▲基于RBF-Q学习的四足机器人运动协调控制算法matlab仿真
目录
1.引言
四足机器人因其出色的地形适应能力和负载能力,在灾难救援、星球探测等领域具有广阔的应用前景。四足机器人的运动协调控制是实现稳定行走的核心问题,其本质是要求四条腿在时间和空间上按照特定的步态规律协调运动,使得每条腿的足端能精确跟踪给定的理想轨迹(包括位移轨迹和速度轨迹),从而实现机器人的平稳前进。
传统的四足机器人控制方法(如PID控制、计算力矩法等)依赖于精确的动力学模型,而四足机器人具有多自由度、强耦合、非线性等特性,精确建模十分困难。强化学习方法可以在不需要精确动力学模型的前提下,通过与环境的交互学习最优控制策略。然而,经典的Q学习采用表格形式存储Q值,面对连续状态空间时存在严重的"维数灾难"问题。为解决这一问题,本文将径向基函数(Radial Basis Function, RBF)神经网络与Q学习相结合,利用RBF网络强大的函数逼近能力来近似Q值函数,从而实现对四足机器人连续状态-动作空间下运动协调控制策略的学习。
2.四足机器人运动学模型
2.1 腿部结构与坐标系
四足机器人每条腿通常采用三自由度结构,包含髋关节(Hip)、大腿关节(Thigh)和小腿关节(Shank),各关节角分别记为θ1、θ2、θ3。设大腿连杆长度为l1,小腿连杆长度为l2,髋关节横向偏移为l0。以髋关节为原点建立坐标系,足端在腿坐标系下的位置可通过正运动学关系求得:
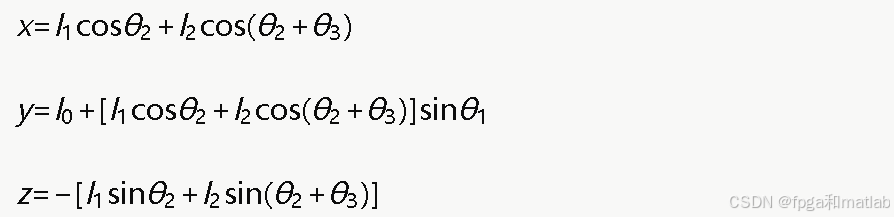
2.2 足端理想轨迹规划
四足机器人通常采用对角步态(trot gait)行走,即对角线上的两条腿同时摆动,另外两条腿支撑。足端在一个完整步态周期T内的理想轨迹分为摆动相和支撑相两部分。设步长为S,抬腿高度为H,采用复合摆线规划摆动相轨迹:

3.RBF-Q学习算法原理
3.1 Q学习基本框架
Q学习是一种无模型(model-free)的强化学习方法。智能体在状态 s下执行动作a,环境返回即时奖励r并转移到新状态s′。Q学习的目标是学习最优动作值函数Q∗(s,a),使得在每个状态下选择使Q值最大的动作即为最优策略。经典Q学习的更新规则为:

3.2 RBF神经网络结构
RBF神经网络是一种三层前馈网络,包含输入层、隐含层和输出层。输入层节点直接将输入向量传递到隐含层;隐含层采用径向基函数作为激活函数;输出层为隐含层输出的线性加权和。设网络输入为x∈Rn,隐含层有m个节点,第j个隐含层节点的输出为:

3.3 RBF网络逼近Q值函数
将状态和动作联合编码为RBF网络的输入。对于每个离散动作ak(k=1,2,…,K),维护一个独立的RBF网络(或等价地,维护一组独立的权重向量wk),则动作值函数的近似为:
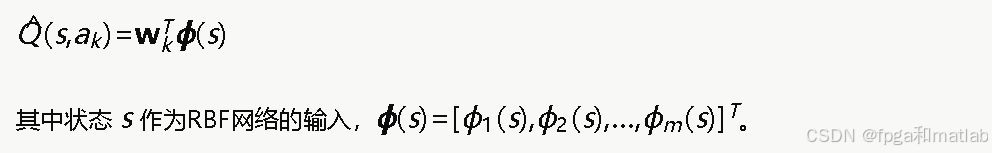
3.4 权重更新规则
利用梯度下降法最小化TD误差的平方来更新RBF网络权重。定义损失函数为:

4.状态空间、动作空间与奖励函数设计
4.1 状态空间定义
四足机器人每条腿的控制状态定义为足端位置跟踪误差和速度跟踪误差:

4.2 动作空间定义
动作空间定义为各关节的力矩增量Δτ,将连续动作空间离散化为K个离散动作。每个动作对应关节力矩的一种调整组合:

4.3 奖励函数设计
奖励函数的设计应引导机器人足端精确跟踪理想轨迹,同时惩罚过大的控制力矩和不稳定行为。综合奖励函数设计为:

4.4 环境交互
机器人执行所选动作后,系统按照简化动力学方程演化:

观测新状态s′并计算即时奖励r。
5.四条腿的协调机制
四足机器人采用对角步态时,四条腿的相位关系为:
![]()
其中LF、RH、RF、LH分别表示左前、右后、右前、左后腿。每条腿使用独立的RBF-Q学习控制器,但共享相同的网络结构和训练好的权重参数(因为每条腿的结构相同)。各腿控制器的输入根据各自的步态相位计算对应的理想轨迹和跟踪误差。通过这种方式,每条腿独立跟踪其时间偏移后的理想轨迹,自然实现四条腿之间的协调配合。
6.MATLAB程序
........................................................
for frame = 1:frame_skip:n_frames
clf;
t = t_vec(frame);
% 机身中心位置
body_cx = body_advance(frame);
body_cy = 0;
body_cz = z0;
% 机身顶点 (长方体)
bx = body_cx + [-1 1 1 -1 -1 1 1 -1]*body_L/2;
by = body_cy + [-1 -1 1 1 -1 -1 1 1]*body_W/2;
bz = body_cz + [-1 -1 -1 -1 1 1 1 1]*body_H/2;
% 绘制机身
faces = [1 2 3 4; 5 6 7 8; 1 2 6 5; 3 4 8 7; 1 4 8 5; 2 3 7 6];
patch('Vertices', [bx', by', bz'], 'Faces', faces, ...
'FaceColor', [0.3, 0.5, 0.8], 'FaceAlpha', 0.7, 'EdgeColor', 'k', 'LineWidth', 1.5);
hold on;
% 绘制四条腿
leg_colors = {'b', 'r', [0 0.7 0], 'm'};
for i = 1:4
% 髋关节世界坐标
hip_x = body_cx + hip_pos(i,1);
hip_y = body_cy + hip_pos(i,2);
hip_z = body_cz - body_H/2;
% 足端世界坐标
foot_x = hip_x + leg_x(i, frame);
foot_y = hip_y;
foot_z = hip_z + leg_z(i, frame) + z0 * 0.15;
% 计算膝关节位置(简化为中点偏移)
knee_x = (hip_x + foot_x) / 2;
knee_y = hip_y;
knee_z = (hip_z + foot_z) / 2 + 0.03;
% 画大腿
plot3([hip_x, knee_x], [hip_y, knee_y], [hip_z, knee_z], ...
'Color', leg_colors{i}, 'LineWidth', 3);
% 画小腿
plot3([knee_x, foot_x], [knee_y, foot_y], [knee_z, foot_z], ...
'Color', leg_colors{i}, 'LineWidth', 3);
% 关节点
plot3(hip_x, hip_y, hip_z, 'ko', 'MarkerSize', 6, 'MarkerFaceColor', 'k');
plot3(knee_x, knee_y, knee_z, 'ko', 'MarkerSize', 5, 'MarkerFaceColor', leg_colors{i});
plot3(foot_x, foot_y, foot_z, 'ko', 'MarkerSize', 6, 'MarkerFaceColor', 'y');
end
end
fprintf('动画播放完毕!\n');
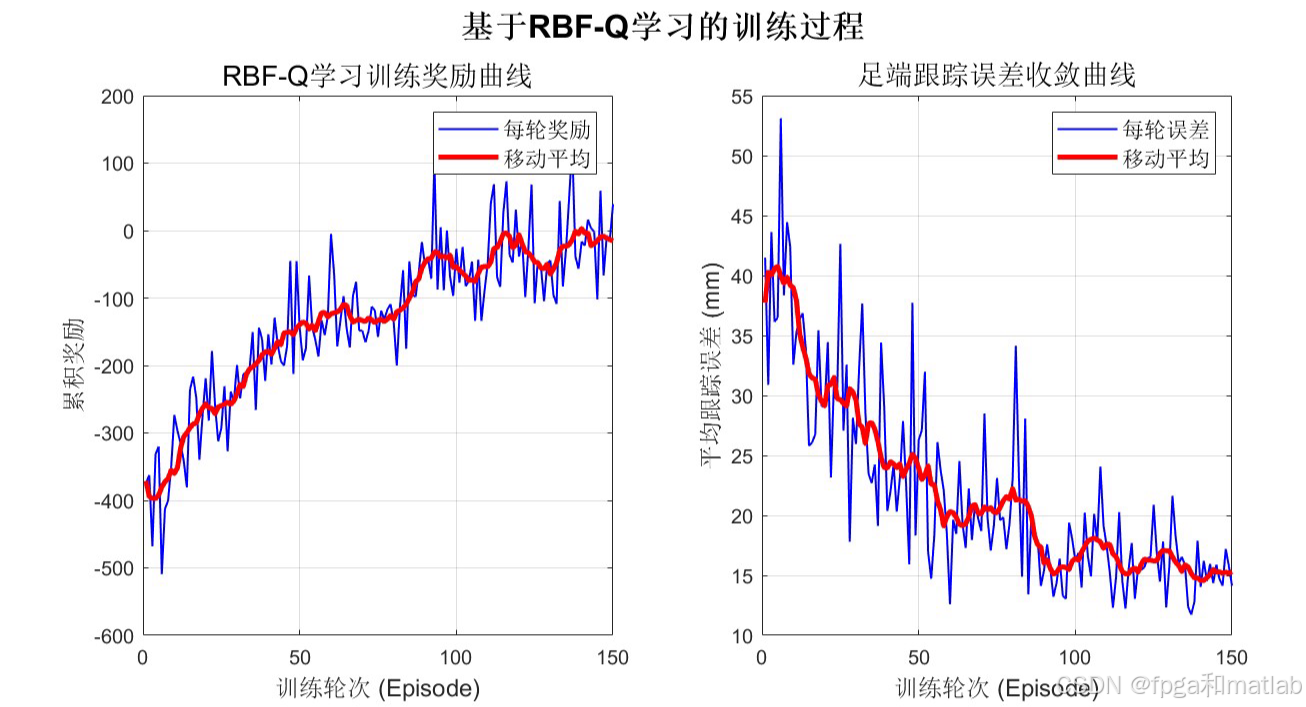
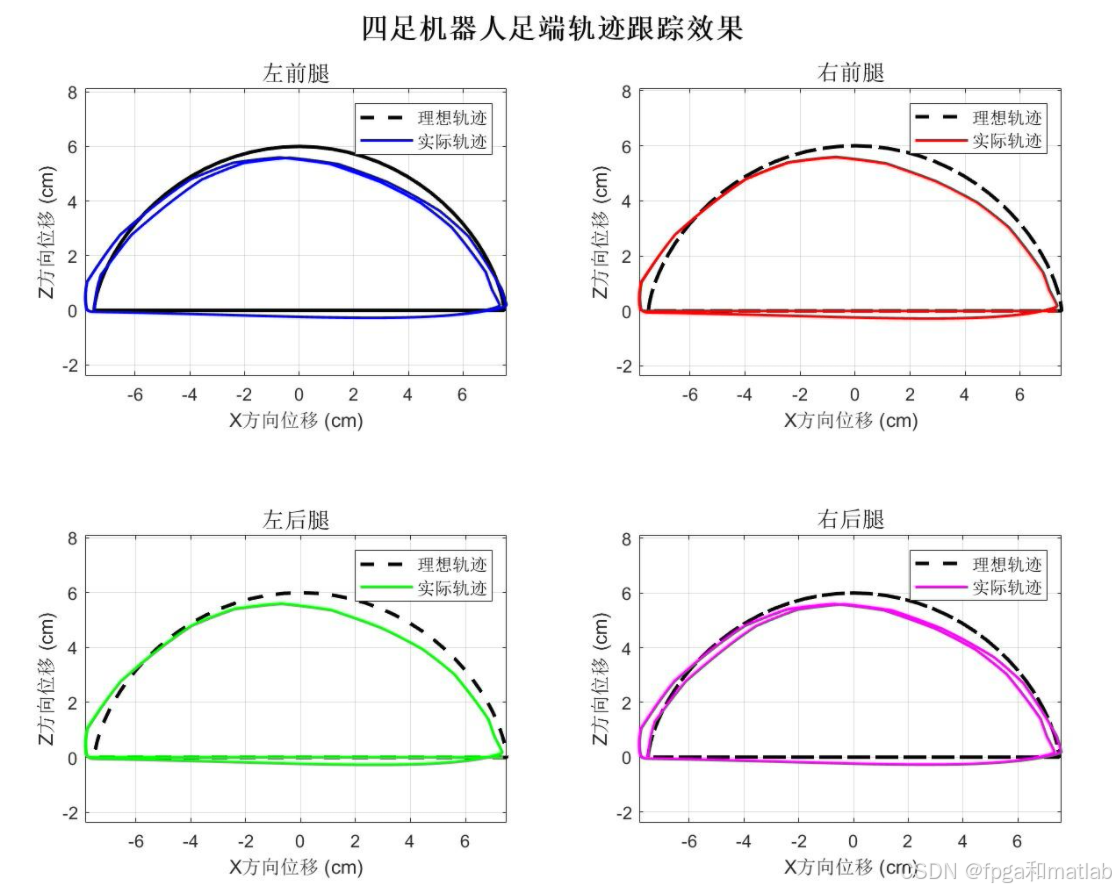
7.仿真结果分析
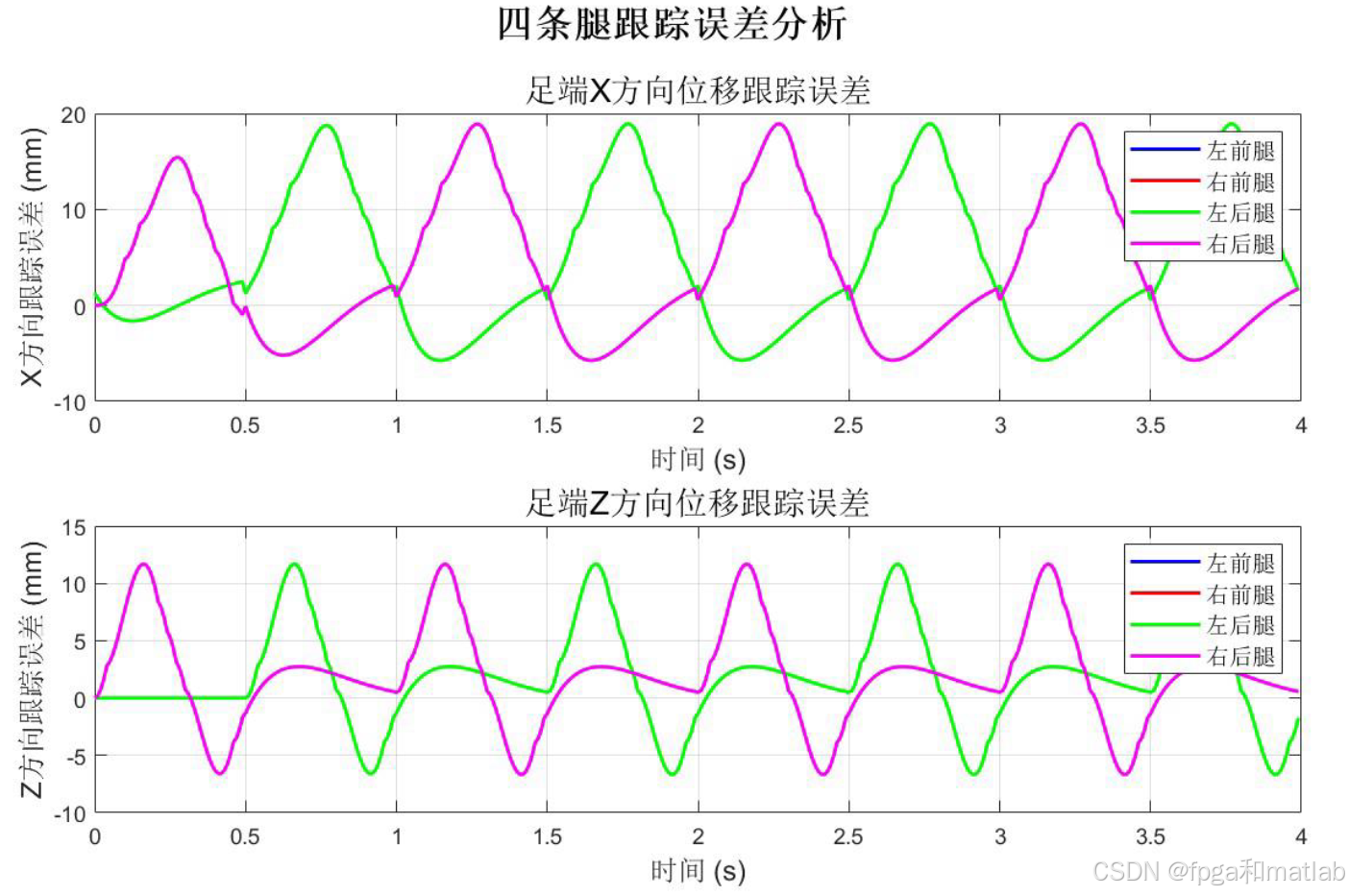
8.完整程序下载
完整可运行代码,博主已上传至CSDN,使用版本为MATLAB2024b:
(本程序包含程序操作步骤视频)
基于RBF-Q学习的四足机器人运动协调控制算法matlab仿真【包括程序,中文注释,程序操作和讲解视频】资源-CSDN下载

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)