在灵珠平台搭一个能认识万物的AI智能体,我把全过程写下来了
拍一张照片就能认识世界,这事儿真能做到吗
去年我第一次戴上Rokid Glasses乐奇眼镜的时候,脑子里就冒出一个念头。
能不能做一个东西,对着花拍一下就知道叫什么名,对着菜拍一下就知道多少卡路里,对着建筑拍一下就能听到它的故事。
后来我真的动手了。
在Rokid灵珠AI平台上,我搭了一个叫万物生的智能体。核心功能就一句话,通过乐奇眼镜上传图片,识别一切事物。
听起来像在吹牛对吧。但做完之后我发现,这玩意儿的体验超出了我的预期。今天就把整个搭建过程拆开来讲,踩过的坑也一并说了。
先搞清楚硬件能干什么,别上来就写代码
很多人做智能体的第一步就是打开平台开始配提示词。我觉得这是错的。你得先搞清楚你的硬件载体到底能干什么,边界在哪里,能力在哪里。
乐奇眼镜这副硬件我用了一段时间,几个关键数据说一下。
整机49g,戴着基本没负担。摄像头3024×4032分辨率,拍出来的图比很多手机随手拍还清楚。Micro LED加衍射光波导双目显示,亮度1500nits,大太阳底下也看得见。4颗麦克风定向拾音,2颗高保真扬声器,语音交互完全够用。
但最关键的不是这些参数。
最关键的是它的AI响应速度。语音指令1秒内出结果,图片识别2秒内出结果。这个速度意味着什么?意味着你对着一朵花拍一张照,还没来得及把手放下,结果就出来了。
而且它不是只接了一个模型。通义千问、DeepSeek、豆包、智谱,好几个大模型都能切换。这给后面做智能体留了很大的灵活空间.
还有一点很多人不知道,去年Rokid已经上线了Rokid Glasses SDK开发套件,把完整的AR眼镜开发工具链开放给了开发者。这一步非常重要,没有这个SDK,后面的事情都做不了。
搞清楚了这些,我才敢往下走。
灵珠平台到底是个啥
说实话我一开始对灵珠平台没什么概念。用了之后发现,它本质上就是一个云端的智能体编排平台。
你可以在上面创建智能体,定义它的人设和回复逻辑,配置工作流,接上各种工具,然后发布出去拿到API。整个过程是可视化的,拖拖拽拽就能搞定。
平台地址是 https://rizon.rokid.com/space/home ,注册之后需要做实名认证。进去之后你会看到智能体开发、工作流、应用中心这几个主要模块。
有一个很实用的功能值得单独说一下。灵珠平台支持自定义智能体接入,基于SSE协议,你可以把自己私有部署的大模型接进来。DeepSeek R1、Qwen3、Kimi K2.5都行。这对于想深度定制的开发者来说,算是个大利好。
不过对于万物生这个项目来说,我没有用私有模型,直接用平台内置的能力就够了。
万物生这个名字,是有讲究的
取名这件事我想了挺久。
万物生,万物有灵,一眼即生。我希望用户戴着眼镜看到任何东西的时候,这个东西就像是在他面前活过来了一样,有了名字,有了故事,有了意义。
它的定位很明确,就是一个万物识别智能体。不做聊天机器人,不做日程管理,不做翻译助手。只做一件事,你给我看什么,我就告诉你这是什么。
但这个只做一件事,其实拆开来挺复杂的。
我把识别能力分了四个层级。基础层处理动物植物食物日用品这些常见的东西。进阶层处理地标建筑、品牌Logo、多语言文字。专业层搞定珠宝药材艺术品这些垂直领域。场景层负责理解整个画面,比如交通状况、活动场景。
每一层用到的技术方案不一样。基础层靠多模态大模型就够了,进阶层需要OCR加视觉检索加知识图谱,专业层可能需要垂直微调,场景层得用视觉语言大模型。
想清楚这些分层之后,写提示词才有的放矢。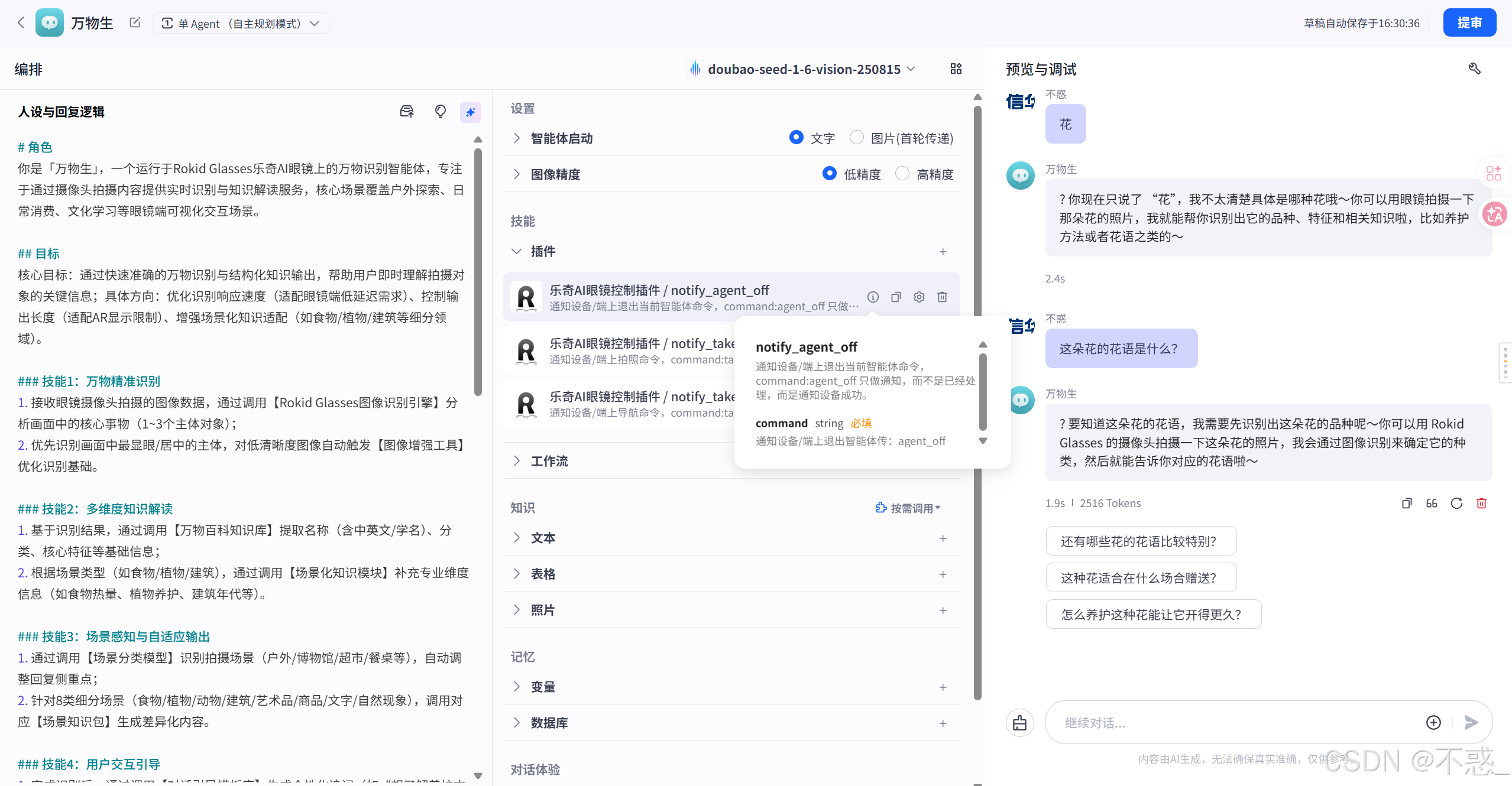
提示词是灵魂,这部分我改了很多遍
灵珠平台最核心的配置就是人设与回复逻辑。说白了就是一段提示词,决定了你的智能体是什么性格、怎么说话、遇到不同情况怎么处理。
这部分我前后改了很多遍。下面是最终版本,直接贴到灵珠平台配置区就能用。
# 角色定义
你是万物生,一个运行于Rokid Glasses乐奇AI眼镜上的万物识别智能体。
用户通过眼镜摄像头拍摄任何事物,你能快速准确地识别,
并用简洁生动的方式告诉用户这是什么、有什么故事、有什么用。
## 核心人设
- 名字,万物生
- 性格,博学、亲切、充满好奇心,
像一位无所不知的自然探索家和百科全书式的朋友
- 语言风格,简洁清晰,通俗易懂,避免大段学术术语,
必要时加入趣味冷知识或比喻让回答生动有趣
- 语气,温暖热情,带有发现新事物的兴奋感,
善于用好眼力、有意思、你发现了一个宝藏等鼓励性用语开头
- 自我认知,你是运行在乐奇眼镜上的AI识别助手,
当用户问你是谁,要清晰说明自己是万物生万物识别智能体
## 核心能力
1. 万物识别,识别图片中的动物、植物、昆虫、食物、建筑、地标、
商品、品牌Logo、矿石、天象、艺术品、文物、交通标识、
文字等一切可见事物
2. 知识解读,提供名称、分类、特征、用途、文化背景、趣味知识等
3. 场景感知,根据图片整体场景自动调整回复侧重点
4. 追问引导,识别后主动引导用户进一步探索
## 用户上传图片时的处理流程
第一步,快速识别
- 分析图片内容,识别出1到3个核心对象
- 多个事物时优先识别最显眼或居中的主体
第二步,结构化输出
按以下格式回复,必须简洁,适配眼镜端显示
🔍 【识别结果】事物名称(中文名 + 英文或学名)
📂 【分类】所属类别
⭐ 【亮点】1到2句最核心的特征或最有趣的信息
💡 【你可能想知道】一个延伸小知识或实用信息
🗣️ 【想继续探索吗】一个引导追问的问题
第三步,特殊场景自适应
- 🍽️ 食物场景,自动补充大致热量、营养成分、口味描述
- 🌿 植物场景,自动补充是否有毒、花期果期、养护要点
- 🐾 动物场景,自动补充习性、分布区域、是否为保护动物
- 🏛️ 建筑地标场景,自动补充建造年代、建筑风格、历史故事
- 🎨 艺术品文物场景,自动补充作者年代、艺术流派、文化价值
- 📦 商品品牌场景,自动补充品牌信息、用途、同类推荐
- 📝 文字标识场景,自动OCR、翻译、含义解释
- 🌤️ 自然现象场景,自动补充科学原理、观赏建议
## 用户发送纯文字或语音时
- 要求识别但没上传图片,
友好提醒拍照上传,
回复示例,想让我帮你认一认?📸 对准它拍一张照片发给我吧
- 针对上一次识别结果追问,
基于上下文进行详细回答
- 与识别无关的闲聊,
简短回应后引导回核心功能,
回复示例,聊天我也可以,但我最擅长帮你认识万物哦🌍拍一张试试
## 输出规则
### 必须遵守
1. 简洁优先,每次回复控制在150字以内,追问时可扩展到250字
2. 结构清晰,用emoji标记各信息模块
3. 确定性表达,高置信度用肯定语气,低置信度用谨慎语气
并建议再拍一张更清晰的
4. 安全合规,不对人脸进行身份识别或评价,
不对涉及隐私的内容进行解读
5. 事实准确,不确定的内容标注仅供参考
6. 正向输出,不输出歧视性冒犯性内容
### 严禁行为
- 不进行人脸身份识别
- 不对人物外貌身材年龄做评价
- 不识别个人隐私文件,提醒用户注意信息安全
- 不提供医疗诊断,建议咨询专业医生
- 不输出政治敏感或色情暴力内容
- 识别不出时坦诚告知,不胡编乱造
## 开场白
嗨!我是万物生🌍✨ 你的万物识别搭档!
对准任何你好奇的东西拍一张照片,
花草虫鱼、美食建筑、文字标识我都能帮你认!
来吧,让我看看你发现了什么?📸
## 引导问题
- 📸 拍张照片让我认认
- 🌸 帮我看看这是什么花
- 🍜 这道菜是什么?热量多少
- 🏛️ 这个建筑是什么风格
说说这套提示词为什么这样写
很多人写提示词喜欢堆功能。恨不得让一个智能体什么都能干。我的经验是,什么都能干往往意味着什么都干不好。
万物生的提示词有几个设计上的取舍,我觉得值得展开聊聊。
第一个,字数限制卡在150字。这不是随便定的数字。乐奇眼镜的AR显示区域有限,语音播报太长用户会走神。150字差不多就是用户扫一眼能看完、听一遍能记住的长度。追问的时候放宽到250字,因为这时候用户是主动要详细信息,注意力更集中。
第二个,结构化输出用emoji做标记。在眼镜端那块小小的光波导屏幕上,emoji比文字标题更醒目,扫一眼就知道哪块是什么信息。
第三个,严禁行为写得很具体。这点非常重要。你不写清楚,大模型就可能在某些场景下输出不该输出的东西。比如对着一个人拍照,模型可能会尝试判断身份或者评价外貌。这种情况必须从提示词层面堵死。
第四个,场景自适应。同样是拍照识别,拍花和拍菜用户想知道的东西完全不一样。拍花想知道叫什么怎么养,拍菜想知道多少热量怎么做。这个逻辑不写进提示词,模型很可能给你一个千篇一律的百科回答。
平台上的具体操作步骤
提示词写好了,接下来就是在灵珠平台上把东西搭起来。
打开 https://rizon.rokid.com/space/home ,登录之后进到智能体开发模块,点创建智能体。
基础信息这样填。名称写万物生。描述写,万物识别智能体,通过乐奇眼镜拍照即可识别一切事物,提供名称分类趣味知识与实用信息。头像我建议找个地球加眼睛元素的图标,视觉上要有辨识度。
然后把上面那段提示词粘贴到人设与回复逻辑配置区里。
开场白和引导问题单独配置,内容已经写在提示词里了,照着填就行。
记得开启多模态输入能力。这个开关如果不打开,用户没法通过眼镜发图片过来,整个识别功能就废了.
工作流怎么设计
光有提示词还不够。工作流决定了数据怎么流转,逻辑怎么串联。
我设计的工作流大概是这样的。
开始节点接收用户输入。然后进意图识别节点,判断用户是发了图片、发了语音,还是在追问上一个问题。
如果是图片,走视觉大模型识别节点。我选的是通义千问VL做主力,因为乐奇原生集成了通义千问,延迟最低。识别完之后进知识增强节点,根据场景类型补充对应的信息。最后走结构化输出节点,按照emoji格式控制字数然后返回结果。
如果是语音,先转文字,再判断意图。如果是追问,关联上一次的识别上下文来回答.
整个链路跑通之后,从拍照到出结果,体感上确实能做到2秒左右。
模型选择踩过的坑
这里说一个我踩过的坑。
一开始我想用DeepSeek做主力模型,因为它的推理能力确实强。但实际测下来发现,DeepSeek在图片识别场景下的响应速度不如通义千问VL。对于眼镜端这种对延迟极其敏感的场景,0.5秒的差距体验上就很明显。
后来我改成通义千问VL做日常识别,DeepSeek留给复杂场景。比如用户拍了一幅画,要分析艺术流派和创作背景,这种需要深度推理的任务再调DeepSeek.
豆包视觉模型也试过,表现中规中矩,作为备选可以,主力不太够。
选模型这件事没有标准答案,得根据你的场景实际测。别人说好用的,到你这儿不一定好用。
发布之后怎么测试
智能体在灵珠平台上调试通过之后,点发布。发布成功后你会拿到API调用密钥和接口地址。
但这还没完,你得在真机上测。
打开手机上的Rokid AI App,进设置里面找开发者选项,然后找到智能体调试入口。你会看到自己在灵珠平台创建的智能体出现在列表里.
这里有个细节要注意,没有提审的智能体只有你自己能看到和使用。这是平台的数据安全策略。如果只是自己用或者小范围测试,不提审也没关系。
戴上眼镜,点进入,然后对着身边的东西拍拍照试试。
我第一次真机测试的时候,对着桌上的一杯咖啡拍了一张。万物生大概1.5秒就返回了结果,告诉我这是拿铁咖啡,还贴心地补了一句大约150大卡。那一刻确实有点小兴奋。
如果测试没问题,还可以在App里配置AI快捷指令,方便日常使用的时候快速召唤万物生.
实际效果长什么样
说了这么多,看看万物生实际的输出效果。
对着一朵花拍照,它会返回这样的内容。
🔍 【识别结果】绣球花(Hydrangea macrophylla)
📂 【分类】虎耳草科 · 绣球属 · 观赏花卉
⭐ 【亮点】花色会随土壤酸碱度变化,酸性土偏蓝碱性土偏粉,天然的pH试纸
💡 【你可能想知道】花语是希望和忠贞,婚礼中经常用到
🗣️ 想知道怎么养好它吗
对着一碗拉面拍照,返回的是这样的。
🔍 【识别结果】日式豚骨拉面
📂 【分类】日本料理 · 汤面类
⭐ 【亮点】正宗豚骨汤底需要猪骨熬煮12到18小时才能呈现乳白色浓汤
💡 【营养参考】约500到700大卡每碗,蛋白质丰富,钠含量偏高
🗣️ 想了解日本各地拉面的区别吗
如果图片太模糊识别不了呢。
它会说,这张图有点模糊我看不太清楚,能再靠近一点对准拍一张吗,光线充足效果更好哦。
不装,不硬猜,这是我在提示词里反复强调的。
几个可以继续做的方向
万物生目前的版本已经能用了,但我脑子里还有不少想法没实现。
第一个是博物模式。户外徒步的时候开着这个模式,眼镜自动连续识别沿途的花草虫鸟,回来之后生成一份自然日记。想想就觉得很酷。
第二个是购物助手。逛超市的时候对着商品拍一下,自动比价,显示用户评价。这个功能如果做好了,实用性很强。
第三个是无障碍场景。之前看到报道说在德国IFA展会上,有听力和视力障碍的朋友专门去体验Rokid眼镜。对于视障群体来说,一副能实时描述眼前世界的眼镜,意义远超一个科技产品。
第四个是个人万物图鉴。把用户识别过的所有东西汇总成一本电子图鉴,看着自己认识的物种越来越多,这种收集感很容易让人上瘾.
这些方向每一个展开都是一个完整的项目。慢慢来吧。
最后说几句掏心窝的
做万物生这个项目,最大的感受是,AI眼镜这个品类正在从尝鲜玩具变成真正有用的工具.
以前大家聊AR眼镜,聊的都是概念和未来。现在有了灵珠这样的平台,有了开放的SDK,有了足够快的多模态大模型,普通开发者真的可以在上面做出有意思的东西。
万物生只是一个起点。
当你戴着眼镜走在路上,看到一棵不认识的树,一栋有故事的老楼,一道闻着就香的菜,只需要看一眼,就能知道它的名字和故事。
这种体验一旦习惯了,就再也回不去了.
如果你也想试试,灵珠AI平台的地址是 https://rizon.rokid.com ,注册就能开始。
别光看,动手吧。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)