DeepTracer: Tracing Stolen Model via Deep Coupled Watermarks
Yunfei Yang(杨云飞)Xiaojun Chen(陈晓军,通讯作者)Yuexin Xuan(宣跃欣)Zhendong Zhao(赵振东)Xin Zhao(赵鑫)He Li(李赫)
中国科学院信息工程研究所,北京网络空间安全防御国家重点实验室,
北京中国科学院大学网络空间安全学院,北京中石油(北京)数字智能研究院有限公司,北京
发表会议:AAAI 2026(美国人工智能协会年会,人工智能领域顶级会议)
发表时间:2026 年
会议页码:27711-27718
DOI:10.1609/AAAI.V40I33.39992
怎么证明对方偷的是你的模型能力?一种常见方法是模型水印:提前往模型里埋一些只有你知道的“特殊输入—特殊输出”规则。以后你怀疑别人偷了你的模型,就拿这些特殊样本去测对方模型;如果它也对这些样本给出你设计好的答案,就能作为版权证据。
问题是:
以前很多水印方法,在原模型上有效,但一旦模型被偷走,水印常常就“忘掉了”。
这正是本文要解决的核心难题
为什么以前的水印会失效?
这是全文最关键的洞察。
作者认为,老方法失败的根本原因不是“水印不够强”,而是:
水印任务的分布,和主任务的分布太独立、太分离了。
以前很多水印,是往图里加奇怪图案、噪声块、抽象图、特殊文本块之类。这些水印样本和正常任务样本不像是一类东西。所以原模型虽然容量大,能同时记住“正常识别任务”和“奇怪水印任务”,但当攻击者通过正常查询去偷模型时,他学到的主要是“正常任务那部分能力”,很容易把那套奇怪的水印规则漏掉。
要让被偷走的模型也保留水印,就必须让“水印任务”和“主任务”深度耦合。
DeepTracer 的核心思想:把水印“绑”到主任务上
作者提出的方法叫 DeepTracer。
它的核心策略可以概括成一句话:
不要让水印像贴纸一样贴在模型外面,而要让水印像骨头一样长进模型学主任务的过程里。
论文里把这个叫做 deep coupled watermarking(深度耦合水印)。
这个“耦合”分两层理解:
1)输入层面耦合
水印样本不再来自奇怪的外部分布,而是直接由主任务里的真实类别样本拼出来。
也就是说,水印本身就“长得像”主任务数据的一部分。
2)输出/表示层面耦合
训练时不仅要求模型“把水印样本判成某个目标类”,还要让它在特征空间里真的靠近那个目标类。
这样水印不是“表面上判对”,而是“内在表示上也贴近”。
这就是 DeepTracer 比很多旧方法更强的原因。

这是不同水印方法下神经网络的激活热力图。颜色越浅,代表激活程度越高。
1. 传统基线方法 (a) Abstract (Adi et al. 2018)
- 激活特征:正常数据和水印数据的激活模式完全分离,两类数据的高激活(浅色)区域几乎无重叠,相当于激活了两套完全独立的神经元。
- 本质问题:水印任务和主任务是弱耦合 / 完全独立的 —— 水印是 “外挂” 在模型上的额外任务,和主任务的业务特征完全无关。
- 安全隐患:在模型窃取攻击中,攻击者只需要复刻主任务的功能,完全可以通过微调、剪枝等操作删除水印对应的冗余神经元,让水印彻底失效,无法验证版权。
2. 近年对比方法 (b) MEA-Defender (Lv et al. 2024)
- 激活特征:相比传统方法有一定改进,但正常数据和水印数据的激活模式仍有明显差异,高激活区域的重叠度依然很低。
- 本质问题:水印任务和主任务的耦合度不足,水印仍存在独立于主任务的特征空间,依然有被针对性移除的空间,无法彻底抵御窃取攻击。
3. 本文自研方法 (c) DeepTracer (Ours)
- 核心亮点:正常数据和水印数据的激活模式高度一致!两类数据的高激活、低激活区域几乎完全重合,说明水印样本和正常样本激活的是同一批神经元。
- 本质优势:DeepTracer 实现了水印任务与主任务的深度耦合—— 水印不再是附加的 “外挂”,而是完全融入主任务的特征空间,成为主任务本身的一部分。
- 安全价值:在模型窃取场景下,攻击者要复刻主任务的功能,就必须保留这些支撑主任务的神经元,水印会被强制保留,无法在不破坏模型业务能力的前提下移除水印,完美解决了现有水印易被窃取攻击删除的核心痛点。
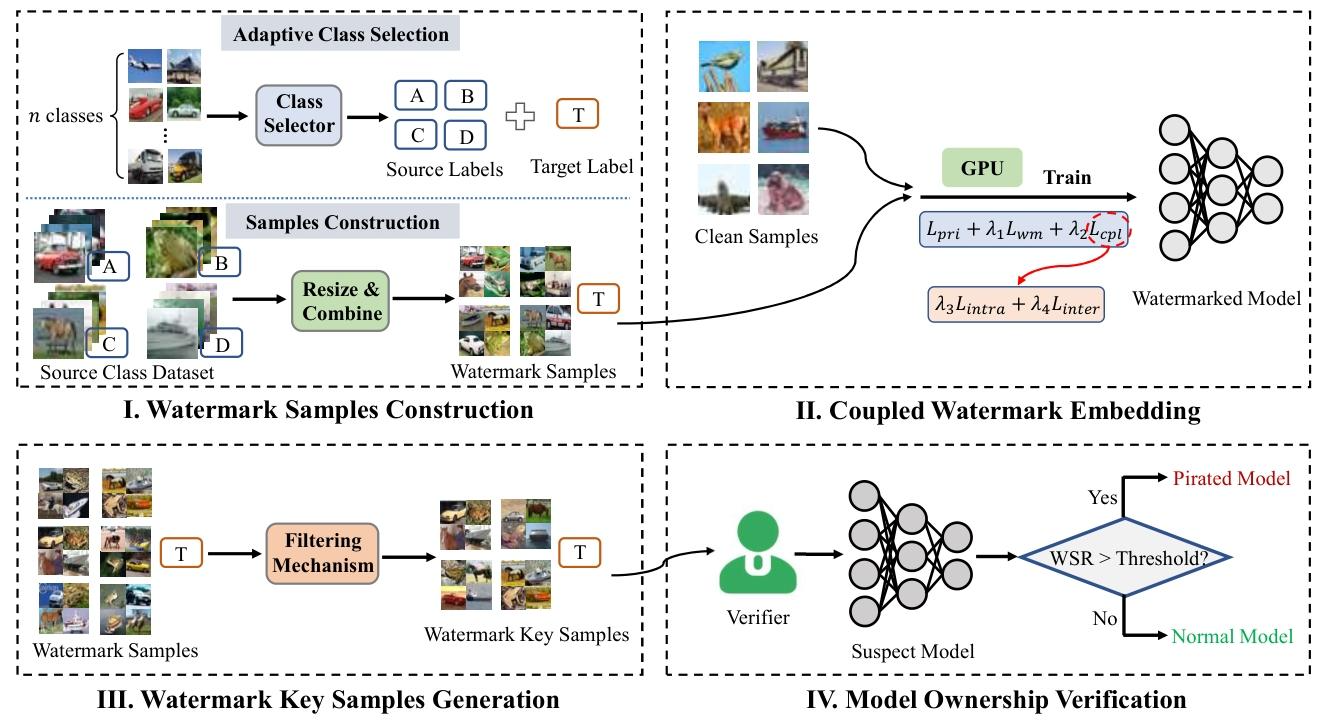
I. Watermark Samples Construction
第一步:构造水印样本
论文不是随便挑几类图片来做水印,而是从原始任务的所有类别里,挑出 4 个最有代表性的类别,作为水印的“原材料”。图里 A、B、C、D 就是这 4 个源类别
论文里具体怎么选?
它的做法是:
-
先用一个干净模型提取每个训练样本的特征;
-
再算出每个类别的“类别中心”;
-
对这些类别中心做 K-Means 聚类;
-
从每个簇里选一个最靠近簇中心的类别。
最后选出 4 个类别,作为 A、B、C、D。然后把 4 个类别的图拼成水印图,从 A、B、C、D 这 4 个源类别里各拿一张图,把它们缩小,再拼成一张新图。
你在图上也能看到,最后那张 watermark sample 就像一个 2×2 的拼图。
因为这样拼出来的图仍然来自正常数据本身:
-
左上角可能带着 A 类的特征
-
右上角带着 B 类的特征
-
左下角带着 C 类的特征
-
右下角带着 D 类的特征
所以它不是那种“外来的奇怪触发器”,比如噪声块、文字 TEST、随机图案;
它还是由主任务内部的真实特征组成的。
这就是论文反复强调的:要让水印任务分布嵌在主任务分布里面。
Target Label:给这些拼图指定一个目标类别 T
图里 A、B、C、D 旁边还有个 T,这个 T 就是目标标签。
意思是:
虽然这张拼图来自 4 个源类别,但训练时会要求模型把它们都判成同一个目标类 T。
T 是怎么选的?
不是随便选的。论文的正文里说:
-
先把这些候选水印样本送进一个干净模型;
-
看它对每个类别的平均预测概率;
-
选那个平均概率最低的类别,作为目标标签 T。
为什么要这么做?
因为这样能减少误报。
你可以理解成:
作者故意选一个“普通模型最不容易想到的答案”作为 T。
这样以后如果你拿这些水印样本去测一个正常模型,它不太可能碰巧全都答成 T;
但被加过水印、或者从它那里偷出来的模型,就更可能答成 T。
所以这一步的作用是:让水印既能测出来,又不容易冤枉无辜模型。
II. Coupled Watermark Embedding
第二步:把水印“耦合式”嵌进模型
这一块是整篇论文最核心的地方。
图里你会看到两路输入:
-
Clean Samples -
Watermark Samples
它们一起进入训练。训练过程总损失函数为:Ltotal=Lpri+λ1Lwm+λ2Lcpl各损失项的作用:
- Lpri:主任务损失:保证模型正常业务精度,水印嵌入不影响模型原有功能
- Lwm:水印分类损失:让模型记住 “水印样本→目标标签 T” 的专属映射
- Lcpl:同类别耦合损失(核心):进一步拆分为 λ3Lintra+λ4Linter
- Lintra(类内紧凑损失):让同类别样本的特征空间更紧凑
- Linter(类间分离损失):让不同类别样本的特征空间更分离
- 作用:强制水印任务和主任务共享同一套特征空间,也就是之前热力图中 “正常样本和水印样本激活模式完全一致” 的核心原因
最后训练出 Watermarked Model。
为什么 clean samples 和 watermark samples 要一起训练?
因为模型不能只学会水印,还要保持原本分类能力。
-
Clean Samples保证主任务性能不坏; -
Watermark Samples负责把作者的水印规则学进去。
如果只喂水印图,模型会偏;
如果只喂正常图,水印又进不去。
所以两者一起训练,相当于一边守住正常能力,一边慢慢埋入水印。
LwmL_{wm}Lwm:水印分类损失
这个损失的作用是:
强迫水印样本被分到目标类 T。
比如一张由 A、B、C、D 拼起来的图,本来它并不是自然属于 T,
但训练时通过 LwmL_{wm}Lwm,模型会被逼着学会:
“只要看到这种特殊拼图结构,就把它判成 T。”
这是最直接的“埋水印”。
4)最关键:LcplL_{cpl}Lcpl —— 耦合损失
这篇论文最新、最有价值的地方就在这里。
作者认为,只靠 LwmL_{wm}Lwm 还不够。
因为只让模型“最后输出 T”,不代表水印真的和 T 类绑紧了。
它可能只是表面上答成 T,但内部表示还是松散的。
这样模型一旦被偷、被蒸馏、被微调,这种表面的水印就容易掉。
所以论文又加了一个 same-class coupling loss,也就是图里的 LcplL_{cpl}Lcpl。
它又分成两部分:
(1)LintraL_{intra}Lintra:类内拉近
作用是:
让水印样本靠近目标类 T 的特征中心。
形象地说:
-
T 类正常样本是一群人,站成一团;
-
水印样本原本像一个外来者;
-
LintraL_{intra}Lintra 就是在把这个外来者往 T 那一团人里拉。
这样水印样本不是“标签上像 T”,而是“特征上也越来越像 T”。
(2)LinterL_{inter}Linter:类间推远
作用是:
让水印样本远离其他非 T 类别的中心。
也就是不光要“靠近 T”,还要“远离别的类”。
继续用刚才的比喻:
-
LintraL_{intra}Lintra 是把你拉进 T 班;
-
LinterL_{inter}Linter 是防止你还站在别的班门口摇摆。
这样水印样本就更稳地融进 T 类。
III. Watermark Key Samples Generation
第三步:从很多水印图里,筛出“最适合验版权”的那一批
这一块是图的左下角。
图里写着:
-
Watermark Samples -
Filtering Mechanism -
Watermark Key Samples
意思是:
前面构造出来的水印图很多,但不是每一张都适合拿去做最终验证。
所以作者还要再做一次筛选,留下最可靠的“密钥样本”。
理想的验证样本必须同时满足三件事:
-
在作者自己的水印模型上能触发;
-
在盗版模型上也尽量能触发;
-
在普通无辜模型上不要触发。
如果一个样本只能在原模型上成功,但盗版模型不认它,那它就不适合拿来“抓盗版”;
如果普通模型也容易答对,那它又会造成误报。
第一阶段:三模型联合筛
作者先准备三个模型:
-
FV:victim model,也就是作者自己的水印模型; -
FS:surrogate model,模拟盗版模型; -
FB:benign model,普通干净模型。
然后只保留满足下面三个条件的水印样本:
-
在 victim model 上预测成 T;
-
在 surrogate model 上也预测成 T;
-
在 benign model 上不预测成 T。
surrogate model 是干嘛的?
这个很关键。
它不是最终的盗版模型,而是作者自己先模拟一次“模型被偷”:
-
用公开数据去查询自己的模型;
-
训练出一个替身模型;
-
看哪些水印样本在这个替身模型上也还活着。
这样筛出来的样本,更像是“未来真的盗版模型也容易保留的水印样本”。
第二阶段:挑最稳的前 M 个
在第一阶段剩下的样本里,论文又进一步挑选:
-
选那些在 surrogate model 上,
-
被预测成目标类 T 时置信度最高的前 M 个样本。
最后留下来的这一小批样本,才叫 Watermark Key Samples。
这就是作者真正保存起来、以后用来验版权的“密钥”。
IV. Model Ownership Verification
第四步:拿密钥样本去验证可疑模型
这一块是图的右下角。
图里流程是:
-
Verifier -
Suspect Model -
判断
WSR > Threshold? -
Yes →
Pirated Model -
No →
Normal Model
这一步就是最后的“版权鉴定”。
1)Verifier 是谁?
就是模型所有者,或者第三方鉴定方。
他手里有前面保存好的 Watermark Key Samples。
这些样本相当于一串“只有作者知道的探针”。
2)Suspect Model 是谁?
就是你怀疑它是盗版的那个模型。
注意,论文强调这是 black-box verification,黑盒验证。
也就是说:
-
不要求看到对方模型参数;
-
不要求看到网络结构;
-
只要能像普通 API 一样喂输入、拿输出就行。
这很实用,因为现实里你大多数时候也拿不到别人模型内部。
3)WSR 是什么?
WSR 就是 Watermark Success Rate,水印成功率。
简单说就是:
你把所有 key samples 喂给嫌疑模型后,
有多少比例被它判成了作者预设的目标类 T。
如果这个比例很高,说明这个模型身上带着作者的水印痕迹。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)