【山东大学软件学院创新项目实训】(三)大模型微调调研
蒸馏:
通常⽤于通过将⼤模型(教师模型)的知识转移到⼩模型(学⽣模型)中,使得⼩ 模型能够在尽量保持性能的同时,显著减少模型的参数量和计算需求。
SFT有监督微调Supervised Fine-Tuning:通过提供⼈⼯标注的数据,进⼀步训练预训练模型,让模型能够更加精准地处理特定领域的 任务 除了 “ 有监督微调 ” ,还有 “ ⽆监督微调 ”“ ⾃监督微调 ” ,当⼤家提到 “ 微调 ” 时通常是指有监督微调。
提⾼模型对企业专有信息的理解、增强模型在特定⾏业领域的知识
案例⼀:希望⼤模型能更好理解蟹堡王的企业专有知识,如蟹⽼板的⼥⼉为什么是⼀头 鲸⻥
案例⼆:希望⼤模型能特别精通于汉堡制作,并熟练回答关于汉堡⾏业的所有问题
RLHF强化学习Reinforcement Learning from Human Feedback:
DPO ( Direct Preference Optimization ) 核⼼思想:通过 ⼈类对⽐选择(例如: A 选项和 B 选项,哪个更好)直接优化⽣成模型,使 其产⽣更符合⽤户需求的结果;调整幅度⼤
提供个性化和互动性强的服务
案例三:希望⼤模型能够基于顾客的反馈调整回答⽅式,⽐如⽣成更⼆次元⻛格的回答 还是更加学术⻛格的回答
RAG检索增强生成:
将外部信息检索与⽂本⽣成结合,帮助模型在⽣成答案时,实时获取外部信息和最新信息
提⾼模型对企业专有信息的理解、增强模型在特定⾏业领域的知识、获取和⽣成最新的、实时的信息
案例四:希望⼤模型能够实时获取蟹堡王的最新的促销活动信息和每周菜单更新
微调算法分类:
全参数微调( Full Fine-Tuning ): 对整个预训练模型进⾏微调,会更新所有参数。
优点:因为每个参数都可以调整,通常能得到最佳的性能;能够适应不同任务和场 景
缺点:需要较⼤的计算资源并且容易出现过拟合
部分参数微调( Partial Fine-Tuning ): 只更新模型的部分参数(例如某些层或模块)
优点:减少了计算成本;减少过拟合⻛险;能够以较⼩的代价获得较好的结果
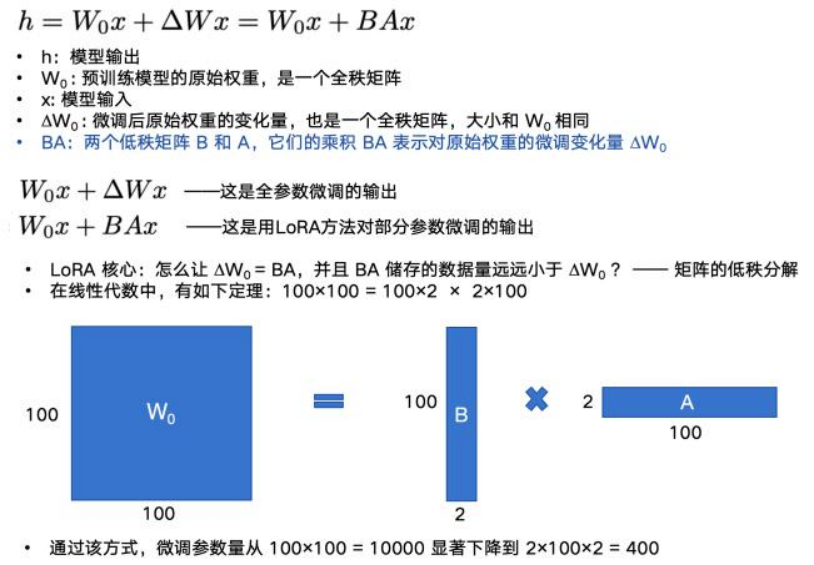
缺点:可能⽆法达到最佳性能 最著名算法: LoRA
LoRA:通过低秩矩阵分解的方法进行部分参数微调。
测试指标:
Perplexity(困惑度) 是衡量一个语言模型对文本流畅性掌握程度的指标。
本质上是:模型有多“惊讶”文本是这样的。

BERTScore 是一种基于语义理解的文本相似性度量方法。
不是简单比对单词,而是用深层语义向量去对比!
适合用来衡量:
生成的故事有没有偏离推荐单词的意义?
生成内容是否合理连贯?
它不是比字面是否一样,而
用一个强大的预训练模型(比如 BERT、RoBERTa、DeBERTa)把句子编码成一组词向量。
计算生成文本和参考文本之间每个词的向量相似度(cosine similarity)。
最后综合这些相似度,给出 Precision、Recall、F1 分数。
是比“意思有没有跑偏”。
BLEU是一种用于评估机器翻译结果质量的指标。它主要侧重于衡量机器翻译输出与参考翻译之间的相似程度,着重于句子的准确性和精确匹配。BLEU通过计算N-gram(连续N个词)的匹配程度,来评估机器翻译的精确率(Precision)。
ROUGE是一种用于评估文本摘要(或其他自然语言处理任务)质量的指标。与BLEU不同,ROUGE主要关注机器生成的摘要中是否捕捉到了参考摘要的信息,着重于涵盖参考摘要的内容和信息的完整性。ROUGE通过计算N-gram的共现情况,来评估机器生成的摘要的召回率(Recall)。
BLEU侧重于衡量翻译的准确性和精确匹配程度,更偏向于Precision,而ROUGE侧重于衡量摘要的信息完整性和涵盖程度,更偏向于Recall。
n代表连续的n个词的组合。"n"可以是1、2、3,或者更高。
- 1-gram:也称为unigram,是指单个的词语。例如,在句子 "我喜欢学习自然语言处理。" 中的1-gram为:["我", "喜欢", "学习", "自然语言处理", "。"]
- 2-gram:也称为bigram,是指两个连续的词语组合。例如,在句子 "我喜欢学习自然语言处理。" 中的2-gram为:["我喜欢", "喜欢学习", "学习自然语言处理", "自然语言处理。"]
- 3-gram:也称为trigram,是指三个连续的词语组合。例如,在句子 "我喜欢学习自然语言处理。" 中的3-gram为:["我喜欢学习", "喜欢学习自然语言处理", "学习自然语言处理。"]
n-gram在自然语言处理中是一种常用的技术,特别在机器翻译、文本摘要和语言模型等任务中广泛使用。使用n-gram可以捕捉一定长度的上下文信息,有助于更好地理解文本和评估翻译质量。例如,在机器翻译中,使用n-gram可以帮助评估系统生成的翻译与参考翻译之间的相似程度。
参考翻译: "今天天气晴朗。"
系统生成的翻译: "今天的天气是晴朗的。"
我们将使用这两个句子来计算BLEU和ROUGE指标。
BLEU指标计算过程:
a. 首先,我们将参考翻译和系统生成的翻译拆分成n-gram序列。n-gram是连续n个词的组合。
参考翻译的1-gram:["今天", "天气", "晴朗", "。"]
系统生成的翻译的1-gram:["今天", "的", "天气", "是", "晴朗", "的", "。"]
b. 接下来,我们计算系统生成的翻译中n-gram与参考翻译中n-gram的匹配数。例如,1-gram中有4个匹配:["今天", "天气", "晴朗" "。”]
c. 计算BLEU的精确度(precision):将系统生成的翻译中的匹配数除以系统生成的翻译的总n-gram数。在这里,精确度为4/7。
d. 由于较长的翻译可能具有较高的n-gram匹配,我们使用短文本惩罚(brevity penalty)来调整精确度。短文本惩罚可以防止短翻译在BLEU中得分过高。
短文本惩罚是指一种在计算BLEU分数时用于调整精确度的机制,它旨在防止短翻译得分过高;在BLEU评估中用于平衡长翻译和短翻译的得分。它通过比较翻译结果的长度与参考文本的长度来计算,如果翻译结果较短,会给予一定的惩罚,从而降低其BLEU分数。通过这种方式,短文本惩罚确保了长翻译和短翻译在BLEU分数上的公平比较,避免了短翻译因为匹配n-gram少而获得不合理的高分。
e. 最后,计算BLEU得分:BLEU = 短文本惩罚 * exp(1/n * (log(p1) + log(p2) + ... + log(pn)))
其中,p1, p2, ..., pn是1-gram, 2-gram, ..., n-gram的精确度,n是n-gram的最大长度。
ROUGE指标计算过程:着重于信息完整性和涵盖程度
a. ROUGE指标是用于评估文本摘要任务的,因此我们将参考翻译和系统生成的翻译视为两个文本摘要。
b. 首先,我们计算系统生成的翻译中包含的n-gram在参考翻译中出现的次数。
c. 接下来,计算召回率(recall):将匹配的n-gram总数除以参考翻译中的总n-gram数。例如,1-gram中有3个匹配,参考翻译总共有4个1-gram,因此召回率为3/4。
d. ROUGE得分可以根据需要使用不同的n-gram大小,通常使用ROUGE-1、ROUGE-2和ROUGE-L。
ROUGE-1 = 召回率(系统生成的1-gram匹配数 / 参考翻译中的1-gram总数)
ROUGE-2 = 召回率(系统生成的2-gram匹配数 / 参考翻译中的2-gram总数)
ROUGE-L = 最长公共子序列(Longest Common Subsequence,LCSS)的长度 / 参考翻译的总长度
https://zhuanlan.zhihu.com/p/647310970

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)