从0开始构建大语言模型——以《凡人修仙传小说》为例
从0开始构建大语言模型
1 认识大语言模型
1.1 什么是LLM
大语言模型(LLM)是一种以深度神经网络为基础而构建,专注于理解、生成和响应人类文本输入的AI模型(相对的图像类的模型为VLM),典型的代表有GPT,Deepseek等。LLM相对于传统的DNN其主要体现在“大”,特别是其庞大的模型参数规模和天量的训练数据。从不同的AI领域的划分来看,LLM是深度学习领域的应用,是机器学习的一小块,更是人工智能领域的一种方法。另外,LLM相比于早期的NLP模型,其核心优势为泛化能力,早期的模型多为特性类型的任务设计,而LLM展现出多任务的能力。
LLM的核心训练任务是利用语言序列特性捕捉文本的上下文,结构和语义关系,来预测目标序列的下一个word。但是LLM并不意味着其具有人类的理解能力,而是通过大量的数据理解文本信息进而能以连贯、符合人类语言习惯的方式处理和生成文本。
LLM自从出现以来,其发展速度非常快,从最早期的专注于理解非结构化文本,到现如今(2026/03)能够理解复杂任务,复杂图像和视频。现在已知的一些应用场景有:
- 专业知识检索和问答。比如google search ai;
- 视频理解和生成。比如OpenAI的sora,ByteDance的SeedDance等;
- 原创内容的生成。比如llm写小说,设计海报等。
- coding。claude code,minmax等。
需要注意的是,本文不会对神经网络的基本概念和相关基本结构进行过多描述,对于文中不清楚的内容建议查阅相关资料。
1.2 LLM结构
Transformer是LLMs结构的基石,Transfomer的结构出自于2017年Google的Attention Is All You Need,文章中提出的模型在翻译任务上的性能超过了之前比较常用的RNN网络。
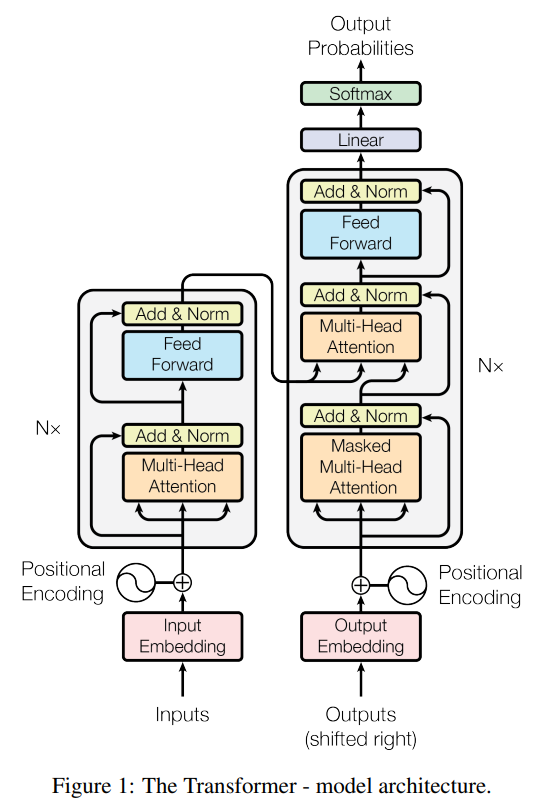
Transformer的结构主要包括编码器和解码器两部分,编码器和解码器的结构基本相同,都是由多个相同的层组成。每个层由两个子层组成,第一个子层是多头自注意力机制(Multi-Head Self-Attention),第二个子层是前馈神经网络(Feed-Forward Neural Network)。
编码器由6个相同的层堆叠而成,每层包含两个子层:多头注意力层和前馈神经网络。多头注意力层允许模型在处理输入序列时关注序列中的不同部分,以捕捉长程依赖关系,而前馈神经网络则通过多层感知机来增强模型的表达能力。为了丰富特征信息量每个子层使用残差连接。每个子层的输出通过以下公式计算: L a y e r N o r m ( x + S u b l a y e r ( x ) ) LayerNorm(x+Sublayer(x)) LayerNorm(x+Sublayer(x))。其中, S u b l a y e r ( x ) Sublayer(x) Sublayer(x)是子层本身实现的函数。所有子层和嵌入层的输出维度均为 512。解码器同样由N=6个相同的层堆叠而成,除了编码器中包含的两个子层,解码器还包含第三个子层,即编码器-解码器注意力层。编码器-解码器注意力层允许解码器在生成输出序列时关注编码器的输出,以捕捉输入序列和输出序列之间的关系。
主流 LLM 架构以Transformer为基础,分化为仅编码器、仅解码器、编码器-解码器、前缀解码器四大经典范式;2026 年主流模型普遍在仅解码器基础上叠加MoE、Mamba/SSM、长上下文优化等技术,形成混合架构。
| 架构类型 | 核心思想 | 注意力机制 | 代表模型 | 擅长任务 | 目前地位 |
|---|---|---|---|---|---|
| Encoder-Only | 双向编码理解 | 全双向注意力 | BERT、RoBERTa | 分类、匹配、抽取 | 偏向NLP基础任务 |
| Decoder-Only | 自回归生成 | 因果掩码(单向) | GPT、Llama、Claude、Qwen、Mistral | 对话、写作、代码、推理 | 生成式LLM绝对主流 |
| Encoder-Decoder | 编码+解码+交叉注意力 | 双向+单向+交叉 | T5、BART | 翻译、摘要、改写 | 逐渐被Decoder-Only替代 |
| Prefix-Decoder | 前缀双向+生成单向 | 混合注意力 | GLM、ChatGLM | 填空、续写、对话 | 中文开源常用 |
| MoE 架构 | 稀疏混合专家 | 因果+稀疏激活 | GPT‑4、Llama 4、DeepSeek、Qwen MoE | 大模型、长文本、推理 | 超大规模模型标配 |
| Mamba/SSM | 线性时序状态模型 | 线性复杂度 | Mamba、Jamba、DeepSeek V4 | 超长上下文、速度优化 | 下一代架构热门方向 |
1.3 构建和使用大语言模型的步骤
创建 LLM 的核心过程分为预训练和微调两个阶段,是一种 “先通用后专用” 的两阶段训练方法:
- 预训练:打造基础模型:使用无标注的原始海量文本数据(如互联网文本、书籍、维基百科等)进行训练,核心任务是让模型学习预测文本中的下一个单词;
- 微调:适配特定任务:微调是在预训练基础模型的基础上,使用更小的标注数据集进行专门训练,让模型适配特定任务或领域。微调的核心是在保留模型基础语言能力的前提下,优化其在目标任务上的表现,主要分为两种类型:
- 指令微调:标注数据集为 “指令 - 答案” 对,适用于翻译、问答、文本生成等交互式任务;
- 分类任务微调:标注数据集为 “文本 - 类别标签” 对,适用于垃圾邮件分类、情感分析、文档分类等任务
微调的实现方式主要有两种,可根据数据量和训练需求选择:
- 全权重微调:调整模型的所有预训练权重,仅做微小修改,能最大程度适配目标任务,保持语言生成能力;
- 冻结部分权重微调:冻结学习到基础语言特征的低层权重,仅调整高层权重,适用于数据量较小(避免过拟合)或需要加速训练的场景。
LLM 的强大能力,离不开规模大、多样性高的预训练数据集,这类数据集涵盖数十亿甚至数万亿个 token,涉及自然语言、计算机语言等多种类型,覆盖各类主题和知识领域。比如GPT-3 作为 ChatGPT 的基础模型,其预训练数据集总计包含约 5090 亿个 token,实际训练使用 3000 亿个 token,其中仅 CommonCrawl 数据集就包含 4100 亿个 token,存储量约 570GB。后续的 LLM(如 Meta 的 LLaMA)还在数据集中加入了 Arxiv 研究论文、StackExchange 代码问答等专业数据,进一步丰富了数据多样性。
本文将参考《Build a Large Language Model》从0构建一个类似GPT的LLM。
2 文本处理
LLM无法直接处理离散的原始文本,需将其转换为连续值向量,而对应的技术就是词嵌入(Embeding)。词嵌入就是把文本里的词、句子、段落,通过模型映射成固定长度的稠密向量,让计算机能像处理数字一样理解语义:向量相近代表意思相似,可直接用于检索、分类、聚类、相似度计算。
| 数据类型 | 典型嵌入模型/方案 | 输出维度 | 擅长场景 |
|---|---|---|---|
| 通用文本 | BGE-base/small, m3e-base, text-embedding-ada-002 | 768/512 | 语义检索、问答、文档匹配、通用NLP |
| 长文本/文档 | BGE-M3, GTE-Large, E5-large | 1024/768 | 长文档、论文、书籍、多段落语义理解 |
| 代码 | CodeBERT, StarCoder-Embed, CodeGen-Emb | 768 | 代码检索、代码相似度、代码问答 |
| 图像 | CLIP-ViT, ResNet+投影, DINOv2 | 512/768 | 图文检索、图像分类、图像相似度、多模态 |
| 图文多模态 | CLIP, Align, AltCLIP | 512/768 | 图搜图、文搜图、图文跨模态检索 |
| 音频/语音 | Whisper-Embed, CLAP, Wav2Vec2 | 512/768 | 语音检索、声纹匹配、音频内容理解 |
| 表格/结构化 | TabNet, T5-Table, 结构化字段拼接+文本嵌入 | 不定 | 表格检索、结构化数据语义匹配 |
| 视频 | VideoCLIP, ViViT, 帧特征融合 | 768/1024 | 视频检索、视频片段匹配、动作理解 |
| 3D点云 | PointNet++, DGCNN, 3D-CLIP | 不定 | 3D模型检索、点云分类、三维匹配 |
而针对文本数据Embeding的步骤包括拆分单词,单词转换成token,token embeding。
2.1 单词拆分
第一步是将文本拆分成一个个单词。文本拆分比较简单,一般使用正则就可以,特别是类似英语这种有明显分割符的语言,下面就是一个简单的英文分词的例子:
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
# output: ['I', 'HAD', 'always', 'thought', 'Jack', 'Gisburn', 'rather', 'a', 'cheap', 'genius', '--', 'though', 'a', 'good', 'fellow', 'enough', '--', 'so', 'it', 'was', 'no', 'great', 'surprise', 'to', 'me', 'to', 'hear', 'that', ',', 'in']
但是对于中文这种没有明显的词语分隔符的语言,无法直接通过正则进行单词拆分。只能借助中文分词库,分词库类似成语和词语字典,能够正确识别常用的词语和成语。开源有很多好用的分词库,比如jieba,pkuseg,THULAC,hanlp等,不同的分词库的性能,丰富度等不一样,根据自己的场景选择就行了,这里我选择jieba。而具体的文本我直接使用《凡人修仙传小说》:
《凡人修仙传小说》内容是网络获取,只用来学习使用。
def split_word(content):
print("total number of character:", len(content))
print("content[:100]:", content[:100])
# ---------- 标点切分 ----------
# 保留标点
pattern = r"[\u4e00-\u9fa5]+|[a-zA-Z0-9]+|[,。!?;:、“”‘’()《》—…,.!?;:]"
tokens = re.findall(pattern, content)
# ---------- 中文分词 ----------
result_tokens = []
for token in tokens:
if re.match(r"[\u4e00-\u9fa5]+", token):
words = jieba.lcut(token)
result_tokens.extend(words)
else:
result_tokens.append(token)
print("分词示例:", result_tokens[:200])
return result_tokens
借助外部分词库,我们能够得到一个还不错的分词结果:
'仙路', '出现', '在', '了', '他', '的', '脚下', ',', '破解', '门派', '覆灭', '之噩', ',', '破解', '自身', '的', '困局', ',', '他', '冲出', '江湖', ',', '进入', '修仙', '界', '。', '仙缘', '难定', ',', '他', '以', '这样', '的', '身份', ',', '如何', '在', '门派', '中', '立足', '?', '又', '如何', '以', '平庸', '的', '资质', ',', '进入', '到', '修仙', '强者', '的', '行列', '?', '一个', '神奇', '的', '小绿瓶', ',', '让', '他', '拥有', '了', '一丝', '变强', '的', '机会', ',', '通过', '不断', '发掘', '它', '的', '潜力', ',', '再', '加上', '自身', '努力', ',', '以及', '天性', '的', '谨慎', ',', '他', '战战兢兢', '的', '在', '残酷', '的', '修真界', '生存', '下来', ',', '抓住', '每', '一次', '机会', '提升', '自己', '的', '实力', '。', '大浪淘沙', ',', '终现', '真金', ',', '当', '数十年', '数百', '数千年', '之后', ',', '这个', '普通', '的', '小子', '却', '如同', '宝剑', '出鞘', ',', '和', '仙宗', '仙师', '并列', '于山', '海内外', '!', '曾经', '的', '山野', '穷小子', ',', '今日', '纵横', '三界', '的', '韩', '老', '魔']
但是从上面的结果中也能看出来,并不是所有词都能正确分词,比如'韩', '老', '魔',这是因为这个词不是常见的词语。jieba也支持导入自定义的词汇,具体做法参考jieba-github,添加后就可以正常分词了,比如:
def load_preconfig():
jieba.load_userdict(os.path.join(res_path, "user_dict.txt"))
# '今日', '纵横', '三界', '的', '韩老魔', ',', '一切']
在开发一个简单的分词器时,是否将空白字符编码为单独的字符,或者直接将其删除,取决于具体的应用和需求。删除空白字符可以减少内存和计算资源的消耗。然而,如果训练的模型对文本的确切结构敏感(例如,Python 代码对缩进和空格非常敏感),那么保留空白字符就很有用。
2.2 tokenizer
将文本内容拆分成单词(token)后,就需要将每个token转换成模型能够识别的向量,即tokenid。tokenid的转换也比较简单,就是建立一个词汇表,将每一个token映射到对应的id上。
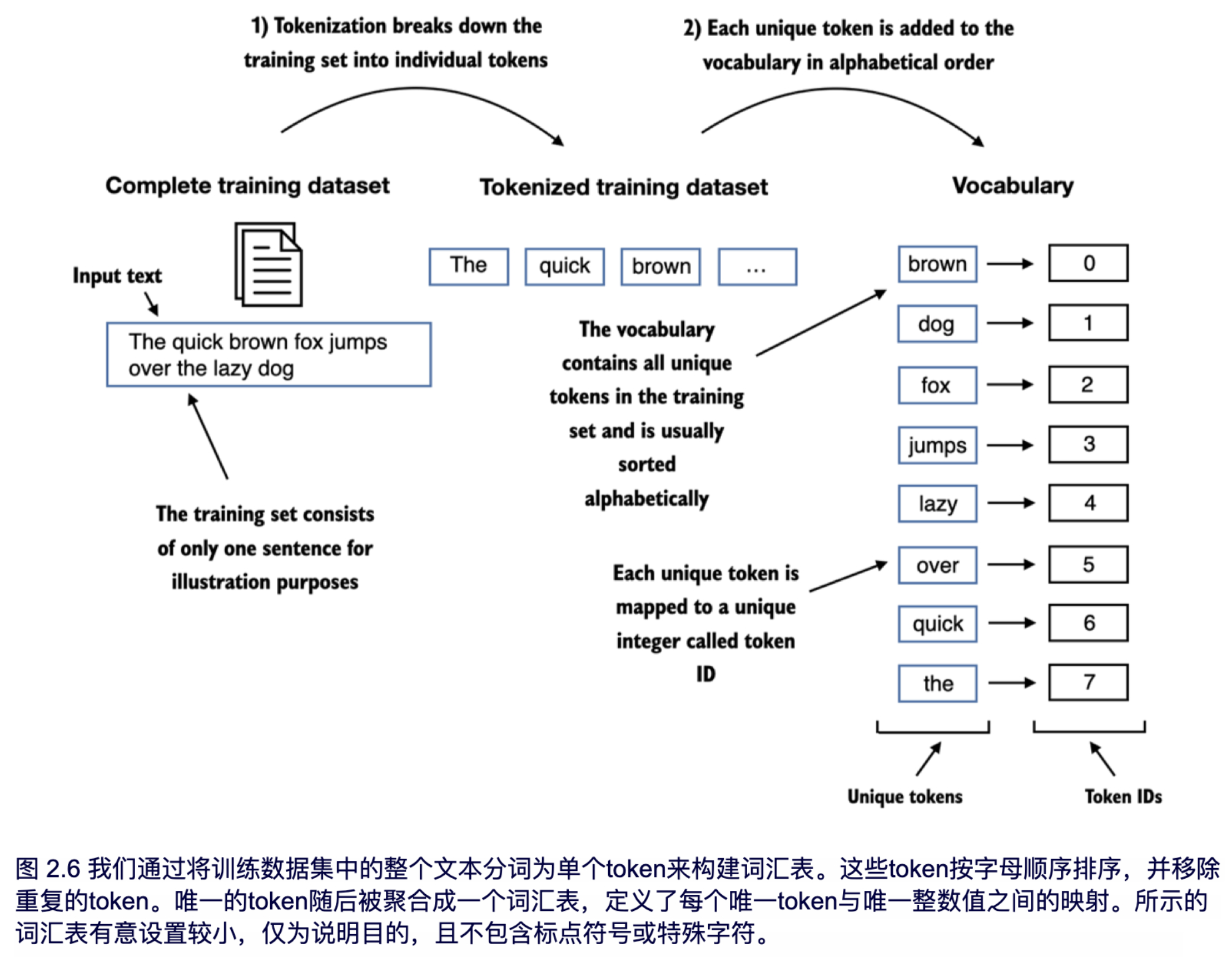
代码比较简单就是利用set去重然后排序:
def convert_content2tokenid(content, token_table):
token_table = sorted(set(token_table))
print("词汇表有", len(token_table))
vocab = {token:integer for integer,token in enumerate(token_table)}
for i, item in enumerate(vocab.items()):
print(item)
if i > 50:
break
下面是部分词汇表的内容,接下来只需要将原来的文本内容使用词汇表一一映射为实际的tokenid就行。
词汇表有 24967
('1', 0)
('12', 1)
('2', 2)
('7', 3)
('—', 4)
('‘', 5)
('’', 6)
('“', 7)
('”', 8)
('…', 9)
('、', 10)
除了输入的文本的词汇表以外,还需要提供一些特殊标记来控制文本处理和生成流程,比如:
[BOS]:作为生成起点:在自回归模型(如 GPT、Llama)中,模型预测第一个词时需要初始状态,[BOS] 提供这个 “启动信号”,即计算 P(第一个词 | [BOS])。[EOS]:模型生成时遇到 [EOS] 立即停止,避免无限循环。[PAD]:将不同长度的序列填充到相同长度,以支持批量(Batch)计算;模型在注意力与损失计算中会忽略该符号。[UNK]:表示词汇表外的词(Out-of-Vocabulary, OOV),处理未见过的生僻词、符号或乱码。[SEP]:分隔不同句子 / 片段(如 BERT 的句对任务),模型借此区分上下文边界。[MASK]:掩码语言模型(MLM)专用(如 BERT),训练时随机替换部分词为 [MASK],让模型预测被掩盖的词。
支持的方式比较简单,extend到词汇表中就行,这里只支持<|unk|>,<|endoftext|>。将上面的代码整理为:
class SimpleTokenizer:
def __init__(self, user_dict=None):
if user_dict and os.path.exists(user_dict):
jieba.load_userdict(user_dict)
self.vocab = {}
self.id2token = {}
self.unk_token = "<|unk|>"
self.eos_token = "<|endoftext|>"
def tokenize(self, content):
pattern = r"<\|endoftext\|\>|[\u4e00-\u9fa5]+|[a-zA-Z0-9]+|[,。!?;:、“”‘’()《》—…,.!?;:]"
tokens = re.findall(pattern, content)
result_tokens = []
for token in tokens:
if token == self.eos_token:
result_tokens.append(token)
elif re.match(r"[\u4e00-\u9fa5]+", token):
result_tokens.extend(jieba.lcut(token))
else:
result_tokens.append(token)
return result_tokens
def build_vocab(self, content):
tokens = self.tokenize(content)
vocab_set = set(tokens)
vocab_set.discard(self.unk_token)
vocab_set.discard(self.eos_token)
vocab_list = [self.unk_token, self.eos_token] + sorted(vocab_set)
self.vocab = {t: i for i, t in enumerate(vocab_list)}
self.id2token = {i: t for t, i in self.vocab.items()}
print("vocab size:", len(self.vocab))
def encode(self, content):
tokens = self.tokenize(content)
ids = [ self.vocab.get(token, self.vocab[self.unk_token]) for token in tokens ]
return ids
def decode(self, ids):
tokens = [ self.id2token.get(i, self.unk_token) for i in ids ]
return tokens
def save_vocab(self, path):
with open(path, "w", encoding="utf8") as f:
json.dump(self.vocab, f, ensure_ascii=False)
def load_vocab(self, path):
with open(path, "r", encoding="utf8") as f:
self.vocab = json.load(f)
self.id2token = {i: t for t, i in self.vocab.items()}
运行之后的结果如下:
vocab size: 24969
token ids: [4501, 3447, 3040, 3298, 24966, 10844, 4116, 24966, 52, 13832, 17358, 9611, 18391, 24965, 24160, 24965, 7256, 20041, 5814, 17358, 10333, 1048, 24965, 21548, 9632, 24965, 21724, 2222, 52, 15373, 9241, 23486, 24965, 11485, 2222, 173, 23445, 17358, 21042, 10345, 24965, 52, 23653, 24965, 21020, 2801, 11476, 17358, 10245, 3447]
tokens: ['凡人', '修仙', '传', '作者', ':', '忘语', '内容简介', ':', '一个', '普通', '的', '山村', '穷小子', ',', '韩立', ',', '在', '自己', '叔叔', '的', '引荐', '下', ',', '走出', '山野', ',', '跨入', '了', '一个', '江湖', '小', '门派', ',', '成为', '了', '一名', '长老', '的', '记名', '弟子', ',', '一个', '阴谋', ',', '让', '他', '懵懵懂懂', '的', '开始', '修仙']
原文也提到了字节对编码(BPE),但是只是利用第三方库,这里我就不多介绍了,有兴趣直接看tiktoken-github
2.3 token embeding
LLM 预训练的核心任务是预测下一个单词,需将 token ID 转换为输入 - 目标对作为训练数据。
目标数据实际上就是以1为步长向前移动的序列。具体实现以指定的最大序列长度max_length和滑动步长stride对 token 序列进行滑动窗口切分,生成一一对应的输入序列和目标预测序列(输入序列向后偏移一个 token 即为目标序列)。
class GPTDataset(Dataset):
def __init__(self, txt, tokenizer, max_length=128, stride=64):
"""
txt: 原始文本
tokenizer: SimpleTokenizer
max_length: 每个序列长度
stride: 滑动窗口步长
"""
self.input_ids = []
self.target_ids = []
token_ids = tokenizer.encode(txt)
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i: i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append( torch.tensor(input_chunk, dtype=torch.long) )
self.target_ids.append( torch.tensor(target_chunk, dtype=torch.long) )
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
def create_dataloader(txt, tokenizer, batch_size=4, max_length=128, stride=64, shuffle=True):
dataset = GPTDataset( txt, tokenizer, max_length, stride)
dataloader = DataLoader( dataset, batch_size=batch_size, shuffle=shuffle, drop_last=True)
return dataloader
2.3 token embeding
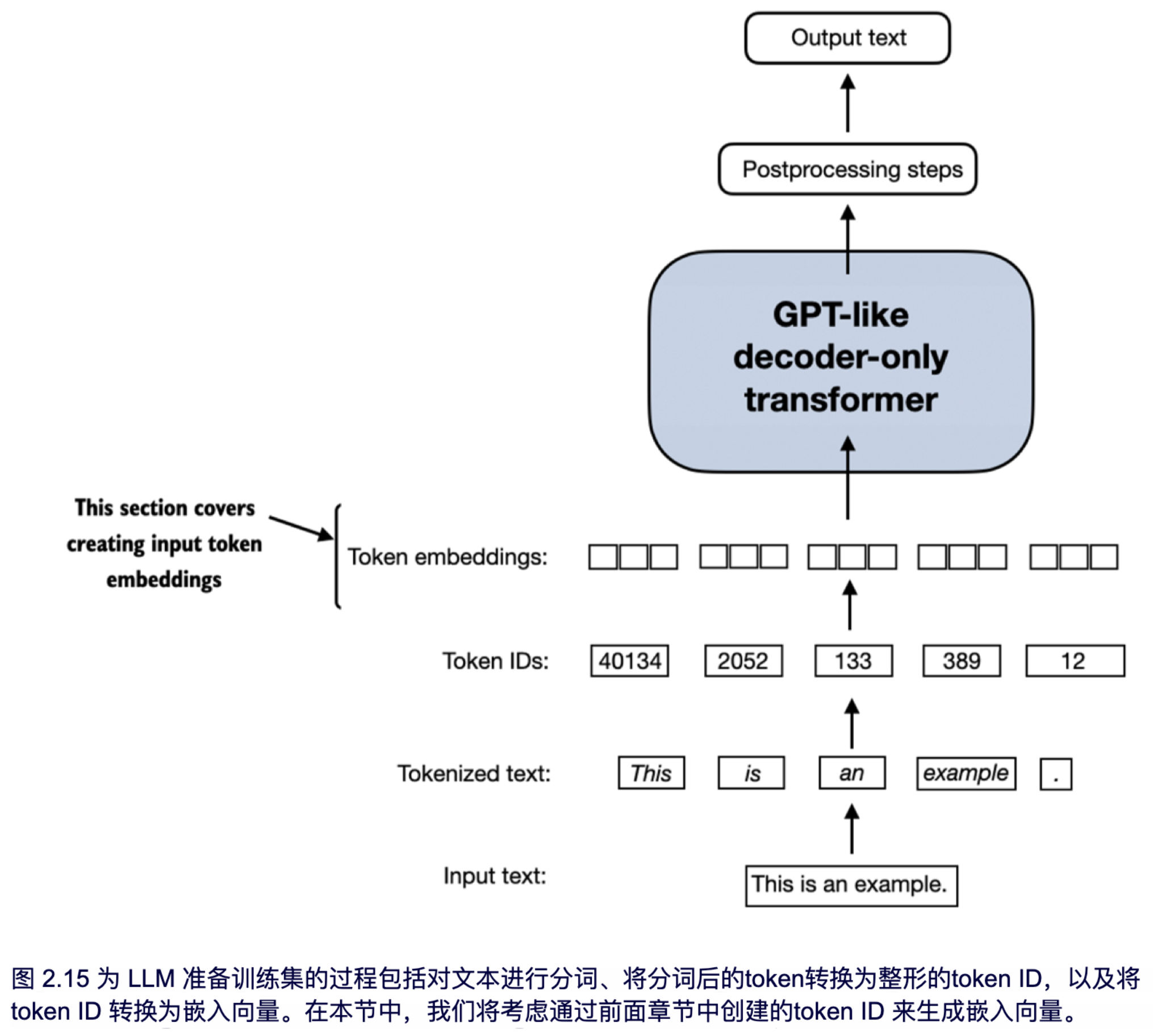
GPT 系列模型(GPT-1/2/3/4)的 Embedding 层是整个神经网络的入口模块,核心作用是将离散的文本 Token ID 转换为模型能处理的连续向量,并注入位置信息。它由 Token Embedding + Position Embedding 两部分组成,最终通过加法融合输出。因此这一小节,主要关注Token Embedding和Position Embedding模块。
Token Embedding
Token Embedding 用于将离散的文本 Token ID 映射为连续稠密向量的核心嵌入层,本质是一个可学习的参数查找表,它把无语义信息的整数索引转化为高维向量表示,让模型能够捕捉词语间的语义、语法关联,同时统一输入维度以适配后续 Transformer 结构计算。
其数学表达式为:
TokenEmb ( t ) = W e [ t ] \text{TokenEmb}(t) = W_e[t] TokenEmb(t)=We[t]
其中 (t) 为输入的 Token 索引,(W_e \in \mathbb{R}^{V \times d_{\text{model}}}) 是可学习的嵌入矩阵,(V) 为词表大小,(d_{\text{model}}) 为模型隐层维度,(W_e[t]) 表示按 Token ID 直接查表取出对应行向量。
由于是简单的查表,直接使用torch提供的就行:
embedding_layer = torch.nn.Embedding(len(tokenizer.vocab), define.embedding_dim)
Position Embedding
Position Embedding 即位置嵌入,是为弥补 Transformer 结构本身缺乏序列顺序感知能力而设计的编码方式,它为输入序列中每个位置分配一个专属向量,将位置信息注入模型,使模型能够区分词语在句子中的先后顺序,从而正确理解语序依赖关系,常见形式包括可学习的位置嵌入、正弦余弦位置编码以及旋转位置编码 RoPE 等,通常与 Token Embedding 直接相加后作为 Transformer 模块的输入。
位置编码本质上是为了让模型知道两个 token 之间隔了多远、谁在前谁在后,而不是记住 “第 5 个位置” 这种绝对坐标。Transformer 的自注意力只计算 token 之间的相似度,本身不携带顺序信息,必须靠位置编码引入相对距离关系,才能区分 “我喜欢你” 和 “你喜欢我”。像 RoPE 通过对 query 和 key 向量按位置进行旋转,让注意力分数天然包含相对位置信息;ALiBi 则直接根据相对距离对注意力分数做衰减,都不再依赖固定的绝对位置向量,也让模型能更好地处理超出训练长度的文本序列。
Token Embedding和Position Embedding的维度完全一致,最终输入 = Token Embedding + Position Embedding。Transformer本身采用的是正弦余弦位置编码。而GPT采用的可学习位置编码,实现和Token Embedding类似,只是作用有区别,使用torch提供的embedding层就行。
nn.Embedding()
3 注意力机制
3.1 自注意力机制
自注意力让序列中每个 token 都能关注序列里所有其他 token,自动学习它们之间的关联强度,从而捕捉全局依赖关系,而不像 RNN 只能按顺序逐步处理。对每个 token,生成三个向量:
- Query(查询):我要找什么
- Key(键):我是什么
- Value(值):我要提供什么信息
输入序列嵌入为 (X \in \mathbb{R}^{L \times d})
Q = X W Q , K = X W K , V = X W V Q = X W_Q,\quad K = X W_K,\quad V = X W_V Q=XWQ,K=XWK,V=XWV
其中 (W_Q,W_K,W_V \in \mathbb{R}^{d \times d_k}) 是可学习权重。
计算注意力分数:
AttnScore = Q K ⊤ \text{AttnScore} = Q K^\top AttnScore=QK⊤
维度:(L \times L),表示每个 token 对其他所有 token 的相似度。
点积会随维度增大而数值过大,Softmax 进入饱和区,因此除以 (\sqrt{d_k})来降低训练过程中梯度消失的概率:
ScaledScore = Q K ⊤ d k \text{ScaledScore} = \frac{Q K^\top}{\sqrt{d_k}} ScaledScore=dkQK⊤
通过Softmax 得到权重
A = Softmax ( Q K ⊤ d k ) A = \text{Softmax}\left(\frac{Q K^\top}{\sqrt{d_k}}\right) A=Softmax(dkQK⊤)
(A) 就是注意力矩阵,每行和为 1。
Attention ( Q , K , V ) = Softmax ( Q K ⊤ d k ) V \operatorname{Attention}(Q,K,V) = \operatorname{Softmax}\left(\frac{Q K^\top}{\sqrt{d_k}}\right) V Attention(Q,K,V)=Softmax(dkQK⊤)V
因果注意力(Causal Attention)是专为自回归语言模型设计的掩码自注意力机制,其核心是通过下三角掩码矩阵强制当前位置的 token 只能关注自身及之前位置的 token,而无法看到后续未生成的内容,以此保证文本生成的因果一致性,避免模型在预测时利用未来信息造成“信息泄露”,它在计算注意力分数时会将未来位置的分数置为负无穷,经 Softmax 后权重趋近于零,从而实现严格单向的信息流动,是 GPT 类 decoder-only 模型的核心注意力形式。
因果注意力的公式:
Attention ( Q , K , V ) = Softmax ( Q K ⊤ d k + M ) V \operatorname{Attention}(Q,K,V) = \operatorname{Softmax}\left(\frac{Q K^\top}{\sqrt{d_k}} + M\right) V Attention(Q,K,V)=Softmax(dkQK⊤+M)V
- (M) 为因果掩码矩阵,形状 ((L, L))
- 下三角(含对角线)为 (0),上三角全部为 (-\infty)
- 经 Softmax 后,未来位置权重被完全屏蔽,实现只能看过去、不能看未来
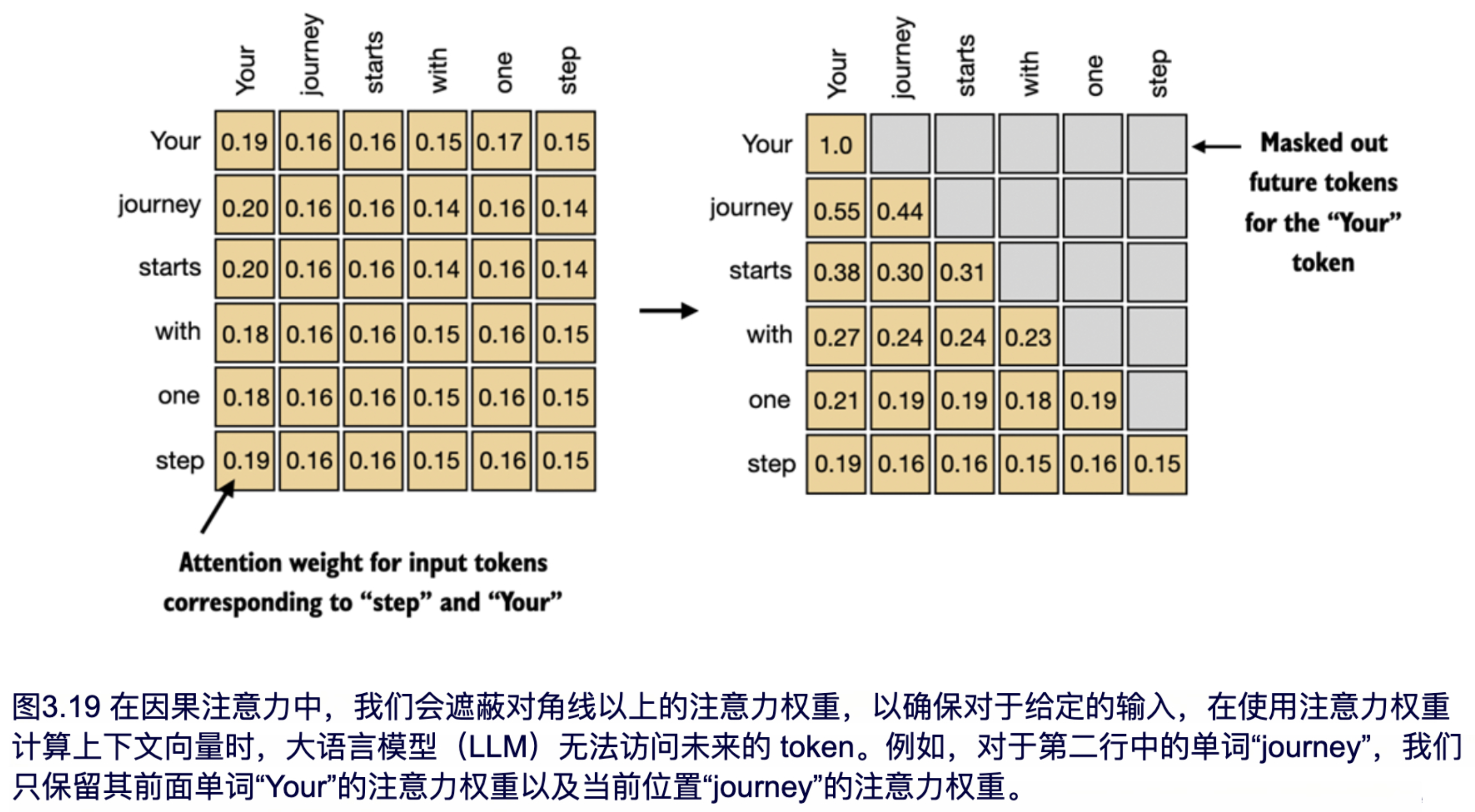
attention的实现非常简单,直接套公式就行。
class SelfAttention(nn.Module):
def __init__(self, embed_dim, dropout=0.1):
super().__init__()
self.embed_dim = embed_dim
self.query = nn.Linear(embed_dim, embed_dim)
self.key = nn.Linear(embed_dim, embed_dim)
self.value = nn.Linear(embed_dim, embed_dim)
self.out_proj = nn.Linear(embed_dim, embed_dim)
self.scale = math.sqrt(embed_dim)
self.attn_dropout = nn.Dropout(dropout)
self.out_dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
Q = self.query(x)
K = self.key(x)
V = self.value(x)
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / self.scale
print(attn_scores)
print(mask)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, float('-inf'))
print(attn_scores)
attn_weights = F.softmax(attn_scores, dim=-1)
attn_weights = self.attn_dropout(attn_weights)
attn_output = torch.matmul(attn_weights, V)
output = self.out_proj(attn_output)
output = self.out_dropout(output)
return output, attn_weights
如果要开启因果注意力,将代码中mask设置为对焦0-1矩阵即可。
tensor([[1., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1.]])
应用mask之后的结果如下:
tensor([[[-0.3590, -inf, -inf, -inf],
[-0.0339, 0.5455, -inf, -inf],
[ 0.0495, -0.1276, -0.2947, -inf],
[-0.7486, 0.2227, 0.1194, 0.7095]],
[[-0.0147, -inf, -inf, -inf],
[-0.3145, 0.4067, -inf, -inf],
[-0.0165, 0.2152, 0.2001, -inf],
[ 0.2822, 0.5097, -0.5307, -0.5645]]])
3.2 多头注意力(Multi-Head Attention)
多头注意力是将高维嵌入向量划分为多个低维子空间,并行执行多组独立的自注意力计算,再将结果拼接融合的注意力机制;它通过多个注意力头分别捕捉不同类型、不同尺度的语义依赖关系(如局部语法关联、长距离语义关联、指代关系等),有效提升模型对复杂上下文的建模能力。
MultiHead ( Q , K , V ) = Concat ( head 1 , … , head h ) W O \text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1,\dots,\text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,…,headh)WO
其中每个头为:
head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW_i^Q,\ KW_i^K,\ VW_i^V) headi=Attention(QWiQ, KWiK, VWiV)
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim, num_heads, dropout=0.1):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
assert embed_dim % num_heads == 0, "embed_dim must be divisible by num_heads"
self.query = nn.Linear(embed_dim, embed_dim)
self.key = nn.Linear(embed_dim, embed_dim)
self.value = nn.Linear(embed_dim, embed_dim)
self.out_proj = nn.Linear(embed_dim, embed_dim)
self.scale = math.sqrt(self.head_dim)
self.attn_dropout = nn.Dropout(dropout)
self.out_dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
batch_size, seq_len, _ = x.shape
Q = self.query(x)
K = self.key(x)
V = self.value(x)
Q = Q.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
K = K.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
V = V.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / self.scale
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, float('-inf'))
attn_weights = F.softmax(attn_scores, dim=-1)
attn_weights = self.attn_dropout(attn_weights)
attn_output = torch.matmul(attn_weights, V)
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.embed_dim)
output = self.out_proj(attn_output)
output = self.out_dropout(output)
return output, attn_weights
4 从0实现一个GPT
GPT-2 本质上是一个 decoder-only Transformer 架构(基于 Transformer),由多层堆叠的自回归 Transformer block 构成。不同参数规模的 GPT-2(如 GPT-2 Small、GPT-2 Medium、GPT-2 Large、GPT-2 XL)主要体现在 层数(N)、隐藏维度( d model d_\text{model} dmodel)以及注意力头数( n heads n_\text{heads} nheads) 的差异上,而整体结构保持一致。每个 Transformer Block 结构完全相同,采用 pre-LayerNorm 架构,具体由以下部分组成:首先对输入进行 LayerNorm,然后进入 masked multi-head self-attention(带因果掩码的多头注意力),确保当前位置只能关注历史 token;随后通过残差连接与输入相加;接着再次进行 LayerNorm,并进入一个两层的前馈网络(MLP,通常为 Linear → GELU → Linear);最后再次通过残差连接输出该层结果。
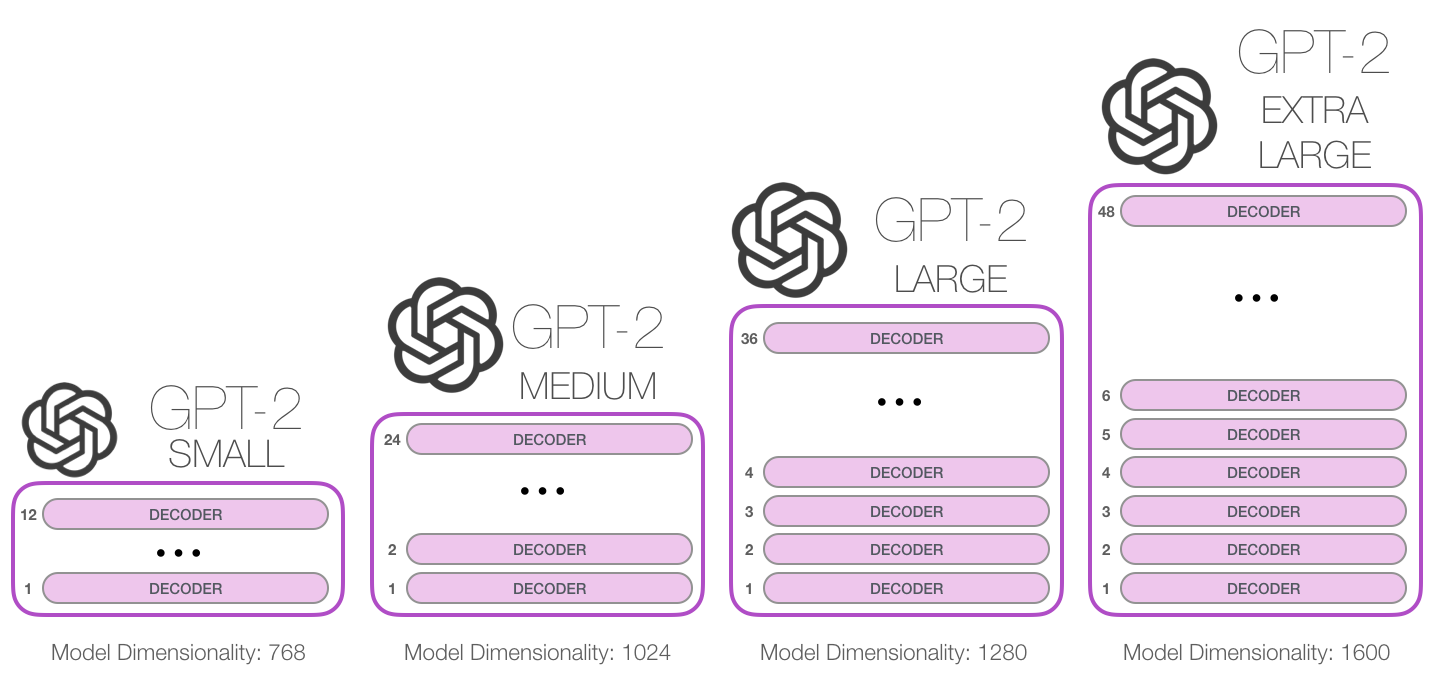
在整个网络前端,输入 token 经过 token embedding 与位置编码(positional embedding)相加后送入第一层 Transformer;在网络末端,最后一层的 hidden states 会经过一个 线性投影层(LM Head)映射到词表空间,并通常与 embedding 权重共享(weight tying),得到每个位置的概率分布。模型通过最大化自回归目标 ( P ( x t ∣ x < t ) ) (P(x_t \mid x_{<t})) (P(xt∣x<t)) 进行训练,从而实现 next-token prediction。因此,GPT-2 的完整数据流可以概括为:Embedding → N×Transformer Block → LayerNorm → Linear(LM Head)→ Softmax 输出概率分布,最终用于文本生成任务。
由于完全去除了 encoder 与 cross-attention,GPT-2 在结构上极度简化为单向信息流,这带来两个直接结果:
- 一是推理阶段可以利用 KV-cache 实现高效增量生成;
- 二是模型更偏向生成任务(generation-oriented),而非理解任务(如双向语义建模)。整体来看,GPT-2 的架构可以概括为:Embedding → N×(Masked Self-Attention + MLP) → Linear LM Head,是后续所有 GPT 系列与大模型架构的基础范式。
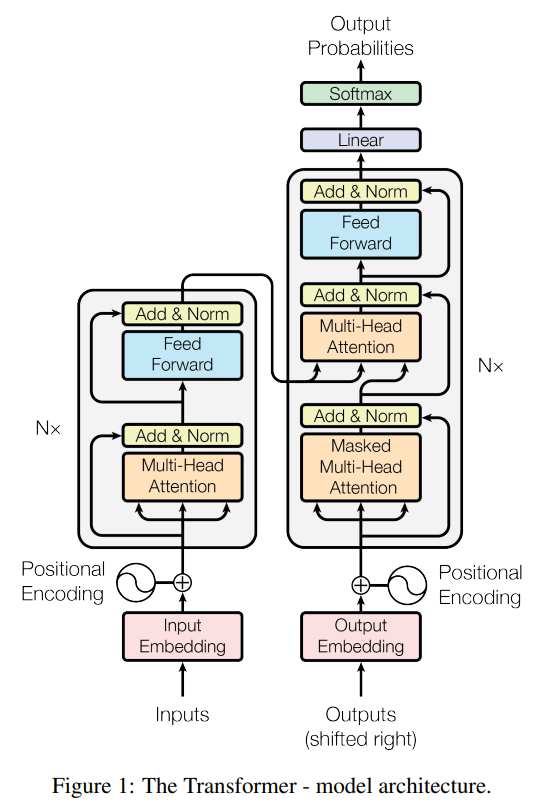
上面提到了现在的LLM基本结构为TransformerBlock,下面就是其结构:
class FeedForward(nn.Module):
def __init__(self, embed_dim, ff_dim, dropout=0.1):
super(FeedForward, self).__init__()
self.linear1 = nn.Linear(embed_dim, ff_dim)
self.linear2 = nn.Linear(ff_dim, embed_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = F.gelu(self.linear1(x))
x = self.dropout(x)
x = self.linear2(x)
return x
class TransformerBlock(nn.Module):
def __init__(self, embed_dim, num_heads, ff_dim, dropout=0.1):
super(TransformerBlock, self).__init__()
self.attention = MultiHeadAttention(embed_dim, num_heads, dropout)
self.feed_forward = FeedForward(embed_dim, ff_dim, dropout)
self.norm1 = nn.LayerNorm(embed_dim)
self.norm2 = nn.LayerNorm(embed_dim)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask=None):
attention_output = self.attention(x, mask)
x = x + self.dropout1(attention_output)
x = self.norm1(x)
ff_output = self.feed_forward(x)
x = x + self.dropout2(ff_output)
x = self.norm2(x)
return x
最终的GPT2模型就是多层Transformer结构搭积木一样搭起来的。
class GPT2Model(nn.Module):
def __init__(self, vocab_size, embed_dim, num_heads, num_layers, ff_dim, max_seq_len, dropout=0.1):
super(GPT2Model, self).__init__()
self.vocab_size = vocab_size
self.embed_dim = embed_dim
self.max_seq_len = max_seq_len
self.token_embedding = nn.Embedding(vocab_size, embed_dim)
self.position_embedding = nn.Embedding(max_seq_len, embed_dim)
self.dropout = nn.Dropout(dropout)
self.blocks = nn.ModuleList([
TransformerBlock(embed_dim, num_heads, ff_dim, dropout)
for _ in range(num_layers)
])
self.final_norm = nn.LayerNorm(embed_dim)
self.lm_head = nn.Linear(embed_dim, vocab_size, bias=False)
self._init_weights()
def _init_weights(self):
for module in self.modules():
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
elif isinstance(module, nn.LayerNorm):
torch.nn.init.zeros_(module.bias)
torch.nn.init.ones_(module.weight)
def forward(self, input_ids, mask=None):
batch_size, seq_len = input_ids.shape
position_ids = torch.arange(seq_len, device=input_ids.device).unsqueeze(0).expand(batch_size, -1)
token_embeds = self.token_embedding(input_ids)
position_embeds = self.position_embedding(position_ids)
x = self.dropout(token_embeds + position_embeds)
if mask is None:
mask = torch.tril(torch.ones(seq_len, seq_len, device=input_ids.device)).unsqueeze(0).unsqueeze(0)
for block in self.blocks:
x = block(x, mask)
x = self.final_norm(x)
logits = self.lm_head(x)
return logits
5 在无标记数据上预训练
训练LLM和训练普通的DNN差不多,只不过相比而言普通的DNN训练成本相对较低,LLM训练时间更长,需要谨慎选择训练的参数和数据。
训练之前,之前已经准备好了模型,Dataloader,还有tokenizer等基本模块,train和val部分大概如下面:
def train_epoch(model, dataloader, optimizer, criterion, device, accumulation_steps=1):
model.train()
total_loss = 0
num_batches = 0
optimizer.zero_grad()
progress_bar = tqdm(dataloader, desc='Training', leave=False)
for batch_idx, (input_ids, target_ids) in enumerate(progress_bar):
input_ids = input_ids.to(device, non_blocking=True)
target_ids = target_ids.to(device, non_blocking=True)
logits = model(input_ids)
loss = criterion(logits.view(-1, logits.size(-1)), target_ids.view(-1))
loss = loss / accumulation_steps
loss.backward()
if (batch_idx + 1) % accumulation_steps == 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
optimizer.zero_grad()
total_loss += loss.item() * accumulation_steps
num_batches += 1
progress_bar.set_postfix({'loss': f'{loss.item() * accumulation_steps:.4f}'})
if batch_idx % 200 == 0:
torch.cuda.empty_cache()
return total_loss / num_batches
验证:
def validate(model, dataloader, criterion, device):
model.eval()
total_loss = 0
num_batches = 0
with torch.no_grad():
progress_bar = tqdm(dataloader, desc='Validating', leave=False)
for input_ids, target_ids in progress_bar:
input_ids = input_ids.to(device, non_blocking=True)
target_ids = target_ids.to(device, non_blocking=True)
logits = model(input_ids)
loss = criterion(logits.view(-1, logits.size(-1)), target_ids.view(-1))
total_loss += loss.item()
num_batches += 1
progress_bar.set_postfix({'loss': f'{loss.item():.4f}'})
return total_loss / num_batches
优化器和学习率可以根据自己需要进行选择,我这里选择的是AdamW和带warmup的cosscheduler:
optimizer = torch.optim.AdamW(model.parameters(), lr=define.learning_rate, weight_decay=0.01)
warmup_epochs = max(1, define.num_epochs // 10)
scheduler = WarmupCosineScheduler(
optimizer,
warmup_epochs=warmup_epochs,
total_epochs=define.num_epochs,
eta_min=1e-6
)
这个学习率曲线为: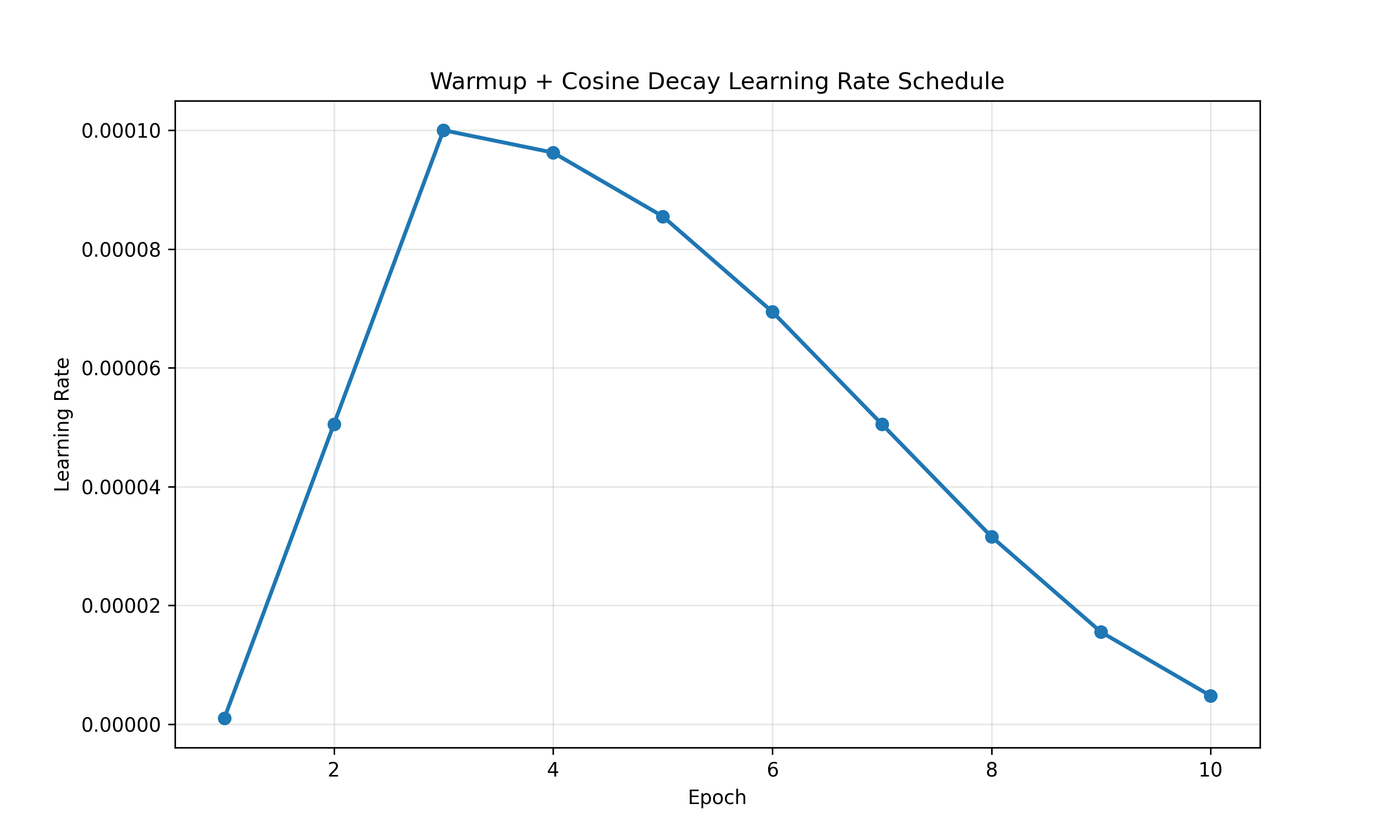
训练的时候模型的层数之类可以根据自己的数据和硬件调整。比如我的3050小水管,根本没法训练全尺寸的GPT2,因此我降低了context上下文的大小。另外,训练的时候,需要注意loss的变化,比如,我下面这次训练loss明显有问题无法继续下降了,这个时候可以看下调整数据或者模型: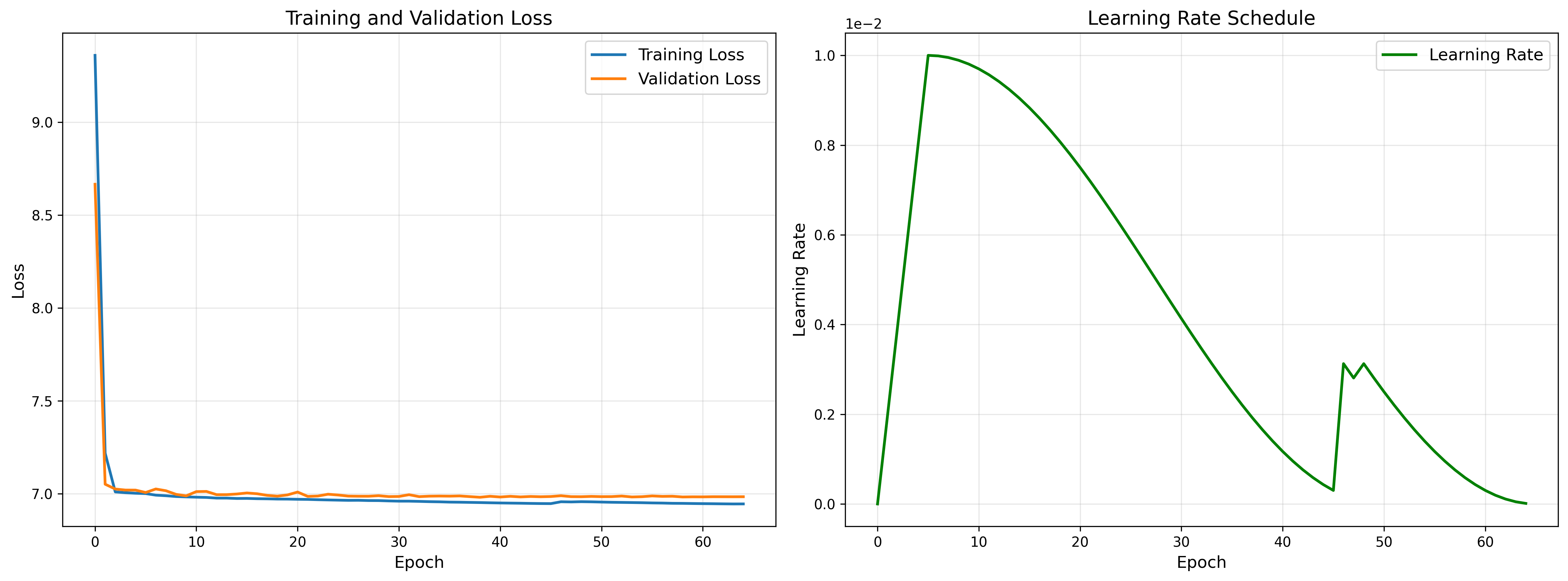
用这次训练的结果就是下面这样,语无伦次。
GPT-2: 看看,了“,。韩立,,了是,。。,。,。,,在了的,后的。和,的和什么,!,了的的,的了,,将在。,,,,韩立了的,的,也的的,。,,,是,,,不他,。你的有,“韩立在。。,中了,了了后,,韩立中了,的的的,,让将
下面这种训练相对好一点儿,而且loss还有可以继续下降趋势的就好很多。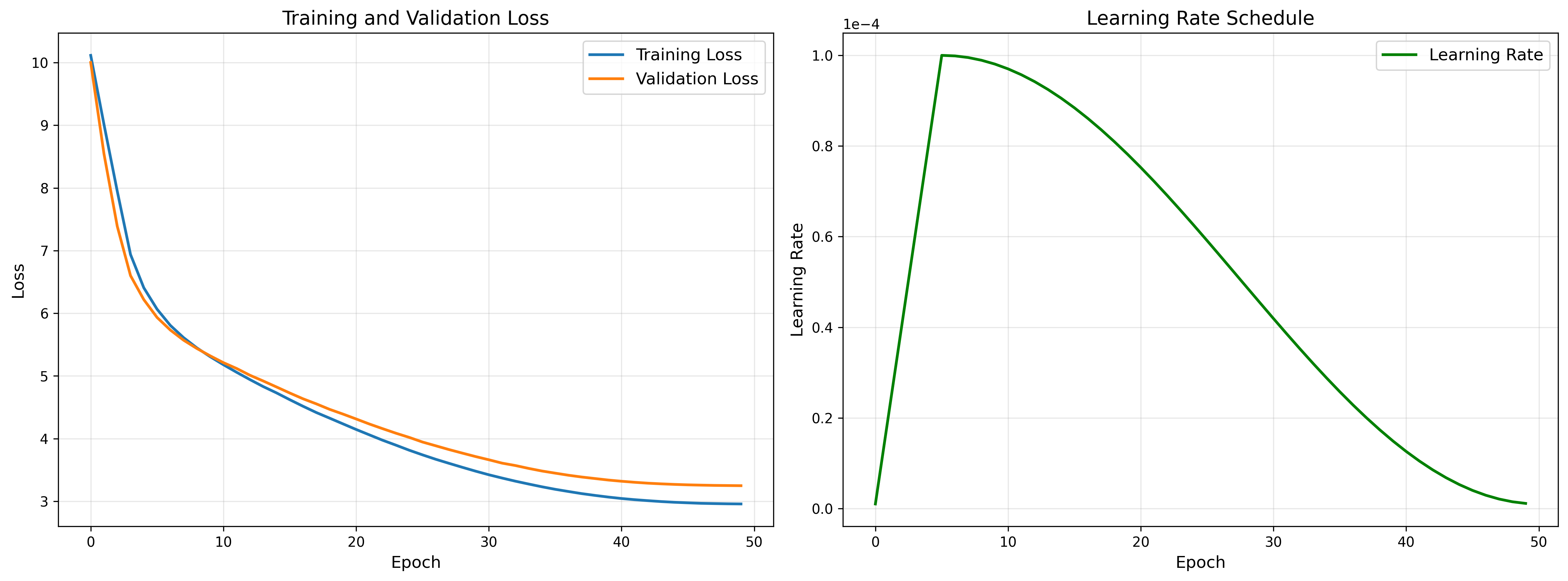
我截取了凡人修仙传的一部分训练的,原文太大了,训练我的小水管至少需要1天一夜。
比如最新的训练结果虽然效果仍然不好但是相对之前的语无伦次来说好多了:
GPT-2: 韩立有哪些法宝威力也绝不介意,成不了多少才行!不过,他恐怕不会有了!于是情急之下竟对,韩立对那还真是不错的是,他怎么可能再加上对方所说的事。难道是一件顶级法器?他也大感头痛而已!“这可是师侄应该是哪位炼丹师吧!”老者见韩立的话后,丝毫不在乎的很正常。可是还没等他言语后,已感到有些吃惊。韩立听了后,还是开口问道
6 pretrain
当然如果感觉自己从0训练他麻烦也可以选择现有开源的模型权重,在其基础进行fine-tuning。具体的技术和方案也比较简单,有空可以简单描述下。
分类任务微调是指在预训练模型基础上,使用带标签的数据对模型进行监督学习,使其能够将输入样本映射到预定义类别(本质是学习判别边界)。
指令遵循微调则是通过构造“指令-响应”格式的数据(Instruction Tuning),让模型学会理解自然语言指令并生成符合人类意图的输出(更偏向对齐与泛化能力)。
参考文献

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)