高可用Kubernetes集群与可观测性运维平台搭建
1.项目说明
1.1 项目描述
- 使用kubeadm搭建 3master+2worker 高可用集群,部署Calico网络插件实现节点间互通,HAProxy+Keepalived 实现高可用架构(负载均衡与故障转移);
- 基于 Helm 部署 kube-Prometheus 监控套件,搭配 Loki+Promtail 日志方案,借助 Grafana 实现监控数据可视化,同时配置 AlertManager 对接企业微信告警,实现异常实时通知;
- 采用 Longhorn 轻量分布式存储,为Prometheus、Loki、Grafana等核心组件配置持久化PVC,通过Longhorn实现数据持久化存储,避免Pod重启导致数据丢失;
- 额外部署一台机器作为 Harbor私有镜像仓库,实现集群内镜像统一托管与安全校验,打通集群镜像拉取权限。
- 使用 Python 与 Kubernetes SDK 开发自动化巡检脚本,实现节点健康、Pod 状态、PVC 存储、服务可用性的自动 化检测与告警推送,替代人工巡检,实现高可用 K8s 集群智能化运维。
点击跳转Python 与 Kubernetes SDK 开发自动化巡检脚本
1.2 项目架构图
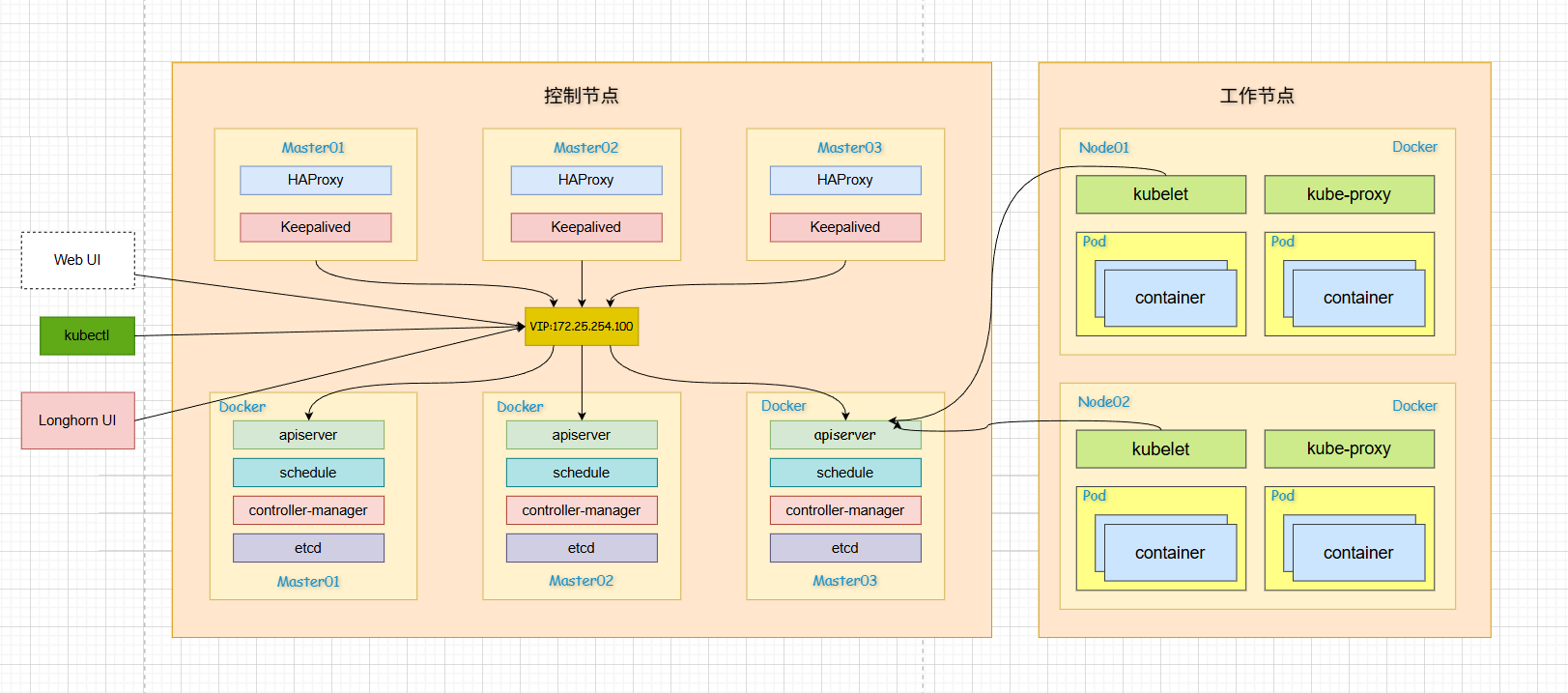
1.3 主机规划
| 主机名 | IP地址 | 配置 | 角色 | OS |
|---|---|---|---|---|
| 172.25.254.100 | VIP | Rocky Linux9.6 mini | ||
| master01 | 172.25.254.101 | CPU:4,MEM:3GB,DISK:100G | Master | Rocky Linux9.6 mini |
| master02 | 172.25.254.102 | CPU:4,MEM:3GB,DISK:100G | Master | Rocky Linux9.6 mini |
| master03 | 172.25.254.103 | CPU:4,MEM:3GB,DISK:100G | Masrer | Rocky Linux9.6 mini |
| node01 | 172.25.254.10 | CPU:4,MEM:3GB,DISK:100G | Worker | Rocky Linux9.6 mini |
| node02 | 172.25.254.20 | CPU:4,MEM:3GB,DISK:100G | Worker | Rocky Linux9.6 mini |
| reg.harbor.org | 172.25.254.200 | CPU:4,MEM:400M,DISK:100G | 本地Harbor | Rocky Linux9.6 mini |
2.基础环境配置
2.1 网络配置
[root@localhost ~]# nmcli c modify eth0 ipv4.method manual ipv4.addresses 172.25.254.101 ipv4.gateway 172.25.254.2 ipv4.dns "223.5.5.5 223.6.6.6 8.8.8.8" connection.autoconnect yes && nmcli c up eth0 && hostnamectl hostname master01 && bash
[root@localhost ~]# nmcli c modify eth0 ipv4.method manual ipv4.addresses 172.25.254.102 ipv4.gateway 172.25.254.2 ipv4.dns "223.5.5.5 223.6.6.6 8.8.8.8" connection.autoconnect yes && nmcli c up eth0 && hostnamectl hostname master02 && bash
[root@localhost ~]# nmcli c modify eth0 ipv4.method manual ipv4.addresses 172.25.254.103 ipv4.gateway 172.25.254.2 ipv4.dns "223.5.5.5 223.6.6.6 8.8.8.8" connection.autoconnect yes && nmcli c up eth0 && hostnamectl hostname master03 && bash
[root@localhost ~]# nmcli c modify eth0 ipv4.method manual ipv4.addresses 172.25.254.10 ipv4.gateway 172.25.254.2 ipv4.dns "223.5.5.5 223.6.6.6 8.8.8.8" connection.autoconnect yes && nmcli c up eth0 && hostnamectl hostname node01 && bash
[root@localhost ~]# nmcli c modify eth0 ipv4.method manual ipv4.addresses 172.25.254.20 ipv4.gateway 172.25.254.2 ipv4.dns "223.5.5.5 223.6.6.6 8.8.8.8" connection.autoconnect yes && nmcli c up eth0 && hostnamectl hostname node02 && bash
[root@localhost ~]# nmcli c modify eth0 ipv4.method manual ipv4.addresses 172.25.254.200 ipv4.gateway 172.25.254.2 ipv4.dns "223.5.5.5 223.6.6.6 8.8.8.8" connection.autoconnect yes && nmcli c up eth0 && hostnamectl hostname reg.harbor.org && bash
2.2 更改软件源
全部主机
sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://dl.rockylinux.org/$contentdir|baseurl=https://mirrors.aliyun.com/rockylinux|g' \
-i.bak \
/etc/yum.repos.d/Rocky-*.repo
dnf makecache
2.3 最小化安装常用工具
全部主机
dnf install wget tree bash-completion vim psmisc net-tools -y
source /etc/profile.d/bash_completion.sh
2.4 火墙与selinux设置
全部主机
systemctl disable firewalld.service
systemctl mask firewalld.service
sed -i '/^SELINUX=/ c SELINUX=disabled' /etc/selinux/config
setenforce 0
2.5 配置hosts解析
集群所有主机
cat > /etc/hosts <<EOF
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.25.254.101 master01 m1
172.25.254.102 master02 m2
172.25.254.103 master03 m3
172.25.254.10 node01 n1
172.25.254.20 node02 n1
172.25.254.200 reg.harbor.org
EOF
2.6 集群主机间配置免密
[root@master01 ~]# ssh-keygen
[root@master01 ~]# for ip in 102 103 10 20 200; do ssh-copy-id root@172.25.254.$ip; done
[root@master02 ~]# ssh-keygen
[root@master02 ~]# for ip in 101 103 10 20 200; do ssh-copy-id root@172.25.254.$ip; done
[root@master03 ~]# ssh-keygen
[root@master03 ~]# for ip in 101 102 10 20 200; do ssh-copy-id root@172.25.254.$ip; done
[root@node01 ~]# ssh-keygen
[root@node01 ~]# for ip in 101 102 103 20 200; do ssh-copy-id root@172.25.254.$ip; done
[root@node02 ~]# ssh-keygen
[root@node02 ~]# for ip in 101 102 103 20 200; do ssh-copy-id root@172.25.254.$ip; done
3.部署高可用组件
3.1 HAProxy
所有master节点
rpm包安装haproxy软件:
dnf install haproxy -y
编辑配置文件:
cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
cat > /etc/haproxy/haproxy.cfg <<EOF
global
maxconn 2000
ulimit-n 16384
log 127.0.0.1 local0 err
stats timeout 30s
defaults
log global
mode http
option httplog
timeout connect 5000
timeout client 50000
timeout server 50000
timeout http-request 15s
timeout http-keep-alive 15s
frontend monitor-in
bind *:33305
mode http
option httplog
monitor-uri /monitor
frontend k8s-master
bind 0.0.0.0:16443
bind 127.0.0.1:16443
mode tcp
option tcplog
tcp-request inspect-delay 5s
default_backend k8s-master
backend k8s-master
mode tcp
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server master01 172.25.254.101:6443 check
server master02 172.25.254.102:6443 check
server master03 172.25.254.103:6443 check
EOF
启动服务:
systemctl enable --now haproxy.service
3.2 Keepalived
所有master节点
安装keepalived软件:
dnf install keepalived -y
创建haproxy检测脚本:
mkdir /etc/keepalived/scripts/
cat > /etc/keepalived/scripts/haproxy_check.sh <<EOF
#!/bin/bash
killall -0 haproxy &> /dev/null
EOF
chmod +x /etc/keepalived/scripts/haproxy_check.sh
编辑配置文件:
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id masrer01 #master02 master03
}
vrrp_script check_haproxy {
script "/etc/keepalived/scripts/haproxy_check.sh"
interval 2
weight -20
fall 2
rise 2
}
vrrp_instance VI_1 {
state MASTER #除了master01都是BACKUP
interface eth0
virtual_router_id 51
priority 100 #master01为100 master02为90 master03为85
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.25.254.100
}
track_script {
check_haproxy
}
}
EOF
启动服务:
systemctl enable --now keepalived.service
3.3 测试高可用组件
测试keepalived的VIP漂移
#依次关闭master01,master02的keepalived查看VIP落在哪天主机上
[root@master01 ~]# systemctl stop keepalived.service #此时落在master02上
[root@master02 ~]# systemctl stop keepalived.service #此时落在master03上
#依次开启回去查看VIP的情况
[root@master01 ~]# ip a
测试haproxy的宕机情况的VIP漂移
#依次关闭master01,master02的haproxy查看VIP落在哪天主机上
[root@master01 ~]# systemctl stop haproxy.service #此时落在master02上
[root@master02 ~]# systemctl stop haproxy.service #此时落在master03上
#依次开启回去查看VIP的情况
[root@master01 ~]# ip a
至此高可用组件已经配置完毕
4.安装Docker
全部主机都要安装Docker
添加仓库源并安装:
yum install -y yum-utils
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
dnf install docker-ce -y
systemctl enable --now docker
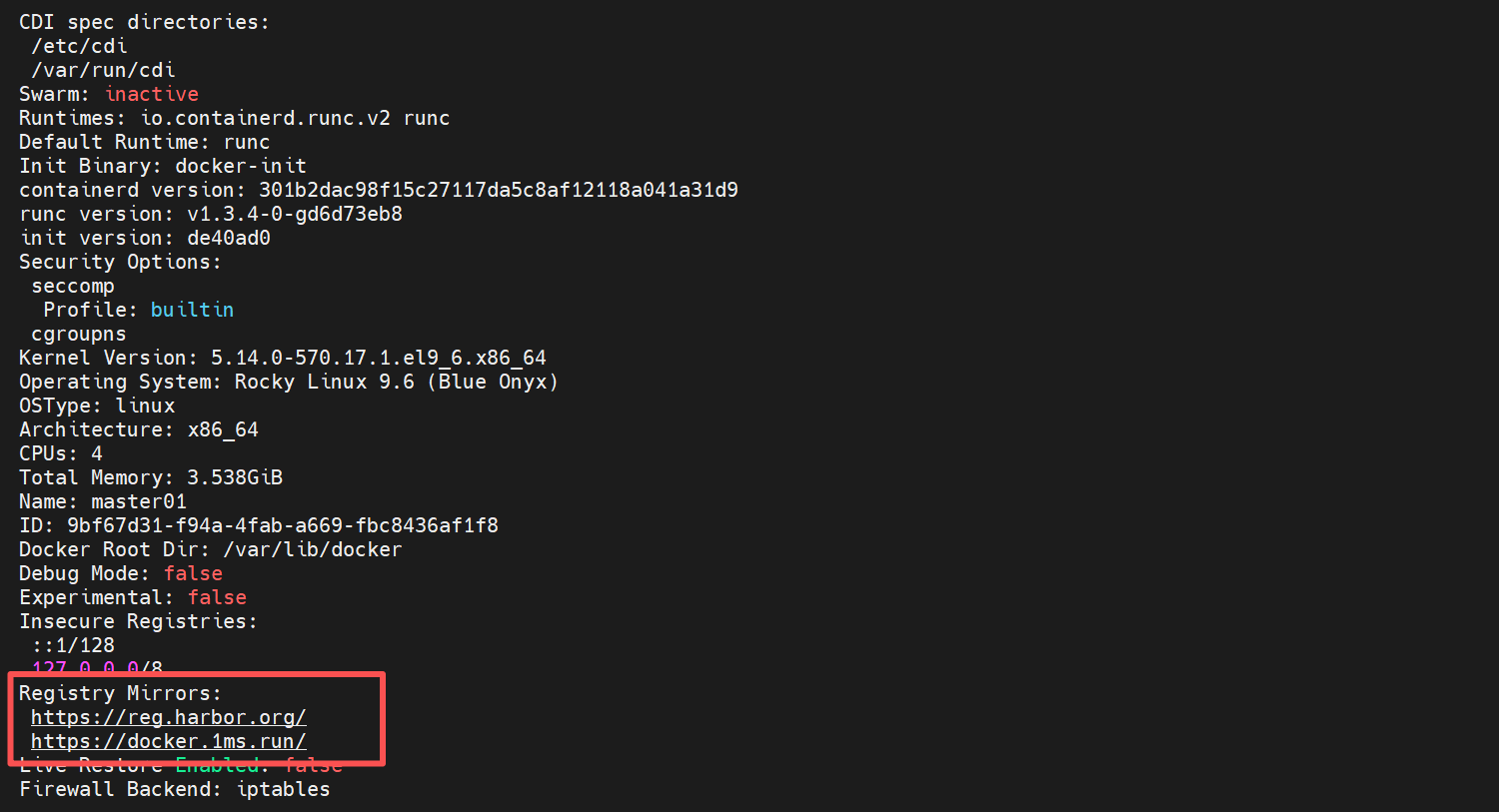
设置镜像仓库源:
配置镜像加速
模拟生产环境中从内网拉取镜像来部署而不是从外网拉取镜像,安全性欠缺
cat >> /etc/docker/daemon.json <<EOF
{
"registry-mirrors": ["https://reg.harbor.org",
"https://docker.1ms.run"
]
}
EOF
systemctl restart docker
查看是否添加成功
docker info
5.Harbor仓库部署
harbor获取地址:https://github.com/goharbor/harbor/
5.1 生成证书与公钥
1.配置ssl生成证书与公钥
[root@reg ~]# mkdir /data/certs/ -p
[root@reg ~]# openssl req -newkey rsa:4096 \
-nodes -sha256 -keyout /data/certs/harbor.org.key \
-addext "subjectAltName = DNS:reg.harbor.org" \
-x509 -days 365 -out /data/certs/harbor.org.crt
5.2 获取资源与部署
2.安装harbor与运行
[root@reg ~]# wget https://github.com/goharbor/harbor/releases/download/v2.13.5/harbor-offline-installer-v2.13.5.tgz
[root@reg ~]# tar zxf harbor-offline-installer-v2.13.5.tgz
[root@reg ~]# cd harbor/
[root@reg harbor]# cp harbor.yml.tmpl harbor.yml
[root@reg harbor]# vim harbor.yml
hostname: reg.harbor.org #habor的访问域名
......
certificate: /data/certs/harbor.org.crt #https证书
private_key: /data/certs/harbor.org.key #https私钥
......
harbor_admin_password: password #设置登录密码
[root@reg harbor]# ./install.sh
[root@reg harbor]# docker compose up -d
5.3 信任仓库证书
3.拷贝证书给docker让其信任并验证
[root@reg ~]# mkdir /etc/docker/certs.d/reg.harbor.org -p
[root@reg ~]# cp /data/certs/harbor.org.crt /etc/docker/certs.d/reg.harbor.org/ca.crt
[root@reg ~]# systemctl restart docker
[root@reg ~]# docker login reg.harbor.org -u admin
Password:
Login Succeeded #显示登录成功即可完成
4.将harbor证书拷贝给k8s集群所有主机让其信任
[root@reg harbor]# for i in {101,102,103,10,20}; do scp -r /etc/docker/certs.d/ root@172.25.254.$i:/etc/docker/; done
#k8s集群主机重启docker并登录
systemctl restart docker
docker login reg.harbor.org
6.k8s高可用集群部署准备
6.1 关闭swap分区
k8s集群主机
systemctl disable --now swap.target
systemctl mask swap.target
sed -i 's/.*swap.*/#&/' /etc/fstab
swapoff -a
free -h
#查看是否关闭
6.2 配置时间同步
全部主机
dnf install chrony -y
sed -i '/^pool/ c server ntp.aliyun.com iburst' /etc/chrony.conf
systemctl enable --now chronyd
systemctl restart chronyd
chronyc sources -v
6.3 修改linux最大连接数
k8s集群主机
cat >> /etc/security/limits.conf <<EOF
* soft nofile 655350
* hard nofile 655350
* soft nproc 655350
* hard nproc 655350
* soft memlock unlimited
* hard memlock unlimited
EOF
ulimit -SHn 655350
6.4 优化内核参数与安装ipvs
k8s集群主机
modprobe br_netfilter
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl -p /etc/sysctl.d/k8s.conf
dnf install ipvsadm -y
6.5 安装cri-docker
所有k8s集群主机
安装cri-docker让docker作为k8s集群的容器运行时
下载地址: https://github.com/Mirantis/cri-dockerd/releases/
1.安装软件与依赖
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.24/cri-dockerd-0.3.24-3.fc36.x86_64.rpm
wget https://rpmfind.net/linux/almalinux/8.10/BaseOS/x86_64/os/Packages/libcgroup-0.41-19.el8.x86_64.rpm
dnf install libcgroup-0.41-19.el8.x86_64.rpm -y
dnf install cri-dockerd-0.3.24-3.fc36.x86_64.rpm -y
2.编辑系统服务文件
vim /lib/systemd/system/cri-docker.service
......
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin=cni --pod-infra-container-image=reg.harbor.org/pause:3.10.1
......
[root@master01 ~]# for i in 102 103 10 20 ; do scp /lib/systemd/system/cri-docker.service root@172.25.254.$i:/lib/systemd/system/; done
3.依次启动服务
systemctl daemon-reload
systemctl enable --now cri-docker.service
systemctl enable --now cri-docker.socket
6.6 安装k8s相关软件
1.添加仓库源并安装,启动服务
k8s集群所有主机
这里node直接可以不安装kubectl,由于写者是批量安装所以方便就全部安装了
#添加仓库源
cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.35/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.35/rpm/repodata/repomd.xml.key
EOF
dnf makecache
dnf install -y kubelet kubeadm kubectl
systemctl enable --now kubelet.service
2.master节点中 kubectl 和kubeadm 补齐
6.6.1 kubectl与kubeadm补齐
echo "source <(kubectl completion bash)" >> ~/.bashrc
echo "source <(kubeadm completion bash)" >> ~/.bashrc
source ~/.bashrc
3.查看版本与所需镜像
#查看版本
kubeadm version
#查看所需的镜像
kubeadm config images list

4.提前拉取镜像下来并上传到本地harbor仓库
只在一个master上拉取即可
拉取镜像:
[root@master01 ~]# kubeadm config images pull \
> --image-repository registry.aliyuncs.com/google_containers \
> --kubernetes-version v1.35.3 \
> --cri-socket=unix:///var/run/cri-dockerd.sock
上传镜像到本地harbor:
#确保已经登录本地仓库
[root@master01 ~]# docker login reg.harbor.org -u admin
Password:
[root@master01 ~]# docker images --format "{{.Repository}}:{{.Tag}}" | awk -F "/" '/google/{system("docker tag "$0" reg.harbor.org/k8s/"$3)}'
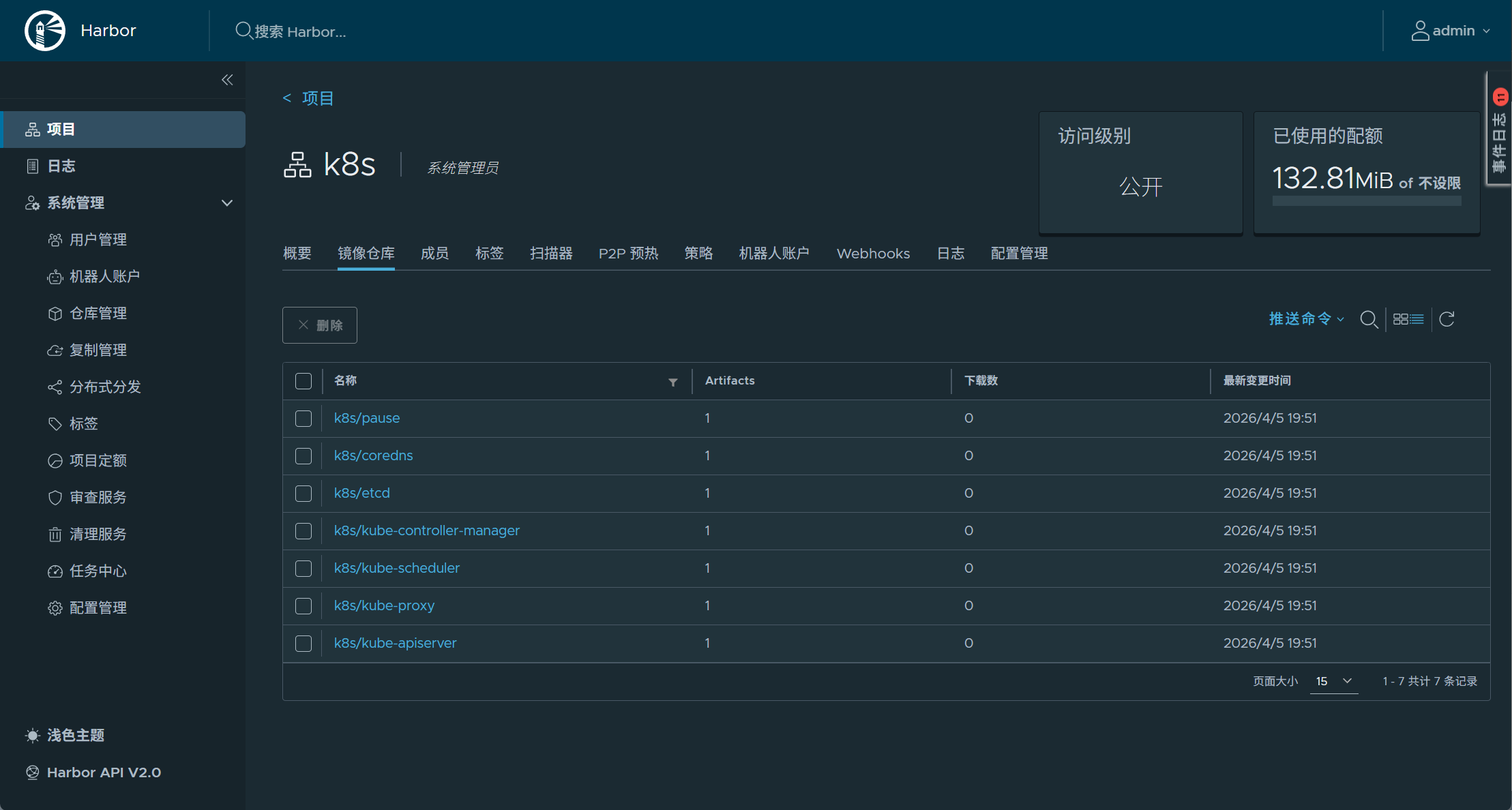
[root@master01 ~]# docker images --format "{{.Repository}}:{{.Tag}}" | awk -F "/" '/harbor/{system("docker push "$0)}'
查看是否推送到了本地harbor仓库
7.kubeadm高可用集群初始化与节点扩容
7.1 初始化集群
master01配置
初始化文件
#生成初始化模板
[root@master01 ~]# kubeadm config print init-defaults > kubeadm-init.yaml
[root@master01 ~]# vim kubeadm-init.yaml
apiVersion: kubeadm.k8s.io/v1beta4
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
#localAPIEndpoint: #注释后可以自动识别
# advertiseAddress: 1.2.3.4
# bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/cri-dockerd.sock #指定使用的容器运行时的套接字
imagePullPolicy: IfNotPresent
imagePullSerial: true
# name: node #主动识别主机名
taints: null
timeouts:
controlPlaneComponentHealthCheck: 4m0s
discovery: 5m0s
etcdAPICall: 2m0s
kubeletHealthCheck: 4m0s
kubernetesAPICall: 1m0s
tlsBootstrap: 5m0s
upgradeManifests: 5m0s
---
apiServer: {}
apiVersion: kubeadm.k8s.io/v1beta4
caCertificateValidityPeriod: 87600h0m0s
certificateValidityPeriod: 8760h0m0s
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
encryptionAlgorithm: RSA-2048
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: reg.harbor.org/k8s #使用本地harbor仓库镜像
kind: ClusterConfiguration
kubernetesVersion: 1.35.3 #指定集群版本
controlPlaneEndpoint: 172.25.254.100:16443 #新增添加高可用VIP与端口
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16 #新增添加pod的网段
proxy: {}
scheduler: {}
---
apiVersion: kubelet.config.k8s.io/v1beta1 #新增
kind: KubeletConfiguration
cgroupDriver: systemd #使用Docker/contained作为容器运行时都要加systemd驱动
imageGCHighThresholdPercent: 95 #磁盘使用率达到95%时自动清理无用镜像
imageGCLowThresholdPercent: 90 #清理降到90%为止
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1 #新增
kind: KubeProxyConfiguration
mode: ipvs #ipvs性能比iptables强生成必开
#检测语法是否ok
kubeadm config validate --config=kubeadm-init.yaml
#开始初始化集群并自动分发证书
kubeadm init --config=kubeadm-init.yaml --upload-certs
#以下为控制节点才需要做的配置
#设置kubectl命令访问权限让其能够管理集群
mkdir -p $HOME/.kube #在当前用户的家目录创建 .kube 隐藏目录(用于存放 kubectl 配置文件)
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config #将集群的管理员配置文件复制到用户专属的 kubectl 配置路径
chown $(id -u):$(id -g) $HOME/.kube/config #修正配置文件的所有权,确保当前用户有权限读取该文件
#设置配置文件的环境变量
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bashrc
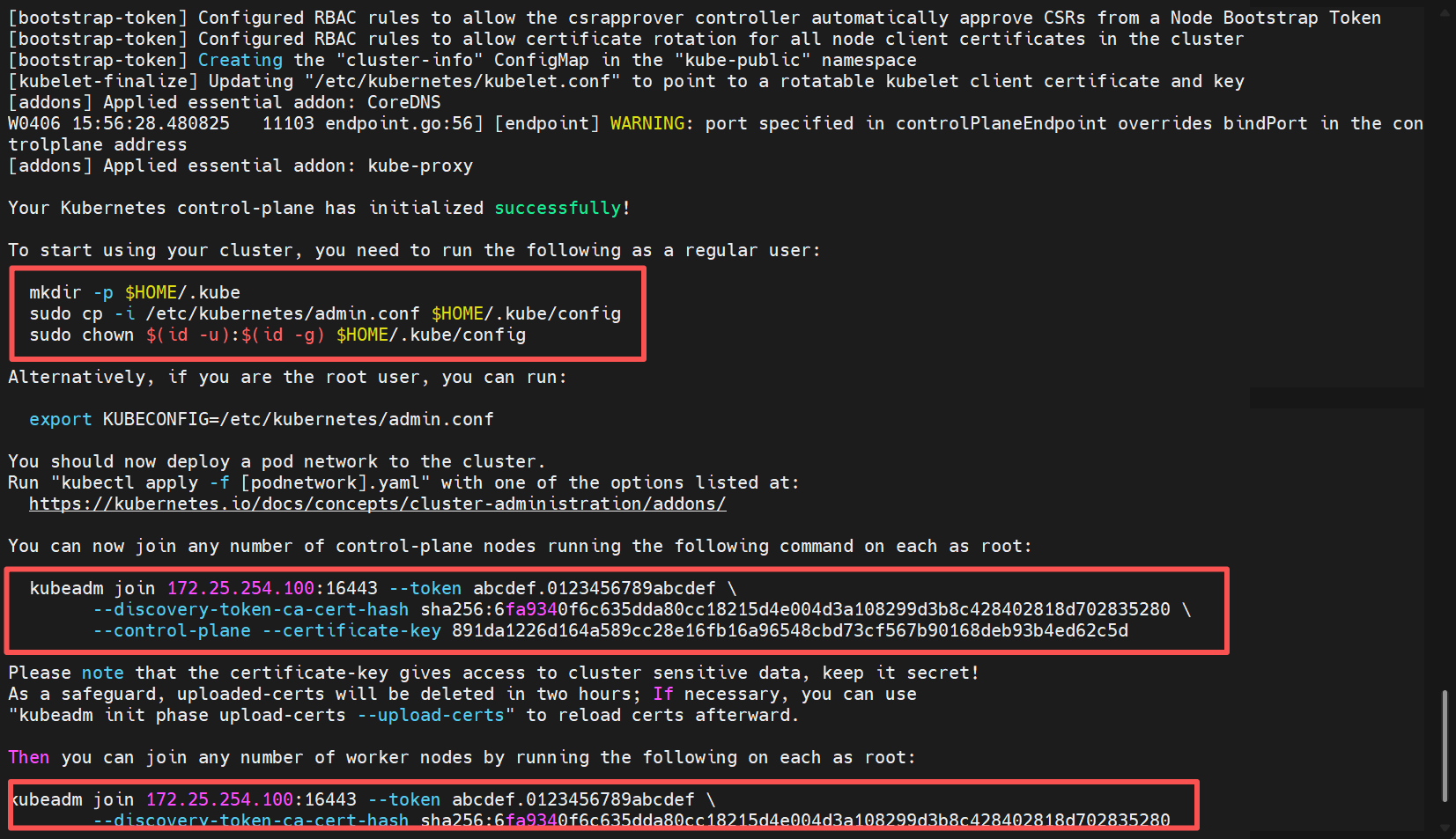
以上为初始化完成的图片
7.2 加入集群
#让另外两个master节点加入集群
[root@master02 ~]# kubeadm join 172.25.254.100:16443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:6fa9340f6c635dda80cc18215d4e004d3a108299d3b8c428402818d702835280 --control-plane --certificate-key 891da1226d164a589cc28e16fb16a96548cbd73cf567b90168deb93b4ed62c5d --cri-socket=unix:///var/run/cri-dockerd.sock
[root@master02 ~]# mkdir -p $HOME/.kube
[root@master02 ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master02 ~]# chown $(id -u):$(id -g) $HOME/.kube/config
[root@master02 ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@master02 ~]# source ~/.bashrc
[root@master03 ~]# kubeadm join 172.25.254.100:16443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:6fa9340f6c635dda80cc18215d4e004d3a108299d3b8c428402818d702835280 --control-plane --certificate-key 891da1226d164a589cc28e16fb16a96548cbd73cf567b90168deb93b4ed62c5d --cri-socket=unix:///var/run/cri-dockerd.sock
[root@master03 ~]# mkdir -p $HOME/.kube
[root@master03 ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master03 ~]# chown $(id -u):$(id -g) $HOME/.kube/config
[root@master03 ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@master03 ~]# source ~/.bashrc
#让node节点加入集群
[root@node01 ~]# kubeadm join 172.25.254.100:16443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:6fa9340f6c635dda80cc18215d4e004d3a108299d3b8c428402818d702835280 --cri-socket=unix:///var/run/cri-dockerd.sock
[root@node02 ~]# kubeadm join 172.25.254.100:16443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:6fa9340f6c635dda80cc18215d4e004d3a108299d3b8c428402818d702835280 --cri-socket=unix:///var/run/cri-dockerd.sock
如果集群初始化错误或者加入错误
#集群初始化错误
[root@master01 ~]# kubeadm reset -f kkubeadm-init.yaml && rm -rf
$HOME/.kube /etc/cni/ /etc/kubernetes/ && ipvsadm --clear
#集群加入错误
kubeadm reset
如果忘记token,可以重新生成
[root@master01 ~]# kubeadm token create --print-join-command
集群加入完成后可以查看节点状态
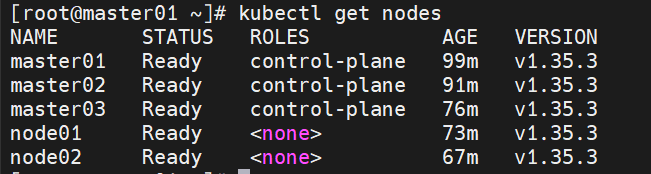
[root@master01 ~]# kubectl get nodes

[!NOTE]
STATUS显示为NotReady是因为没有布置网络插件
7.3 工作节点扩容
[root@node01 ~]# mkdir /root/.kube
[root@node02 ~]# mkdir /root/.kube
[root@master01 ~]# scp .kube/config n1:/root/.kube/
[root@master01 ~]# scp .kube/config n2:/root/.kube/
8.部署Calico网络插件
获取calico部署的自定义资源:
https://docs.tigera.io/calico/latest/getting-started/kubernetes/self-managed-onprem/onpremises#install-calico
打开后点击下载超过50节点yaml文件
8.1 获取yaml文件
只在master01节点操作
1.获取yaml文件
[root@master01 ~]# mkdir calico
[root@master01 ~]# cd calico/
[root@master01 calico]# curl https://raw.githubusercontent.com/projectcalico/calico/v3.31.4/manifests/calico-typha.yaml -o calico.yaml
8.2 拉取镜像
2.上传要使用的镜像到harbor仓库
harbor仓库添加项目
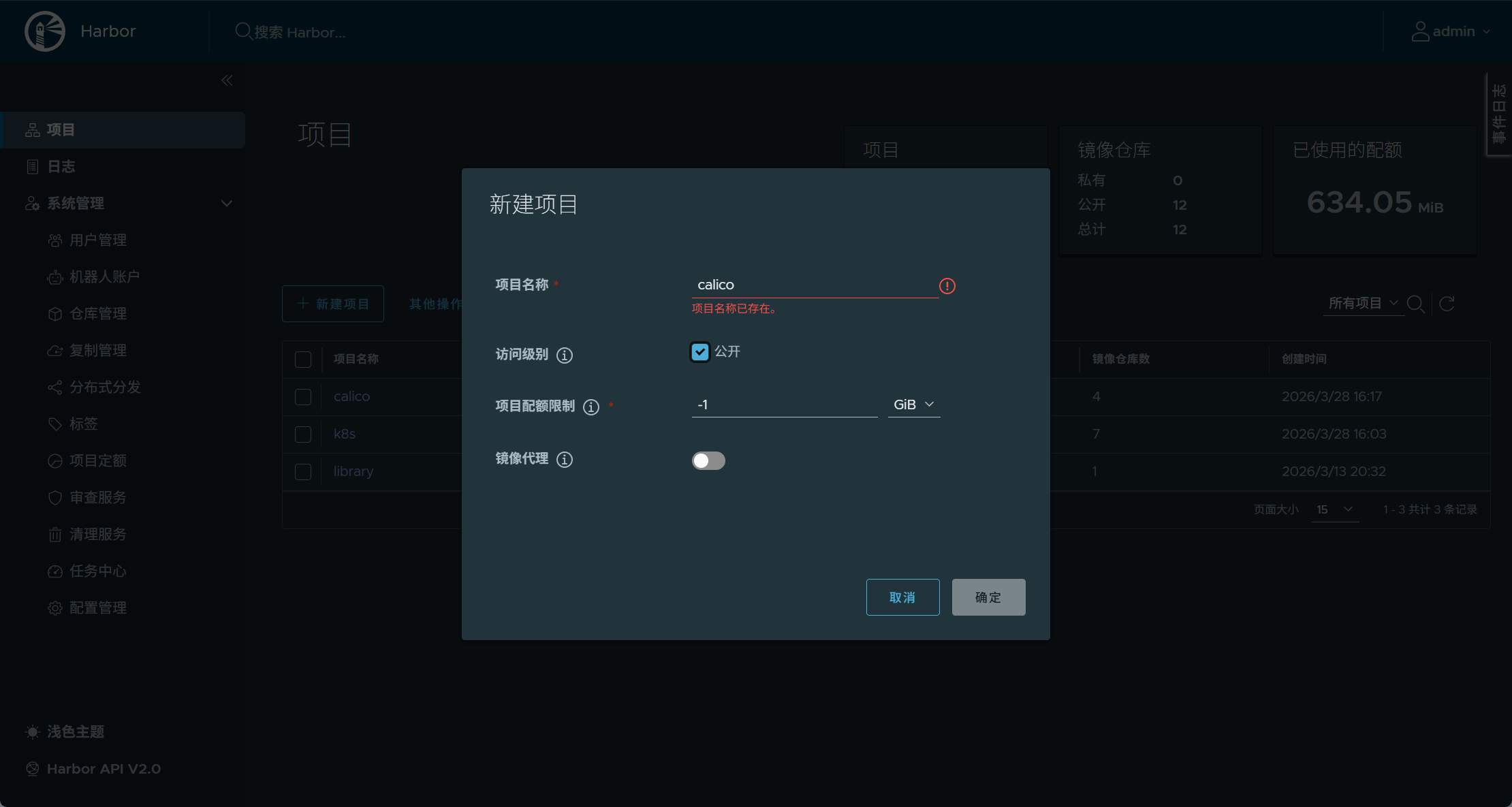
[root@master01 calico]# docker load -i calico-images.tar
[root@master01 ~]# docker images --format "{{.Repository}}:{{.Tag}}" | awk -F "/" '/calico/{system("docker tag "$0" reg.harbor.org/calico/"$3)}'
[root@master01 ~]# docker images --format "{{.Repository}}:{{.Tag}}" | awk -F "/" '/harbor/{system("docker push "$0)}'
8.3 更改yaml文件
3.更改网络模式与镜像地址
[root@master01 calico]# vim calico.yaml
......
image: reg.harbor.org/calico/cni:v3.31.4 #把所有镜像地址改为本地harbor仓库地址
......
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Off" #设置为Off即为BGP模式
# Enable or Disable VXLAN on the default IP pool.
- name: CALICO_IPV4POOL_VXLAN
value: "Never"
# Enable or Disable VXLAN on the default IPv6 IP pool.
- name: CALICO_IPV6POOL_VXLAN
value: "Never"
......
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16" #修改为初始化集群pod的网段
......
8.4 部署与验证
4.应用yaml文件部署
#部署后等待即可全部ready
[root@master01 calico]# kubectl apply -f calico.yaml
#查看集群状态
[root@master01 calico]# kubectl get nodes
9.集群测试与etcd备份
9.1 测试集群创建的资源是否可以正常访问网络和coredns
[root@master01 ~]# kubectl run --image library/busybox --image-pull-policy IfNotPresent --restart Never --rm -it busybox -- /bin/sh
/ # ping www.baidu.com
PING www.baidu.com (183.2.172.177): 56 data bytes
64 bytes from 183.2.172.177: seq=0 ttl=127 time=9.832 ms
64 bytes from 183.2.172.177: seq=1 ttl=127 time=7.549 ms
64 bytes from 183.2.172.177: seq=2 ttl=127 time=8.918 ms
64 bytes from 183.2.172.177: seq=3 ttl=127 time=6.159 ms
9.2 排查 etcd 集群健康状况的标准操作
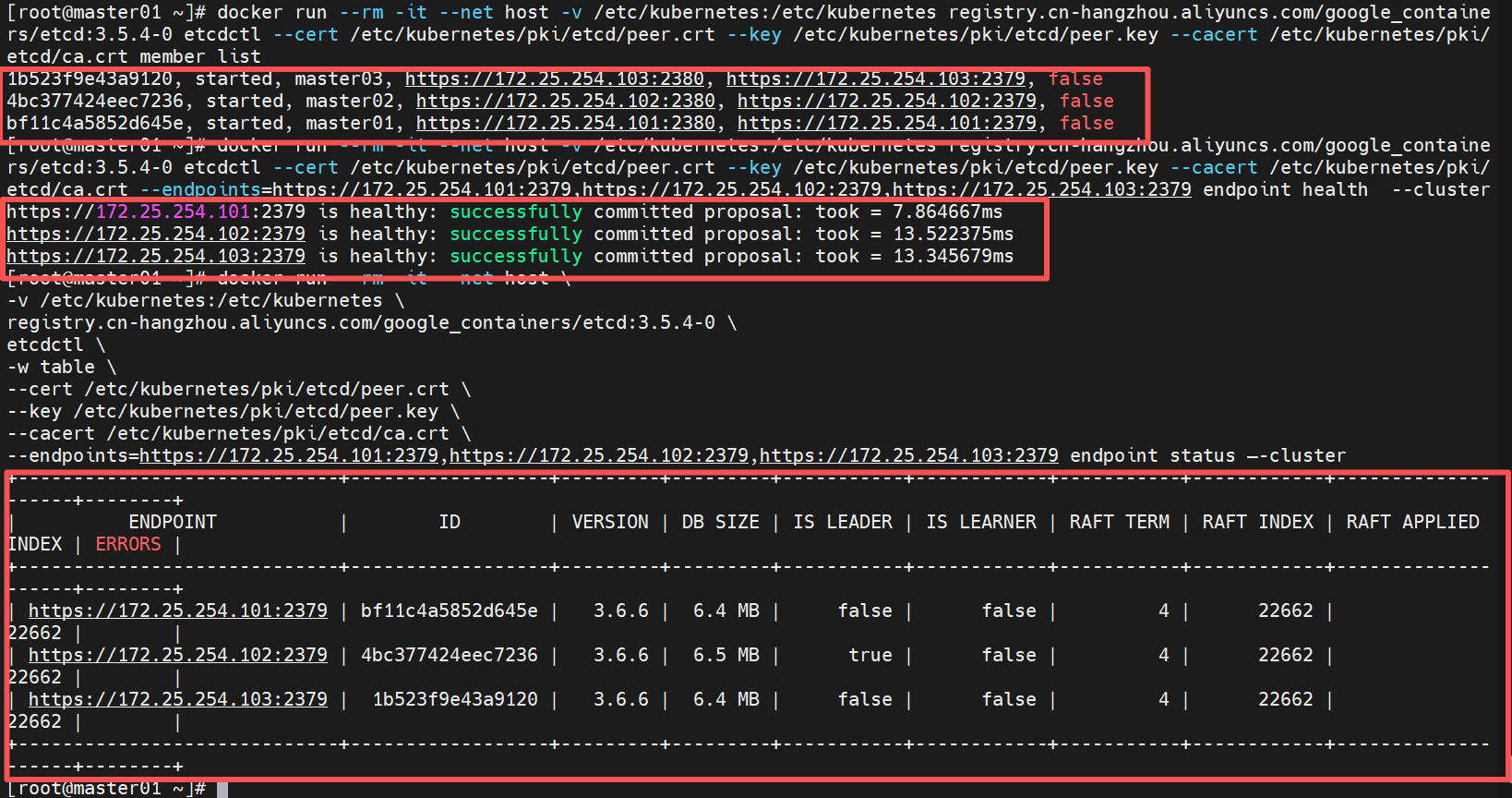
1.列出 etcd 集群当前所有成员(节点)的信息
[root@master01 ~]# docker run --rm -it --net host -v /etc/kubernetes:/etc/kubernetes reg.harbor.org/k8s/etcd:3.6.6-0 etcdctl --cert /etc/kubernetes/pki/etcd/peer.crt --key /etc/kubernetes/pki/etcd/peer.key --cacert /etc/kubernetes/pki/etcd/ca.crt member list
2.检查 etcd 集群中所有指定端点的健康状态
[root@master01 ~]# docker run --rm -it --net host -v /etc/kubernetes:/etc/kubernetes reg.harbor.org/k8s/etcd:3.6.6-0 etcdctl --cert /etc/kubernetes/pki/etcd/peer.crt --key /etc/kubernetes/pki/etcd/peer.key --cacert /etc/kubernetes/pki/etcd/ca.crt --endpoints=https://172.25.254.101:2379,https://172.25.254.102:2379,https://172.25.254.103:2379 endpoint health --cluster
3.以表格格式显示 etcd 集群中所有端点的详细状态信息(包括 leader、raft term、存储大小、版本等)
[root@master01 ~]# docker run --rm -it --net host \
-v /etc/kubernetes:/etc/kubernetes \
reg.harbor.org/k8s/etcd:3.6.6-0 \
etcdctl \
-w table \
--cert /etc/kubernetes/pki/etcd/peer.crt \
--key /etc/kubernetes/pki/etcd/peer.key \
--cacert /etc/kubernetes/pki/etcd/ca.crt \
--endpoints=https://172.25.254.101:2379,https://172.25.254.102:2379,https://172.25.254.103:2379 endpoint status –-cluster
9.3 etcd备份
- 只需要备份任意一个节点的数据就行,不需要三个节点都备份!
- 因为 etcd 是一个强一致性集群,所有节点的数据内容是一样的(同步的),
- 所以备份任何一个健康节点的数据就可以恢复整个集群!
[root@master01 ~]# docker run --rm -it --net host -v /etc/kubernetes:/etc/kubernetes -v /backup:/backup reg.harbor.org/k8s/etcd:3.6.6-0 etcdctl --cert /etc/kubernetes/pki/etcd/peer.crt --key /etc/kubernetes/pki/etcd/peer.key --cacert /etc/kubernetes/pki/etcd/ca.crt --endpoints=https://172.25.254.101:2379 snapshot save /backup/etcd-snapshot.db
# 将备份发送至另一台专门做存储的主机(奈何资源不足,发送至Harbor主机进行保存)
[root@reg ~]# mkdir /backup_k8s
[root@master01 ~]# scp /backup/etcd-snapshot.db reg.harbor.org:/backup_k8s/
[!CAUTION]
etcd备份一定要定时做!比如用 crontab 每天备一份。
最好把快照文件备份到远程,比如 NAS、对象存储,不要只存在本机。
恢复操作尽量在测试环境演练过一次,不要第一次就在生产上操作。
etcd非常重要,它是Kubernetes的心脏,千万不能轻视备份。
#如果要进行测试可以执行以下命令
rm -rf /var/lib/etcd/*
备份文件进行还原(集群宕机)及集群内etcd重启
docker run --rm -it --net host \
-v /etc/kubernetes:/etc/kubernetes \
-v /backup:/backup \
-v /var/lib/etcd:/var/lib/etcd \
reg.harbor.org/k8s/etcd:3.6.6-0 \
etcdctl snapshot restore /backup/etcd-snapshot.db \
--data-dir /var/lib/etcd
10.部署Helm
所有master部署
wget https://get.helm.sh/helm-v4.1.3-linux-amd64.tar.gz
tar zxf helm-v4.1.3-linux-amd64.tar.gz
cp -p linux-amd64/helm /usr/local/bin/
scp -p linux-amd64/helm m2:/usr/local/bin/
scp -p linux-amd64/helm m3:/usr/local/bin/
echo "source <(helm completion bash)" >> ~/.bashrc
source ~/.bashrc
helm version
helm repo add azure http://mirror.azure.cn/kubernetes/charts
helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
helm repo add bitnami https://charts.bitnami.com/bitnami
[root@master01 ~]# helm repo list
NAME URL
azure http://mirror.azure.cn/kubernetes/charts
aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
bitnami https://charts.bitnami.com/bitnami
11.部署Metrics
11.1 Metrics介绍
在 Kubernetes 新的监控体系中,Metrics Server 用于提供核心指标(Core Metrics),包括 Node、 Pod 的 CPU 和内存使用指标,对其他自定义指标(Custom Metrics)的监控则由 Prometheus 等组件 来完成
Metrics Server 是一个可扩展的、高效的容器资源度量,通常可用于 Kubernetes 内置的自动伸缩,即自 动伸缩可依据 Metrics 的度量指标。
Metrics Server 从 Kubelet 收集资源指标,并通过 Metrics API 将它们暴露在 Kubernetes apiServer 中,供 Pod 水平或垂直自动伸缩使用。
kubectl top 也可以访问 Metrics API,可查看相关对象资源使用情况。
11.2 获取配置文件
创建工作目录并添加helm仓库:
[root@master01 ~]# mkdir metrics
[root@master01 ~]# cd metrics/
[root@master01 metrics]# helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server/
[root@master01 headlamp]# helm repo list
NAME URL
azure http://mirror.azure.cn/kubernetes/charts
aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
bitnami https://charts.bitnami.com/bitnami
metrics-server https://kubernetes-sigs.github.io/metrics-server/
11.3 自定义配置
生成变量模板并修改:
[root@master01 metrics]# helm show values metrics-server/metrics-server > defaults-values.yaml
[root@master01 metrics]# vim defaults-values.yaml
6 repository: registry.aliyuncs.com/google_containers/metrics-server #更改镜像源
68 containerPort: 10300 #修改端口
76 enabled: true #启用宿主机网络栈
77
78 replicas: 2 #副本数为2,开启高可用
101 args:
102 - --secure-port=10300
103 - --kubelet-insecure-tls #自签名证书场景必须追加此行
11.4 部署验证
部署并验证:
[root@master01 metrics]# helm upgrade --install metrics-server metrics-server/metrics-server -n kube-system -f defaults-values.yaml
[root@master01 metrics]# kubectl top nodes
[root@master01 metrics]# kubectl top pods --all-namespaces
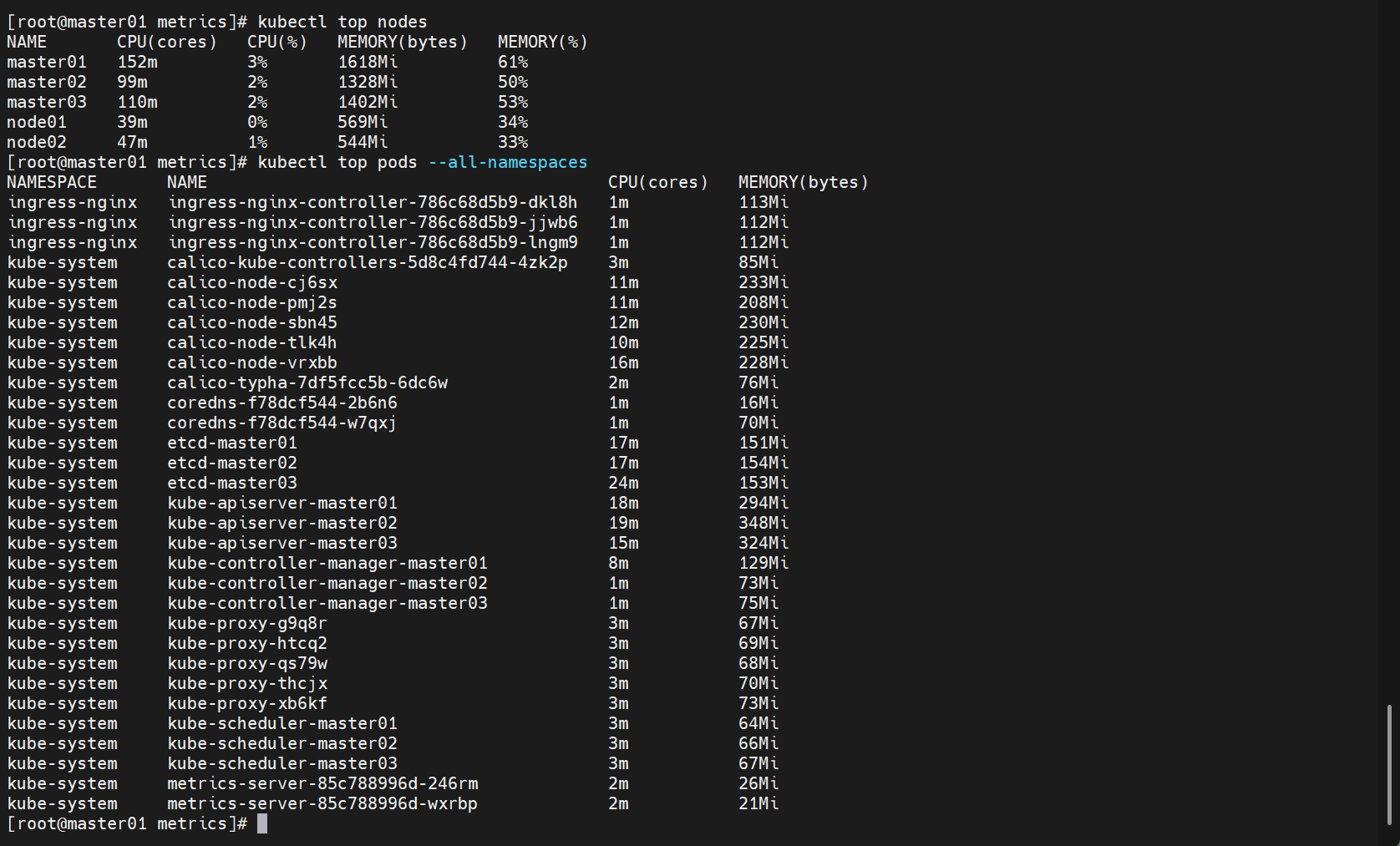
提示:当开启 hostNetwork 的时候,metrics-serverd 是会使用宿主机网络栈,该 pod 默认的 10250 会和kubelet 默认端口 10250 冲突,因此建议修改端口。
12.部署ingress-nginx
12.1 ingress-nginx简介
GitHub:https://github.com/kubernetes/ingress-nginx/blob/main/README.md
Kubernetes中的应用通常以Service对外暴露,而Service的表现形式为IP:Port,即工作在TCP/IP层。 对于基于HTTP的服务来说,不同的URL地址经常对应到不同的后端服务(RS)或者虚拟服务器(Virtual Host),这些应用层的转发机制仅通过Kubernetes的Service机制是无法实现的。
从Kubernetes 1.1版本开始新增Ingress资源对象,用于将不同URL的访问请求转发到后端不同的 Service,以实现HTTP层的业务路由机制。
Kubernetes使用了一个Ingress策略规则和一个具体的Ingress Controller,两者结合实现了一个完整的 Ingress负载均衡器。
使用Ingress进行负载分发时,Ingress Controller基于Ingress策略规则将客户端请求直接转发到Service 对应的后端Endpoint(Pod)上,从而跳过kube-proxy的转发功能,kube-proxy不再起作用。
简单的理解就是:ingress使用DaemonSet或Deployment在相应Node上监听80或443,然后配合相应 规则,因为Nginx外面绑定了宿主机80端口(就像 NodePort),本身又在集群内,那么向后直接转发到 相应ServiceIP即可实现相应需求。
ingress controller + ingress 策略规则 ----> services。 同时当Ingress Controller提供的是对外服务,则实际上实现的是边缘路由器的功能。
但由于Ingress-NGINX 已确定于 2026 年 3 月全面退役,不再维护;Kubernetes 官方与社区全面转向 Gateway API 作为下一代流量入口标准
这里是学习环境所以先使用ingress-nginx
12.2 设置标签
创建工作目录与给master节点打上标签:
[root@master01 ~]# mkdir ingress-nginx
[root@master01 ~]# cd ingress-nginx/
[root@master01 ingress-nginx]# kubectl label nodes master0{1,2,3} ingress=deploy
12.3 获取部署文件
获取yaml资源与编辑:
[root@master01 ingress-nginx]# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/main/deploy/static/provider/baremetal/deploy.yaml
[root@master01 ingress-nginx]# vim deploy.yaml
......
image: reg.harbor.org/ingress-nginx/nginx-ingress-controller:v1.15.1
image: reg.harbor.org/ingress-nginx/kube-webhook-certgen:v1.6.9
......
---
apiVersion: apps/v1
kind: Deployment
spec:
replicas: 3 # 3副本
template:
spec:
hostNetwork:true #使用主机网络栈
nodeSelector:
ingress: deploy #强制只跑在你打标签的 Master 上
#允许运行在masrer(容忍污点)
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
#让每个 Master 只跑一个 Pod
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app.kubernetes.io/name
operator: In
values:
- ingress-nginx
topologyKey: kubernetes.io/hostname
12.4 部署与验证
部署与验证:
[root@master01 ingress-nginx]# kubectl apply -f deploy.yaml
[root@master01 ingress-nginx]# kubectl get all -n ingress-nginx -o wide
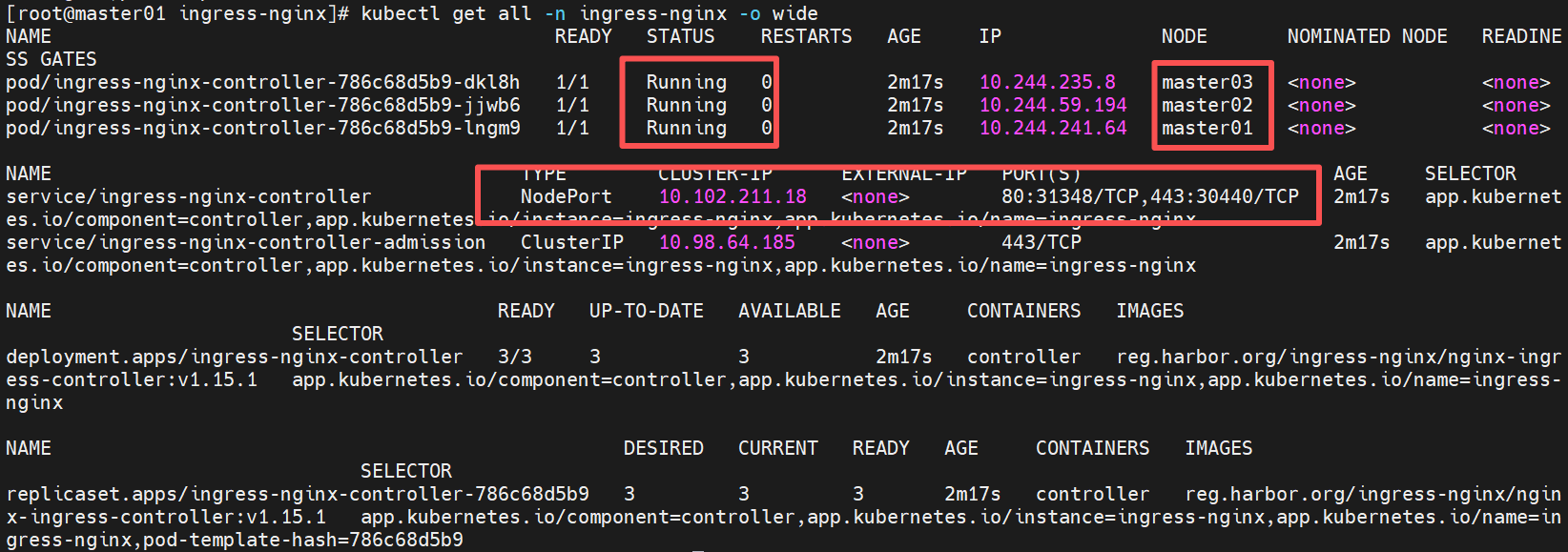
[!TIP]
如果有loadbance可以更改为loadbance来进行暴露ingress
13.部署Web UI Headlamp
13.1 Web UI简介
Headlamp是基于Web的Kubernetes用户界面,即WebUI。可以使用Headlamp将容器化应用程序部署 到Kubernetes集群,对容器化应用程序进行故障排除,以及管理集群资源。
可以使用部署向导扩展部署,启动滚动更新,重新启动Pod或部署新应用程序。
Headlamp还提供有关群集中Kubernetes资源状态以及可能发生的任何错误的信息。
通常生产环境中建议部署Headlamp,以便于图形化来完成基础运维
Github:https://github.com/kubernetes-sigs/headlamp
官网地址:https://headlamp.dev/docs/latest/installation/in-cluster/
13.2 设置标签
[root@master01 metrics]# kubectl label nodes master0{1..3} headlamp=deploy
node/master01 labeled
node/master02 labeled
node/master03 labeled
[!TIP]
提示:建议对于Kubernetes自身相关的应用(如Web UI),此类非业务应用部署在master节 点。
13.3 获取部署文件
添加 headlamp 的 repo 仓库。
[root@master01 dashboard]# helm repo add headlamp https://kubernetes-sigs.github.io/headlamp/
"headlamp" has been added to your repositories
[root@master01 headlamp]# helm repo list
NAME URL
......
headlamp https://kubernetes-sigs.github.io/headlamp/
13.4 自定义配置
#查看版本信息
[root@master01 headlamp]# helm search repo headlamp
NAME CHART VERSION APP VERSION DESCRIPTION
headlamp/headlamp 0.41.0 0.41.0 Headlamp is an easy-to-use and extensible Kuber...
#查看默认配置
[root@master01 headlamp]# helm show values headlamp/headlamp > defaults-values.yaml
#编写自定义配置
[root@master01 headlamp]# cat defaults-values.yaml
replicaCount: 2 #使用2副本机制
image:
registry: registry.cn-hangzhou.aliyuncs.com #更改为国内镜像源
repository: k8s-docker/headlamp #镜像名字
pullPolicy: IfNotPresent
tag: ""
service:
type: ClusterIP
port: 80
ingress:
enabled: false #后面再开
# 把 Pod 调度到打了 `headlamp: deploy` 标签的节点
nodeSelector:
headlamp: deploy
# 容忍 master 污点 → 允许运行在 master 节点
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/control-plane
operator: Exists
- effect: NoSchedule
key: node-role.kubernetes.io/master
operator: Exists
# 给 Headlamp 管理员权限
clusterRoleBinding:
create: true
clusterRoleName: cluster-admin
嗯嗯-h
13.5 正式部署
根据生产环境最佳实践进行调优,调优完成后开始部署。
root@master01 headlamp]# helm upgrade --install headlamp headlamp/headlamp -n headlamp --create-namespace -f defaults-values.yaml
[root@master01 headlamp]# kubectl get -n headlamp all
NAME READY STATUS RESTARTS AGE
pod/headlamp-97b945999-8ksmm 1/1 Running 0 66m
pod/headlamp-97b945999-ph458 1/1 Running 0 67m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/headlamp ClusterIP 10.100.209.24 <none> 80/TCP 67m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/headlamp 2/2 2 2 67m
NAME DESIRED CURRENT READY AGE
replicaset.apps/headlamp-97b945999 2 2 2 67m
13.6 ingress暴露文件配置
#创建清单文件对其进行ingress暴露
[root@master01 headlamp]# cat ingress-headlamp.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: headlamp
namespace: headlamp
annotations:
nginx.ingress.kubernetes.io/ssl-redirect: "false"
nginx.ingress.kubernetes.io/backend-protocol: "HTTP"
nginx.ingress.kubernetes.io/use-regex: "true"
spec:
ingressClassName: nginx
rules:
- host: web.k8s.org #使用这个域名来访问
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: headlamp
port:
number: 80
[root@master01 headlamp]# kubectl apply -f ingress-headlamp.yaml
[root@master01 headlamp]# kubectl get ingress -n headlamp
NAME CLASS HOSTS ADDRESS PORTS AGE
headlamp nginx web.k8s.org 172.25.254.101,172.25.254.102,172.25.254.103 80 52m
13.7 创建管理员用户
创建管理员账户,headlamp默认没有创建具有管理员权限的账户
#创建清单文件
[root@master01 headlamp]# cat <<EOF > admin-user.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: headlamp
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: headlamp-admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: headlamp
EOF
[root@master01 headlamp]# kubectl apply -f admin-user.yaml
13.8 测试访问
本方案采用 ingress 所暴露的域名: https://web.k8s.com,使用对应 admin 用户的 token 进行访问
#查看token
[root@master01 headlamp]# kubectl create token admin-user -n headlamp
eyJhbGciOiJSUzI1NiIsImtpZCI6IndyQjFqclZLaHl1T2VPRTByNWxIdnp5OXFjNlk1bWtoZjVkYjJtUXBNT3MifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNzc1NzM2NTQ5LCJpYXQiOjE3NzU3MzI5NDksImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwianRpIjoiMjUxODM2MmMtNGYzMi00NTBmLTg5NzYtNjJkMTU1NTk5Y2U2Iiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJoZWFkbGFtcCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJhZG1pbi11c2VyIiwidWlkIjoiMjg1ODNkYmItZDFiMC00M2U0LWE1MjQtNTg2MjU3MTkwMzYwIn19LCJuYmYiOjE3NzU3MzI5NDksInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpoZWFkbGFtcDphZG1pbi11c2VyIn0.UZuxr7WAuY2bIcJr-25N9Av9EdDC7X7xwUFm9jeQDIliJpv-DNIqxj4TNfWE3pScCx7pG-XhExgNZ6faii3AM81-5yV3Gaq7pRGS7it0ur_WayofrFYqG3tdPSf1U_WO7vOW0X_OZDw7Dn3brKu8ijEWqZk9gMKLeHmPdp-a0e4stWEYDLIamOkESC6PBnKnHZWdFgQXZ3k0J3MjXmSFb8kUhIUfDyQLvFh40hJ8ntvydumfSPEkVnJTkHGtAIHEvhrJ3_KhJnSSFs_rrWG5xIjeu1a3YGyl4QVYAeYyjV2IMo70oDf8xbH9JQKnsYND0si8cJuFPREJW4_3Gw3QTA
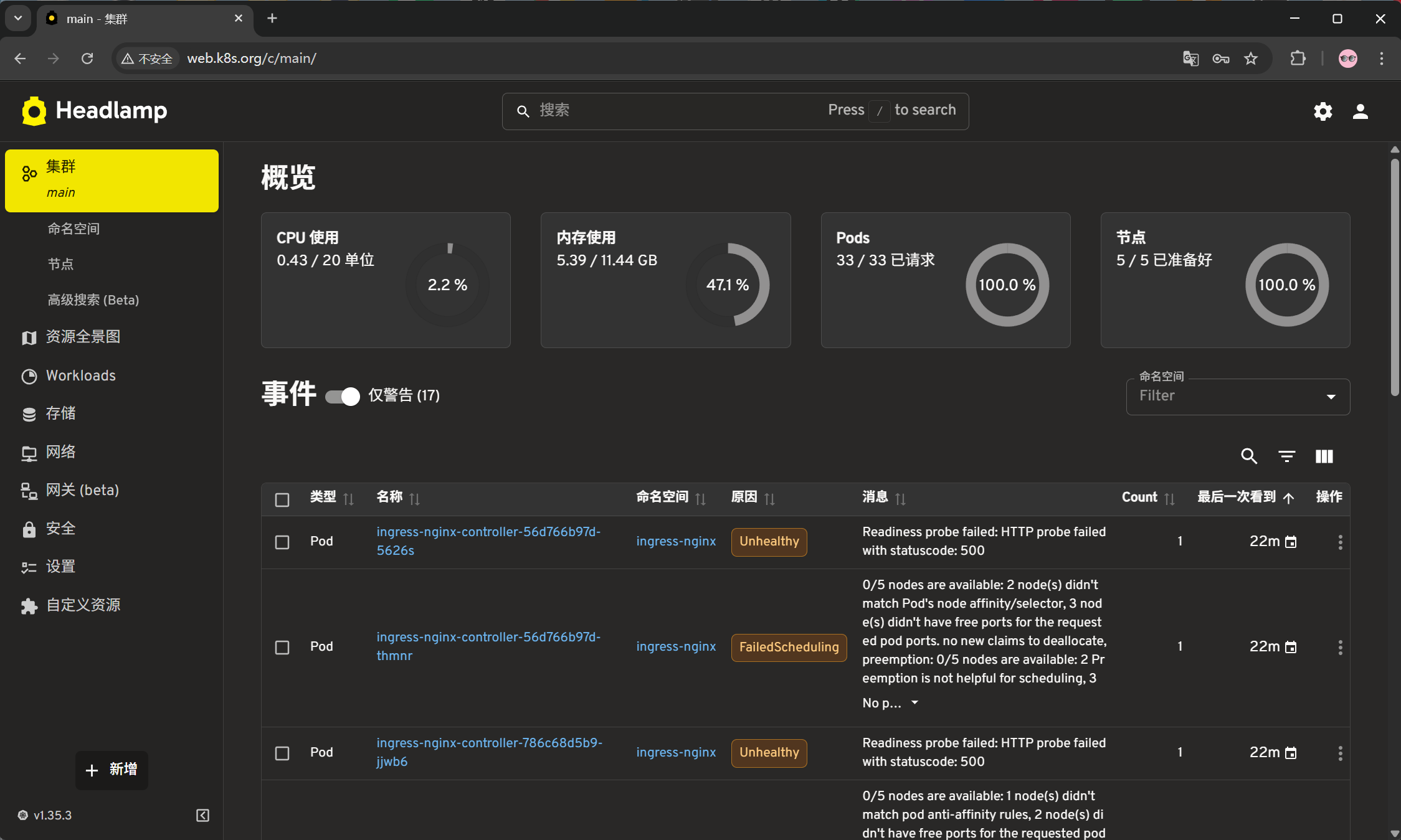
登陆后的界面,可以对整个 Kubernetes 进行管理和查看。
14.部署存储Longhorn
14.1 Longhorn简介
Longhorn(云原生语境下)是 Rancher (SUSE) 开源、专为 Kubernetes 设计的轻量级分布式块存储系统,CNCF 孵化项目,核心解决 K8s 有状态应用的高可用持久化存储问题。
核心定位
- 云原生块存储:只做块存储(不支持对象 / 文件),通过 CSI 与 K8s 深度集成。
- 轻量、易运维:对比 Ceph 更简单、资源占用更低,适合中小集群。
核心架构(两层)
1.控制平面(Longhorn Manager)
- DaemonSet 运行在每个节点
- 负责卷创建 / 删除 / 扩容 / 快照 / 备份 / 副本调度
- 与 K8s API 交互,通过 CRD 管理存储资源
2.数据平面(Longhorn Engine + Replica)
- 每个卷独立一个 Engine(控制器):处理 I/O、多副本同步、故障切换
- 副本(Replica):数据分片存储在不同节点,默认 3 副本(可配置)
- 用 Raft 保证副本一致性,节点故障自动重建副本
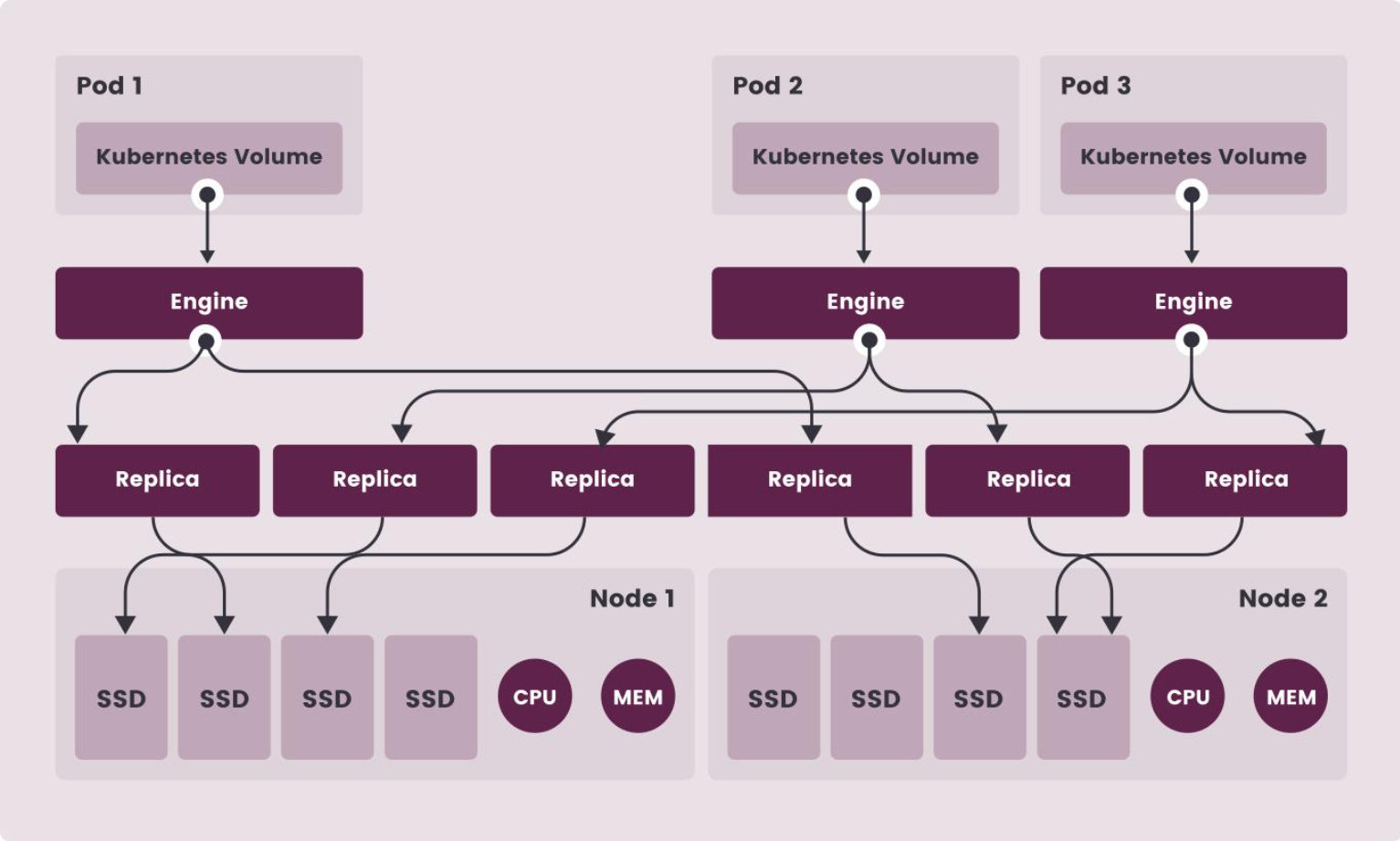
关键特性
- 高可用:多副本跨节点分布,无单点故障
- 动态供给:通过 StorageClass 自动创建 PV/PVC
- 增量快照 & 备份:支持定时快照、备份到 S3/NFS
- 在线扩容 & 克隆:不中断业务扩容、快速克隆卷
- Web UI:内置 Dashboard,可视化管理卷 / 快照 / 备份 / 节点状态
- 无感知升级:升级 Longhorn 不影响正在使用的卷
- 跨集群灾备:支持跨集群备份恢复、远程卷
工作流程(极简)
- 用户创建 PVC → Longhorn Provisioner 自动创建 PV
- Manager 调度:在多个节点创建 Replica
- 在应用所在节点启动 Engine,挂载 iSCSI 目标
- Engine 同步读写到所有副本,保证强一致
- 节点 / 副本故障:自动重建、切换副本,业务不中断
Longhorn vs Ceph(简要)
| 维度 | Longhorn | Ceph |
|---|---|---|
| 架构 | K8s 原生、微服务、单卷单控制器 | 独立分布式集群(RADOS) |
| 部署 | 一键 Helm/Operator,10 分钟 | 复杂,需专业运维 |
| 资源 | 轻量、低开销 | 重、资源需求高 |
| 接口 | 块存储(RBD 兼容) | 块 + 对象 + 文件 |
| 规模 | 中小集群 | 大规模、超融合 |
14.2 安装准备
- open-iscsi已安装,并且iscsid守护程序在所有节点上运行,此为必要条件,Longhorn 依赖 iscsiadm 主机为 Kubernetes 提供持久卷;
- 有关安装 NFSv4 客户端;
集群所有主机执行
dnf -y --setopt=tsflags=noscripts install iscsi-initiator-utils cryptsetup device-mapper
echo \"InitiatorName=$(/sbin/iscsi-iname)\" > /etc/iscsi/initiatorname.iscsi
modprobe iscsi_tcp && systemctl enable --now iscsid
cat > /etc/modules-load.d/iscsi.conf <<EOF
iscsi_tcp
EOF
14.3 设置标签
本实验规划 master 用于 Longhorn UI 部署,node用于提供真实的存储。
在 master 节点上部署存储组件的图形界面。
在 node 节点上部署 Longhorn Manager 和 Longhorn Driver 。
[root@master01 longhorn]# kubectl label nodes master0{1,2,3} longhorn-ui=deploy
node/master01 labeled
node/master02 labeled
node/master03 labeled
[root@master01 longhorn]# kubectl label nodes node0{1,2} longhorn-storage=deploy
node/node01 labeled
node/node02 labeled
14.4 准备磁盘
[root@node01 ~]# mkfs.xfs -f /dev/nvme0n2
[root@node01 ~]# mkdir -p /var/lib/longhorn
[root@node01 ~]# echo '/dev/nvme0n2 /var/lib/longhorn xfs defaults 0 0' >> /etc/fstab
[root@node01 ~]# systemctl daemon-reload
[root@node01 ~]# mount -a
[!TIP]
提示:如上操作需要在所有 worker 节点根据相应的 UUID 进行挂载操作。
14.5 获取部署文件
[root@master01 ~]# mkdir longhorn
[root@master01 ~]# cd longhorn/
[root@master01 longhorn]# helm repo add longhorn https://charts.longhorn.io
[root@master01 longhorn]# helm repo list | grep longhorn
longhorn https://charts.longhorn.io
[root@master01 longhorn]# helm search repo longhorn
NAME CHART VERSION APP VERSION DESCRIPTION
longhorn/longhorn 1.11.1 v1.11.1 Longhorn is a distributed block storage system ...
14.6 自定义配置
[root@master01 longhorn]# helm show values longhorn --repo https://charts.longhorn.io > defaults-values.yaml
# 查看默认配置
[root@master01 longhorn]# vim defaults-values.yaml
# 自定义配置
[root@master01 longhorn]# vim myvalues.yaml
# 1. Longhorn 管理组件(控制大脑)
longhornManager:
# 只调度到打了 longhorn-storage=enabled 标签的节点
nodeSelector:
longhorn-storage: enabled
# 挂载宿主机时间,保证容器时间和系统一致(解决时区问题)
extraVolumeMounts:
- name: timeconfig
mountPath: /etc/localtime
readOnly: true
extraVolumes:
- name: timeconfig
hostPath:
path: /etc/localtime
# 2. Longhorn CSI 驱动(负责 K8s 挂载存储)
longhornDriver:
# 同样只调度到存储节点
nodeSelector:
longhorn-storage: enabled
# 3. Longhorn UI 界面
longhornUI:
replicas: 3 # 高可用开3个副本
# 只调度到打了 longhorn-ui=enabled 标签的节点
nodeSelector:
longhorn-ui: enabled
# 容忍 Master 污点 → 允许 UI 运行在 Master 节点
tolerations:
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
# 时间同步(和上面一样)
extraVolumeMounts:
- name: timeconfig
mountPath: /etc/localtime
readOnly: true
extraVolumes:
- name: timeconfig
hostPath:
path: /etc/localtime
# 4. Ingress 访问配置(域名+密码访问 Longhorn UI)
ingress:
enabled: true # 开启外网/域名访问
ingressClassName: "nginx" # 使用你装的 nginx-ingress
host: "longhorn.k8s.com" # 访问域名
path: /
pathType: Prefix
# 安全配置:基础认证(账号密码登录)
annotations:
nginx.ing.kubernetes.io/auth-type: basic
nginx.ing.kubernetes.io/auth-secret: longhorn-basic-auth
nginx.ing.kubernetes.io/auth-realm: 'Authentication Required'
nginx.ing.kubernetes.io/proxy-body-size: 50m
nginx.ing.kubernetes.io/ssl-redirect: "false"
14.7 创建管理密码
使用已部署完成的 ingress 将 Longhorn UI 暴露,以便于使用 URL 形式访问 Longhorn 图形界面进行 Longhorn 的基础管理。
使用 Helm 部署 Longhorn 中,可直接在自定义 values 中直接配置 ingress,若开启认证,则需要提前 创建好用户密码。
创建用户与密码:
[root@master01 longhorn]# USER=admin; PASSWORD=admin1234; echo "${USER}:$(openssl passwd -stdin -apr1 <<< ${PASSWORD})" >> auth
创建secret:
[root@master01 longhorn]# kubectl create ns longhorn-system
[root@master01 longhorn]# kubectl -n longhorn-system create secret generic longhorn-basic-auth --from-file=auth
14.8 正式部署
基于自定义的 helm values 进行部署
[root@master01 longhorn]# helm upgrade --install longhorn longhorn/longhorn --namespace longhorn-system --create-namespace -f myvalues.yaml
Release "longhorn" does not exist. Installing it now.
I0409 21:03:55.733157 309190 warnings.go:107] "Warning: unrecognized format \"int64\""
I0409 21:03:55.734243 309190 warnings.go:107] "Warning: unrecognized format \"int64\""
I0409 21:03:55.737962 309190 warnings.go:107] "Warning: unrecognized format \"int64\""
I0409 21:03:55.746421 309190 warnings.go:107] "Warning: unrecognized format \"int64\""
NAME: longhorn
LAST DEPLOYED: Thu Apr 9 21:03:55 2026
NAMESPACE: longhorn-system
STATUS: deployed
REVISION: 1
DESCRIPTION: Install complete
TEST SUITE: None
NOTES:
Longhorn is now installed on the cluster!
Please wait a few minutes for other Longhorn components such as CSI deployments, Engine Images, and Instance Managers to be initialized.
Visit our documentation at https://longhorn.io/docs/
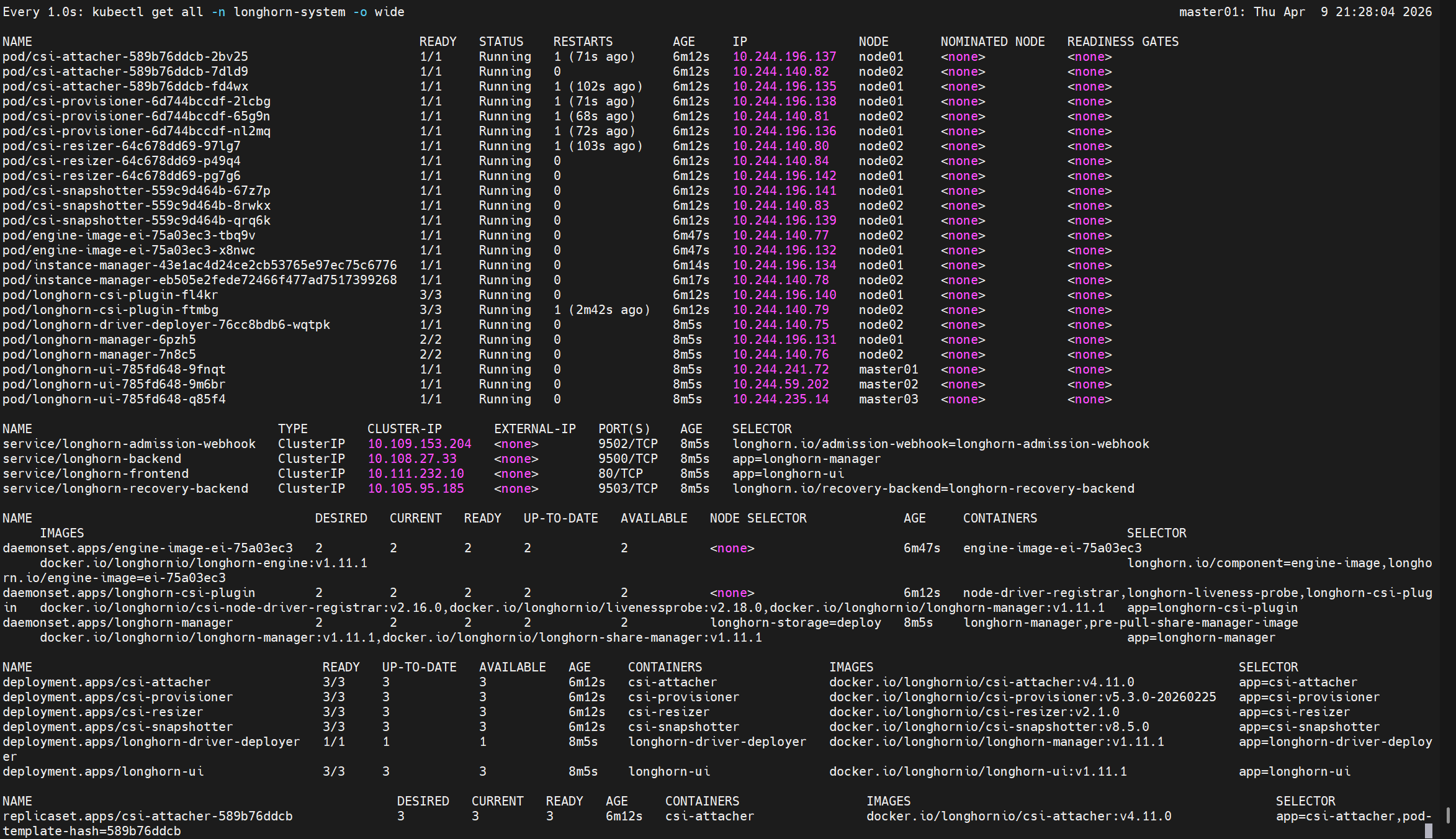
#查看所有已部署的pod与资源
[root@master01 longhorn]# kubectl get all -n longhorn-system
#查看ingres
[root@master01 longhorn]# kubectl get ingress -n longhorn-system
NAME CLASS HOSTS ADDRESS PORTS AGE
longhorn-ingress nginx longhorn.k8s.com 172.25.254.101,172.25.254.102,172.25.254.103 80 9m35s
提示:若部署异常可删除重建,若出现无法删除namespace,可通过如下操作进行删除:
[root@master01 longhorn]# helm uninstall longhorn -n longhorn-system --no-hooks
#所有主机
rm -rf /var/lib/longhorn/*
14.9 动态sc创建
部署 Longhorn 后,默认已创建一个名为 longhorn 的 sc
[root@master01 longhorn]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
longhorn (default) driver.longhorn.io Delete Immediate true 12m
longhorn-static driver.longhorn.io Delete Immediate true 12m
也可以通过如下方式创建一个新的 sc,测试 Longhorn 部署结果。
[root@master01 longhorn]# cat <<EOF > longhornpsc.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-test
provisioner: driver.longhorn.io
allowVolumeExpansion: true
parameters:
numberOfReplicas: "3"
staleReplicaTimeout: "2880" # 48 hours in minutes
fromBackup: ""
fsType: "ext4"
EOF
[root@master01 longhorn]# kubectl apply -f longhornpsc.yaml
[root@master01 longhorn]# kubectl get sc -n longhorn-system
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
longhorn (default) driver.longhorn.io Delete Immediate true 16m
longhorn-static driver.longhorn.io Delete Immediate true 16m
longhorn-test driver.longhorn.io Delete Immediate true 3s
14.10 测试PV与PVC
使用常见的Nginx Pod进行测试,模拟生产环境常见的Web类应用的持久性存储卷
# 创建PVC
[root@master01 longhorn]# cat <<EOF > longhornpvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: longhorn-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 50Mi
EOF
# 创建pod
[root@master01 longhorn]# cat <<EOF > longhornpod.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: longhorn-pod
namespace: default
spec:
containers:
- name: volume-test
image: nginx:stable-alpine
imagePullPolicy: IfNotPresent
volumeMounts:
- name: volv
mountPath: /usr/share/nginx/html
ports:
- containerPort: 80
volumes:
- name: volv
persistentVolumeClaim:
claimName: longhorn-pvc
EOF
#创建对象
[root@master01 longhorn]# kubectl apply -f longhornpvc.yaml -f longhornpod.yaml
persistentvolumeclaim/longhorn-pvc created
pod/longhorn-pod created
# 查看Pod信息
[root@master01 longhorn]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
longhorn-pod 1/1 Running 0 34s 10.244.140.85 node02 <none> <none>
# 查看PVC信息
[root@master01 longhorn]# kubectl get pvc -o wide
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE VOLUMEMODE
longhorn-pvc Bound pvc-6977b388-6924-4070-84de-03ecf531a899 50Mi RWO longhorn <unset> 93s Filesystem
# 查看PV信息
[root@master01 longhorn]# kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE VOLUMEMODE
pvc-6977b388-6924-4070-84de-03ecf531a899 50Mi RWO Delete Bound default/longhorn-pvc longhorn <unset> 105s Filesystem
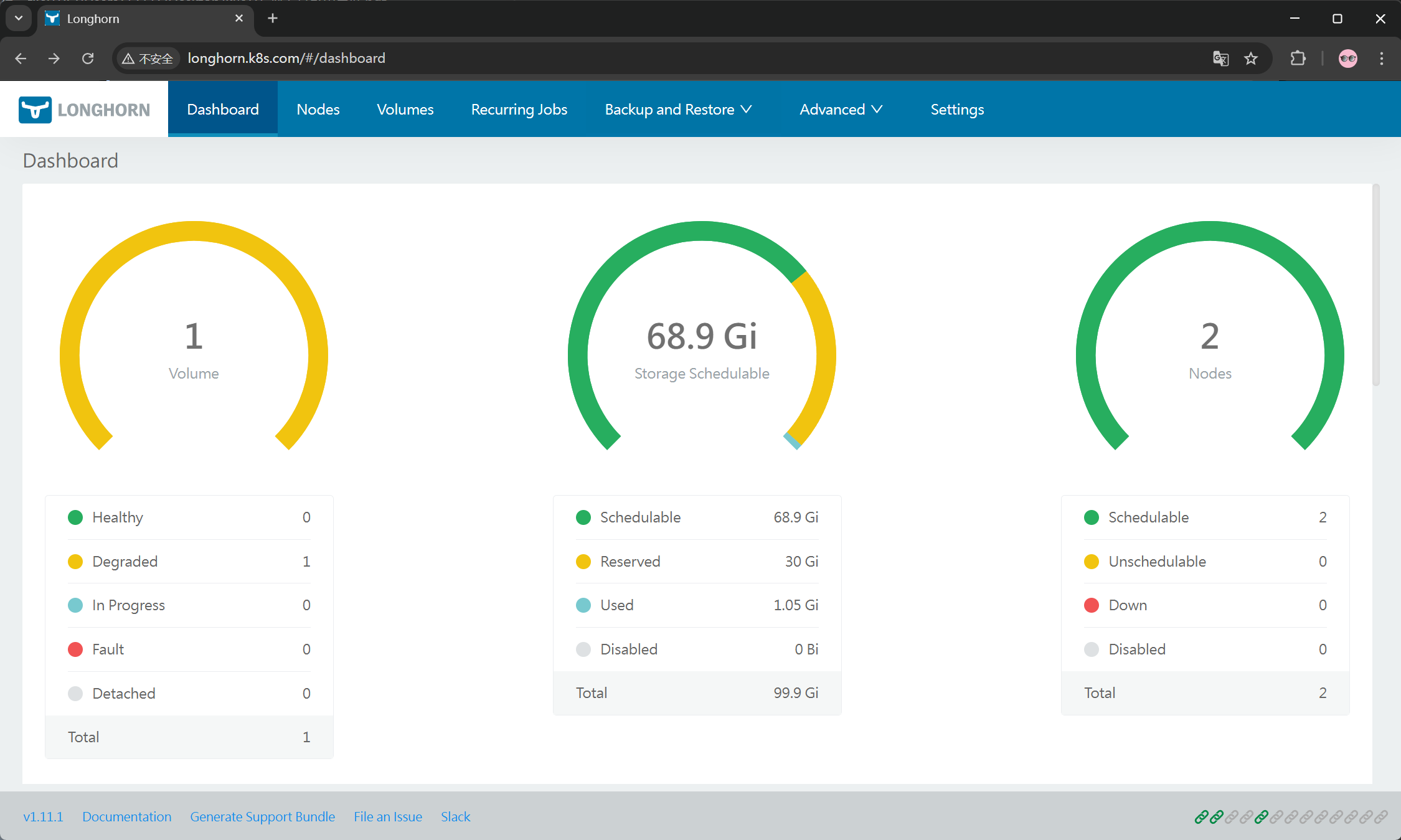
14.11 确认与验证
windows配置本地解析
浏览器访问:longhorn.k8s.com ,并输入设置的账号和密码登录查看
15.部署kube-Prometheus
15.1 介绍
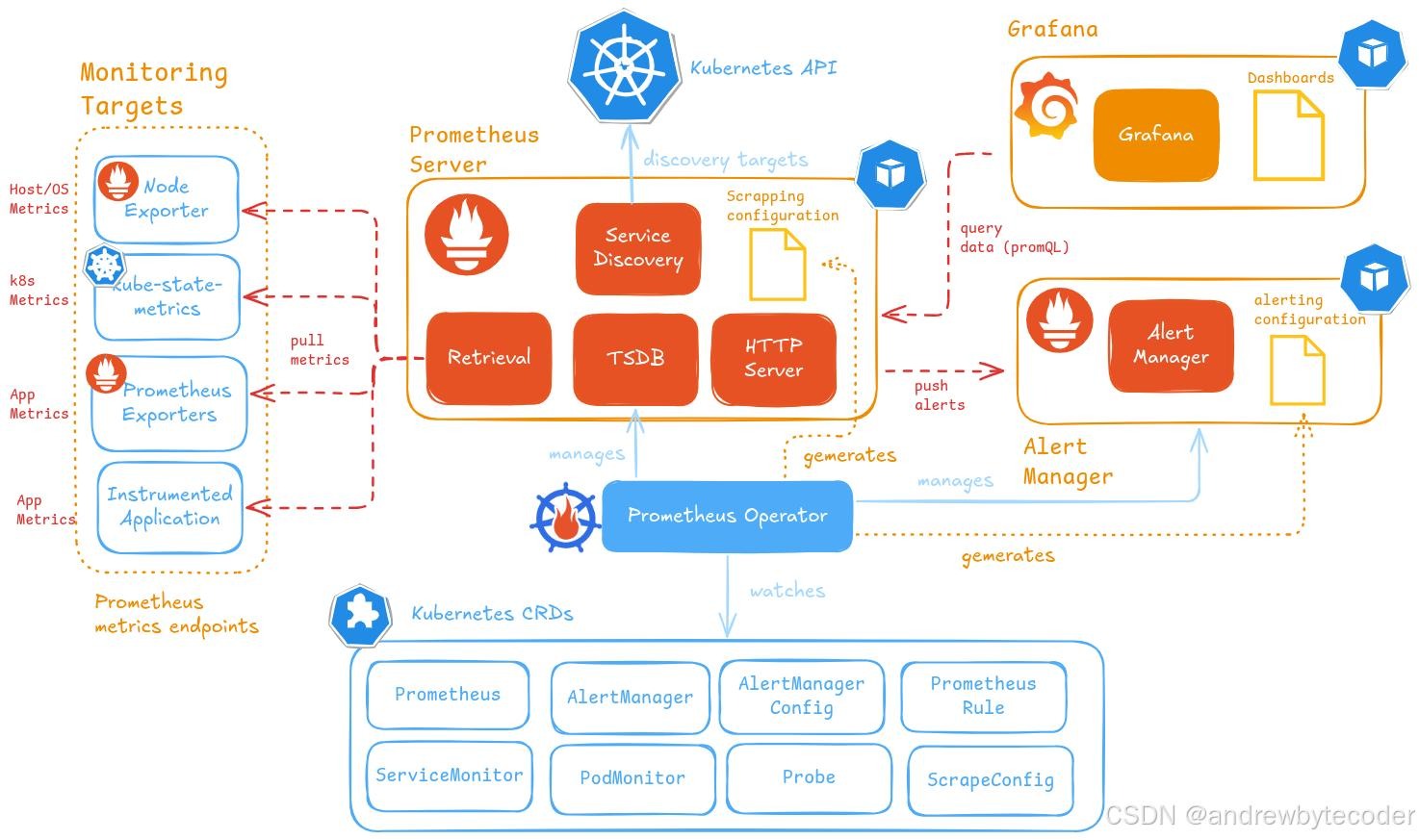
kube-Prometheus 是一个全面集成的 Kubernetes 集群监控解决方案,它将核心的 Prometheus 组件、 Grafana 可视化面板以及 Prometheus 规则等资源精心编排并集成为一个易于部署和管理的整体。该项 目通过 GitHub 仓库提供了详尽的 Kubernetes 清单文件、Grafana 仪表板配置和 Prometheus 规则, 辅以详细的文档和脚本,使得在 Kubernetes 集群中利用 Prometheus 进行端到端的监控变得异常便捷 高效。更进一步,kube-Prometheus 不仅引入了 Prometheus Operator 模式,还在此基础上进行了增 强与拓展,因此可以将其理解为一个经过优化且充分利用 operator 机制的高级 Prometheus 部署方案。
后续专门出一篇关于Prometheus的日志方案来对其进行介绍这里先了解是什么东西进行部署
15.2 获取资源
Github资源地址:https://github.com/prometheus-operator/kube-prometheus
# 安装git工具
[root@master01 ~]# dnf install git -y
#拉取资源
[root@master01 ~]# git clone https://github.com/prometheus-operator/kube-prometheus.git
Cloning into 'kube-prometheus'...
remote: Enumerating objects: 22692, done.
remote: Counting objects: 100% (203/203), done.
remote: Compressing objects: 100% (105/105), done.
remote: Total 22692 (delta 159), reused 104 (delta 95), pack-reused 22489 (from 2)
Receiving objects: 100% (22692/22692), 15.75 MiB | 5.44 MiB/s, done.
Resolving deltas: 100% (15913/15913), done.
[root@master01 ~]# ls
kube-prometheus
[root@master01 ~]# cd kube-prometheus/
15.3 拉取镜像
由于Prometheus所需镜像仓库国外,先提前拉取到本地然后上传到本地harbor仓库
# 查看manifests部署所需镜像
[root@master01 kube-prometheus]# grep -rn "image:" manifests/ | awk '{print $3}' | grep -v ^$ | sort | uniq > images.list
[root@master01 kube-prometheus]# cat images.list
ghcr.io/jimmidyson/configmap-reload:v0.15.0
grafana/grafana:12.4.2
quay.io/brancz/kube-rbac-proxy:v0.21.2
quay.io/prometheus-operator/prometheus-operator:v0.90.1
quay.io/prometheus/alertmanager:v0.31.1
quay.io/prometheus/blackbox-exporter:v0.28.0
quay.io/prometheus/node-exporter:v1.10.2
quay.io/prometheus/prometheus:v3.10.0
registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.18.0
registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.12.0
# 批量拉取
cat images.list | xargs -L 1 docker pull
在harbor上创建对应项目
#给镜像打标签并推送到harbor
[root@master01 kube-prometheus]# cat images.list | awk -F "/" '/prometheus/{system("docker tag "$0" reg.harbor.org/prometheus/"$3)}'
[root@master01 kube-prometheus]# docker images --format "{{.Repository}}:{{.Tag}}" | awk -F "/" '/harbor/{system("docker push "$0)}'
[root@master01 kube-prometheus]# docker tag quay.io/prometheus-operator/prometheus-operator:v0.90.1 reg.harbor.org/prometheus-operator/prometheus-operator:v0.90.1
[root@master01 kube-prometheus]# docker tag quay.io/brancz/kube-rbac-proxy:v0.21.2 reg.harbor.org/brancz/kube-rbac-proxy:v0.21.2
[root@master01 kube-prometheus]# docker tag ghcr.io/jimmidyson/configmap-reload:v0.15.0 reg.harbor.org/jimmidyson/configmap-reload:v0.15.0
[root@master01 kube-prometheus]# docker tag registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.18.0 reg.harbor.org/brancz/kube-rbac-proxy:v0.21.2
[root@master01 kube-prometheus]# docker tag registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.12.0 reg.harbor.org/prometheus-adapter/prometheus-adapter:v0.12.0
[root@master01 kube-prometheus]# docker tag grafana/grafana:12.4.2 reg.harbor.org/grafana/grafana:12.4.2
[root@master01 kube-prometheus]# docker push reg.harbor.org/prometheus-operator/prometheus-operator:v0.90.1
[root@master01 kube-prometheus]# docker push reg.harbor.org/brancz/kube-rbac-proxy:v0.21.2
[root@master01 kube-prometheus]# docker push reg.harbor.org/brancz/kube-rbac-proxy:v0.21.2
[root@master01 kube-prometheus]# docker push reg.harbor.org/brancz/kube-rbac-proxy:v0.21.2
[root@master01 kube-prometheus]# docker push reg.harbor.org/prometheus-adapter/prometheus-adapter:v0.12.0
[root@master01 kube-prometheus]# docker push reg.harbor.org/grafana/grafana:12.4.2
15.4 更改镜像地址
# 替换 quay.io
[root@master01 kube-prometheus]# grep -rl 'quay.io/' manifests/ | xargs sed -i 's|quay.io/|reg.harbor.org/|g'
# 替换 registry.k8s.io
[root@master01 kube-prometheus]# grep -rl 'registry.k8s.io/' manifests/ | xargs sed -i 's|registry.k8s.io/|reg.harbor.org/|g'
# 替换 ghcr.io
[root@master01 kube-prometheus]# grep -rl 'ghcr.io/' manifests/ | xargs sed -i 's|ghcr.io/|reg.harbor.org/|g'
# 替换 grafana/grafana
[root@master01 kube-prometheus]# grep -rl 'grafana/grafana' manifests/ | xargs sed -i 's|grafana/grafana|reg.harbor.org/grafana/grafana|g'
# 验证是否更改成功
[root@master01 kube-prometheus]# grep -rn "image:" manifests/ | awk '{print $3}' | grep -v ^$ | sort | uniq > images2.list
# 跟拉取镜像显示的数量一样切仓库名称变为了本地仓库地址
[root@master01 kube-prometheus]# cat images2.list
reg.harbor.org/brancz/kube-rbac-proxy:v0.21.2
reg.harbor.org/grafana/grafana:12.4.2
reg.harbor.org/jimmidyson/configmap-reload:v0.15.0
reg.harbor.org/kube-state-metrics/kube-state-metrics:v2.18.0
reg.harbor.org/prometheus-adapter/prometheus-adapter:v0.12.0
reg.harbor.org/prometheus-operator/prometheus-operator:v0.90.1
reg.harbor.org/prometheus/alertmanager:v0.31.1
reg.harbor.org/prometheus/blackbox-exporter:v0.28.0
reg.harbor.org/prometheus/node-exporter:v1.10.2
reg.harbor.org/prometheus/prometheus:v3.10.0
15.5 创建Prometheus持久卷
prometheus 默认是通过 emptyDir 进行挂载的,emptyDir 挂载的数据的生命周期和 Pod 生命周期一致 的,为了实现数据持久化,本方案建议提前生成持久卷。
prometheus 是一种 StatefulSet 有状态集的部署模式,可直接将 StorageClass 配置到如下 yaml 中
查看部署好的存储类:
[root@master01 kube-prometheus]# cd manifests/
[root@master01 manifests]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
longhorn (default) driver.longhorn.io Delete Immediate true 19h
longhorn-static driver.longhorn.io Delete Immediate true 19h
longhorn-test driver.longhorn.io Delete Immediate true 19h
编辑yaml文件:
[root@master01 manifests]# vim prometheus-prometheus.yaml
#在文件最后增加如下配置
.....
storage:
volumeClaimTemplate:
spec:
storageClassName: longhorn
resources:
requests:
storage: 1Gi
15.6 创建grafana持久卷
Grafana 是部署模式为 Deployment,所以我们提前为其创建一个 grafana-pvc.yaml 文件
创建PVC文件:
[root@master01 manifests]# vim grafana-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-storage
namespace: monitoring
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 1Gi
接着修改grafana-deployment.yaml 文件:
[root@master01 manifests]# vim grafana-deployment.yaml
......
57 volumeMounts:
58 - mountPath: /var/lib/grafana
59 name: grafana-storage
60 readOnly: false
......
177 volumes:
178 - name: grafana-storage
179 persistentVolumeClaim: # 修改为预创建的PVC
180 claimName: grafana-storage
......
15.7 修改暴露端口
首先修改 alertmanager-service.yaml 配置文件,将服务暴露到指定端口上:
[root@master01 manifests]# vim alertmanager-service.yaml
......
spec:
type: NodePort # 暴露SVC模式为 NodePort
ports:
- name: web
port: 9093
targetPort: web
nodePort: 30010 # 指定nodePort
......
然后再修改 grafana-service.yaml 服务配置文件:
[root@master01 manifests]# vim grafana-service.yaml
......
spec:
type: NodePort
ports:
- name: http
port: 3000
targetPort: http
nodePort: 30011
......
最后再修改 prometheus-service.yaml 服务配置文件:
[root@master01 manifests]# vim prometheus-service.yaml
......
spec:
type: NodePort
ports:
- name: web
port: 9090
targetPort: web
nodePort: 30012
......
15.8 部署operator
首先执行如下命令创建 monitoring 命名空间和 CRD 模板:
[root@master01 manifests]# kubectl apply --server-side -f ./setup/
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/prometheusagents.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/scrapeconfigs.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com serverside-applied
namespace/monitoring serverside-applied
**执行命令等待所有 CRD 完全就绪: **
[root@master01 manifests]# kubectl wait \
--for condition=Established \
--all CustomResourceDefinition \
--namespace=monitoring
然后再安装
[root@master01 manifests]# kubectl apply -f .
[!TIP]
如上操作会创建monitoring 的命名空间,以及相关的 Prometheus Operator 控制器。
创建 Operator 后,可以创建自定义资源清单(CRD),若需要自定义资源对象生效就需要安装对应的 Operator 控制器,因此如上创建operator 需要在创建 CRD 之前。
15.9 确认验证
[root@master01 manifests]# kubectl -n monitoring get all
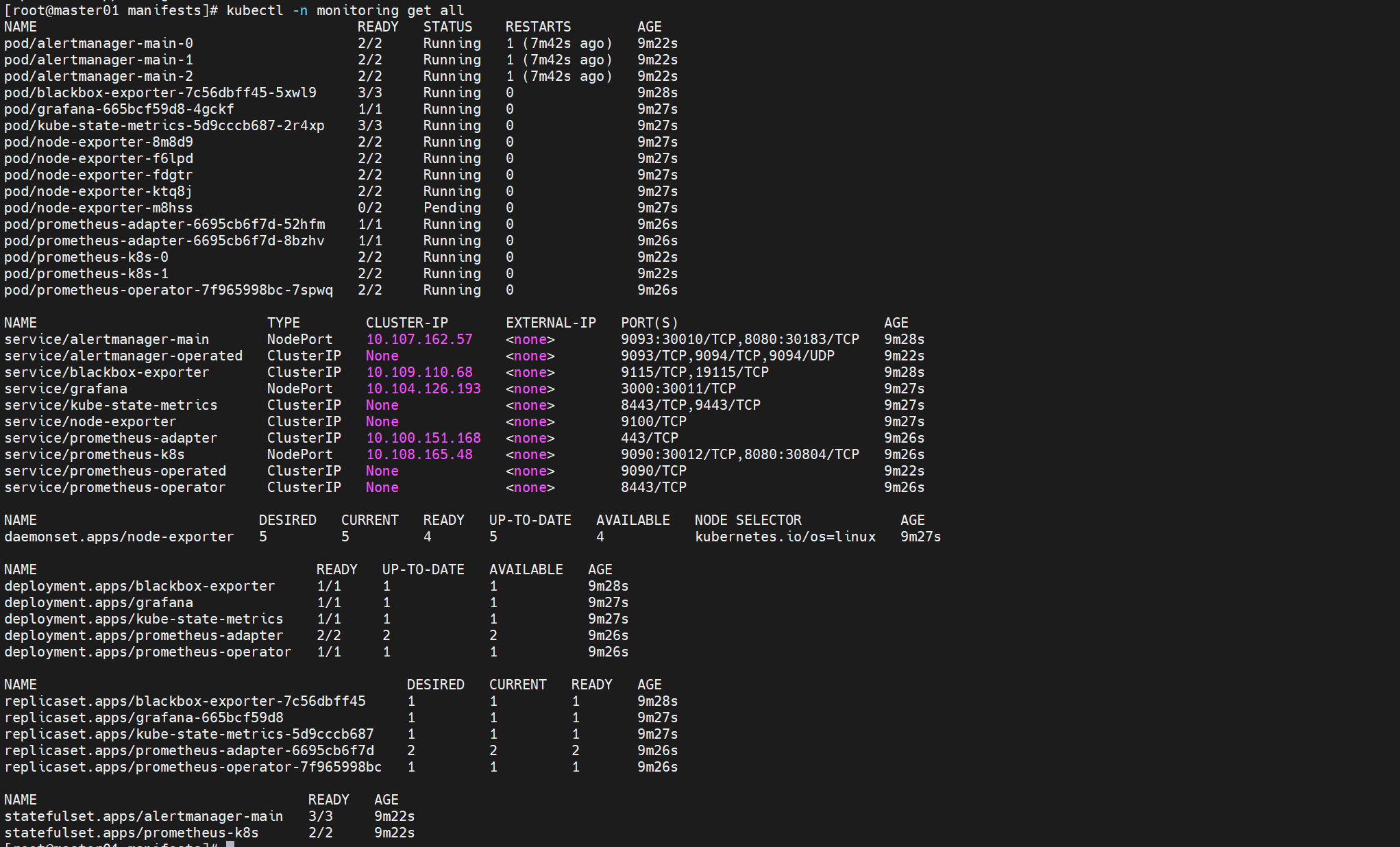
由于只允许同命名空间、同组件内部访问,拒绝外部 / Ingress/HAProxy 的流量!
所以若要使用端口或者ingress访问,由于 kube-Prometheus 默认会创建 networkpolicy,因此在不适用规则的情况下, 可删除相应的策略。
[root@master01 manifests]# kubectl delete -f alertmanager-networkPolicy.yaml
[root@master01 manifests]# kubectl delete -f grafana-networkPolicy.yaml
[root@master01 manifests]# kubectl delete -f prometheus-networkPolicy.yaml
删除成功后就可以访问 alertmanager-main,http://172.25.254.101:30010/ 。
访问grafana,http://172.25.254.101:30011/ ,默认用户名密码都为admin,登录成功后,可将密码修改 为 admin123。
更改密码
访问 prometheus-k8s,http://172.25.254.101:30012/ 。
15.10 ingress暴露alertmanager
首先,在 manifests 目录下创建 alertmanager-ingress.yaml 配置文件:
[root@master01 manifests]# vim alertmanager-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: alertmanager-ingress
namespace: monitoring
labels:
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: alertmanager
spec:
ingressClassName: "nginx"
rules:
- host: alertmanager.k8s.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: alertmanager-main
port:
number: 9093
然后,执行如下命令创建资源对象:
[root@master01 manifests]# vim alertmanager-ingress.yaml
15.11 ingress暴露prometheus
首先,在 manifests 目录下新建 prometheus-ingress.yaml 资源清单文件:
[root@master01 manifests]# vim prometheus-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus-ingress
namespace: monitoring
labels:
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: prometheus
spec:
ingressClassName: "nginx"
rules:
- host: prometheus.k8s.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-k8s
port:
number: 9090
然后,执行如下命令来创建资源对象:
[root@master01 manifests]# kubectl apply -f prometheus-ingress.yaml
15.12 ingress暴露grafana
首先,在 manifests 目录下新建 grafana-ingress.yaml 资源清单文件:
[root@master01 manifests]# vim grafana-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: grafana-ingress
namespace: monitoring
labels:
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: grafana
spec:
ingressClassName: "nginx"
rules:
- host: grafana.k8s.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: grafana
port:
number: 3000
然后,执行如下命令创建资源对象:
[root@master01 manifests]# kubectl apply -f grafana-ingress.yaml
15.13 确认验证ingress暴露
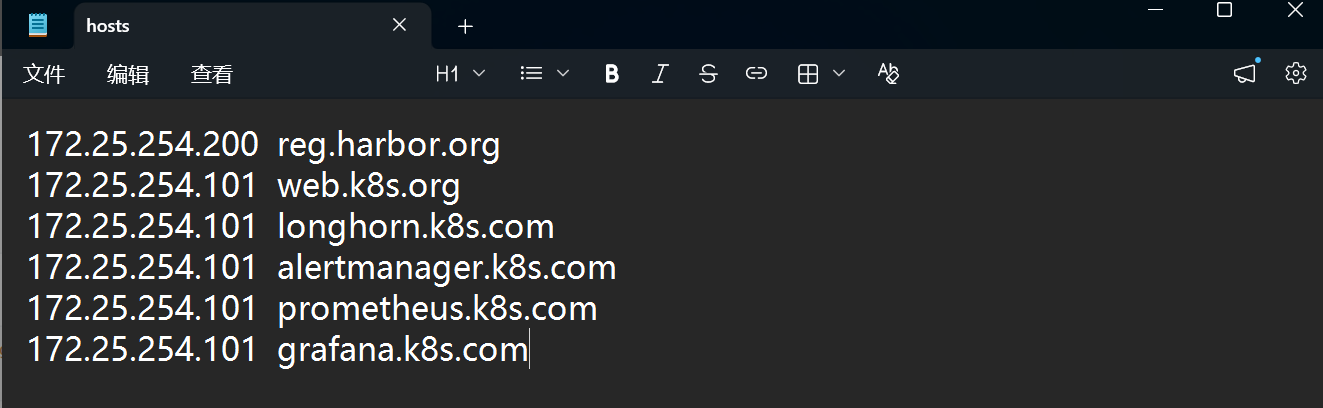
首先在windows配置好上述域名和 IP 的映射:
查看ingress资源是否被创建
[root@master01 manifests]# kubectl get ingress -n monitoring
NAME CLASS HOSTS ADDRESS PORTS AGE
alertmanager-ingress nginx alertmanager.k8s.com 172.25.254.101,172.25.254.102,172.25.254.103 80 4m42s
grafana-ingress nginx grafana.k8s.com 172.25.254.101,172.25.254.102,172.25.254.103 80 93s
prometheus-ingress nginx prometheus.k8s.com 172.25.254.101,172.25.254.102,172.25.254.103
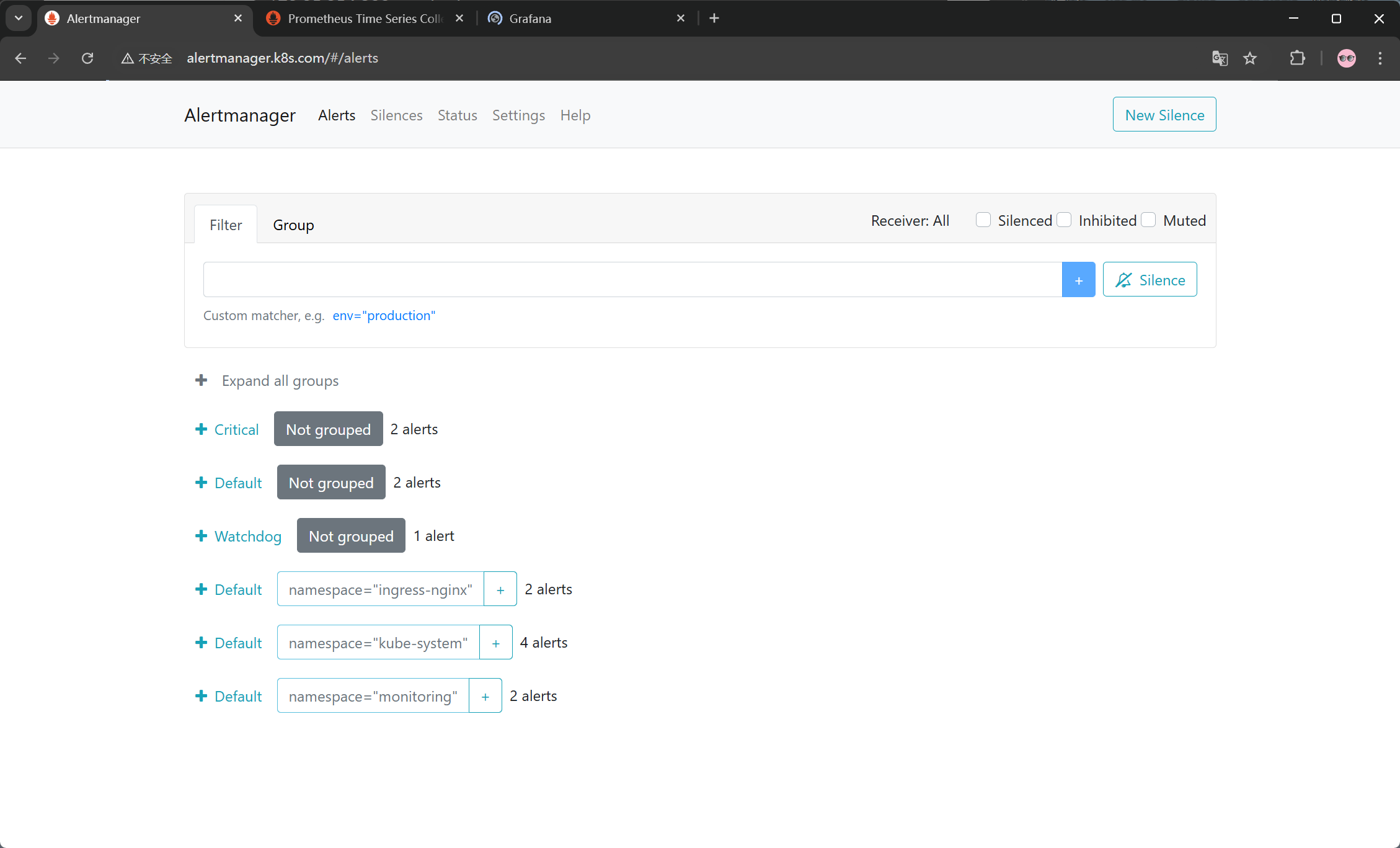
然后访问 alertmanager,http://alertmanager.k8s.com 。
再访问 prometheus,http://prometheus.k8s.com 。
最后访问 grafana,http://grafana.k8s.com 。

16.部署Loki日志方案
16.1 Loki简介
Grafana Loki 是一套功能齐全的日志堆栈组件,与其他日志记录系统不同,Loki 是基于仅索引有关日志 元数据的想法而构建的:标签 (就像 Prometheus 标签一样)。日志数据本身被压缩然后并存储在对象 存储(例如 S3 或 OSS)的块中,甚至可以存储在本地文件系统上,轻量级的索引和高度压缩的块简化了 操作,并显著降低了 Loki 的成本,Loki 更适合中小团队。由于 Loki 使用和 Prometheus 类似的标签概 念,所以如果你熟悉 Prometheus 那么将很容易上手,也可以直接和 Grafana 集成,只需要添加 Loki 数据源就可以开始查询日志数据了。
Loki 还提供了一个专门用于日志查询的 LogQL 查询语句,类似于 PromQL ,通过 LogQL 我们可以很容 易查询到需要的日志,也可以很轻松获取监控指标。Loki 还能够将 LogQL 查询直接转换为 Prometheus 指标。此外 Loki 允许我们定义有关 LogQL 指标的报警,并可以将它们和 Alertmanager 进行对接。
Grafana Loki 主要由 3 部分组成:
- loki : 日志记录引擎,负责存储日志和处理查询。
- Agent : 日志代理,负责收集日志并将其发送给 Loki,可以使用 Alloy 或 Promtail 。
- grafana :日志查询展示平台。
与其他日志聚合系统相比,Loki 具有下面的一些特性:
- 不对日志进行全文索引。通过存储压缩非结构化日志和仅索引元数据,Loki 操作起来会更简单,更 省成本。(LogQL)
- 通过使用与 Prometheus 相同的标签记录流对日志进行索引和分组,这使得日志的扩展和操作效率 更高。
- 特别适合储存 Kubernetes Pod 日志: 诸如 Pod 标签之类的元数据会被自动删除和编入索引。
- 受 Grafana 原生支持。
16.2 获取部署文件
添加loki与promtail的helm仓库源
[root@master01 ~]# mkdir loki
[root@master01 ~]# cd loki/
[root@master01 loki]#
helm repo add grafana https://grafana.github.io/helm-charts
"grafana" has been added to your repositories
16.3 自定义配置
由于grafana/loki 6.x 以上 = Loki 3.x = 必须用对象存储,不能用本地文件 / Longhorn,所以这里使用loki-stack直接部署loki与promtail
#查看软件版本
[root@master01 loki]# helm search repo loki-stack
NAME CHART VERSION APP VERSION DESCRIPTION
grafana/loki-stack 2.10.3 v2.9.3 Loki: like Prometheus, but for logs.
# 查看默认配置模板
[root@master01 loki]# helm show values grafana/loki-stack> defaults-values.yaml
# 自定义配置
# 单实例,无分布式,支持本地文件
loki:
enabled: true
image:
repository: reg.harbor.org/grafana/loki
tag: 2.9.10
persistence:
enabled: true
storageClassName: longhorn
size: 20Gi
config:
storage_config:
filesystem:
directory: /data/loki/chunks
schema_config:
configs:
- from: 2020-10-24
store: boltdb
object_store: filesystem
schema: v11
index:
prefix: index_
period: 24h
# 自动对接 Grafana
grafana:
enabled: false
# 日志收集器(自动部署)
promtail:
enabled: true
image:
repository: reg.harbor.org/grafana/promtail
tag: 2.9.10
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
16.4 部署与查看
正式部署:
[root@master01 loki]# helm upgrade --install loki grafana/loki-stack -n monitoring --create-namespace -f loki-stack-myvalues.yaml
Release "loki" does not exist. Installing it now.
level=WARN msg="this chart is deprecated"
NAME: loki
LAST DEPLOYED: Fri Apr 10 21:27:29 2026
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
DESCRIPTION: Install complete
NOTES:
The Loki stack has been deployed to your cluster. Loki can now be added as a datasource in Grafana.
See http://docs.grafana.org/features/datasources/loki/ for more detail.
查看部署状态:
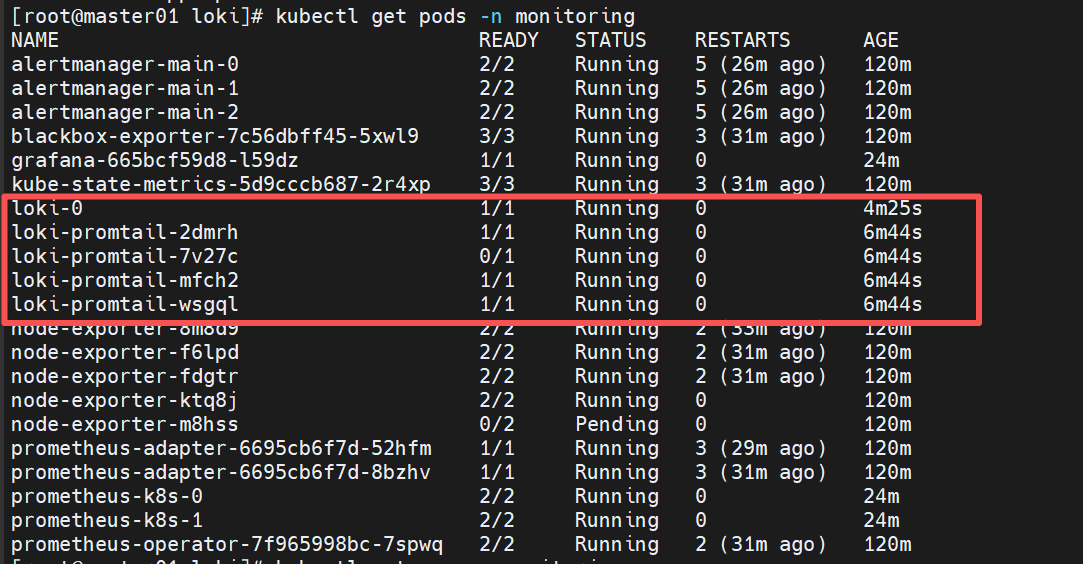
[root@master01 loki]# kubectl get pods -n monitoring
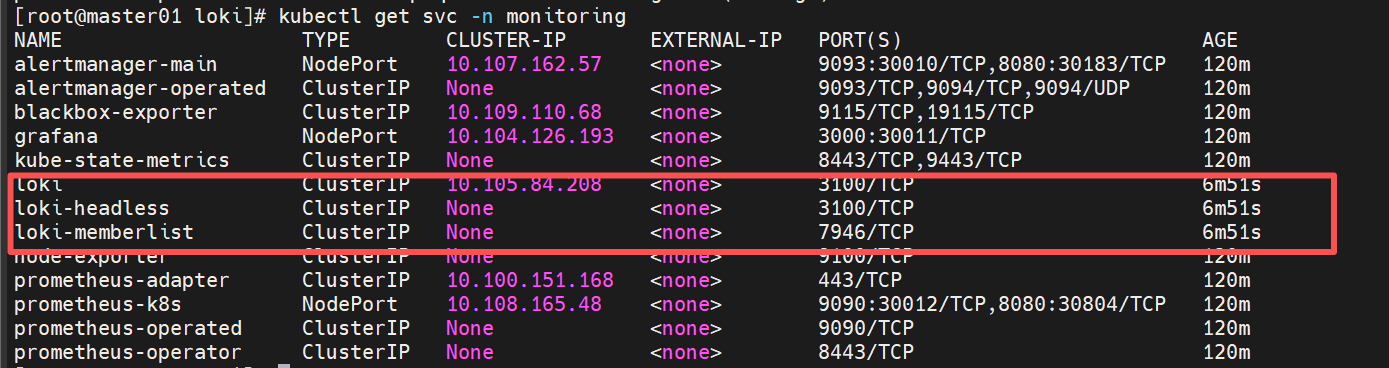
[root@master01 loki]# kubectl get svc -n monitoring
等待pod部署状态都为running
17.配置grafana
17.1 配置源数据
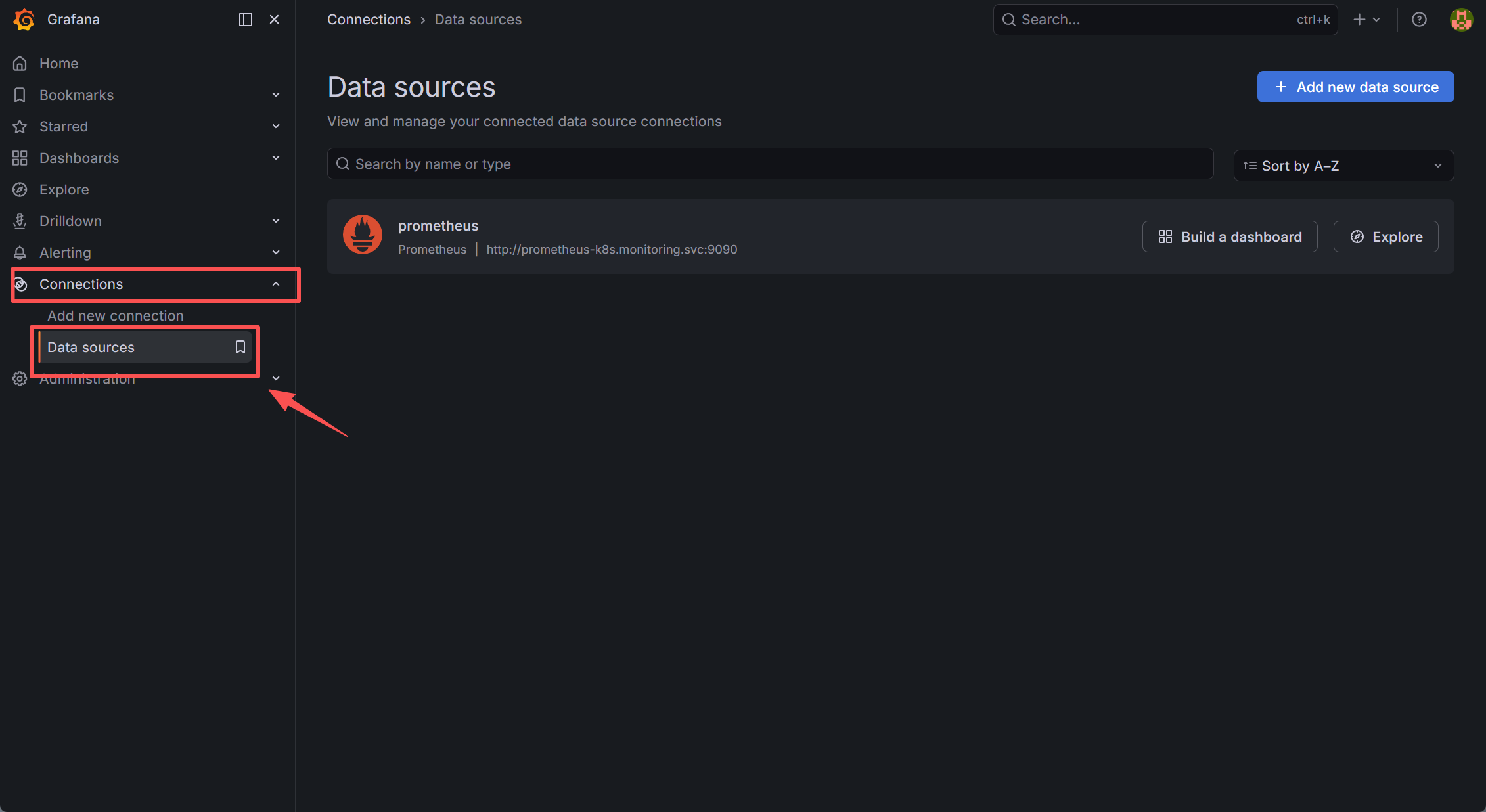
浏览器访问:http://grafana.k8s.com ,然后使用 admin/admin123 进行登录,登录成功后点击左边菜 单中 Connections,然后再点击子菜单 Data Sources,进入如下界面:
由于本案例中 grafana 是由kube-prometheus部署的,默认已经添加了 Prometheus 数据源,可以直接使用:
现在开始配置loki源数据:
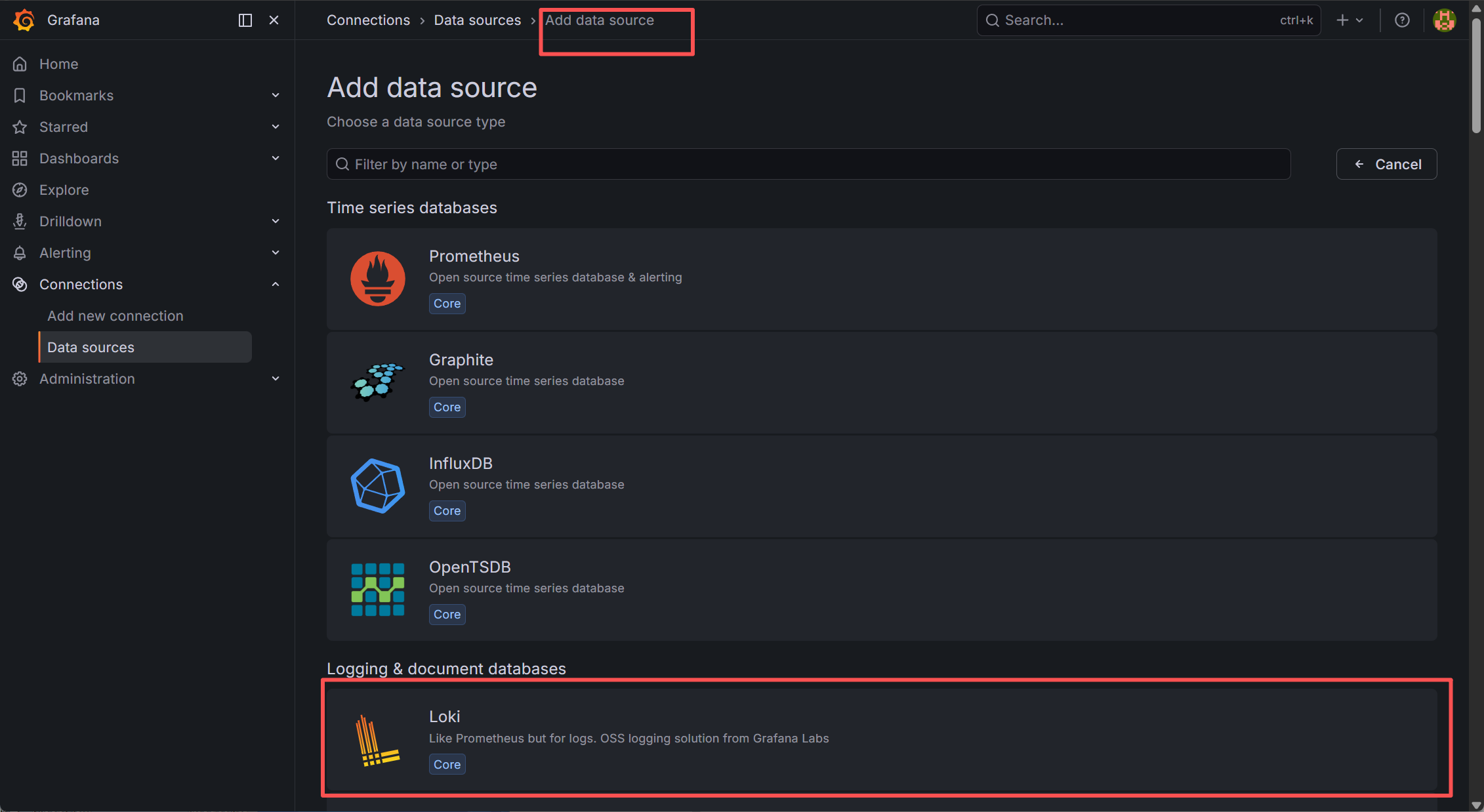
输入URL进行连接:
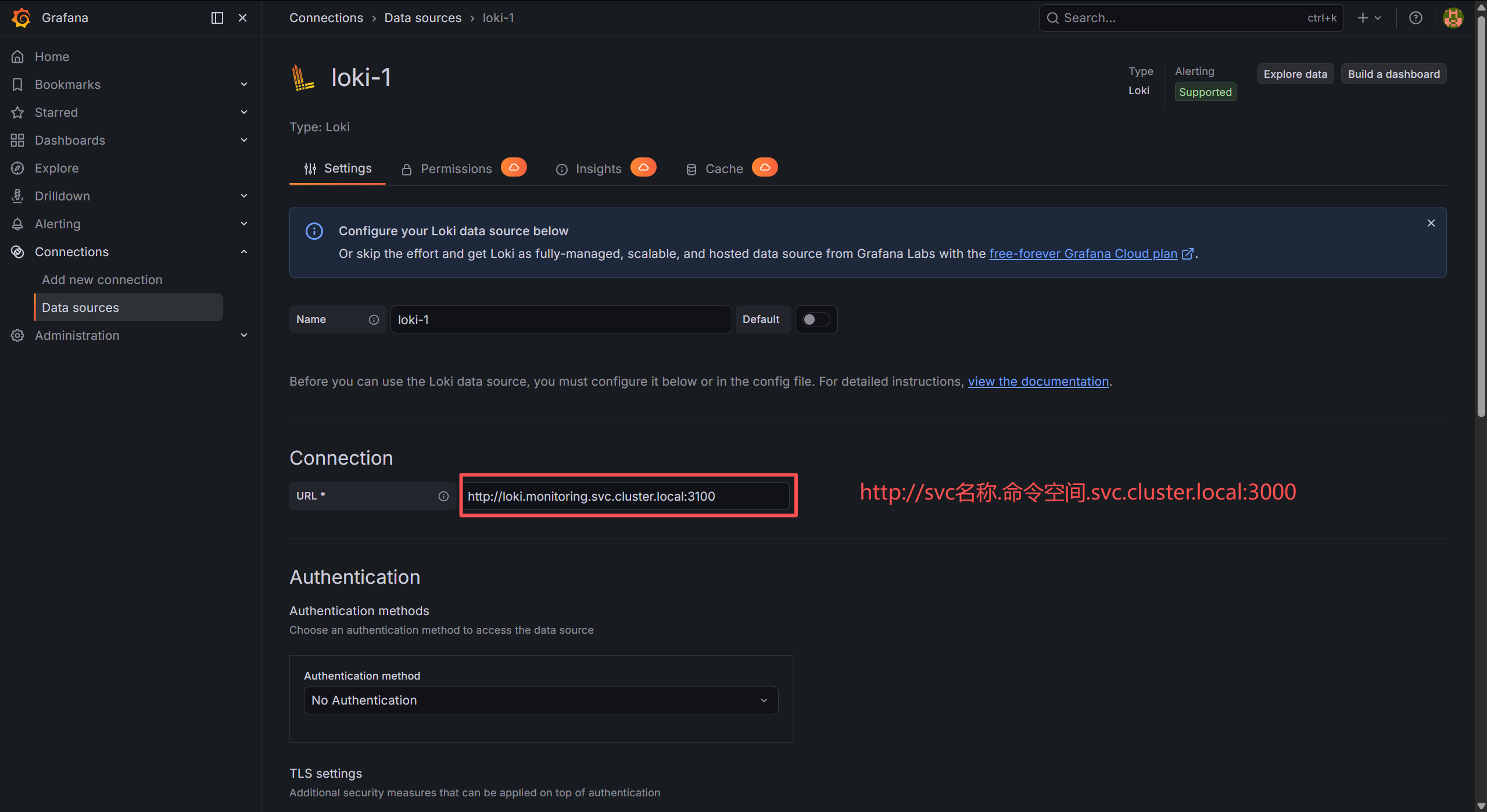
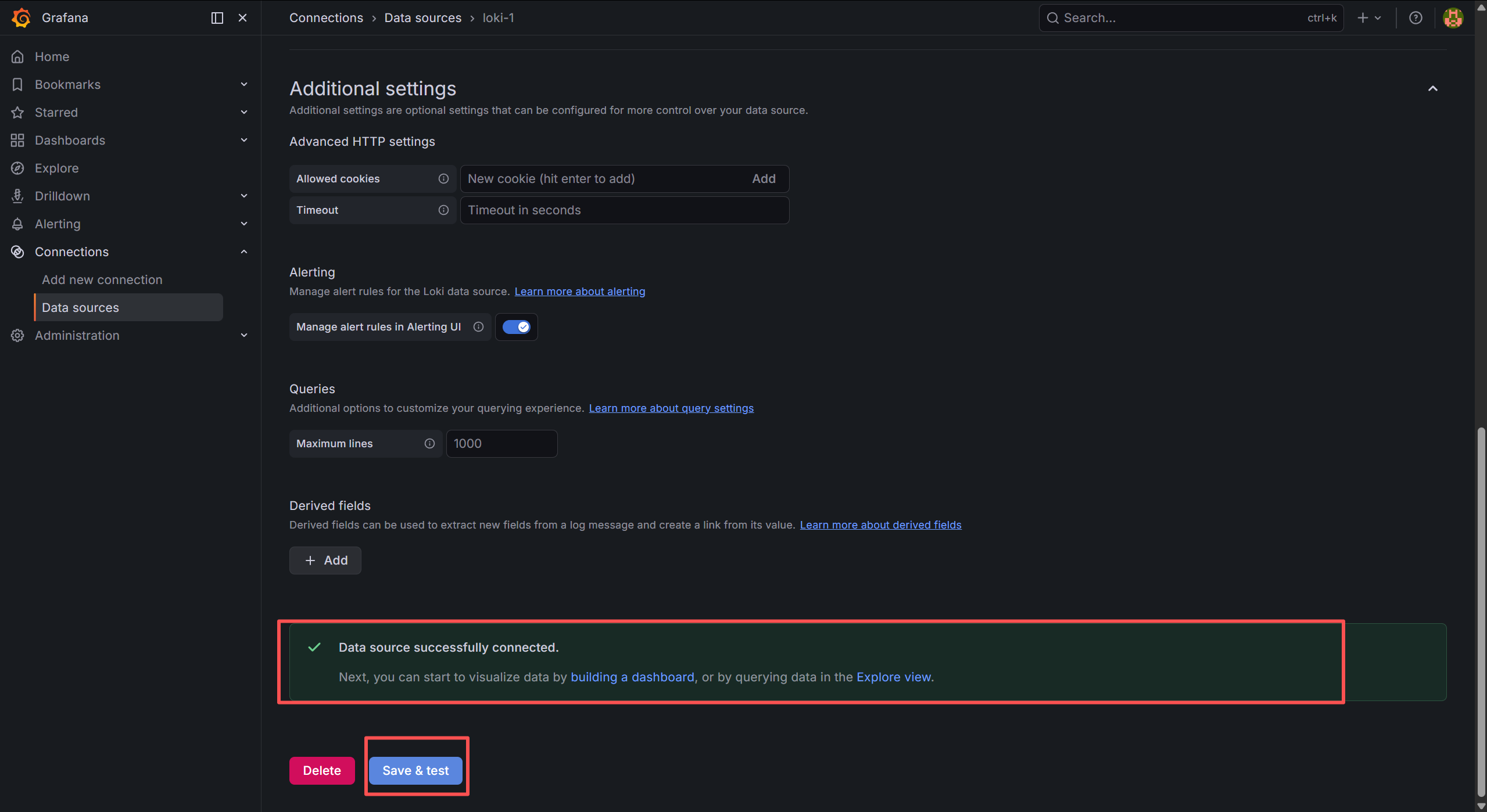
拉到最下面,点击 Save & Test 出现 Data source is working 绿色提示 → 成功!
17.2 配置grafana(添加仪表盘)
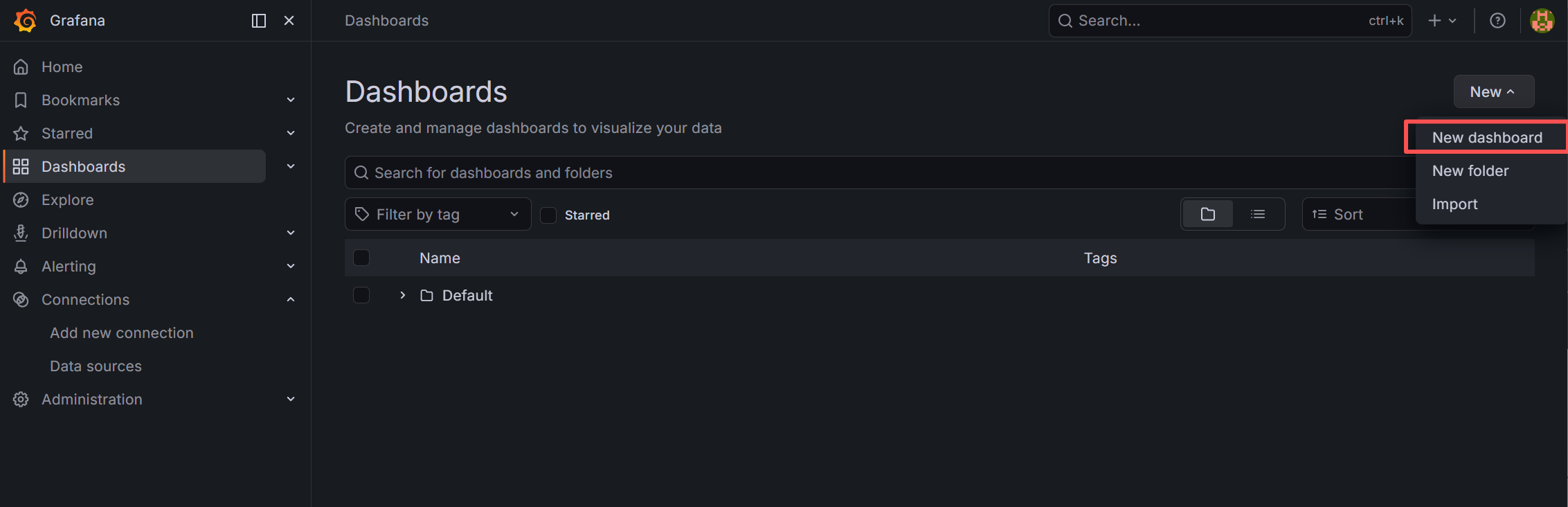
配置好数据源后,接下来配置 dashboard,首先点击左边菜单栏中的 Dashboard 菜单,然后点击 New 按钮下的 New dashboard 菜单 来新增一个 dashboard 面板,如下图所示。
点击后会打开一个新的页面,在这个页面中点击 “Import dashboard” 按钮来导入一个模板,如下图所 示:
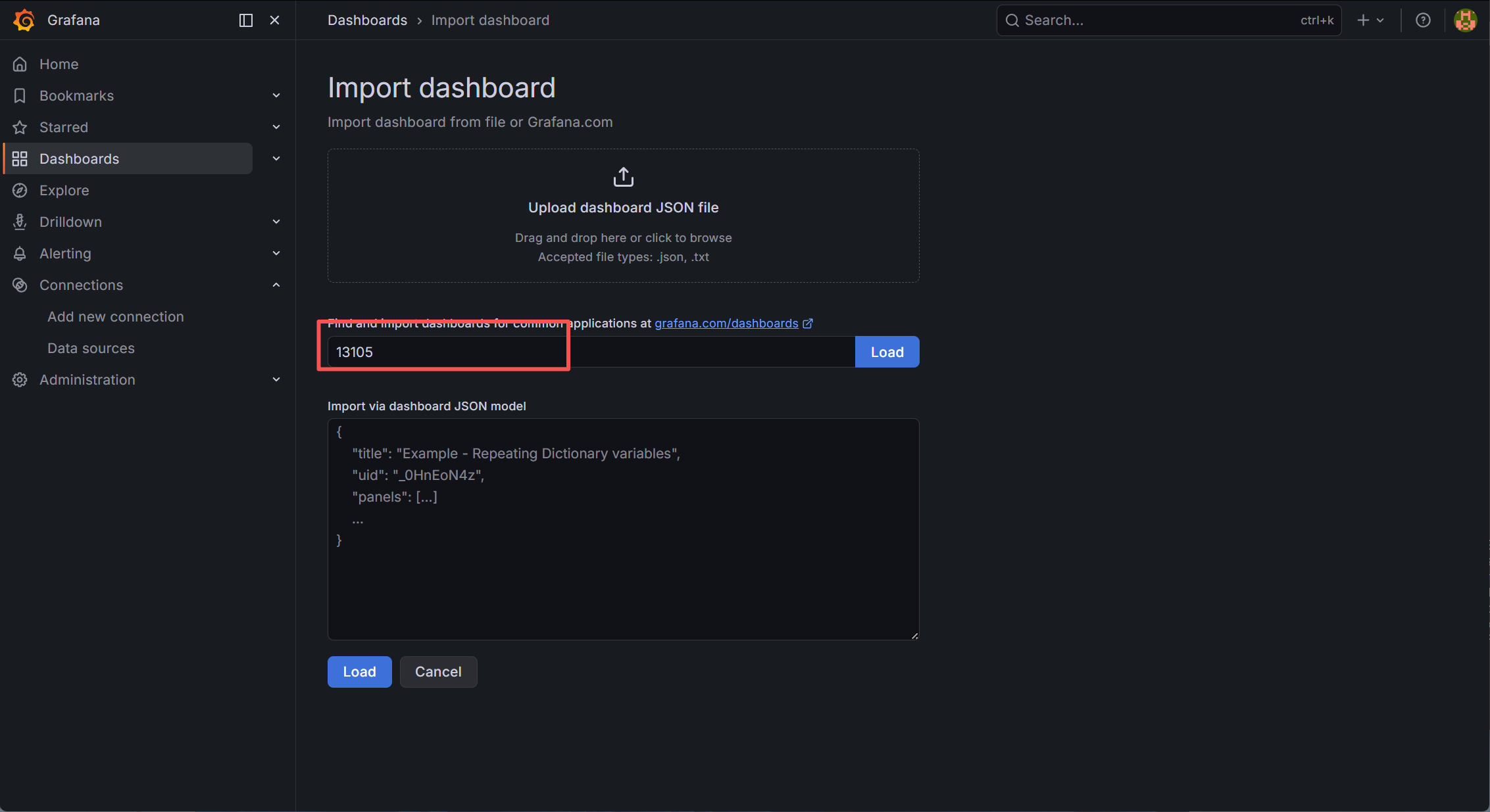
点击后,在弹出的对话框中点击 Discard 按钮后就可以进入如下界面,在界面中输入 13105 模板,此 Dashboard 模板来展示 Kubernetes 集群的监控信息,如下图所示:
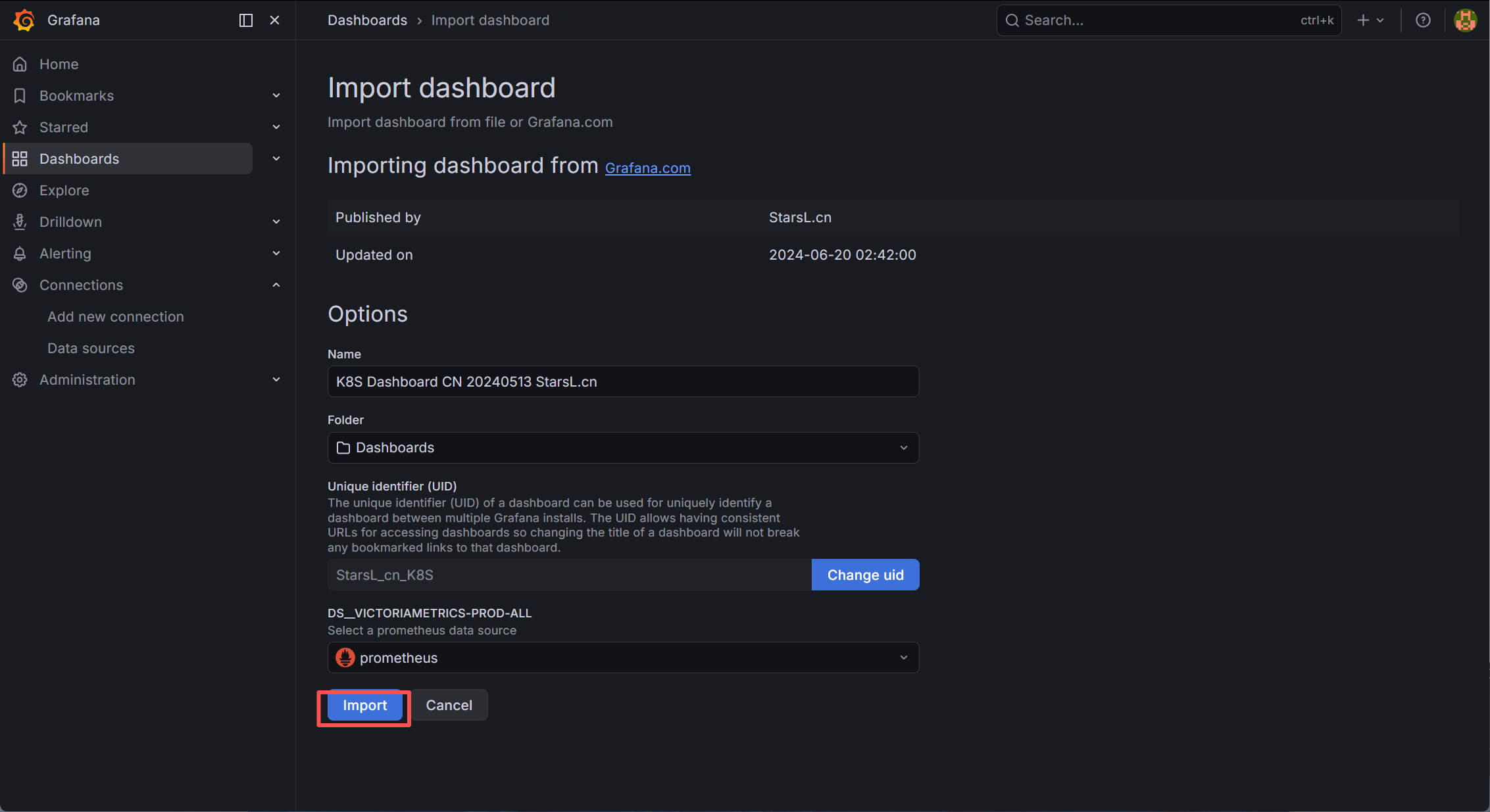
后点击 Load 按钮一会进入如下图所示界面,在这个界面中输入导入的 dashboard 名称以及使用的监控 数据源,如下图所示:
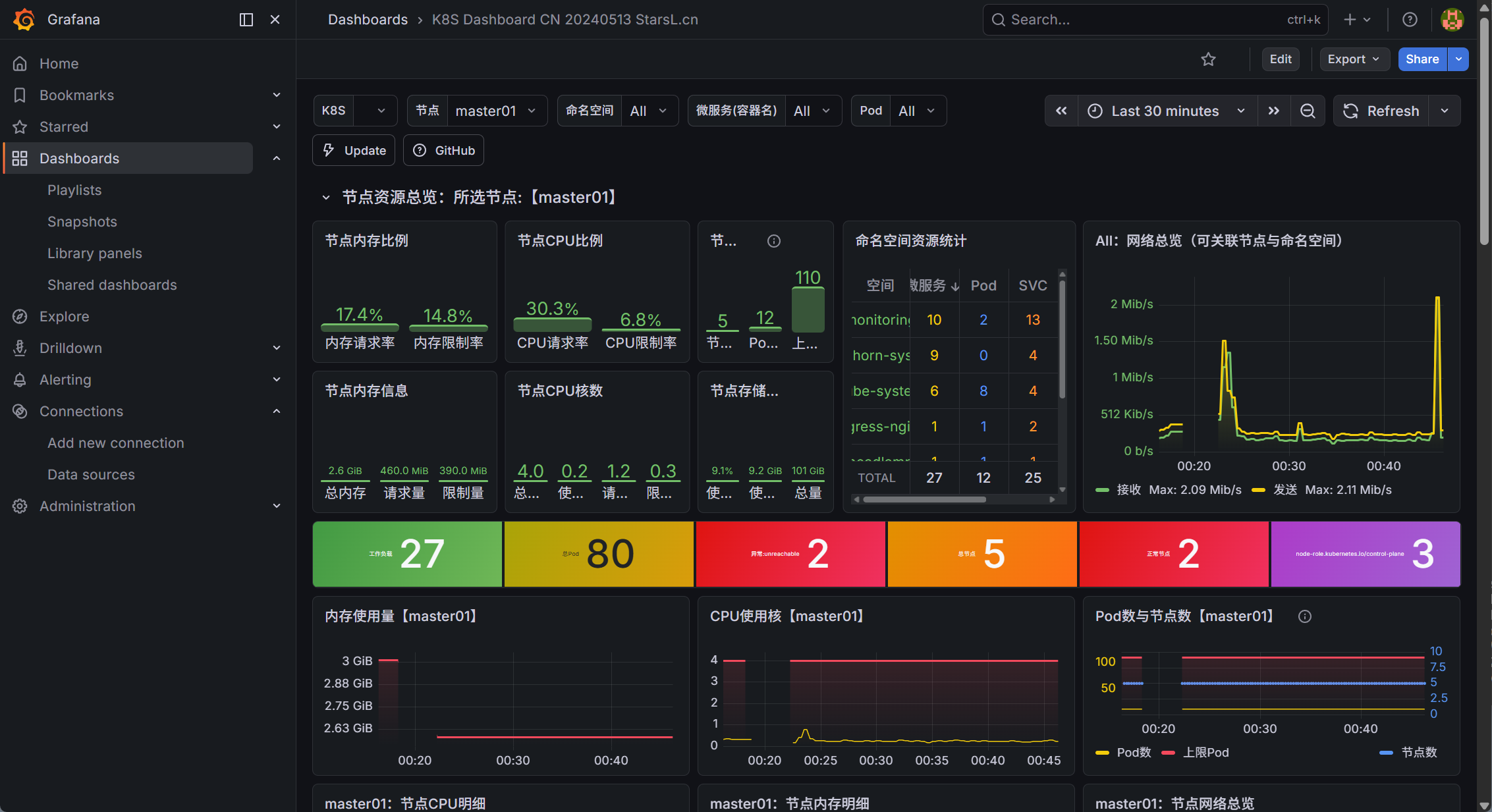
最后点击“Import”按钮导入模板,导入成功后就可以查看 Kubernetes 监控信息:
17.3 查看loki日志采集
首先
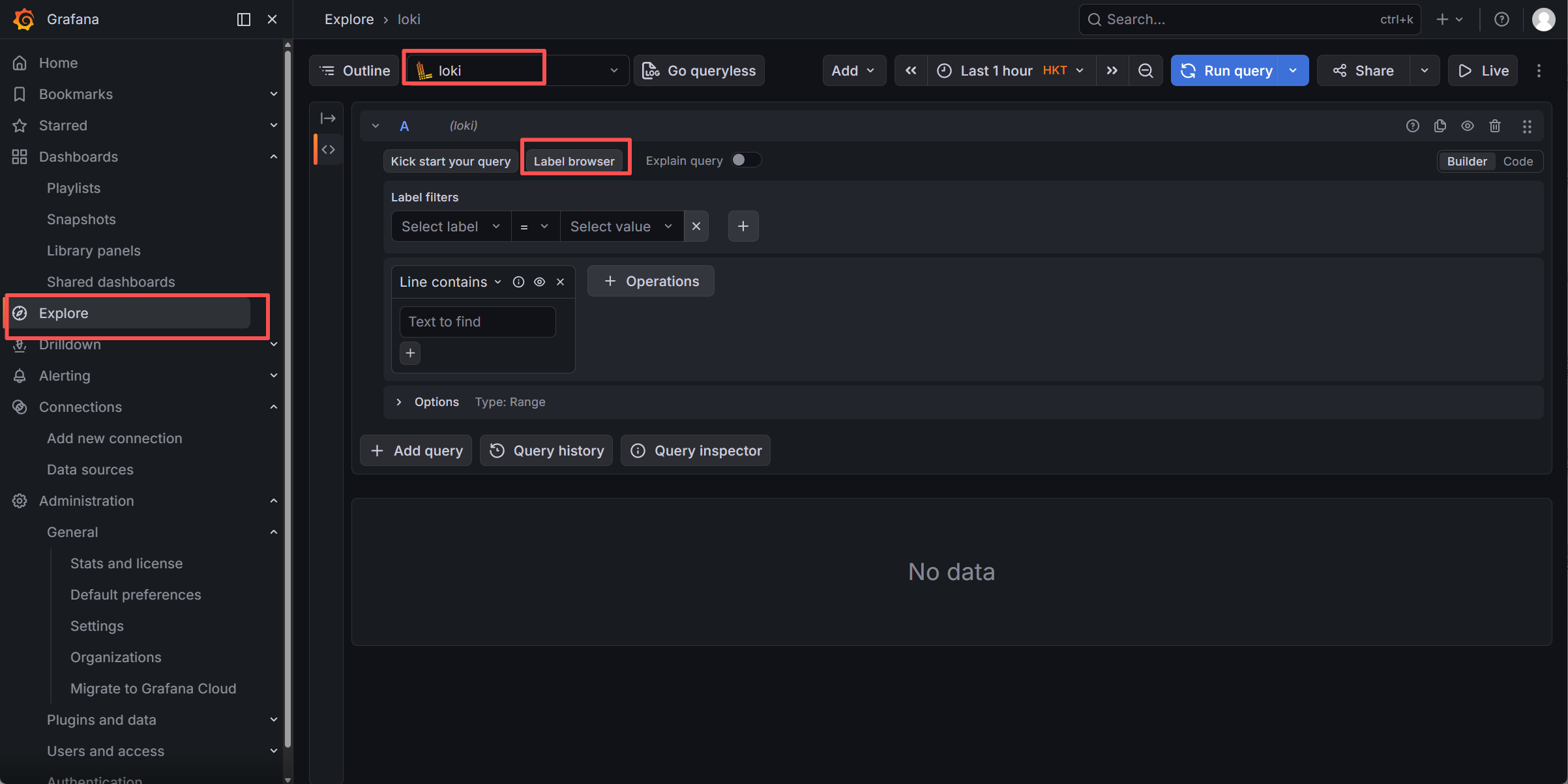
然后
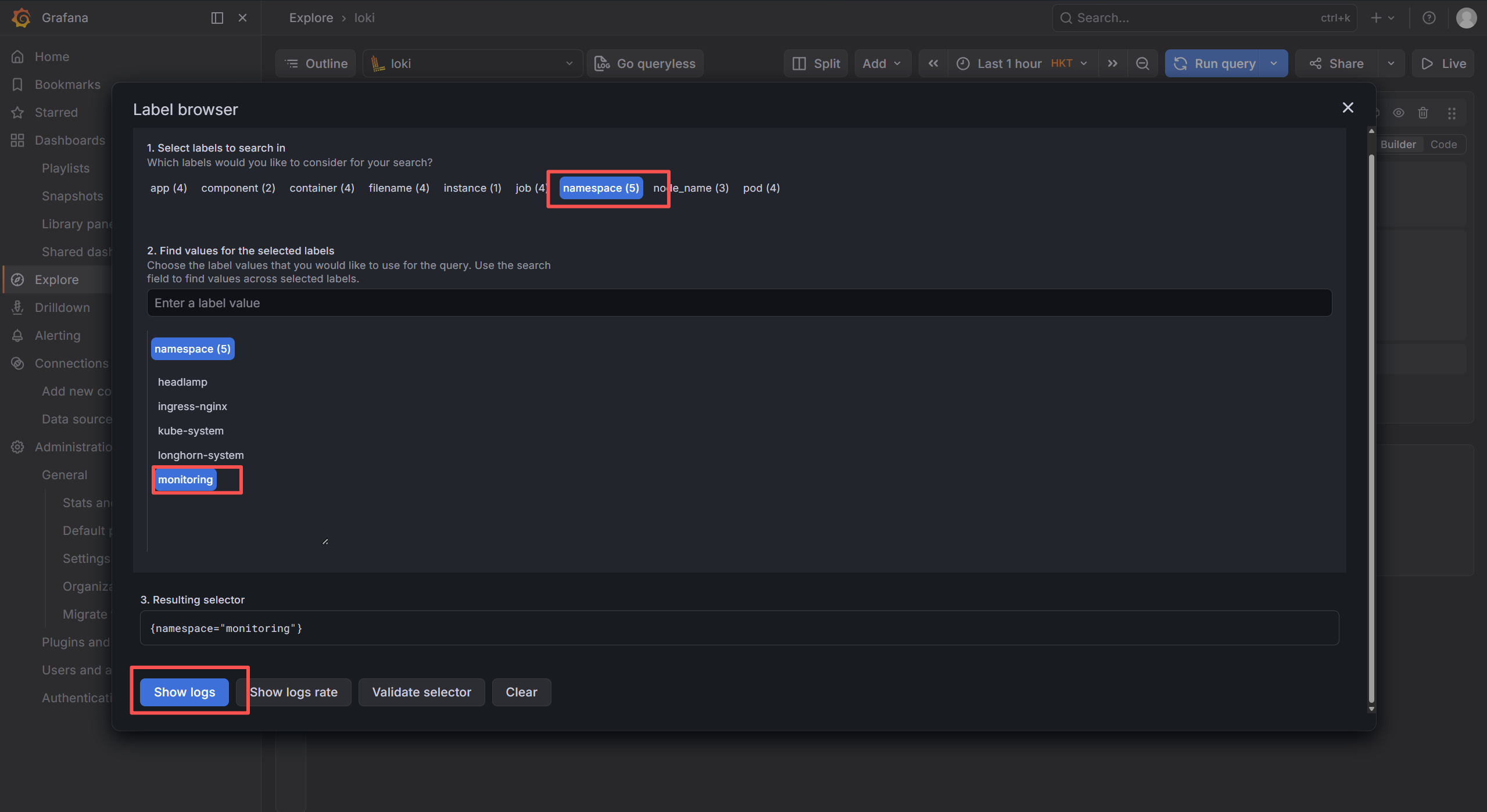
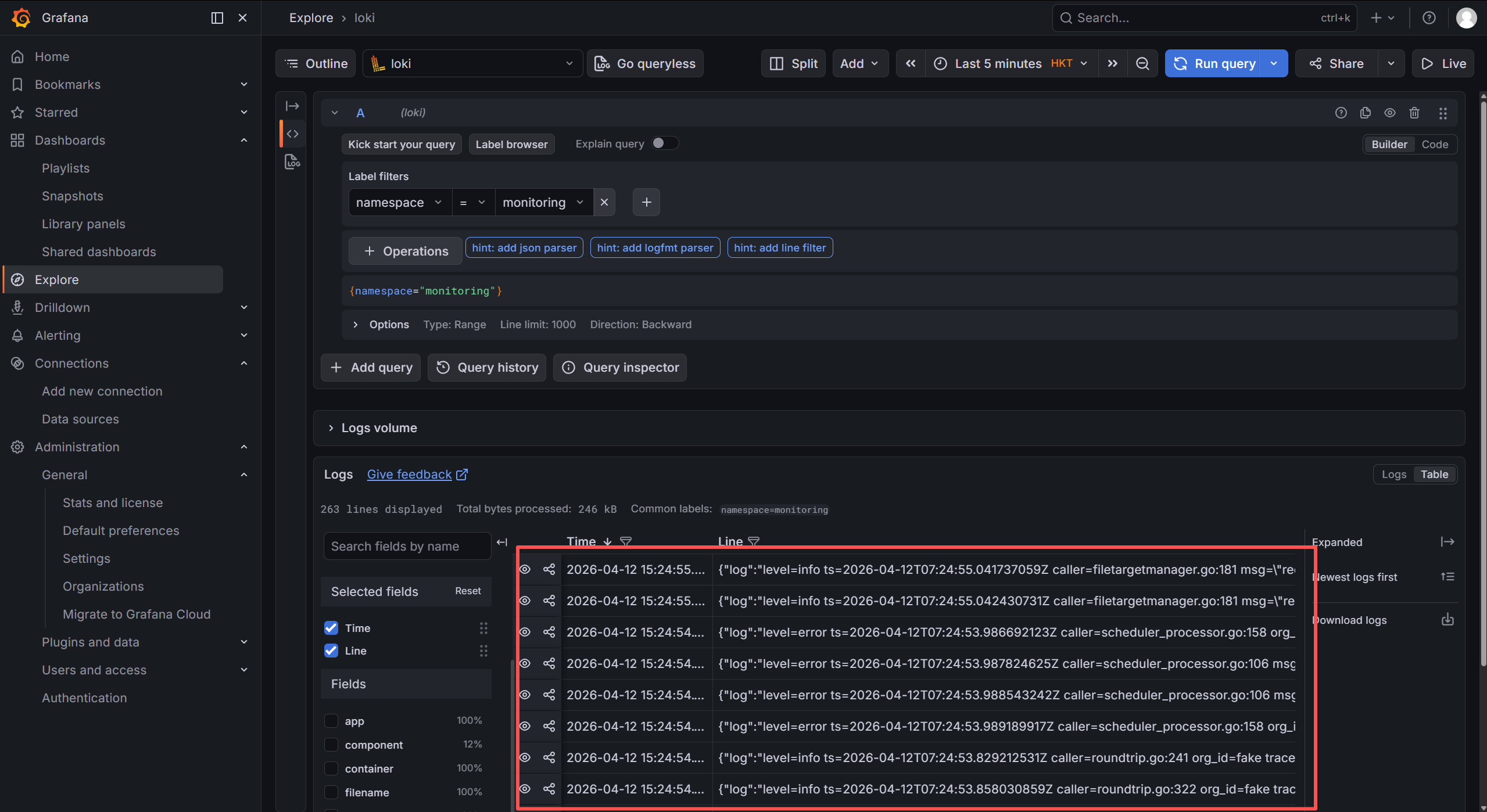
点击show logs即可查看到采集的日志
18.集群扩缩容
18.1 集群扩容
- master 节点扩容:可参考前面集群部署 Master 节点所操作的步骤
- worker 节点扩容:可参考前面集群部署 Workder 节点操作的步骤
18.2 集群缩容
- master 节点缩容:Master 节点缩容的时候会自动将 Pod 迁移至其他节点。
[root@master01 ~]# kubectl drain master03 --delete-emptydir-data --force --
ignore-daemonsets
[root@master01 ~]# kubectl delete node master03
[root@master03 ~]# kubeadm reset -f && rm -rf $HOME/.kube
worker 节点缩容:Worker节点缩容的时候会自动将Pod迁移至其他节点。
[root@master01 ~]# kubectl drain node04 --delete-emptydir-data --force --
ignore-daemonsets
[root@master01 ~]# kubectl delete node node04
[root@node04 ~]# kubeadm reset -f
[root@node04 ~]# rm -rf /etc/kubernetes/admin.conf
/etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf
/etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf
19.遇到故障排查
19.1 Longhorn挂载失败
- 问题:Longhorn 挂载失败、PVC 一直 Pending
- 原因:iscsi 没装、内核模块缺失、权限不足
- 解决:
dnf -y --setopt=tsflags=noscripts install iscsi-initiator-utils cryptsetup device-mapper
echo \"InitiatorName=$(/sbin/iscsi-iname)\" > /etc/iscsi/initiatorname.iscsi
modprobe iscsi_tcp && systemctl enable --now iscsid
cat > /etc/modules-load.d/iscsi.conf <<EOF
iscsi_tcp
EOF
19.2 kube-Prometheus访问拦截
- 问题:Grafana/AlertManager/Prometheus 502/504 网关超时
- 原因:kube-Prometheus一键部署默认会有NetworkPolicy 拦截流量
- 解决:
[root@master01 manifests]# kubectl delete -f alertmanager-networkPolicy.yaml
[root@master01 manifests]# kubectl delete -f grafana-networkPolicy.yaml
[root@master01 manifests]# kubectl delete -f prometheus-networkPolicy.yaml
19.3 内存溢出节点出现OOM
- 问题:节点OOM
- 原因:由于写者的内存为16G,集群到后面pod数量起来后由于资源分配不充分导致的
- 解决:利用高可用组件与etcd的堆叠与选举机制,主动关闭一台masrer确保集群能正常运行,顺便测试集群的高可用性
19.4 loki日志采集时间与宿主机不一致
解决 Loki 日志时间与本地时间不一致问题:定位原因为 Grafana 默认使用 UTC 时区,通过修改 Grafana 全局时区为 Asia/Shanghai,同时统一 K8s 集群节点系统时区,实现日志时间与北京时间对齐,提升运维排查效率
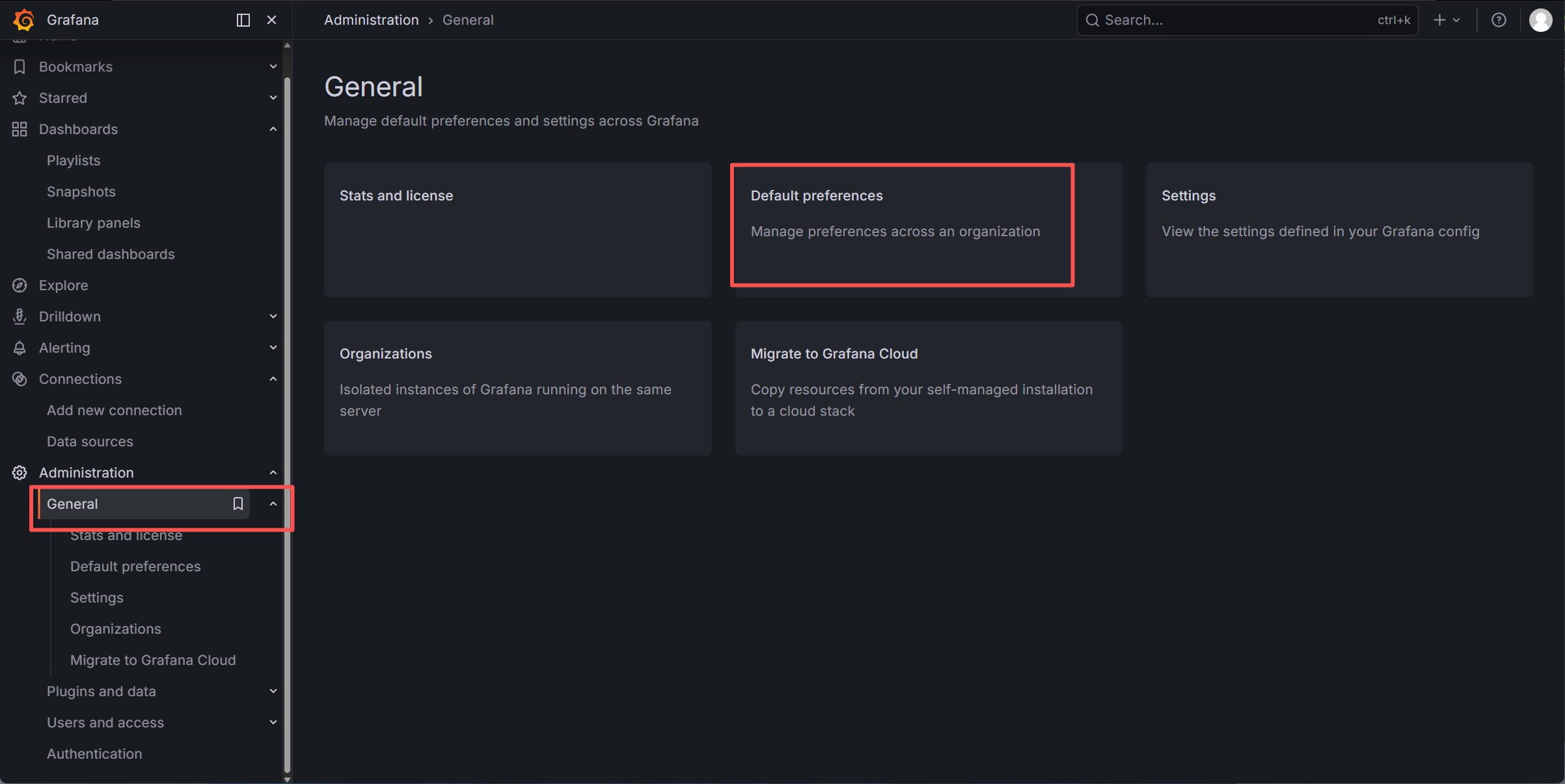
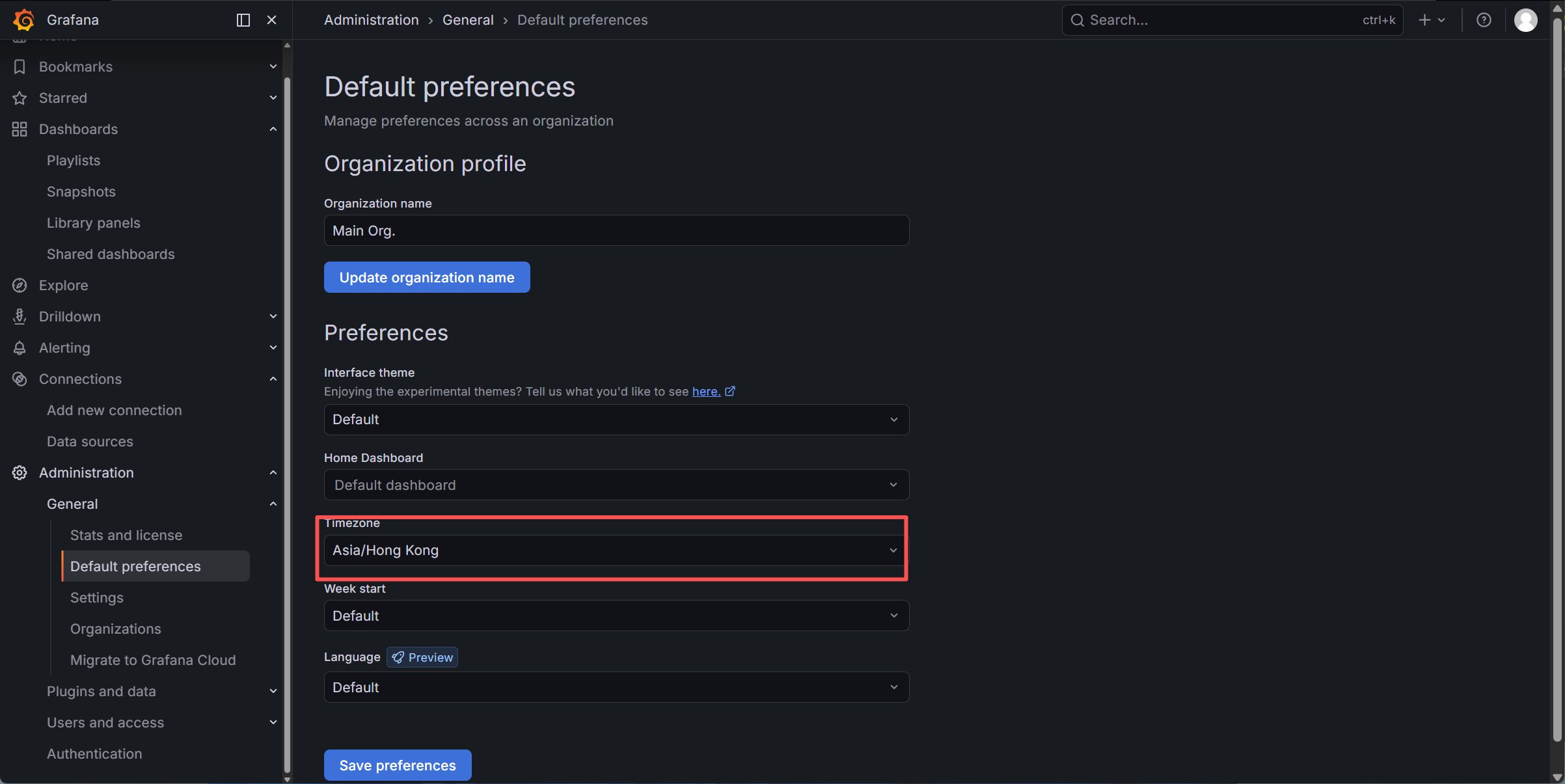
更改时区

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)