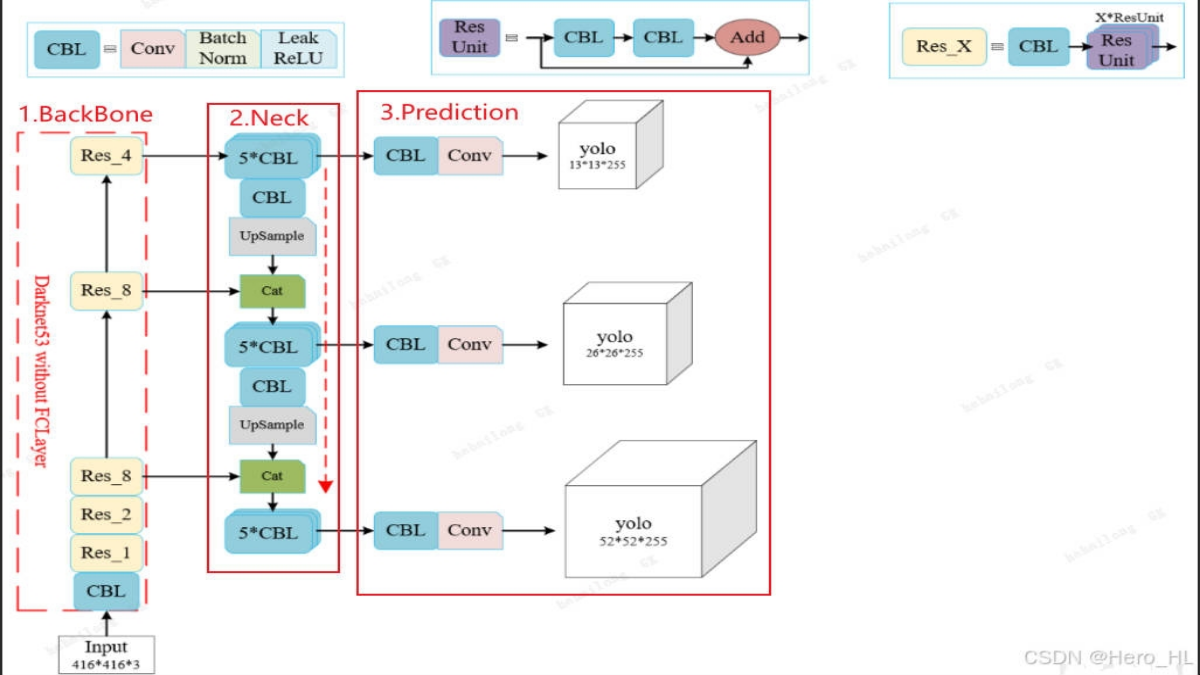
YOLOv3目标类型训练:教网络识别“目标是什么“
代码仓库地址:https://github.com/ultralytics/yolov3
注意:官方维护版的requirements.txt文件里说明了它依赖的库及其最低版本,可以看到它是也依赖Ultralytics的,git clone的是yolov3网络结构,而所用的一些基础模块有些是Ultralytics库的。也要安装Ultralytics库。
1. 目标类型训练:YOLOv3的"识别"能力
在目标检测系统中,YOLOv3的卓越性能来自于其精心设计的多目标损失协同机制。一个完整的目标检测需要同时解决三个核心问题:
定位:目标在哪里?(坐标训练,参见yolov3学习之目标坐标训练)
存在性判断:这里有没有目标?(置信度训练,yolov3学习之目标置信度训练)
识别:目标是什么?(类型训练)
本文将聚焦第三点:目标类型训练。比如网络如何学习识别COCO数据集的80个类别。
2 基础概念:理解分类任务
2.1 多标签 vs 单标签
想象一下现实场景:一张照片中的人可以同时是:
“人”(Person)
“运动员”(Sports Person)
“年轻人”(Young Person)
2.2 实现方式差异

2.3 YOLOv3的设计选择
YOLOv3在架构设计上支持多标签分类(使用Sigmoid激活函数),但在当前实现中是单标签训练。
3 网络输出结构
本文代码来自如下路径:
https://github.com/ultralytics/yolov3
3.1 网络输出结构
YOLOv3的每个预测位置输出85个值:
[tx, ty, tw, th, confidence, class1, class2, ..., class80]
索引: 0 1 2 3 4 5 6 ... 84
索引0-3:目标坐标偏移量
索引4:置信度
索引5-84:80个类别的原始输出值
3.2 训练与推理的差异
在models/yolo.py的Detect.forward方法中:
# models/yolo.py 的 Detect.forward 方法
# 训练模式:返回原始输出
if self.training:
return x # 不应用Sigmoid
# 推理模式:应用Sigmoid并解码
else: # Detect (boxes only)
xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4)
关键设计:
训练时:原始输出 → 损失函数(内部处理Sigmoid——在损失函数BCEWithLogitsLoss内部处理)。
推理时:原始输出 → Sigmoid → 解码 → 最终结果。
支持多标签分类(每个类别独立判断)。
4 损失函数设计与实现
本文代码来自如下路径:
https://github.com/ultralytics/yolov3
4.1 损失函数初始化
在loss.py的ComputeLoss.__init__方法中,第89-90行:
# Classification loss
self.BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
关键参数:
BCEWithLogitsLoss:二元交叉熵损失,内部包含Sigmoid。
pos_weight:正样本权重,处理类别不平衡。
h[‘cls_pw’]:来自配置文件的权重参数。
4.2 损失权重配置
在hyp.scratch-low.yaml中:
cls: 0.5 # 类别损失权重
cls_pw: 1.0 # 类别正样本权重
在train.py中根据模型配置动态调整(第177行):
hyp["cls"] *= nc / 80 * 3 / nl
# nc: 实际数据集类别数
# nl: 检测层数(P3,P4,P5共3层)
5 训练步骤详解
5.1 训练全景图
让我们先看YOLOv3实际的训练流程,在train.py中:
# train.py 训练循环核心代码
for epoch in range(epochs):
for i, (imgs, targets, paths, _) in pbar:
# 第一步:前向传播
with torch.cuda.amp.autocast(amp):
pred = model(imgs) # 网络预测
loss, loss_items = compute_loss(pred, targets.to(device))
# 第六步:反向传播
scaler.scale(loss).backward()
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10.0)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
这个六步走流程在每个训练批次中重复执行,网络逐渐学会识别不同的目标类别。
5.2 训练步骤代码详解
第一步:前向传播(train.py)
# 前向传播
with torch.cuda.amp.autocast(amp):
pred = model(imgs) # 前向传播
loss, loss_items = compute_loss(pred, targets.to(device))
代码解读:
pred :模型输出,包含三个尺度(P3,P4,P5)的预测结果
targets :真实标签,格式为 [image_id, class_id, x, y, w, h]
loss_items 包含三项损失: [box_loss, obj_loss, cls_loss] 其中 loss_items[2] (即 cls_loss)就是目标分类损失
第二步到第五步:在compute_loss中完成
loss.py中ComputeLoss.__call__方法的代码:
# loss.py ComputeLoss.__call__ 方法核心部分
def __call__(self, p, targets):
lcls = torch.zeros(1, device=self.device) # 初始化类别损失
# 遍历三个尺度
for i, pi in enumerate(p): # i=0:P3, i=1:P4, i=2:P5
b, a, gj, gi = indices[i] # 第二步:获取正样本位置
n = b.shape[0] # 正样本数
if n: # 如果有正样本
# 第三步:提取正样本预测
ps = pi[b, a, gj, gi] # 形状[n, 85]
# 第四步:构建标签矩阵
if model.nc > 1: # 只在多类别任务时计算
t = torch.full_like(ps[:, 5:], self.cn, device=self.device) # 全0
t[range(n), tcls[i]] = self.cp # 设置正标签
# 第五步:计算损失
lcls += self.BCEcls(ps[:, 5:], t) # BCE损失
关键变量的实际来源
indices和tcls的来源:
在__call__方法开头,通过build_targets函数获取:
# 在__call__方法开头
tcls, tbox, indices, anchors = self.build_targets(p, targets)
def build_targets(self, p, targets):
# 复杂的匹配逻辑
# 返回:
# - indices: (b, a, gj, gi) 批次、锚框、网格位置
# - tbox: 坐标目标
# - tcls: 类别ID列表
return tcls, tbox, indices, anchors
build_targets函数返回的实际格式::
假设匹配到2个正样本:
# 假设匹配到2个正样本
indices = [
(tensor([0, 0]), # 批次索引 b
tensor([0, 1]), # 锚框索引 a
tensor([6, 15]), # 网格y坐标 gj
tensor([12, 8])) # 网格x坐标 gi
]
tcls = [tensor([15, 16])] # 类别ID列表
重要概念——偏移增强:在匹配过程中,YOLOv3会为靠近网格边界的目标创建额外训练样本。比如目标在网格边缘,除了原始匹配,还会创建偏移样本。这些偏移样本具有相同的类别标签,相当于给网络更多学习机会。
第四步:构建标签
# 创建与pcls形状相同的标签矩阵
t = torch.full_like(pcls, self.cn, device=self.device)
# 设置正样本的真实类别位置为1.0
t[range(n), tcls[i]] = self.cp
示例:
# 假设n=2, tcls[i]=tensor([15, 16])
# 创建标签矩阵
t = torch.zeros(2, 80, device=self.device) # 形状[2,80]
# 设置正标签
t[0, 15] = 1.0 # 第一个样本,类别15设为1.0
t[1, 16] = 1.0 # 第二个样本,类别16设为1.0
第五步:损失计算
# 计算二元交叉熵损失
lcls += self.BCEcls(pcls, t)
BCEcls是初始化时定义的:
# 在__init__中
self.BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
5.3 完整的实际代码流程
这是从train.py到loss.py的完整调用链:
# train.py
loss, loss_items = compute_loss(pred, targets.to(device))
# compute_loss函数内部(在loss.py的ComputeLoss.__call__中)
def __call__(self, p, targets):
# 1. 构建训练目标
tcls, tbox, indices, anchors = self.build_targets(p, targets)
# 2. 初始化损失
lcls = torch.zeros(1, device=self.device)
# 3. 遍历三个尺度
for i, pi in enumerate(p):
b, a, gj, gi = indices[i]
n = b.shape[0]
if n: # 如果有正样本
# 提取预测
ps = pi[b, a, gj, gi]
# 计算类别损失
if model.nc > 1:
# 构建标签
t = torch.full_like(ps[:, 5:], self.cn, device=self.device)
t[range(n), tcls[i]] = self.cp
# 计算损失
lcls += self.BCEcls(ps[:, 5:], t)
return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
5.4 实际的多尺度处理
在实际代码中,三个尺度是独立处理的:
# 实际的多尺度循环
for i, pi in enumerate(p): # p包含三个尺度的预测
# 每个尺度独立计算
# i=0: P3 (大尺度,检测小目标)
# i=1: P4 (中尺度,检测中目标)
# i=2: P5 (小尺度,检测大目标)
5.5 稀疏监督的实际实现
在代码中,稀疏监督是通过if n:条件实现的:
if n: # 只有有正样本时才计算
# 计算类别损失
lcls += self.BCEcls(ps[:, 5:], t)
如果没有正样本(n=0),就不计算类别损失,直接跳过。
5.6 正负样本标签定义
在loss.py的ComputeLoss.__init__方法中:
self.cn = 0.0 # 负样本标签
self.cp = 1.0 # 正样本标签
5.7 多类别时才计算类别损失
咱们也注意到了,其类别损失计算有个条件如下:
if model.nc > 1: # 只有在多类别任务时才计算分类损失
# 计算类别损失
这意味着:
当 model.nc = 1 时:跳过类别损失计算。
当 model.nc > 1 时:计算类别损失。
为啥单类别不用计算类别损失?有如下原因:
(1)只需要学习目标存在性。
(2)不需要学习目标类别区分。
(3)通过置信度损失就能完成检测。
明白吧?单目标任务(人脸识别或者车辆识别等单目标任务),只需要置信度训练+坐标训练就够了。只要目标存在,它就是这个类型!
5.8 总结:实际的六步走
YOLOv3目标类型训练的实际六步是:
(1)train.py:前向传播 → 获取所有预测。
(2)loss.py:build_targets → 匹配正样本,返回indices和tcls。
(3)loss.py:提取预测 → ps = pi[b, a, gj, gi]。
(4)loss.py:构建标签 → t = torch.full_like(ps[:, 5:], self.cn)+ t[range(n), tcls[i]] = self.cp。
(5)loss.py:计算损失 → lcls += self.BCEcls(ps[:, 5:], t)。
(6)train.py:反向传播 → scaler.scale(loss).backward()+ 参数更新。
6 具体计算示例
6.1 场景设定
假设在P4尺度匹配到2个正样本:
样本0:批次0,锚框0,网格(12,6),真实类别15(猫)
样本1:批次0,锚框1,网格(8,15),真实类别16(狗)
6.2 数据流示例
# 步骤2结果
indices = ([0,0], [0,1], [6,15], [12,8]) # (b, a, gj, gi)
tcls = [15, 16] # 类别ID
# 步骤3:提取预测
# 假设网络输出pi形状[1,3,26,26,85]
pcls = pi[0, [0,1], [6,15], [12,8]][:, 5:85] # 形状[2,80]
# 步骤4:构建标签
t = torch.zeros(2, 80) # 形状[2,80]
t[0, 15] = 1.0 # 样本0,类别15设为1.0
t[1, 16] = 1.0 # 样本1,类别16设为1.0
# 步骤5:损失计算
# BCEWithLogitsLoss内部:
# 1. 对pcls应用Sigmoid得到概率
# 2. 计算二元交叉熵损失
loss = BCEWithLogitsLoss(pcls, t)
6.3 损失计算过程
假设网络预测经过Sigmoid后的概率:
样本0类别15:0.7
样本0其他类别:平均0.1
样本1类别16:0.6
样本1其他类别:平均0.1
损失计算(简化):
样本0类别15损失:-log(0.7) = 0.3567
样本0其他类别损失:-log(0.9) = 0.1054
样本1类别16损失:-log(0.6) = 0.5108
样本1其他类别损失:-log(0.9) = 0.1054
总损失 = 平均值
7 训练策略与优化
7.1 稀疏监督机制
类别损失只对正样本位置计算(loss.py的__call__方法):
# 在loss.py的__call__方法中
if n: # 如果有目标(n为正样本数)
# 只为正样本位置计算类别损失
lcls += self.BCEcls(ps[:, 5:], t)
设计原因:
背景无类别:背景区域没有类别概念。
减少噪声:避免背景噪声干扰学习。
提高效率:稀疏监督训练更高效。
防止过拟合:避免网络过度关注背景。
7.2 类别不平衡处理
问题:某些类别样本很少(如"牙刷"),某些很多(如"人")。
解决方案:
# 通过pos_weight参数调整权重
self.BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h[`在这里插入代码片`'cls_pw']], device=device))
作用:
为稀有类别分配更高权重。
防止模型偏向常见类别。
提高所有类别的检测性能。
7.3 多尺度处理
YOLOv3在P3、P4、P5三个尺度上独立计算类别损失:
for i, pi in enumerate(p): # 遍历三个尺度
…… # 省略代码
# 每个尺度独立计算
lcls += self.BCEcls(pcls, t)
7.4 训练收敛过程
典型的训练过程表现为:
Epoch 1-10: 损失很高(2.0-3.0),快速下降
Epoch 10-50: 损失中等(0.5-1.0),持续下降
Epoch 50-100: 损失较低(0.1-0.3),趋于稳定
8 流程简述
8.1 推理步骤
虽然本文聚焦训练,但简要说明推理流程:
(1)网络前向传播得到原始输出。
(2)应用Sigmoid得到类别概率。
(3)取最大概率作为预测类别(单标签判断)。
(4)结合置信度阈值筛选。
在detect.py中,推理流程如下:
# 加载模型
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
# 前向传播
pred = model(im, augment=augment, visualize=visualize)
# 模型已返回解码后的结果,包含Sigmoid处理后的类别概率
# 非极大值抑制
pred = non_max_suppression(pred,
conf_thres=0.25, # 置信度阈值
iou_thres=0.45, # NMS的IoU阈值
max_det=300)
8.2 类别筛选
在non_max_suppression函数内部:
(1)根据conf_thres筛选高置信度预测,
(2)对每个预测框,获取最大类别概率。
(3)结合类别置信度进一步筛选。
(4)应用NMS去除冗余框。
9 与坐标、置信度训练的协同
9.1 三种损失的协同

9.2 端到端优化
三者在反向传播中协同工作:
输入图片 → 网络前向传播 → 三种损失计算 → 梯度反向传播 → 参数更新
↓
坐标更准确 → 置信度更可靠 → 类别判断更准确
10 代码架构总结
YOLOv3类别训练的完整流程: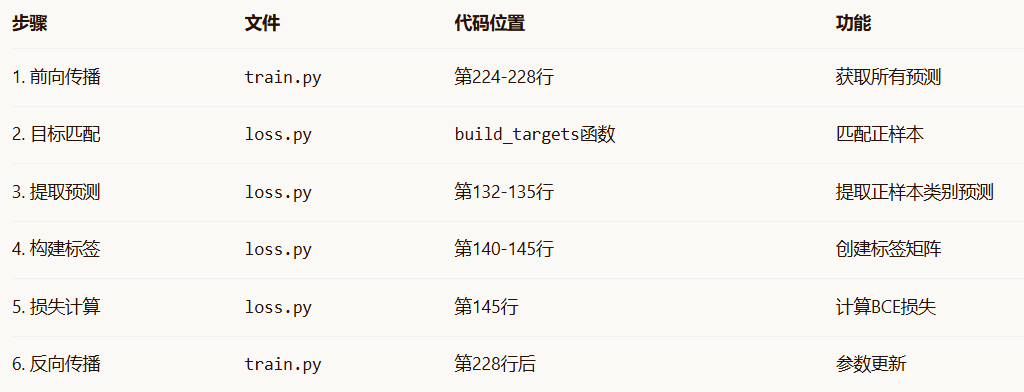
11 设计精髓与总结
11.1 核心要点
(1)训练/推理分离:
训练:原始输出 + 损失函数内建Sigmoid。
推理:统一Sigmoid + 解码。
(2)单标签实现:
当前YOLOv3代码实现是单标签分类训练。
(3)架构潜力:
Sigmoid+BCE设计支持多标签扩展。
(4)稀疏监督:
只对正样本计算类别损失。
提高训练效率和稳定性。
(5)类别平衡:
通过pos_weight处理不平衡。
确保所有类别都被充分学习。
(6)端到端优化:
与坐标、置信度损失协同训练。
实现完整的检测能力。
11.2 技术价值
YOLOv3的类别训练设计体现了:
工程实用性:在理论严谨和工程效率间找到平衡。
可扩展性:架构支持未来的多标签检测需求。
高效性:稀疏监督和端到端优化确保训练效率。
通过这种精心设计的类别训练机制,YOLOv3能够在保持实时性的同时,实现对80个COCO类别的高精度识别,这是其成为经典目标检测模型的重要原因之一。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)