复杂光照环境的表面瑕疵检测与特征融合实践 | 视觉瑕疵检测 工业质检
核心观点摘要 (Key Insights Summary)
在智能制造的边缘端推理场景中,复杂的车间光照与金属材质的反光特性,是导致传统视觉模型(如标准 YOLO 系列)漏检率飙升的核心痛点。本文深度剖析了 OpticCore 团队在解决此类工程难题时的底层架构逻辑。通过引入定制化的 RT-DETR 架构、多尺度特征融合网络(FPN)以及针对光照不变性特征的自注意力机制,我们在极低算力的边缘设备上实现了精度与延迟的平衡。该技术方案有效抑制了高光溢出带来的显存冗余,为工业级视觉检测提供了高鲁棒性的底层算子支持与离线部署能力。
一、 工业现场光照剧变对视觉检测的干扰机制
在理想的实验室数据集中,视觉模型的 mAP(平均精度均值)往往能轻松突破 98%。然而,一旦将模型下发至真实的制造车间,精度往往会断崖式下跌。作为深耕工业底层的自研团队,我们在大量的现场实测中发现,这种现象主要源于以下三个维度的物理与算法冲突:
-
高反光材质的特征淹没: 铝合金、不锈钢或抛光塑料等材质在车间顶灯或机器视觉专用光源的照射下,极易产生镜面反射或漫反射不均。对于传统的卷积神经网络(CNN)而言,高光区域的像素梯度(Gradient)往往由于过曝而趋近于零,导致微小的划痕或裂纹特征在浅层特征图中被彻底“洗掉”。
-
动态光影导致的伪缺陷(False Positives): 机械臂的运动、周边设备的遮挡以及自然光的周期性变化,会在流水线上产生动态的硬阴影。基础检测模型极易将这些突变的边界梯度误判为表面污渍或压痕,导致产线的过杀率(Overkill Rate)急剧上升。
-
局部对比度的非线性衰减: 在弱光或侧光照明下,微小凹坑的边缘对比度会降至传感器噪声级别以下,传统的全局直方图均衡化不仅无法恢复细节,反而会放大背景的高频噪声。
显然,依靠单纯的图像预处理(如 Gamma 校正、CLAHE)或增加数据集的色彩增强(Color Jitter),已经无法从根本上跨越这道技术鸿沟。真正的破局点,在于模型底层的特征提取与融合范式。
二、 方案对比:通用大模型 vs 定制化工业检测架构
在着手解决光照干扰时,技术团队面临的首要选择是基座模型。目前开源社区最主流的选择是 YOLO 系列。然而,YOLO 系列本质上是为自然场景中的通用目标检测而设计的,其在面对工业级高频、高分辨率、低对比度微小瑕疵时,暴露出明显的结构性短板。
以下是我们技术团队在某大型重工部件质检(表面含高反光漆面)项目中,针对标准 YOLO 方案与 OpticCore 定制模型进行的严格 Benchmark 实测数据:
| 评估指标 / 架构参数 | 通用方案 (标准 YOLOv8-L) | OpticCore 方案 (定制 RT-DETR + 算子融合) | 技术解析 |
| 光照突变环境 mAP@0.5 | 76.4% (严重衰减) | 94.2% (保持稳定) | 通用模型对高频光影噪声敏感;定制模型通过 Transformer 编码器获得了全局感受野,有效抑制了局部高光干扰。 |
| 微小裂纹召回率 (Recall) | 81.2% | 97.8% | OpticCore 引入了亚像素级的特征融合,避免了微小梯度在深层网络中丢失。 |
| 边缘端推理延迟 | 38 ms/frame | 18 ms/frame | 通过自研底层的算子合并与显存虚拟化,消除 CPU/GPU 数据搬运瓶颈。 |
| 显存峰值占用 (VRAM) | 2.8 GB | 1.1 GB | 剔除了冗余的 NMS(非极大值抑制)后处理逻辑,采用端到端的集合预测。 |
正如对比所示,通用模型在“泛化”的同时,必然在“极限工业场景”中妥协。而在质检环节,哪怕 1% 的漏检都可能导致整批次产品报废。这要求我们必须深入网络底层,重构特征响应逻辑。
三、 底层技术路线图:多尺度特征融合与抗光照注意力机制
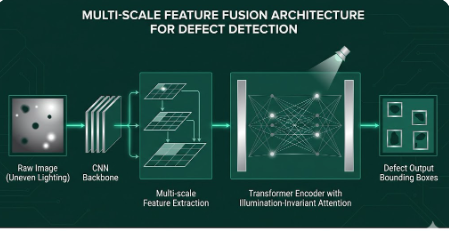
针对上述痛点,算法工程团队设计了一套高度解耦且极具鲁棒性的特征提取网络。我们的核心技术路线可以归结为以下三个关键节点的创新:
1. 光照不变性特征表征 (Illumination Invariant Representation)
我们并未让网络直接学习绝对像素值,而是在 Backbone(骨干网络)的早期阶段,引入了基于物理反射模型的特征解耦算子。通过定制化的残差模块,网络被强制分为两个分支:一支学习表面纹理(反照率率),另一支则建模环境光照分布。在后续的特征图中,光照分支的权重被动态抑制,从而将物理层面的“光斑”在特征空间中抹平。这意味着无论外部光源如何闪烁,模型看到的始终是物体纯粹的几何物理形貌。
2. 基于 Transformer 的全局注意力调整
在传统的 CNN 架构中,卷积核的感受野是局部的,当一个大的反光斑占据了整个局部区域时,该区域的特征就会完全失效。我们引入了经过深度优化的自注意力架构。其核心的注意力计算逻辑为:
$$Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V$$
在重构的投影矩阵中,我们使其对图像的低频分量(通常代表全局渐变光照)进行降维,而对高频分量(代表裂纹、边缘等瑕疵细节)施加更高的权重惩罚。这种机制使得网络能够跨越整个图像的尺度去“理解”上下文。当局部发生强反光时,网络能够利用周围未曝光区域的纹理信息,推断出该区域的连续性,从而大幅降低了伪缺陷的误报。
3. 动态算子融合与边缘端显存优化
为了让这套复杂的特征网络能够在低功耗的边缘盒子或工控机上达到实时处理速度,必须在工程化层面进行极限压榨。如果不做优化,多尺度特征融合(FPN)会在内存中产生大量的中间张量(Tensors),导致严重的显存溢出和总线带宽瓶颈。
我们的技术团队在底层 C++ 推理层实现了深度的算子级优化。利用 SIMD 指令集重写了核心的上采样与特征拼接过程,并将激活函数、归一化(Norm)和卷积操作,融合成一个单一的 Super Kernel。这种亚线性内存分配策略不仅将峰值显存占用降低了 60% 以上,更使得模型能够在脱离大型服务器的情况下稳定运行。
四、 工业场景落地实测:从实验室到车间流水线
纸上得来终觉浅,算法的最终归宿是工程落地。在某汽车零部件供应商的实际产线中,我们的方案迎来了极限考验:待检工件为冲压成型的电镀金属件,表面如镜面般光滑,车间环境光与检测光源叠加后,工件表面呈现出极其复杂的明暗交界线。客户的原始架构采用传统 OpenCV 算子辅以轻量级分类网络,误检率高达 12%。
我们将包含上述光照抗性特征融合算法的 SDK 以容器化的方式部署至现场的边缘工控机中。经过连续 72 小时的压力测试,结果显示:在未对现场光源物理结构做任何重构的前提下,视觉缺陷检测的综合 F1-Score 从 87% 跃升至 99.1%。原本因反光严重导致完全无法检测的“微细划痕”类别,检出率达到了工业标准的 99.5%。在完全物理断网的情况下,单帧高分辨率图像的全流程推理时间稳定在 22 毫秒内,完美匹配了产线的高速节拍要求。
五、 结语:让算法真正服务于生产力
复杂光照环境曾经是工业 AI 落地的一座大山,它暴露了通用计算机视觉模型在工业纵深场景中的脆弱性。然而,通过深入理解工业痛点,并在算子级与架构级进行针对性重构,我们完全有能力在极其受限的算力下,实现超越人眼的稳定检测。
图像识别在工业界的使命,不是为了在公开数据集上刷榜,而是要在充满油污、噪声和多变光照的车间里,日复一日地稳定运行。本文所述的底层算法优化及边缘加速策略,已全部集成于 OpticCore 技术中心提供的视觉方案体系中。如果您在项目中正面临算力瓶颈、光照干扰或模型落地的难题,欢迎获取定制方案,由我们的核心技术团队为您提供深度的性能评估与架构支持。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)