RAG 冠军项目
RAG 冠军项目学习分解~更新中(后续更新代码细节)
最近我系统学习了一个企业知识库 RAG 项目实战。最开始我以为 RAG 就是“把 PDF 扔进向量数据库,然后提问”,但真正结合开源项目代码一路看下来,我发现自己之前对 RAG 的理解其实非常浅。
老规矩先看定义:
RAG(Retrieval-Augmented Generation,检索增强生成)
指一种问答/生成方法:在大模型生成答案之前,先从外部知识库中检索相关信息,再把这些检索结果作为上下文提供给大模型,由大模型基于这些外部证据生成答案。
项目地址:https://github.com/llyaRice/RAG-Challenge-2
比赛网址: https://github.com/trustbit/enterprise-rag-challenge/tree/main
这次学习对我最大的帮助,不是记住了几个名词,而是终于把一条完整的链路串起来了:
PDF 解析 -> 文本整理 -> 分块 -> 向量化 -> 检索 -> 重排 -> 上下文增强 -> LLM 回答 -> 引用页校验
更重要的是,我开始理解:RAG 的本质不是“接一个大模型”,而是“把对的证据,以对的形式,在对的时机交给模型”。
一、为什么这个项目值得学
这个项目参考的是企业 RAG 比赛冠军方案。主线非常清楚:系统围绕公司年报问答展开,重点包括:
- 基础 RAG 系统流程
- PDF 解析与 Docling 优化
- 内容提取(Ingestion)
- 检索(Retrieval)
- LLM 重排序(LLM reranking)
- 父页面检索(Parent Page Retrieval)
- 结构化输出与 Prompt 设计
这是一个“从理论到工程”的完整案例;从代码视角看,它不是教程型 Demo,而是真正为了比赛成绩不断做优化的工程型项目。
也正因为如此,它特别适合用来回答一个问题:
RAG 在真实项目里,到底是怎么跑起来的?
二、RAG
我之前对 RAG 的理解大概是这样的:
- 把文档转成文本
- 切块
- 做 embedding
- 放进向量数据库
- 问题来了就检索几个 chunk
- 拼给 LLM 回答
这个理解不能说错,但太“平面化”了。真正看完项目以后,我发现至少有 5 个问题必须想清楚,否则对 RAG 的理解是不完整的。
1. 为什么要分块,不能直接整篇检索?
一开始我觉得,整篇文档不是信息更全吗?为什么还要切碎?
后来我明白了,分块的核心不是为了“切”,而是为了提高检索粒度。
如果整篇文档直接做向量表示,会有两个问题:
- 一篇文档里混着很多主题,语义被稀释
- 即使检索到了,也无法把整篇文档高效交给模型
所以 chunk 的作用,是把“检索单元”变小,让系统更容易找到真正相关的证据。
换句话说:
分块不是为了拆文档,而是为了让检索变精准。
2. 为什么 chunk 要保留 page?
我之前觉得,保留 page 只是为了“以后好找原文”。
后来结合项目代码和比赛要求,我发现它至少有三层意义:
- 为了溯源,能回到原始页面
- 为了给答案附引用页码
- 为了降低幻觉,方便人工复核
在企业知识库、财报问答这类场景里,“答案对不对”还不够,还得回答:
这个答案是从哪一页来的?
所以 metadata 不是可有可无的附属品,而是 RAG 系统可信性的基础。
3. 向量检索和 rerank 分别解决什么问题?
这是我之前理解得最模糊的一点。
现在我更愿意这样理解:
- 向量检索解决召回问题
先从海量 chunk 里找出“可能相关”的候选集合 - rerank 解决排序问题
再从候选集合里把“最适合回答问题”的内容排到前面
也就是说:
- 向量检索像海选
- rerank 像复试
需要反复强调了一点:检索不是一次性完成的,而是分阶段完成的。
先“找得到”,再“排得准”。
4. 为什么 prompt 里要强制结构化输出?
结构化输出真正解决的是系统可用性。
因为在企业问答里,系统不只是要一句自然语言回答,它还要稳定输出:
- 最终答案
- 推理摘要
- 相关页码
- 详细分析
- 必要时返回 N/A
如果没有结构化输出,模型每次回答风格都不一样,后处理、评测、引用校验都会变得很麻烦。
所以这里的 prompt 设计不是“锦上添花”,而是“工程必需”。
5. base -> pdr -> rerank 这几个版本到底在提升什么?
- base:基础向量检索版
- pdr:Parent Document Retrieval,也就是父页面/父文档检索
- rerank:在召回结果上再做重排
它们各自提升的是不同层面:
- base 解决“能不能先找到相关内容”
- pdr 解决“给模型的上下文够不够完整”
- rerank 解决“候选内容里谁应该排在最前面”
所以这几个版本不是简单叠加功能,而是在不断修正一个问题:
如何把最有用、最完整、最可信的上下文交给 LLM。
三、项目的真实技术链路
结合课程内容和我阅读的 RAG-cy 代码,这个项目的实际流程可以概括成下面这条线:
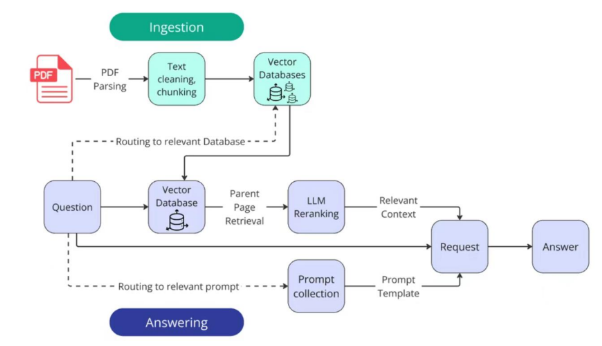
@来源~陈博士大模型开发课程(知乎)
PDF -> Markdown -> chunk JSON -> embedding -> FAISS -> retrieval_results -> rag_context -> LLM
具体来说:
- 先把 PDF 转成 Markdown
- 再把 Markdown 按行切成 chunk,保存为 JSON
- 每个 chunk 的 text 做 embedding,建立向量库
- 问题来了以后,问题本身也做 embedding
- 在 FAISS 里找到最相近的 chunk
- 取回这些 chunk 对应的文本
- 拼成 rag_context
- 再把 rag_context + question 一起发给 LLM
其中还涉及两个路由Routing(虚线):
第一个路由是根据问题从不同的PDF文档中选出有关的向量库,进而提高检索效率。
第二个路由是,针对不同性质的问题,给LLM的提示词是不一样的,类似于分诊台的想法,提高模型的准确性
四、关键工程点
1. Parsing (数据预处理的重要性)
PDF 解析可以说是重要的地基:表格、多栏、页眉页脚、图片、公式、旋转表格等等。
但现在我更认同一句话:
垃圾解析结果,后面不可能靠检索补回来。
如果 PDF 转出来的内容混乱、表格结构丢失、页码不准,那么:
- chunk 会切错
- 检索会召回错误内容
- 模型就只能基于错误上下文作答
也就是说,RAG 的上限,很多时候取决于 Parsing。
################################################################
PDF
-> Docling 解析
-> 01_parsed_reports
-> 页级清洗/合并
-> 02_merged_reports
-> 导出 Markdown
-> 03_reports_markdown
-> 按页分 chunk
-> databases/chunked_reports
-> embedding + FAISS
#################################################################
真正的复杂预处理,不是:PDF -> 一大段文字 -> chunk 而是:
PDF -> 页面里的结构块 -> 项目自己的结构化 JSON -> 页级语义重组 -> chunk
我们只看原版项目里第一页这一小段内容:
Securities registered pursuant to Section 12(b) of the Act:
| Title of each class | Trading symbol(s) | Name of each exchange on which registered |
| Common Stock, par value $0.0001 | HLLY | New York Stock Exchange |
| Warrants to Purchase Common Stock | HLLY WS | New York Stock Exchange |
你可以把它理解成“PDF里的一段标题 + 一张表”。
1. 在 PDF 里,人眼看到的大概是这样
Securities registered pursuant to Section 12(b) of the Act:
Title of each class Trading symbol(s) Name of each exchange on which registered
Common Stock, par value $0.0001 HLLY New York Stock Exchange
Warrants to Purchase Common Stock HLLY WS New York Stock Exchange
这时候对人来说很清楚,但对程序来说还不够,因为程序还不知道:
- 哪一行是标题
- 哪一块是表格
- 表格有几行几列
- 这段在第几页
2. Docling 原始输出后,变成“结构块 + 引用”
这时候它不是一大段文字了,而是这种风格:
{
"body": {
"children": [
{"$ref": "#/texts/21"},
{"$ref": "#/tables/0"},
{"$ref": "#/texts/22"}
]
}
}
意思是:
- 先出现一个文本块 texts/21
- 接着出现一张表 tables/0
- 然后再出现下面的正文 texts/22
而 texts/21 本身长这样:
{
"self_ref": "#/texts/21",
"label": "section_header",
"text": "Securities registered pursuant to Section 12(b) of the Act:"
}
tables/0 本身不是纯文本,而是结构化表格:
{
"self_ref": "#/tables/0",
"data": {
"num_rows": 3,
"num_cols": 3,
"grid": [
["Title of each class", "Trading symbol(s)", "Name of each exchange on which registered"],
["Common Stock, par value $0.0001", "HLLY", "New York Stock Exchange"],
["Warrants to Purchase Common Stock", "HLLY WS", "New York Stock Exchange"]
]
}
}
这一步最关键的变化是:
程序已经知道“这是一个标题块 + 一张表”,不是普通连续文本。
3. 项目自己的结构化 JSON,会把页面整理成“按顺序的块列表”
到了项目的 01_parsed_reports,同一段会变成这样:
{
"page": 1,
"content": [
{
"text": "Securities registered pursuant to Section 12(b) of the Act:",
"type": "section_header",
"text_id": 21
},
{
"type": "table",
"table_id": 0
},
{
"text": "Indicate by check mark if the registrant is a well-known seasoned issuer...",
"type": "text",
"text_id": 22
}
]
}
注意这里:
- 标题保留了
- 表格位置也保留了
- 但表格正文还没直接塞进页面文本
- 页面里现在只是一个 table_id: 0
与此同时,表格单独保存成:
{
"table_id": 0,
"page": 1,
"markdown": "| Title of each class | Trading symbol(s) | Name of each exchange on which registered |\n|---|---|---|\n| Common Stock, par value $0.0001 | HLLY | New York Stock Exchange |\n| Warrants to Purchase Common Stock | HLLY WS | New York Stock Exchange |"
}
这一步你要抓住一句话:
页面里先放“表格占位符”,真正表格内容单独存。
4. 页级清洗后,才真正变成适合 RAG 的文本
到了 02_merged_reports,这一段会被重写成:
## Securities registered pursuant to Section 12(b) of the Act:
| Title of each class | Trading symbol(s) | Name of each exchange on which registered |
|-----------------------------------|---------------------|---------------------------------------------|
| Common Stock, par value $0.0001 | HLLY | New York Stock Exchange |
| Warrants to Purchase Common Stock | HLLY WS | New York Stock Exchange |
你看见没有,这里发生了真正重要的事:
- section_header 被转成了 ##
- table_id = 0 不见了
- 表格真实内容被回填进来了
- 现在这一页已经变成“适合检索”的干净文本了
这一步就是最核心的数据预处理。不是抽字,而是:把结构块重新组织成语义更清晰的页文本。
5. 最后再切成 chunk
到了最终给向量库的 chunk,大概会变成这样:
{
"page": 1,
"text": "## Securities registered pursuant to Section 12(b) of the Act:"
}
下一个 chunk:
{
"page": 1,
"text": "| Title of each class | Trading symbol(s) | Name of each exchange on which registered |\n|---|---|---|\n| Common Stock, par value $0.0001 | HLLY | New York Stock Exchange |\n| Warrants to Purchase Common Stock | HLLY WS | New York Stock Exchange |"
}
再下一个 chunk 可能就是表格后面的正文。
所以最后送去 embedding 的不是原 PDF,也不是表格坐标,而是:
- 干净的标题文本
- 干净的表格文本
- 干净的正文文本
- 且保留页码
你现在只要记住这个最小例子就够了
原始 PDF 里的:
标题 + 表格
先变成:
标题块 + 表格引用
再变成:
页面块列表 + 表格单独实体
再变成:
标题 + 真正表格文本
最后变成:
page=1 的多个 chunk
最短总结就是:
复杂预处理的本质,是先识别结构,再把结构重写成适合检索的文本。
如果你愿意,我下一条继续用这种方式,直接把“列表”再举一个真实例子给你看,比如:
一段正文 + 多个 bullet list
是怎么从 Docling 变成最终 RAG chunk 的。
################################################################
2. 表格是 RAG 里最容易被低估的问题
大型表格往往会削弱 chunk 的语义连贯性。
原因很简单:
- 横向表头和纵向内容离得很远
- 一个表格未必能完整塞进一个 chunk
- 就算塞进了,模型也未必能正确理解列和行的对应关系
表格序列化理论上很有希望,但在实际测试里未必真的提升效果。
一个很实用的经验是:
- 对人和 LLM 都友好的表格格式,Markdown 是一个方案
- 但在复杂表格、合并单元格场景里,HTML 往往更强
这也是为什么我现在不会再简单地说“把表格转成文本就行”。
3. Metadata (用于PDR)
metadata 是 text 以外的重要信息,比如 page。
RAG 系统里常见的 metadata 包括:
- 页码
- 文档名
- 公司名
- 时间
- 章节号
- 文档类型
这些信息不仅服务于溯源,也能参与路由、过滤和答案生成。
一个真正能落地的企业知识库系统,绝不是只有“文本向量”这一种信息。
4. Small-to-Big 思路
项目里的 Parent Document Retrieval(PDR) 实际是一种 small-to-big思想。
它的思想很简单:
- 先用小粒度内容召回
- 再扩展到更完整、更大的上下文
为什么这样做有效?
因为小 chunk 更容易精准命中,但小 chunk 往往上下文不完整;而大页内容更完整,但直接检索又不够精细。所以真正好的做法往往不是二选一,而是:用小粒度检索,用大粒度回答。
5、BM25
项目里有 BM25Ingestor 和 BM25Retriever,所以实际上采用了“关键词检索 + 向量检索”的混合搜索。
因为从经验上看,混合检索通常更强:
- BM25 擅长精确关键词命中
- 向量检索擅长语义召回
- 再加 rerank,效果往往更好
但我实际看完 RAG-cy 以后发现,这版中文改造流程里:
- 主流程没有真正接入 BM25
- 问答时实际用的是 VectorRetriever 或 HybridRetriever
- 这里的 HybridRetriever 指的是“向量检索 + LLM 重排”,不是“向量 + BM25”
更有意思的是,这版 BM25 对中文的分词方式还是简单 split(),这对中文其实并不友好。
五、总结
经过这次学习,我对 RAG 的理解发生了一个明显变化。
我以前理解的是:
RAG = 检索 + 生成
我现在更愿意理解为:
RAG = 围绕“证据质量”展开的一整套系统设计
它至少包括:
- 文档能不能被正确解析
- chunk 怎么切
- metadata 怎么保留
- 用什么方式检索
- 是否需要 rerank
- 是否需要 small-to-big
- 最终怎么把上下文拼给模型
- 输出是否结构化
- 能不能回溯到引用页码
也就是说,RAG 的难点从来不只是“接一个向量库”。
真正难的是:
怎样让模型基于可靠证据回答,而不是基于模糊印象回答。
六、一些问题与思考
Q:冠军模型用的LLM 的reranking 模型是什么?
o3-mini,通过prompt的方式让它扮演 reranking的专家
Q:为什么要用基于LLM的重排序?
由于query和pdf的文字内容都是文字,而大模型是在语言空间内进行重排序,这样比传统的用query 与 向量数据库之间的相似度计算更准确,但速度会比较慢;。
Q:Top-K 大于多少阈值才需要重排序?太小就不需要重排序了吧
Top-K 一般要大于30,因为在分chunk一般如果想精细化会在500token,放入一个chunk,表格和图片orc后的另说。
30个chunk*500token=15000
Q:拓展可以在哪里进行?
agentic下工具调用,MLLM,多轮对话
Q:那切分时表格必须在一个切分块吧?
建议放到一个chunk(可能这个chunk >500,比如不超过 20%的buffer,如果表格 <=600,可以用完整的一个)
1200token => 拆分成2个表格(表头)
Q:不切分表格或者图片会咋样?有一些不切分是不是效果更好?比如一个人一份简历就是完整检索召回不会效果更好吗?
如果想要效果好,可以做一些分隔符标记,比如 ====,具体案例具体分析。
Q:业界会用按照章节号和chunk size结合方式来切分吗?
大纲,有章节号,可以直接用章节号进行切分
可以让LLM进行语义切分,chunk size是软规则,建议 chunk_size不要超过500
Q:那切分时表格必须在一个切分块吧
以及标书空白页、格式等20项检查。有什么好的方案实现
给示例,让LLM来检查,人工先标注做为种子示例,让LLM对其他的文档进行标注
Q:切片是算法工程师做吗?还是产品+算法工程师
chunk 可以让产品经理,也可以让算法工程师来进行设计
Q:将一本书的PDF放进去解析,太大了,如何操作
MinerU,1000页
1-100页,100-200页拆分分别处理
Q:有图像时,与文字的向量空间怎么对齐
1)都转化成文字的向量空间
可以利用 Qwen-VL 对图像进行语义理解 => 输出文本
2)图embedding(vec_size=768), 就不能与文字向量(vec_size=1024)进行匹配,需要进行size对齐,但会影响图片质量,建议第一种,目前多模态空间还是有更大的幻觉问题
Q:要给客户,构建知识库 =>
方法1:就用原始数据 => 向量数据库
方法2:对原始数据进行整理,summary
level1:摘要内容
level2:完整的全文
small-to-big
small:摘要
big:全文
当用户提问一个问题的时候,我们可以从 level1的角度进行召回,如果想要回答的更细,可以给LLM,level2数据
CoT, Step by Step
七、如果我要自己搭一个企业知识库,我会重点盯这几件事
如果让我自己做一个企业知识库 RAG,我会优先关注:
- 先把 Parsing 做对,尤其是表格和页码
- chunk 设计不要只盯 token 数,要结合章节、页面和业务结构
- metadata 一定要保留
- 先做基础向量检索,再考虑 rerank
- 如果回答需要完整上下文,优先考虑 small-to-big 或 parent page retrieval
- 输出一定要结构化,方便评测、调试和溯源
- 不要迷信“理论上更强”的模块,必须做实验
八、这次学习后,我给自己的一个复习框架
如果以后我再复习 RAG,我会反复问自己下面这几个问题:
- 文档是怎么从 PDF 变成可检索文本的?
- chunk 为什么要这样切?
- 向量检索召回了什么?有没有漏掉关键内容?
- rerank 到底排的是什么?
- 最终喂给 LLM 的上下文是什么样子?
- 输出为什么必须结构化?
- 这个系统如何证明答案来自原文?
如果这 7 个问题都能回答清楚,我觉得才算是真的把一个 RAG 项目学懂了。
结语
这次最大的收获,不是我学会了几个新模块,而是我对 RAG 的认知从“工具调用”变成了“系统设计”。
RAG 不是一句“接知识库”就能概括的东西,它是一条完整的数据流和证据流。
从课程、笔记到代码,我现在越来越认同一句话:
大模型决定回答上限,检索系统决定回答下限。
而一个好的 RAG 系统,真正做的事情就是:
尽可能把下限抬高。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)