【大语言模型】 WizardLM:赋能大型预训练语言模型以遵循复杂指令
【大语言模型】 WizardLM:赋能大型预训练语言模型以遵循复杂指令
目录
文章目录
📌 文章信息
- 论文原始标题: WizardLM: Empowering Large Pre-Trained Language Models to Follow Complex Instructions
- 论文标题翻译: WizardLM:赋能大型预训练语言模型以遵循复杂指令
| 项目 | 内容 |
|---|---|
| arXiv ID | 2304.12244v3 |
| 作者 | Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao 等 (9位作者) |
| 发布日期 | 2023-04-24 |
| 分类 | cs.CL, cs.AI |
| 搜索日期 | 2026-04-12 |
| arXiv 链接 | https://arxiv.org/abs/2304.12244v3 |
📄 摘要信息
训练大型语言模型(LLM)使用开放领域的指令遵循数据取得了巨大的成功。然而,手动创建此类指令数据非常耗时且劳动密集。此外,人类可能难以产生高复杂度的指令。本文展示了一种利用LLM而非人类来创建具有不同复杂度级别的大量指令数据的方法。从一个初始指令集开始,我们使用提出的Evol-Instruct方法,逐步将它们重写为更复杂的指令。然后,我们混合所有生成的指令数据来微调LLaMA模型,最终模型被称为WizardLM。自动化和人工评估均一致表明,WizardLM的性能优于Alpaca(基于Self-Instruct训练)和Vicuna(基于人工创建指令训练)等基线模型。实验结果证明,通过Evol-Instruct创建的指令遵循数据集的质量可以显著提升LLM的性能。
1. 🔍 研究背景
大型语言模型(LLM)如GPT系列和LLaMA,在自然语言处理领域展现了卓越的能力。然而,基础LLM本质上是下一个词元的预测器,其产出形式由训练数据的统计规律决定,而非主动遵循用户的明确指令或意图。为了提升LLM的实用性和对齐性,指令微调(Instruction Tuning)成为一种关键技术。早期的指令微调工作多集中于封闭领域,即通过整合众多有标签的NLP任务(如问答、摘要、情感分类)并配以少量人工编写的指令来训练模型。这种方法虽然能提升模型在“未见”任务上的泛化能力,但其指令形式固定、任务单一,难以覆盖真实世界中用户指令的多样性、开放性和复杂性。
为应对此问题,后续研究转向开放领域指令微调。OpenAI的InstructGPT/ChatGPT通过雇佣大量人工标注员,编写了海量、多样化的真实用户指令,取得了突破性成功。然而,这种纯人工构建数据集的方式面临着成本高昂、效率低下以及高难度指令数据稀缺(人类更倾向于提出简单或中等难度的问题)等核心挑战。因此,如何以较低成本、自动化地生成大量高质量、高多样性的开放域指令数据,特别是高复杂度的指令,成为推动指令微调模型发展的关键。斯坦福大学的Alpaca模型尝试使用“Self-Instruct”方法,让LLM自身生成指令数据,但其生成的指令在复杂度和多样性上仍有不足。
2. ❗问题与挑战
本文旨在解决现有指令微调方法中的三个核心问题与挑战:
-
数据获取的高成本与低效率:纯依赖人类专家创建大规模、高质量的开放域指令数据极其昂贵且耗时。这限制了数据集的规模,也使得快速迭代和扩展变得困难。
-
高复杂度指令的稀缺性:人类标注者在自然状态下倾向于提出难度较低或中等的问题,而高难度、需要多步推理、综合约束的复杂指令占比较低。这种数据分布上的偏差导致模型在处理复杂用户请求时表现不佳,限制了其在高级任务(如复杂代码生成、数学推理)上的能力。
-
现有自动化方法的局限性:Alpaca采用的Self-Instruct方法虽然实现了部分自动化,但其生成的指令在复杂度和多样性上提升有限。该方法主要是通过种子指令引导LLM生成类似难度的新指令,缺乏系统性地增加指令复杂性、拓展指令广度和深度的机制。因此,如何设计一个能可控地、迭代地提升指令复杂度并同时保证其合理性的自动化算法,是本文面临的核心算法挑战。
3. ⚙️ 算法模型
针对上述挑战,本文提出了 Evol-Instruct 算法。该算法并非一个单一的模型,而是一个用于自动生成和演化复杂指令数据的流程框架。其核心思想是模拟生物进化过程,通过一系列“进化操作”迭代地将简单指令升级为更复杂、更多样化的指令。整个流程主要包含三个组件: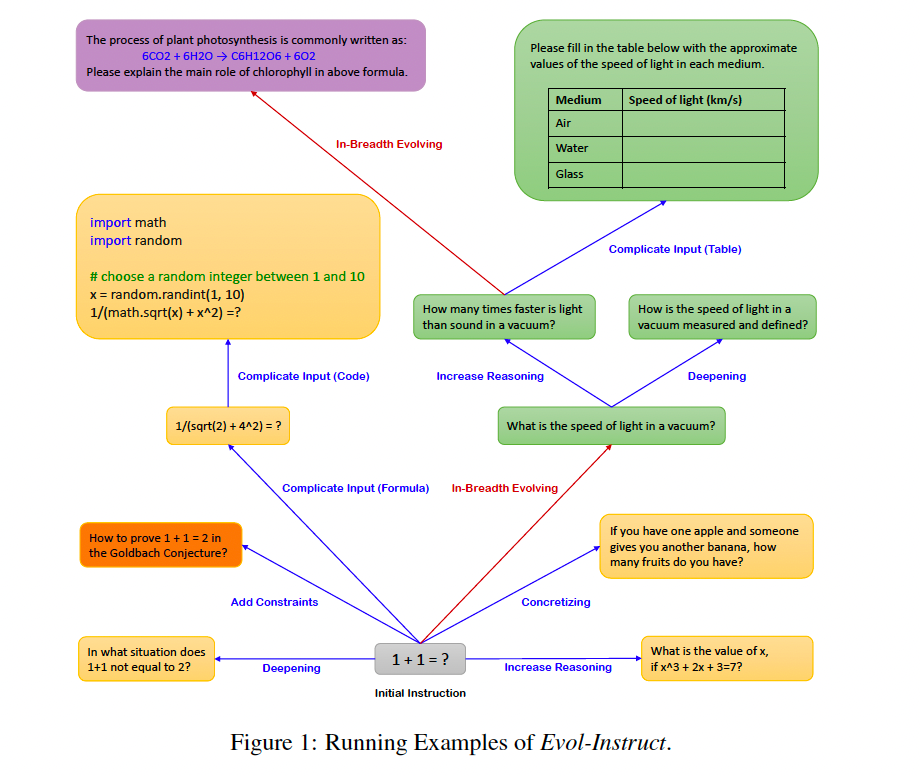
3.1 指令进化器 (Instruction Evolver)
这是算法的核心,通过两种进化模式来操作指令:
-
深度进化 (In-Depth Evolving):旨在增加单条指令的复杂性。它通过随机选择以下五种操作之一来实现:
- 添加约束 (Add Constraints):向原始指令中添加新的限制条件或要求,例如要求输出格式为JSON,或必须包含特定信息。
- 深化 (Deepening):如果指令涉及某个问题,则增加问题的深度和广度,要求模型进行更深入的探究。
- 具体化 (Concretizing):将指令中的通用概念替换为更具体、更细节的概念,使任务更聚焦但也更复杂。
- 增加推理步骤 (Increase Reasoning Steps):要求模型不能直接给出答案,而必须通过多步逻辑推理才能得出结果。
- 复杂化输入 (Complicate Input):向指令中嵌入结构化的复杂输入数据,如XML、SQL数据库片段、Python代码、HTML页面等,要求模型在处理指令前先理解和解析这些数据。
所有这些深度进化操作都通过精心设计的Prompt来驱动一个LLM(如ChatGPT)执行。Prompt的核心要求是“将给定提示重写为更复杂的版本,使其对著名的AI系统(如ChatGPT和GPT-4)更难处理,但重写后的提示必须是合理的,并能被人类理解和回应”。同时,为了控制难度增长过快,还限制了每次增加10-20个单词。
-
广度进化 (In-Breadth Evolving):旨在增加整个数据集的多样性和主题覆盖范围。它通过“突变”操作,要求LLM基于给定的指令,生成一个全新的、属于同一领域但更罕见(long-tailed) 的指令。新指令的长度和难度应与原指令相似,从而在不牺牲合理性的前提下,探索更广阔的指令空间。
3.2 指令消除器 (Instruction Eliminator)
这是一个过滤机制,用于移除进化失败的指令。失败的判定标准包括:
- 进化后的指令相比原指令没有信息增益。
- 进化后的指令导致LLM无法生成合理回应(例如,回应中包含“sorry”且内容很短)。
- LLM生成的回应仅包含标点符号和停用词。
- 进化后的指令明显复制了Prompt中的特定词汇(如“given prompt”)。
3.3 整体流程与模型微调
- 初始化:从一个初始指令数据集开始,例如Alpaca的52k数据集。
- 迭代进化:对当前数据集中的每条指令,随机选择一种进化操作(深度或广度),调用LLM API生成新的指令。然后使用指令消除器进行过滤,成功的指令被加入数据集,失败的则保留原样,等待下一轮进化。这个过程重复多轮(论文中为4轮)。
- 响应生成:对于所有成功进化出的新指令,再次调用LLM生成对应的响应。
- 数据合并与采样:将原始指令与所有轮次进化出的指令合并,形成一个大规模的指令池(论文中为250k)。为了公平比较,从中随机采样与基线模型(Vicuna,70k)等量的数据。
- 模型微调:使用采样后的数据集,以标准的监督学习方式(如预测下一个词元)对基础LLM(如LLaMA 13B)进行微调,最终得到WizardLM模型。
4. 💡 创新点
本文的核心创新点可以总结为:
- 提出Evol-Instruct算法:这是一个新颖的、不依赖人类的、可自动生成大规模开放域指令数据的范式。它通过模拟“进化”过程,系统性地提升了指令的复杂度和多样性,这是对Self-Instruct等现有方法的显著改进。
- 双维度进化策略:巧妙地设计了“深度进化”和“广度进化”两种互补的机制。深度进化专注于在单一指令的“复杂度”维度上进行挖掘,通过五种具体的操作(如添加约束、增加推理步骤)精细控制难度提升。广度进化则专注于在指令的“主题/技能”维度上进行拓展,通过“突变”生成新颖、罕见的指令,极大地丰富了数据集的多样性。
- 构建高质量指令数据集:通过Evol-Instruct生成了一个包含25万条指令的高质量、高复杂度、高多样性的数据集。实验证明,即使只使用其中与Vicuna等量的70k数据进行微调,WizardLM也能在多个基准测试中显著超越对手。
- 验证指令复杂度的关键作用:通过详细的消融实验(如分析不同进化轮次的数据),本文有力地证明了训练数据的复杂度是决定指令微调模型最终性能的关键因素之一。随着数据复杂度提升,模型性能同步提升。
5. 📊 实验效果(重要数据与结论)
实验设置
- 基础模型:LLaMA (13B, 65B, 70B), Mistral-7B。
- 基线模型:ChatGPT (GPT-3.5), Alpaca-13B, Vicuna-13B, Baize, CAMEL, Tulu。
- 初始数据:Alpaca的52k指令数据。
- 进化引擎:Azure OpenAI ChatGPT API (GPT-3.5)。
- 进化轮次:4轮,最终得到250k指令。为公平比较,从中随机采样70k用于训练WizardLM-13B。
- 评估基准:
- 自动评估:OpenLLM Leaderboard (MMLU, ARC, HellaSwag, TruthfulQA), HumanEval (代码), GSM8k (数学), AlpacaEval, MT-Bench。
- 人工评估:自建的WizardEval测试集(包含218个来自真实世界的高难度、多技能指令)。
- 评估者:GPT-4、10名受过良好教育的人类标注员。
重要数据与结论
-
性能全面超越开源基线:从表1可以看出,在13B参数规模下,WizardLM-13B在所有9个评估基准上的平均得分(58.96)远高于Vicuna-13B(54.60)和Alpaca-13B(43.44)。在代码(HumanEval)、数学(GSM8k) 和 GPT-4评估(MT-Bench, AlpacaEval) 等复杂任务上,优势尤为显著。例如,在HumanEval上WizardLM得分24.03,远超Vicuna的12.5;在GSM8k上得分为7.15,而Vicuna仅为4.34。
-
人工评估验证有效性:在人工评估中(图4b),WizardLM在与Alpaca和Vicuna的成对比较中均取得了显著的胜率,表明其生成的回答在相关性、知识性、推理能力、计算准确性和整体准确性上更受人类评估者青睐。
-
复杂度是性能提升的关键:图5b的消融实验清晰地展示了,随着进化轮次(C0到C4)的增加,训练数据的平均复杂度逐步提升,而基于这些数据微调得到的模型在9个基准上的平均性能也随之同步、稳定地提升。这直接证明了Evol-Instruct通过增加数据复杂度带来性能增益的核心逻辑。
-
Evol-Instruct的通用性与可扩展性:
- 不同种子数据:使用ShareGPT作为初始种子数据训练的WizardLM(ShareGPT Seed)在大多数基准上表现更好(表2),说明算法不依赖特定种子,且高质量种子数据能带来更大提升。
- 不同进化引擎:使用开源的LLaMA-2-70B-Chat代替ChatGPT作为进化引擎,训练的模型仍取得显著优于基线的性能(表2),证明了算法对底层LLM不敏感,具有很强的普适性。
- 不同基础模型:在Mistral-7B和LLaMA-65B/70B上应用Evol-Instruct进行微调,均取得了大幅度的性能提升(表2),证明了该方法可以广泛适配各种预训练模型。
- 数据规模:使用全部250k数据训练的WizardLM-13B (250K) 性能优于使用70k采样数据训练的版本,表明更多的进化数据能进一步提升模型容量。
-
优于传统NLP任务数据:与使用1600+ NLP任务构建的Super-NaturalInstructions (SNI) 数据集相比,基于Evol-Instruct数据训练的模型性能全面大幅领先(表2),凸显了开放域、高复杂度指令数据的独特价值。
6. 📈 推荐阅读指数
推荐指数:⭐⭐⭐⭐ (4/5)
推荐理由
- 方法新颖且有效:Evol-Instruct为解决LLM指令微调中的数据瓶颈问题提供了一条非常新颖且高效的路径。它巧妙地借鉴了进化算法的思想,通过提示工程驱动LLM自我博弈,生成高质量数据,这一思路具有很强的启发性和可迁移性。
- 实验扎实,结论可靠:论文实验设计严谨,对比基线全面(包括多个当时SOTA的开源模型),评估维度丰富(自动+人工,涵盖多种复杂任务)。详尽的消融研究(数据种子、进化引擎、模型规模、数据规模、复杂度轮次)有力地支撑了其核心结论,使读者能够深入理解算法各组成部分的作用。
- 实践指导价值高:该方法不仅停留在理论层面,其生成的WizardLM模型性能卓越,代码、模型、数据(部分)已开源,对学术界和工业界的研究者、工程师都具有极高的参考和实用价值。它为如何低成本、高质量地构建指令数据集提供了可复现的范例。
- 开启新研究方向:该工作有力地证明了“指令复杂度”在指令微调中的关键作用,这将激励后续研究更深入地探索如何量化、生成和控制指令的复杂度,以及如何设计更优的课程学习策略。
7. 总结与展望
总结:
本文提出的WizardLM和Evol-Instruct方法是LLM指令微调领域的一项重要突破。它直面了高质量、高复杂度指令数据稀缺这一核心痛点,并创新性地提出了一种利用LLM自身来进化数据的自动化解决方案。通过深度与广度两种进化模式,Evol-Instruct能够可控地生成既复杂又多样的指令数据。充分的实验证据表明,基于此数据训练的WizardLM模型在代码、数学、推理等复杂任务上显著超越了当时最先进的开源模型(如Vicuna、Alpaca),甚至在某些方面缩小了与闭源商业模型(如ChatGPT)的差距。该工作不仅提供了一个强大的模型和数据生成工具,更重要的是,它深刻揭示了指令数据复杂度对于激发LLM潜能的重要性,为后续研究指明了方向。
未来研究展望:
- 进化的精细控制与评估:目前的进化操作虽然有效,但主要依赖随机选择和简单的难度控制(如限制增加词数)。未来的研究可以探索更精细的复杂度度量方法,并设计更具适应性的进化策略,例如根据模型当前的能力水平动态调整进化难度(类似于课程学习)。
- 进化过程的链式推理:当前方法对指令进行进化,但对响应的生成是一次性的。未来可以探索在进化过程中同时进化“思维链”或“推理轨迹”,让模型不仅面对更复杂的问题,也学习更复杂的解题过程,如Orca模型所做的那样。
- 多模态与具身智能指令进化:本文方法主要针对纯文本指令。未来可以将Evol-Instruct的思想拓展到多模态领域(如视觉-语言指令)或具身智能领域(如机器人操作指令),自动化生成更复杂、更贴近真实世界的多模态任务数据。
- 降低进化成本:虽然比人工标注成本低,但调用GPT-4等强模型进行多轮进化仍有一定开销。未来可以研究如何通过蒸馏、自举等技术,用更小、更经济的模型来执行进化过程,同时保持或接近原有性能。
- 避免进化陷阱:论文中提到了“进化失败”并用消除器处理。未来可以研究如何从根本上引导LLM避免产生无意义或无法回答的指令,例如通过强化学习来优化进化过程的Prompt,使其生成质量和成功率更高。
后记
- 如果您对我的博客内容感兴趣,欢迎三连击(点赞, 关注和评论) !!!
- 本博客将持续为您带来计算机人工智能前沿技术研究进展分享,助您更快了解 AI前沿技术。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)