面向基于混合专家模型(MoE)的鲁棒四足运动的可靠Sim-to-Real可预测性(论文翻译)
面向基于混合专家模型(MoE)的鲁棒四足运动的可靠Sim-to-Real可预测性
Tianyang Wu, Hanwei Guo, Yuhang Wang, Junshu Yang, Xinyang Sui, Jiayi Xie, Xingyu Chen, Zeyang Liu, Xuguang Lan (通讯作者)
西安交通大学
项目主页: https://robogauge.github.io/complete/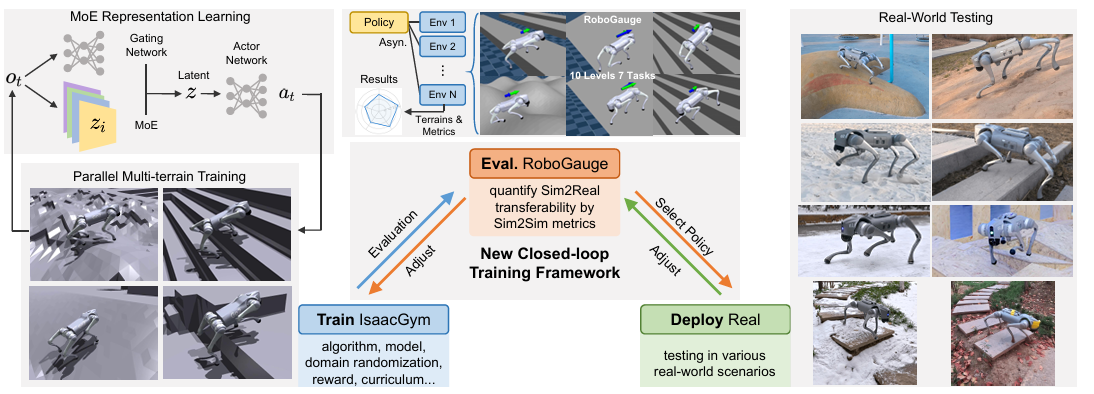
图1:我们提出的框架集成了一个用于地形和指令表示的混合专家(MoE)架构,并结合了RoboGauge评估套件,通过Sim-to-Sim指标来量化Sim-to-Real的迁移能力。这种闭环设计能够实现可靠的策略选择,从而在仅依靠本体感觉的情况下,在各种具有挑战性的环境中实现敏捷运动的鲁棒部署。
摘要
强化学习在四足敏捷运动中展现出巨大潜力,即使仅依靠本体感觉也是如此。然而在实践中,复杂地形中的虚实差距(Sim-to-Real gap)和奖励过拟合会产生无法成功迁移的策略,而物理验证仍然存在风险且效率低下。为了解决这些挑战,我们引入了一个统一的框架,该框架包含一个混合专家(MoE)运动策略(用于鲁棒的多地形表示),以及RoboGauge(一个量化Sim-to-Real迁移能力的预测评估套件)。MoE策略采用一组带门控的专家网络来分解潜在的地形和指令建模,仅通过本体感觉就实现了卓越的部署鲁棒性和泛化能力。RoboGauge进一步通过跨地形、难度级别和领域随机化的Sim-to-Sim测试,提供了基于本体感觉的多维指标,无需进行大量的物理试验即可实现可靠的MoE策略选择。在Unitree Go2上的实验证明了在未见过的复杂地形(包括雪地、沙地、楼梯、斜坡和30厘米障碍物)上的鲁棒运动。在专门的高速测试中,机器人的速度达到了 4 m / s 4~m/s 4 m/s,并展现出一种与高速稳定性提高相关的涌现式窄步态。
I. 引言
机器人经常在需要高机动性的复杂动态环境中运行。四足机器人因其卓越的机动性和环境适应性而备受瞩目。强化学习已成为运动控制的一种有效方法,它通过基于仿真的交互促进连续的策略优化,以增强机器人运动的鲁棒性。
固有的虚实差距仍然是一个主要障碍,因为基于仿真的性能指标在实际部署中往往被证明是不可靠的。具体来说,跨多种地形的高训练奖励通常无法保证物理稳定性,因为策略往往会过拟合于仿真机器人的特定动力学特性,从而降低了向实际硬件迁移的泛化能力。此外,由于缺乏可靠的定量代理指标,研究人员不得不依赖直接的物理验证,而这一过程仍然具有极高的风险且效率低下。
为了缓解这些挑战,我们提出了一种训练框架,该框架集成了用于地形和指令表示的混合专家(MoE)架构,以及RoboGauge评估套件。这种MoE方法通过完全依赖本体感觉来编码未知地形和指令,从而提高建模能力,同时避免使用摄像头、激光雷达或足部接触传感器等外感受传感器(这些传感器在浓烟、光线不足或剧烈震动等极端条件下经常失效)。
作为策略迭代架构的补充,我们开发了RoboGauge作为一个预测性评估框架,旨在通过采用并行的Sim-to-Sim方法来量化Sim-to-Real的稳定性。该方法跨越了涉及7种地形和10个难度级别、3个目标以及4种领域随机化的6个不同指标。
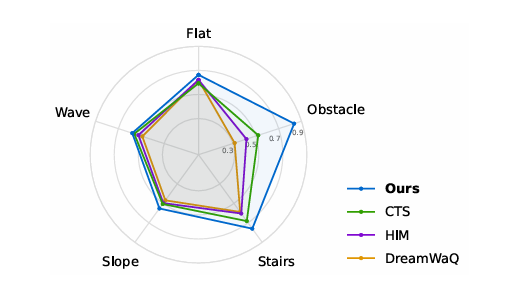
图2:与包括CTS、HIM和DreamWaQ在内的单阶段本体感觉方法的对比分析。在RoboGauge框架内,每个轴反映了在特定地形上的平均性能,并作为量化Sim-to-Real能力的可靠代理。在RoboGauge的指标下,我们的架构在所有评估的地形中始终优于或与先前的最先进技术持平。
图2展示了在RoboGauge中评估的各种模型在七种地形上的性能分布。我们的MoE策略在每个地形类别中均优于所有基线方法,展示了全面的优势。这种方法在物理机器人的实际部署中进一步展现了卓越的性能。
我们的贡献总结如下:
- 我们提出了RoboGauge,这是一个综合的预测评估框架,利用Sim-to-Sim方法来量化Sim-to-Real迁移能力,从而降低在直接物理部署过程中造成硬件损坏的风险。
- 我们在策略中集成了一个混合专家(MoE)模块,以解决现有在多地形表示方面的缺陷,并在物理Unitree Go2机器人上展示了卓越的机动性。
- 我们证明了我们的框架使机器人能够在平坦地形上达到 4 m / s 4~m/s 4 m/s 的高速运动,同时展现出一种与提高稳定性相关的涌现式窄步态。
II. 相关工作
A. 用于四足运动的强化学习
在物理环境中使用强化学习进行四足运动受到严重的样本低效和潜在硬件危险的阻碍。主流的Sim-to-Real方法采用诸如近端策略优化(PPO)或师生训练等框架,以实现在低于 1 m / s 1~m/s 1 m/s 的速度下穿越多种地形。通过适应模块或循环信念编码器进行潜在参数估计,以及在并行仿真中进行对比学习,适应性得到了进一步提升。此外,研究通过指令课程将敏捷性推向了3.9 m/s的峰值速度,而通过能量优化奖励和多专家门控架构则涌现出了多样的步态和无缝切换。
B. Sim-to-Real 评估套件
运动模型的评估框架目前还很有限。相比之下,机器人操作领域的研究通过采用排名指标来验证仿真与现实之间的一致性,从而解决了类似的挑战。高保真数字孪生通过环境重建提供闭环评估,但通常面临成本高昂的问题,限制了它们在各种现实场景中的可扩展性。
III. MOE 潜在表示学习
所提出的单阶段强化学习框架的核心是用于四足运动的混合专家潜在表示学习,如图1的训练阶段所示。本节介绍了运动控制任务的数学公式和多专家神经网络架构的内部结构设计,随后详细说明了奖励配置和环境配置。
A. 强化学习中的运动控制
四足运动控制的核心目标是基于本体感觉为所有驱动关节确定合适的关节扭矩指令。假设本体感觉信息仅通过IMU和关节编码器获取,四足运动动力学被建模为一个无限视野的部分可观察马尔可夫决策过程(POMDP),由元组 ( S , A , O , P , Ω , R , ρ 0 ) (\mathcal{S}, \mathcal{A}, \mathcal{O}, P, \Omega, R, \rho_{0}) (S,A,O,P,Ω,R,ρ0) 定义。其中, S ⊂ R n \mathcal{S}\subset\mathbb{R}^{n} S⊂Rn 表示包含机器人感知及其周围环境所有动态信息的特权状态空间。集合 A ⊂ R m \mathcal{A}\subset\mathbb{R}^{m} A⊂Rm 代表动作空间, O ⊂ R o \mathcal{O}\subset\mathbb{R}^{o} O⊂Ro 代表观察空间。状态转移概率由 P ( s ′ ∣ s , a ) P(s^{\prime}|s,a) P(s′∣s,a) 表征,观察函数由 Ω ( o ∣ s ) \Omega(o|s) Ω(o∣s) 表征,奖励函数由 R ( s , a , s ′ ) R(s,a,s^{\prime}) R(s,a,s′) 表征,初始状态分布由 ρ 0 ( s 0 ) \rho_{0}(s_{0}) ρ0(s0) 表征。我们的目标是获得一个最优策略 π ∗ \pi^{*} π∗,使轨迹 τ = { s t , a t , r t , s t + 1 , . . . } \tau=\{s_{t},a_{t},r_{t},s_{t+1},...\} τ={st,at,rt,st+1,...} 上的期望累积折扣奖励最大化:
J ( π ) = E s 0 ∼ ρ 0 , τ ∼ π [ ∑ t = 0 ∞ γ t R ( s t , a t , s t + 1 ) ] J(\pi)=\mathbb{E}_{s_{0}\sim\rho_{0},\tau\sim\pi}[\sum_{t=0}^{\infty}\gamma^{t}R(s_{t},a_{t},s_{t+1})] J(π)=Es0∼ρ0,τ∼π[t=0∑∞γtR(st,at,st+1)]
其中 γ ∈ ( 0 , 1 ) \gamma\in(0,1) γ∈(0,1) 为折扣因子。
令 o t ∈ O o_{t}\in\mathcal{O} ot∈O 和 s t ∈ S s_{t}\in\mathcal{S} st∈S 分别表示时间t的观察和状态。观察包含IMU测量的角速度、机体坐标系下重力矢量的投影 g p r o j g_{proj} gproj、关节位置 q q q、关节速度 q ˙ \dot{q} q˙、纵向和横向的线速度指令 v x c m d v_{x}^{cmd} vxcmd 和 v y c m d v_{y}^{cmd} vycmd、偏航角速度指令 ω z c m d \omega_{z}^{cmd} ωzcmd,以及前一个动作 a t − 1 a_{t-1} at−1。除了 o t o_{t} ot 的组件外,状态 s t s_{t} st 还包含线速度 v t v_{t} vt、采样地形高度 h t h_{t} ht,以及代表足端接触力、关节扭矩和关节加速度的环境潜在参数 μ t \mu_{t} μt。高度测量在以机器人底座为中心的 1 m × 1.6 m 1m\times1.6m 1m×1.6m 矩形区域内以0.1m的间隔进行采样,提供了局部地形的全面表示。动作 a t ∈ A a_{t}\in\mathcal{A} at∈A 表示相对于初始关节位置的关节位置偏移量。对于每个驱动关节,模型输出目标位置,所需的扭矩通过比例-微分(PD)控制器计算得出。
B. 混合专家(MoE)表示编码器
为了便于获取最优策略,训练期间通常采用特权观察 s t s_{t} st 来加速学习并提高性能上限。考虑到模型在部署期间仅限于观察 o t o_{t} ot,师生范式利用蒸馏技术将优势策略转移给学生。并发师生(CTS)框架同时优化教师和学生网络。通过这种并行学习过程,两个实体都更新了actor和critic网络,使学生的反馈能够主动微调教师的参数。这种联合优化通常会产生优于独立训练所取得的结果。我们观察到,学生模型有限的表达能力往往使其无法准确推断出由教师编码的特征,从而限制了性能上限。为了克服这一限制,我们将混合专家(MoE)结构集成到CTS框架内的学生架构中。这种增强增强了学生的表征能力,并进一步提高了整个系统的性能上限。
我们将CTS框架中的学生编码器替换为MoE网络。该架构包含 K K K 个并行专家子网络 { E k } k = 1 K \{E_{k}\}_{k=1}^{K} {Ek}k=1K,其中每个专家专门处理特定指令类型或环境上下文下的观察数据。为了协调这些子网络,我们引入了一个门控网络 g g g,该网络根据观察序列 o t − H : t = [ o t − H , ⋅ ⋅ ⋅ , o t ] T o_{t-H:t}=[o_{t-H},\cdot\cdot\cdot,o_{t}]^{T} ot−H:t=[ot−H,⋅⋅⋅,ot]T 动态分配权重 ω k \omega_{k} ωk:
ω k = s o f t m a x ( g ( o t − H : t ) ) k \omega_{k}=softmax(g(o_{t-H:t}))_{k} ωk=softmax(g(ot−H:t))k
这些系数决定了每个专家对当前状态表示的相对贡献。因此,学生编码器产生的潜在状态 z j z_{j} zj 公式化为所有专家输出的加权和:
z j = ∑ k = 1 K ω k E k ( o t − H : t ) z_{j}=\sum_{k=1}^{K}\omega_{k}E_{k}(o_{t-H:t}) zj=k=1∑KωkEk(ot−H:t)
针对第j个样本。这种表述鼓励系统在所有专家之间均匀分配任务,以确保表示的多样性和表达能力。为防止门控网络仅仅激活单一的专家子网络,我们加入了辅助的负载均衡损失:
L l o a d _ b a l a n c e = ∑ k = 1 K ( ω ‾ k − 1 K ) 2 = 1 B ∑ j = 1 B ( ω k ( j ) − 1 K ) 2 \mathcal{L}_{load\_balance}=\sum_{k=1}^{K}(\overline{\omega}_{k}-\frac{1}{K})^{2} = \frac{1}{B}\sum_{j=1}^{B}(\omega_{k}^{(j)}-\frac{1}{K})^{2} Lload_balance=k=1∑K(ωk−K1)2=B1j=1∑B(ωk(j)−K1)2
其中 B B B 指定训练期间使用的批次大小,而 ω k ( j ) \omega_{k}^{(j)} ωk(j) 代表分配给第k个专家的权重。
C. 奖励设计
我们在多地形和基于平地的高速运动模型中使用了统一的奖励函数结构。基本的奖励配置是基于已确立的方法建立的。在这些基础上,我们引入了髋关节位置奖励,以减少高速运动中大腿向外展的现象。附录表IX给出了全面的奖励规范。在这个框架中, σ \sigma σ 表示速度跟踪精度参数,初始值为0.25。此外,奖励组件 r f r r^{fr} rfr 采用了CTS模型中的公式,以激励机器人在高速运动中保持足够的离地间隙。对于平地上的高速运动训练,我们引入了一个外部髋关节对称性奖励 r h s r^{hs} rhs,以在执行纵向直线运动指令时规范关节位置。这一项确保机器人保持对称姿态,定义如下:
r h s = ∣ v x c m d ∣ ∣ ∣ v c m d ∣ ∣ 2 ⋅ ( ∣ q F L h i p + q F R h i p ∣ + ∣ q R L h i p + q R R h i p ∣ ) r^{hs}=\frac{|v_{x}^{cmd}|}{||v^{cmd}||_{2}}\cdot(|q_{FL}^{hip}+q_{FR}^{hip}|+|q_{RL}^{hip}+q_{RR}^{hip}|) rhs=∣∣vcmd∣∣2∣vxcmd∣⋅(∣qFLhip+qFRhip∣+∣qRLhip+qRRhip∣)
由于训练课程包含多种地形,一旦机器人实现稳定运动,垂直线速度奖励的权重就会衰减为零。这种减少可以防止由地形不规则引起的垂直速度波动干扰策略优化过程。我们观察到,增加基础高度奖励权重可以有效缓解平地高速运动时身体下垂的问题。对于多地形模型,参考基座高度设定为0.38m。相比之下,高速模型使用0.33m的较低参考高度,通过降低姿态来增强质心的稳定性。
D. 环境配置
我们使用IsaacGym仿真环境来跨多种地形并行训练8192个智能体。实验平台是具有12个自由度的Unitree Go2四足机器人。所有关节的电机PD控制增益指定为 k p = 20.0 k_{p}=20.0 kp=20.0 和 k d = 0.5 k_{d}=0.5 kd=0.5。系统控制频率为50Hz,仿真频率为200Hz。MoE输入的观察序列长度 O t − H : t O_{t-H:t} Ot−H:t 设置为5。算法配置遵循CTS框架。
建立适当的课程难度对于确保训练过程中的表征多样性至关重要。我们实施了一个包含七种地形(包括平地、波浪、斜坡、崎岖斜坡、上楼梯、下楼梯和障碍物)的地形课程。斜坡倾角从5.7°到29.6°不等,崎岖斜坡地形包含5厘米的随机高度波动。楼梯高度在5厘米到25.7厘米之间,踏板宽度恒定为31厘米。障碍物地形由高度跨越5厘米至27.5厘米、宽度在1m至2m之间的随机立方体结构组成。
为了促进有效的Sim-to-Real迁移,我们引入了领域随机化参数,详细信息如表I所示。
表 I:领域随机化规范
| Randomization Term | Range | Unit |
|---|---|---|
| Friction | [0.5, 1.5] | |
| Payload mass | [-1, 1] | kg |
| Link mass | [0.9, 1.1] x Nominal Value | kg |
| Base center of mass | [ − 3 , 3 ] × [ − 3 , 3 ] × [ − 3 , 3 ] [-3,3]\times[-3,3]\times[-3,3] [−3,3]×[−3,3]×[−3,3] | cm |
| Restitution | [0.0, 0.5] | |
| Proportional gain k p k_p kp | [0.9, 1.1] x Nominal Value | N m / r a d Nm/rad Nm/rad |
| Derivative gain k d k_{d} kd | [0.9, 1.1] x Nominal Value | N m ⋅ s / r a d Nm\cdot s/rad Nm⋅s/rad |
| Actuator strength | [0.8, 1.2] x Nominal Value | |
| Actuator offset | [-0.035, 0.035] | rad |
| Control latency | [0, 20] | ms |
我们指出了原始框架中的几个训练问题,这些问题在附录B中进行了详细说明,并附有相应的消融实验以验证我们改进的有效性。为了确保在复杂地形上的奖励稳定性,我们实施了动态速度跟踪精度调整,根据地形难度和指令幅度来缩放约束。我们进一步纳入了一套全面的指令设计套件,包括指令课程、极端指令采样和动态指令采样,以确保在不同地形等级上的持续进步。这些策略共同加速了收敛速度,并将最高RoboGauge得分提高了11%,同时促进了不同环境中稳定的运动模式。
IV. ROBOGAUGE预测评估框架
如图1中央评估模块所示,RoboGauge作为核心评估引擎,旨在弥合仿真训练与实际部署之间的差距。本节详细介绍了RoboGauge的设计理念,这是一个为定量验证强化学习(RL)运动控制器性能而开发的综合框架。
该框架基于MuJoCo仿真环境构建,其工作流程如图3所示,将评估过程组织为三个分层阶段:(1)用于原子级单环境评估的BasePipeline;(2)用于并行化难度评估和领域随机化的Multi/Level Pipeline;以及(3)用于合成统一鲁棒性得分的Stress Pipeline。以下小节分别详细介绍了我们定量指标的公式化、评估环境的设计以及分层评分方法。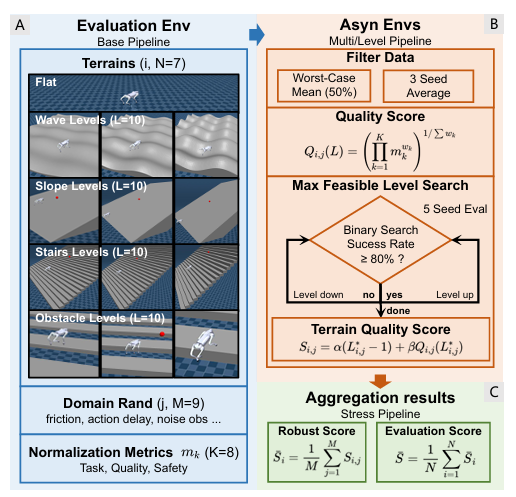
图3:RoboGauge评估架构由三个分层阶段组成。(A) Base Pipeline 作为包含特定地形和领域随机化的单一评估环境。(B) Multi/Level Pipeline 强调跨各种随机种子的并行评估。© Stress Pipeline 触发对整个地形套件的全面测试以综合最终得分。
A. 定量性能指标
RoboGauge的主要目标是从纯本体感受反馈中得出定量指标,这些指标能准确反映控制器在真实环境部署时的效果。基于在物理测试中常见故障模式的经验观察,我们制定了6个指标(如表II详述),解决了Sim-to-Real迁移的三个关键方面。首先,为了确保硬件安全和效率,我们评估了自由度限制(dof limits)和自由度功率(dof power),防止因电机运行不佳而导致执行器损坏或热故障。其次,通过速度误差量化跟踪精度,测量控制器在跟随线速度和角速度指令时的保真度。最后,我们通过扭矩平滑度和姿态稳定性评估运动稳定性,以减轻结构振动并确保鲁棒的姿态控制。
为了进一步形式化这种稳定性评估,我们整合了两个物理标准:零力矩点(ZMP)裕度以及接触扳手锥(CWC)约束下的库仑摩擦裕度。ZMP裕度通过聚合的牛顿-欧拉方程得出,评估ZMP相对于标称跨距的水平距离误差。库仑摩擦裕度计算所有有效接触上距离摩擦锥边界的法向力加权平均松弛量。附录A-A提供了这些稳定性指标的详细数学公式。为了便于统一评估,所有原始测量值都被归一化并通过函数 f ( x ) = 1 − x f(x)=1-x f(x)=1−x 转换,确保得分越高始终代表性能越好。
表 II:RoboGauge框架的指标
| Metric | Description |
|---|---|
| Lin. Velocity Error | Linear velocity l 2 l_{2} l2 tracking error |
| Ang. Velocity Error | Angular velocity l 2 l_{2} l2 tracking error |
| Dof Power | Motor power consumption |
| Dof Limits | Joint angles exceeding soft limits |
| Orientation Stability | Gravity projection on the lateral (y) axis |
| Torque Smoothness | Temporal smoothness of motor torques |
| ZMP Margin | Normalized Zero Moment Point deviation |
| Friction Margin | Normal-force-weighted Coulomb friction |
B. 评估环境与随机化
为了确保严格和全面的评估,该框架建立了一个系统的评估矩阵,整合了各种运动目标、复杂的地形结构和广泛的领域随机化。
运动目标: 我们设计了运动目标来对控制策略进行压力测试,详见附录表VIII。这些任务涵盖了最大指令执行、快速紧急停止和突然的对角线速度阶跃变化。此外,评估还纳入了受比例误差控制器调节的特定目标位置任务。此任务用作穿越地形的通过标准。它允许通过二分搜索策略来确定模型可以导航的最大难度级别。
地形配置: 评估套件拥有5个不同的地形类别:平地、波浪、斜坡、楼梯和障碍物。除了平地表面外,每种地形类型被细分为10个离散的难度级别,以探究控制器机动性的极限。图3明确说明了难度级别3、5和10的环境复杂性。除了难度按比例增加外,在斜坡和楼梯上导航还带来了独特的方向挑战。因此,我们明确评估了上行和下行配置,以确保无论坡度方向如何都能保持强劲的性能。
领域随机化: 我们在两个主要维度(环境因素和固有机器人属性)上实施领域随机化。具体而言,环境因素包括有效载荷和摩擦系数等变化,而机器人属性涵盖电机响应延迟和观察噪声。总的来说,这些扰动模拟了物理硬件的不完美之处,防止策略过拟合于理想的仿真动态,并确保稳健的真实世界迁移。
C. 分层评分方法
我们将包含 N = 7 N=7 N=7 个地形配置的集合表示为 T = { T 1 , . . . , T N } \mathcal{T}=\{T_{1},...,T_{N}\} T={T1,...,TN},通过将斜坡和楼梯上的上行和下行方向视为独立的评估环境,扩展了五个不同的地形类别。对于每种地形 T ∈ T T\in\mathcal{T} T∈T,我们应用 M = 9 M=9 M=9 种不同的领域随机化,表示为 D = { d 1 , . . . , d M } \mathcal{D}=\{d_{1},...,d_{M}\} D={d1,...,dM}。地形难度被分为10个级别,表示为 L ∈ { 1 , 2 , . . . , 10 } L\in\{1,2,...,10\} L∈{1,2,...,10}。每次评估会产生 K = 8 K=8 K=8 个性能指标,表示为 M = { m 1 , . . . , m K } \mathcal{M}=\{m_{1},...,m_{K}\} M={m1,...,mK}。
接下来,我们将评估模型的综合评分方法公式化。对于给定的地形 T i T_{i} Ti、领域随机化 d j d_{j} dj 和难度级别 L L L,我们聚合 K = 8 K=8 K=8 个归一化指标 { m 1 , . . . , m 8 } \{m_{1},...,m_{8}\} {m1,...,m8},其中每个 m k ∈ [ 0 , 1 ] m_{k}\in[0,1] mk∈[0,1] 表示三个随机种子的平均结果。为了惩罚不平衡的性能,特别是防止在关键维度失败时出现高分,我们采用加权几何平均值来计算执行质量得分:
Q i , j ( L ) = ( ∏ k = 1 K m k w k ) 1 / ∑ k = 1 K w k Q_{i,j}(L)=(\prod_{k=1}^{K}m_{k}^{w_{k}})^{1/\sum_{k=1}^{K}w_{k}} Qi,j(L)=(k=1∏Kmkwk)1/∑k=1Kwk
我们采用“最差情况平均(Worst-Case Mean)”聚合策略来评估运动目标的性能。此方法涉及对每个目标中最低50%的得分进行平均,从而有效降低对简单指令的高分权重,将评估重点集中在障碍物跨越和步态转换等具挑战性的机动动作上。此外,我们计算全局均值和前25%的均值作为更广泛的参考,详见附录表XIII。
我们使用二分搜索策略来确定模型在特定领域随机化参数下能够达到的每种地形的最大可行难度级别 L i , j ∗ ∈ L L_{i,j}^{*}\in\mathcal{L} Li,j∗∈L。在给定级别上,对模型在五个随机种子上进行评估,以验证其是否成功到达目标。如果在目标到达任务中的成功率超过80%,则认为难度级别是可通关的。
令 Q i , j ( L i , j ∗ ) Q_{i,j}(L_{i,j}^{*}) Qi,j(Li,j∗) 表示在最高可通关难度级别下的执行质量得分。为了平衡不同地形上的任务难度和执行质量,特定地形 T i T_{i} Ti 和领域随机化 d j d_{j} dj 的地形质量得分 S i , j S_{i,j} Si,j 使用以下重叠评分函数公式化:
S i , j = α ( L i , j ∗ − 1 ) + β Q i , j ( L i , j ∗ ) S_{i,j}=\alpha(L_{i,j}^{*}-1)+\beta Q_{i,j}(L_{i,j}^{*}) Si,j=α(Li,j∗−1)+βQi,j(Li,j∗)
通过设置 β > α \beta>\alpha β>α,这种设计确保了在较低难度级别上的高质量表现能够逼近在较高难度级别上的平庸表现的得分,从而促进不同难度层级之间的平滑过渡。
框架结果通过算术平均进行汇总。最初,我们通过对 M M M 个领域随机化的结果取平均值来计算每种地形 T i T_{i} Ti 的鲁棒得分 S ‾ i \overline{S}_{i} Si。随后,通过对所有 N N N 种地形的这些鲁棒得分取平均值,得到最终的框架得分 S S S:
S ‾ i = 1 M ∑ j = 1 M S i , j \overline{S}_{i}=\frac{1}{M}\sum_{j=1}^{M}S_{i,j} Si=M1j=1∑MSi,j
S = 1 N ∑ i = 1 N S ‾ i S=\frac{1}{N}\sum_{i=1}^{N}\overline{S}_{i} S=N1i=1∑NSi
鉴于地形类型、随机化参数和随机种子存在大量组合,顺序执行完整评估会极其耗时。因此,我们采用多进程加速来并发运行环境实例。这种效率满足了整个训练阶段对快速性能反馈的需求。附录A详细阐述了进一步的实现细节和所有特定的超参数值。
V. 框架验证与消融实验
在本节中,我们展示了旨在解决以下研究问题的实验:
- Q1:RoboGauge提供的指标与现实世界的性能密切相关吗?
- Q2:目前最先进的方法在我们的评估框架下表现如何?
- Q3:混合专家(MoE)架构能否有效区分各种编码地形?
A. RoboGauge的指标可靠性
我们将所提出的模型和基线部署在Unitree Go2四足机器人上。我们利用运行频率为90Hz的12摄像头NOKOV Mars 18H动作捕捉系统,通过在机器人基座上安装五个标记点,获取平地和10厘米楼梯上的实时线速度和角速度数据。同时,我们收集本体感受反馈和电机扭矩,以得出表II中的六个特定指标。
为了量化这些评估方法的保真度,我们将训练环境和我们提出的框架得出的指标误差与现实世界的真实情况(Ground Truth)进行比较。我们特别评估了一个在训练期间表现出色但遭受严重Sim-to-Real衰减的模型。如表III所示,训练环境持续产生较大的误差。附录表XII中提供的综合评分数据进一步证实,通过我们框架获得的误差明显低于标准训练评估的误差。这些结果表明,我们的评估框架更准确地反映了实际性能,并为模型选择提供了更可靠的基础。
表 III:指标误差比较
| Env. | Cmd. | Tracking↓ | Safety | Quality |
|---|---|---|---|---|
| MuJoCo (Ours) | Longitudinal | 0.0573 | 0.0253 | 0.0246 |
| Lateral | 0.0541 | 0.0049 | 0.0079 | |
| Angular | 0.0560 | 0.0050 | 0.0035 | |
| Average | 0.0558 | 0.0117 | 0.0120 | |
| IsaacGym (Training) | Longitudinal | 0.1365 | 0.0844 | 0.0678 |
| Lateral | 0.0572 | 0.0052 | 0.0125 | |
| Angular | 0.0713 | 0.0103 | 0.0337 | |
| Average | 0.0883 | 0.0333 | 0.0380 |
B. RoboGauge下基线的比较
为了促进严格的比较评估,我们将我们提出的方法与其他几种完全基于本体感觉的最先进的单阶段训练算法进行基准测试:
- DreamWaQ: 策略利用具有变分估计器的非对称actor-critic方案来联合预测机体速度和地形潜变量。
- HIM: 策略结合了一个混合内部模型,使用对比学习显式估计机器人的响应。
- CTS: 策略采用非对称的师生设置,通过强化学习和监督重建来优化智能体。
我们使用一致的配置实现所有上述方法,在IsaacGym中并行训练8192个智能体。由于DreamWaQ和HIM不支持特定地形的速度指令范围,我们将其最大限制设为 1 m / s 1~m/s 1 m/s。在RoboGauge评估中对这些模型应用相同的约束,以降低指令跟踪的难度。相反,CTS和我们提出的模型在训练和评估期间均使用 2 m / s 2~m/s 2 m/s 的指令范围。每种算法都使用三个独立的随机种子进行训练,我们选择RoboGauge得分最高的模型进行后续分析。表IV总结的结果表明,我们的方法在所有指标上均显著优于其他方法。
表 IV:基线在RoboGauge的测试结果
| Model | Score | Tracking ↑ | Safety ↑ | Quality ↑ | Level |
|---|---|---|---|---|---|
| Ours | 0.6713 | 0.6669 | 0.7857 | 0.7392 | 7.85 |
| CTS | 0.5786 | 0.5755 | 0.7066 | 0.6624 | 6.83 |
| HIM | 0.5379 | 0.5453 | 0.6476 | 0.6050 | 6.19 |
| DreamWaQ | 0.5054 | 0.5105 | 0.6149 | 0.5730 | 5.74 |
如图4中的训练曲线所示,与其它基线相比,我们的模型在训练阶段并不一定达到最高的地形级别。然而,可预测性评估框架提供了准确反映底层性能的精确分数。图5说明了在各种摩擦系数下达到的最大地形级别。附录的图14提供了地形级别的详细信息。我们的模型在整个摩擦值范围内始终表现出卓越的地形级别精通度。这些发现得到了表VI中真实世界部署数据的进一步证实,这证实了该控制器拥有在物理环境中导航这种具有挑战性环境的能力。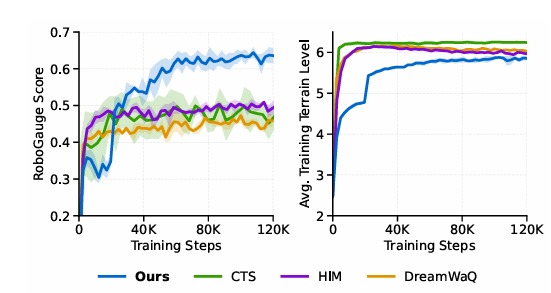
图4:训练期间各种基线的RoboGauge得分和地形级别曲线的比较。尽管地形级别波动,但RoboGauge得分保持稳定,表明训练级别无法准确代表模型性能。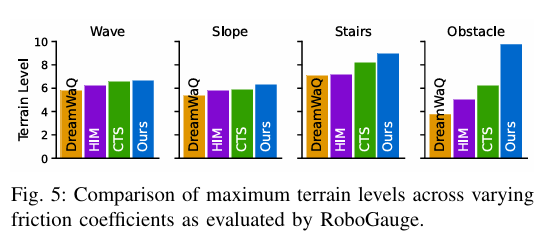
图5:RoboGauge评估的在不同摩擦系数下的最大地形级别比较。
C. MoE的消融实验与潜在表示
我们设计了各种消融实验来研究集成的MoE结构,包括以下变体:
- MoE-NG: 指令信息从MoE输入中被排除,仅利用观察信息传递给专家网络。
- AC-MoE: 遵循MoE-Loco的做法,将MoE结构应用于Actor-Critic网络而不是学生编码器。
- MCP: 对Actor输出的动作采用乘法组合策略。
如表V所示,我们提出的方法在所有评估指标中均取得了最佳性能。此外,在训练期间,我们观察到对动作网络(如AC-MoE和MCP)的修改容易出现损失发散。这种不稳定性可能源于专家组合直接在动作空间内起作用。门控网络和各个专家的并发适应会产生不稳定的控制信号,从而引发危险的机动动作,进而破坏训练的稳定性。
表 V:MoE消融实验的RoboGauge结果
| Model | Score | Tracking | Safety | Quality | Level |
|---|---|---|---|---|---|
| MoE (Ours) | 0.6713 | 0.6669 | 0.7857 | 0.7392 | 7.85 |
| AC-MoE | 0.6509 | 0.6442 | 0.7644 | 0.7149 | 7.52 |
| MoE-NG | 0.6519 | 0.6447 | 0.7639 | 0.7186 | 7.56 |
| MCP | 0.6399 | 0.6355 | 0.7542 | 0.7058 | 7.41 |
随后,我们通过应用主成分分析(PCA)对学生编码器隐藏状态进行降维,来可视化MoE潜在空间。图6对比了在不同地形上向前运动5秒期间的状态分布,以评估MoE模块的影响。类似地,附录中的图16说明了在所有地形下,包括向前、向后、左转和右转各种指令(持续5秒)的隐藏状态分布。这些结果表明,MoE架构在不同地形和运动指令下实现了对编码特征的卓越区分。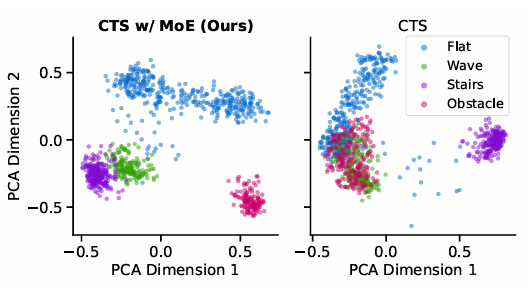
图6:不同地形前向指令下学生编码器潜在空间的PCA可视化。
VI. 物理部署与泛化
在本节中,我们的真实世界实验旨在解决以下研究问题。
- Q4:与其它基线相比,所提出的框架在更具挑战性的地形上表现是否更好?
- Q5:其跟踪速度指令的准确度如何?
- Q6:该模型能否在训练中未遇到过的多样化复杂环境中可靠地执行?
表 VI:真实世界存活率比较
| Model | Lat. Impulse (80-100 N) | Tile Stairs 15.5cm ( μ = 0.38 ) (\mu=0.38) (μ=0.38) | Obstacle 30cm ( μ = 0.85 ) (\mu=0.85) (μ=0.85) |
|---|---|---|---|
| Ours | 18 / 20 18/20 18/20 | 85 / 85 85/85 85/85 | 17 / 20 17/20 17/20 |
| Built-in RL | 5 / 20 5/20 5/20 | 85 / 85 85/85 85/85 | 0 / 20 0/20 0/20 |
| CTS | 11 / 20 11/20 11/20 | 18 / 85 18/85 18/85 | 0 / 20 0/20 0/20 |
| HIM | 8 / 20 8/20 8/20 | 24 / 85 24/85 24/85 | 0 / 20 0/20 0/20 |
| DreamWaQ | 7 / 20 7/20 7/20 | 12 / 85 12/85 12/85 | 0 / 20 0/20 0/20 |
A. 在地形挑战上的比较
我们将所提出的模型和基线部署在Unitree Go2四足机器人上,以评估其实际性能,如表VI所总结。实验验证包括三个鲁棒性场景:80 N到100 N的突然侧向拉力、15.5厘米的光滑瓷砖楼梯以及30厘米的障碍物攀爬,附录图17描绘了具体的设置。只有我们的模型成功翻越了30厘米的障碍物,同时在侧向拉力期间展现了最有效的抗干扰能力。虽然我们的方法和内置的强化学习控制器都征服了楼梯,但我们的模型跑完85级台阶比基线快了17秒。
B. 速度跟踪精度
我们采用动作捕捉系统来评估在平地和楼梯场景下的速度跟踪准确性。图7描绘了机器人以 1.31 m / s 1.31~m/s 1.31 m/s 的平均速度在楼梯上行进,跟踪误差为 0.15 m / s 0.15~m/s 0.15 m/s,这证实了该框架在应对复杂环境时依然具备鲁棒的跟踪能力。我们进一步评估了在30度木质斜坡上的运动性能,机器人在此保持着 1.53 m / s 1.53~m/s 1.53 m/s 的平均速度。如附录图8所记录,与内置强化学习基线相比,这种高效性将穿越时间减少了1.7秒。
图9说明了在平坦地面上高速运动期间的跟踪性能。受限于8米长的室内跑道,机器人在2.16秒内达到 4.01 m / s 4.01~m/s 4.01 m/s 的峰值速度,跟踪误差为 0.20 m / s 0.20~m/s 0.20 m/s,展现了卓越的加速和制动能力。值得注意的是,尽管没有显式的运动约束,模型仍自主地发展出一种稳定的窄基步态,以最小化高速机动时的质心横向振荡并增强稳定性。
图7:在10厘米上升、15厘米下降的木质楼梯上的实验。右上方的图描绘了通过动作捕捉系统捕获的速度跟踪曲线,跟踪误差为 0.15 m / s 0.15~m/s 0.15 m/s。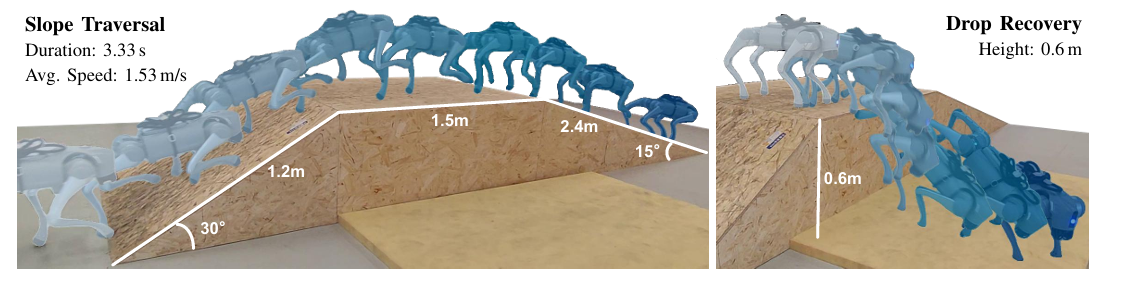
图8:在穿越斜坡和跌落恢复期间的鲁棒运动。左侧面板显示,与内置RL基线相比,在 μ = 0.71 \mu=0.71 μ=0.71 的斜坡上效率提升了1.7秒,右侧框架验证了从60厘米跌落中可靠恢复。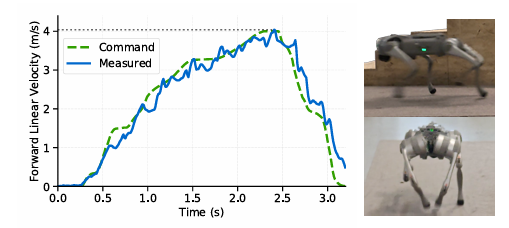
图9: μ = 0.6 \mu=0.6 μ=0.6 表面上的速度跟踪和步态。左图显示了指令跟随情况,在2.16秒内达到 4.01 m / s 4.01~m/s 4.01 m/s,误差为 0.20 m / s 0.20~m/s 0.20 m/s。右上图捕捉了瞬态飞行阶段,而右下图突出显示了稳定的窄基步态。
C. 稳定性与泛化能力
我们验证了所提模型在两种具有挑战性的真实场景中的紧急恢复能力。首先,机器人会受到强烈推拉等外力作用,它通过改变质心和创造步态来抵消冲击,表现出极大的抗干扰性。图10和17显示,机器人在经历25 N至40 N的连续横向拉力以及85 N至100 N的突发冲量下保持稳定,而既有基线在此情况下几乎完全失去平衡。其次,当遇到突然的支撑丢失时,机器人会迅速重新配置其步态,以确保立足稳固并防止向前翻滚。图8展示了从60厘米高度跌落后的成功恢复序列,而图18描绘了从平地意外跌落到楼梯后自然过渡到稳定姿态的过程。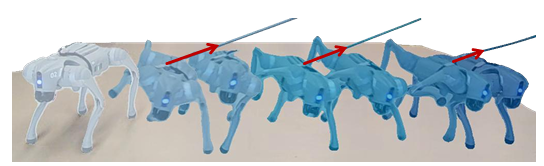
图10:平坦地形上的连续侧向拉力抗干扰实验。机器人承受大约25~40N的反复侧向拉力,同时保持稳定的运动。
最后,我们在多样化的户外环境中进行了实地测试,以评估框架的泛化能力。图1的右侧面板说明了在沙地、冰面以及斜坡和不平坦地形等各种地形上的表现。机器人以100%的成功率完成了所有试验,没有出现意外终止,这突显了所学策略的卓越鲁棒性。
VII. 结论与未来工作
在这项工作中,我们提出了一个训练框架,包括RoboGauge评估套件和MoE运动策略,该框架实现了仅依靠本体感觉的鲁棒多地形运动。在Unitree Go2机器人上的物理实验表明,我们的框架成功克服了包括30厘米障碍物和100 N冲量在内的极具挑战性的环境,同时在平坦地面上使用相同的训练配置达到了4.01 m/s的峰值速度。该框架在跟踪精度和恢复稳定性方面始终优于现有的基线,在多样化的户外现场测试中具有100%的成功率。预测性评估与模块化架构之间的这种协同作用,为弥合仿真结果与实际物理性能之间的差距提供了一种可靠而有效的方法。
未来的研究将把RoboGauge扩展到人形机器人等更广泛的形态,并将外感受性感知与MoE表示相结合,以进一步提升越过复杂结构障碍物的能力。
致谢
作者感谢Tencent AI Arena和Unitree Robotics提供Go2四足机器人用于初始实验。感谢Guangsheng Li提供基线DreamWaQ的训练代码。
附录 A ROBOGAUGE补充材料
A. 稳定性指标
为了对运动稳定性进行更全面的评估,我们在RoboGauge中引入了两个正式的物理标准:零力矩点(ZMP)裕度和接触扳手锥(CWC)约束下的库仑摩擦裕度。
1) 零力矩点(ZMP)裕度: 零力矩点(ZMP)是腿足运动中的一个基本概念,定义为地面上的一个点,在该点惯性力矩和重力矩的净矩没有水平分量。为了在我们的框架内将这一指标形式化,我们建立了以下定义:
- 支撑多边形:机器人与地面之间所有有效接触点形成的凸包。
- 虚拟ZMP (FZMP):当计算出的ZMP落在支撑多边形之外时,被称为FZMP,表明系统处于动态不平衡状态。
- 虚拟水平面:平移至 O ′ O^{\prime} O′(代表所有有效地面接触点几何中心)的坐标系,将系统投影到xy平面上。
在MuJoCo仿真环境中,通过聚合机器人所有 N N N 个刚体上的动力学来计算ZMP。对于当前时间步的第 i i i 个刚体,我们定义其质量为 m i m_{i} mi,其相对于 O ′ O^{\prime} O′ 的质心(CoM)位置为 p i p_{i} pi,其CoM线加速度为 p ˙ i \dot{p}_{i} p˙i,其角速度为 ω i \omega_{i} ωi,其角加速度为 ω ˙ i \dot{\omega}_{i} ω˙i,以及其惯性张量为 I i I_{i} Ii。至关重要的是,所有的运动学和惯性属性都严格在世界坐标系中表达。系统的总力 F t o t a l F_{total} Ftotal 和总力矩 M t o t a l M_{total} Mtotal 的公式如下:
F t o t a l = ∑ i = 1 N m i ( g − p ˙ i ) F_{total}=\sum_{i=1}^{N}m_{i}(g-\dot{p}_{i}) Ftotal=i=1∑Nmi(g−p˙i)
M t o t a l = ∑ i = 1 N [ ( p i × m i ( g − p ˙ i ) ) − ( I i ω ˙ i + ω i × ( I i ω i ) ) ] M_{total}=\sum_{i=1}^{N}[(p_{i}\times m_{i}(g-\dot{p}_{i}))-(I_{i}\dot{\omega}_{i}+\omega_{i}\times(I_{i}\omega_{i}))] Mtotal=i=1∑N[(pi×mi(g−p˙i))−(Iiω˙i+ωi×(Iiωi))]
根据定义,在ZMP处总力矩和力的关系由 M = r z m p × F t o t a l M=r_{zmp}\times F_{total} M=rzmp×Ftotal 给出。展开该叉积可以得到力矩分量:
{ M y = − x z m p F z + z z m p F x M x = y z m p F z − z z m p F y \begin{cases}M_{y}=-x_{zmp}F_{z}+z_{zmp}F_{x}\\ M_{x}=y_{zmp}F_{z}-z_{zmp}F_{y}\end{cases} {My=−xzmpFz+zzmpFxMx=yzmpFz−zzmpFy
通过将ZMP投影到虚拟水平面 ( z z m p = 0 ) (z_{zmp}=0) (zzmp=0),精确的ZMP坐标 ( x z m p , y z m p ) (x_{zmp},y_{zmp}) (xzmp,yzmp) 推导如下:
x z m p = − M y F z , y z m p = M x F z x_{zmp}=-\frac{M_{y}}{F_{z}}, \quad y_{zmp}=\frac{M_{x}}{F_{z}} xzmp=−FzMy,yzmp=FzMx
令 D n o r m D_{norm} Dnorm 表示机器人默认姿态下的对角跨距。归一化的ZMP裕度(表示ZMP相对于有效接触几何中心的水平距离误差)定义为:
m z m p _ m a r g i n = max ( 0 , 1 − ∣ ∣ ( x z m p , y z m p ) ∣ ∣ 2 D n o r m ) m_{zmp\_margin}=\max(0,1-\frac{||(x_{zmp},y_{zmp})||_{2}}{D_{norm}}) mzmp_margin=max(0,1−Dnorm∣∣(xzmp,yzmp)∣∣2)
2) 库仑摩擦裕度: 为了考虑潜在的滑动和接触扳手锥(CWC)约束,我们引入了平移摩擦裕度。令 N c N_{c} Nc 为脚底与地面的有效接触数量。对于每个接触 i i i, f i t a n g e n t f_{i}^{tangent} fitangent 表示切向力, f i n o r m a l f_{i}^{normal} finormal 表示法向力, μ \mu μ 为表面摩擦系数。库仑摩擦裕度计算为所有有效接触上摩擦锥边界的法向力加权平均松弛度:
m f r i c t i o n _ m a r g i n = ∑ i = 1 N c w i max ( 0 , 1 − ∣ ∣ f i t a n g e n t ∣ ∣ μ f i n o r m a l ) m_{friction\_margin}=\sum_{i=1}^{N_{c}}w_{i}\max(0,1-\frac{||f_{i}^{tangent}||}{\mu f_{i}^{normal}}) mfriction_margin=i=1∑Ncwimax(0,1−μfinormal∣∣fitangent∣∣)
其中权重因子 w i w_{i} wi 动态地强调承载更大垂直载荷的接触:
w i = f i n o r m a l ∑ j = 1 N c f j n o r m a l w_{i}=\frac{f_{i}^{normal}}{\sum_{j=1}^{N_{c}}f_{j}^{normal}} wi=∑j=1Ncfjnormalfinormal
B. 超参数配置
在质量得分计算方程5中,任务完成指标的权重设为 w k = 2 w_{k}=2 wk=2,其余指标设为 w k = 1 w_{k}=1 wk=1。对于重叠评分函数方程6,超参数设为 α = 0.09 \alpha=0.09 α=0.09 和 β = 0.19 \beta=0.19 β=0.19,这确保了性能得分有界于 [ 0 , 1 ] [0,1] [0,1] 范围内。领域随机化包括从0.2到1.0(增量为0.1)的摩擦系数。地形等级设计有从0.1到1.0(增量为0.1)的难度参数 d d d,详见表VII。运动控制目标按表VIII进行配置。
C. 实现细节
每个流程的运行逻辑概述如下。BasePipeline(图11)协调仿真引擎 sim、负责控制指令和指标计算的评估器 gauge 以及运动模型 robot 之间的交互。此外,它还管理异常处理、领域随机化和观察噪声的应用。MultiPipeline利用多进程来跨各种种子和领域随机化配置执行BasePipeline,同时汇总输出文件。为了确定给定地形的最大可行难度,LevelPipeline(图12)确定模型在三个独立随机种子上成功穿过的最高级别。
表 VII:地形等级设计参数 ( d = 0.1 , 0.2 , ⋅ ⋅ ⋅ , 1.0 ) (d=0.1, 0.2, \cdot\cdot\cdot, 1.0) (d=0.1,0.2,⋅⋅⋅,1.0)
| Terrain | Specification & Formula | Range / Unit |
|---|---|---|
| Wave | Amplitude A = 0.4 d A=0.4d A=0.4d Period T = 1.6 T=1.6 T=1.6 Height Field z ( x , y ) = A s i n ( x / T ) + A c o s ( y / T ) z(x,y)=A~sin(x/T)+A~cos(y/T) z(x,y)=A sin(x/T)+A cos(y/T) |
A ∈ [ 0.04 , 0.4 ] A\in[0.04,0.4] A∈[0.04,0.4] m m |
| Slope | Slope k = 0.07 + 0.5 d k=0.07+0.5d k=0.07+0.5d | Angle θ ∈ [ 8.4 ∘ , 29.7 ∘ ] \theta\in[8.4^{\circ},29.7^{\circ}] θ∈[8.4∘,29.7∘] |
| Stairs | Step Width w = 0.31 w=0.31 w=0.31 h = { 0.05 + 0.3 d , 0.1 ≤ d ≤ 0.4 0.17 + 0.1 ( d − 0.4 ) , 0.5 ≤ d ≤ 1.0 h=\begin{cases}0.05+0.3d, & 0.1\le d\le0.4\\ 0.17+0.1(d-0.4), & 0.5\le d\le1.0\end{cases} h={0.05+0.3d,0.17+0.1(d−0.4),0.1≤d≤0.40.5≤d≤1.0 |
m h ∈ [ 0.08 , 0.23 ] m h\in[0.08,0.23]m h∈[0.08,0.23]m |
| Obstacles | Height h = 0.05 + 0.23 d h=0.05+0.23d h=0.05+0.23d | h ∈ [ 0.073 , 0.28 ] m h\in[0.073,0.28]m h∈[0.073,0.28]m |
表 VIII:运动控制目标配置
| Goal Name | Description | Reset Condition | Max Trials |
|---|---|---|---|
| Max Velocity | Evaluation of peak linear or angular velocity in a single dimension. | Sudden stop after each directional command. | 6 |
| Diagonal Velocity | Tracking of coupled diagonal velocity vectors (combined linear and angular). | Completion of each pair of diagonal commands. | 8 |
| Target Pos. Velocity | Position-based tracking using a Proportional controller to reach targets. | Goal reached or time limit exceeded. |
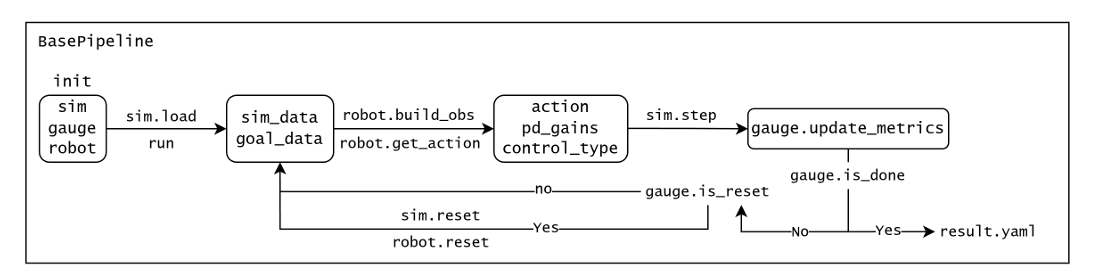
图11:BasePipeline的运行工作流。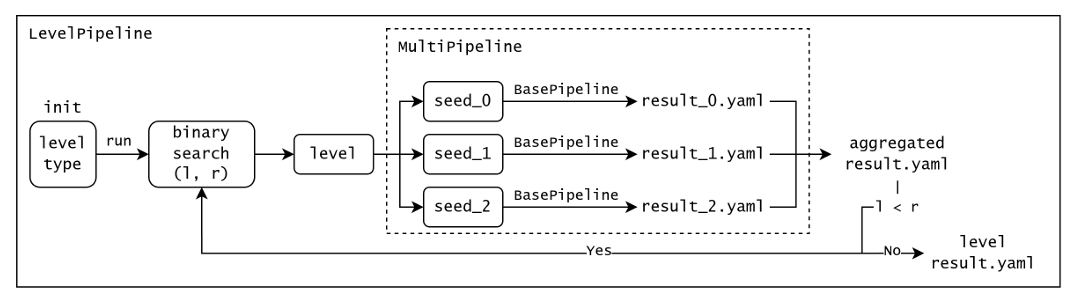
图12:LevelPipeline的运行工作流。
附录 B 训练细节
A. 动态速度跟踪精度调整
为了根据地形特征和难度级别调整速度跟踪精度,我们实施了动态缩放调整。我们观察到,当最大指令范围从0.5扩展到1.5时,在波浪、楼梯和障碍物等挑战性地形上的运动往往无法准确跟踪目标线速度。因此,我们调整了跟踪系数以放宽这些场景的跟踪约束。
我们定义 [ v m i n , v m a x ] [v_{min},v_{max}] [vmin,vmax] 为用于动态调整 σ \sigma σ 的速度幅度范围。参数 σ m a x T i \sigma_{max}^{T_{i}} σmaxTi 表示分配给第 i i i 种地形的最大速度跟踪系数。给定第 i i i 种地形的指令速度 v v v,中间系数 σ v e l \sigma_{vel} σvel 公式化如下:
σ v e l = { σ , v ∈ [ 0 , v m i n ) σ ( v − v m i n ) + σ m a x T i ( v m a x − v ) , v ∈ [ v m i n , v m a x ) σ m a x T i , v ∈ [ v m a x , ∞ ) \sigma_{vel} = \begin{cases} \sigma, & v \in [0, v_{min}) \\ \sigma(v-v_{min})+\sigma_{max}^{T_{i}}(v_{max}-v), & v \in [v_{min}, v_{max}) \\ \sigma_{max}^{T_{i}}, & v \in [v_{max}, \infty) \end{cases} σvel=⎩
⎨
⎧σ,σ(v−vmin)+σmaxTi(vmax−v),σmaxTi,v∈[0,vmin)v∈[vmin,vmax)v∈[vmax,∞)
最终的自适应跟踪系数 σ n o w \sigma_{now} σnow 融合了地形难度级别 L L L,描述如下:
σ n o w = σ + min ( e L 10 − 1 , 1 ) ( σ v e l − σ ) \sigma_{now}=\sigma+\min(e^{\frac{L}{10}}-1,1)(\sigma_{vel}-\sigma) σnow=σ+min(e10L−1,1)(σvel−σ)
速度指令 v v v 涉及纵向和横向线速度以及角速度指令。附录表X详述了最大速度跟踪系数 σ m a x T i \sigma_{max}^{T_{i}} σmaxTi 以及各种地形下相关的速度调整范围。
B. 指令设计
直接在所有地形上使用完整的 [ − 1 , 1 ] m / s [-1,1]m/s [−1,1]m/s 指令范围进行训练可以快速提升难度级别,但常常产生不稳定的步态。具体来说,机器人经常表现出跳跃和高频腿部动作等不稳定行为。相反,从低速指令开始训练有助于获得稳定的运动模式。因此我们引入了指令课程(如表XI所详述)来解决这些问题。
我们观察到,当最大指令幅度超过 [ − 1 , 1 ] m / s [-1,1]m/s [−1,1]m/s 时,机器人在波浪、楼梯和障碍物等复杂地形上无法准确跟踪目标线速度。这种跟踪差异会在训练过程中引发不稳定性。因此,我们对个别地形的最大指令范围施加了特定的限制,如表X所示。值得注意的是,尽管这些限制在训练阶段被严格执行,但在物理硬件测试中并未施加这些限制。尽管存在这种差异,模型仍能遵循训练分布之外的指令,并展现出稳健的泛化能力。
我们的实证分析表明,均匀的采样分布是次优的,因为边界值尽管在硬件部署中经常遇到,但出现的概率极低。为了解决这个问题,我们引入了一种极端的指令采样策略。该方法为静止指令分配10%的概率,为在所有三个维度上代表最大速度限制的指令组合分配20%的概率。此外,当线速度为零时,框架保持20%的概率来采样最大角速度,以增强枢轴转弯时的鲁棒性。
在训练开始时,线速度指令范围限制在 [ − 0.5 , 0.5 ] m / s [-0.5,0.5]m/s [−0.5,0.5]m/s,有10%的概率保持静止。如此狭窄的分布常常产生无法满足地形升级条件的指令序列(升级要求相对于初始位置的最终水平距离超过4米,相当于地形长度的一半)。此限制阻止了智能体探索更高难度级别。为了保证累积指令长度超过所需阈值,我们实施了动态指令采样策略。
令 n r n_{r} nr 代表采样的指令数量, v i c m d v_{i}^{cmd} vicmd 代表第 i i i 个线速度指令。假设 T r T_{r} Tr 为采样间隔, T e p T_{ep} Tep 为片段持续时间,第 ( n r + 1 ) (n_{r}+1) (nr+1) 个指令的采样范围限制在区间 ( − v m i n , − v ∗ ) ∪ ( v ∗ , v m a x ) (-v^{min},-v^{*})\cup(v^{*},v^{max}) (−vmin,−v∗)∪(v∗,vmax),其中 v ∗ v^{*} v∗ 公式化如下:
v ∗ : = clip ( 5 − ∣ ∣ ∑ i = 1 n r v i c m d ∣ ∣ 2 T r T e p − n r T r , 0 , min ( ∣ v m i n ∣ , ∣ v m a x ∣ ) ) v^{*} := \text{clip}(\frac{5-||\sum_{i=1}^{n_{r}}v_{i}^{cmd}||_{2}T_{r}}{T_{ep}-n_{r}T_{r}},0,\min(|v^{min}|,|v^{max}|)) v∗:=clip(Tep−nrTr5−∣∣∑i=1nrvicmd∣∣2Tr,0,min(∣vmin∣,∣vmax∣))
如果第 ( n r + 1 ) (n_{r}+1) (nr+1) 个样本选择了静止指令,其特定持续时间确定如下:
T z e r o = clip ( T e p − n r T r − 5 − ∣ ∣ ∑ i = 1 n r v i c m d ∣ ∣ 2 T r 0.8 × max ( v x m a x , v y m a x ) , 0 , T r ) T^{zero}=\text{clip}(T_{ep}-n_{r}T_{r}-\frac{5-||\sum_{i=1}^{n_{r}}v_{i}^{cmd}||_{2}T_{r}}{0.8\times \max(v_{x}^{max},v_{y}^{max})},0,T_{r}) Tzero=clip(Tep−nrTr−0.8×max(vxmax,vymax)5−∣∣∑i=1nrvicmd∣∣2Tr,0,Tr)
上述指令课程、极端指令采样和动态指令采样的整合促进了更稳定的运动步态的发展,同时确保了跨地形难度级别的稳步前进。此外,这些策略显著提高了用RoboGauge评估的模型的性能上限。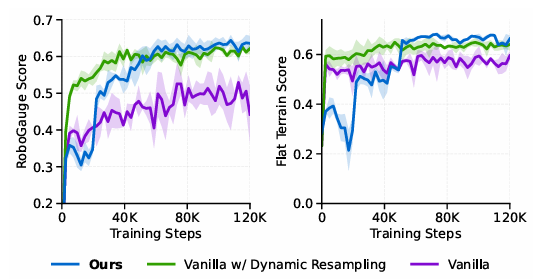
图13:训练策略的消融实验。
我们对训练配置进行了消融实验,图13说明了动态指令采样的影响。激活此功能可加速收敛,并使峰值奖励相对于没有动态采样的版本提高11%。最终的训练曲线是通过进一步合并动态速度跟踪精度调整和指令课程来实现的。这些附加功能显著增强了训练稳定性并改善了在平地上的性能。
附录 C 训练配置
表 IX:奖励函数规范
| Reward Term | Equation | Weight |
|---|---|---|
| Lin. velocity tracking | exp ( − σ ∣ v x y c m d − v x y ∣ 2 2 ) \exp(-\sigma|v_{xy}^{cmd}-v_{xy}|_{2}^{2}) exp(−σ∣vxycmd−vxy∣22) | 1.0 / 2.0 1.0/2.0 1.0/2.0 |
| Ang. velocity tracking | $\exp(-\sigma | \omega_{z}^{cmd}-\omega_{z} |
| Lin. velocity (z) | v z 2 v_{z}^{2} vz2 | -2.0 |
| Ang. velocity ( x y ) (xy) (xy) | ∣ ω x y ∣ 2 2 |\omega_{xy}|_{2}^{2} ∣ωxy∣22 | -0.05 |
| Joint acceleration | ∣ q ¨ ∣ 2 2 |\ddot{q}|_{2}^{2} ∣q¨∣22 | − 2.5 × 10 − 7 -2.5\times10^{-7} −2.5×10−7 |
| Joint power | $ | \tau\cdot\dot{q} |
| Joint torque | ∣ τ ∣ 2 2 |\tau|_{2}^{2} ∣τ∣22 | − 1 × 10 − 4 -1\times10^{-4} −1×10−4 |
| Base height | ( h d e s − h ) 2 (h^{des}-h)^{2} (hdes−h)2 | -1.0 |
| Action rate | ∣ a t − a t − 1 ∣ 2 2 |a_{t}-a_{t-1}|_{2}^{2} ∣at−at−1∣22 | -0.01 |
| Action smoothness | ∣ a t − 2 a t − 1 + a t − 2 ∣ 2 2 |a_{t}-2a_{t-1}+a_{t-2}|_{2}^{2} ∣at−2at−1+at−2∣22 | -0.01 |
| Collision | n c o l l i s i o n n_{collision} ncollision | -1.0 |
| Joint limit | I l i m i t a t i o n I_{limitation} Ilimitation | -2.0 |
| Foot regulation | -0.05 | |
| Hip regulation | ∣ q h i p − q d e f a u l t h i p ∣ |q^{hip}-q_{default}^{hip}| ∣qhip−qdefaulthip∣ | -0.05 |
| Hip symmetry | r h s r^{hs} rhs | -1 |
| 黑色:多地形模型使用的奖励项。 | ||
| 红色:平地高速模型修改后的权重。 |
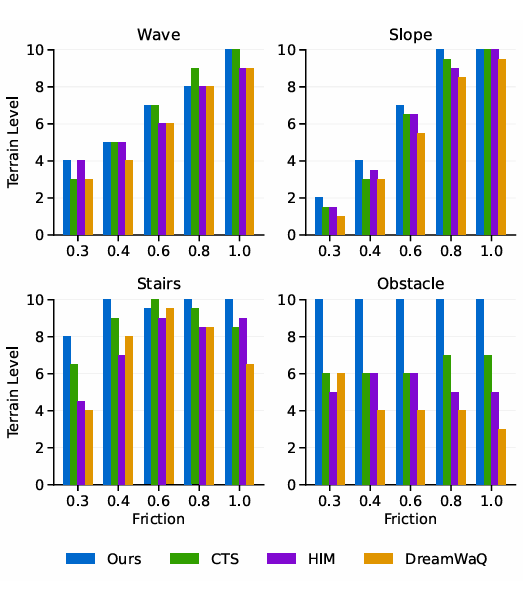
图14:在部分摩擦系数子集(从0.2到1.0,增量为0.1)下,各种模型达到的最大地形难度级别。
表 X:跨地形的最大速度跟踪系数和指令限制
| Terrain Type | σ m a x T i \sigma_{max}^{T_i} σmaxTi | v x [ m / s ] v_x [m/s] vx[m/s] | v y [ m / s ] v_y [m/s] vy[m/s] | ω z [ r a d / s ] \omega_z [rad/s] ωz[rad/s] |
|---|---|---|---|---|
| Flat | 1 / 4 1/4 1/4 | ± 2.0 \pm2.0 ±2.0 | ± 1.0 \pm1.0 ±1.0 | ± 2.0 \pm2.0 ±2.0 |
| Wave | 5 / 12 5/12 5/12 | ± 1.5 \pm1.5 ±1.5 | ± 1.0 \pm1.0 ±1.0 | ± 1.5 \pm1.5 ±1.5 |
| Slope | 1 / 4 1/4 1/4 | ± 1.5 \pm1.5 ±1.5 | ± 1.0 \pm1.0 ±1.0 | ± 1.5 \pm1.5 ±1.5 |
| Stairs Up | 1 / 2 1/2 1/2 | ± 1.0 \pm1.0 ±1.0 | ± 1.0 \pm1.0 ±1.0 | ± 1.5 \pm1.5 ±1.5 |
| Stairs Down | 1 / 2 1/2 1/2 | ± 1.0 \pm1.0 ±1.0 | ± 1.0 \pm1.0 ±1.0 | ± 1.5 \pm1.5 ±1.5 |
| Obstacle | 3 / 4 3/4 3/4 | ± 1.0 \pm1.0 ±1.0 | ± 1.0 \pm1.0 ±1.0 | ± 1.5 \pm1.5 ±1.5 |
| 注:速度范围定义为 v l i n ∈ [ 0.5 , 1.5 ] m / s v^{lin}\in[0.5,1.5]m/s vlin∈[0.5,1.5]m/s 和 v a n g ∈ [ 1.0 , 2.0 ] r a d / s v^{ang}\in[1.0,2.0]rad/s vang∈[1.0,2.0]rad/s。 |
表 XI:指令课程阶段和速度限制
| Stage | Training Steps | v x [ m / s ] v_{x} [m/s] vx[m/s] | v y [ m / s ] v_{y} [m/s] vy[m/s] | ω z [ r a d / s ] \omega_{z} [rad/s] ωz[rad/s] |
|---|---|---|---|---|
| Initial | [ 0 , 2 × 10 4 ] [0,2\times10^{4}] [0,2×104] | ± 0.5 \pm0.5 ±0.5 | ± 0.5 \pm0.5 ±0.5 | ± 1.0 \pm1.0 ±1.0 |
| Intermediate | ( 2 × 10 4 , 5 × 10 4 ] (2\times10^{4},5\times10^{4}] (2×104,5×104] | ± 1.0 \pm1.0 ±1.0 | ± 1.0 \pm1.0 ±1.0 | ± 1.5 \pm1.5 ±1.5 |
| Advanced | ( 5 × 10 4 , ∞ ] (5\times10^{4},\infty] (5×104,∞] | ± 2.0 \pm2.0 ±2.0 | ± 1.0 \pm1.0 ±1.0 | ± 2.0 \pm2.0 ±2.0 |
附录 D 补充实验
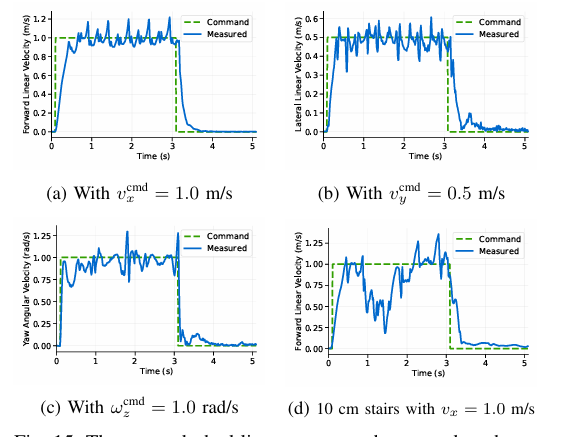
图15:绿色虚线表示由动作捕捉系统以90 Hz的采样频率测量的真实世界速度,而蓝色实线表示通过预定义的评估程序自动传输到Unitree Go2的对应目标指令值。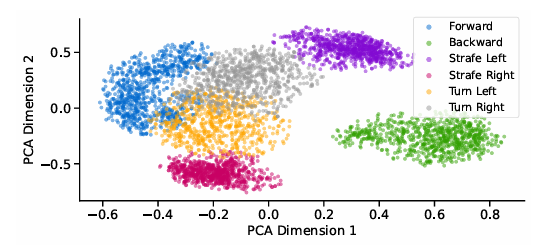
图16:不同指令在所有地形下学生编码器潜在空间的PCA可视化。
图17:Unitree Go2在三个挑战性场景中的运动性能。顶部图片展示了机器人在80N到100N的侧向冲量下保持平衡。左下图片描绘了在 μ = 0.38 \mu=0.38 μ=0.38 的15.5厘米瓷砖楼梯上的稳定攀登。右下图片展示了在 μ = 0.85 \mu=0.85 μ=0.85 时成功翻越30厘米障碍物。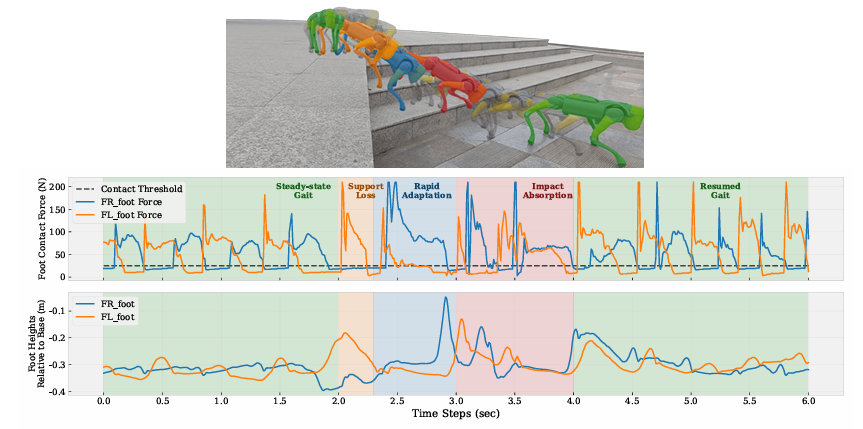
图18:顶板显示当边缘地面结束时,机器人迅速调整姿势以安全下降。中间的图描绘了足部传感器测量到的接触力信号。底图说明了通过正向运动学计算出的相对于机座的前脚高度。这些结果证实了策略的鲁棒性及其在应对各种挑战时进行自适应步态过渡的能力。
表 XII:综合评估:真实世界测量值、预测值与绝对误差
| Source | Movement | Lin. Trk. | Ang. Trk. | DOF Power | DOF Limits | Orient. | Smooth. |
|---|---|---|---|---|---|---|---|
| Real (Ground Truth) | Linear ( x = 1 ) (x=1) (x=1) | 0.9185 | 0.5808 | 0.8527 | 0.9159 | 0.9675 | 0.7739 |
| Lateral ( y = 0.5 ) (y=0.5) (y=0.5) | 0.9552 | 0.7037 | 0.9696 | 0.9384 | 0.9661 | 0.8985 | |
| Angular ( z = 1 ) (z=1) (z=1) | 0.9552 | 0.8010 | 0.9659 | 0.9439 | 0.9614 | 0.9020 | |
| Stairs ( x = 1 ) (x=1) (x=1) | 0.8554 | 0.2732 | 0.6721 | 0.8395 | 0.8749 | 0.5944 | |
| RoboGauge (Predicted) | Linear ( x = 1 ) (x=1) (x=1) | 0.8217 | 0.5669 | 0.8330 | 0.9386 | 0.9592 | 0.7853 |
| Lateral ( y = 0.5 ) (y=0.5) (y=0.5) | 0.8685 | 0.6822 | 0.9704 | 0.9293 | 0.9627 | 0.8861 | |
| Angular ( z = 1 ) (z=1) (z=1) | 0.8763 | 0.7679 | 0.9734 | 0.9414 | 0.9647 | 0.8983 | |
| Stairs ( x = 1 ) (x=1) (x=1) | 0.7596 | 0.2507 | 0.6211 | 0.8472 | 0.8625 | 0.6606 | |
| RoboGauge (Ours) (Abs. Error)↓ | x = 1 x=1 x=1 (Merge) | 0.0963 | 0.0182 | 0.0354 | 0.0152 | 0.0103 | 0.0388 |
| Average | 0.0873 | 0.0243 | 0.0145 | 0.0089 | 0.0057 | 0.0183 | |
| IsaacGym (Predicted) | Linear ( x = 1 ) (x=1) (x=1) | 0.8977 | 0.7826 | 0.9155 | 0.9361 | 0.9737 | 0.8289 |
| Lateral ( y = 0.5 ) (y=0.5) (y=0.5) | 0.9694 | 0.8039 | 0.9598 | 0.9378 | 0.9707 | 0.8781 | |
| Angular ( z = 1 ) (z=1) (z=1) | 0.9853 | 0.9134 | 0.9751 | 0.9325 | 0.9798 | 0.9510 | |
| Stairs ( x = 1 ) (x=1) (x=1) | 0.8786 | 0.5732 | 0.8635 | 0.9027 | 0.9339 | 0.7454 | |
| IsaacGym (Abs. Error)↓ | x = 1 x=1 x=1 (Merge) | 0.0220 | 0.2509 | 0.1271 | 0.0417 | 0.0326 | 0.1030 |
| Average | 0.0221 | 0.1545 | 0.0487 | 0.0179 | 0.0185 | 0.0575 |
表 XIII:RoboGauge下基线的详细指标
| Model | mean | ang vel err mean@25 | mean@50 | mean | lin vel err mean@25 | mean@50 | mean | dof limits mean@25 | mean@50 | mean | dof power mean@25 | mean@50 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Our | 0.7018 | 0.6431 | 0.6047 | 0.7394 | 0.6497 | 0.6908 | 0.8139 | 0.8029 | 0.8073 | 0.7889 | 0.7411 | 0.7642 |
| CTS | 0.6231 | 0.5632 | 0.5253 | 0.6464 | 0.5363 | 0.5878 | 0.7341 | 0.7232 | 0.7275 | 0.7113 | 0.6607 | 0.6856 |
| HIM | 0.5652 | 0.5025 | 0.4620 | 0.6297 | 0.5443 | 0.5881 | 0.6781 | 0.6645 | 0.6699 | 0.6529 | 0.5996 | 0.6253 |
| DreamWaQ | 0.5309 | 0.4305 | 0.4698 | 0.5937 | 0.5060 | 0.5512 | 0.6437 | 0.6307 | 0.6360 | 0.6200 | 0.5939 | 0.5690 |
(表 XIII 续)
| Model | mean | orientation stability mean@25 | mean@50 | mean | torque smoothness mean@25 | mean@50 | mean | zmp margin mean@25 | mean@50 | mean | friction margin mean@25 | mean@50 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Our | 0.8147 | 0.7946 | 0.8040 | 0.7734 | 0.7400 | 0.7535 | 0.7933 | 0.7401 | 0.7653 | 0.6892 | 0.6340 | 0.6051 |
| CTS | 0.7346 | 0.7232 | 0.7124 | 0.6954 | 0.6594 | 0.6744 | 0.7163 | 0.6670 | 0.6900 | 0.6188 | 0.5310 | 0.5622 |
| HIM | 0.6780 | 0.6497 | 0.6643 | 0.6416 | 0.6053 | 0.6201 | 0.6604 | 0.6092 | 0.6344 | 0.5544 | 0.5014 | 0.4706 |
| DreamWaQ | 0.6443 | 0.6312 | 0.6170 | 0.6060 | 0.5709 | 0.5853 | 0.6290 | 0.5814 | 0.6049 | 0.5236 | 0.4706 | 0.4392 |
表 XIV:RoboGauge下基线的详细地形得分
| Model | flat mean@25 | mean@50 | mean | wave mean@25 | mean@50 | mean | slope forward mean@25 | mean@50 | slope backward mean@25 | mean@50 | mean |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Our | 0.7549 | 0.5594 | 0.6629 | 0.6152 | 0.5416 | 0.5785 | 0.5831 | 0.5194 | 0.5514 | 0.5530 | 0.5216 |
| CTS | 0.4361 | 0.7211 | 0.5923 | 0.6017 | 0.5255 | 0.5575 | 0.5615 | 0.4884 | 0.5213 | 0.4909 | 0.4583 |
| HIM | 0.7387 | 0.6210 | 0.4860 | 0.4904 | 0.5693 | 0.5324 | 0.4924 | 0.4247 | 0.4574 | 0.5714 | 0.5042 |
| DreamWaQ | 0.7363 | 0.4854 | 0.6196 | 0.4581 | 0.5249 | 0.4908 | 0.4043 | 0.3425 | 0.3733 | 0.5368 | 0.5334 |
(表 XIV 续)
| Model | stairs forward mean@25 | mean@50 | mean | stairs backward mean@25 | mean@50 | mean | obstacle mean@25 | mean@50 |
|---|---|---|---|---|---|---|---|---|
| Our | 0.8255 | 0.7431 | 0.7910 | 0.7748 | 0.7102 | 0.7438 | 0.8825 | 0.7988 |
| CTS | 0.7992 | 0.7217 | 0.6658 | 0.7457 | 0.5865 | 0.6170 | 0.5692 | 0.4829 |
| HIM | 0.5602 | 0.4857 | 0.7352 | 0.5143 | 0.6629 | 0.6929 | 0.4599 | 0.4184 |
| DreamWaQ | 0.5884 | 0.5152 | 0.6804 | 0.5421 | 0.6022 | 0.6333 | 0.3547 | 0.2799 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)