从 219 秒到 1.3 秒!CausVid:首个媲美双向扩散的流式视频生成模型深度解析
前言
你是否有过这样的经历:输入一段文本生成视频,盯着屏幕等了 3 分多钟才看到结果?这就是传统双向视频扩散模型的致命痛点 —— 生成 128 帧视频需要 219 秒,且必须等全部内容生成完毕才能观看,更别提中途修改提示词调整内容了。
2024 年底,MIT 与 Adobe 联合提出的CausVid彻底打破了这一僵局。它通过创新的非对称蒸馏技术,将 50 步双向扩散模型转化为 4 步因果自回归模型,在单张 H100 GPU 上实现了1.3 秒初始延迟和9.4FPS 的流式生成,视频质量甚至超越了 CogVideoX、MovieGen 等所有公开的双向模型,在 VBench-Long 基准上以 84.27 的总分登顶。
本文将从底层原理出发,深度解析 CausVid 如何解决 "质量与速度不可兼得" 的行业难题,带你搞懂因果注意力、非对称 DMD 蒸馏、KV 缓存等核心技术,以及它为什么能开启交互式视频生成的新时代。
论文地址:https://arxiv.org/pdf/2412.07772

一、传统视频生成的致命瓶颈:双向注意力的原罪
1.1 什么是双向注意力?
Transformer 的自注意力机制本身是无约束的,双向注意力就是不给注意力加任何掩码,允许序列中任意位置的 token 访问所有其他位置的 token,包括过去和未来的信息。
打个比方:双向注意力就像写作文时,必须先想完整篇文章的所有内容,才能写下第一个字。因为每一句话的写法,都依赖于后面所有句子的内容。
1.2 为什么双向模型生成单帧要处理整个视频?
传统视频扩散模型(如 CogVideoX、OpenSORA)全部采用双向注意力架构,这就导致:
- 生成第 10 帧时,模型需要同时看到第 1-9 帧和第 11-128 帧的所有信息
- 必须一次性加载并处理完整的视频序列才能生成任何一帧
- 计算和内存成本随视频帧数平方级增长:生成 256 帧的时间是 128 帧的 4 倍以上
1.3 为什么双向模型无法支持交互式应用?
双向模型的生成是一次性全局并行的:
- 所有帧的生成条件(文本提示)在生成开始前就必须固定
- 生成过程中无法修改任何参数
- 如果中途改了提示词,必须丢弃所有已生成内容,从头开始重新生成
这就注定了双向模型只能用于 "一次性生成" 的场景,永远无法支持实时游戏渲染、直播内容编辑、交互式视频创作等需要动态响应的应用。
二、自回归:流式生成的唯一可行路径
2.1 什么是自回归生成?
自回归是一种生成范式:逐个生成序列元素,每个新元素的生成仅依赖于之前已经生成的元素,绝对不依赖任何未来信息。
还是用写作文打比方:自回归就像边想边写,写完第一句就输出第一句,然后基于第一句写第二句,写完第二句就输出第二句,以此类推。读者不需要等你写完,看一句就能懂一句。
2.2 因果注意力:自回归的必要条件
要实现自回归生成,模型必须满足一个硬约束:计算当前元素的输出时,不能看到任何未来元素的信息。而因果注意力(下三角掩码)就是唯一能严格强制执行这个约束的机制。
表格
| 注意力类型 | 掩码设置 | 能访问的信息 | 典型应用 |
|---|---|---|---|
| 双向自注意力 | 无掩码(全 1 矩阵) | 所有位置的 token(过去 + 未来) | Transformer 编码器、原始 DiT |
| 因果自注意力 | 下三角掩码 | 仅当前及之前的 token(仅过去) | GPT、CausVid 的块间注意力 |
2.3 传统自回归视频模型的死穴:误差累积
自回归模型天然支持流式生成和无限长度,但在 CausVid 之前,它一直无法实用化,核心问题就是误差累积:
- 每个生成的帧都可能存在微小误差
- 后续帧基于有误差的前帧生成,误差会像滚雪球一样越滚越大
- 通常生成几十帧后,视频质量就会急剧下降,出现画面崩坏、内容混乱等问题
CausVid 的核心贡献,就是通过非对称蒸馏技术,首次让自回归视频模型的质量达到了与双向模型相当的水平,同时完美解决了误差累积问题。
三、CausVid 的四大核心技术创新
CausVid 的整体架构基于 Diffusion Transformer(DiT),通过四大核心技术创新,实现了 "质量媲美双向模型 + 速度支持交互式应用" 的目标。
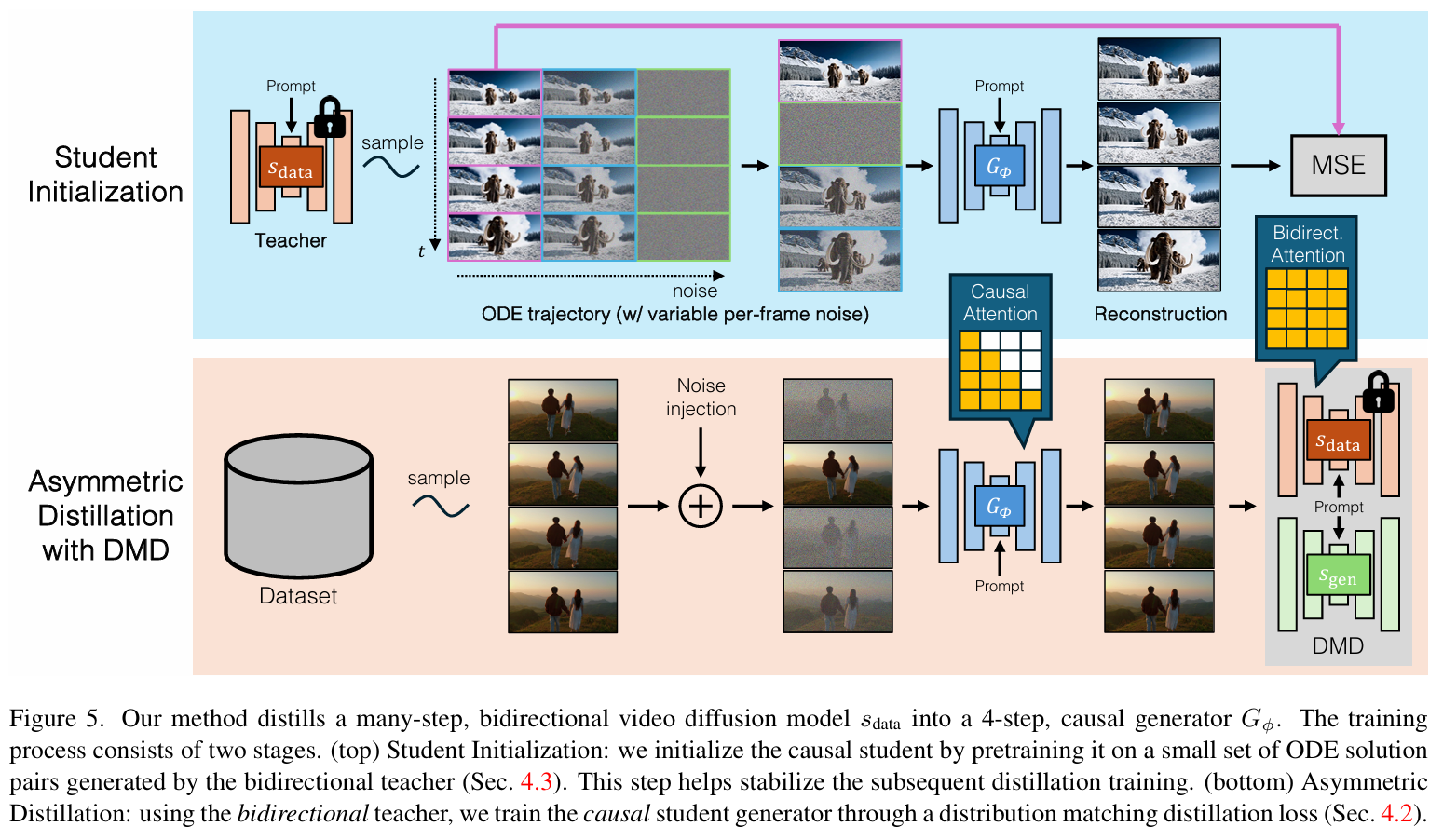
3.1 块级因果注意力:平衡质量与效率
CausVid 没有采用纯逐帧的因果注意力,而是设计了块级因果注意力机制:
- 用 3D VAE 将原始视频压缩到潜空间:每 16 个连续的像素帧被压缩为5 个潜帧,组成一个chunk(块)
- 块内:使用双向自注意力,捕捉局部短时间内的运动和内容一致性
- 块间:使用因果自注意力,禁止当前块访问未来块,保证生成的因果性
这种设计的优势非常明显:
- 块内双向注意力保证了局部时序一致性,避免了纯逐帧生成的闪烁问题
- 块间因果注意力保证了整体的生成因果性,支持流式生成
- 可以完全复用预训练双向 DiT 的权重,仅修改注意力掩码,大幅降低训练成本
3.2 非对称 DMD 蒸馏:用高质量教师教因果学生
这是 CausVid 最核心、最具突破性的创新。
传统蒸馏的问题
传统的自回归视频蒸馏采用 "因果教师→因果学生" 的对称蒸馏范式,但存在致命缺陷:
- 因果教师本身的生成质量就远低于双向教师
- 因果教师的误差累积问题会直接传递给学生
- 最终学生模型的质量无法达到实用标准
CausVid 的非对称蒸馏
CausVid 反其道而行之,提出了 **"双向教师→因果学生" 的非对称蒸馏范式 **:
- 教师:冻结的预训练双向 DiT 模型(质量高,但延迟高、无法交互)
- 学生:因果自回归 DiT 模型(延迟低、可交互,但直接训练质量差)
这种设计的妙处在于:
- 用高质量双向教师的监督信号,直接指导因果学生的训练
- 有效抑制了自回归生成的误差累积问题
- 让因果学生直接继承了双向教师的高质量生成能力
DMD 蒸馏的本质
分布匹配蒸馏(DMD)的核心是让学生模型的输出分布尽可能逼近教师模型的输出分布,而不是简单地模仿单个样本。这保证了学生模型不仅生成质量高,还能保留足够的输出多样性。
3.3 ODE 轨迹初始化:解决架构差异导致的训练不稳定
直接用 DMD 损失训练因果学生时,由于双向教师和因果学生的注意力架构差异巨大,训练会严重震荡甚至不收敛。
CausVid 的解决方案是ODE 轨迹初始化:
- 用确定性 ODE 求解器(如 DDIM)让双向教师生成从 "纯噪声→干净视频" 的完整确定性路径(即 ODE 轨迹)
- 从轨迹中精确抽取与学生 4 步推理对应的 4 个时间点([999, 748, 502, 247])
- 用简单的 MSE 损失让学生模型拟合这些轨迹点,进行 3000 次迭代的预训练
这个过程就像给学生做了一次 "架构适配预热",让它先学会用因果注意力模仿教师的基本生成行为,为后续的分布级蒸馏打下稳定基础。
3.4 KV 缓存:实现恒定速度的流式生成
很多人会问:因果模型每次生成都要依赖之前的所有帧,那视频越长,计算量不是越大吗?
答案是不会,因为有 **KV 缓存(Key-Value Caching)** 机制。
KV 缓存的工作原理
- 生成第 1 个 chunk 时,计算它的 Key 和 Value 并缓存起来
- 生成第 2 个 chunk 时,只需要计算第 2 个 chunk 的 Key 和 Value,然后和缓存中第 1 个的 KV 拼接起来计算注意力
- 历史 KV 值永远不需要重新计算
效果
- 计算量从 O (F²)(平方增长)变为 O (F)(线性增长,实际是常数级)
- 生成第 1000 个 chunk 的计算量和第 1 个完全相同
- CausVid 的 9.4FPS 吞吐量是绝对恒定的,和视频长度无关
这是因果模型能实用化的核心技术,没有 KV 缓存,自回归视频生成永远只能停留在实验室阶段。
四、CausVid 的完整训练与推理流程
4.1 两阶段训练流程
CausVid 的训练分为两个严格串行的阶段,总训练时长约 2 天(64 张 H100 GPU):
第一阶段:ODE 初始化(3000 次迭代)
- 冻结双向教师模型的所有参数
- 用教师生成 1000 对 ODE 轨迹样本
- 用 MSE 损失训练因果学生,让它拟合教师的 ODE 输出
- 此阶段不使用真实数据集,也不计算 DMD 损失
第二阶段:非对称 DMD 蒸馏(6000 次迭代)
- 丢弃所有 ODE 轨迹数据,使用真实视频数据集
- 对每个视频 chunk,随机从 4 个时间步中采样一个,注入对应强度的噪声
- 因果学生输入带噪声的 chunk,预测干净的 chunk
- 计算 DMD 分布损失,同时更新学生模型和在线分数模型
- 教师模型始终保持冻结,且始终使用双向注意力
4.2 逐块流式推理流程
这是 CausVid 与传统双向模型最本质的区别:
- 加载模型和文本提示,初始化空的 KV 缓存
- 生成第 1 个 chunk:
- 初始化 5 个潜帧的纯噪声(t=999)
- 执行 4 步去噪:t=999→748→502→247→干净潜帧
- 用 3D VAE 解码器还原为 16 个像素帧
- 立即输出这 16 帧(初始延迟 1.3 秒)
- 计算当前 chunk 的 KV 值,存入缓存
- 生成第 2 个 chunk:
- 初始化新的纯噪声 chunk(还是从 t=999 开始)
- 执行 4 步去噪,历史信息全部从 KV 缓存读取
- 还原为 16 个像素帧并立即输出
- 追加 KV 值到缓存
- 重复步骤 3,直到用户停止生成或达到预设长度
对比传统双向模型:必须先生成所有 128 帧的纯噪声,然后执行 50 步全帧双向注意力计算,最后一次性输出所有帧,总延迟 219 秒。
五、实验结果:质量与速度的双重突破
5.1 基准测试成绩
CausVid 在 VBench-Long 官方榜单上以84.27的总分登顶,超越了所有已公开的视频生成模型。
在 10 秒短视频生成任务上,CausVid 在 VBench 的三项核心指标上均排名第一:
表格
| 方法 | 时间质量 | 帧质量 | 文本对齐 |
|---|---|---|---|
| CogVideoX-5B | 89.9 | 59.8 | 29.1 |
| OpenSORA | 88.4 | 52.0 | 28.4 |
| Pyramid Flow | 89.6 | 55.9 | 27.1 |
| MovieGen | 91.5 | 61.1 | 28.8 |
| CausVid(Ours) | 94.7 | 64.4 | 30.1 |
5.2 效率对比
在单张 H100 GPU 上生成 10 秒 120 帧 640×352 视频:
表格
| 方法 | 总延迟(s) | 初始延迟(s) | 吞吐量(FPS) |
|---|---|---|---|
| CogVideoX-5B | 208.6 | - | 0.6 |
| 双向教师模型 | 219.2 | - | 0.6 |
| Pyramid Flow | 6.7 | - | 2.5 |
| CausVid(Ours) | - | 1.3 | 9.4 |
CausVid 的初始延迟降低了 160 倍,吞吐量提升了 16 倍,真正达到了交互式应用的帧率要求。
5.3 人类偏好研究
在与 MovieGen、CogVideoX、Pyramid Flow 的盲测对比中,CausVid 的偏好率均超过 50%,与双向教师模型相当。这证明了 CausVid 的生成质量已经达到了人类可感知的 SOTA 水平。
六、CausVid 的零样本应用能力
CausVid 仅通过文本生视频训练,即可零样本支持多种交互式应用:
- 图像生成视频:将输入图像复制为第一个 chunk,自回归生成后续帧,在 VBench-I2V 基准上时间质量达 92.0,超越 CogVideoX 和 Pyramid Flow
- 流式视频转视频:对输入视频块注入噪声后一步去噪,实现实时风格迁移和内容编辑
- 动态提示:在生成过程中任意时刻修改文本提示,下一个 chunk 就会使用新的提示进行生成,支持构建长篇叙事和交互式内容
例如,你可以先生成一个人在公园走路的视频,中途把提示改成 "这个人开始跑步",CausVid 会无缝衔接,让人物从走路自然过渡到跑步,而传统模型必须从头开始重新生成整个视频。
七、局限性与未来方向
CausVid 虽然取得了重大突破,但仍存在一些局限性:
- 长程一致性:滑动窗口推理仅保留最近 10 秒的上下文,极长视频中物体再次出现时可能出现不一致
- 延迟瓶颈:当前 3D VAE 需生成 5 个潜帧才能输出像素,限制了最低初始延迟
- 输出多样性:基于反向 KL 的 DMD 蒸馏会导致输出多样性略有降低
未来的改进方向包括:
- 开发帧级 VAE,进一步降低初始延迟
- 探索 EM-Distillation 等保留多样性的蒸馏目标
- 通过长视频微调提升长程一致性
- 结合模型编译、量化等工程优化,实现真正的实时生成(30FPS 以上)
八、总结
CausVid 通过创新的非对称蒸馏技术,首次证明了自回归视频生成模型可以达到与双向模型相当的质量,同时实现了 1.3 秒的初始延迟和 9.4FPS 的流式生成。它不仅解决了传统视频生成的延迟痛点,更开启了交互式视频生成的新时代。
未来,随着技术的进一步发展,我们有望看到 CausVid 这类模型应用于实时游戏渲染、直播内容实时编辑、虚拟数字人驱动、机器人视觉模拟等领域,彻底改变我们创作和消费视频内容的方式。
参考资料:
[1] Yin T, Freeman W T, Zhang Q, et al. From Slow Bidirectional to Fast Autoregressive Video Diffusion Models [J]. arXiv preprint arXiv:2412.07772, 2024.
[2] CausVid 官方项目主页:https://causvid.github.io/
[3] VBench 官方榜单:https://huggingface.co/spaces/Vchitect/VBench_Leaderboard
#视频生成 #扩散模型 #CausVid #人工智能 #计算机视觉 #自回归 #交互式生成

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 25
25 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)