Superpowers - 06 从文档到“结构契约”:Superpowers 技能剖析与 Frontmatter 深度解读
文章目录
- Pre
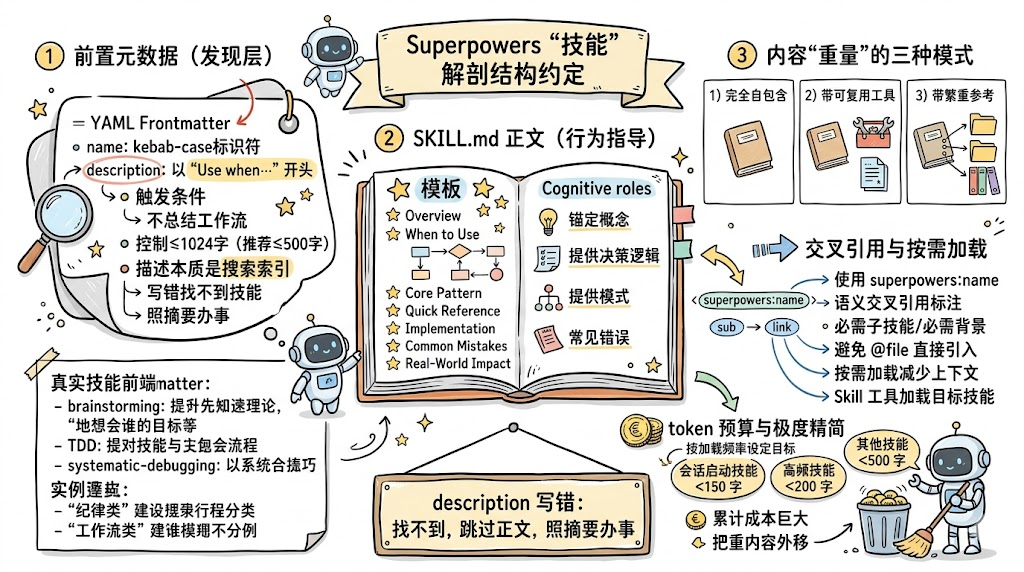
- 一、技能不是文档,而是结构契约
- 二、统一的技能目录结构与扁平命名空间
- 三、Frontmatter:发现层的两行 YAML 有多关键?
- 四、Claude 搜索优化(CSO):如何写出可被正确发现的描述?
- 五、推荐的技能正文结构:从 Overview 到 Common Mistakes
- 六、真实技能的前置元数据模式:纪律 vs 工作流
- 七、三种文件组织模式:自包含、可复用工具与繁重参考
- 八、技能间的交叉引用:为什么避免 `@` 语法?
- 九、Token 预算与加载优先级:不对称的现实约束
- 十、命名约定:name 既是标识符,也是搜索关键词
- 十一、 实战建议
- 十二、总结:description 不是文档,而是索引
Pre
Superpowers - 01 让 AI 真正“懂工程”:Superpowers 软件开发工作流深度解析
Superpowers - 02 用 15 个技能给你的 AI 装上「工程大脑」:Superpowers 快速开始深度解析
Superpowers - 03 一文搞懂 Superpowers:面向多平台 AI 编码助手的安装与实践指南
Superpowers - 04 从“会写代码”到“会做工程”:Superpowers 工作流引擎架构深度剖析
Superpowers - 05 构建一个“会自己找插件用”的 Agent:深入解析 Superpowers 的技能发现与激活机制
在 Superpowers 框架里,“技能(Skill)”不再是随意书写的说明文档,而是 AI Agent 与技能作者之间的一份结构化契约。这份契约决定了:一个技能是否会被发现、何时被激活、被加载后如何具体影响 Agent 的行为,以及在不浪费 Token 的前提下,如何提供足够的深度与工具支持。
本文面向已经在实践 LLM 应用、Agent 框架或工具链建设的开发者与技术作者,系统拆解 Superpowers 技能的内部结构、前置元数据(Frontmatter)设计与撰写规范,并结合仓库中的真实技能示例,讨论如何写出“可被正确发现、合理激活、且 Token 友好”的高质量技能。
一、技能不是文档,而是结构契约
Superpowers 给技能下的第一个定义非常关键:技能不是自由格式的说明书,而是一份结构化协议,这个协议在逻辑上拆分为三个层级:
- 发现元数据(Discovery Metadata)
- 行为指导(Behavioral Guidance)
- 辅助资源(Auxiliary Resources)
这三个层级分别解决三个问题:
-
发现元数据:技能要不要被加载?
Agent 在“发现阶段”只看这一小块信息来决定是否调用 Skill 工具并加载该技能,如果这里写错了,等于技能在系统中“隐身”。 -
行为指导:加载之后具体怎么做?
一旦技能被加载,正文部分负责约束和引导 Agent 的行为:用什么流程、遵循什么模式、避免哪些错误、如何做权衡等。 -
辅助资源:如何在不膨胀关键路径的前提下提供深度?
各种长参考、可复用脚本、模板、API 文档等被放在独立文件中,避免在每次技能加载时把上下文“灌爆”,但仍可按需引用。
这种设计背后,有几个非常工程化的考虑:
- 前置元数据如果泄露了工作流摘要,Agent 就可能“抄近道”,只按摘要执行而不去读技能正文。
- 正文如果写成大而全的长文,并且所在技能又被频繁或自动加载,那么你会在每个会话无意义地燃烧大量 Token。
- 参考资料如果被直接内联到技能正文中,会让与当前任务无关的大块内容充斥上下文,降低检索与推理效果。
用一句话总结:Superpowers 把“写技能”从写说明文档,提升为设计一份在 Agent 运行时具有真实约束力的协议对象。
二、统一的技能目录结构与扁平命名空间
Superpowers 中所有技能统一放在 skills/ 目录下的扁平命名空间中,每个技能一个子目录,至少包含一个 SKILL.md 文件,其他文件则为可选的辅助资源。
典型结构如下:
skills/
skill-name/
SKILL.md
supporting-file.* # 仅在需要时添加
这里有两个关键选择:
-
扁平命名空间(无嵌套技能目录)
系统刻意禁止在技能目录中再嵌套技能目录,这样 Skill 工具在发现阶段可以通过一次扫描完成全局技能列表,避免出现“某些技能藏在别的技能下面”的情况。 -
一个技能 = 一个子目录 = 一个 SKILL.md
目录层级直接映射到技能标识符和交叉引用形式,降低 Agent 侧搜索和加载的复杂度。
对开发者而言,这意味着:
- 你在添加新技能时不需要纠结“放在哪个主题目录下”;
- 只要遵循约定的目录结构和命名规范,Skill 工具就能在一次扫描中把它纳入候选集合。
三、Frontmatter:发现层的两行 YAML 有多关键?
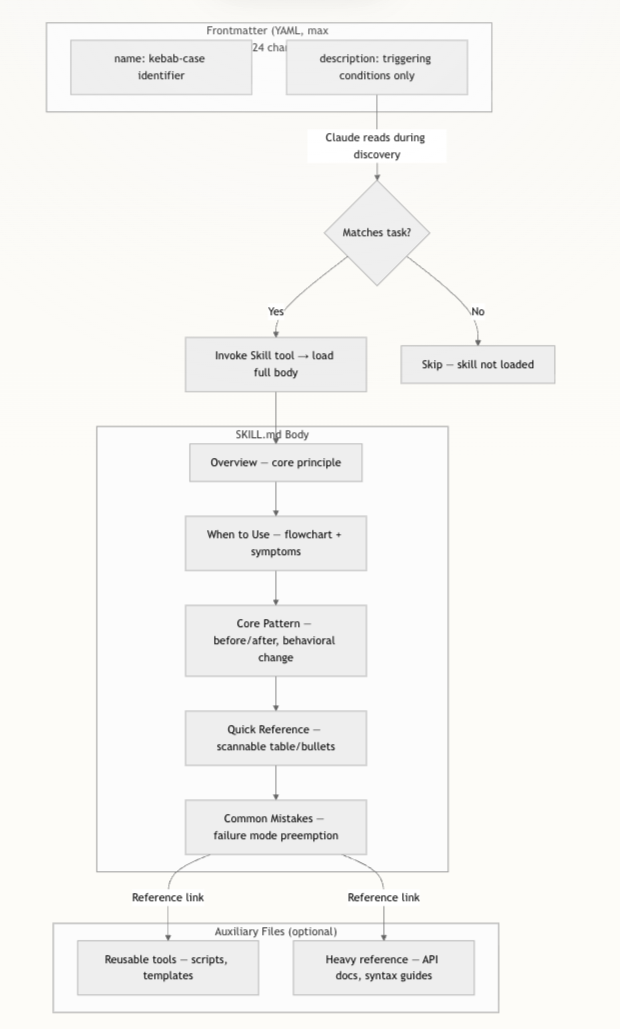
每个技能文件 SKILL.md 必须以一段由 --- 包裹的 YAML 前置元数据(Frontmatter)开头,这就是 Agent 在发现阶段唯一可见的文本内容。
示例结构如下:
***
name: skill-name-with-hyphens
description: Use when [specific triggering conditions and symptoms]
***
3.1 只有两个必需字段
虽然 agentskills.io 规范允许更多字段,但 Superpowers 只强制这两个字段:
| 字段 | 约束 | 用途 |
|---|---|---|
name |
仅限字母、数字、连字符,不允许括号和特殊字符 | 作为唯一标识,用于 superpowers:name 交叉引用和路径名 |
description |
必须用第三人称、以 “Use when…” 开头、不能总结技能工作流,推荐不超过 500 字符,硬上限 1024 字符 | Agent 依据它判断是否为当前任务加载该技能 |
注意这里的一个设计细节:整个前置元数据块的字符数硬性限制为 1024,这是为了确保“发现层”足够轻量,避免在每次技能扫描时浪费过多上下文。
3.2 description 是全系统最重要的单一字段
Superpowers 明确指出:description 是技能系统中最关键的字段,因为在调用 Skill 工具之前,Agent 只会看到这一小段文本。
- 如果它写得过于模糊,Agent 可能永远不会选择这个技能。
- 如果它写成了“流程摘要”,Agent 可能直接按摘要执行,而不调用技能,导致你在正文里写的所有流程、模式和限制形同虚设。
因此,在 Superpowers 的实践中,围绕 description 发展出了一套专门的写作规范:Claude 搜索优化(Claude Search Optimization, CSO)。
四、Claude 搜索优化(CSO):如何写出可被正确发现的描述?
CSO 是围绕 description 字段形成的一套写作纪律,目标是最大化技能被正确发现与加载的概率,同时避免描述本身替代技能正文。
4.1 首要原则:描述触发条件,而不是工作流
经验表明,如果你在 description 中详细写了“这个技能将如何执行步骤 A、B、C”,Claude 往往会把它当成“完整指令”,直接按这几句话执行,而不会去加载和遵循完整的技能正文。
对比示例非常典型:
# ❌ 错误:总结了工作流 —— Claude 可能会抄近道跳过技能正文
description: Use when executing plans - dispatches subagent per task with code review between tasks
# ✅ 正确:仅包含触发条件 —— 迫使 Claude 阅读完整技能
description: Use when executing implementation plans with independent tasks in the current session
第二种写法只描述“当前任务何时适用该技能”,而不暴露具体的执行步骤,从而迫使 Agent 调用 Skill 工具加载全文。
4.2 CSO 的几条具体写作规则
在不泄露工作流的前提下,CSO 还强调几类实践:
-
始终以 “Use when…” 开头
这是一个显式的触发条件锚点,也利于模型在搜索时对齐模式。 -
描述的是问题和症状,而非某种语言的表象
如:使用“竞态条件、时序依赖”等概念,而不是“setTimeout、sleep”等具体 API 名称,除非技能本身是特定技术栈技能。 -
包含 Agent 可能用来搜索的关键词
如:典型错误信息、症状、同义词、相关工具名称,让技能在向量或关键词召回时有更大命中概率。 -
使用第三人称表述
因为 description 会被注入系统提示,通常以“Assistant 应该…”这样的语境呈现,用第三人称更自然。 -
长度控制在 500 字符内(总上限 1024)
给未来可能新增的元字段留出空间,同时避免发现层过胖。
实操建议:
- 把
description当作“技能的搜索索引条目”,而不是“技能正文摘要”。 - 写完后问自己:如果 Agent 仅看这段文本,它是否能正确判断“何时需要这个技能”,但又不会误以为这里就是全部步骤?
五、推荐的技能正文结构:从 Overview 到 Common Mistakes
Frontmatter 之后,就是真正承载行为逻辑的技能正文。Superpowers 为技能正文设计了一套推荐的章节模板,虽然没有强制 schema 校验,但在仓库中被广泛遵循。
5.1 推荐模板结构
文档给出如下 Markdown 模板:
# Skill Name
# Overview
What is this? Core principle in 1-2 sentences.
# When to Use
[Small inline flowchart IF decision non-obvious]
Bullet list with symptoms and use cases
When NOT to use
# Core Pattern (for techniques/patterns)
Before/after code comparison
# Quick Reference
Table or bullets for scanning common operations
# Implementation
Inline code for simple patterns
Link to file for heavy reference or reusable tools
# Common Mistakes
What goes wrong + fixes
# Real-World Impact (optional)
Concrete results
5.2 各章节的认知职责
每个章节都有清晰的“认知角色”:
- Overview:用 1–2 句给出技能的核心原则,让 Agent 快速建立概念锚点。
- When to Use:给出具体触发条件和症状;对于复杂决策,可以配 Graphviz 流程图帮助 Agent 决定是否继续执行技能。
- Core Pattern:对技术型/模式型技能,用“Before/After”的对比方式,突出行为上的变化,而非只列出步骤。
- Quick Reference:以表格或要点形式列出常见操作,方便 Agent 快速扫描,而不必每次阅读全文。
- Implementation:给出简短的内联代码示例,或者链接到外部脚本/模板,避免把大量参考代码塞进正文。
- Common Mistakes:总结技能旨在预防的典型失败模式,并给出修正建议,这对减少错误路径非常重要。
- Real-World Impact(可选):用具体结果或案例强化技能的重要性,让 Agent 更有“使用这个技能的动机”。
5.3 流程图:只在决策复杂时使用
当技能的“使用时机”或内部流程存在非线性决策点时,推荐在 “When to Use” 中嵌入 Graphviz DOT 语法的流程图。不过文档强调:流程图只用于以下情况:
- 决策点本身不直观;
- 流程存在可能过早终止的循环;
- 存在“用 A 还是用 B”的分支逻辑。
而线性步骤、普通参考和代码示例仍然用标准 Markdown 书写,避免流程图滥用带来的阅读负担。
六、真实技能的前置元数据模式:纪律 vs 工作流
仓库中多个核心技能的 description 展现了两类典型模式:纪律类技能与工作流类技能。
6.1 典型技能与触发策略
若干技能以及其截断的描述与触发策略:
| 技能 | 描述(截断)示例 | 触发策略 |
|---|---|---|
brainstorming |
“You MUST use this before any creative work…” | 强制语气 + 穷举使用场景 |
test-driven-development |
“Use when implementing any feature or bugfix, before writing implementation code” | 时间条件(写实现代码前) |
systematic-debugging |
“Use when encountering any bug, test failure, or unexpected behavior, before proposing fixes” | 时间条件 + 症状枚举 |
receiving-code-review |
“Use when receiving code review feedback, before implementing suggestions…” | 时间条件 + 边缘情况约束 |
verification-before-completion |
“Use when about to claim work is complete… before committing or creating PRs” | 时间条件 + 动作枚举 |
dispatching-parallel-agents |
“Use when facing 2+ independent tasks that can be worked on without shared state…” | 结构条件(任务独立性) |
subagent-driven-development |
“Use when executing implementation plans with independent tasks in the current session” | 结构条件 + 时间条件 |
6.2 两种模式:纪律类 vs 工作流类
从这些示例可以归纳出两种核心模式:
-
纪律类技能(Discipline Skills)
如 TDD、系统化调试、完成前验证等,强调的是“在做某件事情之前,你必须先做这套流程”。- 常用时间触发器(before writing code / before proposing fixes / before claiming work is complete)。
- 常配合强制语气(MUST use),减少 Agent 主观跳过的空间。
-
工作流类技能(Workflow Skills)
如并行子 Agent 分派、Subagent 驱动开发等,更关注当前任务结构是否满足一定条件。- 常用结构条件(独立任务、多步骤实现、特定依赖关系)指明适用场景。
- 时间条件常作为辅助手段(在执行某类计划时等)。
对技能作者的启发是:
- 如果你的技能是“流程纪律”,请突出时间触发布局,让 Agent 在关键节点“想起”它。
- 如果你的技能是“工作流模式”,就从任务结构特征出发描述触发条件。
七、三种文件组织模式:自包含、可复用工具与繁重参考
虽然前置元数据与正文结构是所有技能共享的“硬契约”,但技能目录内具体如何组织文件,可以根据内容重量采用三种模式。
7.1 自包含技能(Self-contained Skill)
defense-in-depth/
SKILL.md # 所有内容内联
- 所有概念、流程、示例代码等都在
SKILL.md中完成。 - 适用于:原则性技能、长度有限(例如代码不超过约 50 行)的模式、检查清单与简单流程。
这是最常见、也是默认的组织方式。
7.2 带可复用工具的技能(Skill with Reusable Tools)
condition-based-waiting/
SKILL.md # 概述 + 模式说明
example.ts # 可直接复制/调整的辅助代码
特征是:目录下存在可直接操作的脚本或模板文件,这些文件可被开发者复制、修改并直接运行。
SKILL.md负责讲清模式、使用方式和注意事项。- 辅助文件则提供“可落地”的代码实现。
与“繁重参考”的区别在于,这里内容是可执行/可操作的,而非纯信息性文档。
7.3 带繁重参考的技能(Skill with Heavy Reference)
pptx/
SKILL.md # 概述 + 工作流
pptxgenjs.md # ~600 行 API 参考
ooxml.md # ~500 行 XML 结构说明
scripts/ # 可执行工具(可选)
当技能涉及大量 API 文档、协议细节、复杂语法说明时,这些“重参考”被拆分为独立 Markdown 文件,由 SKILL.md 以链接形式索引:
SKILL.md扮演索引页与工作流指南的角色。- 参考文件充当“书架”,在需要时按需读取。
这种结构既保持主技能文档可浏览、可加载,又支持深度查阅,避免在每次技能加载时把几百行参考文档硬塞进上下文。
八、技能间的交叉引用:为什么避免 @ 语法?
在复杂项目中,一个技能引用另一个技能是常态。Superpowers 为此设计了专门的交叉引用语法,而刻意避免了 @file 方式。
8.1 标准写法:语义引用而非文件导入
推荐写法示例:
**REQUIRED SUB-SKILL:**
Use superpowers:test-driven-development
**REQUIRED BACKGROUND:**
You MUST understand superpowers:systematic-debugging
这里有三个关键点:
- 使用
superpowers:name这种语义引用,而不是@path/to/SKILL.md。 - 用清晰的级别标记(REQUIRED SUB-SKILL、REQUIRED BACKGROUND),而不是软性提示(see also)。
- 在需要时,Agent 会基于
name使用 Skill 工具加载对应技能,而不是在解析文本时就硬性展开引用文件。
8.2 避免 @ 导入的原因:Token 成本
@ 导入机制的一个典型问题是:只要引用存在,对应文件就会立刻被加载进上下文,即使当前任务并不会真正用到它。
在大型技能体系中,这可能意味着:
- 仅仅因为一个技能引用了几个子技能,你就在每次加载时自动拖带数十甚至上百 KB 的上下文。
- Token 成本呈指数叠加,对长会话与多轮交互尤为致命。
相比之下,语义交叉引用 + Skill 工具按需加载的组合,使 Agent 能够先知道“这里存在一个相关技能”,但仅在需要时才实际加载其正文,从而显著节约上下文预算。
九、Token 预算与加载优先级:不对称的现实约束
在实际系统中,技能加载具有明显的频次差异:有的技能在每个会话一开始就被注入,有的则只在少数任务下按需加载。
文档因此定义了一个 Token 预算层级和目标字数:
| 技能类别 | 目标字数 | 理由 |
|---|---|---|
| 会话启动工作流(using-superpowers) | < 150 字 | 通过 SessionStart 钩子注入到每一个对话 |
| 高频加载技能(brainstorming, TDD 等) | < 200 字 | 被多种任务类型频繁引用,加载概率高 |
| 其他技能 | < 500 字 | 按需加载,但仍建议保持简洁,减少不必要消耗 |
9.1 SessionStart 钩子如何加载技能?
在 SessionStart Hook 中,系统会读取 using-superpowers/SKILL.md,对内容进行 JSON 转义,然后作为 additionalContext 注入到钩子输出,使其在任何用户消息到达前就出现在 Agent 上下文中。
这意味着:
using-superpowers是所有对话的“基础规则集”,必须极度精简。- 任何被 SessionStart 或其它高频 Hook 注入的技能,其每增加一行文字都会乘以整个系统的所有会话数放大成本。
9.2 Token 压缩策略
为了在保证表达力的前提下控制成本,Superpowers 建议的一些压缩手段包括:
- 将详细参数说明移入可执行脚本或工具的
--help输出,而不是全部写在 SKILL.md 中。 - 使用交叉引用代替复制粘贴别的技能内容,让 Agent 在需要时再加载那个技能。
- 在代码示例上选择一个高质量代表性例子,而不是堆叠很多类似示例。
Token 预算是真实且不对称的,特别是会话启动技能,其总体开销往往比按需加载技能高出多个数量级。
十、命名约定:name 既是标识符,也是搜索关键词
最后,还有一个经常被忽略,但在 Superpowers 中被反复强调的细节:技能名称本身就承担着标识符、搜索目标与认知锚点三重角色。
10.1 命名规则
- 使用小写 kebab-case:如
condition-based-waiting、subagent-driven-development。 - 只允许字母、数字与连字符:不允许括号和其它特殊字符,由前置元数据规范强制限制。
- 流程型技能优先使用以动词开头的动名词:如
creating-skills、testing-skills、debugging-with-logs。 - 用动作或核心洞察命名,而不是模糊类别:
- 用
flatten-with-flags而不是data-structure-refactoring。 - 用
root-cause-tracing而不是debugging-techniques。
- 用
10.2 名称的三重角色
一个好的技能名能够同时完成三件事:
-
唯一标识符
被用于目录路径和superpowers:name类型的交叉引用。 -
搜索关键词
当 Agent 在技能空间中检索时,技能名本身就参与相似度与关键词匹配。 -
认知锚点
让人类读者和 Agent 看到名称,就能大致理解技能的核心意图与适用场景。
因此,可以把为技能命名视为 CSO 的一部分:如果你用的是人类和 Agent 都自然会搜索的词汇,技能被找到的机会就会显著提高。
十一、 实战建议
结合整篇文档的设计理念,如果你计划在 Superpowers 或类似框架中编写自己的技能,可以从以下几个方向着手实践:
-
先想清楚:这是纪律,还是工作流?
- 纪律技能突出“在某个关键时间点之前必须执行”;
- 工作流技能突出“当任务结构满足某些条件时适用”。
-
把
description当作搜索条目,而不是宣传文案- 明确“Use when…”后面要回答的是:在什么症状或条件下我应该想到这个技能?
- 避免把任何流程细节写进这段描述。
-
为技能正文设计“认知路径”
- 从 Overview 迅速建立核心概念;
- 在 When to Use 做清晰决策树(必要时用流程图);
- 在 Core Pattern 中强调行为变化,而不是堆叠步骤;
- 在 Common Mistakes 中写下你希望 Agent 不再犯的典型错误。
-
根据内容重量选择文件组织模式
- 简单模式和原则:自包含在一个 SKILL.md 中即可;
- 涉及可复用脚本:把脚本拆出去、在正文中链接;
- 有长文档和 API 细节:抽成单独 Markdown 参考,并让 SKILL.md 只做索引和工作流说明。
-
时刻记住 Token 预算与加载频次是不对称的
- 任何有可能被自动加载(如 SessionStart 注入)的技能必须被压缩到骨感;
- 把“可选的深度”移到辅助文件中,保证发现层和主体的“关键路径”足够瘦。
十二、总结:description 不是文档,而是索引
-
description 字段不是文档,而是一条搜索索引条目。
技能编写中最常见的失败模式,就是写出了一段“准确但摘要化”的描述,结果 Claude 完全跳过技能正文,仅按描述行事。 -
Token 预算是真实且不对称。
一个 500 字且加载到每个会话的技能,其累计上下文消耗远远超过一个按需加载的 500 字技能。在为了“看起来完整”而添加内容前,先问自己:它的激活频率有多高?值不值得这份开销?
理解“技能剖析与 Frontmatter”中这套结构契约, 是从“写提示词”进化为“设计可组合技能体系”的关键一步。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)