AAAI2025:用于弱监督时间动作定位的相似模态增强与动作
AAAI2025:Similar Modality Enhancement and Action Consistency Learning for Weakly Supervised Temporal Action Localization用于弱监督时间动作定位的相似模态增强与动作
一、现有方法不足
- 弱监督时序行为定位(WTAL)旨在仅依托视频级标签,完成未剪辑视频中行为实例的识别与时序定位。现有主流方法通常采用面向剪辑行为分类(TAC)任务、且参数冻结的预训练编码器所输出的原始特征,该方式不可避免会引入任务域偏差。
- 现有方法往往忽视从多维度构建行为一致性约束的重要性,尤其是行为过程一致性与行为语义一致性—— 二者是模型理解行为特征的核心关键。
二、本文创新点
本文提出一种融合相似模态增强与行为一致性学习的新型弱监督时序行为定位算法(SEAL)。
- 首先,为各类行为构建全局描述子,依托该描述子生成伪标签,引导模型学习表征更具一致性的特征,进而缓解任务域偏差问题
- 其次,设计两类损失函数实现行为一致性学习:一是过程一致性损失,对偏离行为中心的候选提案施加惩罚,保障行为时序过程的完整性
- 二是语义一致性损失,借助局部描述子,引导同类行为提案(尤其存在明显语义混淆的样本)习得相近的特征分布。
三、具体方法
3.1 整体框架
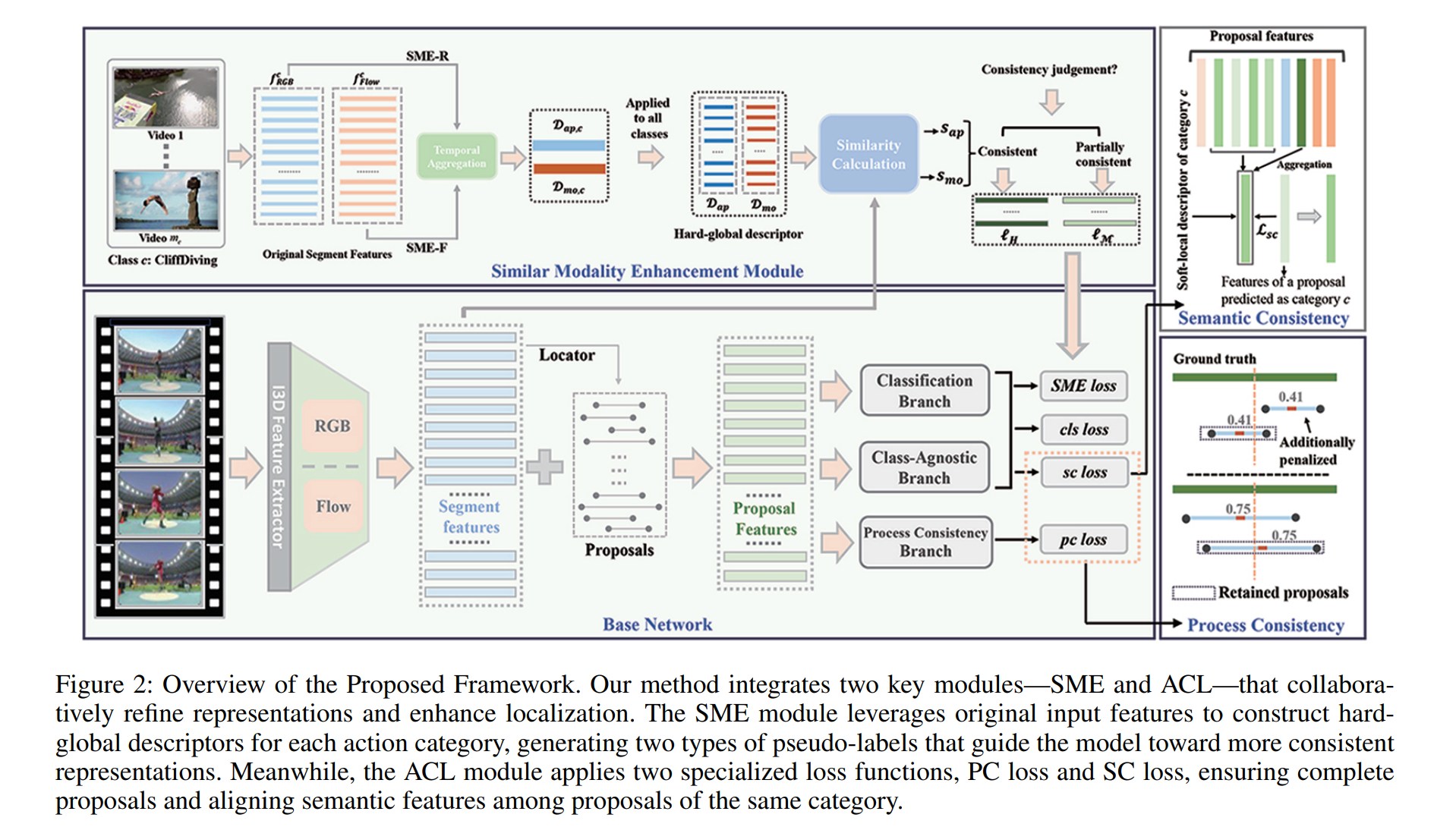
此图完整展示了弱监督时序动作定位(WTAL)的端到端 pipeline,核心由相似模态增强模块(SME)、** 基础网络(Base Network)和动作一致性学习(ACL)** 三大部分协同工作:
3.1.1 相似模态增强模块(SME)
输入:mcm_cmc个属于类别ccc(如 CliffDiving 悬崖跳水)的视频,提取原始片段特征:
f{RGB}f_{\{RGB\}}f{RGB}:RGB 视觉特征(捕捉外观信息) ◦ f{flow}f_{\{flow\}}f{flow}:光流特征(捕捉运动信息)
核心步骤:
- 时间聚合(Temporal Aggregation)
对所有同类动作的视频特征做全局融合,生成硬全局描述符:
- D{ap,c}\boldsymbol{D_{\{ap,c\}}}D{ap,c}:类别c的外观(RGB)全局描述符
- DmoD_{mo}Dmo:全类别运动全局描述子
外观描述子有两种聚合方式:
(1)片段级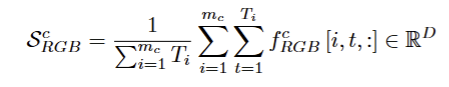
先进行求和,把类别c下所有视频全部帧的特征加总,再除以总帧数,得到一个D维的全局特征向量(忽略了视频边界,直接做平均,更加关注局部特征的一致性)
(2)视频级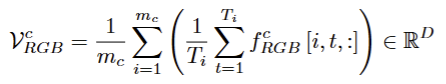
对单个视频内部的所有帧做平均,得到该视频的视频级特征;再对这些所有的特征做平均,两级平均输出一个D维的全局特征向量
(强调的是不同视频间类内差异)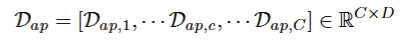
外观描述子集合的定义
Dap,cD_{ap,c}Dap,c:第c个动作类别的单类别外观描述子(由上面两个公式得到)
RC×DR^{C \times D}RC×D:表示该集合是一个 C 行D 列的矩阵:每一行对应一个动作类别的外观全局特征
Dhard=cat[Dap,Dmo]∈RC×2D \mathcal{D}_{hard} = cat\left[\mathcal{D}_{ap}, \mathcal{D}_{mo}\right] \in \mathbb{R}^{C \times 2D} Dhard=cat[Dap,Dmo]∈RC×2D
硬全局描述子的定义(融合了外观与运动信息的完整类别特征矩阵)cat:特征拼接
将外观(RGB 视觉信息)和运动(光流时序信息)两个独立的类别描述子集合,沿特征维度拼接,得到同时包含视觉与运动语义的完整类别特征。
2. 相似度计算(Similarity Calculation)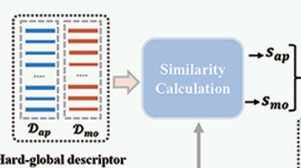
用全局描述符和视频片段特征计算相似度,得到两个得分:
- saps_{ap}sap:外观相似度得分
- smos_{mo}smo:运动相似度得分
s{ap,n}=norm(cos(f^{RGB,n},D{ap}))∈RC,s{mo,n}=norm(cos(f^{flow,n},D{mo}))∈RC, \begin{align*} s_{\{ap,n\}} &= \mathrm{norm}\left( \cos\left( \hat{f}_{\{RGB,n\}}, \mathcal{D}_{\{ap\}} \right) \right) \in \mathbb{R}^C, \\ s_{\{mo,n\}} &= \mathrm{norm}\left( \cos\left( \hat{f}_{\{flow,n\}}, \mathcal{D}_{\{mo\}} \right) \right) \in \mathbb{R}^C, \end{align*} s{ap,n}s{mo,n}=norm(cos(f^{RGB,n},D{ap}))∈RC,=norm(cos(f^{flow,n},D{mo}))∈RC,
特征池化:对第 nnn个视频的时序片段特征,沿时间维度做全局池化,得到视频级的 RGB / 光流特征 ,再进行余弦相似度计算,归一化到[0,1]区间内,得到最终相似度向量分数
3. 一致性判定与伪标签生成
根据双模态得分的一致性,生成两类伪标签:
- ℓ_H\ell\_Hℓ_H:完全一致(Consistent) → 高置信度伪标签 ◦
- ℓ_M\ell\_Mℓ_M:部分一致(Partially consistent) → 中置信度伪标签
- 这些伪标签用于后续的SME loss,监督模型学习更一致的跨模态表示,缓解任务差异。
3.1.2 基础网络(BaseNetwork)
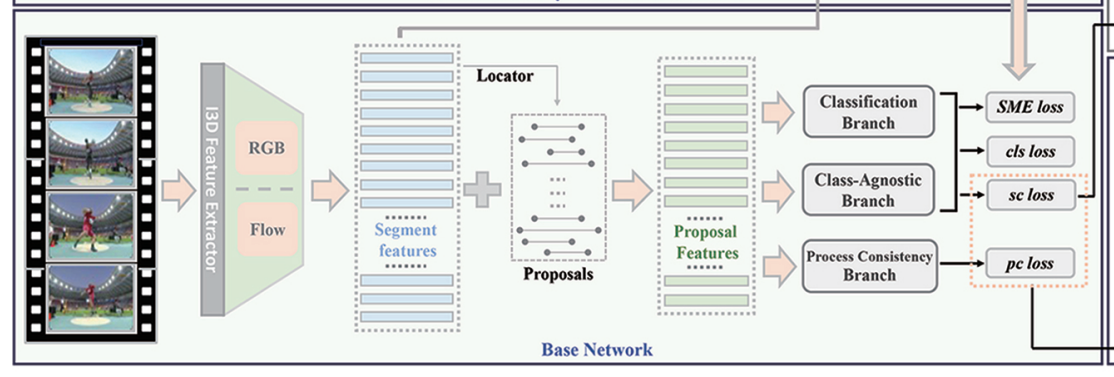
主干,从原始视频中提取特征、生成动作提案:
- 3D特征提取器
- 输入未裁剪的视频,提取片段特征(Segment features)同样分为RGB和光流两个模态
- 候选框生成(Proposals)
- 用locator定位器基于片段特征生成动作候选区域(proposals)
- 片段特征+候选框,得到候选框特征(Proposal Features)
- 三分支预测结构
- Classification Branch(分类分支):预测每个候选框的动作类别,输出分类结果
- Class-Agnostic Branch(类别无关分支):仅区分 “动作 / 背景”,不区分具体类别,用于定位
- Process Consistency Branch(过程一致性分支):建模动作时序过程的一致性,保证候选框覆盖完整动作
- 多损失函数联合训练
-
SME loss:由 SME 模块的伪标签监督,对齐候选框特征与类别全局描述子,保证特征一致性
LSME=1mH∑i=1mHφ(pH,i,ℓH,i)+λ(t)mM∑i=1mMφ(pM,i,ℓM,i)(8) \mathcal{L}_{SME} = \frac{1}{m_H} \sum_{i=1}^{m_H} \varphi(p_{H,i}, \ell_{H,i}) + \frac{\lambda(t)}{m_{\mathcal{M}}} \sum_{i=1}^{m_{\mathcal{M}}} \varphi(p_{\mathcal{M},i}, \ell_{\mathcal{M},i}) \tag{8} LSME=mH1i=1∑mHφ(pH,i,ℓH,i)+mMλ(t)i=1∑mMφ(pM,i,ℓM,i)(8)
mHm_HmH:高置信度样本数量:双模态完全一致、生成ℓH\ell_HℓH伪标签的样本数
φ\varphiφ:均方误差(MSE)函数:衡量预测分数与伪标签的差异,提供平滑梯度
pH,ip_{H,i}pH,i:第i个高 / 中置信度样本的视频级分类预测分数(由候选框分数加权平均得到)
ℓH,i\ell_{H,i}ℓH,i第i个高 / 中置信度样本的伪标签(one-hot 编码)
λ(t)\lambda(t)λ(t):动态衰减系数:随训练 epochttt从 1 线性衰减到 0,用于平衡中置信度标签的权重 -
cls loss:分类分支的标准分类损失,优化类别预测精度
-
sc loss (Semantic Consistency loss):语义一致性损失,对应右侧Semantic Consistency模块,对齐同类别候选框的语义特征
-
pc loss (Process Consistency loss):过程一致性损失,对应右侧Process Consistency模块,保证候选框覆盖完整动作时序,惩罚不完整的候选框
Lpc=1N∑i=1N(φ(CP,i,CG,i)+diIi+ε+δ(C(i))) \mathcal{L}_{pc} = \frac{1}{N} \sum_{i=1}^{N} \left( \varphi(C_{P,i}, C_{G,i}) + \frac{d_i}{I_i + \varepsilon} + \delta(\mathcal{C}(i)) \right) Lpc=N1i=1∑N(φ(CP,i,CG,i)+Ii+εdi+δ(C(i)))
CP,iC_{P,i}CP,i:第i个视频中,模型预测的动作类别分数(基于 Process Consistency Branch)
CG,iC_{G,i}CG,i:第i个视频的真实标签(Ground Truth),用于计算分类损失
did_idi:不重叠长度(Displacement),衡量预测动作区间与真实区间的时间偏移量
IiI_iIi:频的总帧数(总时间长度),用于归一化
diIi+ε\frac{d_i}{I_i + \varepsilon}Ii+εdi:时间偏移惩罚项,衡量定位位置的准确性,值越大惩罚越重
δ(C(i))\delta(\mathcal{C}(i))δ(C(i)):完整性约束项(通常为 Hinge Loss),强制要求预测框必须覆盖完整动作
NNN:训练样本总数
分类一致性项:确保模型预测的动作类别与真实标签一致。
时间偏移惩罚项:衡量预测动作区间与真实区间的时间偏移程度。
完整性约束项:核心创新点,保证候选框必须覆盖完整的动作过程。
#### 3.1.3 两个一致性子模块
语义一致性(Semantic Consistency)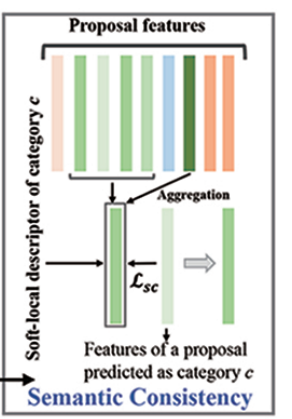
输入:候选框特征(被预测为c)
对每一个候选框提取软局部描述子,再做聚合得到ℓ_{sc}
通过sc loss约束,让同一类别的所有候选框语义特征尽可能对齐,减少类内特征差异
过程一致性(Process Consistency)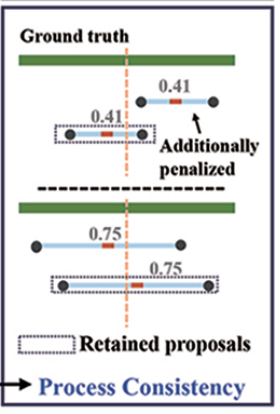
输入:候选框时序一致性评分
Additionally penalized:不完整的候选框(的分太低)会被额外惩罚
Retained proposals:完整的候选框被保留
作用:通过pc loss 约束,让模型输出覆盖完整动作时序的候选框,过滤掉只包含动作片段的不完整候选框
四、实验结果
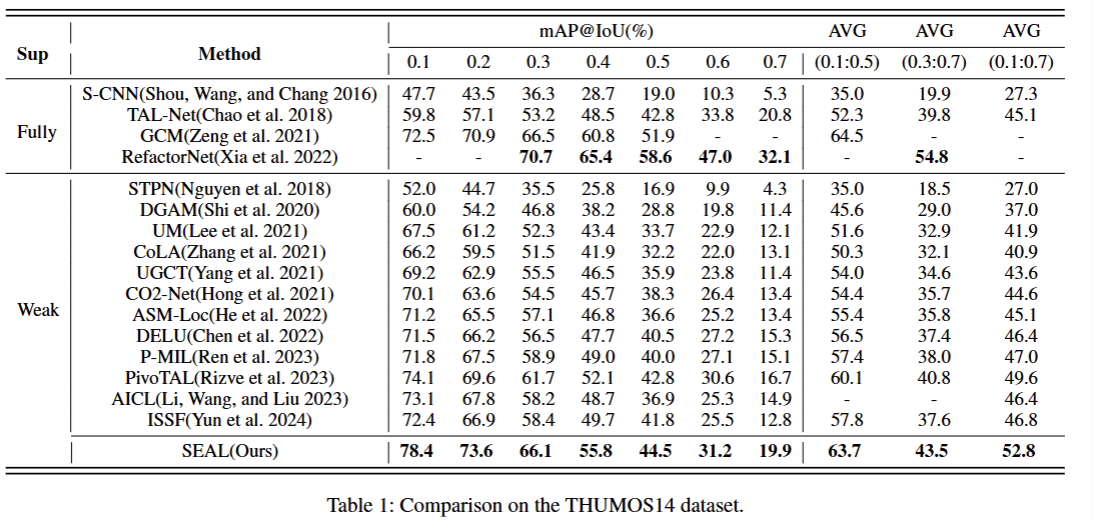
展示了SEAL(Ours) 方法在 THUMOS14 视频动作检测基准数据集上的实验表现,并与当前 SOTA(State-of-the-Art)方法进行了对比。
mAP@IoU%:计算在不同的loU交并比阈值(表示预测的时间区间与真实区间的重合度)下的平均精度均值
发现:
综合指标均有较大幅度提升;
全监督场景,高于传统全监督方法的检测精度;
弱监督场景下,各项指标大幅度领先现有SOTA方法
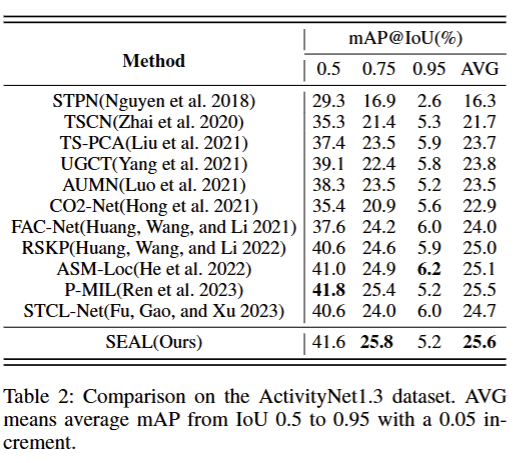
论文在ActivityNet v1.3(长视频、类别均衡) 时序动作检测数据集上的对比实验表,用来验证 SEAL 方法的泛化能力和 SOTA 性能:
AVG指标下,我们的方法领先其他方法
结论:
- SEAL方法泛化能力很好,通用性高
- 在搞loU(0.75)的严格评估下,表现很好,说明其动作定位精度更高,能更精准预测动作边界
- 弱监督场景下有效
五、消融实验
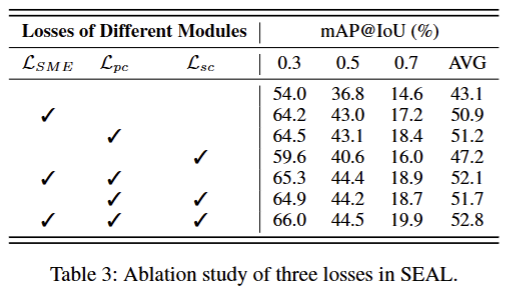
验证三个关键损失函数的贡献(相似模态增强模块、过程一致性损失、语义一致性损失)
结论:
- 三个损失函数均有效
- 核心是SME+PC,提供最大的基础增益、再进一步提升定位精度
- 语义一致性损失SC进一步优化特征对齐
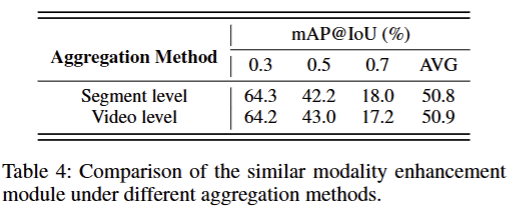
两种全局描述子聚合方法:片段级、视频级
发现两种方法性能几乎持平,而且片段级在高阈值下表现更好,说明更适合对定位精度要求高的场景;视频级在中等loU阈值下表现更好,说明对不同长度视频的泛化性更好
论文最终选择视频级聚合,是因为其更符合 每个样本权重公平的训练逻辑,避免长视频主导全局特征,更加适合弱监督场景。
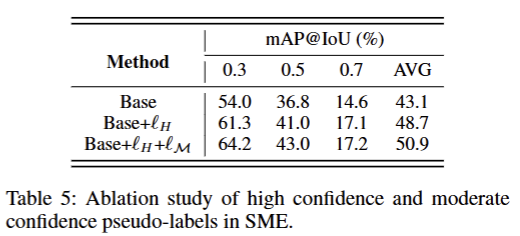
针对SME模块中“分层伪标签设计”的消融实验,用来验证高置信度和中置信度两种伪标签对模型性能的贡献
发现
仅加入高置信度伪标签时增益就很大,验证了“双模态一致性伪标签监督”的核心有效性
中置信度伪标签进一步性能提升,验证了分层伪标签设计的合理性

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)