MEM——解决VLA长时记忆问题的框架:短时靠高效视频编码抓细节,长线凭文本记忆系统记进度
前言
著名具身公司PI发布的每一篇论文基本都是具身开发者 必看的,特别是对于讲究实用落地效果而言的我司
- 更何况PI公司发布的视频具备相对高的真实度,毕竟会开源部分模型的权重供验证,以及充满详细技术细节的技术报告或paper供研究
- 这点比某些执着于拍“影视宣传片”的部分公司强多了(部分公司为了融资或忽悠客户,无所不用其极,比如明明是遥操 非得说是自主,明明是多段剪辑 非得说全流程无人工干预)
——
我司七月坚持:在目前具身的两个急迫点(一方面 技术亟待突破;二方面 亟需真正实用落地)下,真实尤为可贵(如果是遥操 一定把遥操打到公屏上,如果是自主才明确自主,永远实事求是)
毕竟我司是要实际落地、实际交付的,故一味夸张/修饰 没有任何意义
如MEM原论文所说,传统上,端到端机器人学习中的记忆是指将过去观测序列输入到已学习的策略中,然而,在复杂的多阶段真实世界任务中,机器人的记忆必须以多种粒度表示过去事件(字体颜色上,用长蓝、短绿以示区分):
- 捕捉抽象语义概念的长期记忆(例如,做饭的机器人应记住菜谱中已经完成的步骤)
- 捕捉近期事件并补偿遮挡的短期记忆(例如,当机械臂将目标物体遮挡住后,机器人仍能记得它想要抓取的物体)
在本文中,PI公司的核心见解是:面向长时间尺度机器人控制的有效记忆架构应当融合多种模态,以刻画这些不同层级的抽象
- 对此,他们提出了 Multi-ScaleEmbodied Memory (MEM),一种用于机器人策略的混合模态长时记忆方法
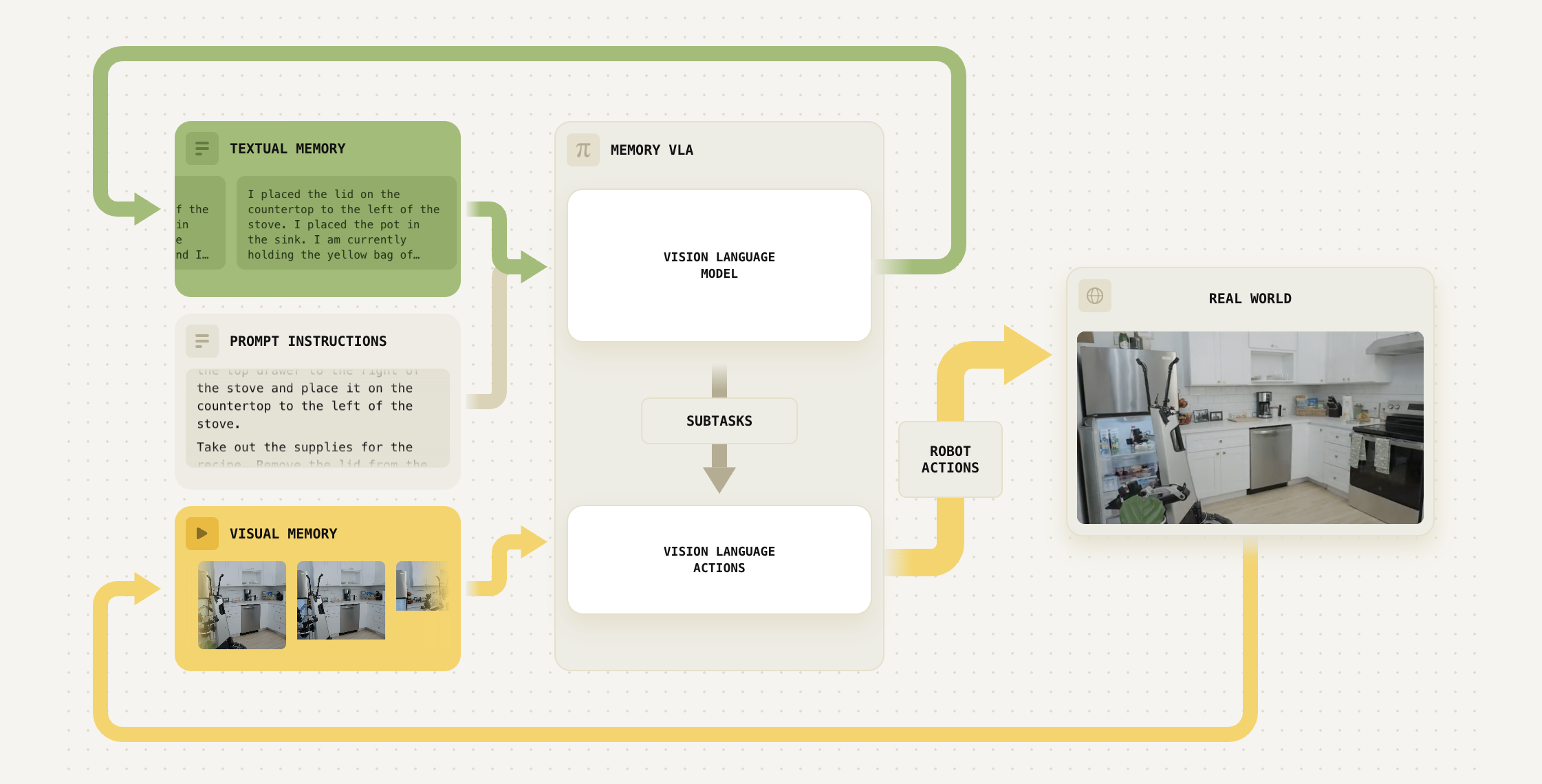
- MEM 将通过视频编码器压缩的视频模态短时记忆,与基于文本的长时记忆结合起来。二者结合,使机器人策略能够执行时长可达十五分钟的任务,例如整理厨房或制作烤奶酪三明治
毕竟机器人可能需要详细记住最近发生的事件,也可能需要长期记忆,例如记住厨房的哪个部分已经清洁过
将所有这些记忆以原始图像的形式塞进模型中是不切实际的,尤其是在需要实时控制的情况下
简言之,短平快的物理动作靠短视频帧,长线宏观的任务进度靠文本总结
第一部分 MEM: Multi-Scale Embodied Memory forVision Language Action Models
1.1 引言与相关工作
1.1.1 引言
如原论文所述,高效且有效地为机器人策略赋予记忆能力需要多个层次的抽象。虽然原则上可以简单地将过去观测的整个序列编码进策略的上下文中,但对于长时任务,这将变得难以处理,从而不得不采用非常短的序列或进行大幅度的子采样
然而,在实际场景中,用于长期和短期记忆的表征很可能是截然不同的。例如(字体颜色上,用长蓝、短绿以示区分)
- 机器人可能需要记住一次最近的观测来处理遮挡问题
- 也可能需要记住在烹饪时它已经加入过某一种配料
但这两类记忆在本质上是不同的:前者可能需要在较短时间窗口内存储若干图像,后者则可能只需要极少量比特的信息却要跨较长时间范围保留
一种高效的机器人策略记忆架构应当使用多种模态,在不同抽象层级上表示这些记忆
- 对于短时记忆而言,稠密的基于图像的记忆非常适合用于解决遮挡问题,并且允许使机器人能够快速适应其操作策略,例如在未能抓起物体之后通过改变抓取方式进行调整
- 对于长时间跨度的记忆,往往只需要在语义层面跟踪事件,例如某道菜中哪些配料已经被加入
在这种情况下,基于语言的表示相比原始观测能够提供更好的压缩效果,并允许在较长时间范围内存储高层次的记忆
基于这些观察,来自PI的研究者提出多尺度具身记忆(Multi-Scale Embodied Memory,MEM),一个用于为策略配备多模态、长时程记忆的系统
具体而言
- 首先,采用视频编码器架构,将持续数秒的稠密图像记忆有效编码为紧凑的表示
- 其次,引入了一种基于语言的记忆机制,在该机制中,策略以压缩的语言格式跟踪语义事件
该记忆系统不仅可以适配时间跨度极长的任务,还能够通过利用短期记忆带来多种新能力,例如基于上下文的自适应以纠正错误,以及在部分可观测和自遮挡情况下保持鲁棒性
1.1.2 相关工作
首先,对于具备记忆的视觉-语言-动作模型
- 最近的工作表明,在大量多样化机器人经验上训练得到的机器人控制策略,可以带来具备泛化能力的操作能力,例如在未见过的环境中
19-π0.5
18-π0
43-Gemini robotics 1.5
46-A careful examination of large behavior models for multitask dexterous manipulation
31-Gr00t n1
52-World action models are zero-shot policies,探讨了世界动作模型(World action models)作为零样本策略的应用
视觉-语言-动作模型VLA
15-Palm-e
8-Rt-2
33-Open X
32-Octo
13-Scaling cross-embodied learning: One policy for manipulation, navigation, locomotion and aviation
22-Openvla
5-π0
49-Tinyvla
54-3d-vla
2-Minivla
41-From multimodal llms to generalist embodied agents: Methods and lessons
34-Fast_π0
44-Gemini robotics: Bringing ai into the physical world,探讨了 Gemini 机器人技术如何将人工智能切实引入物理世界
50-Dexvla
4-Gr00t n1
51-A pragmatic vla foundation model
45-Gigabrain-0.5M*,详见此文《GigaBrain-0.5M*(可对标π∗0.6)——从基于世界模型的RL中学习的VLA:通过“预测的价值和未来状态、经验数据、人工纠正”优化动作策略》
是训练此类通用策略的一种流行方法,其中先对视觉-语言模型进行预训练,然后再利用机器人经验对其进行微调
当今许多最先进的 VLA 是在无记忆的设置下训练的,仅基于对环境的当前观测来决策
22-Openvla
18-π0
19-π0.5
43-Gemini robotics 1.5
46-A careful examination of large behavior models for multitask dexterous manipulation
31- Gr00t n1
但越来越多的工作开始探索在策略训练中加入记忆,因为记忆是解决各类真实世界任务的核心需求 - 早期工作探索了带有循环记忆模块的架构
37-Vision-based multi-task manipulation for inexpensive robots using end-to-end learning from demonstration
28-What matters in learning from offline human demonstrations for robot manipulation
而更近期采用 transformer 架构的工作则只是将过去观测的稠密历史直接输入到策略中
38-Behavior transformers: Cloning k modes with one stone
23-Behavior generation with latent actions
32-Octo
然而,计算和时延约束使得将此类方法扩展到支持超长时程记忆变得颇具挑战
一些工作探索了潜在记忆结构
24-Cronusvla
39-Memoryvla,探讨了用于机器人操作的 VLA 模型中感知与认知记忆的引入
17-Sam2act
12-Rethinking progression of memory state in robotic manipulation: An object-centric perspective,从以物体为中心的视角出发,重新思考机器人操作任务中记忆状态的推进机制
但只在短时程记忆任务上进行了评估
还有一些工作提出了各种启发式方法来压缩记忆信息,例如仅依赖本体感觉记忆[53-Ta-vla: Elucidating the design space of torque-aware vision-language-action models,阐明了具备扭矩感知能力的视觉-语言-动作模型(Ta-vla)的设计空间]
55-Tracevla,探讨了视觉轨迹提示(Visual trace prompting)如何增强通用机器人策略的时空感知能力
9-History-aware visuomotor policy learning via point tracking,提出了一种通过点跟踪技术来进行具有历史感知的视觉运动策略学习方法
40-Memer: Scaling up memory for robot control via experience retrieval,介绍了一种通过经验检索机制来扩大机器人控制记忆容量的方法 Memer
48-Cycle-manip: Enabling cyclic task manipulation via effective historical perception and understanding,提出了通过有效历史感知和理解来实现循环任务操作的 Cycle-manip
29-Bpp: Long-context robot imitation learning by focusing on key history frames,研究了通过关注历史关键帧来进行包含长上下文的机器人模仿学习方法 Bpp
[26-Onetwovla]
————
所有这些方法面临的一个难题在于,很难为机器人记忆找到一种单一模态通用的解决方案,而每种单独的表征都会在能力上做出折中:
例如,仅使用本体感觉、点轨迹或自然语言,会丢失有关抓取角度和高度的精确空间信息,而这些信息对于纠正发生打滑的抓取是必需的
另一方面,关键帧则需要对观测历史进行大幅稀疏化,才能在长时程任务中使推理在计算上可行,但这可能会丧失估计环境和机器人动力学的能力,而这通常需要更密集采样的观测 - 与这些先前工作相比,作者提出了一种多模态记忆系统,将短时程、稠密的基于视觉的记忆与长时程、基于语言的记忆结合起来
这使作者能够解决部分可观测性问题、执行基于上下文的适应,并在不牺牲效率的前提下完成长时程任务
最后,一条正交的研究路线提出了一些方法来缓解因果混淆问题
11-Diffusion policy
55-Tracevla
即带记忆的策略会错误地学会简单复制先前的动作,例如通过引入辅助目标[47-Learning long-context diffusion policies via past-token prediction]
尽管类似的方法可以与作者的记忆系统结合使用,但作者宣称,他们的实验表明,在不使用此类目标的情况下也能获得很高的策略性能,这可能归因于他们使用了大规模且多样化的训练数据
其次,对于长上下文模型
- 除机器人领域之外,大量研究工作已经探索了长上下文语言模型和视觉-语言模型的训练
27-A comprehensive survey on long context language modeling
42-Video understanding with large language models: A survey,对结合大型语言模型进行视频理解的相关研究进行了综述
30-Expanding language-image pretrained models for general video recognition,研究了如何扩展语言-图像预训练模型,以适应通用的视频识别任务
特别是在视频处理背景下,已有丰富文献致力于为长视频输入设计高效的编码器
1-ViViT: A video vision transformer,详见此文《视频生成背后技术的全面解析:从AI绘画、ViT到ViViT、TECO、DiT、VDT、NaViT、Sora等》的2.2 ViViT:视频元素token化且时空编码——没加扩散过程、没带文本条件融合(21年5月)
3-Is space-time attention all you need for video understanding?,探讨了时空注意力机制在视频理解中的核心作用及充分性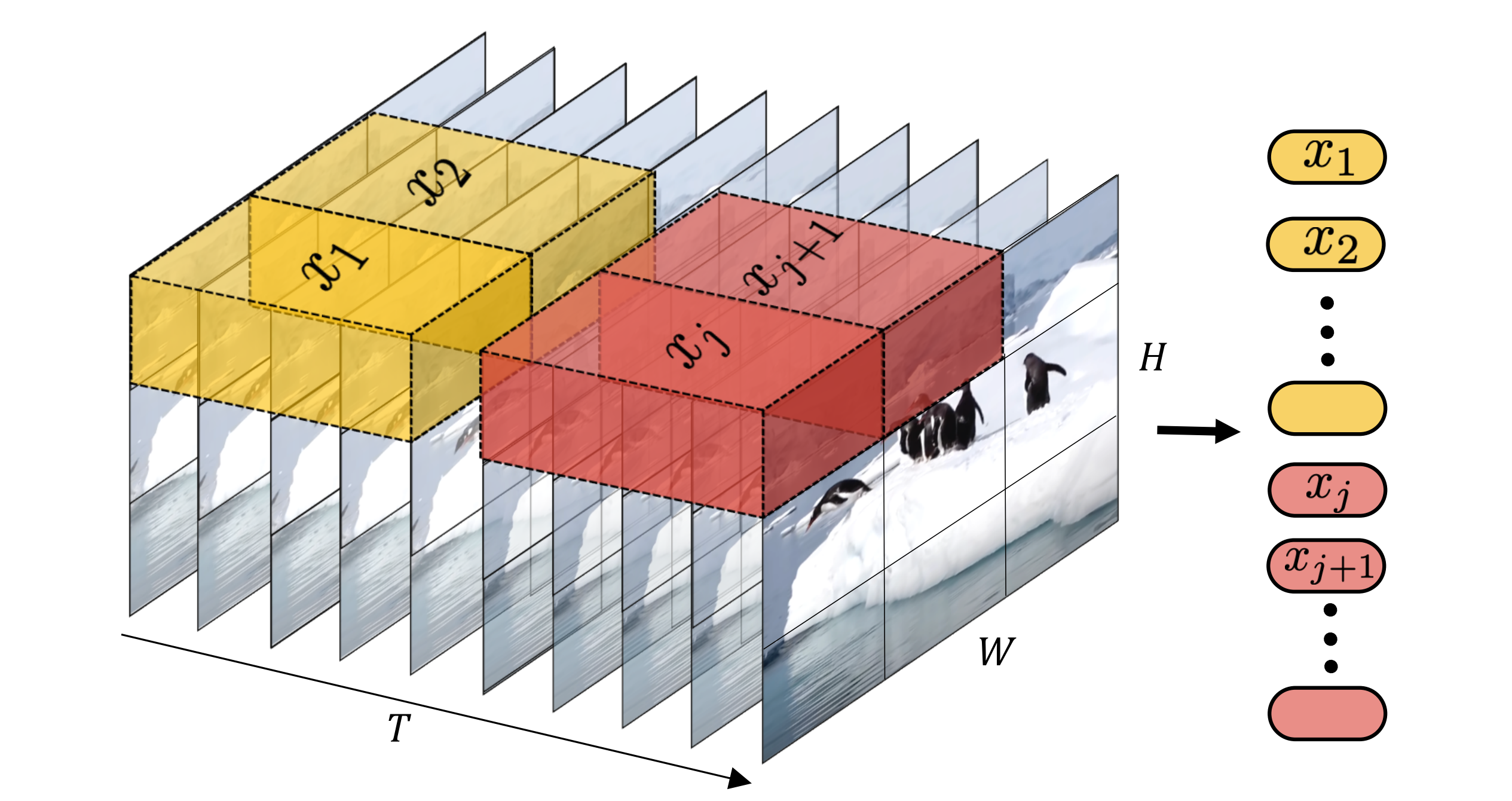
25-Videomamba: State space model for efficient video understanding,介绍了一种基于状态空间模型的高效视频理解方法 Videomamba - 作者的工作借鉴了 [3,1] 中的类似思想,使用稀疏注意力操作来高效处理视频输入
————
说白了,不是像ViViT那样 直接编码过长的图像帧,即视频编码器只编码较短的图像帧 用于短时记忆,而利用大模型总结超长步骤的文字以获取超长记忆
1.2 面向 VLA 的多尺度具身记忆
如原论文所述,对于需要决定下一步行动的机器人策略而言,相关的上下文往往跨越多个时间尺度(字体颜色上,用长蓝、短绿以示区分)
- 最新的时间步 有助于理解机器人和场景的动力学、解决自遮挡问题,并能快速调整诸如重新抓取之类的细粒度操作策略
- 另一方面,长时间跨度的记忆 则是理解例如菜谱中的哪些步骤已经完成、或者哪个子任务反复失败所必需的
理论上,这两种类型的上下文都可以通过将策略条件化在其先前所有观测组成的稠密序列上来提供
然而,对于持续数十分钟的任务来说,这很快就会变得不可行
作者在设计Multi-Scale Embodied Memory(MEM,多尺度具身记忆)时的目标,是同时实现高效的短期和长期记忆
- 对于短时间跨度的记忆,作者使用一种高效的视频编码器架构,使得能够将持续数秒的观测序列传递给策略,从而实现快速的上下文内自适应,并提高对自遮挡的鲁棒性
- 对于长时间跨度的记忆,作者设计了一种基于语言的记忆表示,并训练模型以自然语言在语义层面跟踪过去事件
通过这种方式,作者可以为策略配备长达 15 分钟的记忆,而不牺牲运行时延迟方面的约束
1.2.0 多尺度具身记忆(MEM)
图2 展示了作者的MEM 系统概览『MEM 内存系统通过两个关键组件,为像 π0.6 这样的 VLA 提供长时程记忆能力:(1) 通过更新语言记忆 (左图,第 III-B 节),训练一个高层策略来跟踪长时间跨度的语义事件;(2) 低层策略使用一种短时间跨度、基于观测的记忆,该记忆通过视频编码器进行高效编码(右图,第 III-C 节)』
作者的目标是训练一个策略,用于在给定自然语言任务目标
以及作为输入提供的一系列稠密观测(例如图像、本体感受状态)的条件下,预测一段连续的机器人动作片段
相比之下,大多数以往的VLA 仅仅条件化于单一观测,而作者希望策略能够处理多个(
) 观测
如上所述,要将过去观测的数量扩展到足以跨越数分钟、并从而充当一种长程记忆是不可行的。因此,作者将动作预测问题分解如下:
其中作者将动作的概率分解为低层策略 和高层策略
- 低层策略对在任务目标
、较短的观测序列(
),以及子任务指令
条件下的动作序列进行建模
- 反过来,子任务指令由高层策略生成,高层策略不仅以任务目标为条件,还以自然语言形式的前序语义事件的总结
为条件
————
下面将这一总结称为语言记忆。它使得能够在不牺牲对长达数分钟记忆进行建模能力的前提下,将输入到模型中的稠密观测数量显著减少到
而以往的工作采用了类似的划分为高层和低层策略并使用子任务指令作为接口的方法,其关键创新在于,还会基于自身先前的预测
1.2.1 面向长期记忆的语言记忆
语言记忆 是策略在执行任务过程中先前发生的语义事件的总结
其主要思想是训练高层策略,使其能够从先前的总结
以及当前的观测和任务中预测相关的总结
通过这种方式,模型可以显式地决定何时以及如何更新其记忆表征。比如,对于一个厨房清洁机器人来说,它已经将一个盘子放进了橱柜,并且刚刚完成拾起下一个碗,那么一次记忆更新可能如下所示
:我把一个盘子放进橱柜,走到操作台,并拿起一个碗
为了训练,作者需要获得合适的训练数据,其中包括希望高层策略采取的摘要动作
为此,作者开发了一条流水线,用于生成在 和
之间转换的训练数据,如下所示
- 给定一个具有子任务语言标注
的机器人episode,作者将子任务指令,与一个指示子任务执行是失败还是成功的token 一起输入到一个现成的预训练语言模型LLM中,并让它总结先前子任务中对于未来任务执行仍然相关的所有信息
————
本质上就是:子任务预测及子任务成功与否的标志,然后一块丢给大模型做摘要总结
『大模型做摘要总结可擅长了,我司在23年做论文审稿GPT时 便意识到了这一点,详见此文《七月论文审稿GPT第2版:用一万多条paper-review数据微调LLaMA2 7B最终反超GPT4》的3.2节 为了让模型对review的学习更有迹可循:归纳出来4个要点且多聚一』 - 收集相应的输出,并用其对序列进行标注,以训练高层策略
此外,重要的是,指示语言模型在适当的时候删除或压缩语言记忆中的信息
- 例如,与其记住所有被操作过对象的精确属性(“我把一个浅绿色碗、一个深蓝色碗和一个亮黄色碗放进了右上方的橱柜”)
通常只需要记住这些碗被放到哪里(“我在右上方的橱柜里放了三个碗”)就足够了- 对语言记忆进行压缩有助于使其保持简洁(从而推理更快),并降低训练与推理之间出现分布偏移的可能性,因为在各个时间步之间传递的信息比特更少
作者发现,当被提示仅保留最小集合的相关信息时,当前一代的大型语言模型(LLM)在这一任务上表现有效
1.2.2 用于稠密短期视觉记忆的视频编码器
为了使得策略能够推理细粒度细节与动态并解决自遮挡问题,需要将之前观测的稠密序列作为输入提供给该策略
- 在大多数 VLA 中,对观测进行编码(尤其是图像)占据了训练过程中计算量的最大部分,并且对推理速度有显著影响
因此,正如作者在图 3中所示『将一序列观测结果直接朴素地输入到 VLA 的主干网络,会迅速增加推理时延。作者高效的视频编码器架构使得能够使用大量观测帧,同时仍保持在关键的实时推理阈值 [6,7] 之下。时间测量基于 π0.6VLA,在一块NVIDIA H100 GPU 上接收四路输入相机流』
随着上下文超过少数时间步,仅仅将一串观测逐个编码后再输入到 VLA 主干网络中,会很快变得不可行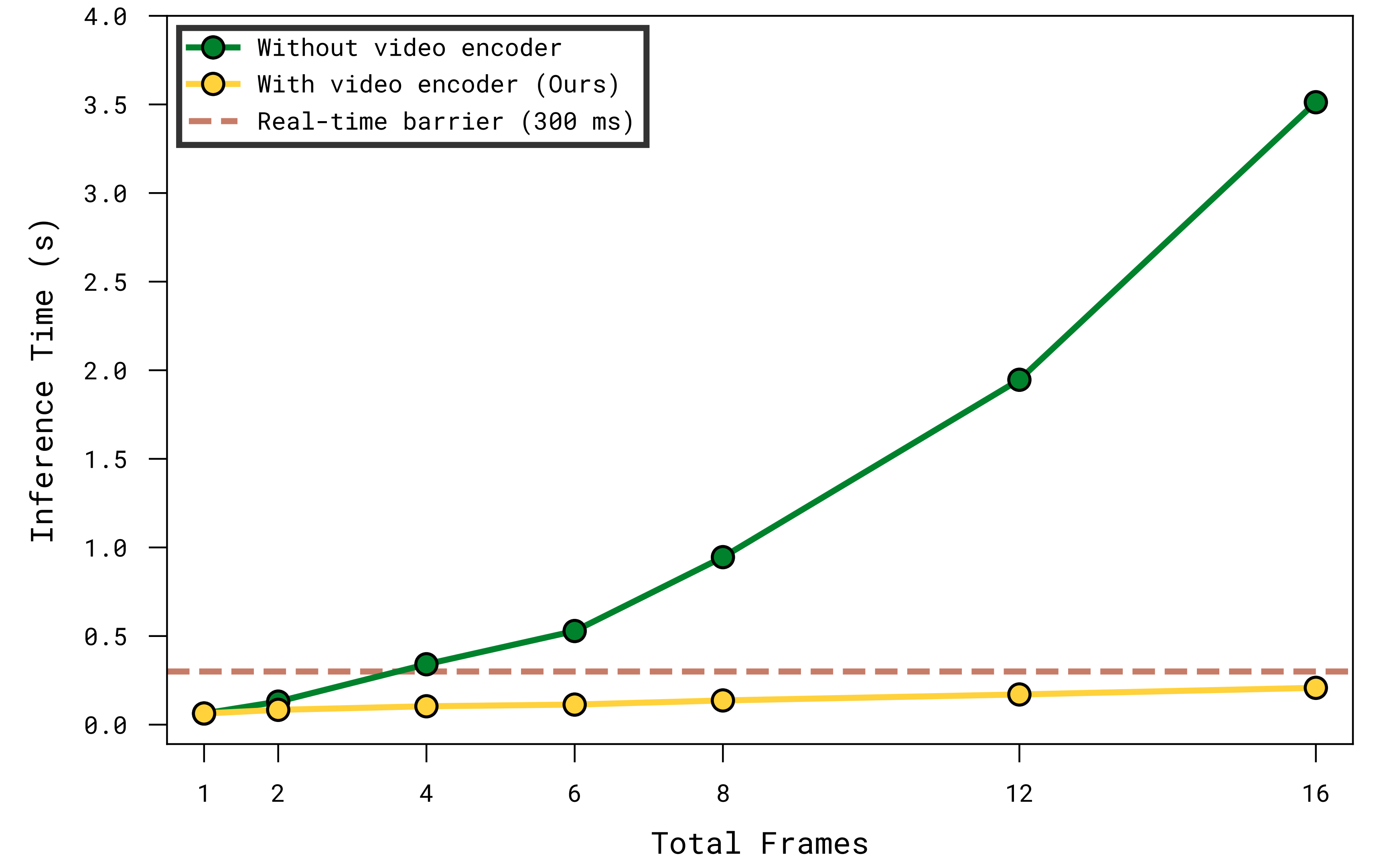
VLA 的推理时延将迅速超过先前工作所认为可接受的范围,从而难以避免在真实机器人上执行灵巧操作任务时的性能出现显著退化 [6,7] - 为了解决这一问题,作者提出使用一种视频编码器,在将编码传入 VLM 主干网络之前,先在时间维度上对视频帧进行压缩
作者的视频编码器将通常在大多数VLA 中用作视觉编码器的 Vision Transformer(ViT)[14] 扩展为能够对视频输入进行编码
重要的是,作者的编码器不会改变所使用的 VLM 在单幅图像上的性能,因此可以用来为任意预训练的 VLM 赋予高效(但计算开销很低)的视觉记忆能力
简言之,可视化示意见图4
即在用于编码视频输入的标准 ViT基础上进行扩展,通过交替堆叠两类层来实现:
- 一类是在每个观测内部施加双向空间注意力的层(白色箭头)
- 另一类是在此基础上,额外在不同观测之间施加因果时序注意力操作的层(黑色箭头)
且作者在 ViT 的高层中丢弃过去时间步的观测 token,从而压缩输入并减少传递给 VLA 主干网络的 token 数量
具体而言
- 修改注意力层而不是重头训练
ViTs以图像块为单位处理图像,并在多个层中反复对图像块嵌入进行双向注意力操作,以得出最终的一组输出嵌入,且作者保持相同的一般结构,视频编码器首先将输入视频中的所有图像分别切分为patch
受“现有用于视频理解的时空可分注意力工作”的启发(例如参见 Bertasius et al.[3- Is space-time attention all you need for video understanding?] 中的综述)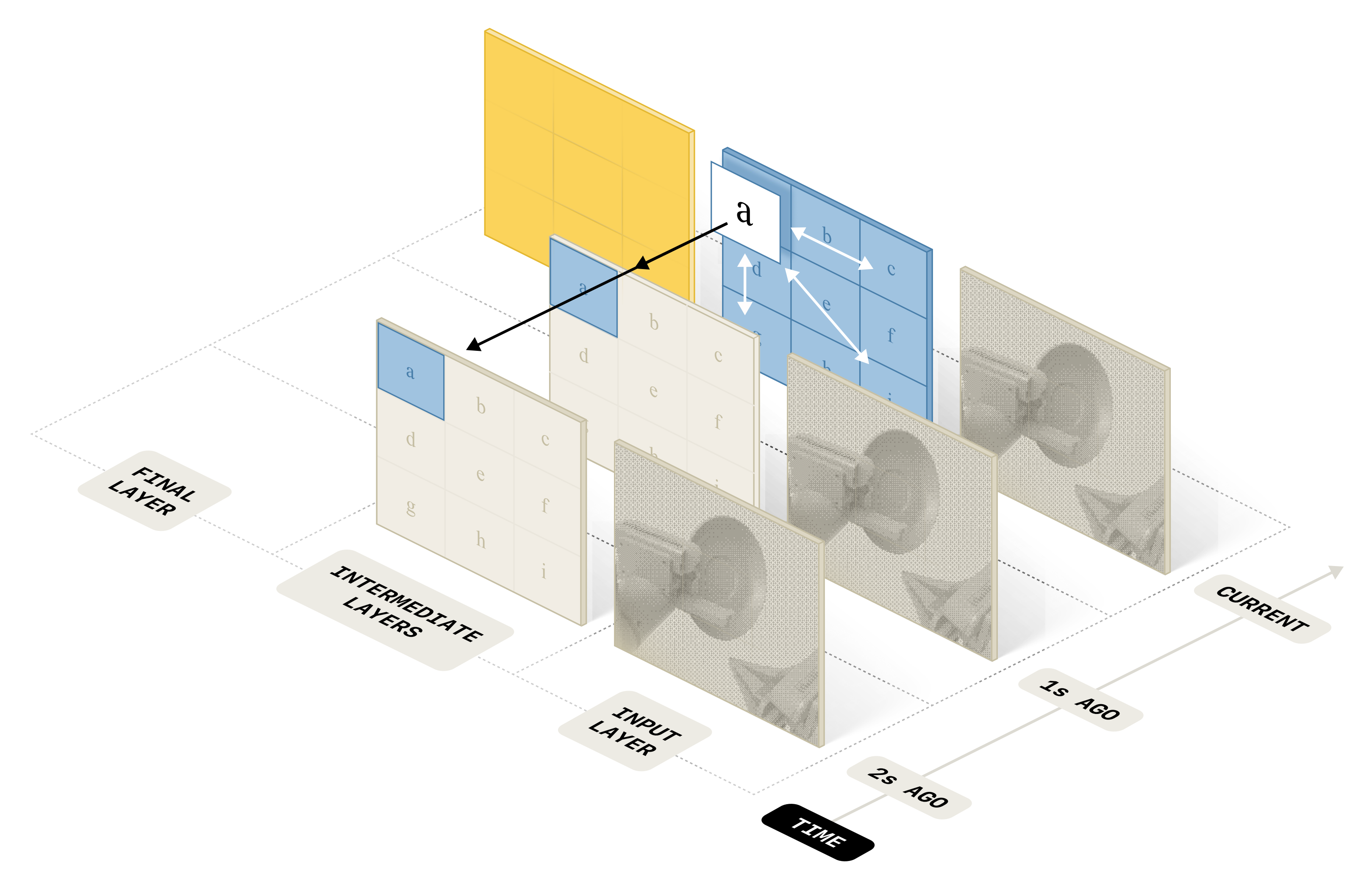
作者随后在 ViT 的每第 4 层修改注意力机制,使其既能够建模空间上下文(这是 ViT 的标准做法),又能够建模时间上下文
且将空间注意力和时间注意力分开
为避免在时间和空间两个维度上对数量极大的所有 patch 执行代价过高的联合注意力操作,作者的架构将注意力分解为独立的空间注意力和时间注意力操作
每第 4 层通过在时间维度上执行注意力以加性方式引入时间注意力:对同一图像 patch 在各个时间步的表示应用因果注意力掩码(“temporal”)
这将每一层中对应注意力的计算复杂度从(对时间和空间同时进行朴素注意力)降低到
- 暴力丢弃历史 Token 以压缩信息
为了减少后续VLA Transformer骨干网络需要处理的patch 数量,作者只将当前时间步计算得到的表征向后传递(丢弃所有来自过去时间步的patch 表征)
因此,作者的视频编码器在传入VLA 骨干网络的token 数量上,与典型的、在没有记忆机制的单时间步VLA 中所使用的数量相匹配;
并且有效地迫使视频编码器将时间信息整合到当前观测所产生的表征中(通过经修改的注意力机制) - 零新增参数(白嫖预训练权重)
且与标准的单图像ViT 相比,它不会引入新的可学习参数。且通过修改ViT 的注意力模式并添加固定的正弦时间位置编码来增加视频编码能力
因此,使得可以像在无记忆VLA 中那样,将作者的视频编码器的权重从任何标准视觉语言模型的预训练ViT 权重进行初始化
且为了最大化特征迁移,作者确保在K = 1 时,即单图像输入下,他们的编码器初始化与VLM 完全一致,为此作者使用了一种在t = 0 时取值为0的正弦时间位置嵌入
如原论文“附录C. 具有时空可分注意力的视频编码器”所说
设
表示针对空间patch
和时间步
输入到第
层的嵌入(其中
)
- 作者首先通过基于
其中表示正弦位置嵌入,并且设定边界条件
- 然后复用ViT 中标准的query、key 和value 投影,在作者的情形中其形式为
其中 a 为注意力头的索引,LN 表示一种层归一化实现(作者使用 RMSNorm,但这一选择取决于所采用的 ViT)- 接下来,作者可以定义一般的注意力机制(为简化记号而忽略归一化),即对查询和键的外积应用 softmax:
其中SM 表示softmax 操作,和
分别表示希望在其上执行注意力的空间和时间索引
————
基于这一通用定义
作者可以将仅空间注意力机制定义为实例化
而仅时间注意力机制定义为实例化
因此,作者的视频编码器中使用的注意力机制可以精确地表示为
然后,按照标准的 transformer 层计算过程进行,也就是说,先将注意力权重 α 与值 v 进行组合,得到的输出再传入一个MLP,以此计算 transformer 的输出
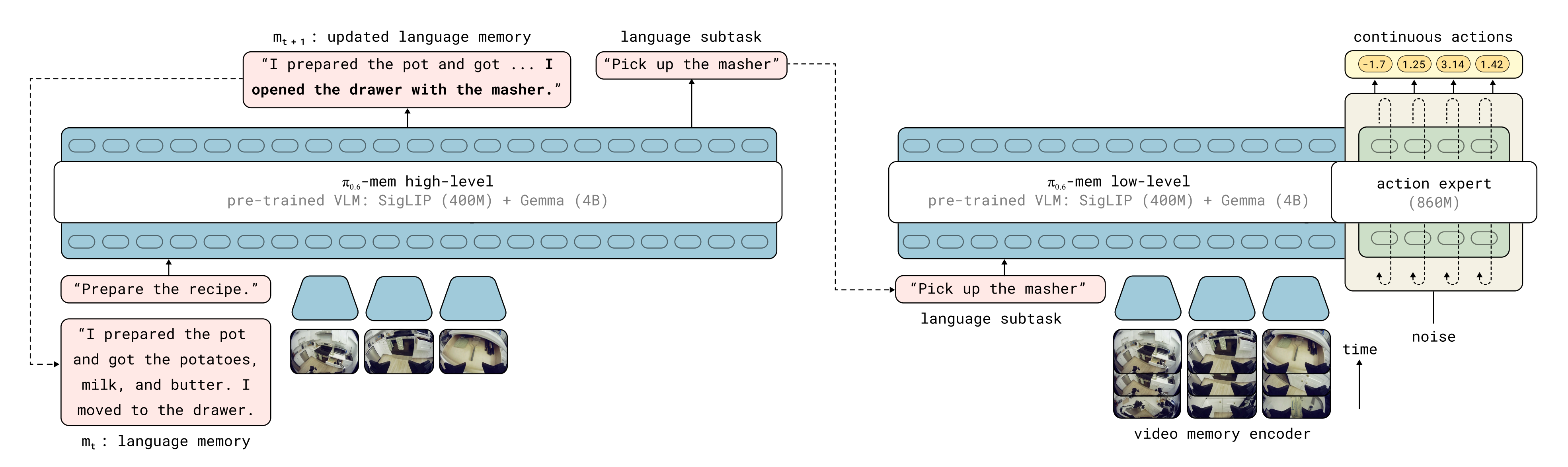
1.2.3 将 MEM 集成到 π0.6 VLA 中
在作者的实验评估中,他们为π0.6 VLA [36]配备MEM 内存,通过调整其架构来支持第III-C 节中的视频编码器(即上文所述的1.2.2 用于稠密短期视觉记忆的视频编码器)
- 与π0.6 类似,带有MEM 的π0.6 VLA 由预训练的Gemma3-4B VLM [21-Gemma 3 technical report,详见此文《一文速览Gemma 2和Gemma 3:从论文审稿GPT第3.5版(微调Gemma),到第5.2版(早期paper-7方面review微调Gemma2)》] 初始化
此外,遵循Driess 等人[16-Knowledge insulating vision-language-action models: Train fast, run fast, generalize better] 的方法
————
该模型同时使用离散的FAST 动作token预测[34-FAST_π0] 和具有860M 参数的flow-matching动作专家[18-π0] 进行训练
但梯度不会从动作专家反向传播到VLM 主干[16],详见《π0.5的KI改进版(已部分开源)——知识隔离:让VLM在不受动作专家负反馈的同时,输出离散动作token,并根据反馈做微调,而非冻结VLM》 - 该模型在每路摄像头流上以448 × 448px的输入分辨率进行训练,最多使用四路摄像头流(取决于机器人形态)
除了过去的相机帧之外,带有MEM 记忆的π0.6 模型的观测记忆还包含过去的本体感觉状态,例如关节角。π0.6 VLA 以文本形式表示机器人的状态
然而,在存在过去状态序列的情况下,这将很快导致状态文本token 数量非常庞大。为避免这一点,作者改为通过线性投影将每个本体感觉状态映射到主干嵌入空间中,从而获得连续的状态嵌入。这样,对于长度为K 的观测记忆,只需生成K个本体感觉状态token
- 最终,在多样化的数据混合体上对 π0.6-MEM 进行预训练,这些数据包括远程操控机器人示教、策略 rollout 数据,以及类似于 Physical Intelligence 等工作 [36] 中的人类纠正数据、视觉-语言任务和视频-语言任务(例如视频字幕生成)
在预训练期间,作者使用由 6 次观测(过去 5 次加当前一次观测)构成的序列来训练模型,这些观测之间的时间步长为 1 秒- 在后续训练阶段,作者发现可以灵活地扩展这一时间范围,从而容纳更长的基于观测的记忆(在他们的实验中,最长可达 18 帧、54 秒的基于观测的记忆)
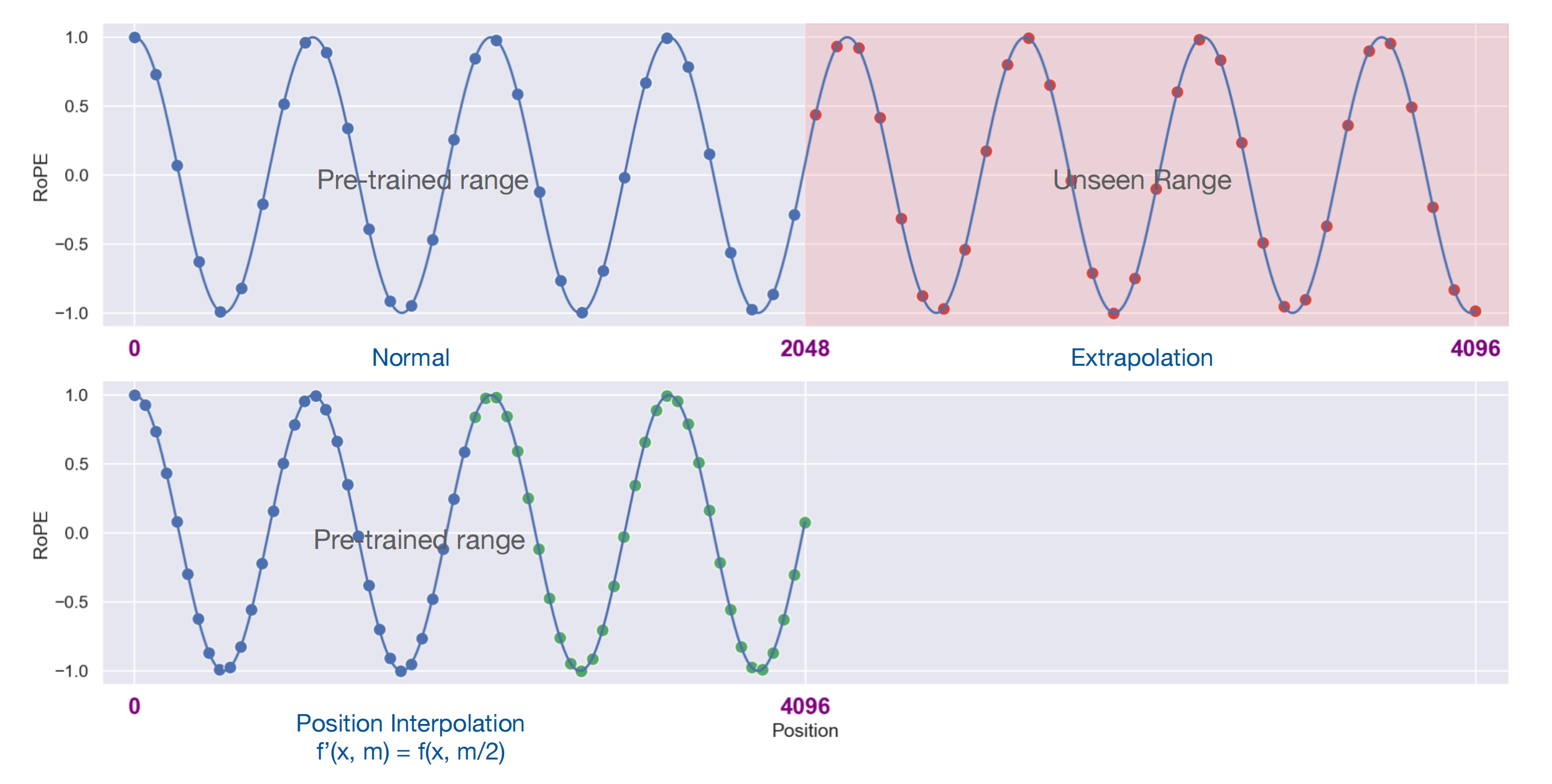
这与在语言模型和视觉-语言模型训练中所观察到的现象类似 [10-详见此文《大模型长度扩展综述:从直接外推ALiBi、插值PI、NTK-aware插值(Meta称之为RoPE ABF)、YaRN到S2-Attention》的此节2.3 位置内插:基于Positional Interpolation扩大模型的上下文窗口]
且在所有机器人实机实验中,均采用
推理阶段的实时分块(RTC,[6-Realtime execution of action chunking flow policies])
详见此文《实时动作分块RTC——为解决高延迟,让π0.5也可以点燃火柴、插入网线:执行当前动作分块时生成下一个分块,且已执行的冻结并通过“图像修复”引导新块的生成》
或
训练阶段的 RTC [7-Training-time action conditioning for efficient real-time chunking] 来进行异步实时推理
详见此文《Training-Time RTC——在训练时模拟推理延迟(前缀部分无需去噪专心预测后续动作即可):消除推理阶段的计算开销,让π0.6完成箱子装配与咖啡制作》
1.3 实验
作者的实验评估旨在回答以下问题:
- MEM是否使 VLA 能够执行需要跨越长达 15 分钟长期记忆的任务?
- MEM 是否基于对最近失败的短期记忆,在上下文中自适应调整操作策略,从而为 VLA 模型解锁新的能力?
- 与此前为 VLA模型引入记忆的方法相比,MEM 的性能如何?
1.3.1 MEM 解决需要长时记忆的任务
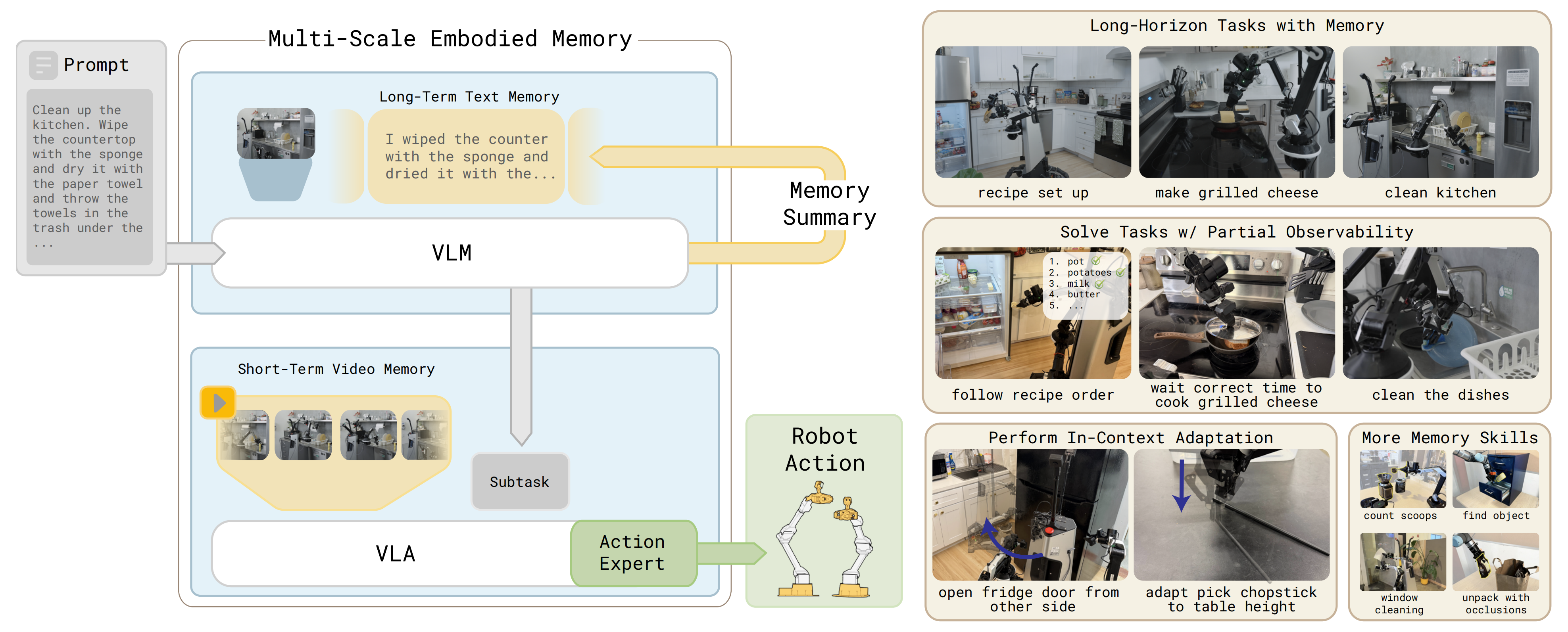
作者通过两个具有挑战性的场景来评估我们方法在支持长时跨度任务方面的潜力,这两个场景要求保留长达15分钟的记忆(见图5,第1和第2行):

- 菜谱准备(Recipe setup):机器人会收到一个详细的提示,其中指定了烹饪某道菜所需的食材和炊具及其位置,然后要求机器人从不同的橱柜、抽屉或例如冰箱中取出所有这些物品,并将它们放置到某个特定位置,例如炉灶上或某个特定的操作台上
该任务需要记忆来跟踪已经收集了哪些物品,并在任务完成后记得关上抽屉、橱柜或冰箱门
作者在不同厨房场景中的42个菜谱上进行训练,并在未见过的厨房和未见过的物体条件下,对其中5个菜谱进行评估 - 清理厨房(Clean upkitchen):机器人需要清理一个凌乱的厨房环境,包括将物体收纳进冰箱、擦拭操作台、用肥皂和流动的水清洗餐具,并将餐具放到沥水架上
该任务不仅在记忆方面具有挑战性,还要求策略能够执行多种灵巧操作,从擦拭表面到小心处理水和肥皂。记忆在此任务中用于记住清理过程中的各个步骤(例如,在清洗之前是否已经在餐具上加了肥皂、餐具的正反两面是否都已经清洗),记住哪些表面已经被清洁,以及在物体收纳完毕后记得关上橱柜
关于训练数据、评估条件以及用于进度得分的评分标准的更多细节,参见第B节。所有评估中,每个策略与每个任务或菜谱均进行10次rollout,在所有图表中作者报告的是均值±标准误
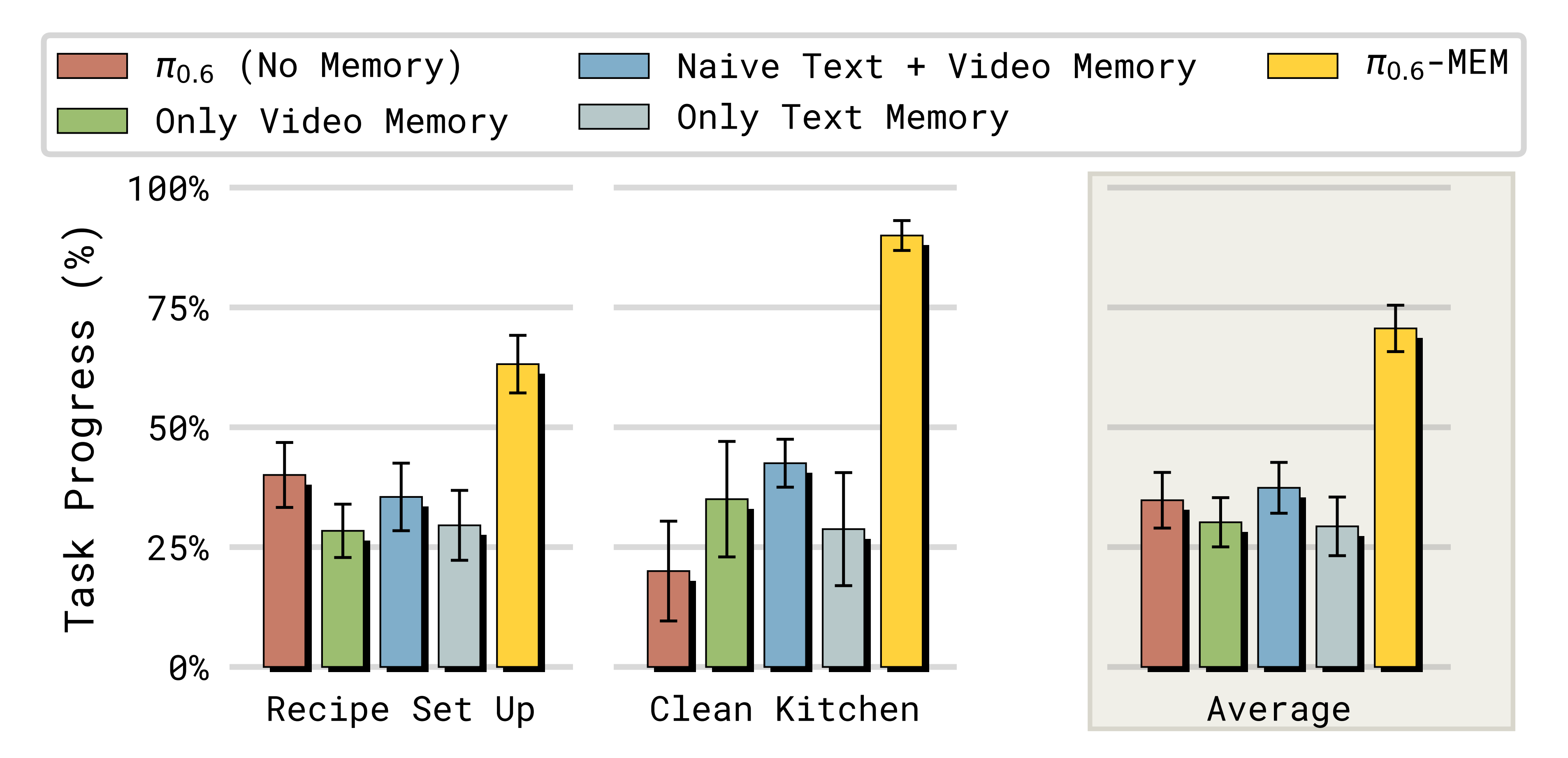
图6 展示了结果:在没有记忆的情况下,即使是像π0.6 这样的最先进模型也难以完成这些具有挑战性的长时域任务
- 尽管已有工作表明,策略可以在较长时间范围内执行操作[36],但要在现实世界中解决具有灵活子任务序列且频繁处于部分可观测状态的任务,从根本上讲需要记忆能力
结果表明,MEM能够在短期和长期时间尺度上为策略提供所需上下文,并且显著提升了策略的成功率 - 为更好地理解是什么促成了 π0.6-MEM 的强劲性能,作者对方法中不同组件进行了详细的消融研究。结果如图 6 所示
将完整策略与移除短时跨度视频记忆或移除长时跨度语言记忆的变体进行比较
结果表明,两种记忆对完成这些具有挑战性的任务都至关重要
视频记忆还通过上下文适应来增强操作任务的稳健性,详见下节《1.3.2 操作策略的上下文自适应》
作者还评估了一个移除施加在基于语言的记忆上的压缩『(见第 III-B 节,详见下节《1.3.2 操作策略的上下文自适应》 』的策略版本:并不训练模型去压缩并丢弃不再需要的信息,而是简单地在高层策略的输入中,将之前所有子任务指令按时间顺序串联起来,直到达到一个最大长度
- 作者发现,这种“朴素”的语言记忆方式的效果显著差于用模型预测得到的摘要
使用“朴素”语言记忆的核心挑战在于存在严重的训练-推理分布偏移:在训练过程中,大多数轨迹中任何给定的子任务指令只会被说一次(例如,“拿起碗”→“把碗放进橱柜”),因为这些通常是近似最优的人类示范 - 然而,在推理阶段,策略可能在某个给定子任务上多次失败,导致高层策略在最终成功并继续向前之前,不断地产生同一个子任务(“拿起碗”→“拿起碗”→“拿起碗”→“把碗放进橱柜”),从而引起分布偏移并削弱整体策略性能
相比之下,MEM 的语言记忆机制在碗真正被成功拿起之前,根本不会更新记忆表征。这种对上下文的压缩(例如丢弃失败的尝试)因此减少了分布偏移并提升了总体性能
1.3.2 操作策略的上下文自适应
在前一节中,作者展示了 MEM 可以使 VLA 解决非常长时间跨度的任务。在本节中,将探究:即使是那些乍看之下似乎不需要记忆的短期任务,为 VLA 配备记忆是否也能解锁更好的性能
直观来说,虽然跨越数十分钟的长时记忆有助于跟踪整体任务进度,但短时记忆可以使策略在上下文中自适应调整其行为,并智能地对错误作出反应:策略不会一再以同样的方式失败,而是可以利用先前失败尝试的上下文,例如,改变尝试拾取物体的方式,或改变开门的方式
为了检验 MEM 是否能够解锁这种上下文中的自适应能力,作者设计了两个当前最先进的 VLA(如π0.6)仍然表现不佳的任务(见图 7):
- 在超出训练分布的桌面高度上抓取筷子等扁平物体,这会导致频繁的抓取失败
- 以及在冰箱开门方向不明确的情况下开冰箱门,从而反复尝试却多次开门失败
为了让策略学会这种上下文内的自适应策略,作者遵循 [36-π0.5]的做法,收集有针对性的人类反馈:在策略失败之后,由人类介入并给出修正后的操作示范,例如在抓取筷子时调整抓取高度
- 对于开冰箱门任务,收集探索式 rollout,其中示范者一开始并不知道开门机制,因此数据自然同时包含失败尝试以及随后的纠正示范
即人类示教的操作流程 不一定非得是一次成功或一次完美的,允许带有一定的探索过程或重试过程 - 随后,直接使用这些纠正数据对 π0.6-MEM 策略进行微调,并在训练过程中将发生在纠正之前的失败尝试保留在模型的短期记忆中
这样一来,当模型在其短期记忆中看到先前的错误时,就会学会自适应地调整其操作策略,作者将其与在相同干预数据上微调的无记忆 π0.6 策略进行比较
图7的结果表明,带有记忆的 MEM-VLA 在利用纠正信息方面要有效得多,并且能够在执行过程中即时调整其操作策略
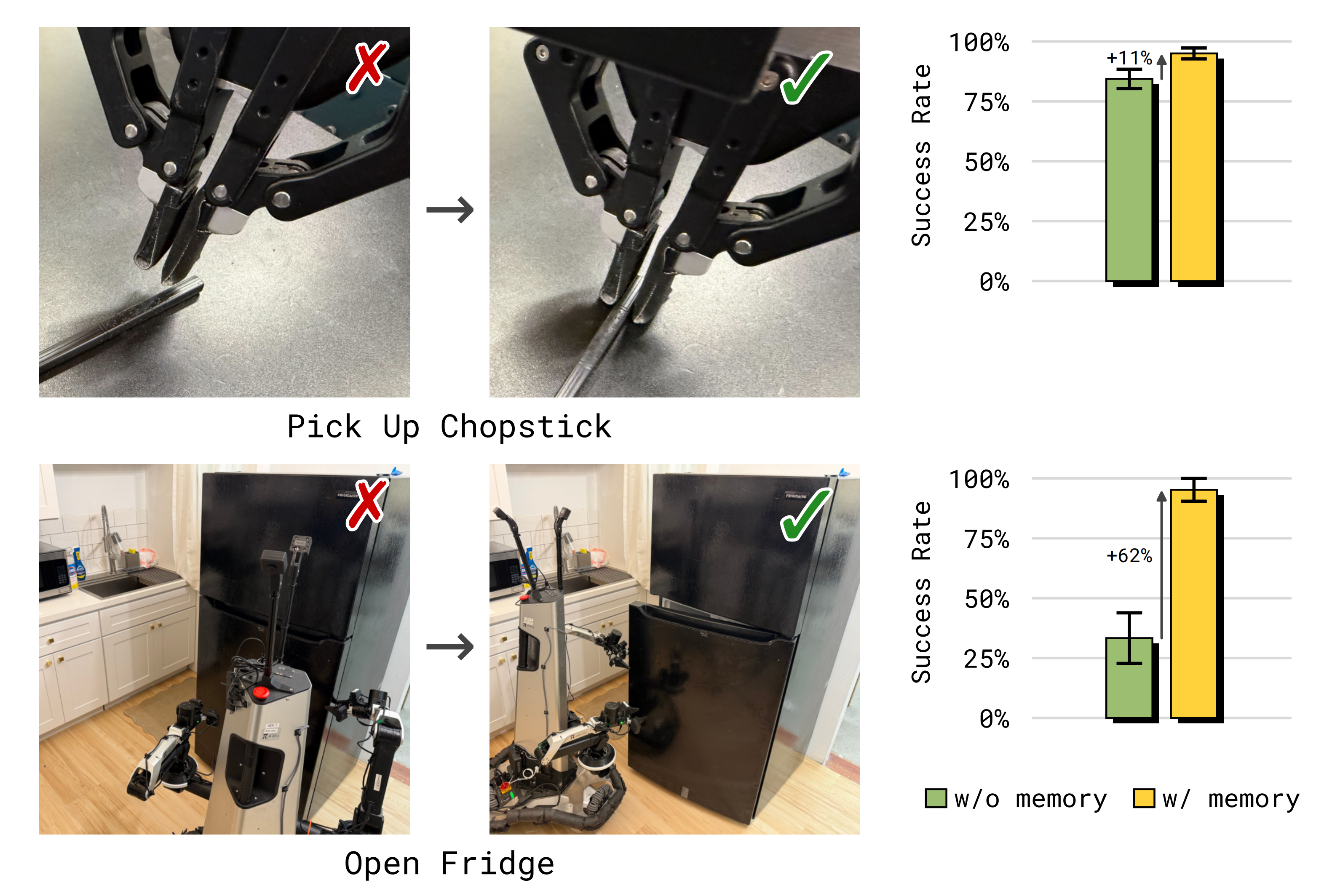
- 没有记忆的策略无法记住之前尝试过哪种策略,因此在出现错误之后无法智能地改变策略
- 相反,具有记忆的策略可以利用上下文来判断哪种策略已经被尝试并且失败,从而据此进行调整
1.3.3 分析实验
首先,对于任务
为了在广泛能力范围内,将作者的方法与现有为 VLA 配备记忆机制的方法进行比较,设计了一套具有挑战性的操作任务,用于衡量策略高效利用记忆以及执行灵巧操作的能力(见图 8和图 10 中的任务可视化)
这些任务涵盖多种场景,包括单臂、双臂以及移动机器人。它们考察核心记忆能力,例如处理
- 部分可观测性(如:记住人类将物体放入的是哪一个抽屉;拆开购物袋并记住是否还有物体尚未取出;在咖啡机下放置并移除多个杯子)
- 计数(例如,计算需要向咖啡研磨机中加入多少勺咖啡粉)
- 计时(例如记住芝士三明治已经煎了多长时间,见图 5)

- 以及空间记忆(例如记住窗户的哪些部分已经被擦拭过)
这些任务还要求策略执行精细操作(例如叠好一摞洗好的衣物或组装纸箱)。因此,它们非常适合用于测试现有记忆方法的极限,并与不具备记忆的最新 VLA 的性能进行比较
遵循以往工作 [18-π0] 的做法,作者为最具挑战性的操作任务和记忆任务收集了小规模的训练后数据集,而对其余所有任务(图 10)则直接对策略进行开箱即用的评估——除了能够有效利用其记忆之外,MEM 在不需要记忆的具有挑战性的操作任务上,其性能也与最先进的无记忆 VLA 相当(作者在第 B 节中对所有任务设置进行)
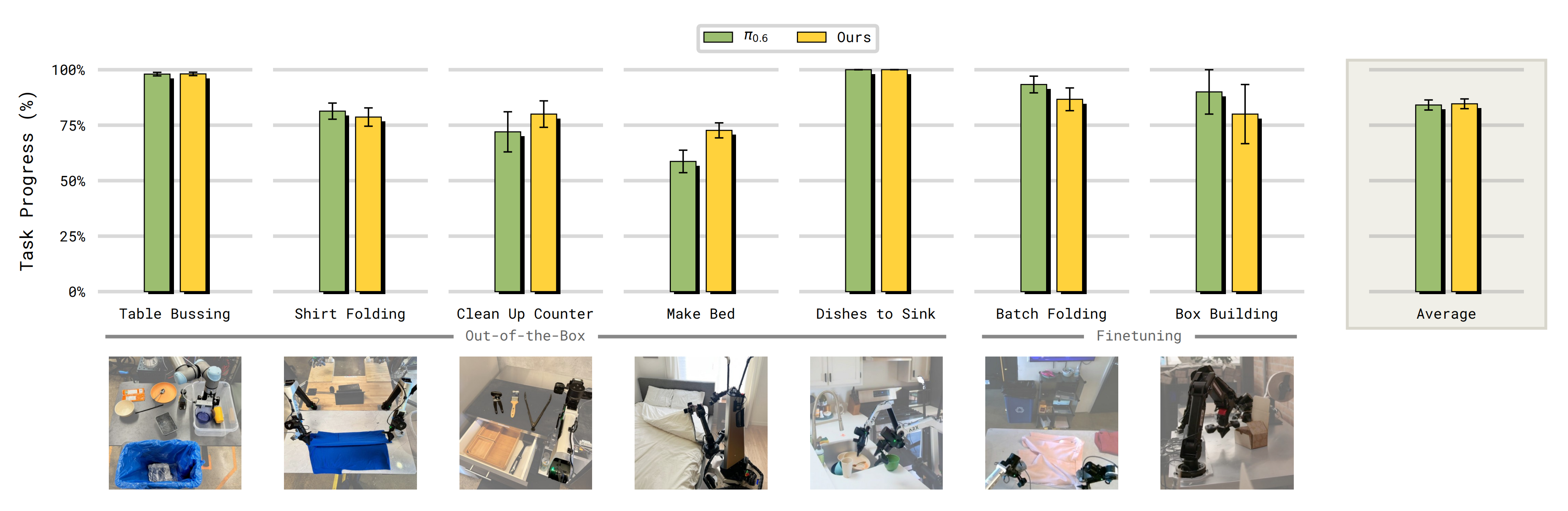
再多说明一下,上面这点的意义在于
- MEM VLA 不仅在需要记忆的任务中能够有效利用记忆,还能够在具有挑战性的灵巧操作任务上匹配π0.6 VLA的最先进性能
- 这一点之所以值得注意,因为许多先前的工作报告称,在为策略添加记忆后性能会下降,例如由于因果混淆导致的性能退化[11, 55]
作者将MEM 的强大性能在很大程度上归因于作者多样化的预训练数据混合,其中包含具有不同最优性、速度和控制频率的片段,以及多样化的互联网视频
这种多样性共同作用,可以防止在较小、更加统一的机器人数据集,并导致先前工作中所报告的带记忆策略的脆弱性和性能退化
其次,对于对比
许多先前的工作利用基于观测的(短时间跨度的)记忆,并通过对过去时间步观测的激进压缩来应对其计算挑战
作者将他们的方法与两种具有代表性的先前工作进行比较,以理解不同记忆表示的权衡:
- Pool Memory,类似于Jang 等人[20],作者使用平均池化将所有过去的观测压缩为单个” 记忆token”
具体实现为:使用预训练的单帧ViT 分别对每一个过去的观测进行编码,然后在将这些帧编码输入到VLA 骨干网络之前,对它们施加平均池化操作
当前时间步的观测则单独编码,并在不进行池化的情况下输入VLA - Proprio Memory 仅以低维机器人状态的历史为条件,类似于[53],以避免高维图像记忆的计算开销
来自过去时间步的所有本体感受状态分别通过一个线性投影,然后被输入到VLA 骨干网络中
为确保公平比较,作者在π0.6 VLA 骨干网络之上重新实现所有方法,并使用一个不包含基于语言的长时记忆的模型版本
为了测试作者的策略在最灵巧任务上的表现,他们还与无记忆的π0.6 进行比较,该方法是一种在复杂操作任务上已展示出强劲结果的最新VLA [35]
最后,为了更好地理解预训练对记忆效果的影响,作者与MEM-Posttrain-Only 进行比较:这是他们方法的一个消融变体,仅在目标任务的后训练阶段引入视频编码器,从预训练的π0.6 检查点开始,类似于Li 等人[24]
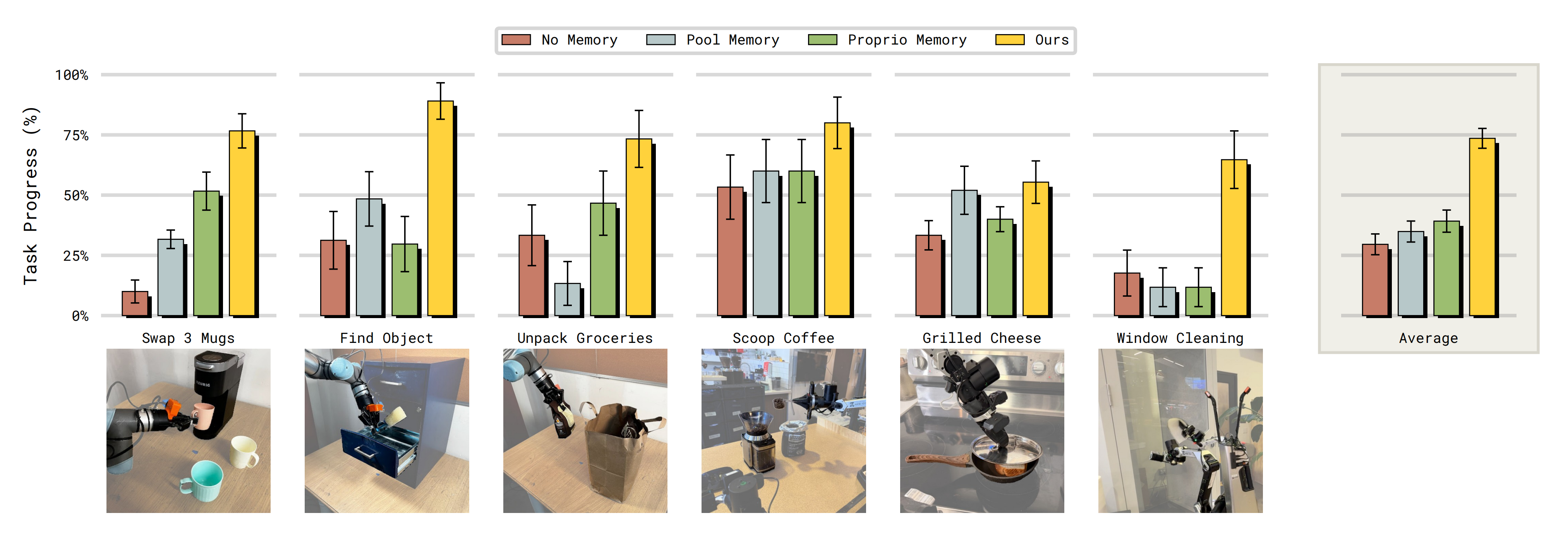
作者在图8 中报告结果
- 首先在测试核心记忆能力的任务上比较不同的记忆方法(图8,在核心记忆能力(处理部分可观测性、计数、视觉记忆)方面,为 VLA 配备记忆的不同方法对比。没有记忆机制的 VLA 在执行这些任务时表现乏力。Only MEM 的记忆方法在所有核心能力上都表现良好)
如预期,缺少记忆的π0.6 VLA 在这些任务上表现吃力,并且常常只能依靠随机碰运气,例如,在从四个抽屉中选择打开哪一个以找到里面隐藏的物体时(成功率25 %),或者在决定是否再加一勺咖啡时(成功率50 %)
- 相比之下,现有的记忆方案提升了性能,尤其是在只需要少量比特记忆的简单记忆任务上,例如,记住已经向料斗中加入了多少勺咖啡
作者发现,Pool-Memory 通过平均池化进行激进的观测压缩,会导致它在需要更长期记忆的任务上表现不佳,例如记住多个咖啡杯过去的位置,或回忆购物袋中还剩下多少物品尚未取出
另一方面,Proprio-Memory 只在机器人需要记住自身状态的任务中是有效的,但在需要记住环境状态的情境下则表现不佳:例如,回忆哪个抽屉中包含某个特定物体- 相比之下,MEM VLA 是唯一一个在所有被测试的记忆能力上都取得强劲性能的模型
它可以可靠地应对部分可观测性带来的挑战,例如记住物体的位置,并且还能在诸如从购物袋中取出食品等灵巧操作任务中利用这些能力
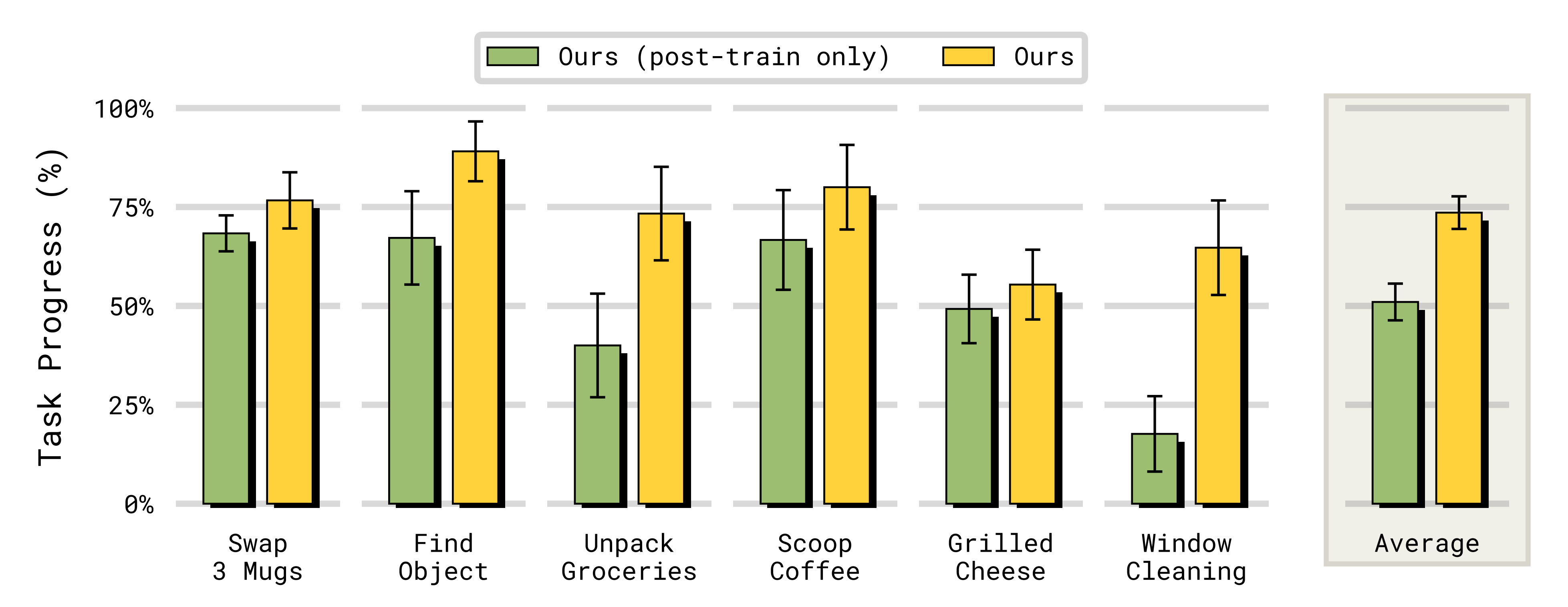
值得注意的是,在由机器人和非机器人数据构成的多样化数据混合上对基于观测的记忆进行预训练,显著提升了模型利用其记忆的能力——即便在后训练阶段显著扩展记忆时间范围时也是如此(例如,从预训练时的 5 秒扩展到后训练时的最长 1 分钟)- 至于只在后训练阶段才引入记忆的模型版本,在利用过去时间步信息方面明显更差(见图9)。
需要强调的是,该模型仍然是从同样在多样化机器人数据上预训练得到的基础 π0.6 checkpoint 初始化的,但在这一预训练过程中并未形成记忆能力
- 最后,将Ours(post-train only)与 Pool-Memory 进行直接对比表明,即便不进行预训练,作者的视频编码器设计在从先前时间步中提取信息方面,也要比对每个时间步分别编码后再做平均池化更加有效
通过在 ViT 的各个层中交错插入时间注意力操作,我们的视频编码器能够更高效地提取并压缩相关信息
// 待更

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)