NLP自然语言处理-Bert篇
一、简介
BERT(Bidirectional Encoder Representations from Transformers)是由Google于2018年10月提出的一种基于Transformer的预训练语言模型,基于2017年发布的transform,的编码器的架构设计。它在NLP任务中取得了突破性的成果,极大地提升了模型在问答、文本分类等任务上的表现。
BERT在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩: 全部两个衡量指标上全面超越人类, 并且在11种不同NLP测试中创出SOTA表现。包括将GLUE基准推高至80.4% (绝对改进7.6%), MultiNLI准确度达到86.7% (绝对改进5.6%)。成为NLP发展史上的里程碑式的模型成就。
核心思想
BERT的核心思想是双向编码和Transformer结构。以往的语言模型,如ELMo,通常采用单向或浅层双向的方式处理文本。BERT首次使用了真正的双向Transformer编码器,使得模型能够同时考虑上下文中的信息,从而更好地理解语言的含义。
二、架构
总体架构: 如下图所示, 最左边的就是BERT的架构图, 可以很清楚的看到BERT采用了Transformer Encoder block进行连接, 因为是一个典型的双向编码模型。
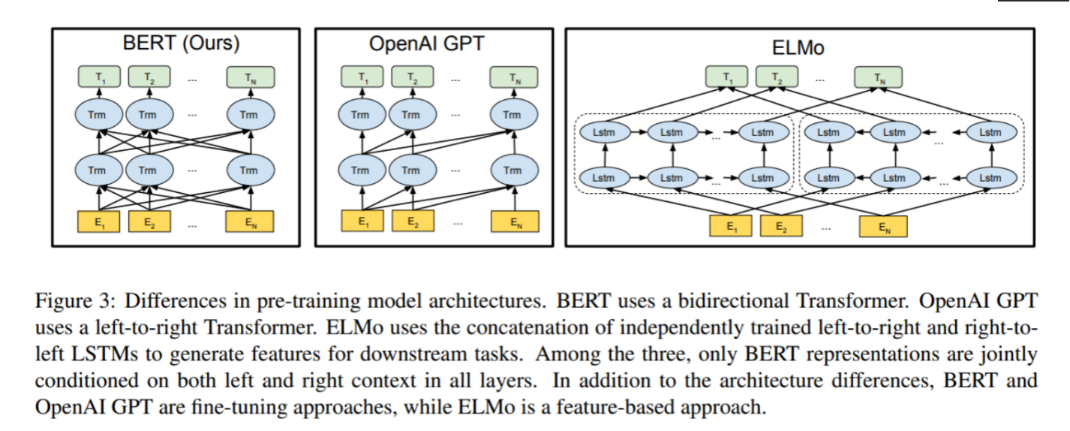
从上面的架构图中可以看到, 宏观上BERT分三个主要模块:
-
最上层绿色标记的预微调模块
-
中间层蓝色标记的Transformer模块
-
最底层黄色标记的Embedding模块
2.1Embedding模块
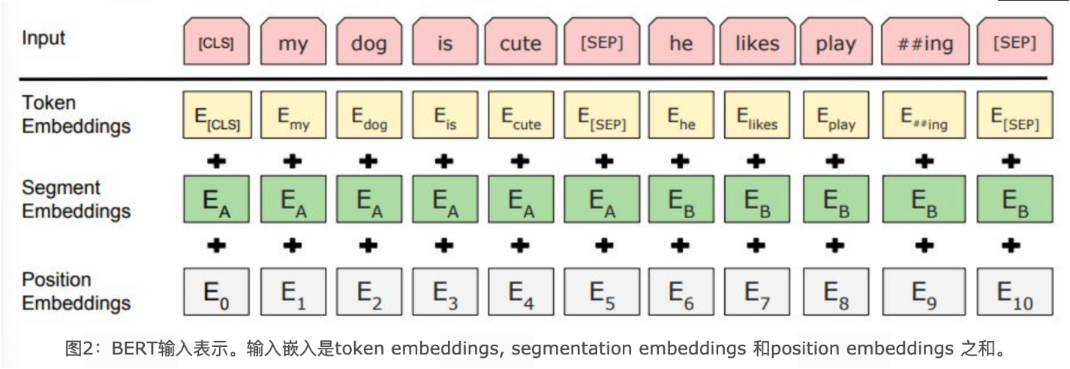
BERT中的该模块是由三种Embedding共同组成而成, 如下图:
-
Token Embeddings:词嵌入张量, 第一个单词是CLS标志, 可以用于之后的分类任务
-
Segment Embeddings:句子分段嵌入张量, 是为了服务后续的两个句子为输入的预训练任务
-
Position Embeddings:位置编码张量, 此处注意和传统的Transformer不同, 不是三角函数计算的固定位置编码, 而是通过学习得出来的
-
整个Embedding模块是这三个部分并行处理,然后将结果相加
2.2双向Transformer模块
BERT中只使用了经典Transformer架构中的Encoder部分, 完全舍弃了Decoder部分。而两大预训练任务也集中体现在训练Transformer模块中。
多层 Transformer 编码器, 每个编码器包含:
-
自注意力机制 (Self-Attention): 这是 Transformer 的核心,允许模型在处理每个单词时,关注句子中其他所有单词,从而捕捉单词之间的关系。 BERT 使用多头自注意力机制 (Multi-Head Attention),可以捕捉不同类型的关系。
-
前馈神经网络 (Feed-Forward Network): 对自注意力机制的输出进行进一步处理。
-
残差连接 (Residual Connection) 和层归一化 (Layer Normalization): 为了提高模型的训练效率和稳定性。
BERT 模型的层数和隐藏层维度是可配置的。 常见的 BERT 版本包括 BERT-base (12 层编码器,768 个隐藏单元) 和 BERT-large (24 层编码器,1024 个隐藏单元)。
2.3预微调模块
-
经过中间层Transformer的处理后, BERT的最后一层根据任务的不同需求而做不同的调整即可
-
比如对于sequence-level的分类任务, BERT直接取第一个[CLS] token的final hidden state, 再加一层全连接层后进行softmax来预测最终的标签
-
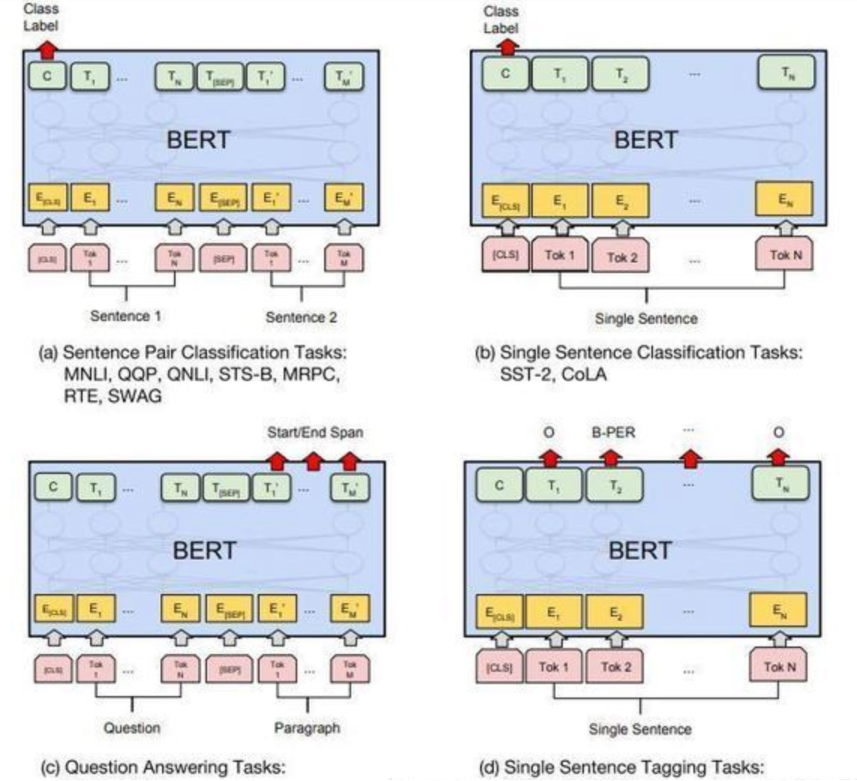
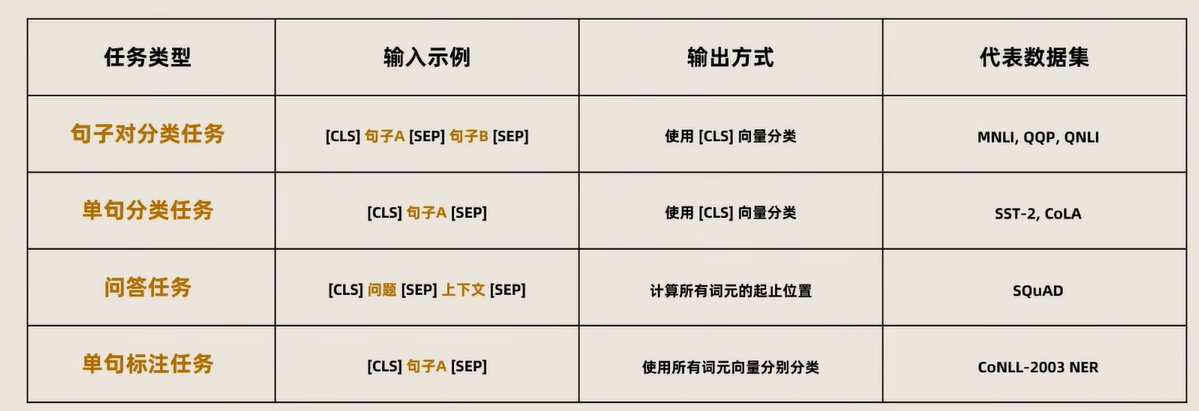
对于不同的任务, 微调都集中在预微调模块, 几种重要的NLP微调任务架构图展示如下
-
a:句子对任务
-
输入:
[CLS] + 句子1 + [SEP] + 句子2 + [SEP] -
输出:
[CLS]标记的隐藏状态经过一个全连接层,输出分类结果(如是否相似)。
-
-
b:文本分类
-
输入:
[CLS] + 句子 + [SEP] -
输出:
[CLS]标记的隐藏状态经过一个全连接层,输出类别概率。
-
-
c:问答任务 (QA)
-
输入:
[CLS] + 问题 + [SEP] + 段落 + [SEP] -
输出:模型预测答案在段落中的起始和结束位置。
-
-
d:命名体识别(NER)
-
输入:
[CLS] + 句子 + [SEP] -
输出:每个单词的隐藏状态经过一个分类层,输出实体标签(如人名、地名)。
-
-
从上图中可以发现, 在面对特定任务时, 只需要对预微调层进行微调, 就可以利用Transformer强大的注意力机制来模拟很多下游任务, 并得到SOTA的结果. (句子对关系判断, 单文本主题分类, 问答任务(QA), 单句贴标签(NER))
-
若干可选的超参数建议如下:
-
Batch size: 16, 32
-
Learning rate (Adam): 5e-5, 3e-5, 2e-5
-
Epochs: 3, 4
三、BERT的预训练任务
BERT包含两个预训练任务:
-
任务一: Masked Language Model (MLM:带mask的语言模型训练)
-
任务二: Next Sentence Prediction (NSP:下一句话预测任务)
3.1 Masked Language Model (MLM)
MLM是BERT的核心预训练任务,旨在让模型学习词级别双向上下文表示。
关于传统的语言模型训练, 都是采用left-to-right, 或者left-to-right + right-to-left结合的方式, 但这种单向方式或者拼接的方式提取特征的能力有限. 为此BERT提出一个深度双向表达模型(deep bidirectional representation)。 即采用MASK任务来训练模型。
🎯 1. 随机掩码 (Masking)
BERT 在预训练时,会随机选择输入句子中约 15% 的词(token)进行“掩盖”。这个掩盖操作并非简单地全部替换为 [MASK] 标记,而是采用了一种更精细的策略来增强模型的鲁棒性:
-
80% 的情况:将选中的词替换为特殊的
[MASK]标记, 比如my dog is hairy -> my dog is [MASK]。 -
10% 的情况:将选中的词替换成一个随机的词,, 比如my dog is hairy -> my dog is apple。
-
10% 的情况:保持原词不变, 比如my dog is hairy -> my dog is hairy。
这种混合策略可以防止模型过度依赖 [MASK] 标记本身,并模拟了真实场景中的噪声,迫使模型真正学习上下文语义。
🧠 2. 上下文编码 (Contextual Encoding)
经过掩码处理的句子被输入到 BERT 模型中。BERT 的核心是多层 Transformer 编码器,它通过自注意力机制(Self-Attention)让每个词都能“看到”句子中的所有其他词。
因此,模型会为每个位置(包括被掩盖的位置)输出一个新的向量表示。这个向量不再是静态的,而是蕴含了该位置词语本身以及其完整上下文(左侧和右侧)的深层语义信息。这正是 BERT“双向”理解能力的体现。
🔮 3. 预测被掩盖的词 (Prediction)
对于被掩盖的位置,其输出的上下文向量会被送入一个专门用于预测的输出层。这个输出层通常就是一个全连接神经网络(Linear Layer),它将 BERT 输出的高维向量映射到整个词汇表的大小。
接着,通过一个 Softmax 函数,将这个映射后的向量转换成一个概率分布。这个分布中的每一个值,都代表了词汇表中对应词语是被掩盖词的可能性。最终,模型会选择概率最高的那个词作为预测结果。
3.2 Next Sentence Prediction (NSP)
NSP任务旨在让模型理解句子间的关系,适用于需要句子对输入的任务(如问答、自然语言推理)。
在NLP中有一类重要的问题比如:QA(Quention-Answer)问答, NLI(Natural Language Inference)自然语言推理, 需要模型能够很好的理解两个句子之间的关系, 从而需要在模型的训练中引入对应的任务. 在BERT中引入的就是Next Sentence Prediction任务。采用的方式是输入句子对(A, B), 模型来预测句子B是不是句子A的真实的下一句话。
所有参与任务训练的语句都被选中作为句子A.
-
其中50%的B是原始文本中真实跟随A的下一句话. (标记为IsNext, 代表正样本)
-
其中50%的B是原始文本中随机抽取的一句话. (标记为NotNext, 代表负样本)
-
模型预测第二个句子是否是第一个句子的下一句,输出是一个二分类标签(是/否)
在任务二中, BERT模型可以在测试集上取得97%-98%的准确率.
3.3 预训练与微调的关系
-
预训练:在大规模无标签数据上学习通用的语言表示。
-
微调:在特定任务的小规模有标签数据上调整模型参数,使其适应具体任务。
BERT的预训练和微调机制使其能够高效地迁移到各种NLP任务中,而无需从头训练模型。
四、小结
1.什么是BERT
-
BERT是一个基于Transformer Encoder的预训练语言模型.
-
BERT在11种NLP测试任务中创出SOAT表现.
2.BERT的结构
-
最底层的Embedding模块, 包括Token Embeddings, Segment Embeddings, Position Embeddings.
-
中间层的Transformer模块, 只使用了经典Transformer架构中的Encoder部分.
-
最上层的预微调模块, 具体根据不同的任务类型来做相应的处理.
3.BERT的两大预训练任务 - MLM任务(Masked Language Model), 在原始文本中随机抽取15%的token参与任务. - 在80%概率下, 用[MASK]替换该token. - 在10%概率下, 用一个随机的单词替换该token. - 在10%概率下, 保持该token不变. - NSP任务(Next Sentence Prediction), 采用的方式是输入句子对(A, B), 模型预测句子B是不是句子A的真实的下一句话. - 其中50%的B是原始文本中真实跟随A的下一句话.(标记为IsNext, 代表正样本) - 其中50%的B是原始文本中随机抽取的一句话. (标记为NotNext, 代表负样本)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)