AI圈最近疯狂造词,Prompt工程→上下文工程→Harness工程,你在第几层?
目录
第一层:Prompt Engineering——学会跟天才说话
第二层:Context Engineering——给天才配全参考资料
第五层:Harness Engineering——给天才套上缰绳
读完这篇,你会明白:为什么光有一个强大的AI还不够,以及怎么从零搭出一个真正能干活的AI Agent
开场:你是不是也有这种感觉
上个月刚把Chain of Thought提示词练熟,感觉自己是AI界高手了。
这周朋友发来一篇文章:《Prompt Engineering已经过时了,学Context Engineering吧》
下周又看到:《MCP、Skill、Agent……》
再下周:《Context Engineering也不够,Harness Engineering才是未来》
我:?
能不能等我把上周的消化完再出新词?
但仔细一想,这些词其实不是在互相替代——它们是一层套一层的关系。
今天我们换一个角度来理解它们:
假设你要从零开始搭一个真正能干活的AI Agent,你需要依次解决哪些问题?
答案,就是这些词出现的顺序。
跟我走,一层一层来。
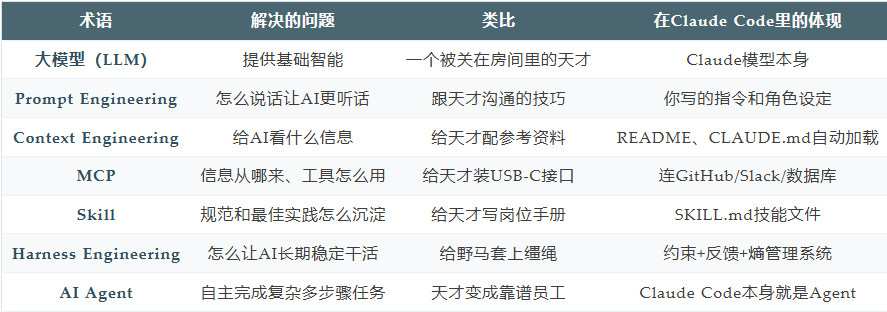
第 0 层:大模型——一切的地基
在所有词之前,先搞清楚一件事:
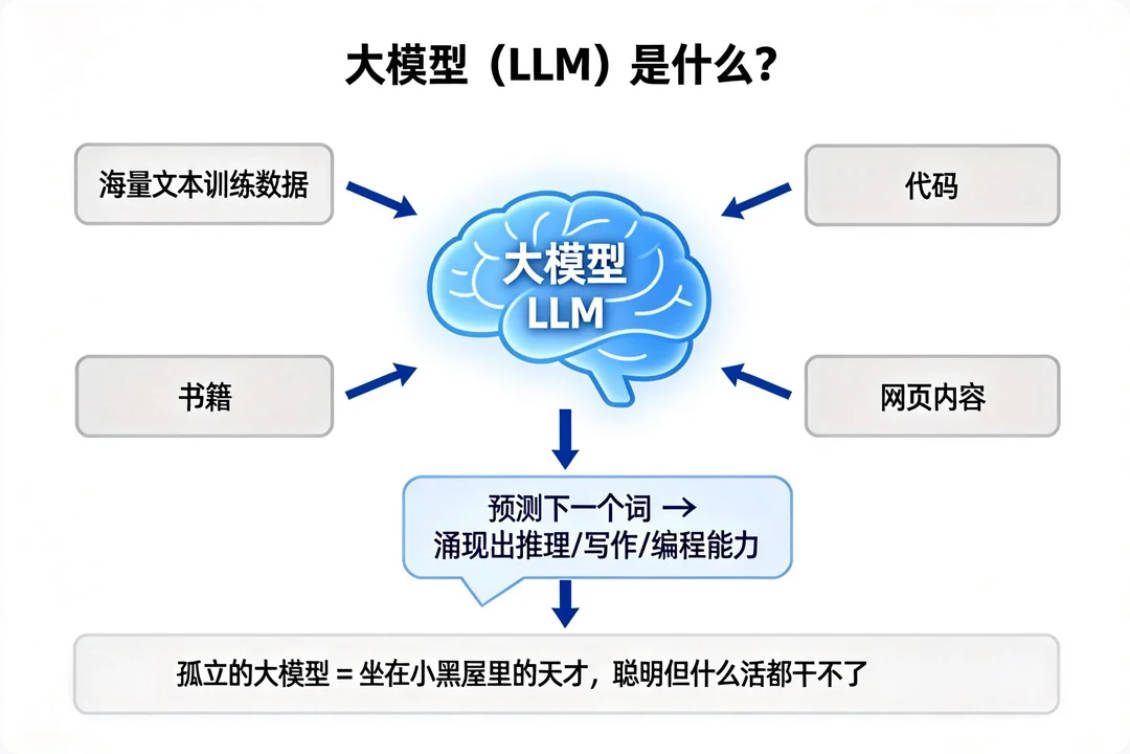
大模型(LLM,Large Language Model)是什么?
简单说,大模型是一个经过海量文本训练的"超级预测机器"——你给它一段话,它预测下一个词应该是什么,然后再预测下下个词,一直预测下去,就成了一段看起来很有道理的回答。
听起来很简单对吧?
但就是这个"预测下一个词"的能力,在参数规模足够大的时候,涌现出了推理、写作、写代码、解数学题的能力。
这就是为什么GPT、Claude、GLM-5.1这些模型被叫做"大"模型——不是因为它们体积大,是因为它们的参数规模大到出现了质变。
但问题来了:
大模型本身,只是一个"坐在房间里等你提问"的天才。
它不主动做事,不记得昨天聊了什么,不知道你的项目是什么,也不会自己去查资料。
一个孤立的大模型,就像一个被关在小黑屋里的天才——聪明归聪明,但什么活都干不了。
所以,问题变成了:怎么把这个天才,一步步变成一个真正能干活的员工?
第一层:Prompt Engineering——学会跟天才说话
天才进了房间,你第一件要做的事是什么?
跟他说话。
这就是Prompt Engineering(提示词工程)解决的问题:怎么跟大模型说话,才能让它输出更好的结果?
你可能试过这两种问法:
❌ 普通版:「帮我写个报告」
✅ 进阶版:「你是一名有10年经验的行业分析师,请用数据驱动的方式,为科技创业公司写一份500字的市场分析报告,结构包括:市场规模、竞争格局、机会点,语气专业但不晦涩」
同一个模型,输出天差地别。
这就是提示词工程的价值——通过角色设定、思维链(Chain of Thought)、少样本示例(Few-shot)等技巧,让大模型的"预测"方向更精准。
但它有一个根本性的天花板:
只解决了单次对话的问题。
你跟它说了半天,下一个对话窗口打开,它完全不记得你是谁,你的项目是什么,你们昨天达成了什么共识。
每次对话都要重新自我介绍,就像每天见面都忘了你的同事。
这不是模型的问题,这是"只有提示词"这种方式的结构性缺陷。

第二层:Context Engineering——给天才配全参考资料
提示词练好了,但你发现一个新问题:
这个天才虽然博学,但他只知道训练数据里有的东西。
你的项目文档、你的代码库、你们公司的规范、今天发生的新闻——他一概不知道。
怎么办?
把这些信息塞给他看。
这就是Context Engineering(上下文工程)的核心逻辑:
不只是写好一条指令,而是管理AI能看到的全部信息。
前Tesla AI总监、OpenAI联合创始人Andrej Karpathy给了一个经典定义:
上下文工程是"一门精巧的技艺——把恰好正确的信息,在恰好正确的时刻,以恰好正确的格式,填进AI的上下文窗口"。
这里有个关键概念需要理解:
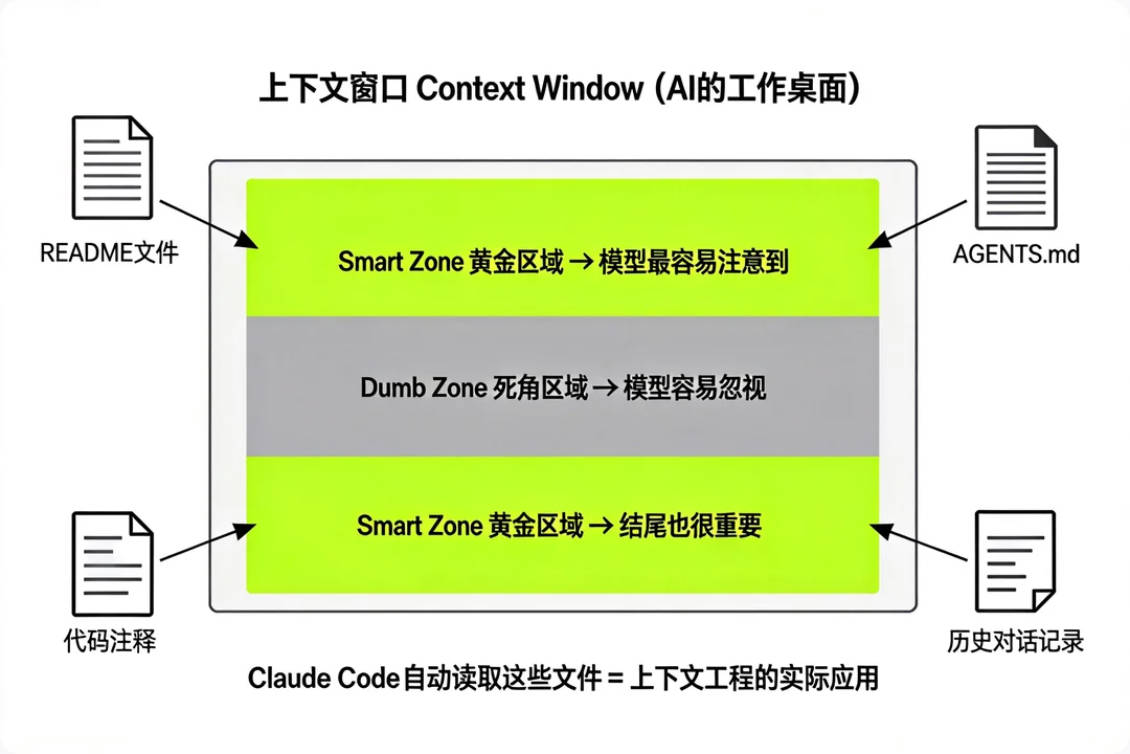
Context Window(上下文窗口)——这是AI每次能"看到"的全部信息的总量,可以理解为AI的"工作桌面"。桌面就这么大,你放什么、怎么放,直接决定它能干多好的活。
研究者还发现了一个有意思的现象:上下文窗口里有Smart Zone(黄金区域)和Dumb Zone(死角区域)——重要信息放在开头和结尾,模型更容易注意到;塞在中间的内容,模型经常"视而不见"。
用Claude Code举个例子:
你用Claude Code帮你写代码,它为什么不需要你每次都解释项目背景?
因为它会自动读取你项目里的readme.md、claude.md、代码注释——这些文件就是你提前准备好的"上下文"。你写得越详细,它干活越靠谱。
这就是上下文工程在真实产品里的体现。
但问题又来了:
信息从哪里来?你不可能手动把所有资料一条条复制粘贴给AI吧?
第三层:MCP——给天才接上互联网
想象一下,你给那个天才的小黑屋装了一排插口——
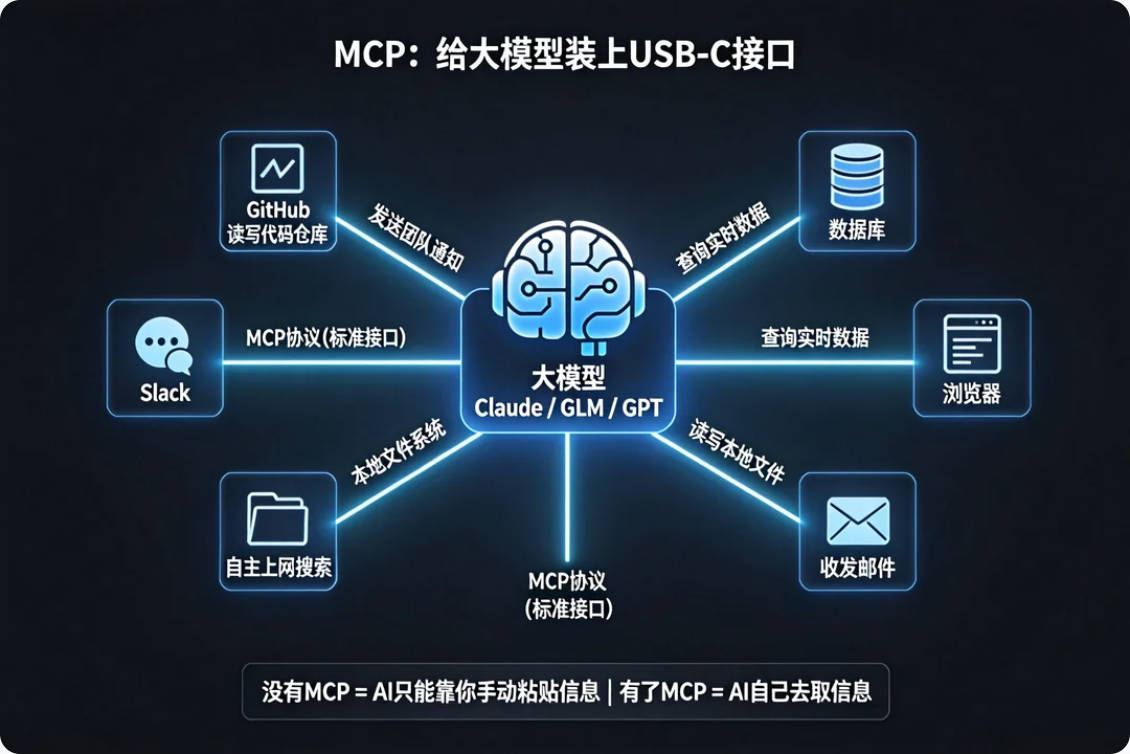
插上GitHub,他就能读你的代码库; 插上Slack,他就能看到团队的对话; 插上数据库,他就能查到实时数据; 插上浏览器,他就能自己上网查资料。
这就是MCP(Model Context Protocol,模型上下文协议)。
这是Anthropic在2024年底提出的开放协议,解决的核心问题是:
让大模型能标准化地连接任何外部工具和数据源。
通俗类比:MCP就像手机的USB-C接口。
以前每个设备都有自己的充电口,乱七八糟;现在统一成USB-C,任何充电器插上就能用。
MCP对AI也是一样——以前每个工具都要单独开发接口,现在按照MCP协议做,任何工具都能接入任何支持MCP的AI。
再用Claude Code举例:
Claude Code通过MCP可以连接GitHub直接提PR,连接数据库直接查数据,连接Slack直接发通知——整个过程AI自主完成,你坐着喝咖啡就好。
MCP和Context Engineering的关系:
MCP是Context Engineering的"基础管道"——它负责把外部世界的信息搬进上下文窗口。
没有MCP,上下文工程的信息来源就只有你手动粘贴进去的内容,严重受限。
有了MCP,上下文窗口里的信息可以是实时的、动态的、来自真实系统的。
第四层:Skill——给天才写入岗位手册
现在这个天才有了信息来源,但你发现一个新问题:
每次让他做同一类任务,他的做法都不一样。
有时候他写PPT风格很好,有时候乱七八糟。 有时候他写代码格式规范,有时候随心所欲。
你不可能每次都在提示词里把规范重新说一遍——那太累了,而且他还是会忘。
解法是什么?
把规范写成文件,让他每次遇到对应任务就去读。
这就是Skill(技能文件)的概念。
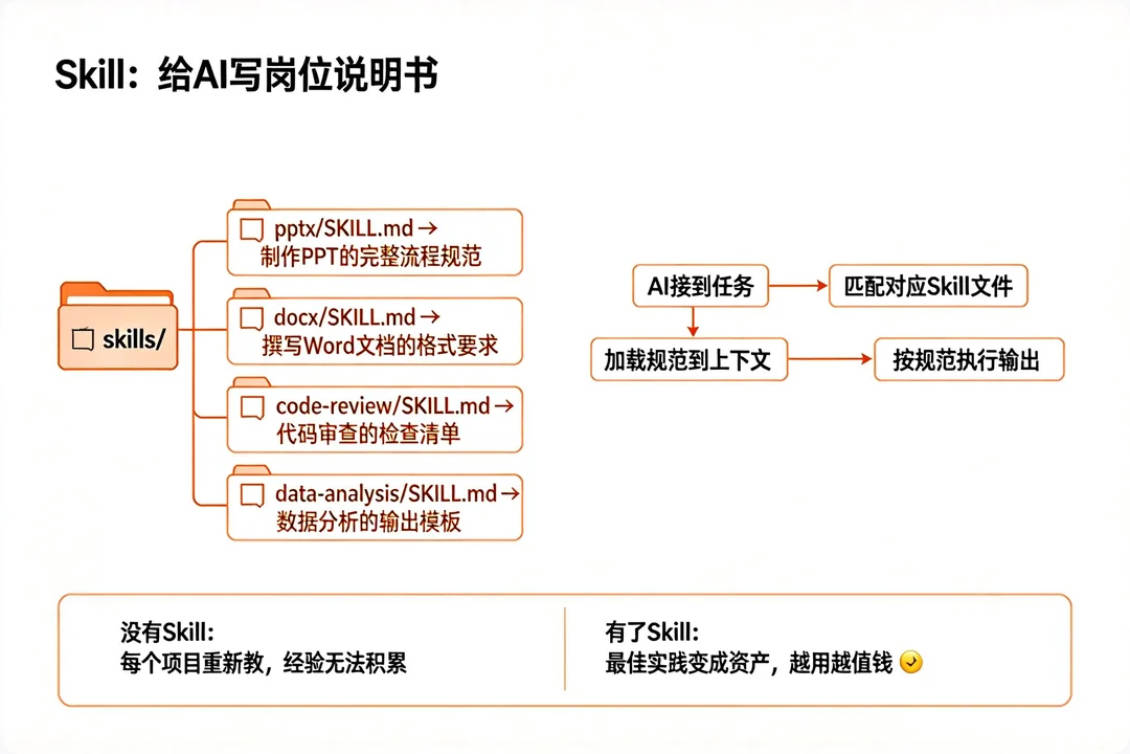
Skill本质上是预先为特定场景写好的结构化指令文件——你把某类任务的最佳实践、注意事项、输出规范都写进去,AI遇到这类任务就加载这个文件。
Claude Code里的实际体现:
Claude Code支持SKILL.md文件。
比如你在项目里放一个pptx/SKILL.md,里面写了"制作PPT时:第一步分析内容结构,第二步选择配色方案,第三步……"。
以后每次让Claude Code帮你做PPT,它就自动去读这个文件,按照你定义的流程来——不用每次重新解释,不会忘记,跨项目也能复用。
Skill和Context Engineering的关系:
Skill是上下文工程里"知识库"那一层的具体实现形式。
它解决的问题是:知识和规范如何沉淀、复用、跨项目迁移。
没有Skill,你的AI每个项目都是重新开始,经验不能积累;
有了Skill,你的最佳实践可以变成资产,越用越值钱。
一句幽默的话: Skill就是给AI写的"岗位说明书"——让它知道在你这里干活,规矩是什么。不然它会凭感觉发挥,而AI的"感觉"……有时候很难评。
第五层:Harness Engineering——给天才套上缰绳
好,现在我们有了:
- 强大的大模型(大脑)
- 精心设计的提示词(说话方式)
- 丰富的上下文信息(参考资料)
- MCP连接的外部工具(手脚)
- Skill文件定义的规范(岗位手册)
这个时候你以为万事俱备了。
然后你让它跑一个复杂任务,回来一看:
它绕了一大圈做了件你根本没让它做的事。或者它改了不该改的文件。或者它"成功完成任务"——但完成的方式和你想的完全不一样。
问题在哪里?
问题在于:你给了它能力、给了它信息、给了它工具、给了它规范,但你没有给它一套完整的约束、反馈和纠错系统。
这就是Harness Engineering(驾驭工程)要解决的问题。
Harness这个词来自驾驭马匹的马具——缰绳、马鞍、嚼子。
这个比喻是刻意为之的:没有Harness的AI智能体,就像是一匹在旷野中的纯血马——速度惊人,令人印象深刻,但对于完成任何实际任务完全无用。
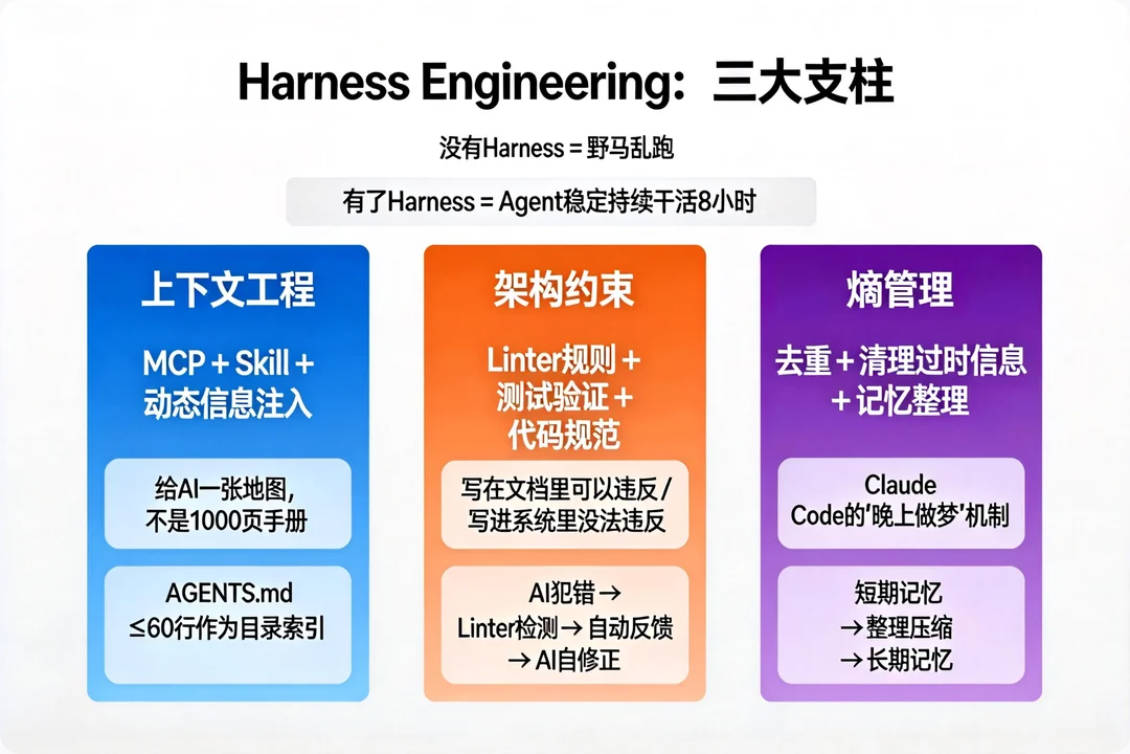
Harness Engineering是目前AI工程的最高层,它包含三大支柱:
支柱一:上下文工程(就是前面讲的那些)
MCP、Skill、动态信息注入——都在这一层。
但Harness Engineering对上下文提出了更高要求:
OpenAI团队发现,传统的"一个巨大的AGENTS.md文件"方法注定失败:上下文是稀缺资源,过多的指导反而变成"陈旧规则的坟场"。
正确做法:用一个≤60行的AGENTS.md当目录索引,按需加载具体细节——给AI一张地图,不是1000页手册。
支柱二:架构约束(让规则长出牙齿)
这是Harness Engineering里最反直觉、也最精髓的部分:
写在文档里的规则,AI可以违反;写进系统里的规则,AI根本没有违反的机会。
OpenAI用AI自己编写Linter(代码检查工具)来约束AI。Linter的错误信息本身也是上下文的一部分,它会告诉AI"为什么错了"以及"如何修复",AI读取后会自动修正代码并重新提交。
这不是在防AI犯错,而是在把纠错机制编进系统——AI犯错→系统自动检测→反馈给AI→AI自动修正→继续推进。
人类工程师甚至不需要在场。
支柱三:熵管理(给AI安排"睡眠")
随着任务越来越长,上下文会越来越乱——过时的信息、矛盾的记录、重复的内容堆积在一起,AI开始"记忆混乱"。
Claude Code的解法是通过后台进程在不活跃时自动激活,对历史信息进行整理——去重、丢弃过时的、合并相关的——形成精炼的新记忆。这个机制被形象地称为"晚上做梦":就像人类睡眠时的记忆固化过程,把短期记忆转化为长期记忆。
AI也需要"睡一觉整理思路",这不是比喻,是真实的工程设计。
Harness Engineering有多重要?两组数据:
LangChain的编码Agent,通过仅优化Agent运行的外部环境(文档结构、验证回路、追踪系统),排名从全球第30位跃升至第5位,得分从52.8%飙升至66.5%。底层模型一个参数都没改。
Anthropic说了一句被广泛引用的话:Agent表现不好,80%的原因不在模型,在Harness。
下次AI犯错,先别骂它——先问问自己:缰绳系好了吗?
最终形态:AI Agent——把前五层全部激活
终于到了这一层。
AI Agent是什么?
就是能自主规划、调用工具、完成多步骤复杂任务的AI系统。
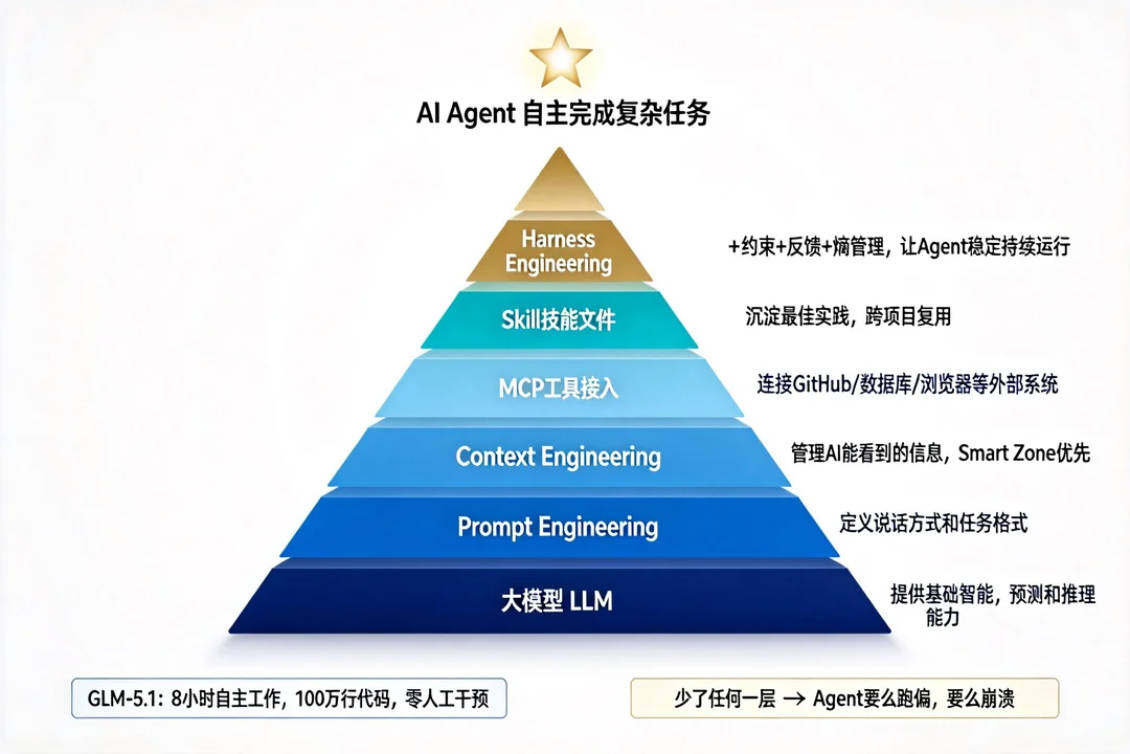
但关键是:Agent不是凭空出现的,它是大模型 + 前面每一层叠加的产物。
用一个公式来表达:
AI Agent = 大模型(大脑) + Prompt Engineering(说话方式) + Context Engineering(参考资料) + MCP(手脚/工具) + Skill(岗位手册) + Harness Engineering(约束+反馈+纠错系统)
少了任何一层,Agent要么能力不够,要么跑偏,要么干着干着崩掉。
一个真实的例子:
GLM-5.1最近开源,能连续自主工作8小时完成工程级任务——100万行代码、零人工干预。
这背后不是因为模型有多神奇,而是因为:
它有完整的工具调用(MCP层),能读写文件、执行命令、查看输出;
它有结构化的任务规划(Skill层),知道先做什么后做什么;
它有完整的错误反馈机制(Harness层),碰壁了会自动切换策略,出错了会自行修复,而不是卡死或乱跑。
研究者提出了一个新的衡量指标:不再问模型"多聪明",而是问它"能独立完成多长时间的人类任务"。前沿模型的这个时间线,每7个月翻一倍。
今天是8小时,7个月后呢?
一张表,串联所有术语
结尾
2023年,大家在学怎么跟AI说话。
2025年,大家在学怎么给AI准备资料。
2026年,真正的问题变成了:怎么给AI搭一套完整的工作系统。
从大模型到AI Agent,不是一步跨过去的——是一层一层搭出来的。
你掌握的层数,决定了你能让AI帮你干多复杂的活。
读完这篇,你应该已经从第一层升到第六层了。
最后一件事:
转发给你那个还在死磕提示词、每次用AI都要解释半天背景的朋友——
告诉他:哥,你现在练的是青铜技能。
这篇文章,能帮他直接跳到黄金段位。
别让他继续输在起跑线上了

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)