【ICLR 2026 高分论文】预测之后的预测:时间序列的自适应后处理方法
一段话总结
本文为ICLR 2026会议论文,提出δ-Adapter——轻量级、架构无关的时间序列预测后处理框架,在不重训、不修改冻结骨干模型的前提下,通过输入微调(Input Nudging)与输出残差校正(Output Residual Correction)双接口实现预测精度提升,同时具备稀疏特征选择与分位数/共形不确定性校准能力,无标签泄漏、计算开销极低(仅增2%-6%参数),在7类数据集、多款SOTA预测模型上均实现显著精度增益(MSE最高降低96%)。
论文:The Forecast After the Forecast: A Post-Processing Shift in Time Series
作者:Daojun Liang, Qi Li, Yinglong Wang, Jing Chen, Hu Zhang, Xiaoxiao Cui, Qizheng Wang, Shuo Li
单位:齐鲁工业大学,山东大学,凯斯西储大学
代码:https://github.com/Anoise/Adapter
请各位同学给我点赞,激励我创作更好、更多、更优质的内容!^_^
更多资讯,关注微信公众号:时序前沿研究
添加小助手微信Aniose,加入时序交流群 。
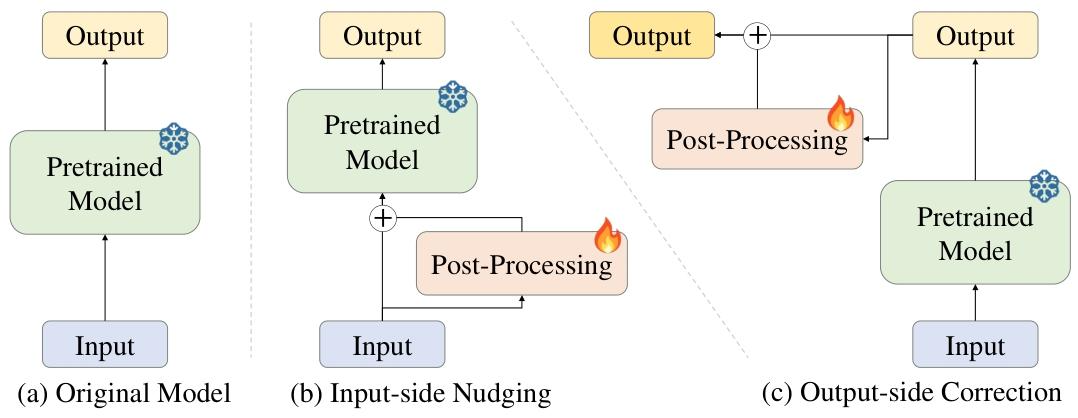
图1:δ-Adapter在冻结的预测器上执行输入微调与输出校正。
详细总结
一、研究背景
时间序列预测(TSF)领域长期聚焦模型架构优化,已进入精度收益递减阶段;实际部署面临概念漂移、性能方差高、训练/推理低效三大痛点,传统微调、架构修改等方案成本高、易破坏系统稳定性,且现有测试时适配方法存在标签泄漏问题。
二、核心方法:δ-Adapter
δ-Adapter是冻结骨干模型F的轻量适配模块,仅在输入/输出双接口做有界修正,核心设计:
- 输入侧微调(Input Nudging)
加性: X ~ = X + δ A θ i n ( X ) \tilde{X}=X+\delta A_{\theta}^{in}(X) X~=X+δAθin(X);乘性: X ~ = X ⊙ ( 1 + δ A θ i n ( X ) ) \tilde{X}=X \odot(1+\delta A_{\theta}^{in}(X)) X~=X⊙(1+δAθin(X)),通过小参数 δ ∈ ( 0 , 1 ) \delta∈(0,1) δ∈(0,1)约束修正幅度。 - 输出侧残差校正(Output Residual Correction)
加性: Y ~ = F ( X ) + δ A θ o u t ( F ( X ) , X ) \tilde{Y}=F(X)+\delta A_{\theta}^{out}(F(X),X) Y~=F(X)+δAθout(F(X),X);乘性: Y ~ = F ( X ) ⊙ ( 1 + δ A θ o u t ( F ( X ) , X ) ) \tilde{Y}=F(X) \odot(1+\delta A_{\theta}^{out}(F(X),X)) Y~=F(X)⊙(1+δAθout(F(X),X)),学习低复杂度残差模式。 - 组合适配:输入+输出联合训练,保持 O ( δ ) O(\delta) O(δ)漂移边界。
三、理论保障
- 小步优化保证:校正与残差对齐时,小 δ \delta δ可严格降低预测损失。
- 预测稳定性:冻结模型为Lipschitz时,预测漂移为** O ( δ ) O(\delta) O(δ)**。
- 损失稳定性:β-平滑损失下,输入/输出适配器均有局部下降保证。
- 组合稳定性:双适配器联合修正仍保持稳定损失边界。
四、实现细节
- δ-Adapter主体
采用浅层MLP,通过tanh约束模块输出范围, δ \delta δ直接控制最大修正幅度,参数增量**<2%-6%**(相对128M Sundial、48M TabPFN)。
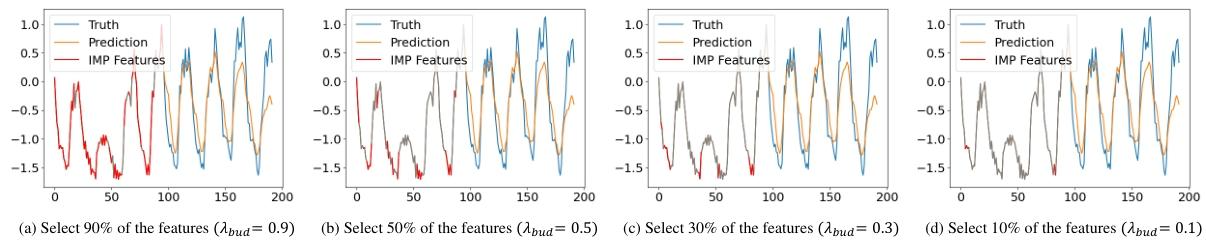
图4:掩码适配器学习到的不同重要特征的可视化
- 特征选择适配器
学习稀疏、近二值、时域感知掩码,用Gumbel-Sigmoid松弛实现可微训练,结合稀疏性、时域平滑、预算正则,自动筛选关键输入特征。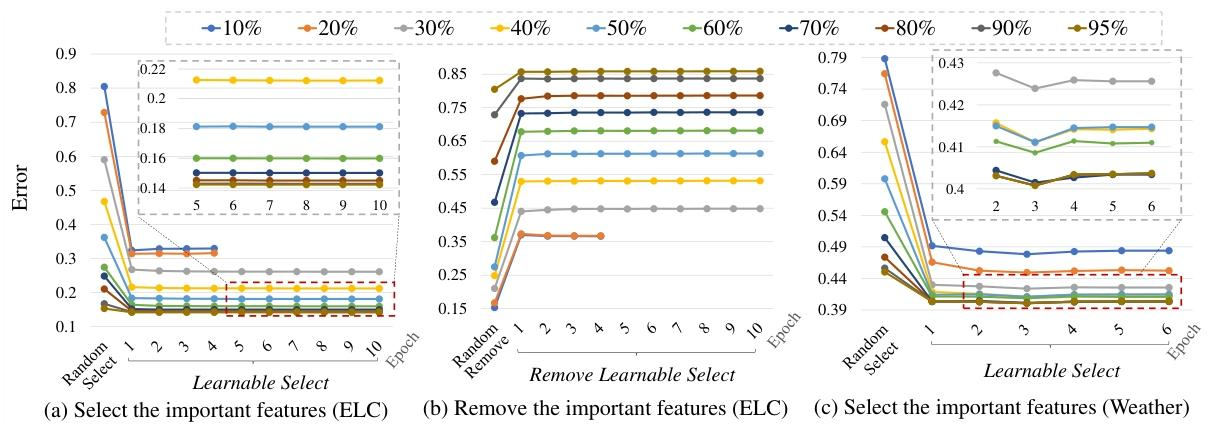
图3:选择或剔除有效特征后预测器的性能变化
- 分布校准器
- 分位数校准器(QC):学习分位数偏移,用pinball损失训练,输出平滑分位数区间。
- 共形校准器(CC):学习异方差尺度函数,结合归一化残差共形预测,提供有限样本覆盖保证。

图6:分位数校准器与共形校准器预测结果的可视化。
五、实验结果
- 核心实验设置
数据集:ETTh1/ETTh2/ETTm1/ETTm2/ELC/Exchange/Traffic/Weather共7类;
骨干模型:Sundial-S、TTM-R2、iTransformer、Autoformer、TabPFN、TimesFM等;
超参: δ \delta δ取0.1(强概念漂移数据集)/0.01(ETT数据集),学习率1e-4。 - 精度提升效果
| 数据集 | Sundial-S(MSE最大降幅) | TTM-R2(MSE最大降幅) |
|---|---|---|
| Weather | 96% | 2% |
| ETTm2 | 32% | 4% |
| ELC | 17% | 6% |
- 效率表现
训练/推理速度快于SOLID、TAFAS、OneNet、FSNet,仅需单样本更新,内存占用低。 - 黑盒模型适配
对TabPFN、TimesFM等黑盒模型,仅加输出适配器(Ada-Y)即可显著降误差。 - 消融实验
- δ \delta δ:0.1为最优值,过大修正导致增益下降;
- 结构:组合适配器(Ada-X+Y)效果最优;
- 容量:深度影响小,宽度增加小幅提升性能。
| Model Type Dataset | Sundial-S (Univariate) | TTM-R2 (Multivariate) | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| original | Ada-X | Ada-Y | original | Ada-X | Ada-Y | |||||||||||
| MSE | MAE | MSE | MAE | IMP | MSE | MAE | IMP | MSE | MAE | MSE | MAE | IMP | MSE | MAE | IMP | |
| ELC | 0.427 | 0.463 | 0.334 | 0.410 | 17% | 0.404 | 0.451 | 4% | 0.180 | 0.272 | 0.167 | 0.262 | 6% | 0.168 | 0.262 | 5% |
| Traffic | 0.237 | 0.314 | 0.220 | 0.301 | 6% | 0.224 | 0.302 | 5% | 0.517 | 0.344 | 0.492 | 0.329 | 5% | 0.492 | 0.325 | 5% |
| Exchange | 0.249 | 0.332 | 0.241 | 0.332 | 2% | 0.235 | 0.329 | 3% | 0.094 | 0.213 | 0.090 | 0.206 | 3% | 0.092 | 0.210 | 1% |
| Weather | 0.427 | 0.463 | 0.025 | 0.005 | 96% | 0.039 | 0.059 | 89% | 0.150 | 0.196 | 0.148 | 0.193 | 2% | 0.143 | 0.191 | 4% |
| ETTm1 | 0.121 | 0.217 | 0.078 | 0.190 | 24% | 0.087 | 0.202 | 18% | 0.338 | 0.357 | 0.329 | 0.357 | 1% | 0.331 | 0.353 | 3% |
| ETTm2 | 0.348 | 0.420 | 0.201 | 0.325 | 32% | 0.254 | 0.371 | 19% | 0.177 | 0.259 | 0.174 | 0.243 | 4% | 0.175 | 0.240 | 4% |
六、结论
δ-Adapter以极低计算成本实现冻结时间序列预测模型的精度、可解释性、不确定性校准三重提升,无标签泄漏、部署友好,是时间序列预测最后一公里优化的通用方案。
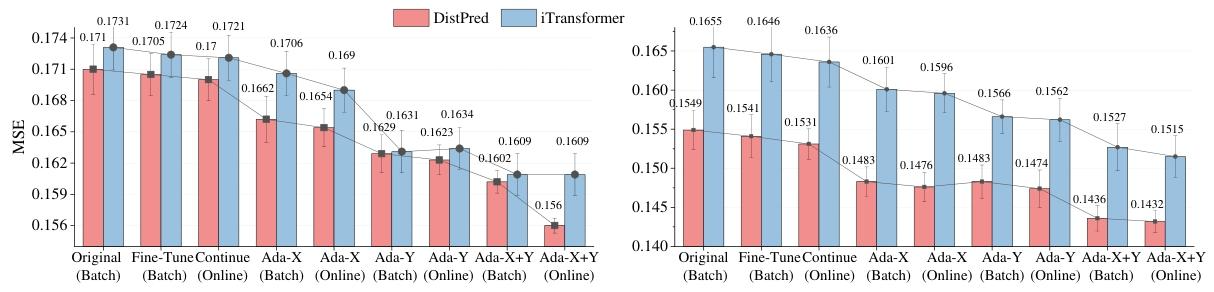
图2:预测器F和δ-Adapter在批量或在线训练下的性能表现
关键问题
-
问题1:δ-Adapter相比传统测试时适配方法的核心优势是什么?
答案:①无标签泄漏:不依赖未来真实标签,避免长期预测性能退化;②轻量低耗:仅增2%-6%参数,训练/推理速度更快;③架构无关:不修改冻结骨干,适配所有预测模型;④理论保障:具备局部下降、漂移边界、组合稳定性保证;⑤多功能:同时实现精度提升、特征选择、不确定性校准。 -
问题2:δ-Adapter的特征选择模块如何实现,实际效果如何?
答案:实现:学习时域感知稀疏掩码,用Gumbel-Sigmoid松弛实现可微训练,结合L1稀疏、时域平滑、预算约束正则,自动筛选关键特征。效果:①筛选特征对预测至关重要,移除后误差大幅上升;②10%-95%保留比例下,学习选择均优于随机选择;③最佳性能时掩码保留率约92%-98%,仅保留核心特征。 -
问题3:δ-Adapter的分位数校准(QC)与共形校准(CC)的区别和适用场景?
答案:①分位数校准器(QC):直接学习多水平分位数偏移,无分布假设,输出平滑分位数曲线,区间更保守、更宽。适用场景:需要完整预测分布、多置信水平的场景。②共形校准器(CC):学习异方差尺度+共形预测,提供有限样本边际覆盖保证,区间更紧凑。适用场景:需要严格覆盖概率保证的实际部署场景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)