人工智能篇---视觉大模型
第一部分:历史的转折——为什么需要"视觉大模型"?
1. 传统计算机视觉的"天花板"
过去十年,我们熟悉的计算机视觉(CV)模型是专才:
-
ResNet 负责"这是猫还是狗"(图像分类)
-
YOLO 负责"猫在哪里"(目标检测)
-
U-Net 负责"把猫的轮廓描出来"(语义分割)
这套范式有三个致命的局限:
-
闭集假设:训练时见过1000类物体,上线后遇到第1001类就直接"瞎了"。
-
有眼无珠:能检测出图片里有"人"和"斑马线",但不理解"这个人正在闯红灯"这一行为语义。
-
模态孤岛:视觉模型不懂文字,语言模型不懂像素。
2. 大模型时代的降维打击
2021年,OpenAI 的 CLIP 模型横空出世,完成了一次认知上的"核聚变":
它收集了4亿对(图片,文字描述)数据,通过对比学习,把语义空间和像素空间强行焊在了一起。
-
效果:不用任何微调,直接就能识别出训练集里没出现过的东西(零样本学习)。你说"找一个穿红色羽绒服正在滑雪的人",它就能在图片库里搜出来。
由此,视觉大模型(Vision Foundation Model) 正式登上历史舞台。它的定义是:在海量图文数据上预训练,具备强大泛化能力和跨模态理解能力的通用视觉基座。
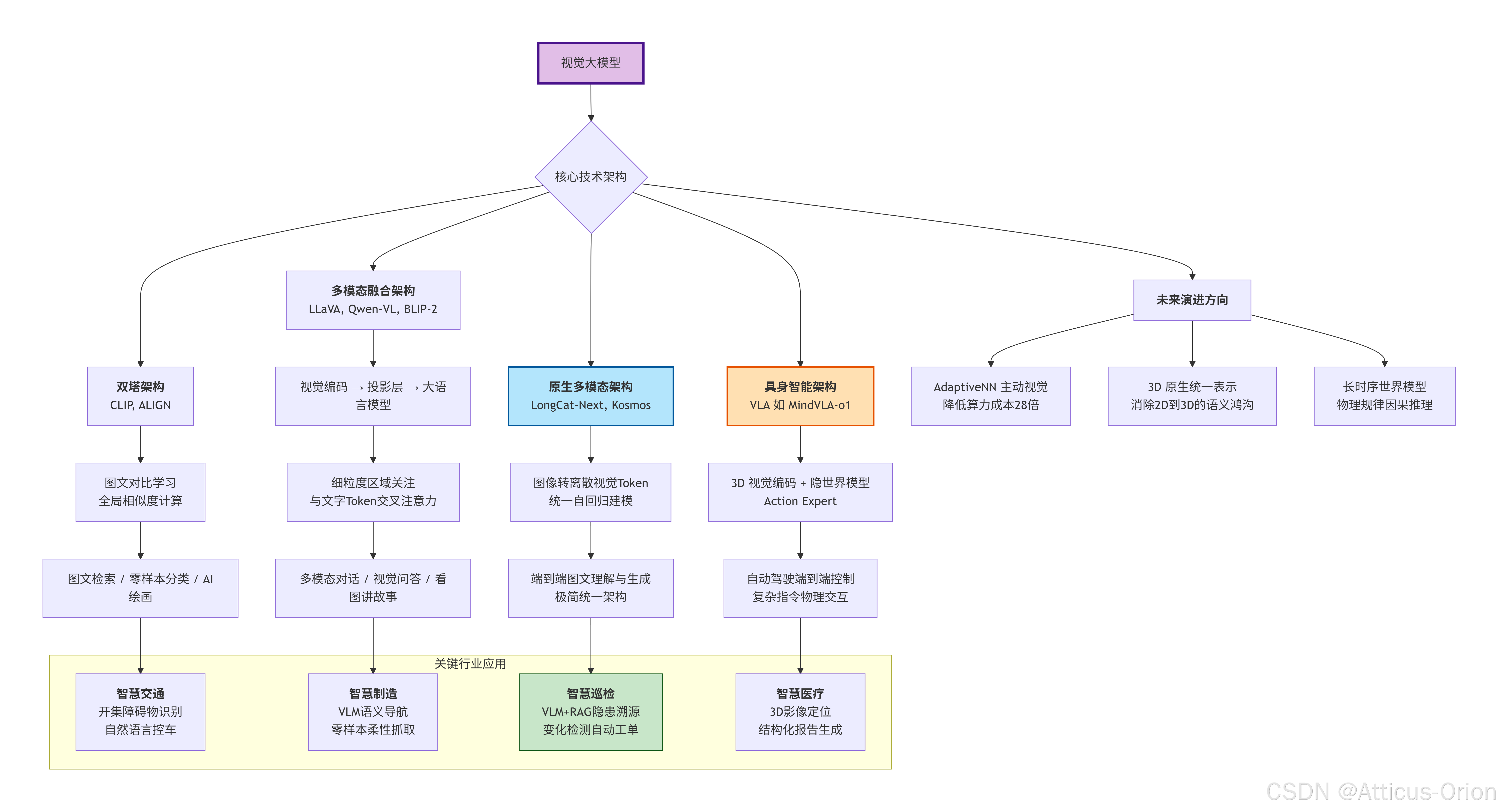
第二部分:核心技术架构——模型是如何"看懂"世界的?
视觉大模型的发展脉络清晰,经历了从"拼接"到"原生融合"的演进。
架构1:双塔/双流架构 —— "有中间商赚差价"的时代
-
代表模型:CLIP
-
工作原理:
-
视觉塔:用 ViT 或 ResNet 把图片压扁成一个特征向量。
-
文本塔:用 BERT 把文字压扁成另一个特征向量。
-
训练目标:让匹配的图文向量越近越好,不匹配的越远越好。
-
-
应用场景:图文检索、零样本分类、AI绘画提示词反向理解。
-
硬伤:它只能判断整体相似度,无法细粒度交互。它知道这张图是"狗在追球",但没法回答"球是什么颜色的"这种细节问题。
架构2:多模态融合架构 —— 视觉与语言的"深度对话"
-
代表模型:LLaVA、Qwen-VL、BLIP-2
-
工作原理:
-
视觉编码器提取特征。
-
通过一个投影层(Projection Layer) 把视觉特征"翻译"成大语言模型能看懂的Token。
-
把图像Token和文字Token拼在一起,一股脑喂给大语言模型(LLM)。
-
-
关键飞跃:LLM 强大的注意力机制会在图像区域和文字Token之间交叉计算。当你问"最左边的人穿什么鞋子",LLM 会驱动视觉特征去关注图片的左下角区域。
-
应用场景:多模态对话、详细图片描述、视觉问答。
架构3:原生多模态架构 —— 打破模态的边界
-
代表模型:LongCat-Next(美团2026开源)、Kosmos
-
工作原理:这是2025-2026年的最新趋势。它不再区分"视觉Token"和"文字Token",而是像处理语言一样,直接把图片压缩成离散的视觉词汇。
-
核心价值:
-
统一表示:同一个Transformer处理所有模态,同一个损失函数训练所有任务。
-
看图作画一体化:模型既理解了内容,又能直接生成新的图像Token,不再需要外挂扩散模型。
-
终极目标:让AI像人类一样,视觉、听觉、语言在同一个大脑皮层处理。
-
架构4:VLA —— 从"感知"到"行动"的闭环
-
代表模型:理想MindVLA-o1、RT-2
-
原理:在理解图片和文字的基础上,直接输出动作指令。
-
关键技术突破:
-
3D 视觉编码器:不再只看2D像素,而是通过多视角融合(如自动驾驶环视摄像头、LiDAR)重建3D几何空间,理解物体的占据栅格和深度。
-
隐空间世界模型:模型内部会推演"如果我打方向,下一秒旁边的车会怎么动",具备物理直觉。
-
Action Expert:直接生成方向盘转角、油门开度等控制序列。
-
第三部分:落地应用——视觉大模型正在改变哪些行业?
1. 自动驾驶:从"感知"到"具身智能"
-
传统方案痛点:白名单物体检测(只认识标注过的车、人),遇到倒地的树、散落的纸箱直接懵了。
-
VLA 大模型方案:
-
开集识别:哪怕没见过"散落的建筑垃圾",通过语言对齐也能知道这是不可通行的障碍物。
-
语言指令交互:你说"前面路口右转,走最堵的那条车道,看看热闹",它能听懂并执行复杂的、带主观判断的指令。
-
因果推理:看到路边有球滚出,会预测后面可能有小孩冲出来(人类驾驶员的防御性预判)。
-
2. 智慧制造与机器人:从"固定轨迹"到"人机协作"
-
应用:基于 VLM 的移动机器人导航。
-
突破:
-
自然语言导航:工人说"去把A3货架第三层的红色物料箱搬过来,小心别碰到旁边的玻璃",机器人结合 3D 场景重建和语义分割,直接理解并规划路径。
-
零样本抓取:不需要针对每一种新零件训练模型,只需给一张参考图或一句描述,机械臂就能识别并抓取。
-
3. 安防与工业巡检:从"报警"到"溯源"
-
应用:铁路低空智能巡检系统(灵眸晓晓2.0)。
-
技术实现:
-
VLM + RAG(检索增强生成):无人机拍到疑似隐患(如彩钢瓦松动)→ VLM 识别物体并理解状态("松动")→ 自动检索专业知识库(铁路安全规范)→ 生成处置工单:"根据XX条例第X条,此处彩钢瓦未加固,存在侵限风险,建议立即绑扎。"
-
变化检测:结合 SAM(分割一切模型)和特征匹配,排除光照、阴影、积雪干扰,精准发现不同时期的细微变化。
-
4. 医疗影像:从"阅片"到"自动生成报告"
-
突破:模型能从 3D CT/MRI 数据中,自动定位病灶(如肺结节),测量大小,并直接生成符合医学规范的结构化诊断报告草稿。
第四部分:当前的局限与未来挑战
尽管视觉大模型很强,但根据 AAAI 2026 的最新综述,我们仍面临关键瓶颈:
| 挑战维度 | 具体问题 | 未来趋势 |
|---|---|---|
| 效率 | 处理一张千万像素图,ViT复杂度是平方级。 | AdaptiveNN(自适应推理):像人眼一样只盯着关键区域看,计算量可降28倍。 |
| 幻觉 | 看图说话时,会编造图中不存在的东西。 | 更强的跨模态对齐约束。 |
| 3D 理解 | 从2D图片推测3D结构的能力仍弱于人类。 | 3D 原生视觉编码器(如3DGS结合ViT)。 |
| 评测 | 传统准确率无法衡量"理解深度"。 | 引入世界模型基准(测物理推理)。 |
第五部分:Mermaid 总结框图
这张图梳理了视觉大模型从基础架构到行业应用的全景脉络。
结语
视觉大模型的发展路径,正是一条从"能看见"到"能理解",再到"能行动" 的进化之路。对于开发者而言,与其追逐每一个新出的 SOTA 模型名称,不如深刻理解底层范式的转变:当视觉信号被统一离散化为Token的那一刻,图像就不再是像素矩阵,而是AI可以阅读、推理和书写的另一种"语言" 。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)