中 o_t 表示视觉观察结果,l_t 表示 RoboClaw 智体生成的指令,q_t 表示机器人关节状态。预测动作块(长度为 H)定义为:A_t = [a_t,…,a_t+H−1], 该策略通过条件流匹配目标 Lτ (θ) 来训练,从而对分布 p(A_t | o_t, l_t, q_t) 进行建模。它学习一个速度场 v_θ,该速度场将标准高斯噪声分布传递到真实的动作分布,其中 τ ∈ [0,1] 是流匹配时间步长,Aτ_t = (1 − τ)ε + τA_t 是采样高斯噪声 ε 与真实动作块 A_t 之间的线性插值状态。
对于每个策略 k,学习一个前向执行策略 π→_θ_k 和一个重置策略 π←_θ_k。前向交互收集一条轨迹。一旦智体确定子任务已成功完成,则触发重置策略以恢复环境状态,这两条轨迹共同构成一个纠缠对τ_k =(τ_k→,τ_k←),使得环境能够在无需人工干预的情况下自动返回到其初始状态。所有收集的轨迹都存储在数据集 D 中,用于后续的策略学习。
部署时过程监督与技能调度
在部署期间,RoboClaw 作为任务执行器运行,并组合先前学习的策略来完成长期任务。执行过程遵循与前面介绍的相同闭环决策结构,其中智体基于当前观测值 o_t 和结构化内存 m_t 进行推理,以选择下一个子任务 z_t。
给定选定的子任务,RoboClaw 通过 MCP 工具接口从前向策略集 {π→_θ_k} 中调用相应的前向策略。在执行过程中,智体定期查询环境摘要和机器人状态(例如,通过“获取机器人统计信息 Fetch Robot Stats”和“环境摘要 Env Summary”),以监控任务进度。这些反馈信号被写入工作内存 w_t,并用于评估当前子任务是否已完成。
如果子任务的成功条件得到满足,智体更新任务级内存 g_t,并继续执行任务计划中的下一个子任务。否则,智体可以重试相同的策略,或通过“更改策略”工具切换到其他前向策略。
如果系统检测到重复故障或意外的环境状态,RoboClaw 会尝试通过重新规划并从前向技能集中选择替代技能来进行恢复。当自主恢复失败或触发安全条件时,智体会通过 MCP 界面上的“呼叫人工干预”工具请求人工干预。这种设计使得系统在大多数情况下能够自主运行,同时在安全关键情况下保留人工监督。
重要的是,部署期间生成的轨迹会被记录并纳入数据集 D。这些轨迹捕获实际任务执行过程中遇到的其他状态分布,可用于进一步优化技能策略 {π→_θ_k}。这样,部署不仅可以执行任务,还可以作为改进技能库的额外经验来源。
RoboClaw 通过数据收集和部署共享相同的决策循环和技能接口,形成一个统一的生命周期学习框架,其中执行过程不断改进底层技能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 15
15 0
0- 0



 已为社区贡献119条内容
已为社区贡献119条内容

所有评论(0)