从 DMD 到 DMD2:搞懂扩散模型的 “提速革命“
我会把大家最常问的问题,用最通俗的语言、最清晰的逻辑串起来,不讲复杂公式,只讲核心逻辑。看完你就能彻底明白:DMD 到底是什么、为什么能让扩散模型一步生成高清图、它和其他加速方法有什么不一样。

摘要:扩散模型凭借卓越的生成质量统治了 AIGC 领域,但数十步的迭代采样使其推理速度难以满足实时需求。本文从扩散模型速度瓶颈的本质出发,深入解析传统蒸馏方法的致命缺陷,系统讲解 DMD(分布匹配蒸馏)如何通过 "学规律而非抄作业" 实现一步高质量生成,并重点剖析 DMD2 的三大核心改进 —— 彻底移除回归损失、集成 GAN 对抗训练、反向模拟解决多步匹配问题,最终实现推理速度提升 500 倍且生成质量超越原教师模型的突破性成果。本文适合从事生成式 AI、模型加速与部署的开发者阅读。
本文核心知识点:
扩散模型速度瓶颈的本质原因
传统一步蒸馏 "抄作业" 思路的致命缺陷
DMD 分布匹配蒸馏的核心原理与三大组件
DMD2 的三大关键技术改进与实现细节
三代蒸馏方法的全面对比与权威实验数据
DMD/DMD2 的开源资源与落地应用前景
一、扩散模型为什么天生慢?—— 从原理看速度瓶颈
这是所有扩散加速技术要解决的根本问题,理解它才能真正明白 DMD 系列方法的革命性。
1.1 扩散模型的对称设计:训练加噪 = 推理去噪
扩散模型的核心逻辑是 **"对称的噪声添加与去除"**,可以用一个非常直观的类比理解:
- 训练阶段(前向扩散):相当于用黑板擦一步一步擦掉一幅画,总共擦 1000 次,直到黑板变成全黑(纯高斯噪声)。模型学习的是 **"每一步擦完之后,黑板的状态是什么样的"**。
- 推理阶段(反向扩散):给你一块全黑的黑板,你必须严格按照训练时的逆过程,一步一步往回画,画 1000 次才能还原出清晰的图像。
这就是扩散模型天生慢的根本原因:训练时加了多少步噪声,推理时理论上就需要多少步去噪。虽然实际应用中会用快速采样器减少步数,但本质上无法突破这个对称逻辑的限制。
1.2 扩散加速的两大技术路线:巧算 vs 重练
为了解决速度问题,行业内发展出了两条完全不同的技术路线:
表格
| 技术路线 | 代表方法 | 核心思想 | 速度上限 | 质量损失 |
|---|---|---|---|---|
| 快速采样器(巧算,不训练) | DPM++、UniPC、Euler | 用更高效的数值解法跳步采样 | 10~20 步 | 步数 < 10 时质量急剧下降 |
| 模型蒸馏(重练,改模型) | LCM、InstaFlow、DMD | 重新训练一个天生就能少步 / 一步生成的模型 | 1 步 | 优秀方法几乎无质量损失 |
显然,模型蒸馏才是实现实时生成的唯一终极方案,而 DMD 系列正是这条路线上的里程碑式工作。
1.3 生成质量的金标准:FID 与 CLIP 分数
评估生成模型的性能不能只靠人眼,行业有两个通用的量化指标:
- FID(Fréchet Inception Distance):衡量生成图像与真实图像分布的相似度,数值越低越好。FID<10 时人眼几乎无法区分真假。
- CLIP 分数:衡量生成图像与文本提示的对齐程度,数值越高越好。
二、传统一步蒸馏的致命缺陷:只会 "抄作业",不会 "学规律"
在 DMD 出现之前,所有的一步蒸馏方法都陷入了同一个死胡同:逐样本映射的死记硬背。
2.1 传统蒸馏的本质:死记硬背 "噪声→图像" 对
传统蒸馏的思路非常直接粗暴:
- 用原教师扩散模型跑 50 步,生成 100 万张图像,得到 100 万对
(噪声z, 图像y) - 训练一个学生模型,输入噪声 z,直接输出图像 y
- 用 MSE(逐像素误差)或 LPIPS(感知误差)损失,让学生的输出尽可能接近老师的输出
2.2 为什么这种方法注定失败?
高维图像空间的复杂度远超我们的想象,100 万对样本连冰山一角都覆盖不了,这导致传统蒸馏存在三个无法解决的问题:
- 泛化能力极差:遇到训练集中没有的噪声,学生就会生成乱码或完全不相关的图像
- 模式崩溃严重:学生只会生成训练集中最常见的几种模式,比如只会画猫,不会画狗
- 细节丢失严重:死记硬背的结果永远不如老师一步步推导出来的精细
这就像学数学:传统蒸馏是背下来 100 道题的答案,考试遇到新题直接崩盘;而 DMD 是学会了数学公式和解题思路,任何题都能自己解。
三、DMD 的核心革命:从 "逐样本映射" 到 "分布级匹配"
DMD(Distribution Matching Distillation,分布匹配蒸馏)是 2024 年 CVPR 的最佳论文候选之一,它彻底颠覆了传统蒸馏的思路,实现了几乎无质量损失的一步生成。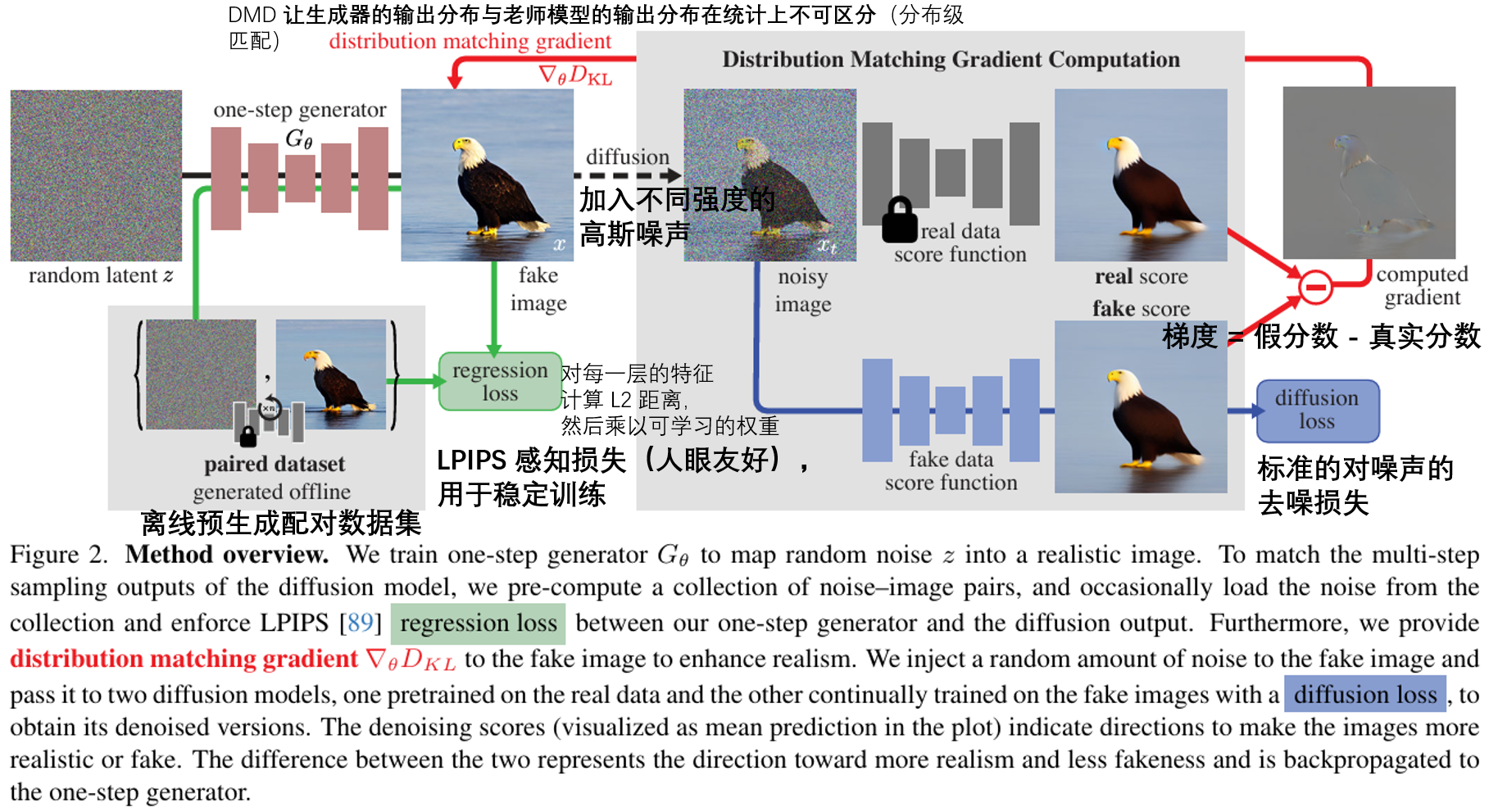
3.1 一句话讲透 DMD 的核心思想
让一步生成器学习真实图像的整体分布规律,而不是死记硬背老师生成的某一张具体图像。
还是用学画画的类比:
- 传统蒸馏:照着老师画好的 100 幅画一笔一划抄
- DMD:看老师画了 100 幅画,总结出 "人有两只眼睛、鼻子在中间、太阳是圆的" 这些普适规律,然后自己就能画出任何符合规律的画
3.2 DMD 的三大核心组件
DMD 的框架非常简洁,只有三个核心部分,却实现了革命性的效果。
组件 1:一步生成器 Gθ —— 天生一步出图,不是 "步数设为 1"
这是最容易被误解的点:DMD 的一步生成器绝对不是把采样器的步数设为 1。它输入高斯噪声,直接输出干净的图像,不需要任何采样器。
结构改造(简单到离谱):
- 和原扩散模型的 UNet 架构完全相同
- 只做了一个改动:移除了时间步 t 的输入
- 原因:一步生成器不需要知道 "现在画到第几步了",直接输出最终结果即可
初始化方式:直接复制原教师模型的权重进行微调,大大降低了训练难度,保证了初始生成质量。
组件 2:双分数模型 —— DMD 的灵魂,两个裁判教你画画
这是 DMD 最核心的创新,也是它能实现高质量一步生成的关键。
什么是 "分数"?你可以把它理解成 **"画画的方向指引"**:
- 真分数 sreal:由固定不动的教师模型计算,告诉你 "往这个方向改,画会更像真的"
- 假分数 sfake:由一个动态训练的模型计算,告诉你 "往这个方向改,画会更像假的"
DMD 的核心梯度公式:
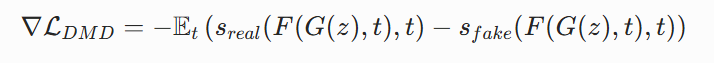
简单来说就是:真分数拉着你往真图靠,假分数推着你远离假图,两者一结合,生成的图像就会越来越接近真实分布。
组件 3:LPIPS 正则 —— 防止偏科的稳定器
纯靠双分数进行分布匹配有一个小问题:生成器容易 "偏科",只生成几种最常见的模式(模式崩溃)。
DMD 用一个非常轻量的方法解决了这个问题:加入LPIPS 感知损失作为正则项。
- 提前用教师模型生成少量(几万对)"噪声 - 图像" 对
- 训练时让生成器的输出和教师的输出在视觉特征层面尽可能相似
- 权重很小(总损失的 1/4),只起辅助稳定作用,不会限制生成器的创造力
3.3 DMD 的完整训练流程(5 步走)
DMD 的训练流程非常清晰,核心是两条数据流并行训练:
- 初始化:加载预训练教师模型并冻结;复制两份权重得到一步生成器Gθ和假分数模型μfake;预生成少量 "噪声 - 图像" 对用于 LPIPS 正则。
- 数据采样:采样两批数据 —— 纯随机噪声 z(用于分布匹配)和预存的 "噪声 z_ref→图像 y_ref" 对(用于 LPIPS 正则)。
- 图像生成:用生成器分别生成x=Gθ(z)和xref=Gθ(zref)。
- 更新生成器:计算分布匹配损失和 LPIPS 损失,总损失 = 分布匹配损失 + 0.25 × LPIPS 损失,反向传播更新Gθ。
- 更新假分数模型:给生成的假图像 x 加随机噪声,让μfake学习去噪,保证它能实时跟踪当前生成器的输出分布。
四、DMD 的致命痛点:成也正则,败也正则
DMD 虽然实现了接近原模型的一步生成,但它有一个致命的遗留问题,这个问题让它在大规模应用上举步维艰,也限制了它的性能上限 ——就是它用来稳定训练的 LPIPS 回归损失。
这个问题有多严重?
- 训练成本爆炸:为了保证训练稳定,DMD 需要提前用教师模型生成数百万甚至上千万对 "噪声 - 图像"。对于 SDXL 这种大模型来说,生成 1200 万对样本需要整整700 个 A100 天,光是数据准备的成本就超过了 DMD2 总训练成本的 4 倍。
- 质量上限被锁死:回归损失相当于给学生套上了一个紧箍咒 —— 它永远不能画出老师没画过的东西,质量上限被死死绑定在老师的采样路径上,永远不可能超越老师。
- 仅支持单步生成:原 DMD 的框架只能支持一步生成,对于 SDXL 这种特别复杂的大模型,一步很难学会所有细节,生成质量会明显下降。
五、DMD2 的终极进化:彻底解决痛点,实现 "青出于蓝而胜于蓝"
2024 年 5 月,同一支团队推出了 DMD 的进化版 ——DMD2,彻底解决了上述所有痛点,并且实现了一个所有人都不敢想的目标:让学生模型的生成质量超越原教师模型。
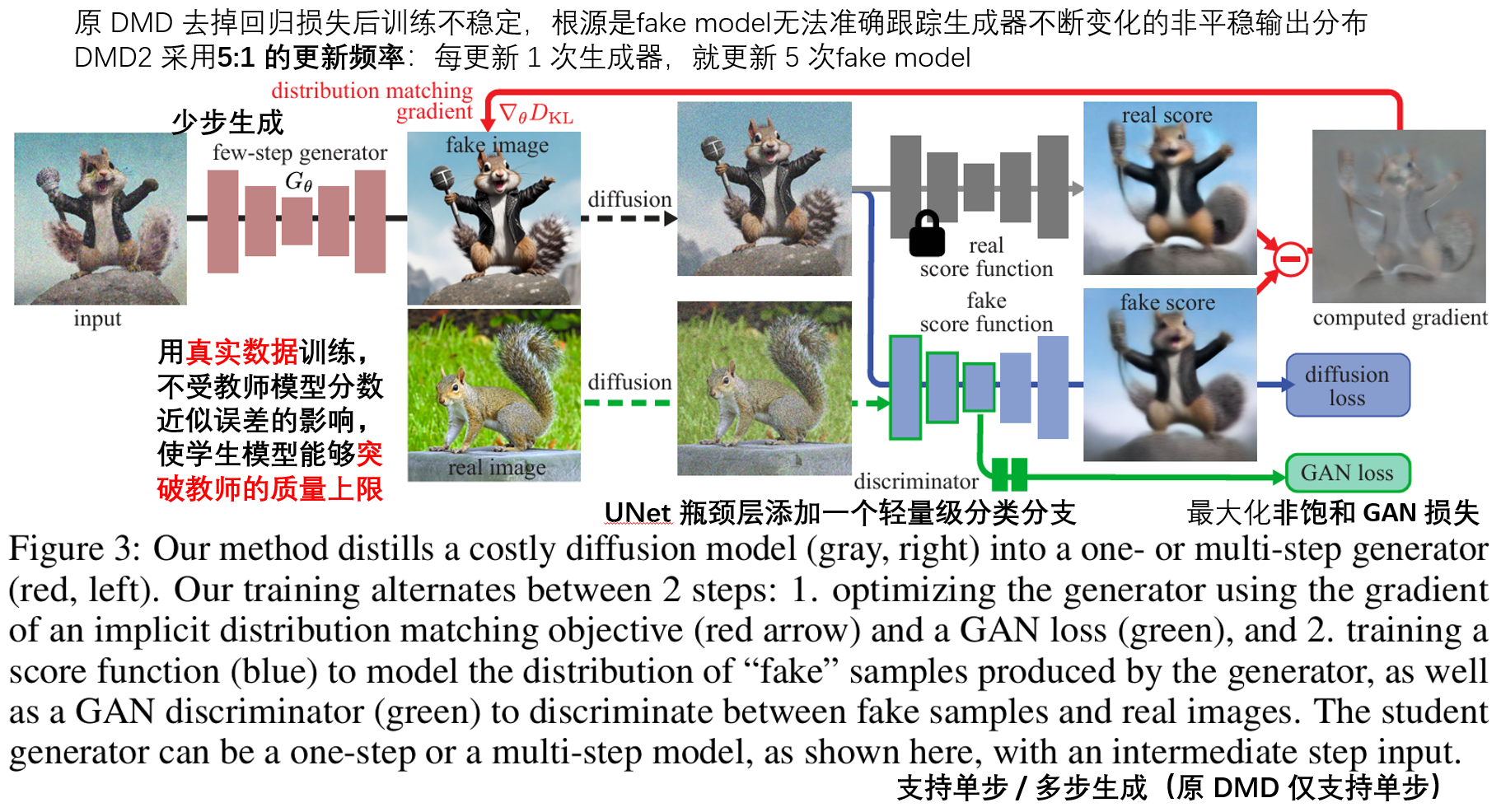
5.1 改进 1:彻底移除回归损失,用双时间尺度更新稳定训练
DMD2 做的第一件事,就是彻底扔掉了 LPIPS 回归损失,也彻底消除了预生成海量数据的需求。
但直接扔掉回归损失会导致训练严重不稳定:生成器的输出分布一直在快速变化,假分数模型(假图裁判)根本跟不上,导致裁判判错,训练就会崩溃。
DMD2 的解决方法简单到离谱:让裁判比选手跑得快。
- 原 DMD:假分数模型和生成器同步更新(更新频率 1:1)
- DMD2:每更新 1 次生成器,就更新 5 次假分数模型(更新频率 5:1)
就这么一个小小的改动,就彻底解决了训练不稳定的问题。实验证明,这个方法能让无回归损失的 DMD 在 ImageNet 上的 FID 从 3.48 恢复到 2.61,和原 DMD 完全相当,而且收敛速度更快。
5.2 改进 2:集成 GAN 对抗训练,让学生能纠正老师的错误
原来的 DMD 只有两个 AI 裁判(真分数和假分数),它们都是从教师模型衍生出来的,老师犯的错,它们也会犯。
DMD2 加了第三个裁判 —— 一个直接看真实图像的 GAN 判别器。这个裁判不看老师怎么画,只看真实世界的图长什么样。这样一来,学生不仅能学会老师的优点,还能纠正老师的错误,甚至画出比老师更好的图。
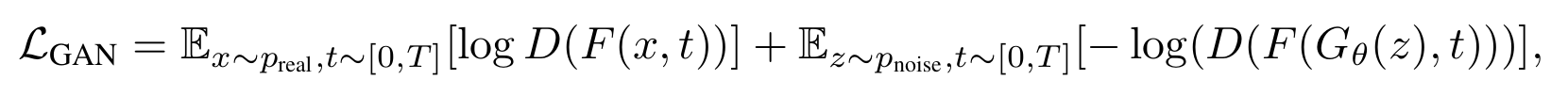
GAN 判别器的巧妙设计:
- 直接附加在假分数模型的 UNet 瓶颈层,不需要额外训练一个独立的大模型
- 几乎没有增加计算成本,却带来了巨大的质量提升
- 采用标准的非饱和 GAN 损失,训练稳定且效果好
5.3 改进 3:支持多步生成,用反向模拟解决训练 - 推理不匹配
原 DMD 只能做一步生成,对于 SDXL 这种大模型来说,一步很难学会所有细节。DMD2 扩展支持了 2 步、4 步生成,让用户可以在速度和质量之间自由权衡。
更重要的是,DMD2 解决了所有多步蒸馏方法都有的一个通病:训练和推理环境不匹配。
- 传统多步蒸馏:训练时用真实图像加噪作为输入,但推理时用前一步生成的假图像作为输入,相当于 "平时练的是真题,考试考的是模拟题",学生当然考不好。
- DMD2 反向模拟:训练时就模拟推理环境,用学生自己生成的中间结果作为输入,相当于 "平时练的就是考试题",考试自然能考高分。
这个技术让 DMD2 的 4 步 SDXL 模型的 Patch FID(衡量高分辨率细节的指标)从 24.21 直接降到了 20.86,细节质量提升了 14%。
六、三代蒸馏方法全面对比:从抄作业到超越老师
表格
| 对比维度 | 传统一步蒸馏 | 原 DMD | DMD2 |
|---|---|---|---|
| 训练目标 | 逐样本映射(抄单张图) | 匹配教师分布(学老师的规律) | 匹配真实分布(学世界的规律) |
| 核心损失 | 仅回归损失 | 分布匹配损失 + 回归损失 | 分布匹配损失 + GAN 损失 |
| 梯度来源 | 教师的单步输出 | 教师分布 - 假分布 | 真实分布 + 教师分布 - 假分布 |
| 预生成数据需求 | 极高(百万级) | 中(十万级) | 无 |
| 模式崩溃风险 | 高 | 极低 | 极低 |
| 质量上限 | 远低于教师 | 等于教师 | 超越教师 |
| 支持生成步数 | 单步 | 仅单步 | 单步 / 2 步 / 4 步 |
| 训练 - 推理匹配度 | 差 | 好(单步) | 完美(单步 / 多步) |
| ImageNet-64×64 单步 FID | >6 | 2.62 | 1.28 |
| SD v1.5 单步 COCO FID | >15 | 11.49 | 8.35 |
七、DMD2 的炸裂实验结果:速度快 500 倍,质量超越原模型
DMD2 的效果有多夸张?我们用论文中最权威的实验数据说话:
- 类条件生成(ImageNet-64×64):单步 FID 达到1.28,不仅远超原 DMD 的 2.62,还超越了需要 511 步的原 EDM 教师模型(FID 2.32)。
- 文本生成(SD v1.5):单步 FID 达到8.35,超越了需要 50 步的原 SD v1.5 教师(FID 8.59),推理速度提升约 500 倍。
- 文本生成(SDXL):4 步 FID 达到19.32,Patch FID 达到20.86,均超越了需要 100 步的原 SDXL 教师,速度却快了 25 倍。
- 用户研究:62% 的评估者认为 DMD2 生成的图像质量优于原 SDXL 教师,50.5% 认为其文本对齐更好。
八、总结与展望
从 DMD 到 DMD2,我们看到了扩散蒸馏技术的一次质的飞跃。
DMD 打破了 "扩散模型必须多步生成" 的神话,证明了一步生成可以媲美多步;而 DMD2 则打破了 "学生永远不如老师" 的神话,证明了蒸馏不仅能加速,还能提升质量。它彻底消除了大规模蒸馏的成本障碍,让快速高质量的图像生成真正走向了实用化。
未来展望:
- 低成本蒸馏:结合 LoRA 技术,将 DMD2 的训练成本降低到普通研究者也能承受的水平
- 视频生成扩展:将 DMD2 的思想应用到视频扩散模型,实现实时视频生成
- 多模态扩展:扩展到 3D 生成、语音生成等其他模态
- 实时应用落地:在实时 AI 绘画、游戏内容生成、视频通话美颜等领域实现大规模应用
资源汇总:
- DMD 论文:https://arxiv.org/abs/2311.18828
- DMD2 论文:https://arxiv.org/abs/2405.14867
- DMD 非官方实现:https://github.com/devrimcavusoglu/dmd
- DMD2 官方代码与预训练模型:https://tianweiy.github.io/dmd2/
你在项目中用过哪些扩散加速方法?DMD2 的哪些特性最让你心动?欢迎在评论区分享你的经验和看法~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)