【第四十周】论文复现记录03
文章目录
摘要
本周主要完成了论文模型的复现,对过程中遇到的问题进行记录。同时对论文《Token Sequence Compression for Efficient Multimodal Computing》第二种方法进行进行补充学习。
Abstract
This week, I successfully reproduced the model from the paper and recorded the problems encountered during the process.In addition, I further studied the second method proposed in the paper Token Sequence Compression for Efficient Multimodal Computing.
一、复现过程中问题记录
1. 服务器相关问题
1.1 服务器中模型下载相关问题
问题1:从huggingface中下载的模型默认下载到哪里?服务器中下载到什么位置呢?是否可以自定义位置?能否在D盘?
模型默认下载到系统的缓存目录:
在这里插入图片描述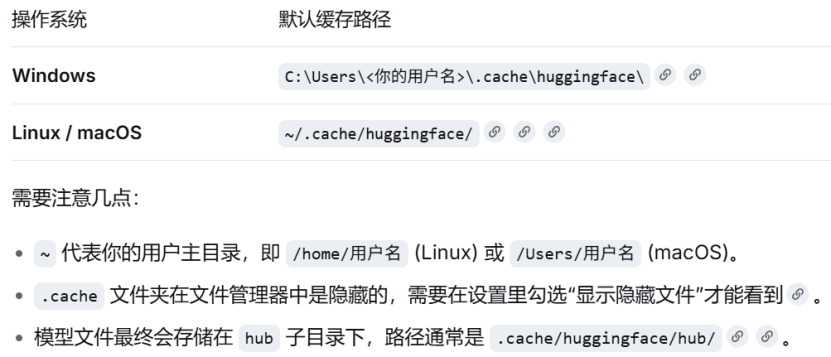
可以进行自定义下载路径,方法有三种:
1,在代码中临时指定
通过环境变量:设置 HF_HOME 环境变量可以更改整个HuggingFace的根目录
2,通过代码参数:在代码中直接指定,如:
from_pretrained("model_name", cache_dir="/your/custom/path")
3,设置HF_HOME环境变量
问题2:下载huggingface模型使用镜像下载是否需要开代理?
使用 hf-mirror.com 这类镜像站下载模型时,通常不需要额外开启VPN或代理。镜像站本身就是为了解决国内网络访问HuggingFace官方慢或不稳定的问题而设计的
问题3:下载模型是占用服务器的数据盘还是系统盘?使用服务器如何修改路径为下载到数据盘?数据盘和系统盘有什么区别?类似电脑的c盘和d盘吗?
默认情况下,模型会下载到系统盘。但是可以进行修改,将模型放在数据盘
方法一:设置环境变量
export HF_HOME=/root/autodl-tmp/hf_cache
方法二:在脚本开头输入
import os
os.environ['HF_HOME'] = '/root/autodl-tmp/hf_cache'
如果已经下载模型到系统盘,可以对模型进行迁移
cp -r ~/.cache/huggingface /root/autodl-tmp/hf_cache
补充说明:
可以先使用命令将模型下载好最后再跑使用模型的脚本,下载指令如下:
#设置国内镜像站,以加速下载
export HF_ENDPOINT=https://hf-mirror.com
#开始下载模型到数据盘
huggingface-cli download zai-org/Glyph --local-dir /root/autodl-tmp/Glyph --resume-download
指令说明:
从国内镜像站 hf-mirror.com 下载,速度会快很多。
将模型文件直接存放在数据盘 /root/autodl-tmp/Glyph 目录下。
加上 --resume-download 参数,可以防止下载中断后需要从头再来
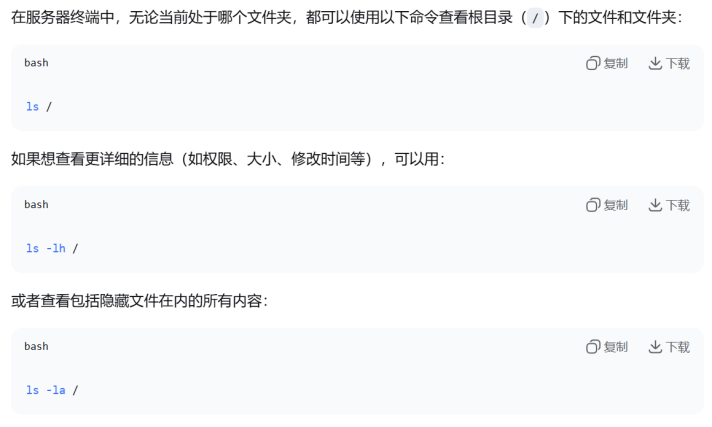
1.2 如何在服务器已经打开某一个文件夹的时候查看根目录下其他文件
1.3 无卡开机模式
基本操作
如何开启:在服务器开机的状态下无法开启,只有把服务器关机后才能选择该模式。
无卡开机模式:不占用GPU,只占用CPU/内存。释放GPU资源,为其他需要计算的任务腾出空间,平台会为你分配非常有限的CPU和内存。
无卡模式优点:工作流程解耦。无卡模式将“准备”和“计算”两个阶段彻底分离:
- 无缝环境准备:在无卡模式完成数据上传、环境配置、代码调试等所有准备工作,而无需为这些时间付费
- 随时切换,状态保留:在无卡模式下配置好的环境,在切换回GPU模式后会被完整保留,实现了工作状态的平滑过渡。
- 不影响数据存储:关机切换模式时,实例的配置和数据盘内容会保留,确保数据安全。
无卡模式缺点:由于无卡模式不占用GPU,因此在无卡模式时可能原本使用的GPU会被释放,可能会被租走,那么当结束无卡模式时,可能需要重新租其他有空余资源的服务器。
无卡模式下数据能下载到服务器的数据盘吗?
数据完全可以正常下载到服务器的数据盘。因为
1,下载操作依赖的是网络和 CPU,GPU 不参与下载过程,因此有无 GPU 不影响下载。
2,数据盘是独立的存储设备,无论有没有 GPU,都能正常读写数据盘。。
需要注意:
1,确认目标路径是否挂载了数据盘。
2,写入权限。
1.4 对于环境变量的设置
API KEY以及有些变量是不适合直接写在代码中,可以专门用个文件写变量,最后进行调用。
例如:创建一个key.env文件用来存放环境变量,在具体脚本中
#加载环境变量(使用绝对路径)
load_dotenv(dotenv_path='key.env文件的绝对路径')
#获取API密钥和基础URL
api_key = os.getenv('key.env文件中API_KEY变量名')
其他环境变量同理
1.5 服务器中相关功能介绍
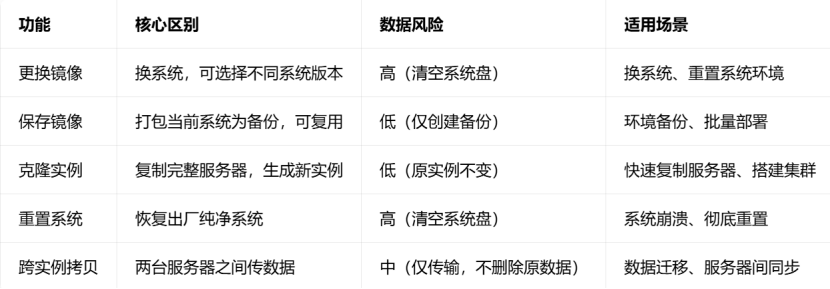
1,更换镜像
**核心作用:**给当前云服务器重装 / 更换操作系统,相当于给电脑换系统。
适用场景:
原来的系统用腻了 / 出问题了,想从 CentOS 换成 Ubuntu,或从 Windows 换成 Linux
系统被入侵、文件损坏,需要彻底重置系统环境
2,保存镜像
**核心作用:**把当前服务器的系统环境(含已安装的软件、配置、数据)打包成一个自定义镜像,相当于给系统做一个 “完整快照备份”。
适用场景:
搭建好一个标准环境(比如 Web 服务、数据库、开发环境),想快速复制到多台服务器
给当前服务器做系统级备份,出问题时可以快速恢复
跨地域 / 跨账号迁移服务器环境
3,升降配置
**核心作用:**调整云服务器的硬件规格,比如 CPU 核心数、内存大小、带宽、磁盘容量等,相当于给电脑升级 / 降级硬件。
二、《Token Sequence Compression for Efficient Multimodal Computing》方法二:与显著性无关的方法
1. 与显著性无关的方法
1.1 随机采样(Random Sampling)
从所有编码器输出的视觉token中均匀随机地抽取固定数量的token,抽取时不考虑Token的内容、位置、或任何重要性分数。最后,保留token原始顺序直接与文本拼接。方法适用于视觉token间存在高度冗余的情况。
1.2 空间采样(Spatial Sampling):按均匀步长采样Token
利用视觉Token与图像空间位置的对应关系(例如CLIP将图像划分为14×14或24×24的网格,每个网格对应一个Token),按照均匀步长在网格上进行采样。等同于对图像进行均匀降采样。
**方法可行原因:**图像中相邻区域的视觉信息往往相似,因此均匀采样可以覆盖图像的不同区域,避免集中于局部。
1.3 聚类聚合(Cluster & Aggregate)
将聚类后的每个簇内所有Token的嵌入取平均,生成一个聚合Token,无需显著性计算
**方法可行性原因:**每个簇内的Token可能非常相似(冗余),因此用一个平均向量代表整个簇,既能大幅压缩数量,又能保留该区域的核心特征。
这些方法均无需微调,直接在投影层后、LLM前对Token序列进行压缩。
2. 结论
1,简单的聚类聚合方法(Cluster & Aggregate)效果最优
在所有无需微调(training‑free)的视觉Token压缩方法中,基于K‑means++聚类后对每个簇内Token嵌入取平均的方法表现最佳,超越了之前无需微调的SOTA方法。该方法计算简单、不依赖文本提示、不依赖注意力分数,且性能稳定。
2,空间采样和随机采样同样具有很强的竞争力
即使是最简单的均匀空间采样或完全随机采样,其性能也超过了大部分基于注意力的显著性方法。这进一步说明视觉编码器输出的Token存在高度冗余,以至于随机子集仍能保留足够的语义信息。
3,基于注意力的显著性方法存在根本性问题
显著性区域与人类直觉不符:高注意力的Token往往不是任务真正关心的区域。
显著性排名不稳定:在不同LLM层之间变化剧烈,缺乏收敛性。
对文本提示不敏感:改变问题内容,显著性排名几乎不变,无法实现动态任务适配。
因此,注意力分数不能可靠地衡量视觉Token的重要性,基于它的压缩方法效果较差。
4,视觉编码器存在高度冗余和低效
原始视觉Token中大量信息是重复的或非关键的,以至于丢弃大部分Token(甚至随机丢弃)仍能保持甚至提升某些任务上的准确率(如VizWiz)。这表明当前的视觉编码方式需要从根本上重新思考,而不是仅仅在LLM层面做后处理压缩。
总结
服务器中下载模型比较花时间,可以尝试更换下载源,使用国内的镜像下载。
同时可以直接在本机下载好模型后上传到服务器,因为租用的服务器都有带宽限制,还有流量限制。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)