ACL2026 | Chunks as Arms:基于多臂老虎机的长上下文LLM偏好优化方法
这篇文章讲了什么?
一句话:
👉 如何让大模型在超长文本里“找重点”,并用更好的数据做DPO训练?
作者提出:
用“多臂老虎机(Multi-Armed Bandit)”来挑选最有用的上下文片段(chunk),再用这些片段生成更高质量的偏好数据。
❗现存的核心问题
当前LLM在长文本里有个经典问题:
👉 Lost-in-the-Middle(中间信息丢失)
模型:
- 重视开头 ✅
- 重视结尾 ✅
- 忽略中间 ❌
同时:
- SFT → 容易过拟合
- DPO → 数据质量强依赖采样
👉 所以问题变成:
如何采样“更有信息量”的上下文,生成更好的DPO训练数据?
🚀方法:LongMab-PO
作者提出:
LongMab-PO = MAB + Chunk Sampling + DPO
🧩核心思路拆解
Step 1:切分上下文
把长文本拆成多个 chunk:
C → {C1, C2, ..., Cn}
Step 2:把chunk当“老虎机臂”
👉 每个chunk = 一个“arm”
目标:
找出“最有用”的chunk组合
Step 3:用UCB策略选chunk
核心公式(不用细看):
👉 平衡:
- 探索(没试过的chunk)
- 利用(效果好的chunk)
Step 4:生成答案 + 打分
每轮:
- 用选中的chunk → 生成回答
- 用指标打分:
SubEM + F1
Step 5:更新chunk价值
👉 哪些chunk贡献了好答案 → 权重↑
👉 没用的 → 权重↓
Step 6:构造DPO数据
最终得到:
(y+, y-) 偏好对
用于训练模型
🔥一句话总结
👉 先动态选上下文 → 再生成更优回答 → 再做DPO优化
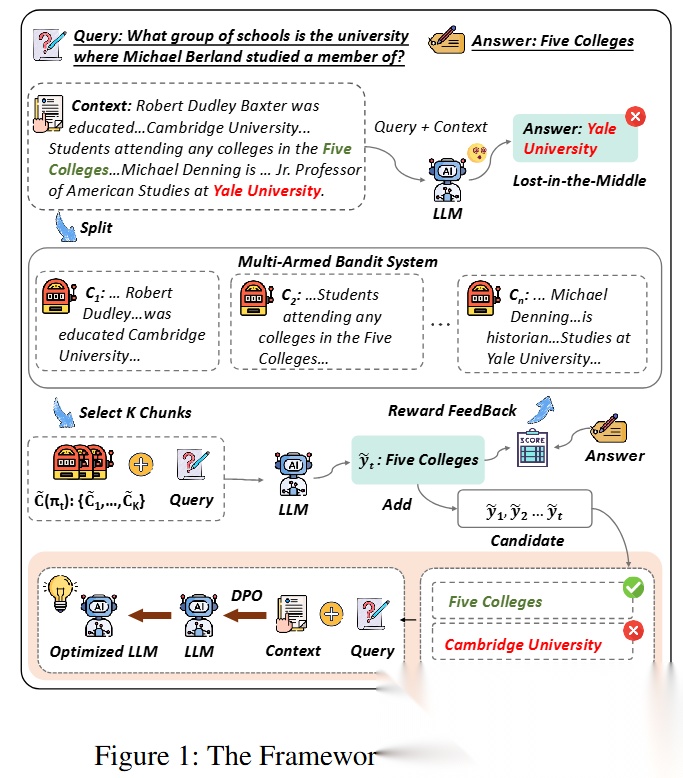
图1展示整体流程:
👉 长文本 → 切chunk → MAB选chunk → 生成答案 → 做DPO
关键点:
- chunk不是一次选死
- 而是多轮试探 + 更新
👉 类似“边试边学”(干中学)
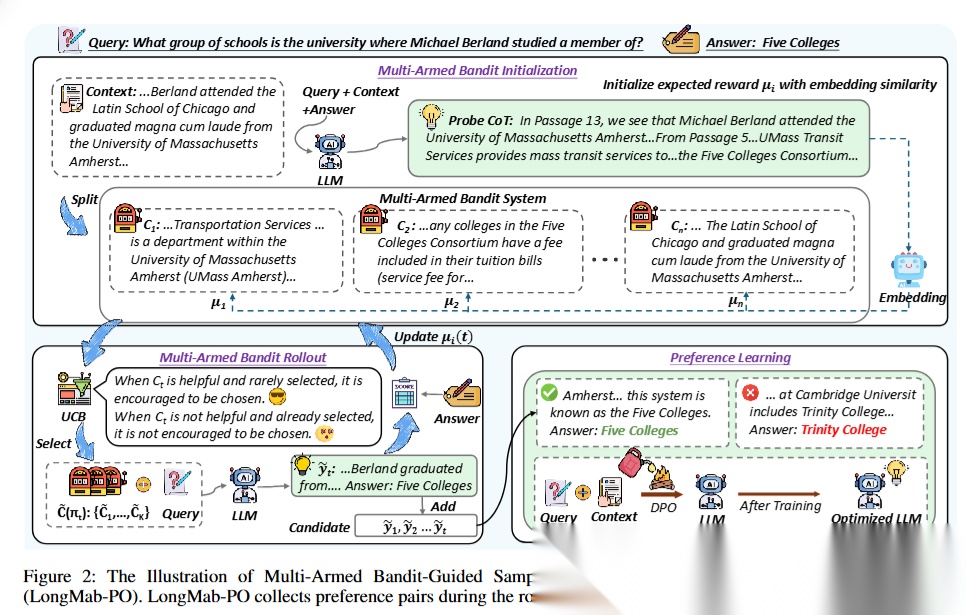
图2是核心创新:
👉 不再一次性喂整个长文本,而是让模型像“刷题一样”反复试不同片段;
👉 每次试都会知道哪些内容有用;
👉 同时自动生成“好答案 vs 坏答案”,直接用来做DPO训练。
本质上,它把:
❌ 静态长文本理解
👉 变成了
✅ 动态探索 + 反馈学习
以下是详细过程:
🟦 ① 初始化:先给每个文本片段打个“价值分”
👉 上半部分
输入:
- Query(问题)
- Context(超长文档)
做的事:
1️⃣ 把长文本切成很多 chunk(C₁, C₂, … Cₙ)
2️⃣ 用 embedding 相似度初始化每个 chunk 的分数 μᵢ
👉 可以理解为:
“先猜一下哪些段落可能有用”
⚠️问题:
👉 embedding 很粗糙,经常不准
(相关 ≠ 有用)
🟨 ② 核心:MAB rollout(整篇最关键!)
👉 左下角这一块
🧠在干嘛?
循环做这几步:
Step 1️⃣:选 chunk(UCB策略)
- 有用的 👉 多选
- 没用的 👉 少选
- 但也会“探索新chunk”
👉 核心思想:
探索 + 利用(explore vs exploit)
Step 2️⃣:喂给 LLM 生成答案
Query + 选中的 chunk → LLM → 生成答案 ŷ
Step 3️⃣:判断这个 chunk 好不好
根据:
- 答案对不对
- chunk 是否贡献了信息
👉 更新 μᵢ(奖励)
Step 4️⃣:继续循环
👉 越选越准:
有用 chunk 分数 ↑
垃圾 chunk 分数 ↓
🔥关键理解(非常重要)
图里这句话其实就是精髓:
✔ 有用但没被选过 → 鼓励
❌ 没用但老被选 → 惩罚
🟩 ③ 顺便干一件大事:构造DPO数据
👉 右边绿色框
每次 rollout 会产生:
- 好答案 ✅
- 坏答案 ❌
比如:
- ✅ Five Colleges(对)
- ❌ Trinity College(错)
然后做:
👉 构造 preference pair:
(好答案, 坏答案)
用来训练:
👉 DPO(偏好优化)
🔥关键点:
数据不是人工标的,是“rollout自动产生的”
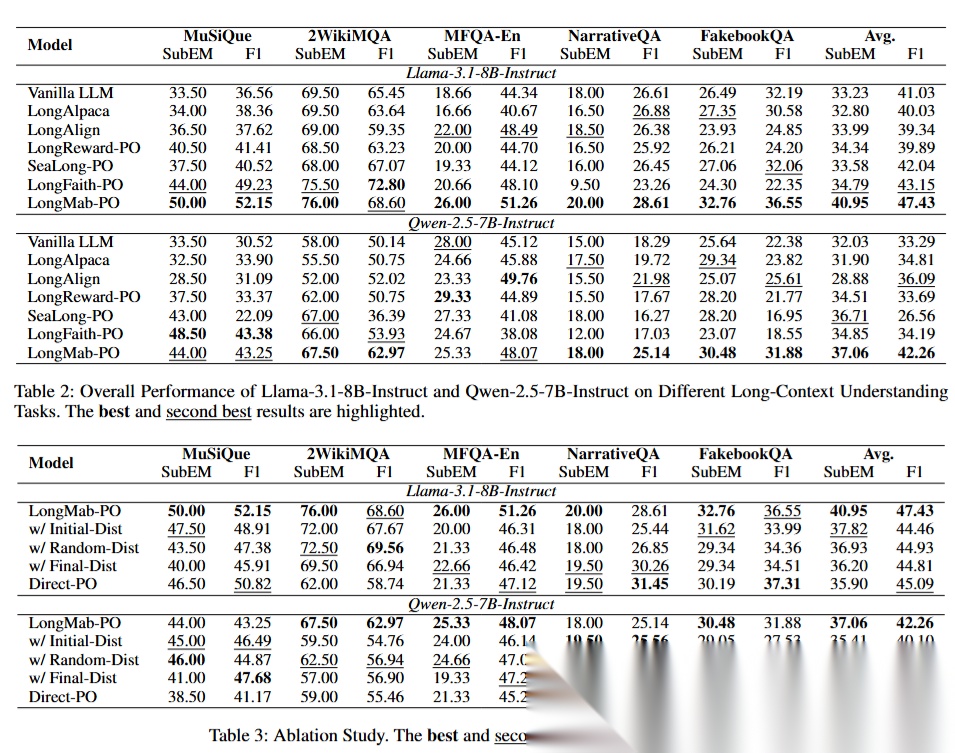
🧠重点1:直接看 Avg(最关键)
🔹LLaMA-3.1-8B
- Vanilla:33.23 / 41.03
- LongMab-PO:40.95 / 47.43(最高)
👉 提升非常明显:
- SubEM +7.7
- F1 +6.4
🔹Qwen-2.5-7B
- Vanilla:32.03 / 33.29
- LongMab-PO:37.06 / 42.26(最高)
👉 同样是大幅提升
🧠重点2:对比不同方法
❌ SFT方法(LongAlpaca / LongAlign)
👉 结论:
- 有时候还不如原始模型
- 比如:
- LongAlign Avg F1 = 39.34 < Vanilla 41.03
👉 说明:
单纯喂数据(SFT)并不能解决长上下文问题
⚖️ DPO方法(LongReward / SeaLong / LongFaith)
👉 有提升,但:
- 不稳定
- 不全面
例如:
- LongFaith 在 MuSiQue 很强
- 但在 NarrativeQA 直接崩(9.50)
👉 问题:
数据质量不稳定
✅ LongMab-PO
👉 特点:
- 所有任务都强
- 没明显短板
- 平均最好
👉 说明:
关键不是DPO本身,而是“你怎么生成DPO数据”
🧠重点3:跨任务稳定性
看5个数据集:
- MuSiQue(多跳推理)
- 2Wiki(跨文档)
- MFQA(开放问答)
- NarrativeQA(长故事)
- FakebookQA(超长)
👉 LongMab-PO:
- 每个任务都在前列
- 没“翻车任务”
👉 这点很关键:
泛化能力强
💡这篇文章的亮点
⭐亮点1:把“上下文选择”变成学习问题
以前:
👉 靠相似度(静态)
现在:
👉 用bandit动态学习
⭐亮点2:直接优化“数据质量”
不是:
👉 改模型结构
而是:
👉 让训练数据更聪明
⭐亮点3:解决长上下文核心痛点
👉 Lost-in-the-middle
通过:
逐步找到“真正有用的chunk”
🧾一句话总结
👉 LongMab-PO 用多臂老虎机动态选择上下文,提升DPO数据质量,从而显著增强LLM的长文本推理能力。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献110条内容
已为社区贡献110条内容

所有评论(0)