机器学习 —— 逻辑回归(混淆矩阵)
目录
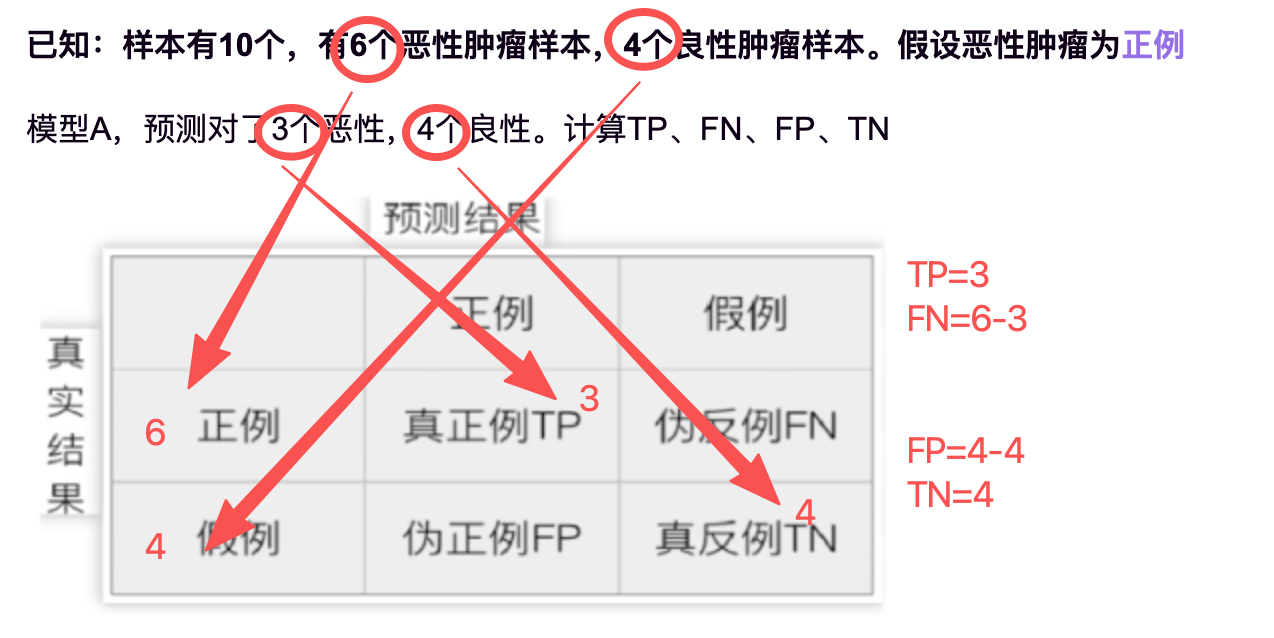
已知:样本有10个,有6个恶性肿瘤样本,4个良性肿瘤样本。假设恶性肿瘤为正例
模型A,预测对了3个恶性,4个良性。计算TP、FN、FP、TN
模型B,预测对了6个恶性,1个良性。计算TP、FN、FP、TN
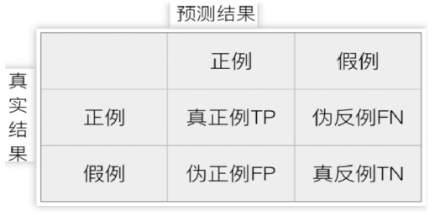
模型的预测结果与实际标签的对比情况
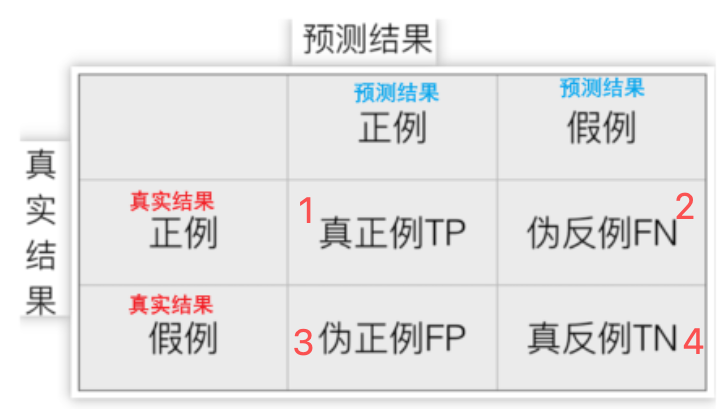
1.真实值是正例,预测值为正例 —— 真正例 TP (True Positive)
2.真实值是正例,预测值为假例 —— 伪反例 FN (False Positive)
3.真实值是假例,预测值为正例 —— 真反例 FP (False Positive)
4.真实值是假例,预测值为假例 —— 真反例 TN (False Negative)
精确率(Precision)
查准率,对正例样本的预测准确率。
计算方法


召回率(Recall)
查全率,指的是预测为真正例样本占所有真正正例样本的比重
计算方法
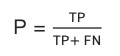

F1-score
若对模型的精确率、召回率都有要求,评估模型在这两个评估方向的综合预测能力。
计算方法
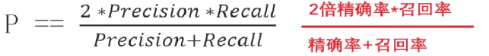
具体案例:
已知:样本有10个,有6个恶性肿瘤样本,4个良性肿瘤样本。假设恶性肿瘤为正例
模型A,预测对了3个恶性,4个良性。计算TP、FN、FP、TN
精确率P = TP / (TP + FP) = 3 / (3 + 0) = 100%
召回率P = TP/ (TP + FN) = 3 / (3 + 3) = 50%
F1 - score = 2 * 精确率P * 召回率P / (精确率P + 召回率P)
= 2* 1 * 0.5 / (1.5)
= 67%
分析->
对了7个,样本有10个,剩余3个预测错了。
样本6个恶心,预测3个良性
样本4个良性,预测4个良性。
所以剩下3个良性
代码数据为
y_predict_A = ['恶性','恶性','恶性','良性','良性','良性','良性','良性','良性','良性']
模型B,预测对了6个恶性,1个良性。计算TP、FN、FP、TN

精确率P = TP / (TP + FP) = 6 / (6 + 3) = 67%
召回率P = TP/ (TP + FN) = 6 / (6 + 0) = 100%
F1 - score = 2 * 精确率P * 召回率P / (精确率P + 召回率P)
= 2* (6/9) * 1 / (1+6/9)
= 80%
分析->
对了7个,样本有10个,剩余3个预测错了。
样本6个恶性,预测6个恶性
样本4个良性,预测1个良性。
所以剩下3个恶性
代码数据为
y_predict_B = ['恶性','恶性','恶性','恶性','恶性','恶性','恶性','恶性','恶性','良性']
代码 - > 混淆矩阵模型
1.导包
import pandas as pd
from sklearn.metrics import confusion_matrix #混淆矩阵
from sklearn.metrics import (
accuracy_score, # 准确率
recall_score, # 召回率
precision_score, # 精确率
f1_score # F1分数
)2.真实数据
y_train = ['恶性','恶性','恶性','恶性','恶性','恶性','良性','良性','良性','良性']
3.模型A 模型B 预测值
y_predict_A = ['恶性','恶性','恶性','良性','良性','良性','良性','良性','良性','良性']
y_predict_B = ['恶性','恶性','恶性','恶性','恶性','恶性','恶性','恶性','恶性','良性']4.构建混淆矩阵
label = ['恶性','良性'] #标签1 代表(正例)
cm_A = confusion_matrix(y_train, y_predict_A,labels=label)
cm_B = confusion_matrix(y_train, y_predict_B,labels=label)5.优化混淆矩阵
df_label = ['恶性(正例)','良性(反例)']
df_A = pd.DataFrame(cm_A,index=df_label,columns=df_label)
df_b = pd.DataFrame(cm_B,index=df_label,columns=df_label)
print(f'混淆矩阵模型A:\n {df_A}')
print(f'混淆矩阵模型B:\n {df_b}')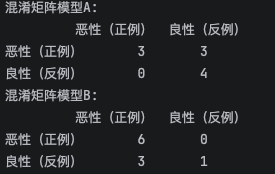
6.模型评估
print("============= 模型A ================")
print(f'准确率:{accuracy_score(y_train,y_predict_A):.2f}')
print(f'精确率:{precision_score(y_train,y_predict_A,pos_label="恶性"):.2f}')
print(f'召回率:{recall_score(y_train,y_predict_A,pos_label="恶性"):.2f}')
print(f'F1-sore:{f1_score(y_train,y_predict_A,pos_label="恶性"):.2f}')
print("============= 模型B ================")
print(f'准确率:{accuracy_score(y_train,y_predict_B):.2f}')
print(f'精确率:{precision_score(y_train,y_predict_B,pos_label="恶性"):.2f}')
print(f'召回率:{recall_score(y_train,y_predict_B,pos_label="恶性"):.2f}')
print(f'F1-sore:{f1_score(y_train,y_predict_B,pos_label="恶性"):.2f}')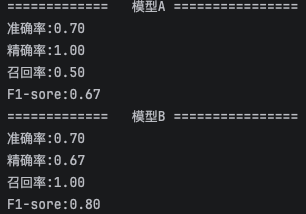
总结
分类模型评估指标 准确率、精确率、召回率、F1-score
回归模型评估指标 MAE、MSE、RMSE

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)