虚拟机openclaw切主机ollama模型
阿里百炼qwen3.5模型tokens没用两天告竭,切换主机ollama的qwen3.5 2b模型(内存不够维持高体量模型)
步骤
1.ipconfig查询主机IP,管理员 PowerShell 运行
$env:OLLAMA_HOST="0.0.0.0:11434"; ollama serve
让 Ollama 监听本机所有网卡的 11434 端口,允许局域网内其他设备访问你的 AI 模型。
# 查看 11434 端口是否被 Ollama 监听
netstat -ano | findstr :11434

从提供的 netstat 输出来看,网络端口监听状态正常
2.控制台拼地址查网络情况
curl 192.168.1.113 11434
让 Ollama 监听所有网卡(0.0.0.0)
# 临时生效
$env:OLLAMA_HOST="0.0.0.0"
ollama serve
# 永久生效(推荐):系统环境变量
[Environment]::SetEnvironmentVariable("OLLAMA_HOST", "0.0.0.0", "Machine")
# 然后重启 Ollama 服务(任务管理器→服务→找到 Ollama 重启)
验证监听(主机执行):应看到 0.0.0.0:11434
# Windows
netstat -ano | findstr :11434
# Linux/macOS
ss -tuln | grep 11434
主机防火墙放行 11434 端口
New-NetFirewallRule -DisplayName "Ollama" -Direction Inbound -LocalPort 11434 -Protocol TCP -Action Allow
虚拟机端确认能 ping 通主机,测试端口连通性
ping 192.168.1.113
# 虚拟机执行
curl -v http://192.168.1.113:11434
# 成功应返回 Ollama 版本信息(如 Ollama is running)
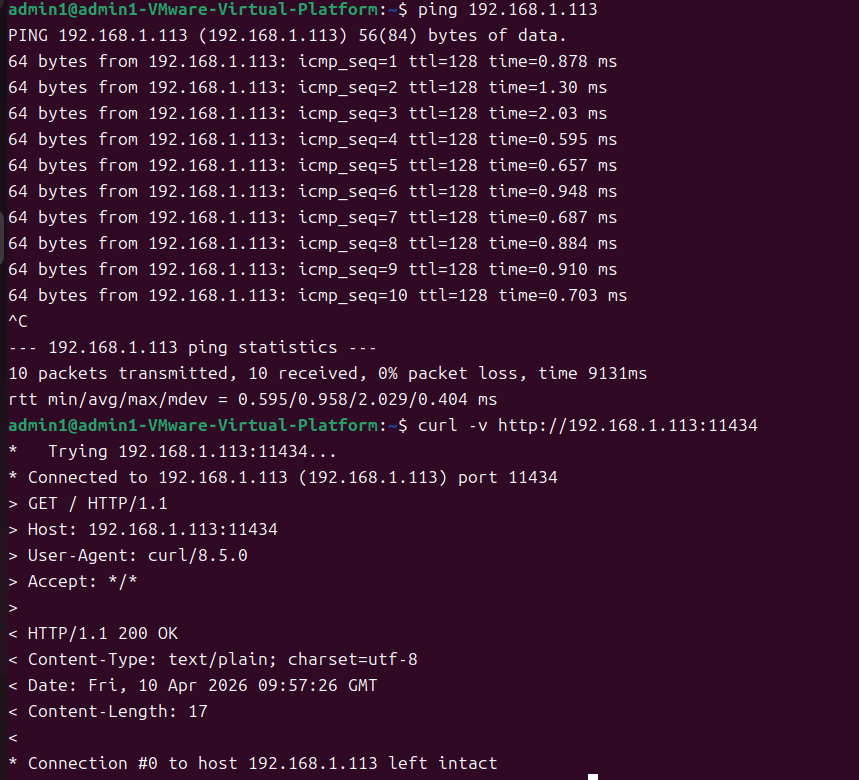
现在网络和端口都通了。
然后测试命令(虚拟机里运行)
curl http://192.168.1.113:11434/api/tags
能看到 qwen3.5:2b 就说明通了。
接下来,只需要在 OpenClaw 的配置文件(openclaw.json) 里,把 Ollama 的 baseUrl 改成 http://192.168.1.113:11434,然后重启 OpenClaw 服务。
3.修改虚拟机openclaw配置为ollama
方式一、openclaw config修改
openclaw config
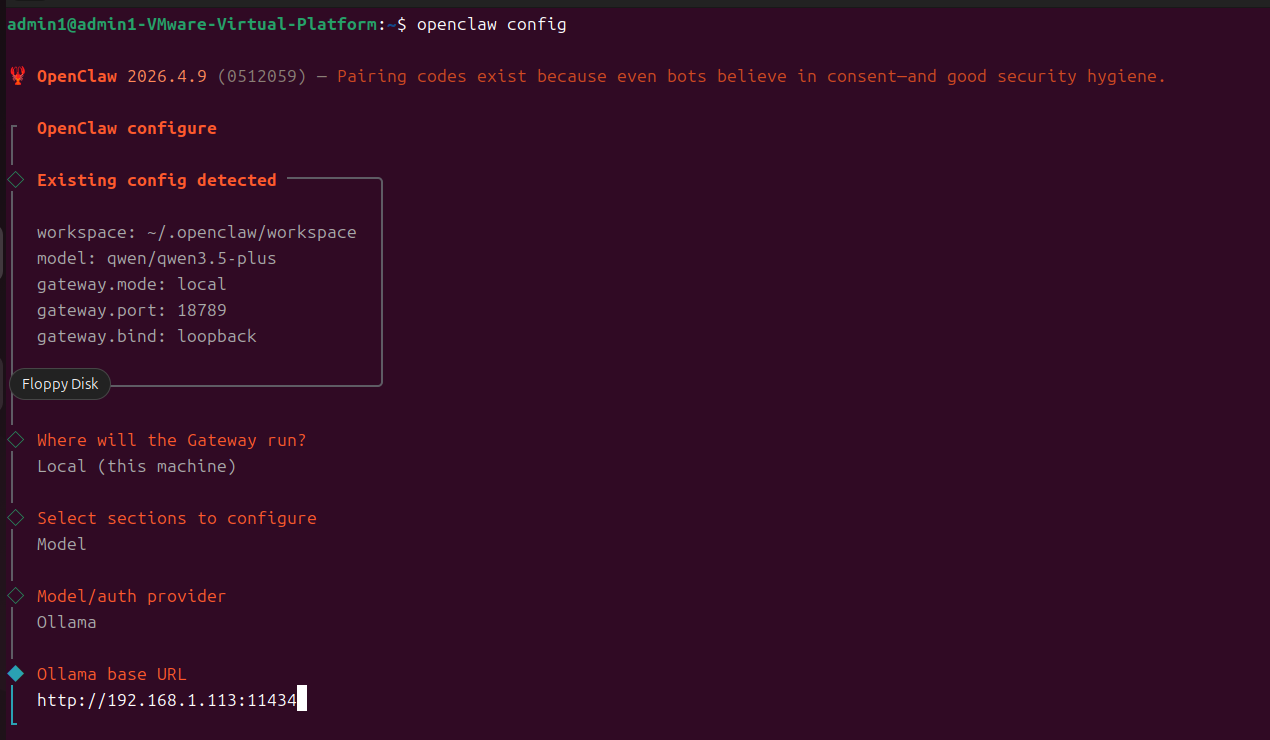
方式二、openclaw.json修改
修改一切后, 配置openclaw.json未同步(可能存在缓存问题?),需手动修改,先备份源文件,接着替换下文:
{
"agents": {
"defaults": {
"model": {
"primary": "ollama/qwen3.5:2b"
},
"compaction": {
"reserveTokensFloor": 0
},
"workspace": "/home/admin1/.openclaw/workspace"
}
},
"gateway": {
"mode": "local",
"auth": {
"mode": "token",
"token": "b22d...773bfeaad371"
},
"bind": "lan",
controlUi: {
allowedOrigins: [
'http://localhost:18789',
'http://127.0.0.1:18789',
'http://192.168.1.130:18789',
'http://192.168.1.1:18789',
],
},
"port": 18789,
"tailscale": {
"mode": "off",
"resetOnExit": false
},
"controlUi": {
"allowInsecureAuth": true
}
},
"models": {
"providers": {
"ollama": {
"baseUrl": "http://192.168.1.113:11434",
"api": "ollama",
"models": [
{
"id": "gemma4",
"name": "gemma4",
"reasoning": false,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 128000,
"maxTokens": 8192
},
{
"id": "qwen3.5:2b",
"name": "qwen3.5:2b",
"reasoning": false,
"input": [
"text",
"image"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 262144,
"maxTokens": 8192
}
],
"apiKey": ""
}
},
"mode": "merge"
},
"plugins": {
"entries": {
"ollama": {
"enabled": true
}
}
},
"meta": {
"lastTouchedVersion": "2026.4.9",
"lastTouchedAt": "2026-04-11T13:16:13.133Z"
},
"session": {
"dmScope": "per-channel-peer"
},
"tools": {
"profile": "coding"
},
"auth": {
"profiles": {
"ollama:default": {
"provider": "ollama",
"mode": "api_key"
}
}
},
"wizard": {
"lastRunAt": "2026-04-11T13:16:12.836Z",
"lastRunVersion": "2026.4.9",
"lastRunCommand": "onboard",
"lastRunMode": "local"
}
}
OpenClaw 的 Ollama 插件需要一些基础依赖包才能正常工作,为保险检测校验:
# 检查配置是否校验通过(关键步骤)
openclaw doctor
# 检查并修复工具问题
openclaw doctor --fix
OpenClaw 只要你在 Raw JSON 里点 Save 保存,重启
openclaw gateway restart

至此模型配置无问题。
方式三、重新 openclaw onboard
# 重新配置openclaw
openclaw onboard

最后展示效果
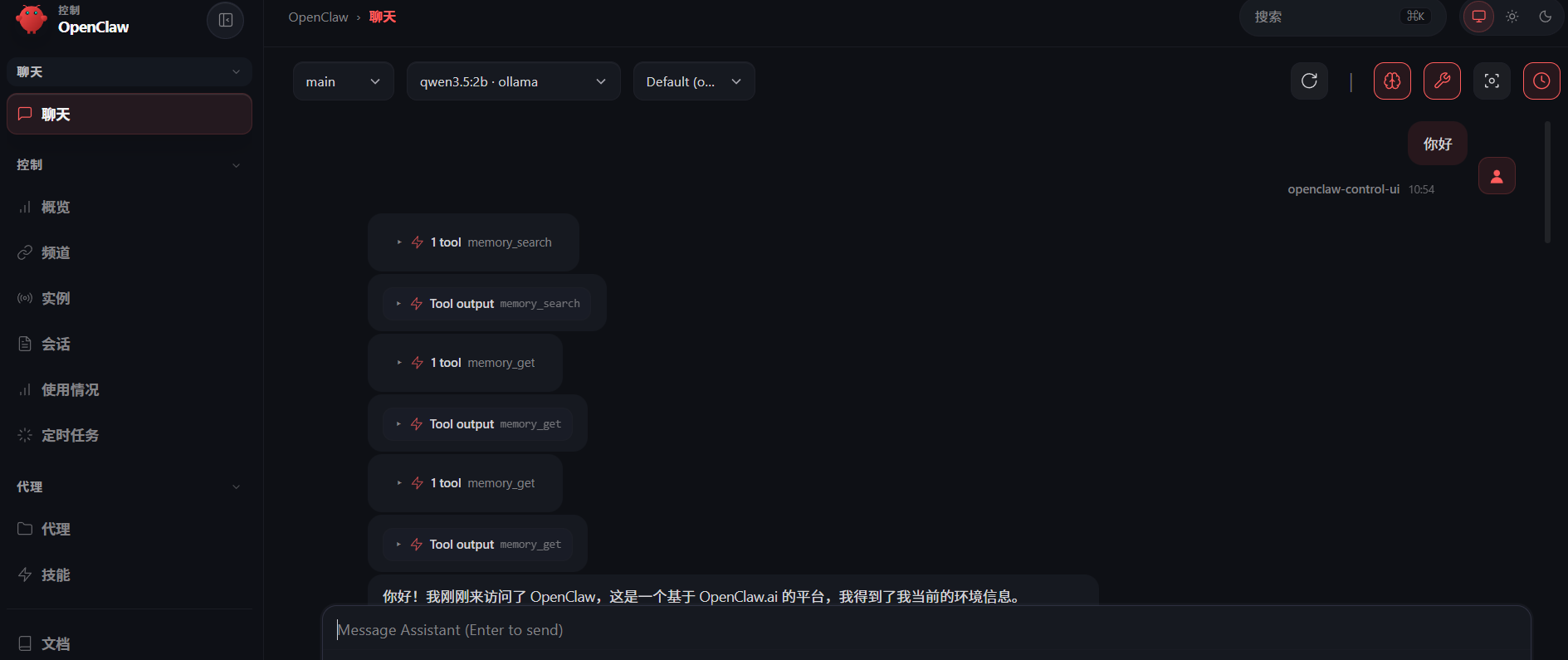
到此整体完成。
4.其他补充
OpenClaw pairing required 权限问题修复
提问后,openclaw长期不回答,查看日志,一直报错,可能存在问题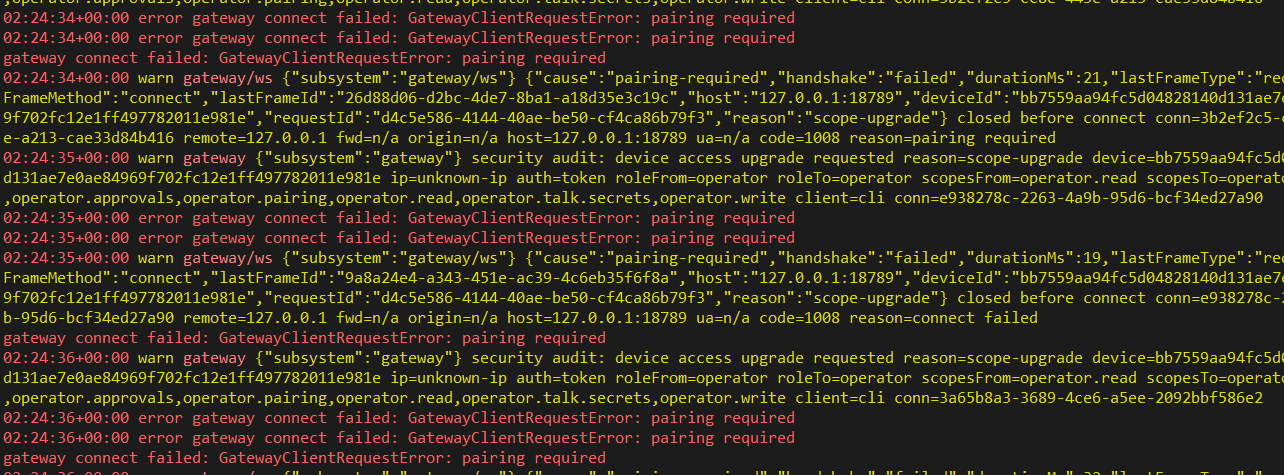
# 查看所有已配对 / 待配对设备(pending 是等待审批的设备,paired是已具备的设备)
openclaw devices list
# 批准权限
openclaw devices approve bb72...011e981e
最低上下文:16000
提问后,openclaw长期不回答,查看日志,一直报错,可能存在问题
openclaw要求 最低 最低上下文:16000,这会导致主机电脑内存占用15G+,使得崩溃,通过查询日志可看到。
model requires more system memory (15.5 GiB) than is available (14.9 GiB)
此刻需要通过GPU加速。
# 1. 全量加载模型到 GPU(GTX1650)
setx OLLAMA_GPU_LAYERS 99 /M
# 2. 强制使用 CUDA
setx OLLAMA_CUDA 1 /M
# 3. 限制上下文=16384(满足OpenClaw最低要求)
setx OLLAMA_NUM_CTX 16384 /M
常用指令跳转
OpenClaw 命令速查手册

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 19
19 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)