CVPR 2026 | 深圳大学等提出OddGridBench:大模型也玩“找不同”?底层视觉感知能力竟远输人类

不知道你有没有玩过“找不同”的游戏?在一堆几乎一模一样的图标里,迅速揪出那个颜色深了一点点,或者角度歪了几度的“异类”。对我们人类来说,这似乎是一种本能,心理学上称之为弹出效应(Pop-out effect)。但你有没有想过,那些能写代码、解奥数的视觉语言大模型(MLLM),在面对这种简单的底层视觉任务时,表现如何呢?
最近,来自深圳大学、广东省人工智能与数字经济实验室(深圳)、深圳技术大学、清华大学深圳国际研究生院以及美团的研究团队,联合发布了一项非常有意思的研究。他们提出了一个专门针对这种底层视觉感知能力的基准测试 —— OddGridBench。
该基准测试的命名寓意深远:OddGridBench 结合了认知心理学中经典的“找不同(Odd-One-Out)”范式,并采用了结构化的网格(Grid)布局。为了解决模型在这些任务上的“视力问题”,研究团队还配套提出了一个名为 OddGrid-GRPO 的强化学习框架。这里的 GRPO 借鉴了 DeepSeek-V3 的优化思路,并针对网格定位任务进行了“距离感知”的特殊设计。

-
论文地址: https://arxiv.org/abs/2603.09326
-
机构信息: 深圳大学;人工智能与数字经济广东省实验室(广州);深圳技术大学;清华大学深圳国际研究生院;美团
-
项目主页: https://wwwtttjjj.github.io/OddGridBench
-
代码仓库: https://github.com/GML-FMGroup/OddGridBench
为什么大模型需要玩“找不同”?
在过去的一两年里,多模态大模型在搞层语义理解上突飞猛进,但在底层视觉感知(Low-level Visual Perception)上却一直缺乏系统的审视。
研究团队认为,细粒度的视觉差异敏感性是所有高阶能力的基础。这种现象在视觉科学中常用最小可觉差(Just Noticeable Difference, JND)来描述。试想一下,如果一个模型连图标旋转了 5 度都看不出来,它又怎么能准确地在工业检测中发现微小的裂纹,或者在复杂的空间场景中进行精准的推理呢?底层能力的缺失,实际上会削弱高层推理的可靠性。
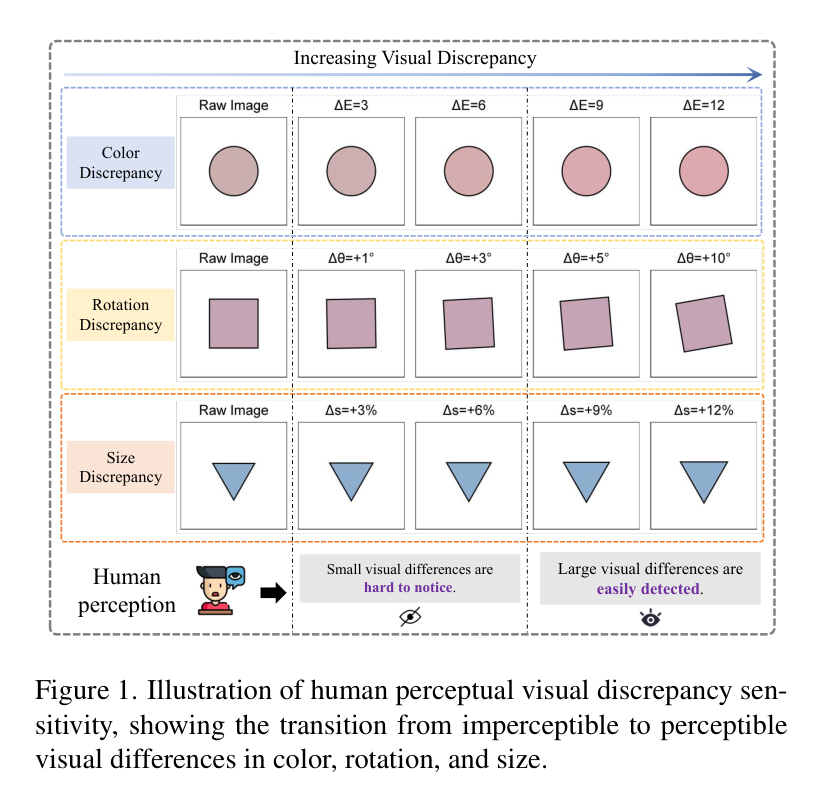
人类视觉对颜色、旋转和大小差异的感知过程
如上图所示,人类视觉系统对这些微小变化非常敏感。然而,目前的模型在面对这些任务时,往往表现得像个“近视眼”。
OddGridBench:一场严苛的“视力测试”
为了量化这种感知能力,研究团队构建了 OddGridBench。它包含 1400 个测试样本,涵盖了四个核心视觉维度:
-
颜色差异 (
):在 CIE-Lab 颜色空间中精确控制色差,范围设定在 [5, 20] 之间。
-
大小差异 (
):微调图标的缩放比例,通常在 85% 到 115% 之间波动。
-
旋转差异 (
):控制图标的旋转角度,范围在
到
。
-
位置差异 (
):让图标在网格单元格内产生 5% 到 12% 的轻微位移。

OddGridBench 任务概览,包含单属性和多属性组合
为了确保测试的纯粹性,研究团队从 IconFont 和 Material Design Icons 收集了大量的矢量图标(SVG),并将其归类为人工制品、自然元素和符号三大类。整个数据生成流程非常严谨,通过参数化的 Python 程序,研究者可以精确控制每一个图标的属性,确保测试的客观性和可重复性。
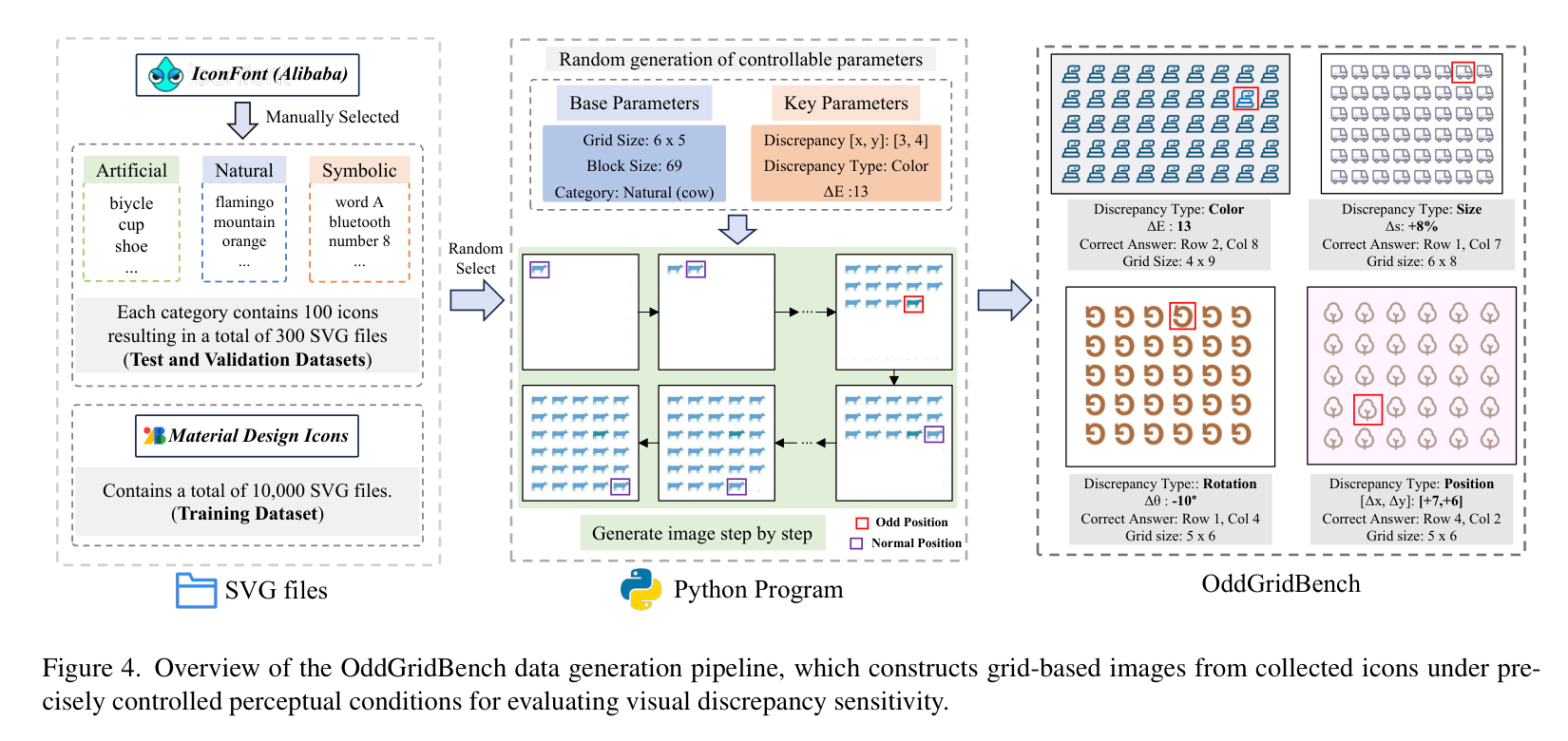
数据生成流水线,从图标收集到网格图像合成
实验结果:大模型集体“翻车”
实验结果令人大跌眼镜。研究团队测试了包括 GPT-5(注:论文中称为 GPT-5-low)、Gemini-2.5-Pro、InternVL3.5 以及 Qwen3-VL 在内的 19 个主流模型。
结果显示,人类的平均准确率高达 87.47%,而目前表现最好的开源模型 Qwen3-VL-32B 也只有 68.07%。更让人意外的是,一些顶尖的闭源模型表现并不理想,Gemini-2.5-Pro 仅为 49.29%,而 GPT-5 甚至只有 28.93%。
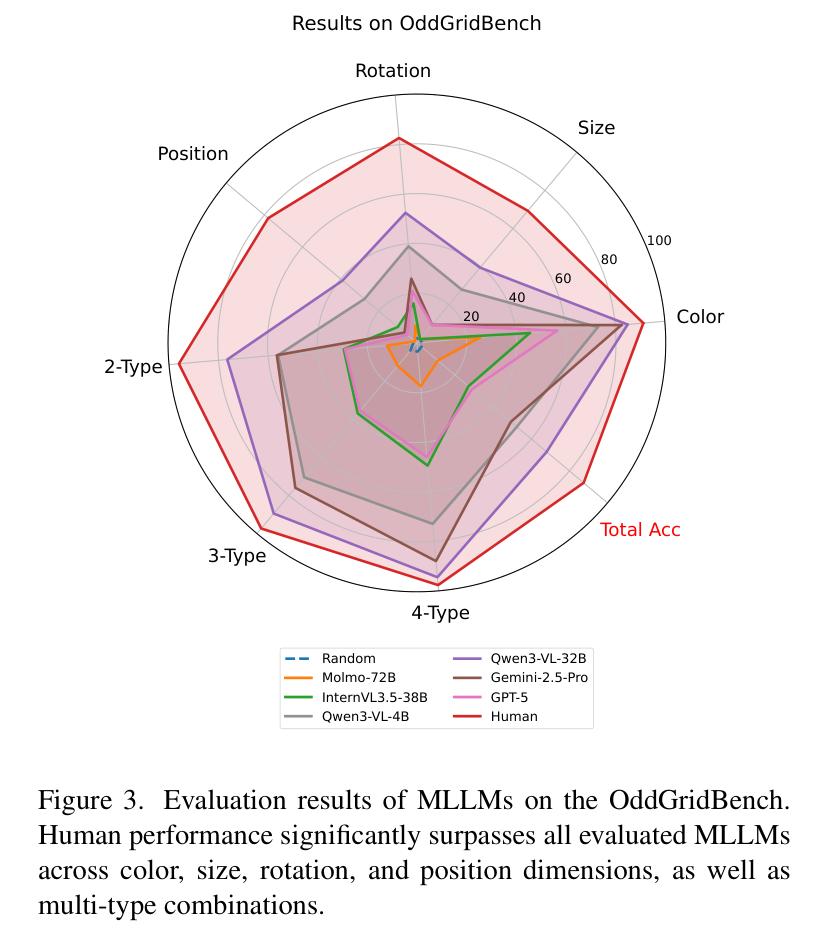
各模型在 OddGridBench 上的雷达图,人类表现遥遥领先
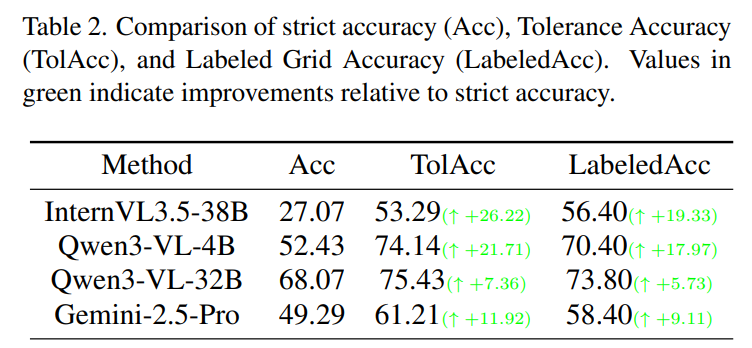
通过下表我们可以看到更详细的数据:在“旋转”和“位置”这两个维度上,模型的表现尤其糟糕。例如,InternVL3.5-38B 在位置差异检测上的准确率仅为 10.00%。这说明目前的 MLLM 在空间感知和几何特征提取上存在明显的短板。
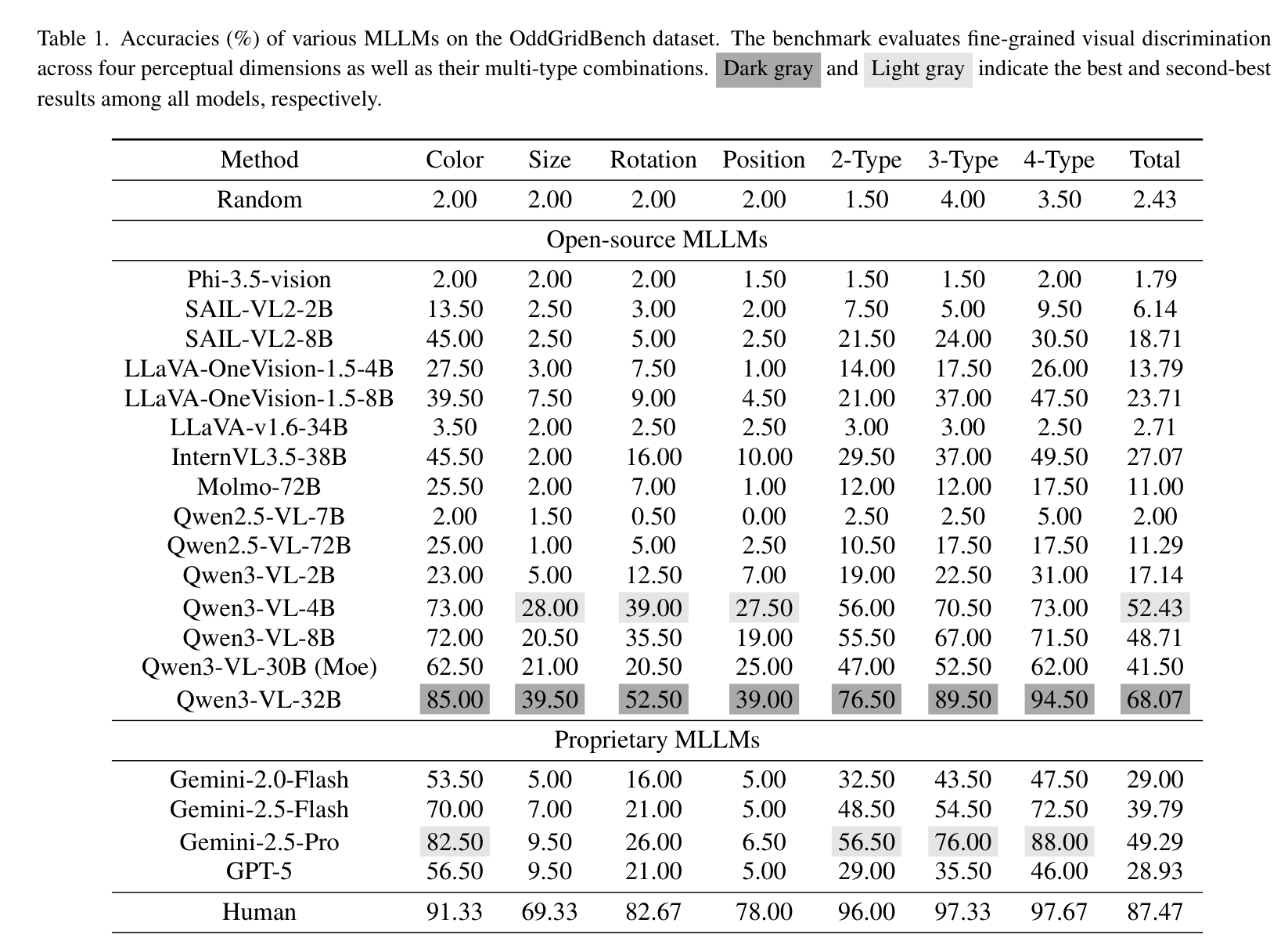
各模型详细准确率对比表
研究团队还进行了一项有趣的分析:如果放宽要求,只要模型预测的位置在正确答案的邻域内(TolAcc),准确率会大幅提升。比如 Qwen3-VL-4B 的准确率会从 52.43% 提升到 74.14%。这暗示了模型其实“看”到了差异,但在将其映射到具体的行列坐标时,由于空间校准(Spatial Calibration)能力不足而犯了错。
OddGrid-GRPO:如何“矫正”模型的视力?
为了提升模型的感知能力,研究团队提出了 OddGrid-GRPO 框架。其核心逻辑在于将强化学习与底层视觉特征深度耦合。
1. 课程引导优化(Curriculum-Guided Optimization)
学习要循序渐进。研究团队将 30,000 张训练图像按难度分为“简单”(15K)、“中等”(10K)和“困难”(5K)三个等级。难度由网格大小、差异属性数量和扰动幅度共同决定。训练从明显的视觉差异开始,逐渐过渡到几乎难以察觉的微小差异。这种“由易到难”的策略有效地稳定了强化学习的训练过程。
2. 距离感知奖励(Distance-Aware Reward)
传统的强化学习通常只给“对”或“错”的二值奖励(0 或 1)。但在网格定位任务中,如果模型猜的位置就在正确答案旁边,它其实已经比猜到天边去要好得多了。
因此,研究者设计了一个基于欧几里得距离的连续奖励函数:
其中 是预测位置,
是真实位置,
是一个随网格大小自适应的参数。这个公式的意思是:预测越接近真实位置,奖励就越高。这种平滑的反馈信号能更好地引导模型建立空间对应关系。
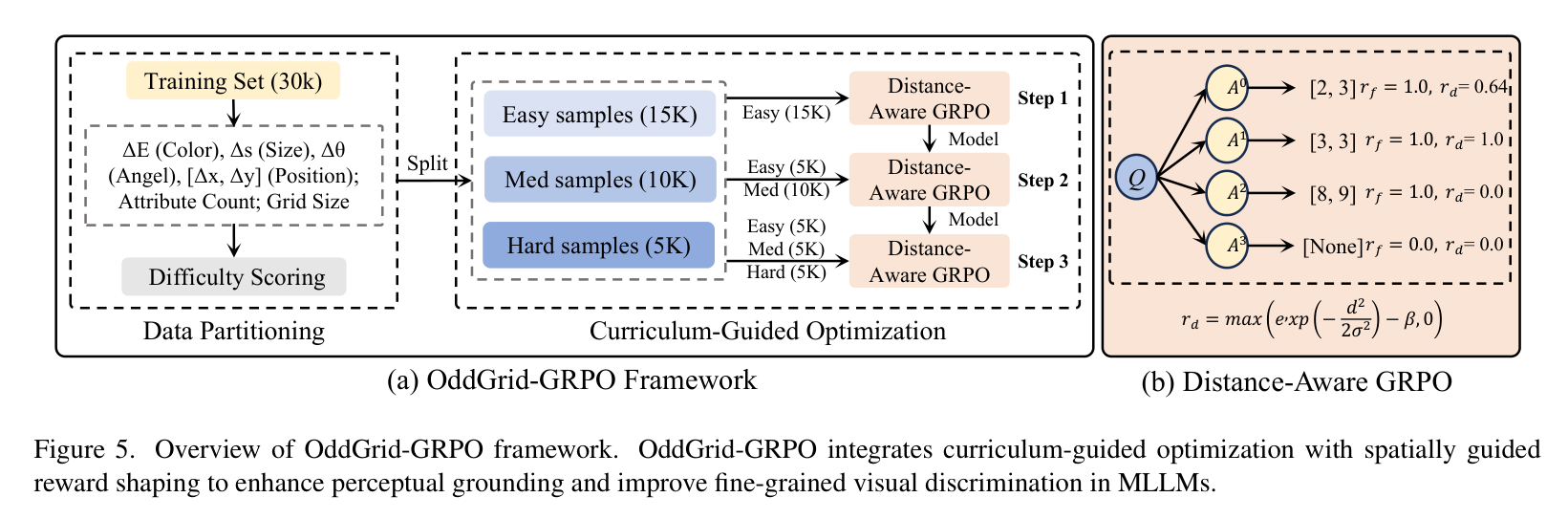
OddGrid-GRPO 框架示意图
在训练流程上,模型的 Input(输入) 是 5x5 到 9x9 不等的网格图像及识别指令,Output(输出) 则要求严格遵循 LaTeX 格式,如 {Row 4, Column 2}。
实验证明,这种方法非常有效。以 Qwen3-VL-2B 为例,经过 OddGrid-GRPO 训练后,其总准确率从 17.14% 飙升至 82.64%,几乎追平了人类水平!
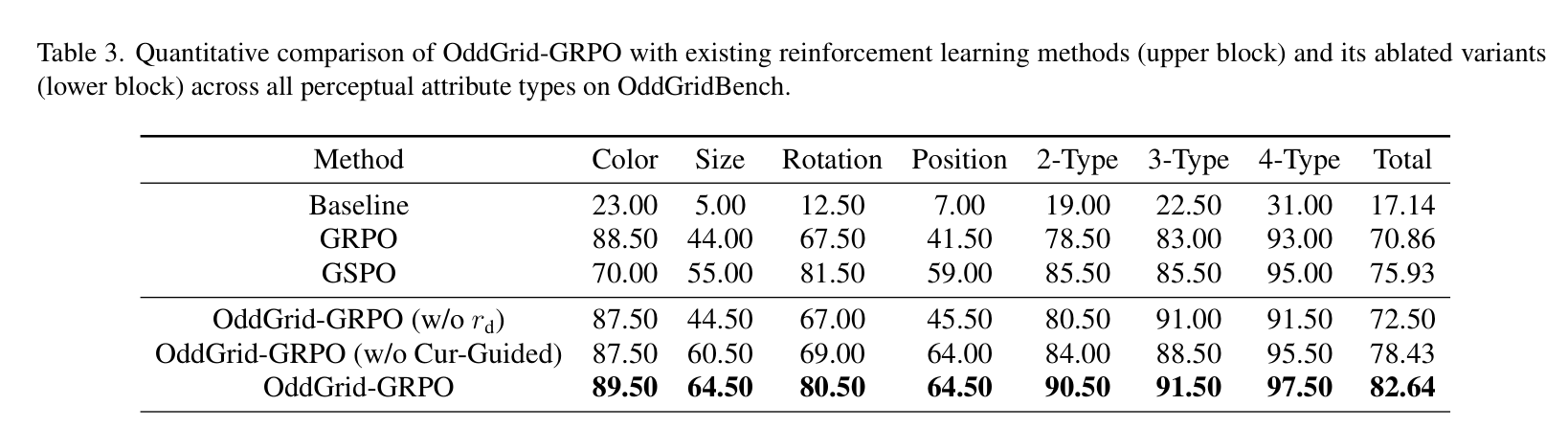
强化学习方法对比,OddGrid-GRPO 提升显著
泛化能力:不仅仅是“刷榜”
你可能会问,这种在合成图标上训练出来的能力,能用到真实世界吗?
研究团队在工业缺陷检测数据集(MVTec-AD, VisA)以及手写体数据集(MNIST)上进行了泛化性测试。在 MVTec-AD 数据集上,Qwen3-VL-2B 在经过训练后,准确率从 20.00% 提升到了 49.00%。这说明经过 OddGrid-GRPO 训练的模型,在未见过的真实场景中依然保持了较强的差异检测能力,显著优于原始基座模型。
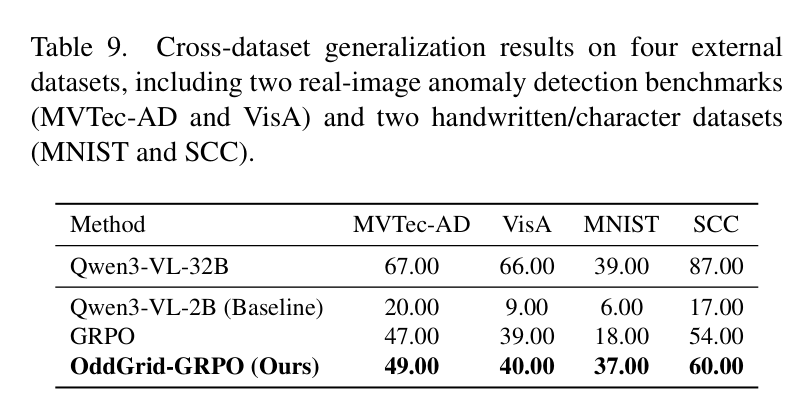
跨数据集泛化实验结果
此外,研究还发现,即使不使用网格布局,而是给模型输入一串独立的图片(Cross-Format),OddGrid-GRPO 训练出的模型依然表现出色,这证明了模型真正习得的是通用的差异辨别能力,而非简单的网格记忆。
写在最后
这项研究给我们提供了一个审视大模型的新视角:聪明的大脑也需要敏锐的眼睛。虽然目前的 MLLM 在逻辑推理上已经非常强大,但在底层视觉感知上仍有巨大的提升空间。
OddGridBench 像是一面镜子,照出了模型在细粒度感知上的短板;而 OddGrid-GRPO 则给出了一条通过强化学习和空间先验来“矫正视力”的可行路径。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)