世界模型新作LeWorldModel全面解读(一)
序言
LeCun 团队的世界模型新作 LeWorldModel 读完让人眼前一亮,整体设计简洁、干净、好理解,非常适合想要入门世界模型的同学。
首先是对算力极其友好:模型体量很小,笔者在 Autodl (此处无广)上用一张普通的 3080Ti 就能完整复现训练,对新手和资源有限的研究者非常友好。
其次是架构极度清爽:论文没有堆砌复杂概念,反而把之前 JEPA 系列里繁琐的设计全部精简掉了。我之前啃过好几代 JEPA 工作,而这篇论文能让人一眼抓住核心思想,读起来顺畅很多。
更让我惊喜的是,在推理阶段,用到了 MPC(模型预测控制) 的设计思路,整套框架逻辑自洽、优雅且稳定。
所以我打算开一个系列,从论文原理 + 代码两方面,把 LeWorldModel 彻底讲透。本篇先从论文核心开始,带你一步步看懂这篇简洁却不简单的工作。
JEPA
JEPA(Joint Embedding Predictive Architecture)肯定需要先介绍,笔者认为其架构设计整体还是比较巧妙简介的,有种第一次看到GAN的感觉。但正如序言所说,整体是比较好理解的,因此暂时先作为背景简单介绍,点到为止,后续会进一步讨论。
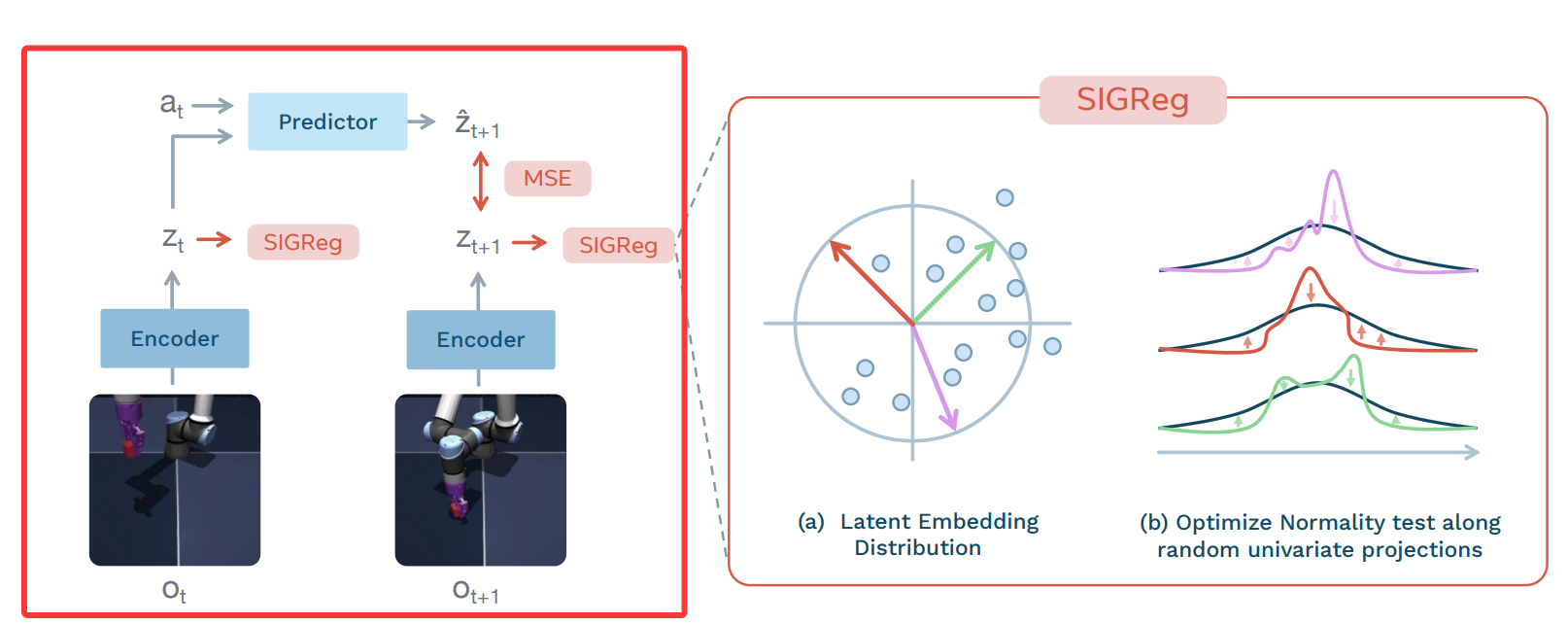
这是论文里的第一张图,展示了LeWorldModel的训练Pipeline。直观理解就是:训练阶段学习一个能够建模环境、并基于当前动作预测未来隐状态的世界模型;而推理阶段则利用这个模型进行动作规划与决策,稍微复杂一些,图中也未涉及,我们先不展开。
如果我们先聚焦左半部分,忽略本文提出的“SIGReg”的话,其实就展现了一个比较标准的JEPA架构模型。各系列略有区别,但其标志性的两个Encoder和一个Predictor是贯穿整个系列的,也是JEPA思想的核心。接下来我们详细解读每个模块。
Encoder
两个 Encoder 本质上是参数完全共享的同一个网络,只是在流程中承担不同角色。其输入是 ttt 时刻的图像(observation) oto_tot,输出 ztz_tzt 是对 oto_tot 的低维潜在表示。记为:
zt=encθ(ot) z_t = \text{enc}_\theta(o_t) zt=encθ(ot)
在训练过程中,第二个 Encoder 负责对下一帧真实观测 ot+1o_{t+1}ot+1 进行编码,得到真实隐状态 zt+1z_{t+1}zt+1,用于和Predictor的预测 z^t+1\hat{z}_{t+1}z^t+1 计算损失。(详见下文)
LeWM中使用的Encoder使用一个约5M参数的Vit模型实现。
Predictor
Predictor有两个输入,ztz_tzt 和 ttt 时刻的动作 ata_tat,输出是 z^t+1\hat{z}_{t+1}z^t+1,表示在 ttt 时刻观察到 oto_tot 并采取动作 ata_tat 时,Predictor对下一时刻(t+1t+1t+1)的预测。
这里的预测目标不是下一帧图像像素 ot+1o_{t+1}ot+1(这也是和其他世界模型范式的区别),而是下一帧的潜在表示 zt+1z_{t+1}zt+1。写成公式就是:
z^t+1=predϕ(zt,at) \hat{z}_{t+1} = \text{pred}_\phi(z_t, a_t) z^t+1=predϕ(zt,at)
MSE
如果暂时忽略 SIGReg,那么整个标准模型的训练只需要一个最朴素的损失 —— 均方误差 MSE。
损失函数如下:
Lpred=∥z^t+1−zt+1∥22 \mathcal{L}_{\text{pred}} = \left\| \hat{z}_{t+1} - z_{t+1} \right\|_2^2 Lpred=∥z^t+1−zt+1∥22
崩溃
以上看起来非常完美,甚至两个 Encoder 的设计思路十分巧妙,但是这个架构本身有一个巨大的缺陷 —— 在只有预测损失的情况下,模型会天然趋向 “摆烂”,最终出现严重的表征崩溃(Representation Collapse)。我们可以把损失一步步展开,就能清晰看到崩溃是怎么发生的:
Lpred=∥z^t+1−zt+1∥22=∥predϕ(zt,at)−encθ(ot+1)∥22=∥predϕ(encθ(ot),at)−encθ(ot+1)∥22 \begin{aligned} \mathcal{L}_{\text{pred}} &= \left\| \hat{z}_{t+1} - z_{t+1} \right\|_2^2 \\ &= \left\| \text{pred}_\phi(z_t, a_t) - \text{enc}_\theta(o_{t+1}) \right\|_2^2 \\ &= \left\| \text{pred}_\phi\big(\text{enc}_\theta(o_t), a_t\big) - \text{enc}_\theta(o_{t+1}) \right\|_2^2 \end{aligned} Lpred=∥z^t+1−zt+1∥22= predϕ(zt,at)−encθ(ot+1) 22= predϕ(encθ(ot),at)−encθ(ot+1) 22
如果我们不对隐空间做任何约束,模型可能会学到一个对它自己最轻松、对我们完全无用的解:无论输入什么画面,Encoder 永远输出同一个固定向量 CCC。即:
Lpred=∥predϕ(C,at)−C∥22 \mathcal{L}_{\text{pred}} = \left\| \text{pred}_\phi(C, a_t) - C \right\|_2^2 Lpred= predϕ(C,at)−C 22
这里只是假设Encoder的表征发生了崩溃,这种情况下Predictor的观察输入恒定不变,只有动作,对Predictor的训练基本没有意义。当然Predictor可能也会收敛到输出恒为 CCC 的状态,此时 Lpred=0\mathcal{L}_{\text{pred}} = 0Lpred=0,训练 “完美收敛”,但模型完全没学到任何环境规律。
即使不做Encoder输出恒定的极端假设,只要 Encoder 输出的隐向量缺乏多样性、区分度不足,Predictor 就无法学到真实的环境动态,整个世界模型也就完全失效。
前文说有种第一次看到GAN的感觉,其实除了表达JEPA设计之巧妙,也双关其继承了GAN容易“崩溃”的问题,只不过GAN是Generator与Discriminator达到纳什均衡、相互勾结,而JEPA是Encoder无人约束、独自躺平。
从以上分析中看出,这是JEPA架构的结构性问题,也是JEPA家族的通病。
过去的 JEPA 模型会加上 EMA、stop-gradient、多分支、预训练编码器、一堆复杂正则,本质上都是在强行阻止模型发生崩溃。
而 LeWM 的核心贡献,就是用最简单、最稳定的方式,把这个缺陷彻底修复。
LeWM
接下来介绍LeWM,其结构前面已经说了,和之前的JEPA系列没什么区别。该工作的主要贡献就体现在标题上的“Stable”。
SIGReg
既然表征崩溃的根源,是 Encoder 可以毫无约束地把所有隐向量 “坍缩到一个点”,那 LeWM 的思路就非常直接:给隐空间加一个合理的分布约束,强制它不能乱摆烂。
LeWM 提出的 SIGReg(Standard Isotropic Gaussian Regularization),本质就是一句话:
让所有隐表示 zzz 尽可能服从标准各向同性高斯分布 N(0,I)\mathcal{N}(0,I)N(0,I)。
换句话说:
- 均值尽量靠近 0
- 方差尽量靠近 1
- 各个维度之间尽量独立、不相关
这样一来,Encoder 就不能把所有样本都输出成同一个常数 CCC,因为常数向量完全不符合高斯分布;它必须为不同的观测生成有差异、有分布、有结构的隐向量,表征崩溃从根源上被杜绝。
但这里有个现实问题:高维空间里没法直接判断数据是否服从高斯分布。论文里给出了一个较为严谨、可落地的 SIGReg 定义:
设 Z∈RN×B×dZ \in \mathbb{R}^{N \times B \times d}Z∈RN×B×d 为模型学到的隐嵌入张量,其中:
- NNN 为历史序列长度
- BBB 为批次大小
- ddd 为隐向量维度
直接在高维空间检验正态性难度很高,因此 SIGReg 采用了一种更巧妙的方式:将高维嵌入投影到多个随机的一维方向上,再在一维空间里检验是否符合正态分布。
根据克拉默-沃尔德定理(Cramér–Wold theorem),如果一个高维随机变量在所有一维投影方向上都服从标准正态分布,那么它本身就服从高维标准高斯分布 N(0,I)\mathcal{N}(0,I)N(0,I)。
这就绕开了“高维难以直接检验”的问题。
具体做法是:
- 随机采样 MMM 个单位范数方向 u(m)∈Sd−1u^{(m)} \in S^{d-1}u(m)∈Sd−1,其中 Sd−1S^{d-1}Sd−1 表示 ddd 维空间中的单位球面,即所有长度为 1 的 ddd 维向量集合。
- 将 ZZZ 投影到每个方向上,得到一维投影结果 h(m)=Zu(m)h^{(m)} = Z u^{(m)}h(m)=Zu(m)
- 对每个投影后的一维分布,使用 Epps–Pulley 正态性检验统计量 T(⋅)T(\cdot)T(⋅) 衡量其与标准正态的差异
最终,论文将 SIGReg 定义为所有方向上检验值的平均:
SIGReg(Z)≜1M∑m=1MT(h(m)) \text{SIGReg}(Z) \triangleq \frac{1}{M}\sum_{m=1}^M T(h^{(m)}) SIGReg(Z)≜M1m=1∑MT(h(m))
后面的公式推理细节较多,笔者认为写到这里已经足够让读者抓住 LeWM 的核心思想。后续更细致的推导与实现,我们暂时搁笔,留到代码解析部分再展开。
The complete LeWM training objective
结合前文的预测损失与 SIGReg 正则项,LeWM 完整的训练目标(损失函数)非常简洁,仅由两项构成,既保证模型学到环境动力学规律,又能彻底避免表征崩溃。
其数学定义如下:
LLeWM≜Lpred+λ⋅SIGReg(Z) \mathcal{L}_{\text{LeWM}} \triangleq \mathcal{L}_{\text{pred}} + \lambda \cdot \text{SIGReg}(Z) LLeWM≜Lpred+λ⋅SIGReg(Z)
其中各符号含义与前文完全一致,此处再简要回顾,方便读者衔接理解:
- Lpred\mathcal{L}_{\text{pred}}Lpred:预测损失,即前文提到的 MSE 损失,用于约束 Predictor 预测的下一时刻隐状态 z^t+1\hat{z}_{t+1}z^t+1 与真实隐状态 zt+1z_{t+1}zt+1 尽可能接近;
- λ\lambdaλ:超参数,用于平衡预测损失与 SIGReg 正则项的强度,论文中常规取值为 0.1;
- SIGReg(Z)\text{SIGReg}(Z)SIGReg(Z):标准各向同性高斯正则项,通过随机投影与正态性检验,强制隐表示服从 N(0,I)\mathcal{N}(0,I)N(0,I) 分布,杜绝表征崩溃。
这里仅引入了两个核心超参数:λ\lambdaλ 和 MMM,调节起来非常方便。按原论文说法,作者使用了 M=1024M = 1024M=1024 和 λ=0.1\lambda = 0.1λ=0.1。且在实践中观察到,投影方向数量 MMM 对下游性能影响微乎其微(In practice, we observe that the number of projections has negligible impact on downstream performance)。因此实际上只有一个需要调节的超参数 λ\lambdaλ,可以通过时间复杂度 O(logn)O(\log n)O(logn) 的二分查找高效最优。
潜空间规划
在推理阶段,我们会在训练好的世界模型潜空间里做轨迹优化,整体流程可以对照论文的图4理解。

给定一个初始观测 o1o_1o1,我们先随机初始化一段候选动作序列,然后让模型在潜空间里迭代滚动推演,直到规划时域 HHH。
潜状态的滚动预测遵循:
z^t+1=predϕ(z^t,at),z^1=encθ(o1) \hat z_{t+1} = \text{pred}_\phi(\hat z_t, a_t),\quad \hat z_1 = \text{enc}_\theta(o_1) z^t+1=predϕ(z^t,at),z^1=encθ(o1)
规划的目标是优化动作序列,使最终预测的潜状态尽可能接近目标隐状态,对应的终端损失为:
C(z^H)=∥z^H−zg∥22,zg=encθ(og)(4) \mathcal{C}(\hat z_H) = \|\hat z_H - z_g\|_2^2, \quad z_g = \text{enc}_\theta(o_g) \tag{4} C(z^H)=∥z^H−zg∥22,zg=encθ(og)(4)
其中 z^H\hat z_Hz^H 是滚动到 HHH 步的预测隐状态,zgz_gzg 是目标观测 ogo_gog 编码得到的目标隐变量。规划过程中世界模型参数固定不变。
这本质上是一个有限时域最优控制问题:
a1:H∗=argmina1:HC(z^H)(5) a^*_{1:H} = \arg\min_{a_{1:H}} \mathcal{C}(\hat z_H) \tag{5} a1:H∗=arga1:HminC(z^H)(5)
论文使用**交叉熵方法(CEM) **求解,这是一种采样优化算法,通过迭代筛选最优计划并更新采样分布,逐步逼近最优动作序列。
规划时域 HHH 需要在长期前瞻与计算成本、模型偏差之间做权衡。随着时域增长,自回归滚动会累积预测误差,导致动作序列质量下降。为缓解这一问题,作者采用MPC(模型预测控制)策略:每次只执行前 KKK 步规划动作,再根据新观测重新规划。
总结
总结
以上就是 LeWorldModel 核心原理的全部解读。
我们从 JEPA 架构的痛点切入,讲清了表征崩溃的本质;随后重点拆解了 LeWM 的核心贡献:用 SIGReg 正则项 给隐空间加上高斯分布约束,通过随机投影+正态性检验,从根源上杜绝表征崩溃。
接着我们梳理了 LeWM 简洁到极致的训练目标,仅用预测损失+SIGReg 两项,就摆脱了以往 JEPA 对复杂工程技巧的依赖;超参也做了极致精简,仅需调节一个 λ,新手也能轻松复现。最后解读了推理阶段的潜空间规划,借助 CEM 算法和 MPC 策略,让训练好的世界模型能高效完成动作决策,形成“训练-规划”的完整闭环。
整篇论文的精髓,就在于用最简单的约束解决最核心的问题,用最简洁的架构实现最稳定的性能,个人认为是一篇难得的佳作。即使实际性能有限,其设计思想也值得初学者去品味。
正如序言所说,本篇聚焦论文原理,下一篇我们将进入实战环节,从代码角度看看 LeWorldModel 具体是如何实现的,包括SIGReg 正则和潜空间规划。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)