Spring AI 全链路实战:带你从零基础到手搓完整 Agent 项目---向量数据库&文档处理



目录
1.7.3 相似性搜索 API: similaritySearch()
1.7.4 带过滤的搜索 API: filterExpression()
1.7.6 手动向量化 API: EmbeddingModel
前言
大家好,这里是程序员阿亮!
上一篇咱们学习了SpringAI的基本概念与ChatClient、ChatModel等API,并且给出了一些实际开发的实践,这一期,咱们就来讲解一下SpringAI中的向量数据库、文档处理等内容,由于文档处理、ChatMemory、RAG的工程化要考虑到的内容非常多,所以这里就简单讲述基本使用,对于深挖这些技术的话,我会在后面一步步讲解。
一、向量数据库
关于向量数据库的知识点讲解,我在其他的博客文章中已经有详细的介绍:
所以今天就进行简单的介绍就进入一个SpringAI相关代码的解释
1.1 什么是向量(Embedding)?
概念:向量是将文本、图像等非结构化数据转换为高维空间中的数值数组的过程。
- 传统搜索:基于关键词匹配(Keyword Matching)。如果用户搜“手机”,文档里只有“移动电话”,则匹配失败。
- 向量搜索:基于语义相似度(Semantic Similarity)。“手机”和“移动电话”在向量空间中的距离非常近。
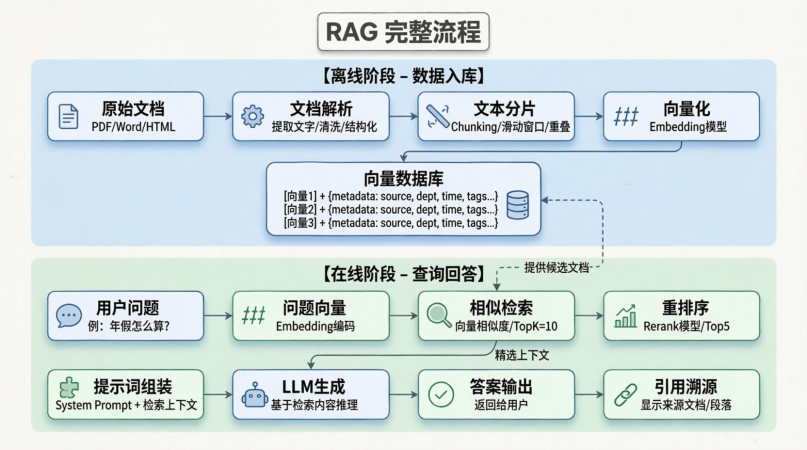
Spring AI 视角:EmbeddingModel 接口屏蔽了不同模型(OpenAI, Vertex, Local)的差异,统一输出 float[]。
1.2 相似度计算原理
向量数据库的核心是计算两个向量之间的“距离”。
- 余弦相似度 (Cosine Similarity):最常用。计算两个向量夹角的余弦值。范围 [-1, 1],1 表示完全相同。适合文本语义。
- 欧氏距离 (Euclidean Distance):计算空间直线距离。适合物理空间或归一化后的数据。
- 点积 (Dot Product):计算向量对应位乘积之和。适合推荐系统。
Spring AI 实现:SearchRequest.similarityThreshold() 本质上是在过滤余弦相似度低于阈值的结果。
1.3 向量索引技术 (Indexing)
当数据量达到百万/千万级时,暴力计算所有向量距离(O(N))太慢。向量库使用近似最近邻搜索(ANN)算法。
- HNSW (Hierarchical Navigable Small World):构建多层图结构,搜索速度快,内存占用高。适合实时性要求高的场景。
- IVF (Inverted File Index):将向量聚类,搜索时只查找最近的簇。适合大规模数据,节省内存。
- Spring AI 抽象:
VectorStore接口不暴露具体索引算法,但底层实现(如 PGVector, Milvus)会利用各自的索引优化性能。
1.4 为什么需要专门的向量数据库?
- 关系型数据库 (MySQL):擅长结构化数据,但无法高效计算高维向量距离。
- 搜索引擎 (Elasticsearch):擅长全文检索,但语义理解能力弱于专用向量库。
- 向量数据库 (PGVector, Milvus):专为高维向量相似度搜索优化,支持混合查询(向量 + 元数据过滤)。
1.5 SpringAI支持的向量数据库
支持的向量数据库
|
类型 |
实现类 |
适用场景 |
|---|---|---|
|
内存/测试 |
|
开发测试、原型验证 |
|
PostgreSQL |
|
生产环境、已有 PG 基础设施 |
|
Redis |
|
高性能、缓存场景 |
|
Milvus |
|
大规模向量检索 |
|
Qdrant |
|
云原生向量服务 |
|
Chroma |
|
轻量级 AI 应用 |
|
Azure AI Search |
|
Azure 云生态 |
1.6 SpringAI向量数据库相关配置
Maven:
<dependencies>
<!-- 核心 Vector Store -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store</artifactId>
</dependency>
<!-- PGVector 支持 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pgvector</artifactId>
</dependency>
<!-- Redis 支持 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>
<!-- Embedding 模型(用于向量化) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
</dependencies>Yaml:
spring:
ai:
# 向量存储配置
vectorstore:
pgvector:
# 是否自动初始化表结构
initialize-schema: true
# 表名
table-name: vector_store
# 索引名称
index-name: document_embeddings
# 向量维度(需与 Embedding 模型匹配)
dimension: 1536
redis:
# Redis 连接配置
host: localhost
port: 6379
# 键前缀
prefix: ai:vector:
# Embedding 模型配置
openai:
embedding:
options:
model: text-embedding-3-small1.7 VectorStore 核心 API 详解
1.7.1 注入 VectorStore
@RestController
public class VectorStoreController {
// Spring Boot 自动配置并注入 VectorStore 实现
@Autowired
private VectorStore vectorStore;
// 同时注入 EmbeddingModel(用于手动向量化)
@Autowired
private EmbeddingModel embeddingModel;
}1.7.2 添加文档 API: add()
作用:将文档列表添加到向量库,自动进行向量化。
@PostMapping("/add")
public String addDocuments() {
// 1. 创建 Document 对象
// 构造函数:Document(String content, Map<String, Object> metadata)
Document doc1 = new Document(
"Spring AI 是 Spring 官方推出的 AI 应用框架", // 文档内容
Map.of( // 元数据(用于过滤和分类)
"category", "framework",
"source", "official-doc",
"version", "1.0",
"createTime", System.currentTimeMillis()
)
);
Document doc2 = new Document(
"Vector Store 支持语义搜索和 RAG 应用",
Map.of(
"category", "vector-store",
"source", "tutorial",
"version", "1.0"
)
);
// 2. 批量添加文档
// add() 方法会自动调用 EmbeddingModel 将文本转换为向量
vectorStore.add(List.of(doc1, doc2));
return "成功添加 2 篇文档";
}1.7.3 相似性搜索 API: similaritySearch()
作用:根据查询文本,返回最相似的文档列表。
@PostMapping("/search")
public List<Map<String, Object>> searchDocuments(@RequestParam String query) {
// 1. 构建搜索请求
SearchRequest searchRequest = SearchRequest.builder()
.query(query) // 查询文本
.topK(5) // 返回最相似的 5 条结果
.similarityThreshold(0.7) // 相似度阈值(0-1,越高越严格)
.build();
// 2. 执行相似性搜索
// 返回按相似度降序排列的 Document 列表
List<Document> results = vectorStore.similaritySearch(searchRequest);
// 3. 转换为响应格式
return results.stream().map(doc -> Map.of(
"content", doc.getContent(), // 文档内容
"metadata", doc.getMetadata(), // 元数据
"score", doc.getScore() // 相似度分数
)).collect(Collectors.toList());
}1.7.4 带过滤的搜索 API: filterExpression()
作用:在相似性搜索基础上,添加元数据过滤条件。
@PostMapping("/search-filtered")
public List<Map<String, Object>> searchWithFilter(@RequestParam String query) {
// 1. 构建过滤表达式
FilterExpressionBuilder builder = new FilterExpressionBuilder();
// 2. 构建复合过滤条件
// eq: 等于,gte: 大于等于,lte: 小于等于,in: 在列表中
Filter.Expression filter = builder.and(
builder.eq("category", "framework"), // 分类必须是 framework
builder.eq("version", "1.0"), // 版本必须是 1.0
builder.gte("createTime", System.currentTimeMillis() - 86400000L) // 24 小时内
).build();
// 3. 构建带过滤的搜索请求
SearchRequest searchRequest = SearchRequest.builder()
.query(query)
.topK(10)
.filterExpression(filter) // 应用过滤条件
.build();
// 4. 执行搜索
List<Document> results = vectorStore.similaritySearch(searchRequest);
return results.stream()
.map(doc -> Map.of("content", doc.getContent(), "score", doc.getScore()))
.collect(Collectors.toList());
}1.7.5 删除文档 API: delete()
作用:根据文档 ID 或删除条件删除文档。
@DeleteMapping("/delete")
public String deleteDocuments(@RequestParam List<String> docIds) {
// 方式 1:按 ID 删除
vectorStore.delete(docIds); // docIds 是 Document 的 id 列表
// 方式 2:按条件删除(部分实现支持)
// Filter.Expression filter = new FilterExpressionBuilder()
// .eq("category", "temp")
// .build();
// vectorStore.delete(filter);
return "成功删除 " + docIds.size() + " 篇文档";
}1.7.6 手动向量化 API: EmbeddingModel
作用:独立调用 Embedding 模型,获取文本向量表示。
@GetMapping("/embed")
public Map<String, Object> getEmbedding(@RequestParam String text) {
// 1. 调用 Embedding 模型
// embedding() 方法返回 float[] 向量数组
float[] vector = embeddingModel.embed(text);
// 2. 批量向量化(更高效)
List<String> texts = List.of("文本 1", "文本 2", "文本 3");
List<float[]> vectors = embeddingModel.embed(texts);
// 3. 返回结果
return Map.of(
"text", text,
"vectorLength", vector.length,
"vectorSample", Arrays.copyOfRange(vector, 0, 5) // 只返回前 5 个值示例
);
}1.7.7 距离度量配置
// 不同向量数据库支持不同的距离度量方式
SearchRequest searchRequest = SearchRequest.builder()
.query("查询文本")
.topK(5)
// 部分实现支持指定距离度量
// .distanceType(DistanceType.COSINE) // 余弦相似度(默认)
// .distanceType(DistanceType.EUCLIDEAN) // 欧氏距离
// .distanceType(DistanceType.DOT_PRODUCT) // 点积
.build();1.7.8 向量数据库的使用实例
@Service
public class KnowledgeBaseService {
@Autowired
private VectorStore vectorStore;
@Autowired
private EmbeddingModel embeddingModel;
/**
* 初始化知识库
*/
public void initKnowledgeBase() {
// 1. 准备文档数据
List<Document> documents = List.of(
new Document("Spring AI 支持 OpenAI、Ollama、Azure 等模型",
Map.of("category", "integration", "level", "basic")),
new Document("Vector Store 用于存储文档向量,支持语义搜索",
Map.of("category", "vector", "level", "intermediate")),
new Document("RAG = 检索 + 生成,提升回答准确性",
Map.of("category", "rag", "level", "advanced")),
new Document("Chat Memory 管理多轮对话上下文",
Map.of("category", "memory", "level", "basic")),
new Document("Function Calling 让 AI 调用外部 API",
Map.of("category", "tools", "level", "intermediate"))
);
// 2. 批量添加到向量库
vectorStore.add(documents);
System.out.println("知识库初始化完成,共 " + documents.size() + " 篇文档");
}
/**
* 语义搜索
*/
public List<Map<String, Object>> search(String query, String category, int topK) {
// 1. 构建搜索请求
SearchRequest.Builder builder = SearchRequest.builder()
.query(query)
.topK(topK)
.similarityThreshold(0.5);
// 2. 可选:添加分类过滤
if (category != null && !category.isEmpty()) {
FilterExpressionBuilder fb = new FilterExpressionBuilder();
builder.filterExpression(fb.eq("category", category).build());
}
// 3. 执行搜索
List<Document> results = vectorStore.similaritySearch(builder.build());
// 4. 格式化返回
return results.stream().map(doc -> Map.of(
"content", doc.getContent(),
"category", doc.getMetadata().get("category"),
"level", doc.getMetadata().get("level"),
"score", doc.getScore()
)).collect(Collectors.toList());
}
/**
* 删除指定类别的文档
*/
public int deleteByCategory(String category) {
// 注意:部分 VectorStore 实现不支持按条件删除
// 需要自行维护文档 ID 映射
FilterExpressionBuilder fb = new FilterExpressionBuilder();
Filter.Expression filter = fb.eq("category", category).build();
// 先搜索出符合条件的文档
List<Document> docs = vectorStore.similaritySearch(
SearchRequest.builder().query("*").topK(1000).filterExpression(filter).build()
);
// 再删除
List<String> ids = docs.stream().map(Document::getId).collect(Collectors.toList());
vectorStore.delete(ids);
return ids.size();
}
}二、Document Processing(文档处理)模块
对于文档处理的知识点,我之前也在其他博客有详细讲解:
所以这里就做简单的讲解
2.1 AI 时代的 ETL 管道
传统 ETL (Extract, Transform, Load) 是为数据仓库设计的。AI 时代的 ETL 是为大模型上下文设计的。
- Extract (读取):从 PDF/Word 中提取纯文本,去除格式噪音。
- Transform (转换):分块 (Chunking) 是最核心的转换。
- Load (加载):向量化后存入 Vector Store。
2.2 分块 (Chunking) 的核心权衡
为什么不能把整本书作为一个向量?
- 上下文限制:LLM 的 Context Window 有限(如 128K),全量输入成本高且易丢失细节。
- 检索精度:用户问“第 3 章的密码是多少”,如果整本书是一个向量,检索到的可能是“第 1 章的引言”,因为整体语义相似但局部不相关。
- 噪声干扰:过大的 Chunk 包含过多无关信息,干扰 LLM 判断。
分块策略详解:
- 固定字符分块:简单,但可能切断句子语义。
- 递归字符分块 (Recursive Character):Spring AI 默认推荐。按段落→换行→句子→单词优先级切分,尽量保持语义完整。
- 语义分块 (Semantic Chunking):利用 Embedding 检测文本语义突变点进行切分(成本高,精度高)。
- 父子分块 (Parent-Child):检索小 chunk(精准),但送给 LLM 的是包含该 chunk 的大 chunk(上下文丰富)。
2.3 元数据 (Metadata) 的战略价值
元数据不仅是标签,它是路由和过滤的关键。
- 访问控制:
doc.metadata.permission = "private",检索时过滤掉无权查看的文档。 - 时间衰减:
doc.metadata.year = 2020,用户问“最新政策”,可优先检索 2023-2024 的文档。 - 来源追溯:RAG 回答中标注“据《2023 员工手册》第 5 页”,增加可信度。
2.4 SpringAI的配置
<dependencies>
<!-- PDF 文档读取器 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
<!-- Apache Tika(支持 Word、Excel、PPT 等) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<!-- Markdown 读取器(内置) -->
<!-- 无需额外依赖 -->
</dependencies>2.5 Document 读取器 API 详解
2.5.1 PDF 文档读取器
@Service
public class PdfProcessor {
/**
* 读取 PDF 文件
*/
public List<Document> readPdf(String filePath) {
// 1. 创建 PDF 读取器
// 构造函数参数:文件路径或 Resource 对象
PdfDocumentReader reader = new PdfDocumentReader(filePath);
// 2. 获取文档列表(一个 PDF 可能包含多页,每页一个 Document)
List<Document> documents = reader.get();
System.out.println("读取了 " + documents.size() + " 页 PDF");
return documents;
}
/**
* 读取 PDF 并添加元数据
*/
public List<Document> readPdfWithMetadata(String filePath, Map<String, Object> metadata) {
PdfDocumentReader reader = new PdfDocumentReader(filePath);
List<Document> documents = reader.get();
// 3. 为每个文档添加额外元数据
for (Document doc : documents) {
// getMetadata() 返回可修改的 Map
doc.getMetadata().putAll(metadata);
}
return documents;
}
}2.5.2 Markdown 文档读取器
@Service
public class MarkdownProcessor {
/**
* 读取 Markdown 文件
*/
public List<Document> readMarkdown(String filePath) {
// 1. 创建 Markdown 读取器
MarkdownDocumentReader reader = new MarkdownDocumentReader(filePath);
// 2. 获取文档
// Markdown 通常按章节或固定大小分块
return reader.get();
}
/**
* 从 URL 读取 Markdown(如 GitHub README)
*/
public List<Document> readMarkdownFromUrl(String url) {
// 1. 创建 Resource
Resource resource = new UrlResource(url);
// 2. 创建读取器
MarkdownDocumentReader reader = new MarkdownDocumentReader(resource);
return reader.get();
}
}2.5.3 Tika 文档读取器(多格式支持)
@Service
public class TikaProcessor {
/**
* 读取多种格式文档(Word、Excel、PPT、TXT 等)
*/
public List<Document> readWithTika(String filePath) {
// 1. 创建 Tika 读取器
TikaDocumentReader reader = new TikaDocumentReader(filePath);
// 2. 获取文档
return reader.get();
}
/**
* 批量读取目录下的所有文档
*/
public List<Document> readDirectory(String dirPath) {
List<Document> allDocuments = new ArrayList<>();
// 1. 获取目录下所有文件
File dir = new File(dirPath);
File[] files = dir.listFiles();
if (files != null) {
for (File file : files) {
// 2. 跳过非文件
if (!file.isFile()) continue;
// 3. 读取每个文件
try {
TikaDocumentReader reader = new TikaDocumentReader(file.getPath());
List<Document> docs = reader.get();
// 4. 添加文件名元数据
for (Document doc : docs) {
doc.getMetadata().put("fileName", file.getName());
doc.getMetadata().put("filePath", file.getAbsolutePath());
}
allDocuments.addAll(docs);
} catch (Exception e) {
System.err.println("读取失败:" + file.getName());
}
}
}
return allDocuments;
}
}2.6 文档分块 (Chunking) API 详解
作用:将长文档切分为合适大小的片段,避免超出模型上下文限制,同时保持语义完整性。
2.6.1 递归字符分块器
@Service
public class DocumentSplitter {
/**
* 使用递归字符分块器
*/
public List<Document> splitDocuments(List<Document> documents) {
// 1. 创建分块器
RecursiveCharacterTextSplitter splitter = RecursiveCharacterTextSplitter.builder()
.chunkSize(500) // 每块最大 500 字符
.chunkOverlap(50) // 块之间重叠 50 字符(保持语义连贯)
.separators(List.of( // 分隔符优先级(从大到小)
"\n\n", // 段落
"\n", // 换行
"。", // 中文句号
".", // 英文句号
" ", // 空格
"" // 字符级
))
.build();
// 2. 应用分块
// apply() 方法接受 Document 列表,返回分块后的 Document 列表
List<Document> chunks = splitter.apply(documents);
System.out.println("原始文档:" + documents.size() + " → 分块后:" + chunks.size());
return chunks;
}
/**
* 自定义分块策略
*/
public List<Document> splitWithCustomStrategy(List<Document> documents) {
// 1. 创建分块器
RecursiveCharacterTextSplitter splitter = RecursiveCharacterTextSplitter.builder()
.chunkSize(1000) // 较大块,适合长上下文模型
.chunkOverlap(200) // 较大重叠,保证语义完整
.lengthFunction(text -> text.length()) // 长度计算函数
.build();
return splitter.apply(documents);
}
}2.6.2 按令牌分块器(Token-based)
@Service
public class TokenSplitter {
@Autowired
private EmbeddingModel embeddingModel;
/**
* 按令牌数量分块(更精确控制)
*/
public List<Document> splitByTokens(List<Document> documents) {
// 1. 创建 Token 分块器
TokenTextSplitter splitter = new TokenTextSplitter(
embeddingModel, // 使用 Embedding 模型的 tokenizer
512, // 每块 512 tokens
50, // 重叠 50 tokens
10000, // 最大令牌数限制
true // 是否保持段落完整
);
return splitter.apply(documents);
}
}2.7 文档转换器 API 详解
作用:对文档内容进行转换、清洗、增强。
2.7.1 元数据增强转换器
@Service
public class MetadataEnricher {
/**
* 为文档添加元数据
*/
public List<Document> enrichMetadata(List<Document> documents) {
// 1. 创建转换器
DocumentTransformer transformer = new DocumentTransformer() {
@Override
public List<Document> apply(List<Document> input) {
return input.stream().map(doc -> {
// 2. 复制文档并添加新元数据
Map<String, Object> newMetadata = new HashMap<>(doc.getMetadata());
newMetadata.put("processedTime", System.currentTimeMillis());
newMetadata.put("contentLength", doc.getContent().length());
newMetadata.put("wordCount", doc.getContent().split("\\s+").length);
// 3. 创建新 Document
return new Document(doc.getId(), doc.getContent(), newMetadata);
}).collect(Collectors.toList());
}
};
return transformer.apply(documents);
}
}2.7.2 文本清洗转换器
@Service
public class TextCleaner {
/**
* 清洗文档内容(移除特殊字符、多余空格等)
*/
public List<Document> cleanDocuments(List<Document> documents) {
DocumentTransformer transformer = new DocumentTransformer() {
@Override
public List<Document> apply(List<Document> input) {
return input.stream().map(doc -> {
// 1. 清洗文本
String cleaned = doc.getContent()
.replaceAll("\\s+", " ") // 多余空格变单空格
.replaceAll("\\n{3,}", "\n\n") // 多余换行变双换行
.trim();
// 2. 创建新 Document
return new Document(doc.getId(), cleaned, doc.getMetadata());
}).collect(Collectors.toList());
}
};
return transformer.apply(documents);
}
}2.8 文档处理完整的实例
@Service
public class DocumentIngestionService {
@Autowired
private VectorStore vectorStore;
@Autowired
private EmbeddingModel embeddingModel;
/**
* 完整的文档入库流程
*/
public IngestionResult ingestDocument(String filePath, String category) {
long startTime = System.currentTimeMillis();
try {
// ========== 阶段 1: 读取文档 ==========
List<Document> documents = readDocument(filePath);
System.out.println("阶段 1 完成:读取 " + documents.size() + " 篇文档");
// ========== 阶段 2: 添加元数据 ==========
Map<String, Object> metadata = Map.of(
"category", category,
"source", filePath,
"ingestTime", System.currentTimeMillis()
);
for (Document doc : documents) {
doc.getMetadata().putAll(metadata);
}
System.out.println("阶段 2 完成:元数据增强");
// ========== 阶段 3: 文本清洗 ==========
documents = cleanDocuments(documents);
System.out.println("阶段 3 完成:文本清洗");
// ========== 阶段 4: 文档分块 ==========
RecursiveCharacterTextSplitter splitter = RecursiveCharacterTextSplitter.builder()
.chunkSize(500)
.chunkOverlap(50)
.build();
List<Document> chunks = splitter.apply(documents);
System.out.println("阶段 4 完成:分块为 " + chunks.size() + " 个片段");
// ========== 阶段 5: 向量化并存储 ==========
vectorStore.add(chunks);
System.out.println("阶段 5 完成:向量存储");
// ========== 返回结果 ==========
return IngestionResult.builder()
.success(true)
.originalDocs(documents.size())
.chunks(chunks.size())
.duration(System.currentTimeMillis() - startTime)
.build();
} catch (Exception e) {
e.printStackTrace();
return IngestionResult.builder()
.success(false)
.error(e.getMessage())
.duration(System.currentTimeMillis() - startTime)
.build();
}
}
/**
* 根据文件类型选择读取器
*/
private List<Document> readDocument(String filePath) {
if (filePath.endsWith(".pdf")) {
return new PdfDocumentReader(filePath).get();
} else if (filePath.endsWith(".md")) {
return new MarkdownDocumentReader(filePath).get();
} else {
return new TikaDocumentReader(filePath).get();
}
}
/**
* 文本清洗
*/
private List<Document> cleanDocuments(List<Document> documents) {
return documents.stream().map(doc -> {
String cleaned = doc.getContent()
.replaceAll("\\s+", " ")
.replaceAll("\\n{3,}", "\n\n")
.trim();
return new Document(doc.getId(), cleaned, doc.getMetadata());
}).collect(Collectors.toList());
}
// 结果对象
@Data
@Builder
public static class IngestionResult {
private boolean success;
private int originalDocs;
private int chunks;
private long duration;
private String error;
}
}总结
那么今天也是讲解了Embedding和Document,接下来会是ChatMemory与RAG的使用!


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 22
22 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)