AI核心知识115—大语言模型之 自监督学习(简洁且通俗易懂版)
自监督学习 (Self-Supervised Learning, SSL) 是大语言模型(LLM)能够“野蛮生长”长成庞然大物,并拥有惊人智慧的绝对核心秘诀。
如果说大模型是一头吞噬数据的巨兽,那么自监督学习就是它的“全自动进食机” 。
简单来说,它的核心思想是:不需要人类辛苦地打标签,让机器自己把数据的一部分藏起来,然后用另一部分去猜被藏起来的部分。
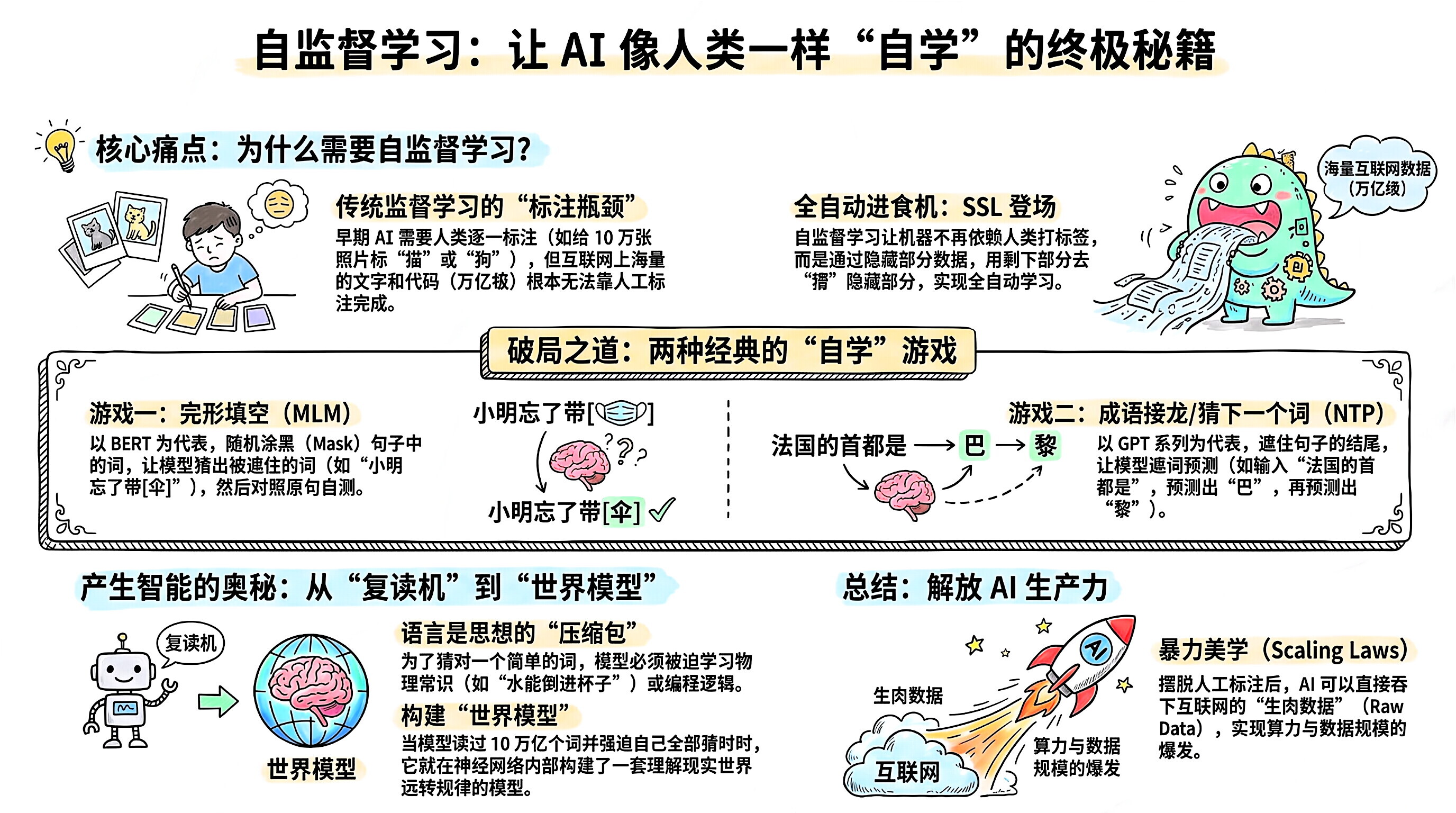
1.🛑 核心痛点:为什么不用传统的“监督学习”?
在深度学习时代早期,主流是监督学习 (Supervised Learning)。
-
做法:人类给数据打标签(标注师)。比如,准备 10 万张照片,人类在一旁标注“这是猫”、“这是狗”。
-
瓶颈:人类太慢,也太贵了。 互联网上有几万亿字的维基百科、新闻、小说和代码。如果要雇人给这几万亿字标注语法、主谓宾、逻辑关系,即使把全人类都雇来也标不完。这就是著名的**“数据标注瓶颈”**。2.💡 破局之道:把数据本身变成标签
自监督学习的天才之处在于:既然数据本来就是完整的,我为什么不自己出题、自己对答案呢?
对于自然语言处理(NLP),这就演变成了两种最经典的“自学”游戏:
A. 游戏一:“完形填空” (Masked Language Modeling, MLM)
-
代表模型:BERT
-
玩法:模型拿到一句话:“小明今天忘了带伞,所以被雨淋湿了。”
-
自动出题:模型随机把几个字涂黑(Mask)。变成:“小明今天忘了带[Mask],所以被[Mask]淋湿了。”
-
自测与对答案:模型去猜这两个词是什么。猜完之后,跟原本完整的句子一对照,就知道自己猜对没有。算错了就调整参数。
B. 游戏二:“成语接龙” / 猜下一个词 (Next Token Prediction, NTP)
-
代表模型:GPT 系列, Claude, Llama (我们在之前专门聊过这个机制)
-
玩法:模型拿到一句话:“法国的首都是巴黎”。
-
自动出题:遮住最后一个字。输入:“法国的首都是”,让模型猜下一个字。
-
自测与对答案:模型猜出“巴”,把书往后翻一页,发现确实是“巴”,得分!接着输入“法国的首都是巴”,猜下一个字“黎”。
2.⚖️ 三种学习方式的终极对比
为了彻底理清概念,我们把 AI 的三种学习方式放在一起看:
| 学习方式 | 数据状态 | 谁提供答案? | 隐喻 | 适用场景 |
| 监督学习 (Supervised) | 数据 + 人工标签 | 人类老师 | 老师发带标准答案的考卷。 | 图像分类、垃圾邮件识别 |
| 无监督学习 (Unsupervised) | 纯数据 | 没有答案 | 丢给你一堆积木,自己按颜色或形状分类(聚类)。 | 用户画像分群、异常检测 |
| 自监督学习 (Self-Supervised) | 纯数据 | 数据本身 | 给一本没有答案的教材,自己把后半句捂住来背书。 | 大模型预训练 (Pre-training) |
注:自监督学习其实是“无监督”的一种高级形式,但因为它巧妙地构造出了“伪标签”(被遮住的词就是标签),所以它的训练效果堪比监督学习。
3.🧠 为什么这种“猜词游戏”能产生智能?
你可能会觉得,天天玩填空和接龙,这不就是个复读机吗?为什么它能学会写代码、做数学题?
因为语言是人类思想的压缩包。
-
为了填对“他把水倒进了[杯子]里”,模型必须学懂物理常识(水能倒进容器)。
-
为了接对“
for i in range(10): print(i)”,模型必须学懂编程逻辑。
当模型通过自监督学习,阅读了人类历史上 10 万亿个词汇,并强迫自己把每一个词都猜对时,它就被迫在神经网络内部构建了一个理解世界运转规律的“世界模型”。
总结
自监督学习 是一场解放 AI 生产力的革命。
正是因为它,AI 彻底摆脱了人类标注员的限制,可以直接把整个互联网的生肉数据(Raw Data)吞下去,从而实现了算力和数据规模的暴力美学(Scaling Laws),迎来了大模型时代的爆发。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 18
18 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)