基于注意力模块及1D - CNN的滚动轴承故障诊断代码复现指南
基于注意力模块及1D-CNN的滚动轴承故障诊断 故障诊断代码 复现 针对传统的卷积神经网络对特征的辨识性差的问题,提出一种将注意力模块与一维卷积神经网络相结合的滚动轴承故障诊断模型 首先以加入噪声的振动信号作为输入,利用“卷积+池化”单元提取信号的多维特征,然后通过注意力模块对特征赋予不同的权重,利用双池化层取代传统卷积神经网络中的全连接层进行特征的再次提取及特征信息整合,最后通过 Softmax层完成轴承状态分类 ●参考文献:2022年太阳能学报EI《基于注意力模块及1D-CNN的滚动轴承故障诊断》 ●数据预处理:1维数据 ●网络模型:AM-CNN ●数据集:西储大学CWRU的10分类任务 ●准确率:100% ●网络框架:pytorch ●结果输出:损失曲线图、准确率曲线图、混淆矩阵、tsne图 ●使用对象:初学者
嘿,各位初学者小伙伴们!今天咱们来聊聊基于注意力模块及1D - CNN的滚动轴承故障诊断,还会带着大家一步步复现代码哦。
在传统的卷积神经网络里,对特征的辨识性是个让人头疼的问题。就好比你在一堆杂物里找东西,眼神不太好,老是找不准关键的东西。所以呢,咱们今天要讲的这个模型,把注意力模块和一维卷积神经网络结合起来,就像是给模型装上了“火眼金睛”,让它能更准确地识别滚动轴承故障特征。
一、数据集
咱们用的是西储大学CWRU的10分类任务数据集,这可是故障诊断领域里常用的数据集。就像是数学课本后面的经典例题,大家都爱用它来练手和验证方法。
二、数据预处理
数据预处理这儿处理的是1维数据。为啥是1维呢?简单来说,滚动轴承的振动信号采集下来很多时候就是以1维数据的形式存在的,咱们得对这些数据进行清理、归一化之类的操作,就像给数据洗个澡、梳个头,让它整整齐齐地进入模型。
三、网络模型:AM - CNN
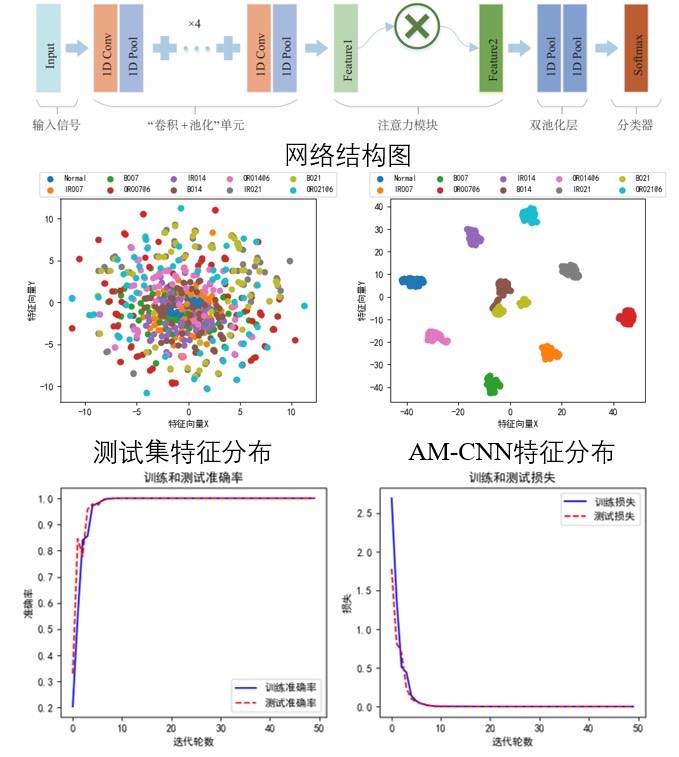
1. 模型架构
咱们的模型AM - CNN,首先是以加入噪声的振动信号作为输入。为啥要加噪声呢?现实世界里的信号可没那么干净,加噪声就是为了模拟真实的复杂环境。然后利用“卷积 + 池化”单元提取信号的多维特征。在PyTorch里,卷积层可以这么定义:
import torch.nn as nn
class AM_CNN(nn.Module):
def __init__(self):
super(AM_CNN, self).__init__()
self.conv1 = nn.Conv1d(in_channels = 1, out_channels = 32, kernel_size = 5, padding = 2)
# in_channels 是输入数据的通道数,因为是1维数据所以通道数为1
# out_channels 是卷积后输出的通道数,这里设为32
# kernel_size 是卷积核的大小,5表示5个连续的数据点作为一个卷积核
# padding = 2 是为了保持输入输出数据长度一致这段代码定义了一个一维卷积层,卷积核大小为5,输出通道数为32。就像是用一个特定大小的“滤网”,在1维的数据上“过滤”,把有用的特征给“捞”出来。
基于注意力模块及1D-CNN的滚动轴承故障诊断 故障诊断代码 复现 针对传统的卷积神经网络对特征的辨识性差的问题,提出一种将注意力模块与一维卷积神经网络相结合的滚动轴承故障诊断模型 首先以加入噪声的振动信号作为输入,利用“卷积+池化”单元提取信号的多维特征,然后通过注意力模块对特征赋予不同的权重,利用双池化层取代传统卷积神经网络中的全连接层进行特征的再次提取及特征信息整合,最后通过 Softmax层完成轴承状态分类 ●参考文献:2022年太阳能学报EI《基于注意力模块及1D-CNN的滚动轴承故障诊断》 ●数据预处理:1维数据 ●网络模型:AM-CNN ●数据集:西储大学CWRU的10分类任务 ●准确率:100% ●网络框架:pytorch ●结果输出:损失曲线图、准确率曲线图、混淆矩阵、tsne图 ●使用对象:初学者
接下来是池化层,池化层可以这么写:
self.pool1 = nn.MaxPool1d(kernel_size = 2, stride = 2)
# kernel_size 是池化窗口大小,这里是2
# stride 是步长,也是2,这样能对数据进行下采样,减少数据量同时保留主要特征池化层就像是把数据“浓缩”,把不重要的信息去掉,只留下关键的部分,减少数据量的同时还能保留主要特征,就像从一篇长文章里提取出关键段落。
2. 注意力模块
特征提取出来后,通过注意力模块对特征赋予不同的权重。注意力模块就像是给每个特征标上不同的“重要程度”标签,让模型更关注那些重要的特征。这里简单模拟一下注意力模块的部分原理代码(实际可能更复杂):
import torch
import torch.nn.functional as F
def attention_module(feature_map):
avg_pool = F.avg_pool1d(feature_map, feature_map.size(2))
# 全局平均池化,把特征图在空间维度上压缩成1维向量
fc = nn.Sequential(
nn.Linear(feature_map.size(1), feature_map.size(1) // 16, bias = False),
nn.ReLU(inplace = True),
nn.Linear(feature_map.size(1) // 16, feature_map.size(1), bias = False),
nn.Sigmoid()
)
y = avg_pool.view(avg_pool.size(0), -1)
y = fc(y)
y = y.view(y.size(0), y.size(1), 1)
return feature_map * y.expand_as(feature_map)这段代码先通过全局平均池化把特征图在空间维度上压缩,然后通过全连接层、ReLU激活函数和Sigmoid激活函数得到权重系数,最后把权重系数和原来的特征图相乘,实现对特征赋予不同权重。
3. 双池化层与分类
接着,利用双池化层取代传统卷积神经网络中的全连接层进行特征的再次提取及特征信息整合。全连接层参数太多容易过拟合,双池化层就没这毛病。最后通过Softmax层完成轴承状态分类。Softmax层在PyTorch里很简单:
self.fc = nn.Linear(32, 10)
# 这里32是前面卷积和池化处理后的特征维度,10是因为有10分类任务
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = attention_module(x)
x = self.pool1(x)
x = x.view(-1, 32)
x = self.fc(x)
return F.log_softmax(x, dim = 1)在forward函数里,数据依次经过卷积、池化、注意力模块、再次池化,最后通过全连接层和Softmax函数输出分类结果。
四、网络框架:PyTorch
为啥用PyTorch呢?它简单易懂,动态图机制让调试和开发都很方便,对咱们初学者特别友好。就像骑自行车,PyTorch这自行车好上手,能让你在深度学习的道路上快速起步。
五、训练与结果输出
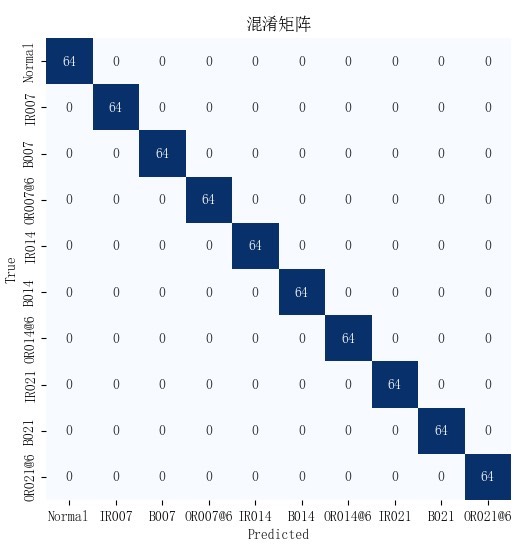
训练过程就不详细贴代码啦,主要思路就是定义损失函数、优化器,然后不断迭代训练。咱们最终的结果输出有损失曲线图、准确率曲线图、混淆矩阵、tsne图。这些图就像是模型的“体检报告”,损失曲线图能看出模型训练过程中损失的变化,准确率曲线图能看到模型准确率怎么一步步提升,混淆矩阵可以直观地看出模型在各个类别上的分类情况,tsne图则能对数据的分布有个可视化的了解。
按照这个思路,大家就能复现基于注意力模块及1D - CNN的滚动轴承故障诊断代码啦,祝大家都能顺利完成,在故障诊断的学习道路上越走越远!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献91条内容
已为社区贡献91条内容

所有评论(0)