2026 AI圈爆火的Harness Engineering:从“会说话“到“会干活“的终极革命
2026 AI圈爆火的Harness Engineering:从"会说话"到"会干活"的终极革命
同样用Claude或GPT,有人让AI写了几行代码就卡住了,有人却让AI连续工作6个小时,交付了一个完整的游戏。一个极端的案例来自OpenAI:3名工程师,五个月,一行代码都没手写,指挥Codex Agent写了100万行代码,做出了一个真实的产品。
差距在哪?2026年初,OpenAI和Anthropic几乎同时给出了答案:Harness Engineering。这个词最近在AI圈刷屏,从硅谷大厂到普通开发者,所有人都在讨论它。它不是又一个被炒作的概念,而是正在重塑AI工程实践的核心方法论。
一、什么是Harness Engineering?
Harness这个词,本来的意思是缰绳、马鞍那一整套控制马的装备。马是模型,跑得快,但自己不知道该往哪跑。咱们就是骑马的人,提供方向。Engineering就是工程的意思。
说白了,Harness Engineering就是给模型说清楚怎么把活干好。任务怎么拆、工具怎么用、做完了怎么验证、失败了怎么恢复、什么时候该把控制权交回给人,这些都是它要管的事。
AI工程的三次范式跃迁
过去三年,围绕LLM的工程方法论经历了三次明显的范式演进,三者是嵌套关系,而非替代关系:
| 层级 | 核心问题 | 工程对象 | 影响范围 |
|---|---|---|---|
| Prompt Engineering | 问什么? | 指令文本 | 单次调用 |
| Context Engineering | 展示什么? | Token窗口内容 | 单个Session |
| Harness Engineering | 环境如何设计? | Agent外部的约束、反馈、工具、运行时 | 整个系统生命周期 |
核心公式:Agent = Model + Harness
Harness是围绕模型构建的一切基础设施——除了模型本身(权重、推理),其他所有东西都属于Harness的范畴。
用两个大家熟悉的系统来理解Model和Harness的关系:
- 引擎Engine = Model(提供动力/推理);燃料+仪表盘 = Context(当前状态信息);转向/刹车/车道/警示灯 = Harness(工具调用/护栏/约束/可观测性)
- CPU处理器 = Model(执行指令/推理);寄存器状态 = Context(当前执行上下文);内存/文件/系统调用/权限 = Harness(上下文管理/持久化/接口/护栏)
二、为什么现在突然火了?
1. 模型能力趋同,Harness决定下限
GPT、Claude、Gemini在核心能力上差距在缩小。模型决定了天花板,但Harness决定了地板。当模型本身不再是差异化因素,围绕模型的系统设计就成了新的竞争壁垒。
2. 长任务的错误累积问题
还有一个很直观的数学问题。假设每一步成功率95%,连续20步之后端到端完成率只剩36%。这就是为什么Agent95%的时间都正常,但真实任务上还有三分之一失败率。
3. 传统方法的天花板
- Prompt Engineering:只能解决"怎么把任务说清楚",面对复杂任务,你很难在一段话里把所有细节和约束都说明白
- Context Engineering:只能解决"怎么把信息给对",面对跨会话的长任务,仍然解决不了失忆和焦虑的问题
这两种方式本质上都是在"更好的跟模型说话",而Harness Engineering的思路完全不同——不是更好地跟模型说话,而是给模型搭一个能持续工作的系统。
三、一个成熟的Harness长什么样?
综合OpenAI、Anthropic、Google DeepMind等头部公司的实践,一个成熟的Harness包含以下核心组件:

1. 工具与API层(Tools & APIs)
工具是Agent与世界交互的唯一手段。Harness的工具设计决定了Agent能做什么、以什么粒度操作。
工具设计原则:
- 最小权限:Agent只应拥有完成当前任务所需的最小工具集
- 可观测:每次工具调用都应被记录,可回溯
- 幂等优先:读操作优于写操作,写操作应有回滚机制
- 沙盒隔离:危险操作(删除、部署)应在隔离环境中执行
Vercel的经验很反直觉:他们最初给Agent配了全套工具库,结果效果很差,Agent做冗余调用、执行不必要的步骤。后来移除了80%的工具,反而更好。约束Agent的解决空间,反而能提升表现。
2. 记忆与状态管理(Memory & State)
LLM本身无状态,Harness负责构建和维护Agent的"记忆系统":
- In-Context Memory:对话历史、工具调用结果,生命周期为单次Session
- External Memory:工作状态摘要、进度文件、Git历史,生命周期为永久,是长任务的关键基础设施
3. 验证机制(Verification)
验证是Harness中最关键的反馈来源,分为两类:
| 类型 | 执行方式 | 速度 | 确定性 | 示例 |
|---|---|---|---|---|
| Computational | CPU,确定性 | 快(毫秒级) | 100% | 单元测试、Linter、类型检查、格式校验 |
| Inferential | GPU,LLM推理 | 慢(秒级) | 非确定 | AI Code Review、语义正确性、架构合规 |
核心原则:Keep Quality Left。发现越早,修复成本越低。Harness的目标是把检测点尽量推到左侧。
4. 护栏与权限(Guardrails)
护栏定义了Agent不能做的边界,是Harness的安全层:
- 等待人工确认:git push、生产环境部署等破坏性操作
- 已拦截:违反约束、越权行为,拦截后必须提供明确的拒绝原因和替代方案
- 已批准执行:无副作用读操作、有限范围写操作,沙盒执行
5. 可观测性(Observability)
“A one-off mistake is usually a context problem. Weeks of gradual degradation is a harness problem.”
没有可观测性,就无法区分这两种情况:
- Logs:结构化日志,记录tool_call入参/出参、prompt+completion、Token消耗
- Metrics:可量化指标,包括任务成功率、Retry次数分布、平均Token/任务
- Traces:调用链追踪,跨Tool调用链、多Agent协作链路、Context注入时序
前馈与反馈:控制系统视角
Martin Fowler借用控制系统的概念来描述Harness的两种工作方式,这是Harness Engineering最核心的思维模型:
- 前馈(Feedforward):行动前引导,在Agent行动之前注入信息,预防问题发生,提高首次正确率
- 反馈(Feedback):行动后感知,在Agent行动之后检测结果,提供自纠正信号
四、头部公司的实战案例
1. OpenAI:用Codex构建内部工具
OpenAI工程团队发布报告,描述了他们如何用Codex在约1/10的时间内完成原本需要手写的代码量。3名工程师,五个月,0行手写代码,指挥Codex生成了100万行代码,合并了约1500个PR。
Harness核心设计:
- Chrome DevTools集成:Agent可直接看到UI并复现bug,无需截图描述
- 隔离可观测栈:每个任务独立的logs/metrics/traces,便于Agent理解状态
- 可衡量的约束:"启动需在800ms内完成"变为可验证的指标
- 架构规则机械化:依赖方向检查自动化,违规在合并前被拦截
- 教学式Linter:错误信息本身就是下次尝试的Context,引导Agent自修复
2. Anthropic:三Agent架构与双层Harness
Anthropic从双Agent演进到三Agent架构:
- Planner:负责把需求拆成可测试的功能清单
- Generator:负责逐步实现
- Evaluator:负责像QA一样真实测试,不只看代码,而是真的去操作页面、检查交互
最关键的发现是生成和评估必须分离,让干活的人自己打分,结果一定偏乐观。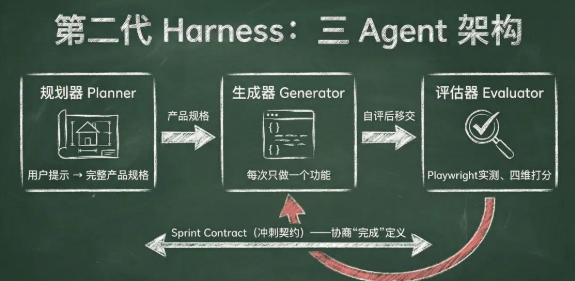
针对长任务,Anthropic提出了双层Harness架构:
- 第一层:Initializer Agent(仅首次运行):创建init.sh、feature-list.json、第一个git commit
- 第二层:Coding Agent(每次Session):读取Git日志+进度文件→选择下一个功能→实现→自测→更新进度文件
对比数据:
- 单Agent运行:20分钟,花费9美元,游戏根本玩不了
- 完整Harness运行:6小时,花费200美元,游戏可以真正玩起来,有精灵动画、AI集成、导出功能
3. Stripe:每周1000+ AI生成PR
Stripe的Agent系统被设计为处理窄范围、定义清晰的任务:单元测试编写、Linter警告修复、API版本迁移、废弃依赖移除、文档更新。
核心Harness设计:
- 任务规范层:构造结构化任务goal/scope/context JSON
- 沙盒执行层:启动隔离容器,无法触达生产环境
- 反馈循环层:运行测试套件,读取错误输出迭代修复代码
- 人工审核层:CI必须全绿方可合并,正常Code Review流程
4. LangChain:Harness改进驱动排行榜提升
LangChain通过专注改进Harness(而非更换模型),在Terminal Bench 2.0排行榜从30名外跃升至第5名。
改进内容:
- 更精确的工具调用格式定义
- 更丰富的错误处理反馈
- 改进的步骤追踪机制
- 更清晰的任务完成判断标准
这一案例清晰说明:在当前阶段,模型已不是瓶颈,Harness才是。
五、多Agent与Harness的关系
很多人误以为多Agent就是Harness,其实不然。真正的一人公司等于多Agent加Harness。没有Harness,你只是请了几个AI角色来帮忙。有了Harness,才是真正在搭一个能稳定运转的AI团队。
- 多Agent:决定团队如何分工,回答"谁来做什么"的问题
- Harness:决定这支AI团队如何稳定运转,提供目标与边界、上下文与记忆、流程与交接、质量闸门、工具与权限、可观测性与人工接管
六、普通人怎么上手?
理论讲完了,下面讲怎么做。不需要写代码,打开claude.ai就能开始。
1. 最简单的方法:多窗口角色扮演
核心思路就是Planner-Generator-Evaluator三角色。每次新开一个对话窗口分阶段扮演,避免相互干扰,尽量做到客观公正。
比如写一篇公众号文章:
- 新建对话1:“你现在是一个内容策划专家。我想写一篇关于AI的公众号文章,目标读者是设计师。请帮我分析选题角度,给出3个可选方向,每个方向列出核心论点和文章结构。”
- 新建对话2:“就按方向二来。你现在是一个内容撰稿人,根据上面的分析逐段撰写完整文章,语言通俗、逻辑清晰。”
- 新建对话3:“你现在是一个挑剔的编辑。审阅上面这篇文章:开头能不能抓住注意力?逻辑有没有跳跃?案例有没有说服力?有没有废话可以删?逐条给修改建议。”
同样一个Claude,分角色执行的效果比直接说"帮我写篇文章"好很多,因为评审者和生成者立场不同,不会自己夸自己。
2. 用Claude Projects建立你的工作手册
如果你用Claude,最推荐的方式是用Projects功能来记录规则和规范:
- 打开claude.ai,点开Projects
- 创建一个项目,填写标题和描述
- 在右边的"Instructions"选项里,把你攒的规则贴在这里
- 还可以添加你项目的各种规范文档、PRD之类的
以后每次在这个项目里新开对话,Claude都会自动读取这些规则,不用你每次手动贴。你可以理解为这就是你给这个AI团队写的工作手册。
3. 把踩过的坑变成规则沉淀下来
这可能是Harness对普通人最有价值的一件事。每次AI犯了一个让你不满意的错,就把它写成一条明确的规则存到文档里,下次对话贴进去。
你还可以把规则写成一个Skill文件。比如语音笔记整理的Skill,里面写好了所有格式要求和风格偏好,每次让Claude整理语音记录时它就自动按这套规则来。
时间一长,这份文档就是你私人定制的Harness,AI的输出质量会越来越稳定。不这么做的话,你每次跟AI的协作都是从零开始,同样的错反复犯,效率永远上不去。
4. 5步起步法(来自HumanLayer)
不要试图一次性搭建完美的Harness。选一个你每周都要重复做的任务,按照这五步来:
- 裸跑,观察失败:什么配置都不加,就用默认设置跑。看agent在你的项目里会犯什么错,记下来。
- 每个错误写一条规则:观察到的错误写进CLAUDE.md。一次一条,措辞清晰,不要写模糊的"注意代码质量",要写"修改文件前先用git diff确认只改了目标文件"。
- 加测试和lint:这是投入产出比最高的harness组件。好的测试套件让agent能自我验证。
- 用Hooks自动化重复检查:如果你发现自己反复在agent提交后手动检查同一件事,那就把它写成hook。
- 定期精简:你的CLAUDE.md会随着时间越来越长,但模型也在进步。三个月前需要明确告诉它的事,现在它可能已经默认会做了。
七、工程师的角色转变
Harness Engineering带来的不仅是技术方法论的变化,更是研发工程师职能定位的根本性转变。
| 职能维度 | 传统工程师 | Harness工程师 |
|---|---|---|
| 主要产出 | 代码 | Harness系统(规范、工具、测试、反馈) |
| 核心技能 | 编程、算法 | 系统设计、反馈工程、可观测性 |
| 调试对象 | 代码逻辑 | Agent行为模式 |
| 质量保证 | 手写测试 | 设计Agent无法绕过的验证门 |
| 文档工作 | 事后补文档 | AGENTS.md是第一优先级 |
| 迭代节奏 | PR→Review→Merge | 观察失败→改进Harness→重跑 |
角色转变:
- 传统工程师:设计→编码→测试→调试
- AI时代工程师:设计系统→构建Harness→引导Agent→验证结果
OpenAI的结论非常有力量:“Humans steer. Agents execute.” 人类负责掌舵,智能体负责执行。
八、当前局限与未来方向
当前局限
| 局限 | 描述 | 缓解方式 |
|---|---|---|
| Inferential验证成本高 | AI Code Review慢且贵,不适合每次提交 | 分层验证,关键路径才用Inferential |
| Harness维护成本 | AGENTS.md等文件会过期 | 背景Agent持续扫描更新 |
| 跨语言/项目迁移性差 | 针对具体项目的Harness难以复用 | 标准化Harness接口规范(NLAH方向) |
| 多Agent协调复杂 | Agent间通信、状态共享有挑战 | 标准化Agent间协议 |
| Guardrail和能力的平衡 | 过严的护栏限制Agent解决创造性问题 | 分层权限+人工审批升级 |
未来方向
Harness Engineering演进路线:
- 2026当前阶段:手工设计Harness,人类迭代改进;单项目Harness;Computational验证为主
- 2026-2027近期:AI辅助发现Harness改进点;标准化Harness接口;验证成本大幅降低
- 2027+远期:Harness自演化,失败自动触发规则更新;跨项目Harness市场,可复用组件生态;全自动Steering
九、写在最后
Harness Engineering的精髓可以用一句话概括:每当你发现Agent犯了一个错误,你就花时间设计一个解决方案,使Agent永远不再犯同样的错误。
从期待模型更好,转变为工程化地消除错误。这才是系统性可靠性的来源。
天花板高不高你我很难左右,但地板稳不稳,完全取决于你怎么搭这套系统。AI圈的概念会继续冒,但底层逻辑就一个:不能只盯着模型有多聪明,多想想怎么让它稳定地落地。
想动手试的话,不需要写代码,现在就能开始。选一个你每周都要重复做的任务,按照上面的方法,搭建属于你自己的第一个Harness吧。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)