体系结构论文(106):MobileKernelBench: Can LLMs Write Efficient Kernels for Mobile Devices?
MobileKernelBench: Can LLMs Write Efficient Kernels for Mobile Devices?【阿里巴巴26年paper】
这篇文章在讲什么
这篇文章研究的是:LLM 能不能帮我们给移动端设备写高质量 kernel。
这里的“移动端 kernel”不是服务器 GPU 上那种 CUDA kernel,而是面向 mobile inference framework 的 operator/kernel 实现。作者把问题落到了 MNN 的 CPU backend 上,并提出了两个核心东西:
1. `MobileKernelBench`:一个专门针对移动端 kernel 的 benchmark 和自动评测流水线。
2. `MoKA`:一个面向移动端 kernel 开发的多 agent 系统。
这篇文章的判断:
1. 现有 LLM 在 server-side kernel 上已经有不少工作。
2. 但 mobile 端是另一套问题,不只是“把平台换成 ARM”这么简单。
3. 直接拿通用模型或者简单微调去做,效果很差。
4. 需要 repository-aware、tool-driven、plan-and-execute 的 agent 才能明显提升结果。
所以这篇文章不是简单把 KernelBench 的平台换成手机,而是在强调:移动端 kernel 开发有自己独立的工程复杂性。
为什么 mobile kernel 和 server kernel 不一样
1. 移动端的目标不一样
服务器侧 kernel 开发,很多时候追求的是:
1. 极限吞吐。
2. 高并行度。
3. 算法级复杂 kernel 的性能突破。
移动端则更强调:
1. 广泛兼容不同模型和框架。
2. 在资源受限设备上稳定运行。
3. 实际部署链条打通,而不只是单点算子跑得快。
这也是文中 Table 1 要表达的核心:mobile kernel development 的首要矛盾不是“某个算子还能不能再提 3% 性能”,而是“能不能把大量 operator 可靠接进碎片化生态里”。
2. 移动端生态很碎
这是理解全文的关键。
移动端开发不像 CUDA 那样相对统一,它涉及:
1. 不同框架。
2. 不同导出格式。
3. 不同 backend。
4. host 开发环境和 device 运行环境分离。
5. 编译、注册、部署、验证链条都更琐碎。
所以你让 LLM 生成的不是一段孤立数学代码,而是一个必须嵌进 framework、能 cross-compile、能 on-device 跑起来的实现。
3. 数据稀缺问题更严重
作者认为移动端 kernel 方向还有一个很大的问题:公开、高质量、可复用的参考实现太少。
这意味着:
1. 通用模型在预训练阶段几乎没真正学到这套知识。
2. 简单 SFT 也很难补齐,因为没有足够训练数据。
一、INTRO
1. 这篇文章在研究什么
- 核心问题
- 文章关注的是:能不能让大模型自动为移动端推理框架生成 kernel。
- 这里的 kernel,不是泛泛的“写代码”,而是给移动推理框架里的算子写底层实现,要求能:
- 编译通过
- 功能正确
- 真机上还有性能收益。
- 和已有工作的区别
- 以前很多工作研究的是 CUDA / GPU / server-side kernel generation。
- 这篇文章把问题扩展到 mobile domain,也就是手机、边缘端、资源受限设备。
2. 作者为什么觉得移动端更难
作者在引言里强调了移动端 kernel 开发有三个本质难点:
- 兼容性优先(Compatibility priority)
- 移动端更强调“支持尽可能多的 operator”,因为要适配不同训练框架和模型迁移。
- 所以重点不只是把少数几个 kernel 做到极致快,而是要覆盖大量算子。
- 工程复杂(Engineering complexity)
- 移动生态非常碎片化。
- 服务端很多时候围绕 CUDA 展开,环境相对统一;但移动端可能涉及 CPU、OpenCL、Vulkan、CoreML、Metal 等多种后端,框架和硬件都更分散。
- 数据稀缺(Data scarcity)
- 移动推理框架里的高质量参考实现和训练数据远少于 CUDA 场景。
- 导致 LLM 容易 hallucination,不懂真实 API,也缺少框架内的优化经验。
你可以把作者的逻辑理解为:
服务端 kernel 生成更像“在成熟生态里做优化”,移动端 kernel 生成更像“在碎片化、低资源、知识稀缺环境里做工程落地”。
3. 图1在表达什么
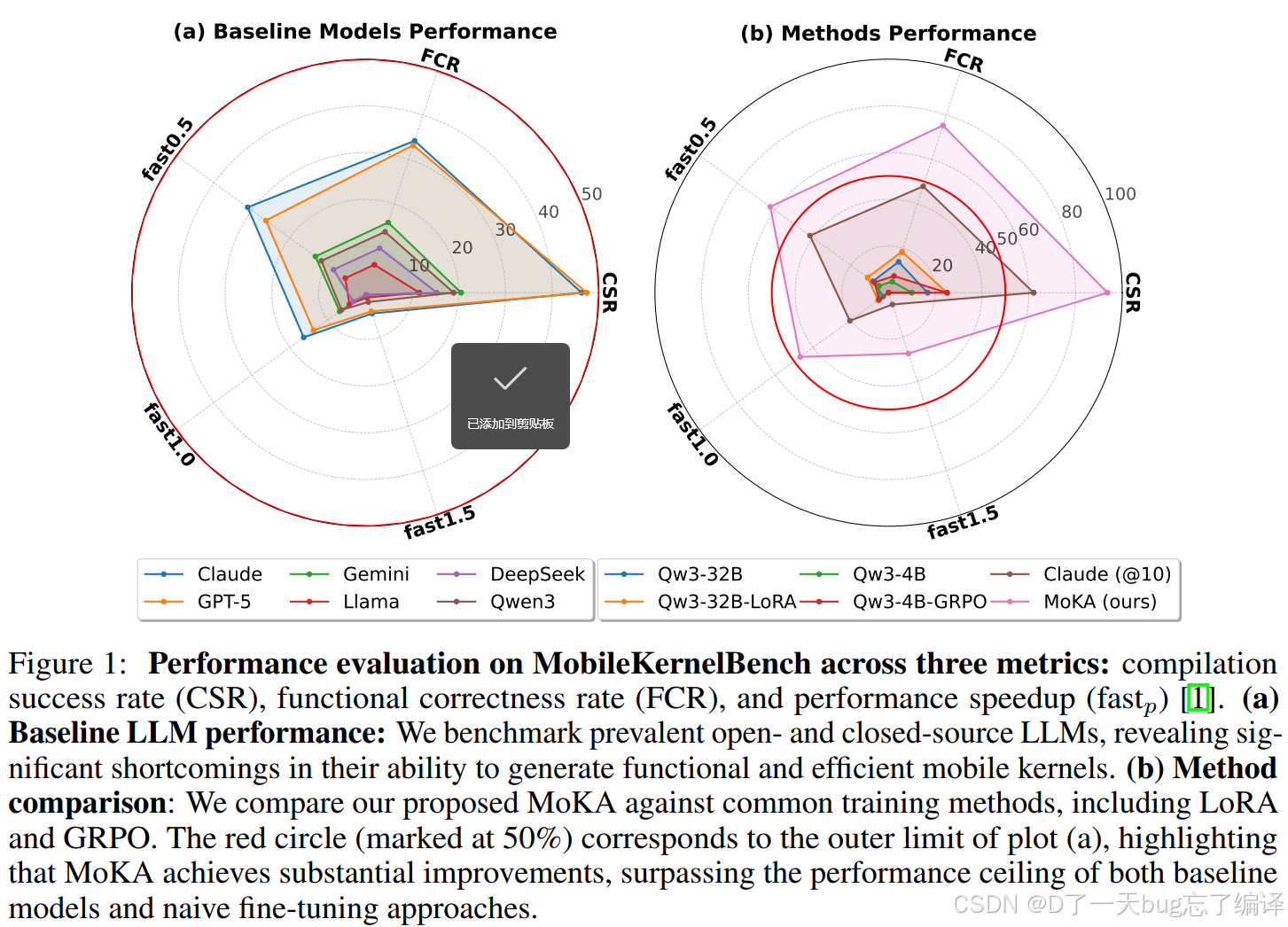
图1其实是全文最核心的一张总览图。
- 左图:Baseline Models Performance
- 比较 Claude、GPT-5、Gemini、Llama、DeepSeek、Qwen3 等模型。
- 指标有三个:
- CSR:Compilation Success Rate,编译成功率
- FCR:Functional Correctness Rate,功能正确率
- fast_p:性能超过原生库一定阈值的比例,比如 fast1.0 表示至少达到 1× speedup 标准,fast1.5 表示超过 1.5×。
- 图的含义
- 通用模型普遍表现不理想:
- 编译成功率不高;
- 功能正确率更低;
- 真正能带来性能提升的比例很小。
- 通用模型普遍表现不理想:
- 右图:Methods Performance
- 比较了普通模型、LoRA、GRPO,以及作者的方法 MoKA。
- 图中最显眼的是 MoKA 曲线明显包住其他方法,说明它在三个维度上都更强。
这张图想证明一句话:
普通 LLM 直接生成 mobile kernel 不够用,必须引入 agent 式迭代修复与优化。
4. MobileKernelBench 是干什么的
这是论文提出的第一个核心贡献。
- 本质
- 它是一个专门针对移动端 kernel generation 的 benchmark + evaluation pipeline。
- benchmark 部分
- 文章构建了一个覆盖 95 个 primitive operators、190 个 tasks、12 个类别 的任务集。
- 它不再像 KernelBench 那样更偏向“算法难度分级”,而是更强调:
- 算子多样性
- 跨框架互操作
- 移动端部署相关性。
- 为什么用 PyTorch + ONNX
- 作者把任务设计成 (PyTorch, ONNX) 对。
- 目的就是让任务有统一的语义参考:
- PyTorch 方便描述模型行为;
- ONNX 作为统一中间标准,方便跨框架对齐。
- evaluation pipeline 部分
- 这个流程模拟真实移动端开发链路:
- Operator Registration:把生成的算子接进框架
- Framework Compilation:重新编译 MNN
- Model Verification:和 ONNX 基准输出做功能比对
- Performance Evaluation:真机运行测性能。
- 这个流程模拟真实移动端开发链路:
5. 文章选了什么具体落地平台
- 框架
- 作者选的是 MNN 的 CPU backend 作为具体实现和测试平台。
- 设备
- 真机平台是 Xiaomi 13 + Snapdragon 8 Gen 2。
6. 为什么普通 LLM 做不好
文章在这几页已经把主要原因讲得很清楚了:
- 第一,框架知识缺失
- LLM 不熟 MNN 这类移动推理框架的内部 API、生命周期、代码组织方式。
- 所以很容易生成不存在的 API,或者调用错接口。
- 第二,工程逻辑不扎实
- 移动端 kernel 不是写一个算法函数就完了。
- 还涉及:
- 算子注册
- 编译系统
- 数据布局
- 框架约束
- 真机执行链路
- 这些都要求更强的工程 grounding。
- 第三,性能优化能力弱
- 即使偶尔写出能跑的代码,也不代表它能打赢原生库。
- 性能优化需要硬件感知、数据布局理解、线程与 backend 使用判断,这些都不是“纯文本生成”能轻松学到的。
7. MoKA 是怎么解决问题的
这是论文第二个核心贡献。
- MoKA 的定位
- 它是一个 Mobile Kernel Agent,也就是专门针对 mobile kernel development 的多智能体系统。
- 核心机制:plan-and-execute
- 不是一次性让 LLM 把代码写完,而是反复迭代:
- 先生成代码;
- 再拿去编译、验证、测性能;
- 根据错误和结果继续修;
- 直到得到更好的 kernel。
- 不是一次性让 LLM 把代码写完,而是反复迭代:
- 三个角色
- Coder
- 负责真正生成 operator code。
- Planning agent 1
- 负责制定编译修复、功能纠错策略。
- Planning agent 2
- 负责制定性能优化策略。
- Coder
你可以简单理解成:
Coder 负责写,Debugger 负责修,Accelerator 负责提速。
- 为什么它比单模型强
- 因为它不是盲写,而是:
- 看仓库结构;
- 看报错位置;
- 看模型节点信息;
- 看性能反馈;
- 再基于这些信息做下一轮决策。
- 因为它不是盲写,而是:
二、背景
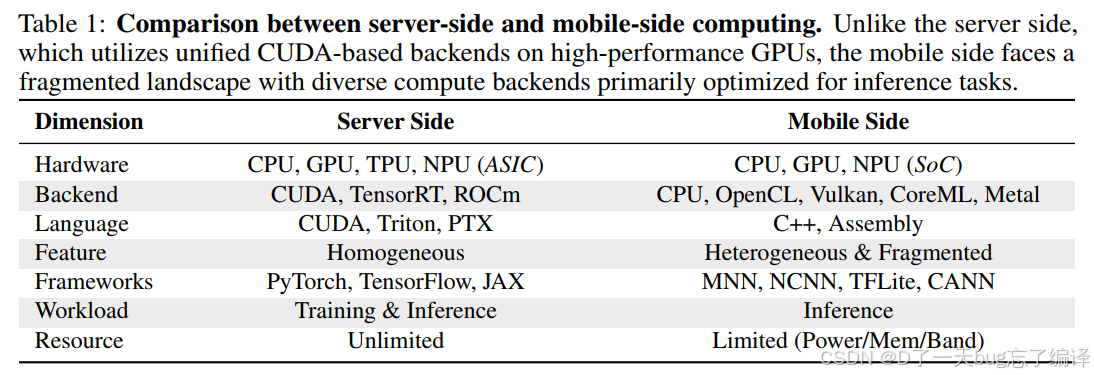
Table 1:为什么 mobile 和 server 不能混为一谈
Table 1 比较 server-side 和 mobile-side computing。
这张表真正要强调三个差异:
1. mobile 侧更强调 compatibility priority。
2. mobile 侧工程复杂度更高。
3. mobile 侧高质量数据更少。
这其实解释了为什么 server 上好用的套路,到了 mobile 上就不一定成立。
举个简单例子:
服务器侧你可能只关心一个 GEMM kernel;
移动侧你可能要为了模型迁移,把大量看似不起眼但必须兼容的 operator 都补齐。
所以如果 benchmark 只测少量复杂算子,就不能很好反映 mobile 真正痛点。
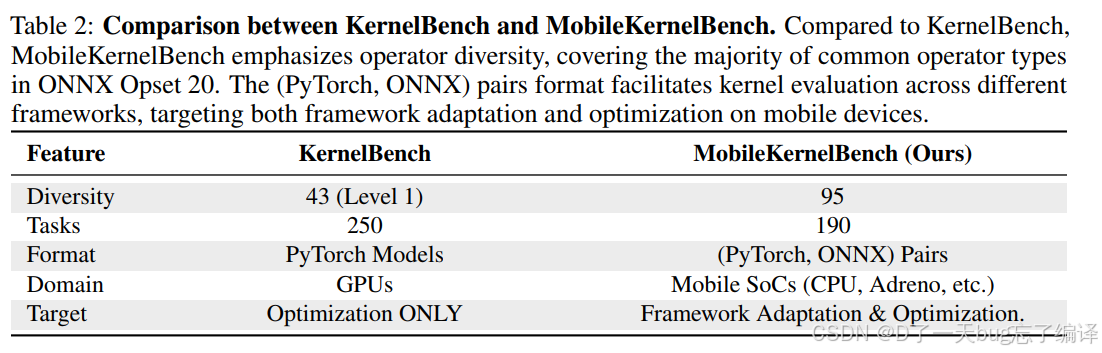
Table 2 比较了 KernelBench 和 MobileKernelBench。
作者的核心转向是:
从“按算法难度分层”转向“按 operator 覆盖面和跨框架可移植性”组织 benchmark。
这点非常合理,因为移动端更关心“能不能迁移更多模型”,而不是只看几个难算子。
Section 3 里作者详细讲了数据构建逻辑:
1. 以 ONNX opset 20 为基础。
2. 用 PyTorch 任务格式包装 operator。
3. 确保 ONNX / PyTorch / MNN 三者之间能形成统一桥梁。
最后构造出:
1. 95 个 distinct operator。
2. 190 个任务。
3. 分成 12 个类别。
三、方法
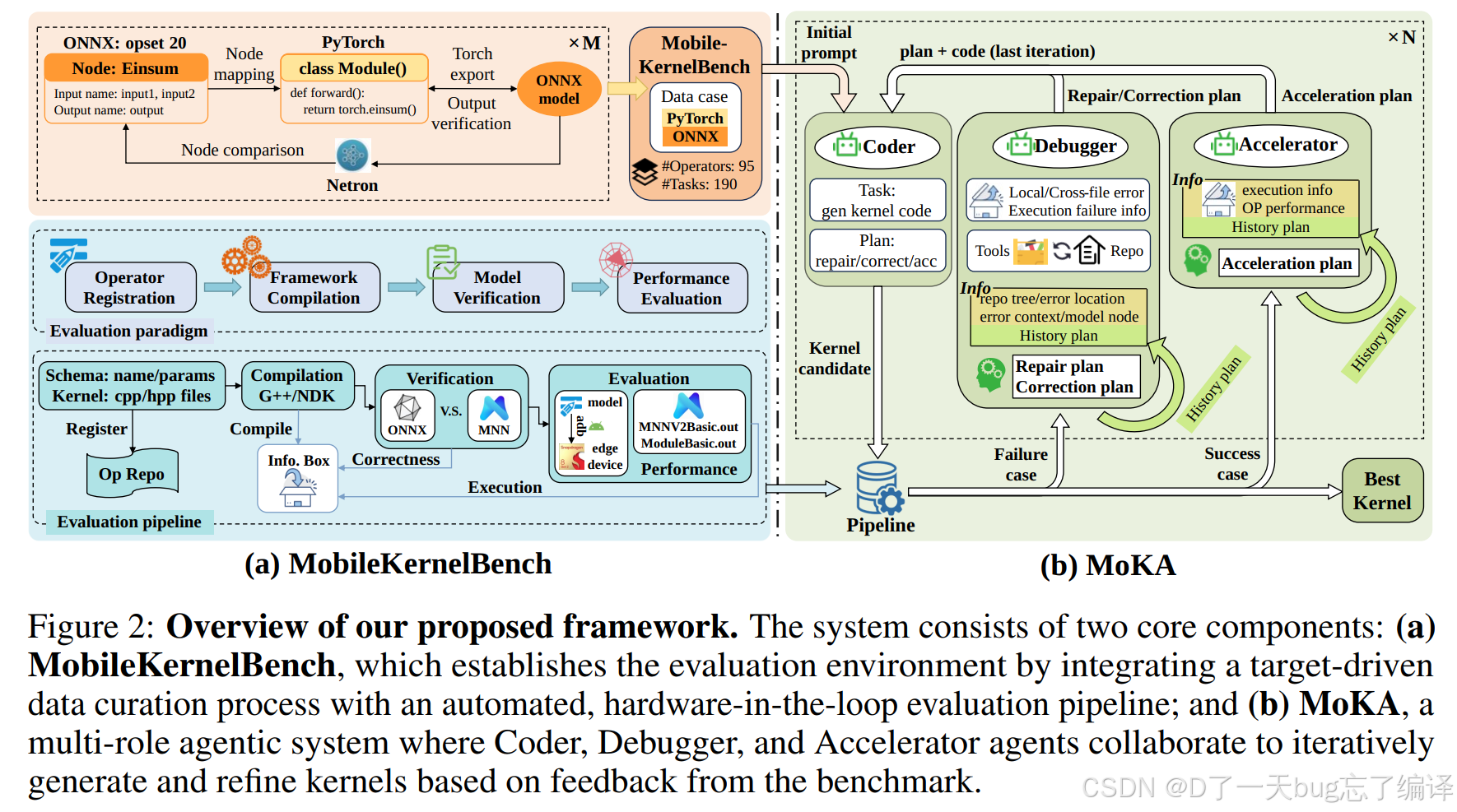
Figure 2:这张图是整篇文章的主结构图
Figure 2 分成两部分:
1. `MobileKernelBench`
2. `MoKA`
Figure 2(a) 讲 benchmark 流水线。它大致包括:
1. 从 ONNX / PyTorch operator 构造任务。
2. 做 operator registration。
3. 编译到目标框架。
4. 进行 correctness verification。
5. 最后做 on-device performance benchmarking。
这部分最重要的是“host-device gap”。
移动端最大的问题之一,就是很多东西在桌面环境看起来没事,但真正到设备上跑才暴露问题。作者把 cross-compilation、远程部署、设备端性能测试都纳入流水线,这是这篇 benchmark 比较扎实的地方。
Figure 2(b) 则讲 `MoKA` 的 agent 结构。这里主要有三个角色:
1. `Coder`
2. `Debugger`
3. `Accelerator`
这三个角色并不是为了“看起来像 multi-agent”而硬拆,而是对应三个不同问题:
1. Coder:负责生成和修改 kernel 代码。
2. Debugger:负责根据编译错误、执行错误、repo 上下文定位问题。
3. Accelerator:在代码已经能跑的情况下继续挖性能。
这个分工比“一个 agent 全干”更符合实际开发过程。
评测流水线
作者在 Section 3 强调 benchmark 不只是测“能否编译”,而是覆盖完整生命周期:
1. operator registration
2. framework compilation
3. model verification
4. on-device profiling
这一点非常重要,因为 mobile kernel 的问题很多都不发生在第一步。
例如:
1. operator 注册方式不对,框架接不上;
2. 编译能过,但实际执行图里 shape/type 对不上;
3. 桌面验证通过,但设备侧行为不一致;
4. correctness 没问题,但实际性能比 native library 更差。
所以 MobileKernelBench 真正测的是“可部署 operator”,而不是“像 C++ 的代码段”。
MoKA 的设计
MoKA 的关键设计思想是 plan-and-execute。
作者认为在 mobile 场景里,LLM 主要缺的不是一点点语法知识,而是:
1. 不知道 framework-specific 约束。
2. 不知道错误该怎么定位。
3. 不知道性能瓶颈该如何分层诊断。
所以 MoKA 不是靠再训练模型来“内化一切”,而是通过:
1. repository-aware context
2. error parsing
3. 历史计划追踪
4. 迭代修复与优化
把外部环境变成模型可用的推理支撑。
这也解释了为什么作者后面会认为 agent 比 LoRA / RL 更有效。
Agent Collaboration
`Coder` 负责根据当前计划写代码;
`Debugger` 负责看错误日志、依赖关系、repo 文件和执行失败上下文;
`Accelerator` 则负责在正确实现基础上定位性能瓶颈并提出优化方案。
这个拆法的优点是:
1. 把“先修对”和“再加速”分开;
2. 不让模型在一轮里同时优化所有目标;
3. 允许不同 agent 共享历史计划和过去失败经验。
这其实是在给模型提供一种工程化思考顺序:
先保证可编译;
再保证正确;
最后追求性能。
如果不这样拆,LLM 很容易一边修 correctness 一边乱动性能相关代码,最后两边都做不好。
Agentic Toolset
作者强调 MoKA 配备了 repository-aware 和 information-parsing tools。
这点很关键,因为 mobile framework 的核心问题之一就是:
很多知识不在通用编程语料里,而藏在 repo 的已有实现、注册方式、目录结构和错误上下文中。
所以 MoKA 的强项不是“天生就懂 MNN”,而是:
它会去读真实工程上下文,再根据上下文修改自己。
这一点和很多只靠 prompt 的工作区别很大。
四、实验
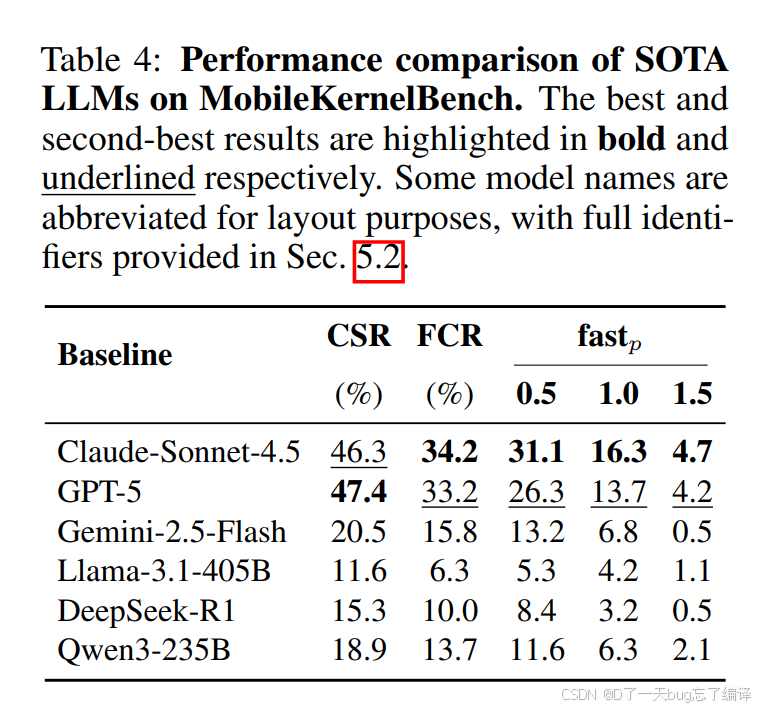
Table 4:baseline LLM 的结果相当差,问题主要卡在 CSR
Table 4 比较了多个 SOTA LLM,包括 GPT-5、Claude Sonnet 4.5、Gemini、Llama、Qwen、DeepSeek 等。
作者指出:
1. baseline 模型整体编译成功率很低。
2. 功能正确率更低。
3. 真正能带来 `fast1.5` 这类较高性能门槛提升的更少。
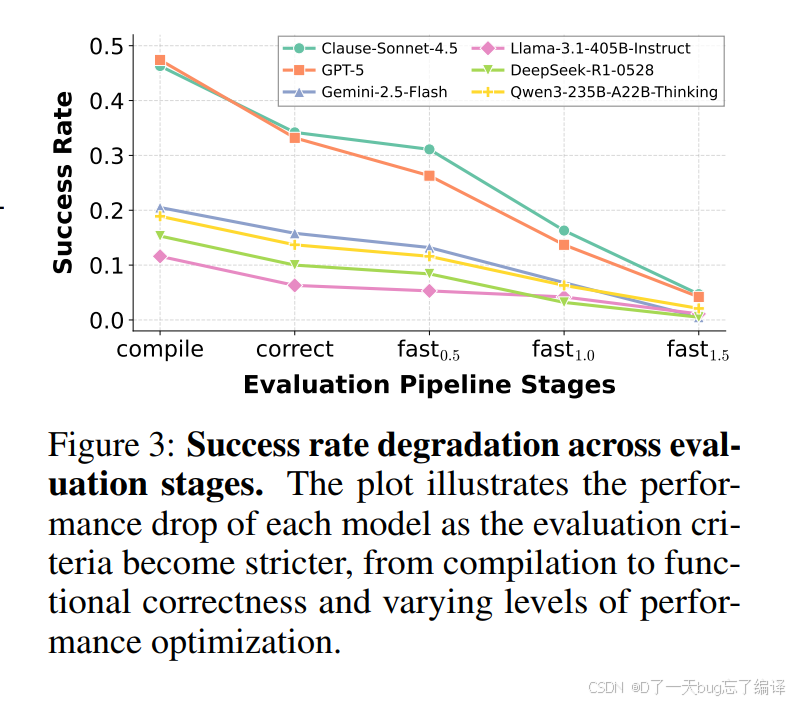
从图文联动看,Figure 3 进一步说明成功率会随着评测复杂度迅速下降。
这里最重要的观察是:
mobile kernel generation 的首要失败模式不是“性能不够好”,而是“根本接不进 framework”。
也就是说,CSR 先塌了,后面 FCR 和 speedup 基本无从谈起。
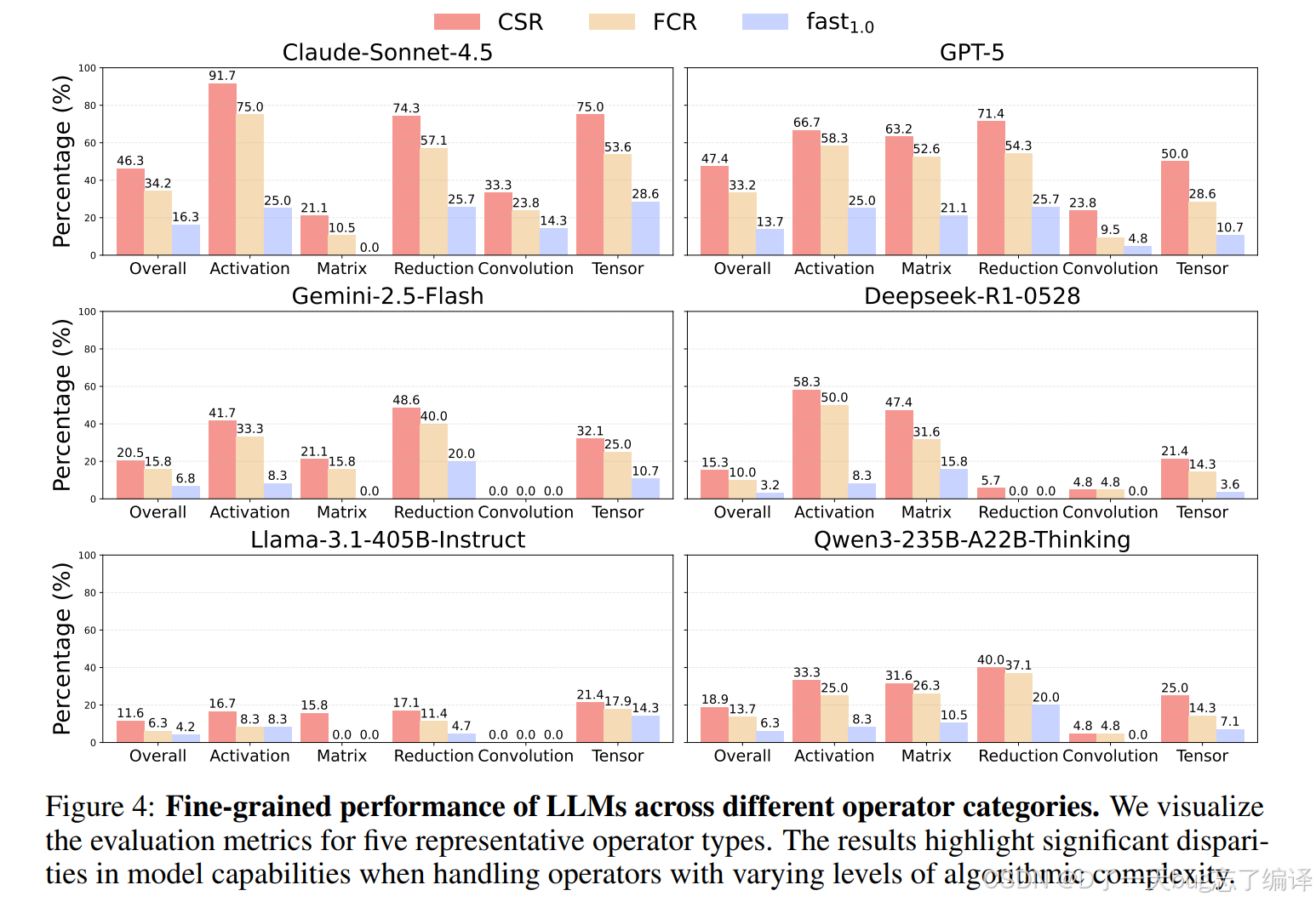
Figure 4:不同 operator 类别差异很大
Figure 4 按 operator 类别拆分了模型表现,比如 activation、matrix、reduction、convolution、tensor 等。
这张图说明:
1. 不同模型的强项并不一样。
2. 有些模型在 matrix 类任务上还保留了一些预训练优势。
3. 但整体上跨类别泛化很差。
作者特别指出 GPT-5 和 DeepSeek-R1-0528 在 matrix operations 上有一定能力,这很可能是因为通用预训练阶段已经见过大量矩阵相关代码与优化模式。
但这种优势并不能自动迁移到 mobile framework 语境里。因为真正的难点不是算子数学本身,而是 framework-specific implementation。
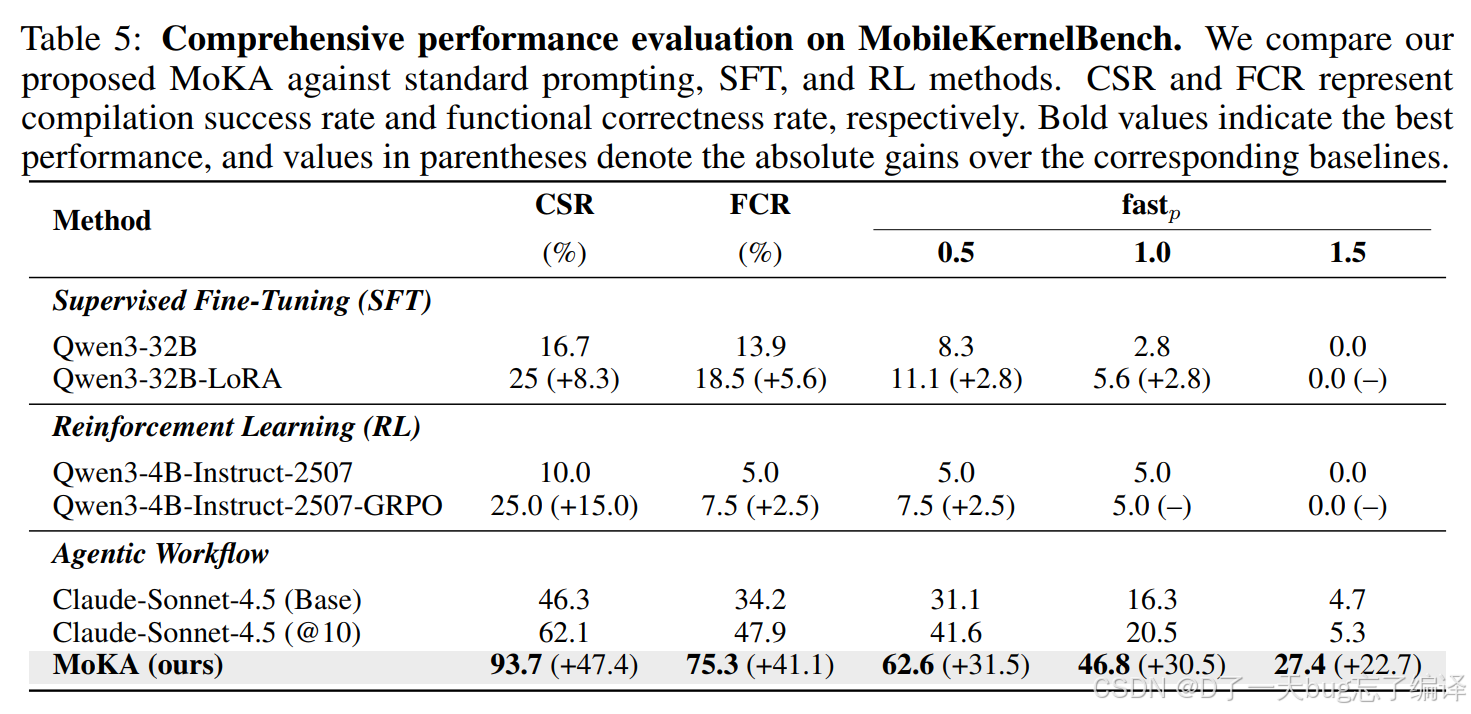
LoRA 和 GRPO:Table 5 显示“训练未必是解法”
Table 5 很关键,因为它把三条路线并排摆在一起:
1. SFT / LoRA
2. RL / GRPO
3. Agentic workflow
先看 LoRA:
1. Qwen3-32B 基线 CSR 16.7%,FCR 13.9%。
2. LoRA 后 CSR 到 25.0%,FCR 到 18.5%。
3. 但 `fast1.5` 仍然是 0。
这说明 LoRA 只能稍微改善“写得更像正确代码”,但并没有学会真正的性能优化。
再看 GRPO:
1. Qwen3-4B 的 CSR 从 10.0% 到 25.0%。
2. FCR 只从 5.0% 到 7.5%。
3. `fast1.0` 以上的性能指标几乎没动。
这说明 RL 在这里更多帮助模型对齐格式和表面约束,但不足以建立深层的 mobile framework 语义与性能感知。
作者的解释是合理的:在这种数据贫瘠、工程知识碎片化的任务里,靠训练把知识硬灌进模型,不如让 agent 去读 repo 和错误上下文。
Table 5 显示:
1. Claude-Sonnet-4.5 单轮基线 CSR 46.3%,FCR 34.2%,`fast1.5` 只有 4.7%。
2. pass@10 后 CSR 62.1%,FCR 47.9%,`fast1.5` 5.3%。
3. MoKA 则直接到 CSR 93.7%,FCR 75.3%,`fast1.5` 27.4%。
这个提升幅度是非常大的。
特别值得注意的是,作者专门拿 pass@10 做对比,目的是说明:
MoKA 的收益不只是因为“多试几次”,而是因为“会根据反馈改进”。
这是一个很好的对照设计。
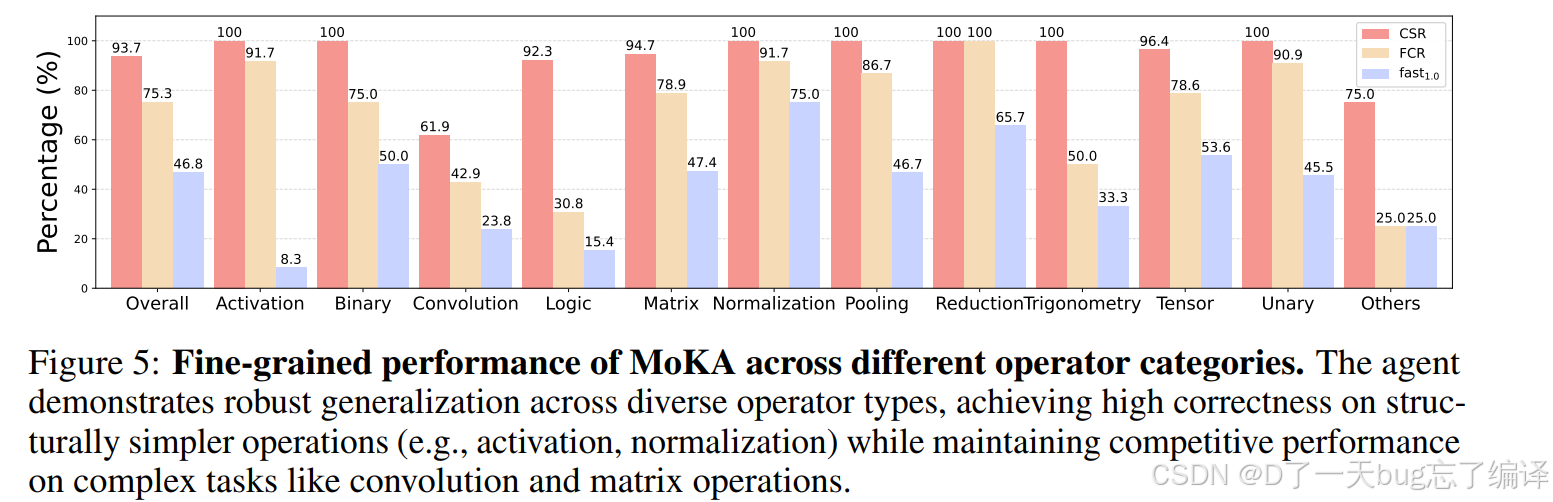
Figure 5 进一步把 MoKA 按 operator category 拆开来看。结论是:
1. 它在 7 个类别上编译成功率做到 100%。
2. 在 activation、normalization 这类结构相对明确的任务上表现非常强。
3. 在 matrix、convolution 这类更复杂任务上也有明显提升。
作者还提到,对成功 kernel 来说平均 speedup 接近 3x,这说明 `Accelerator` agent 确实学会了一些硬件相关优化,而不只是“修到能跑”。
Case study:LayerNorm2D
Appendix 里的 LayerNorm2D case study 很有代表性。
作者展示 MoKA 在 10 次迭代中把实现从 1.00x 提升到 6.82x。
这条轨迹很有启发性,因为它不是一开始就找到最优解,而是按层次逐步修:
1. 先处理计算效率问题,例如 SIMD。
2. 再处理内存延迟问题。
3. 后期引入 memory-hiding 技术,例如预取。
这说明 MoKA 的“优化能力”并不是魔法,而是通过迭代反馈逐步把瓶颈从 compute-bound 推向 memory-bound,再继续修。
这个 case 比单纯报一个最终 speedup 更有说服力,因为它展示了 agent 的过程性能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)