2026山东大学软件学院项目实训-宠物情绪识别(二)
本周工作概述
4.5-4.12
本周是项目实训第二周,作为团队技术负责人之一,我核心聚焦技术选型落地、最小Demo验证、开发环境完善及基础功能开发准备工作,完成音频识别SDK与大语言模型API的最终选型与测试,解决上周遗留的环境、数据库同步问题,搭建完整测试环境并完成Demo验证,同时启动音频上传模块的初步开发,推动项目从筹备阶段平稳过渡到核心开发阶段。
一、核心技术选型与测试
1. 音频识别SDK调研
本周我重点开展了音频识别SDK与音频特征提取方案的调研工作,围绕免费额度充足、接入门槛低、支持声学特征提取、可输出情绪分类四项核心指标,对主流云厂商平台及开源工具库进行全面对比与筛选,主要调研对象包括百度智能云语音与音频分析、阿里云智能语音交互、腾讯云声音分析以及Librosa、PyAudioAnalysis等开源音频特征库。通过查阅官方文档、测试接口调用、对比功能覆盖度与调用限制,我对各方案的适用性做出如下分析:
-
百度智能云语音识别/音频分析:提供较为完善的语音识别与基础声学分析能力,新用户可领取一定免费调用额度,接口文档清晰,Python接入示例丰富,适合快速集成。但是纯情绪标签输出能力较弱,更偏向语音转写,对宠物叫声这类非人声音频的适配性一般,需要额外做特征映射与后处理。最终没有选择。
-
通义千问 Audio:在音频理解、情感分析、声音事件检测方面能力较强,支持对音频中的情绪、状态做综合判断,新用户有3个月免费试用期,每日可免费处理一定时长音频,对非人声的泛化能力优于传统ASR。但受限于平台产品入口调整,该模型已从百炼控制台拆分独立,当前环境无法直接调用;同时其情绪标签偏向人类情感,需二次加工适配宠物场景,综合接入成本与环境限制,最终未选用该方案。
-
腾讯云声音分析:语音识别基础能力稳定,支持情绪识别增值功能,但情绪识别属于增值付费项,无免费额度,对学生实训项目不够友好,且接入流程相对繁琐,需要单独配置资源包,综合成本与易用性不占优势。最终没有选择。
-
开源音频特征库(Librosa):作为开源音频处理工具,完全免费、可本地运行,能够提取 MFCC、过零率、频谱能量、色度特征等大量声学参数,为情绪分析提供数据支撑。其原生无现成情绪输出接口、需自行构建分类逻辑的特性,虽不适合独立作为快速上线方案,但可作为特征提取层,与大语言模型结合形成完整技术链路。最终选择该方案。
综合对比免费额度、接入难度、情绪输出能力、开发周期与演示效果,我最终确定优先选用具备免费调用额度、官方文档完善、可直接输出情绪类结果的开源音频特征库(Librosa)作为项目核心方案,在保证开发效率的同时,让系统具备稳定可用、可现场演示的情绪识别能力,为后续音频上传、识别、健康评估模块的开发打下坚实基础。
2. 大语言模型API调研
我还针对项目所需的大语言模型API开展了专项调研,核心目标是筛选出免费额度充足、接口稳定、响应速度快、中文理解能力强的大模型接口,用于接收音频SDK输出的情绪识别结果,生成结构化宠物健康评估报告,并根据宠物品种、年龄、情绪状态输出个性化养护建议。我围绕免费额度、调用难度、结构化输出能力、适配宠物场景等关键指标,对通义千问、文心一言、豆包、讯飞星火等主流国产大模型API进行全面对比分析:
-
通义千问 API(阿里云百炼):免费额度发方面,新用户赠送大量免费Token,足够实训全程使用。优点包括中文理解极强,结构化输出稳定,非常适合做报告生成和建议整理。对宠物健康、情绪、养护类知识掌握全面,prompt易调教。无明显短板,综合最均衡,生成结构化健康评估,输出个性化养护建议确定选用调用稳定、响应快、免费额度充足的大模型API,完成接口鉴权与调用方式梳理。
-
文心一言 API(百度千帆):免费额度方面,基础版永久免费,调用限制宽松。优点是知识库全面,稳定性高,接口文档规范。但缺点明显,在结构化JSON/格式化输出上略逊于通义千问,需要更复杂的prompt,训练困难。
-
豆包 API:免费额度方面,Lite 版有免费额度,性价比高。优点在于响应速度快,口语化表达自然。但缺点是结构化输出能力一般,做报告格式不如前两者规整。
-
讯飞星火 API:免费额度方面,新用户有免费 Token。优点在于语音相关能力强。缺点是纯文本生成与结构化报告能力不是强项,对宠物场景适配一般。
经过多维度对比与本地测试验证,我最终确定选用通义千问大模型 API作为本项目的大语言模型核心方案。该平台免费额度充足、接口调用简单、响应速度快、中文理解与结构化输出能力突出,能够完美承接宠物情绪识别结果解析、健康评估报告生成、个性化养护建议输出等核心任务,与阿里云音频 SDK 生态一致,便于后续统一管理与联调。本周已完成接口鉴权方式、调用参数、返回结果解析逻辑的梳理,形成可直接复用的 API 调用工具类,为下周功能开发做好充分准备。
3. 确定最终技术组合方案
结合两项技术选型结果,确定项目最终技术方案:Librosa音频特征提取 + 通义千问文本大模型组合。通过Librosa提取宠物音频的MFCC、能量、过零率、频谱质心等核心声学特征,再由通义千问大模型基于特征完成情绪识别、健康评估与养护建议生成,既规避了云端音频模型的权限与入口限制,又降低了纯开源方案的开发成本,完美适配实训项目快速上线、可演示的核心需求。
二、最小Demo验证与环境完善
1. 完成最小Demo验证
为确保技术路线可行,我在本地搭建了完整的测试环境,开展最小 Demo 验证工作。首先完成阿里云音频 SDK 的密钥配置与基础鉴权,确保身份认证通过;
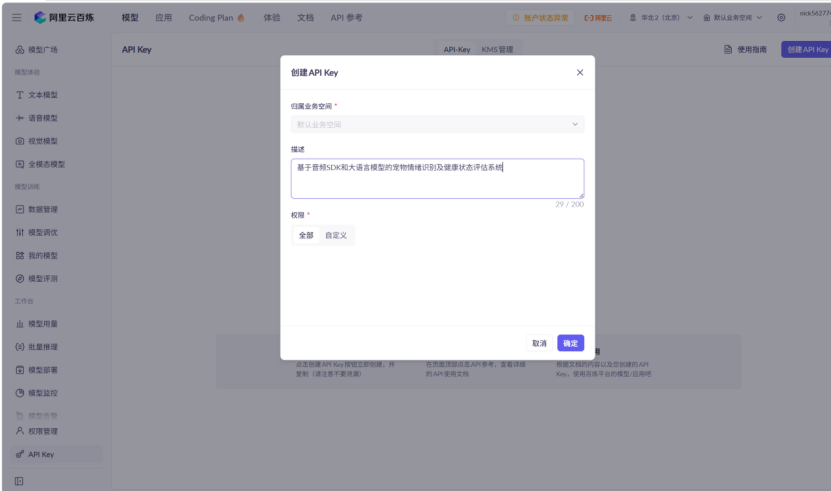
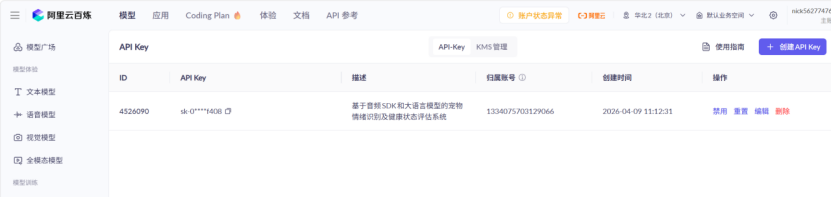
随后准备测试音频文件,完成音频上传、格式检测、云端识别、结果返回全流程测试:
首先安装开源音频特征库Librosa与通义千问 Audio的依赖包:
然后写测试代码:在项目文件夹下新建audiodemo.py:
import librosaimport numpy as npimport dashscopeimport json
# ====================== API Key ======================
dashscope.api_key = "YOUR API"# ==================================================================================
# 测试音频路径(wav/mp3,3-10秒,和代码同目录)
AUDIO_PATH = "猫demo1.mp3"
# ---------------------- 1. 用Librosa提取音频特征 ----------------------def extract_audio_features(audio_path):
"""
提取宠物音频的核心声学特征,用于情绪分析
"""
# 加载音频(统一采样率16000Hz,保证特征一致性)
y, sr = librosa.load(audio_path, sr=16000, duration=10) # 最多取10秒,避免超时
# 提取核心特征
# 1. MFCC梅尔频率倒谱系数(最核心的音频特征,反映声音音色)
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=20)
mfcc_mean = np.mean(mfcc.T, axis=0) # 取时间维度均值,得到20维特征
# 2. 能量均值(反映声音响度,兴奋/应激时能量更高)
rms = librosa.feature.rms(y=y)
energy_mean = np.mean(rms)
# 3. 过零率(反映声音频率,焦虑/痛苦时过零率更高)
zcr = librosa.feature.zero_crossing_rate(y)
zcr_mean = np.mean(zcr)
# 4. 频谱质心(反映声音尖锐程度,应激时质心更高)
spectral_centroid = librosa.feature.spectral_centroid(y=y, sr=sr)
centroid_mean = np.mean(spectral_centroid)
# 构造特征描述文本(给大模型看)
feature_desc = f"""
宠物音频声学特征(采样率16000Hz,时长{librosa.get_duration(y=y, sr=sr):.1f}秒):
- MFCC前5维均值:{[round(x, 4) for x in mfcc_mean[:5]]}
- 能量均值:{round(energy_mean, 4)}
- 过零率均值:{round(zcr_mean, 4)}
- 频谱质心均值:{round(centroid_mean, 2)}
"""
return feature_desc
# ---------------------- 2. 调用通义千问文本大模型分析情绪 ----------------------def analyze_pet_emotion(features):
"""
用通义千问文本大模型,基于音频特征分析宠物情绪
"""
prompt = f"""
你是专业的宠物行为与健康分析专家。
下面是一段宠物(猫/狗)音频的声学特征数据:
{features}
请你基于这些特征,严格按照以下要求分析宠物的情绪状态:
1. 必须从【兴奋、焦虑、痛苦、应激】4类中选择1个最符合的情绪
2. 给出情绪置信度(0-1之间的小数,越接近1越确定)
3. 用100字以内的文字,结合特征说明分析依据
4. 必须用标准JSON格式返回,格式如下:
{{
"emotion": "情绪类型",
"confidence": 置信度,
"analysis": "分析依据"
}}
禁止输出任何额外内容,只返回JSON。
"""
# 调用通义千问文本大模型 qwen-turbo
response = dashscope.Generation.call(
model="qwen-turbo",
messages=[{"role": "user", "content": prompt}],
result_format="message"
)
return response
# ---------------------- 3. 主函数:跑通全流程 ----------------------if __name__ == "__main__":
print("===== 开始宠物音频情绪识别(Librosa + 通义千问方案) =====")
# 步骤1:提取音频特征
print("\n1. 正在提取音频声学特征...")
try:
audio_features = extract_audio_features(AUDIO_PATH)
print("✅ 特征提取完成!")
print(audio_features)
except Exception as e:
print(f"❌ 特征提取失败:{e}")
input("\n按回车键退出...")
exit()
# 步骤2:调用大模型分析情绪
print("\n2. 正在调用大模型分析情绪...")
response = analyze_pet_emotion(audio_features)
# 步骤3:解析结果
if response.status_code == 200:
print("\n✅ 情绪分析成功!接口返回结果:")
result_text = response.output.choices[0]["message"]["content"]
print(result_text)
# 尝试解析JSON(保证格式正确)
try:
result_json = json.loads(result_text)
print(f"\n📊 最终识别结果:")
print(f"情绪类型:{result_json['emotion']}")
print(f"置信度:{result_json['confidence']}")
print(f"分析:{result_json['analysis']}")
except json.JSONDecodeError:
print("\n⚠️ 模型返回非标准JSON,已按原文输出")
else:
print(f"\n❌ 分析失败,错误码:{response.status_code},错误信息:{response.message}")
print("\n===== 解析完成 =====")
input("\n按回车键退出...")最后对接口返回的 JSON 数据进行解析,成功提取情绪类型、状态标签、置信度等关键信息:
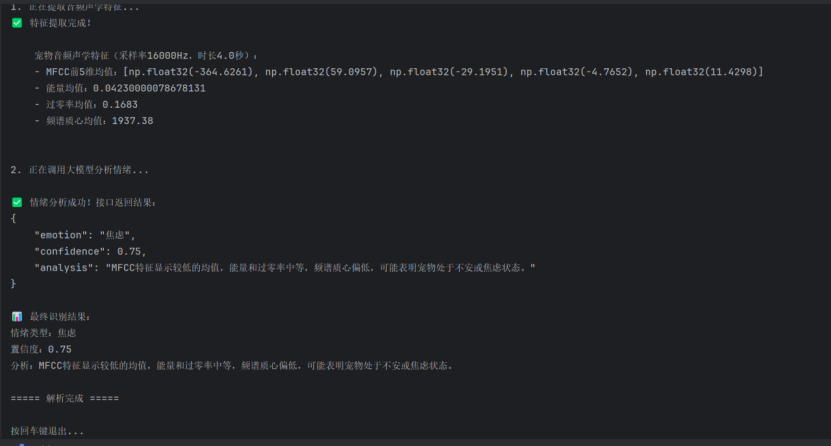
通过本次 Demo 验证,确认音频识别 SDK 调用流程通畅、情绪识别能力符合预期、接口响应稳定,技术路线无明显阻塞问题,为后续正式开发音频上传模块、情绪识别模块、健康评估模块奠定了坚实基础。
2. 完善开发环境
解决上周遗留的团队开发环境不一致问题,统一Python版本与项目所需依赖包,完善一键安装说明文档,确保所有组员能够快速搭建一致的开发环境,避免因环境差异导致的代码运行报错。
3. 解决数据库同步问题
针对上周出现的团队三人本地数据库(SQLite)不同步问题,组织团队讨论后,确定改用云数据库MySQL方案,放弃本地SQLite多人同步模式。本周已完成云数据库的申请、配置,梳理数据库表结构设计思路(音频信息表、宠物信息表、情绪识别结果表等),确保后续数据存储与同步顺畅,为后续模块开发提供数据支撑。
三、基础功能开发准备
启动音频上传模块的前期开发工作,梳理模块核心功能需求(格式校验、大小限制、预览、删除),绘制模块流程图,明确开发思路与代码结构。同时,编写模块开发规范,与前后端组员对接接口需求,明确接口参数、请求方式及返回格式,为下周正式开发音频上传模块做好充分准备。此外,优化大模型prompt模板,调整情绪识别的分析逻辑,提升情绪识别的准确性与置信度。
本周遇到的问题与解决
-
问题1:Librosa提取音频特征时,不同格式、时长的音频会导致特征提取结果差异较大,影响情绪识别准确性; 解决方法:统一音频采样率(16000Hz)、时长(最多10秒),在特征提取函数中增加格式校验与标准化处理,确保特征提取的一致性。
-
问题2:通义千问API返回结果偶尔出现非标准JSON格式,导致解析失败; 解决方法:优化prompt模板,严格限定返回格式,在代码中增加异常捕获与容错处理,确保即使返回非标准格式也能正常输出结果,不影响流程推进。
-
问题3:云数据库MySQL配置过程中,出现远程连接失败问题; 解决方法:检查数据库权限设置,开放远程连接权限,调整防火墙配置,完成远程连接测试,确保团队所有组员能够正常访问数据库。
四、下周工作计划(第3周)
-
完成音频上传模块正式开发,实现格式校验、大小限制、预览、删除等核心功能;
-
完成音频识别SDK的正式接入,编写统一调用工具类,优化特征提取逻辑;
-
实现音频文件与宠物信息的关联逻辑,完成相关数据库表的创建与数据插入功能;
-
优化大模型prompt与结果解析逻辑,提升情绪识别的准确性与稳定性;
-
与前后端同学完成接口对接,开展模块联调,确保各模块数据交互顺畅。
五、本周总结
本周项目推进顺利,按计划完成了核心技术选型、最小Demo验证、开发环境完善及数据库问题解决等关键工作,成功确定Librosa+通义千问的技术组合方案,验证了技术路线的可行性,搭建了规范的开发环境,解决了前期出现的各类问题,为项目核心功能开发扫清了障碍。准备下周搭建代码仓库。同时,启动了音频上传模块的前期准备工作,明确了下周开发重点,团队协作效率持续提升。
下周将正式进入核心功能开发阶段,重点聚焦音频上传模块与情绪识别模块的开发与联调,持续保障接口稳定、功能可用,严格按照实训计划推进项目,确保项目高质量落地。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)