人工智能篇---大语言模型
如果说视觉大模型赋予了AI"眼睛",那么大语言模型就是赋予了AI"大脑"和"嘴巴"。它让机器从"识别"跨越到"理解"和"生成",这是人工智能发展史上一次根本性的范式跃迁。
第一部分:语言模型的"史前时代"——从统计到神经
在大语言模型出现之前,人类已经尝试了多种方式让机器理解语言。
1. 统计语言模型时代(N-Gram)
-
核心思想:一个词出现的概率只与它前面N-1个词有关。比如"我要吃__",统计所有语料里"我要吃"后面接"苹果"、"饭"、"药"的频率,按概率采样。
-
致命缺陷:
-
维度灾难:词汇表有10万个词,3-gram的参数空间就是10万的3次方,根本无法穷举。
-
长程依赖为0:N通常取3-5,句子一长,"前面的主语是单数所以后面动词要用三单"这种依赖关系直接丢失。
-
泛化能力极弱:语料里没见过的词组(如"吃火锅看烟花"),概率直接判0。
-
2. 神经语言模型时代(RNN/LSTM)
-
突破:Bengio团队2003年提出用神经网络建模语言,将词映射为稠密向量(词嵌入),不再需要存储海量N-Gram表。
-
LSTM/GRU的贡献:通过门控机制,让模型拥有了短期记忆,能够处理大约50-100个词范围内的依赖关系。机器翻译、语音识别在这一时期突飞猛进。
-
仍存的瓶颈:
-
串行计算:RNN必须按时间步一步步算,第100个词的梯度要穿越99层回传到第1个词,又慢又容易梯度消失。
-
记忆仍是短期的:读一篇5000字的文章,读到结尾时开头的信息已经模糊了。
-
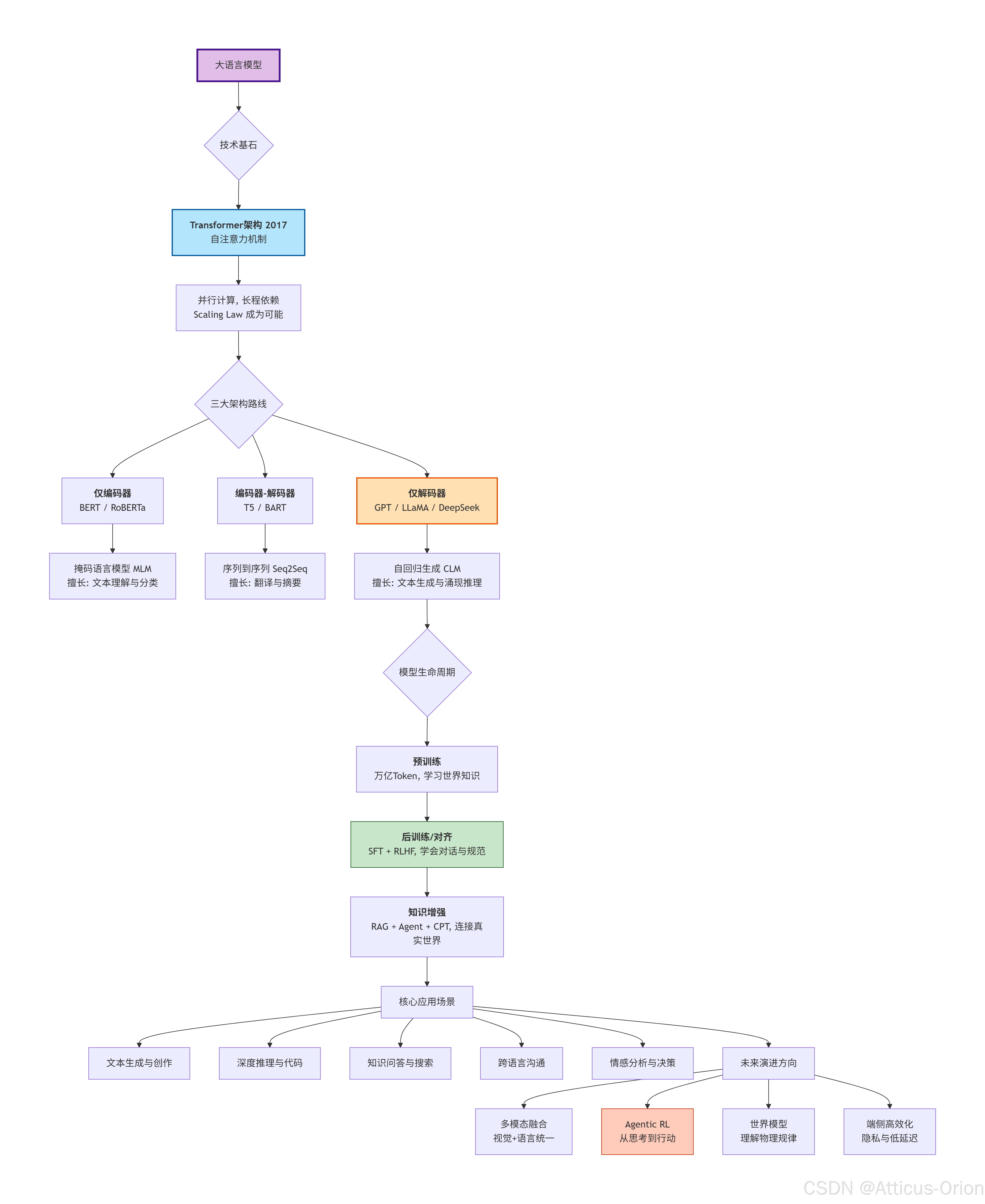
3. 真正引爆核弹的架构:Transformer(2017)
-
论文:Google的《Attention is All You Need》。
-
核心革命——自注意力机制:
想象一个会议室里,每个词都是一个与会者。当轮到"苹果"发言时,它会同时审视房间里所有的词,并给每个词分配一个注意力权重:-
如果语境是科技新闻,"苹果"会高度关注"发布会"、"iPhone"、"库克"。
-
如果语境是菜谱,"苹果"会高度关注"削皮"、"切块"、"烤箱"。
-
-
Transformer带来的三大碾压级优势:
-
并行计算:不再串行,整句话一次性输入,训练速度提升数十倍,Scaling Law(规模定律)成为可能。
-
长程依赖彻底解决:不管词与词相隔多远(1000个词),注意力机制一步就能"看见"。
-
多模态扩展性:同样的架构不仅能处理文字Token,也能处理图像Patch、音频片段——为后来的统一多模态模型铺平了道路。
-
第二部分:大语言模型的进化树——三大技术路线与关键里程碑
Transformer架构出现后,LLM的发展分化为三条主要路线,每条路线都有其独特的哲学和技术选择。
路线一:编码器-解码器架构(Encoder-Decoder)
-
代表模型:T5、BART、最初的Transformer
-
工作方式:编码器"阅读理解"输入,压缩成稠密向量;解码器看着这个向量"写作文"。
-
擅长任务:机器翻译、文本摘要——输入输出有强对应关系的任务。
-
现状:这条路线在多模态融合架构中有复兴趋势(如视觉编码器+语言解码器)。
路线二:仅编码器架构(Encoder-Only)——理解优先
-
代表模型:BERT、RoBERTa、DeBERTa
-
训练方式:掩码语言模型(MLM)——随机挖掉句子里的词让模型填空(完形填空)。
-
特点:双向上下文理解极强,一个词的表示融合了左右两边所有词的信息。
-
杀手锏:在GLUE/SQuAD等"理解类"任务上屠榜。至今仍是搜索排序、情感分析、实体识别的首选基座。
-
局限:不会"生成",只能做判断题和选择题,不能做简答题。
路线三:仅解码器架构(Decoder-Only)——生成优先
-
代表模型:GPT系列、LLaMA、Claude、Gemini、DeepSeek
-
训练方式:自回归语言模型——给定前文,预测下一个词。
-
特点:单向(从左到右),天生就是为"续写"而生的。
-
为什么它成了今天的主角?
因为生成能力涌现出推理能力。当模型被训练得足够大时,它为了更准确地"预测下一个词",不得不内化语法、事实、逻辑链条。GPT-3的1750亿参数让世界第一次看到了少样本学习(Few-shot Learning)的威力:只需给几个例子,模型就能理解新任务,无需任何参数更新。
关键里程碑的演进图谱:
-
2018年 GPT-1 / BERT:证明了Transformer的潜力。
-
2020年 GPT-3 (175B):"涌现能力"的觉醒。一夜之间,Prompt工程成为显学。
-
2022年 ChatGPT (GPT-3.5 + RLHF):对齐技术的胜利。用人类偏好教会模型什么该说、什么不该说,让LLM从实验室走向亿万用户。
-
2023年 GPT-4 / LLaMA 2:多模态与开源生态并进。
-
2024-2025年 o1 / DeepSeek-R1:推理时代。不再是凭直觉蹦词,而是展示内部"思维链",在数学、编程领域逼近人类专家。
第三部分:从"预训练"到"能用"——赋予模型灵魂的三阶段
一个真正可用的LLM,不是一步炼成的,而是经历了三个阶段的生命周期:
阶段一:预训练——"读完人类所有书"
-
数据量:数万亿Token(相当于数千万本书)。
-
目标:学习语言的统计规律和世界知识。
-
产出:Base Model(基座模型)。它的能力是"续写",你问"什么是光合作用?",它只会顺着话茬往下接,可能会说"...是一个有趣的问题,但我不确定",也可能开始胡编。
阶段二:后训练/对齐——"学规矩、学对话"
-
监督微调(SFT):用高质量的人工编写的"问答对"教模型怎么和人聊天。
-
RLHF(基于人类反馈的强化学习):让人类对多个回答排序,模型学习"什么是好答案"的偏好。这是ChatGPT流畅对话感的关键。
-
产出:Instruct/Chat Model。此时它才变成了我们熟悉的"助手"。
阶段三:知识增强与应用——"带上计算器和资料库"
-
RAG(检索增强生成):外挂知识库。问"公司今年报销政策",模型去查内部文档再回答,既专业又杜绝幻觉。
-
Agent(智能体):赋予模型使用工具的能力(搜索网页、调用API、执行Python代码)。从"说"到"做"。
-
增量预训练(CPT/DAP):注入特定领域知识。如eBay用5%的算力成本,让Llama精通电商术语和逻辑,实现领域专家化。
第四部分:LLM的核心能力与典型应用
1. 文本生成与创作
-
从营销文案、新闻摘要到长篇小说的辅助写作,LLM是最强大的"创意副驾驶"。
2. 深度推理与问题求解
-
思维链(Chain-of-Thought):让模型"出声思考",将复杂问题分解为步骤。o1和DeepSeek-R1在AIME数学竞赛中已超过人类平均水准。
-
代码生成:GitHub Copilot背后就是GPT-4,已经改变了软件开发的流程。
3. 知识问答与信息整合
-
传统搜索引擎返回10个蓝色链接,LLM直接整合多个来源给出综合答案。Perplexity和ChatGPT Search正在重塑信息获取方式。
4. 跨语言与跨文化沟通
-
大模型的多语言能力使其成为翻译、本地化的基础设施,甚至能理解方言和网络流行语。
5. 情感分析与决策辅助
-
金融领域分析财报电话会议的情绪倾向,客服领域识别用户不满的早期信号。
第五部分:当前的局限与未来方向
尽管LLM已足够惊艳,但前沿研究者普遍认为纯语言模型有其天花板:
| 挑战维度 | 具体问题 | 演进方向 |
|---|---|---|
| 幻觉 | 会自信满满地编造不存在的事实、论文、法条。 | RAG、严格事实核查、引用溯源。 |
| 推理深度 | 表面流畅但缺乏真正的因果逻辑链。 | o1式的RL推理增强、测试时计算扩展。 |
| 物理世界盲区 | 不知道"杯子掉地上会碎",缺乏常识和世界模型。 | 走向多模态大模型和具身智能。 |
| 成本与效率 | 推理一次消耗巨大算力。 | MoE(混合专家)、量化、蒸馏。 |
| 智能体能力 | 规划执行长流程任务时容易迷失。 | Agentic RL,与环境交互学习。 |
未来的关键趋势:
-
从语言模型到世界模型:让AI通过视频、传感器理解物理规律,而不仅仅是文字的概率分布。
-
从通用到高度专业化:医疗、法律、金融等领域的百亿参数级"专才模型"性价比可能高于万亿参数"通才"。
-
从云端到端侧:手机、汽车本地运行的高效模型,保证隐私和低延迟。
第六部分:Mermaid 总结框图
结语
大语言模型的发展史,本质上是一段从"模仿语言表面形式"到"捕捉语言背后的思维与知识"的探索史。
对于开发者而言,理解LLM不能停留在"它很会聊天"的表象,而要看清三条技术路线的取舍、三个训练阶段的必要、以及Scaling Law背后的工程哲学。当Transformer把一切模态都统一为Token序列的那一刻,语言模型就不再只是"语言"的模型——它正在成为一切智能任务的通用接口。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)