AI核心概念大串联
1.LLM
大语言模型,简称大模型
内部架构:transformer
最底层的生成原理:一个一个地预测
大模型是一个庞大的数学函数,接收数字,输出数字
本质上是看不懂提问人的汉语言的,所以需要一个中间人做翻译,将汉语言转为数字传递给大模型
2.Token
就是用户和大模型的中间人tokenizer,负责编码和解码的工作,编码就是把文字变成数字,解码是把数字还原为文字
解码环节不需要切分,因为模型每次只会返回一个token
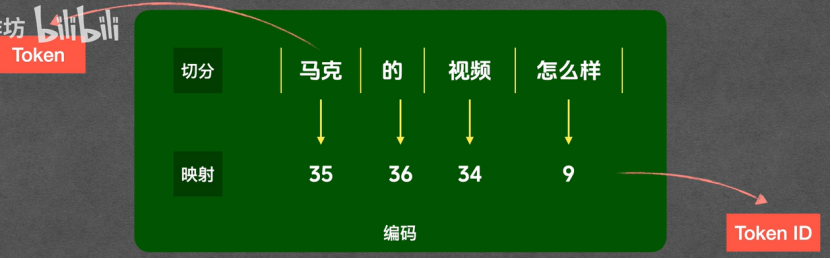
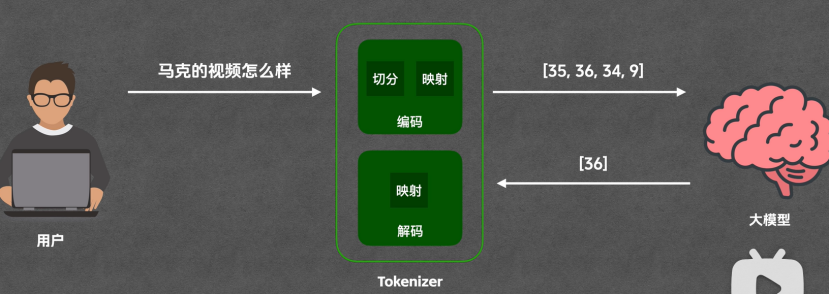
所以,token是大模型处理文本的最基本单元

Token和词并不是一对一的关系
拆分:从左到右,能构成一个通用词就算一个token
一个Token=0.75个英语单词=1.5~2个汉字
3.Context(上下文)
大模型是如何记住每次的聊天内容的:
每次在给大模型发信息的时候,此时并不是把本次的问题发送给大模型,而是背后的程序会把之前的对话历史找出来一起发送过去,所以大模型才会知道之前发生了什么
Context是大模型每次处理任务时所接收到的信息总和,可以看成时大模型的临时记忆体
Context里包含的内容:
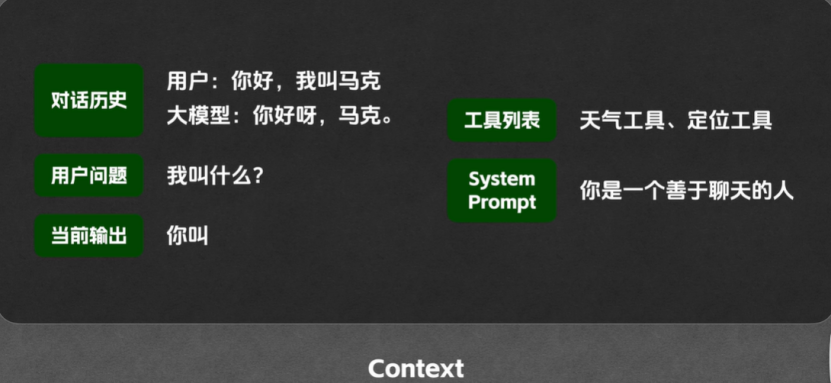
Context Window(上下文窗口):Context能容纳的最大token数量

假如说有一个公司产品手册,希望将产品手册给大模型之后,大模型能回答用户的各种疑问,如何操作呢?
此时,如果把产品手册和用户问题一次性送给大模型是不可取的,无论是成本还是容纳,
所以就需要RAG技术。
RAG可以从产品手册出抽出与用户问题最为匹配的几个片段,把这几个片段发送给大模型
4.Prompt(提示词)
Prompt:是大模型接收的具体问题或指令
就是给大模型的一个问题或者指令
Prompt的写法决定了大模型给出答案的质量,一个好的prompt需要是清晰的,具体的,明确的
所以就有一个专门的领域Prompt Engineering(提示词工程),简单来说,就是研究如何把话说清楚,让大模型更精准的理解用户的意图
有时候我们需要告诉大模型我们这个问题的人设和规则,要做什么样的事,于是就有了两种不同的prompt,
说明具体任务的事User Prompt,是用户自己输入的
说明人设和做事规则的是System Prompt,是开发者在后台配置的,用户看不到,但是会一直影响大模型的行为
5.Tool(工具,函数)
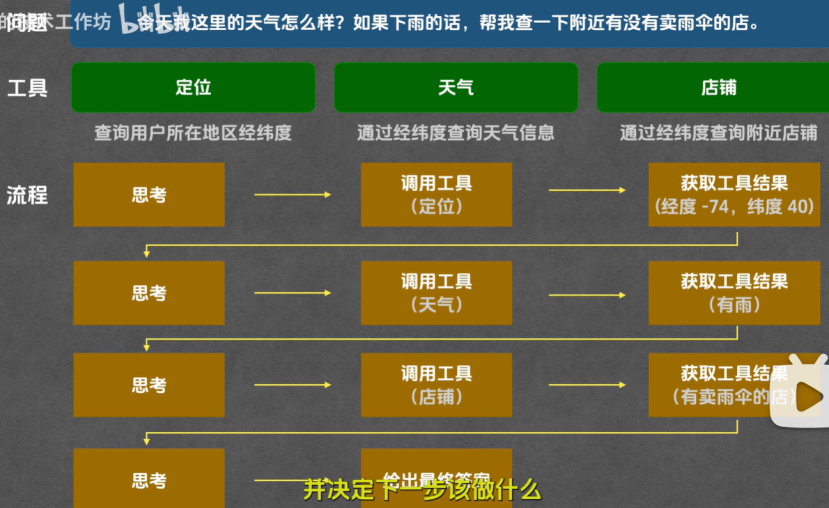
大模型的弱点:无法感知外界的环境,此时就需要tool
Tool本质就是一个函数,给他一个输入,他就会给你一个输出
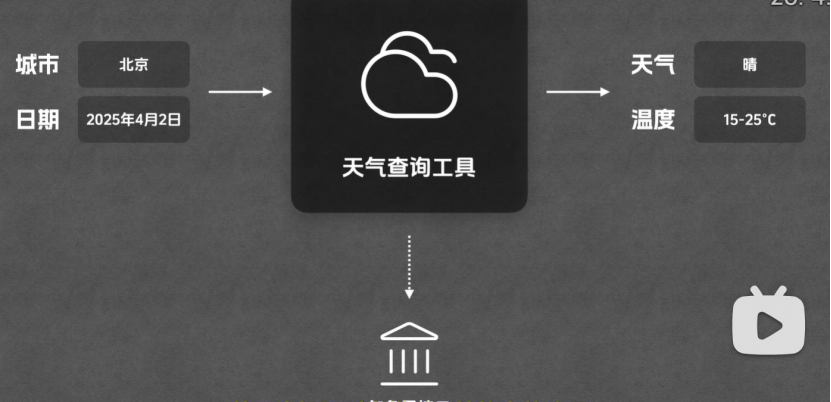
从用户提问到大模型回答的完整流程:
1.用户提出问题:今天上海天气如何,会把这个问题发送给平台
2.平台把这句话和所能用到的工具(天气查询,计算器)一起发送给大模型
3.此时大模型会根据文本调用天气查询工具,但是大模型不能自己调用,他只能借助平台的力量
4.此时大模型就会生成一个调用天气查询工具的指令发送给平台,
5.平台接收指令后,就会真正的去调用天气查询工具,天气查询工具会给平台传一个调用结果
6.平台拿到结果后,会发送给大模型,大模型拿到后整理成一句话输出给平台,平台返回给用户


大模型在过程中,要选择工具和归纳总结,平台负责串联整个流程,调用工具最终需要平台
Tool的本质就是给大模型提供一套可以调用外部的能力,让大模型能够感知外部环境
6.MCP(模拟上下文协议)
在刚才流程中,平台需要把工具列表传给模型,还要能调用工具,首先要把工具列表接入平台,这样平台才知道工具列表以及工具的用途,接入参数等。
不同平台的接入标准都不一样
所以就需要MCP,MCP就是统一的工具接入标准
7.Agent
Agent:能自主规划,自主调用工具,直到能完成用户任务的系统

8.Agent Skill
本质上就是,用户提前写好塞给Agent的一份说明文档

分为两部分,下面部分叫做指令层,不限格式
定义好之后,需要存在硬盘下指定的地方
以cloud code为例
需要存到/.claude/skills目录下
接下来的存放操作有两个规定:1.在此目录下新建文件夹,且文件夹名字要与Agent Skill名字相同 2.进入到文件夹之后,要新建一个文件,把刚才编写的文档全别贴进去,而且该文件名必须叫做SKILL.md

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)