WSL本地部署Ollama大模型并接入OpenCode教程 - 从零开始的AI之旅
一、环境准备
在开始之前,请确保你已经:
- 安装了Windows Subsystem for Linux (WSL)
- WSL可以正常运行
- 拥有sudo权限
二、安装Ollama
执行安装命令
打开WSL终端,执行以下命令:
curl -fsSL https://ollama.com/install.sh | sh
处理依赖问题
安装过程中可能会遇到如下问题:
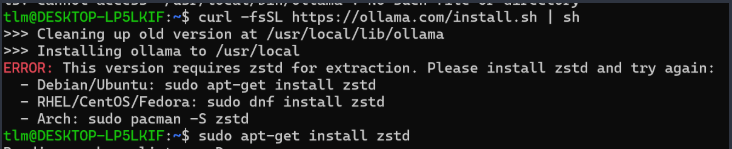
根据提示安装依赖:
sudo apt-get install zstd
安装完成后,再次执行安装命令:
curl -fsSL https://ollama.com/install.sh | sh
提示:如果安装过程中遇到其他依赖问题,按照错误提示安装对应依赖即可。
三、 Gemma4模型介绍
1.什么是Gemma4?
Gemma4 是Google开发的第四代轻量级开源大语言模型,它是Gemma系列的最新版本。Gemma4在保持轻量级的同时,性能得到了显著提升,特别适合本地部署使用。
2.Gemma4 硬件需求参考
根据你的硬件配置,选择合适的 Gemma4 版本:
| 版本 | 最低显存 | 推荐显存 | Apple Silicon 参考 |
|---|---|---|---|
| E4B | ~4GB | 6-8GB | M1/M2 16GB+ 统一内存 |
| 26B A4B | ~18GB | 24GB | M3 Max 64GB 或更高 |
| 31B | ~20GB | 24-32GB | 需要专业级 Mac 或外接 GPU |
💡 推荐选择:gemma4:e4b 版本,适合大多数个人电脑配置,性能和资源占用达到最佳平衡。
3.下载并运行模型
下载Gemma4模型
安装成功后,下载Gemma4模型:
ollama pull gemma4:e4b
⚠️ 注意:模型文件较大(约4.7GB),下载过程中请保持网络稳定。
4.验证模型安装
查看已安装的模型列表:
ollama list
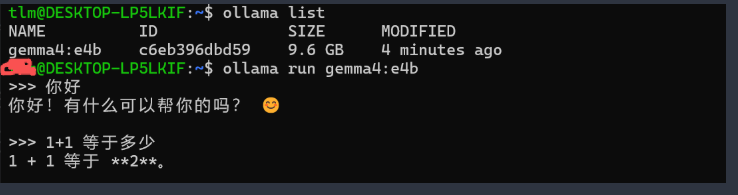
5.启动对话
直接运行模型,开始交互式对话:
ollama run gemma4:e4b
现在你就可以直接在命令行中与AI对话了!如下图:
6.API服务启动
Ollama安装后,会自动在 localhost:11434 提供OpenAI兼容接口,方便第三方工具调用。
四、接入OpenCode
配置文件位置
打开OpenCode配置文件:
~/.config/opencode/opencode.json
添加本地模型配置
在 provider 节点下,新增以下配置:
"gemma": {
"npm": "@ai-sdk/openai-compatible",
"name": "gemma",
"options": {
"baseURL": "https://localhost:11434/v1",
"apiKey": ""
},
"models": {
"gemma4:e4b": {
"name": "gemma4:e4b",
"limit": {
"context": 128000,
"output": 4096
},
"modalities": {
"input": [
"text",
"image"
],
"output": [
"text"
]
}
}
}
}
⚠️ 重点提示:
baseURL使用https://localhost:11434/v1(注意末尾的/v1)- 模型名称
gemma4:e4b必须与ollama中安装的模型名称完全一致 apiKey可以留空
在OpenCode中使用
- 保存配置文件
- 在OpenCode中执行
/models命令 - 选择
gemma4:e4b模型 - 可以开始使用完全免费的模型做代码开发啦。
四、常见问题
Q1:安装命令执行失败怎么办?
检查网络连接,确保可以访问GitHub。如果网络受限,可能需要配置代理。
Q2:模型下载很慢或中断?
- 检查网络稳定性
- 可以尝试重新执行
ollama pull命令,支持断点续传 - 考虑使用镜像源或代理加速
Q3:OpenCode中无法连接到模型?
- 确认
baseURL配置正确(包含/v1) - 检查WSL中的Ollama服务是否正常运行
- 确认模型名称是否匹配
- 检查防火墙设置
Q4:内存不足怎么办?
Gemma4:e4b模型要求约16GB内存。如果内存不足,可以尝试:
- 使用更小的模型(如
gemma2:2b) - 增加系统swap空间
- 关闭其他占用内存的程序
🎉 总结
通过本教程,你已经成功:
- 在WSL中安装了Ollama
- 部署了本地大模型Gemma4
- 接入到OpenCode工具中
- 拥有了属于自己的AI助手
现在你可以:
- 在命令行中直接使用AI
- 在OpenCode中进行AI辅助编程
- 享受完全免费的本地AI服务(无需联网、无需付费)
🔗 相关资源
👍 觉得有用就点个赞吧!有疑问欢迎在评论区留言~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)