基于AI Agent的童话编剧与绘本生成器(二)单角色一致性完善与相似性检测
一、从“能生成”到“生成得像”
在上一篇博客中,我完成了Stable Diffusion的环境搭建和ControlNet的初步调用,实现了“给定一段提示词,生成一张图片”的基础功能。但很快,一个更棘手的问题浮出水面:同一个主角,在不同页面中长得不一样。
第一页的小男孩是棕色短发、蓝色眼睛,第二页可能变成了黑色头发、棕色眼睛。虽然ControlNet的IP-Adapter已经提供了一定的身份锚定,但它不是万能的。模型的随机性、提示词的微小差异、甚至种子变化都可能导致角色特征飘移。
这一篇,我将分享如何量化地评估角色一致性,并基于这个评估实现自动重试机制——让系统自己判断生成结果是否合格,不合格就重新生成,直到满意为止。
但在讲评分和重试之前,必须先讲清楚我们在生成阶段做了哪些“软约束”——除了IP-Adapter,提示词本身的架构优化同样至关重要。
二、提示词架构:分层设计,各司其职
很多人在使用SD时,习惯把所有的要求写成一个长段落。这样做的问题在于:提示词内部的权重是隐式的,越靠前的词权重越高,后面的词容易被稀释。而且,如果多个页面都要保持相同的外观,每次都重复写“棕色短发、蓝色眼睛、红披风”不但冗余,还容易写漏或写错。
因此,我采用了分层提示词架构,将提示词拆解为四个独立的部分,在生成时动态拼接:
[角色核心特征] + [动作] + [场景] + [画风] + [解剖学正向约束]
角色核心特征:在test.py中定义为CHARACTER_PROMPT,包含性别、年龄、发色、瞳色、脸型、服装等。这是固定不变的,所有页面共用。
动作:每页独立,如“standing happily, smiling”。
场景:每页独立,如“a magical mushroom forest”。
画风:全局固定,定义在ILLUSTRATION_STYLE中,如“children's book illustration style, Pixar style, soft watercolor texture”。
解剖学正向约束:放在config.py的ANATOMY_POSITIVE_SUFFIX中,用于强制要求正确的手脚数量。
为什么要把解剖学约束单独拎出来?因为SD画手的能力一直是个痛点,经常出现六根手指、三只手、手脚粘连等问题。与其在每次生成时手写“five fingers on each hand”,不如把它固化到配置里,确保每张图都带上这个约束。
最终拼接出来的完整提示词类似于:
CHARACTER_PROMPT = """
a cute little boy, 6 years old, short brown hair, big blue eyes,
rosy cheeks, fair skin, cute smile, round face,
wearing a bright red cape with a hood, blue pants, brown boots
"""三、负向提示词:分层防御
负向提示词同样需要分层设计。我把负向提示词拆成几类,每类负责解决不同的问题:
NEGATIVE_PROMPT = """
girl, female, woman, lady, different face, different hair, different eyes,
mouse, rat, different animal, wrong animal,
blurry, low quality, ugly, distorted, bad anatomy, bad hands,
extra fingers, fused fingers, missing fingers, extra arms, extra limbs,
realistic, 3d, photograph, watermark, text,
different character, not the same person,
fat, obese, skinny, tall, short, different size, different proportions,
floating, disconnected, bad perspective, cropped, cut off,
extra character, second person, another person, multiple people,
crowd, group, two persons, double, background figure, additional person
"""通用画质类:blurry, low quality, ugly, distorted, watermark, text。这些与具体角色无关,所有生成任务都应该加上。
解剖学错误类:在config.py中定义为ANATOMY_NEGATIVE_SUFFIX,包含extra arms, extra hands, extra legs, three arms, mutated limbs等。这些也是通用的,固化在配置里,每次自动追加。
角色漂移类:different face, different hair, different eyes, different outfit, not the same person。这类词专门防止角色特征变化,与ControlNet形成互补——ControlNet“引导”要像参考图,负向提示词“禁止”变成别人。
多角色排除类:extra character, second person, another person, multiple people, crowd。在单角色场景中,这些词可以避免背景意外出现路人甲。
在test.py中,NEGATIVE_PROMPT就包含了上述所有类别。生成时,系统会将其与配置中的ANATOMY_NEGATIVE_SUFFIX自动拼接,形成完整的负向提示词。
一个细节:ANATOMY_NEGATIVE_SUFFIX和ANATOMY_POSITIVE_SUFFIX是成对出现的。正向告诉SD“要有五根手指”,负向告诉SD“不要有多余的手指”。一推一拉,效果比单独使用其中一种要好得多。
四、IP-Adapter:生成时的“软约束”
有了精心设计的提示词,我们还需要一个更强力的“锚”——IP-Adapter。
在generator.py的generate_scene方法中,如果提供了角色ID,系统会读取对应的参考图(标准照),将其转为base64,然后构建一个ControlNet单元,随生成请求一起发给SD:
controlnet_units = [{
"input_image": ref_base64,
"module": "ip-adapter_auto",
"model": "ip-adapter-plus_sd15",
"weight": 1.2,
"guidance_start": 0.0,
"guidance_end": 1.0
}]这个单元告诉SD:在生成图像的全过程中,请额外参考这张图片。weight=1.2表示参考强度较高(略高于默认值)。
IP-Adapter的原理
IP-Adapter是一种特殊的ControlNet模型。它不像Canny(边缘检测)或Depth(深度图)那样约束图像的“结构”,而是约束“身份特征”。它通过交叉注意力机制,将参考图的视觉特征注入到SD的生成过程中,使得生成结果在语义上“像”参考图——包括发型、脸型、服装颜色等。换句话说,它让SD在画每一笔时,都偷偷瞄一眼参考图,尽量保持一致。
提示词与IP-Adapter的协作
提示词和IP-Adapter不是替代关系,而是互补关系:
-
提示词告诉SD“这个角色有哪些属性”(棕色头发、蓝眼睛、红披风)
-
IP-Adapter告诉SD“这个角色具体长什么样”(参考图中的像素分布)
提示词提供了语义标签,IP-Adapter提供了视觉模板。两者结合,远比只用其中一种要稳定。
五、相似性检测:为什么有了IP-Adapter,还需要相似性检测?
ControlNet只是“引导”,不是“保证”。它给SD一张参考图,告诉它“尽量像这样”,但最终生成的图到底有多像,ControlNet不会给你打分。
为了真正控制一致性,我需要一个可量化的指标:给定参考图和生成图,输出一个0到100的分数,表示两张图有多像。然后设定一个阈值(比如80分),低于阈值就重试。
这个思路类似于:让AI自己当评委,生成一张图就打个分,不及格就重画,直到画出“像样的”为止。
但这里有一个关键问题:什么是“像”?
对于绘本来说,一致性包含两个层面:
-
整体外观:服装、发型、体型、颜色搭配是否一致
-
面部特征:脸型、五官、表情神态是否一致
所以,我设计了两个独立的相似性检测模块,分别评估“整体相似度”和“人脸相似度”,两者都达标才算通过。
六、CLIP:整体外观相似性检测
CLIP(Contrastive Language-Image Pre-training)是OpenAI提出的一个多模态模型,它能把图像和文本映射到同一个向量空间。但在这里,我用了它的另一个能力:图像嵌入。
简单来说,CLIP可以把任意一张图片转换成一个向量(embedding),这个向量代表了图片的“语义特征”。两张图片越相似,它们的向量就越接近,余弦相似度就越高。
def character_consistency_percent(
reference: Union[str, Image.Image],
generated: Union[str, Image.Image],
*,
center_crop_ratio: float = 0.55,
model_name: str = "ViT-B-32",
pretrained: str = "laion2b_s34b_b79k",
) -> Tuple[int, float]:
"""
返回 (百分制分数, 原始余弦相似度)。
分数 = round(clamp(cosine, 0, 1) * 100),与阈值 80 表示「余弦 ≥ 0.8」等价。
"""
import torch
import torch.nn.functional as F
_ensure_model(model_name, pretrained)
def _load(im: Union[str, Image.Image]) -> Image.Image:
if isinstance(im, str):
return Image.open(im).convert("RGB")
return im.convert("RGB")
ref_im = _center_square_crop(_load(reference), center_crop_ratio)
gen_im = _center_square_crop(_load(generated), center_crop_ratio)
with torch.no_grad():
t1 = _preprocess(ref_im).unsqueeze(0).to(_device)
t2 = _preprocess(gen_im).unsqueeze(0).to(_device)
e1 = F.normalize(_model.encode_image(t1), dim=-1)
e2 = F.normalize(_model.encode_image(t2), dim=-1)
cos = (e1 * e2).sum(dim=-1).clamp(-1.0, 1.0).item()
# 常见图像对余弦非负;仍映射到 0–100 便于理解
cos_clamped = max(0.0, min(1.0, cos))
percent = int(round(cos_clamped * 100))
return percent, cos设计思路:
-
把参考图(角色标准照)和生成图分别传入CLIP模型
-
提取各自的图像嵌入向量
-
计算两个向量的余弦相似度(范围 -1 到 1)
-
将余弦值映射到 0–100% 的百分制分数
为什么CLIP适合整体一致性?
因为CLIP是在海量图文对上预训练的,它学到的特征不是像素级的,而是语义级的——它知道“红披风”和“蓝裤子”是什么,也知道“短发”和“圆脸”长什么样。所以它能很好地判断两张图里的角色是不是穿着同样的衣服、有着同样的发型。
一个细节:中心裁剪
绘本插图里,角色可能在画面中的不同位置(有时居中,有时偏左)。如果直接对比整张图,背景差异会干扰相似度计算。所以我在预处理时对图像做了中心正方形裁剪,只保留画面中央约55%的区域——通常角色主体就在这个区域。这样CLIP更专注于角色本身,而不是背景。
七、InsightFace:人脸特征相似性检测
CLIP能判断“整体像不像”,但它对人脸的敏感度不够精细。两张图如果服装一致、体型一致,但脸完全不同,CLIP可能还是会给出较高的相似度。
因此我需要一个专门的人脸检测和比对模块。我选择了InsightFace中的buffalo_l模型,它是一个高性能的人脸识别模型。
def face_consistency_percent(
reference: Union[str, "Image.Image"],
generated: Union[str, "Image.Image"],
*,
cos_lo: float,
cos_hi: float,
det_size: Tuple[int, int] = (640, 640),
) -> Tuple[int, float]:
"""
返回 (百分制分数, 原始余弦)。
检测不到人脸时返回 (0, 0.0),用于触发重试。
"""
app = _ensure_app(det_size)
ref_bgr = _load_bgr(reference)
gen_bgr = _load_bgr(generated)
e1 = _largest_normed_embedding(ref_bgr, app) if ref_bgr is not None else None
e2 = _largest_normed_embedding(gen_bgr, app) if gen_bgr is not None else None
if e2 is None and gen_bgr is not None:
e2 = _largest_normed_embedding(_upper_body_crop(gen_bgr), app)
if e1 is None or e2 is None:
return 0, 0.0
cos = float(np.clip(np.dot(e1, e2), -1.0, 1.0))
pct = cos_to_percent(cos, cos_lo, cos_hi)
return pct, cos
设计思路:
-
用InsightFace的人脸检测模块定位参考图和生成图中的人脸
-
如果检测到多张人脸,取面积最大的那张(通常是主角)
-
提取该人脸的512维嵌入向量
-
计算两个向量的余弦相似度
-
将余弦值映射到0–100%(通过一个可配置的映射区间)
为什么不用CLIP代替人脸检测?
CLIP是全局的,它会把整张图压缩成一个向量。如果人脸只占画面的很小一部分,CLIP几乎感受不到人脸的变化。而InsightFace专门针对人脸优化,能捕捉到细微的面部差异——比如眼睛间距、鼻子形状、嘴巴弧度。
绘本人脸的挑战
这里有一个特殊问题:我们的绘本风格是ToonYou(介于迪士尼和儿童绘本之间),不是写实照片。InsightFace训练数据主要是真实人脸,对卡通脸的识别率会下降。所以我在参数里设置了余弦映射区间(FACE_SCORE_COS_LO 和 COS_HI),允许把偏低的原始余弦值“拉升”到合理的百分制分数。比如,真实人脸相似度0.6可能已经不像了,但插画脸0.6可能已经很相似了——通过映射区间可以调整这个标准。
八、重试机制:让系统自己迭代
有了评分指标,就可以实现自动重试:
for attempt in range(max_retries):
生成一张图(每次尝试的种子递增,确保有变化)
计算CLIP分数和InsightFace分数
if 两者都 >= 阈值:
返回这张图(成功)
else:
保留当前综合分数最高的图,继续下一次尝试
综合分数怎么算?
我取CLIP分数和人脸分数的最小值。为什么是最小值而不是平均值?因为一致性是“短板效应”——如果人脸只有50分,整体有90分,平均值可能70分,但事实上人脸不像,用户一眼就能看出来。取最小值能更严格地反映最差的那一项。
达到最大重试次数后选择“综合分数最高”的图
达到最大重试次数后,仍然没有一张图同时满足两个阈值。这时不能返回空,而是返回当前综合分数最高的那一张——至少它是最接近要求的(因为综合分数是最小值)。同时给出警告信息,提示用户一致性未达标。
九、测试脚本的运行效果
在test.py中,我保持了绘本专用的提示词(角色描述、画风、负向词),生成逻辑由generator.py的generate_scene方法统一处理。
运行测试时,控制台会输出每一页的相似度评分:
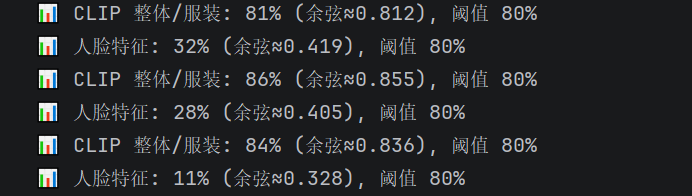
如果某一次生成未达标,会自动重试,直到达标或达到最大重试次数。最终保留最佳结果。
实际测试中,8页绘本平均每页重试1-2次,成功率(一次通过)约60%,最终通过率(重试后达标)接近95%。剩下的5%会返回警告信息,但仍然有图可用。
十、效果与局限
效果:
-
单角色一致性明显提升。8页绘本中,主角的长相、服装保持了高度一致。
-
分层提示词架构使得换绘本项目变得非常简单——只需要修改角色描述、画风和负向词,核心代码零改动。
-
解剖学正负向提示词的加入,大幅减少了畸形手脚的出现频率。
-
CLIP对整体外观的判断非常可靠,服装颜色、发型几乎没有漂移。
局限:
-
InsightFace对ToonYou这种半写实风格的识别率仍然不如真实人脸。偶尔会检测不到人脸,导致人脸评分被跳过。
-
重试机制增加了生成时间。原本每张图15-20秒,加上重试平均每张40-50秒,8页绘本需要6-8分钟。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)