结构动力学仿真-主题096-仿真数据驱动的工程决策支持系统
·
主题096:仿真数据驱动的工程决策支持系统
一、引言
1.1 工程决策的挑战
在现代工程实践中,决策的复杂性日益增加:
- 数据爆炸:仿真产生的数据量呈指数级增长
- 多源异构:来自不同仿真工具、实验测试和现场监测的数据需要整合
- 实时性要求:工程决策需要在有限时间内完成
- 不确定性管理:仿真结果存在不确定性,需要量化分析
1.2 仿真数据驱动决策的优势
仿真数据驱动的工程决策支持系统具有以下优势:
- 知识积累:将仿真经验转化为可复用的知识库
- 快速响应:基于历史数据快速预测新场景
- 优化决策:通过数据分析找到最优设计方案
- 风险管理:量化不确定性,降低决策风险
1.3 本主题内容概述
本主题将介绍三个核心案例:
- 仿真数据管理与可视化:建立高效的数据管理系统
- 基于机器学习的仿真结果预测:利用AI加速仿真分析
- 数字孪生技术在结构健康监测中的应用:实现虚实融合的智能监测



二、理论基础
2.1 仿真数据生命周期管理
2.1.1 数据采集与存储
仿真数据的全生命周期包括:
数据采集阶段
原始数据 → 预处理 → 特征提取 → 数据存储
数据类型
- 结构化数据:模型参数、材料属性、边界条件
- 时序数据:动力响应、振动信号
- 空间数据:应力场、变形场
- 元数据:仿真配置、版本信息、执行时间
存储策略
- 关系型数据库:适合结构化参数数据
- 时序数据库:适合监测数据存储
- 文件系统:适合大体积场数据
- 对象存储:适合非结构化数据
2.1.2 数据质量控制
数据清洗流程
- 缺失值处理:插值、删除或填充
- 异常值检测:统计方法或机器学习方法
- 数据归一化:消除量纲影响
- 数据验证:与理论值或实验值对比
数据质量指标
- 完整性:数据缺失比例
- 准确性:与参考值的偏差
- 一致性:多源数据的一致性
- 时效性:数据更新频率
2.2 机器学习在仿真中的应用
2.2.1 代理模型(Surrogate Model)
代理模型是用机器学习模型替代复杂仿真的技术:
常用代理模型类型
- 高斯过程回归(GPR):适合小样本、提供不确定性估计
- 神经网络(NN):适合大数据、高维问题
- 支持向量机(SVM):适合非线性回归
- 多项式混沌展开(PCE):适合不确定性量化
代理模型构建流程
设计实验(DOE) → 仿真计算 → 特征工程 → 模型训练 → 验证评估
2.2.2 降维技术
高维仿真数据的降维方法:
主成分分析(PCA)
X ∈ R^(n×m) → PCA → Z ∈ R^(n×k), k << m
本征正交分解(POD)
特别适合动力学问题的降维:
u(x,t) ≈ Σ a_i(t) φ_i(x)
其中φ_i(x)是空间基函数,a_i(t)是时间系数。
2.3 数字孪生技术
2.3.1 数字孪生架构
数字孪生的三层架构:
物理层
- 实际结构或设备
- 传感器网络
- 数据采集系统
模型层
- 高保真仿真模型
- 数据驱动模型
- 混合模型
应用层
- 可视化界面
- 决策支持系统
- 预测性维护
2.3.2 虚实融合技术
模型更新策略
- 离线更新:定期用新数据重新训练模型
- 在线更新:实时调整模型参数
- 混合更新:结合物理模型和数据驱动模型
数据同化方法
- 卡尔曼滤波
- 粒子滤波
- 变分同化
三、案例1:仿真数据管理与可视化
3.1 案例背景
某大型工程项目涉及数百次结构动力学仿真,需要建立统一的数据管理系统来:
- 存储和管理仿真数据
- 支持快速检索和对比分析
- 生成可视化报告
- 支持决策制定
3.2 数据管理系统设计
3.2.1 数据模型设计
核心数据表结构
# 仿真项目表
SimulationProject = {
'project_id': '唯一标识',
'name': '项目名称',
'description': '项目描述',
'created_date': '创建日期',
'status': '项目状态'
}
# 仿真案例表
SimulationCase = {
'case_id': '唯一标识',
'project_id': '所属项目',
'case_name': '案例名称',
'model_type': '模型类型',
'parameters': '参数字典',
'results_summary': '结果摘要'
}
# 时序数据表
TimeSeriesData = {
'data_id': '唯一标识',
'case_id': '所属案例',
'variable_name': '变量名',
'time_array': '时间数组',
'value_array': '数值数组',
'sampling_rate': '采样率'
}
3.2.2 数据可视化技术
多维度可视化
- 时间序列图:展示动态响应
- 频谱图:频率域分析
- 散点矩阵:多参数关系
- 热力图:参数敏感性
- 3D场图:空间分布
交互式可视化
- 缩放和平移
- 数据筛选
- 动态更新
- 多视图联动
3.3 Python实现
案例1的Python程序将实现:
- 仿真数据的数据库管理
- 多维度数据可视化
- 交互式数据探索
- 自动化报告生成
四、案例2:基于机器学习的仿真结果预测
4.1 案例背景
某桥梁设计需要评估数千种参数组合的动力响应,传统仿真计算耗时巨大。采用机器学习方法:
- 用少量仿真样本训练代理模型
- 快速预测新参数组合的响应
- 识别关键设计参数
4.2 代理模型构建
4.2.1 实验设计(DOE)
拉丁超立方采样(LHS)
from pyDOE import lhs
# 3个设计参数,50个样本
samples = lhs(3, samples=50)
自适应采样
- 在响应变化剧烈区域增加采样点
- 基于不确定性估计选择新采样点
4.2.2 高斯过程回归
数学模型
f(x) ~ GP(m(x), k(x,x'))
其中:
- m(x) = E[f(x)] 是均值函数
- k(x,x’) = E[(f(x)-m(x))(f(x’)-m(x’))] 是核函数
常用核函数
- 径向基函数(RBF)
- Matérn核
- 有理二次核
4.3 模型验证与不确定性量化
验证指标
- 均方根误差(RMSE)
- 决定系数(R²)
- 最大绝对误差
- 置信区间覆盖率
不确定性量化
- 预测方差分析
- 敏感性分析
- 误差传播分析
4.4 Python实现
案例2的Python程序将实现:
- 拉丁超立方采样
- 高斯过程回归模型
- 神经网络代理模型
- 模型对比与验证
- 参数敏感性分析
五、案例3:数字孪生技术在结构健康监测中的应用
5.1 案例背景
某大跨度桥梁安装了结构健康监测系统(SHM),需要:
- 实时监测结构状态
- 预测剩余使用寿命
- 指导维护决策
- 评估极端事件后的安全性
5.2 数字孪生系统架构
5.2.1 系统组成
物理实体
- 桥梁结构
- 传感器网络(加速度计、应变计、位移计、温度计)
- 数据采集与传输系统
虚拟模型
- 有限元模型
- 损伤识别模型
- 退化预测模型
连接与同步
- 数据同化算法
- 模型更新机制
- 实时可视化
5.2.2 损伤识别方法
基于振动的损伤识别
- 固有频率变化
- 模态振型变化
- 模态阻尼变化
- 柔度矩阵变化
基于机器学习的损伤识别
- 特征提取(小波变换、希尔伯特变换)
- 分类器训练(SVM、随机森林、神经网络)
- 损伤定位与定量
5.3 预测性维护
5.3.1 退化模型
物理退化模型
- 疲劳裂纹扩展
- 腐蚀速率模型
- 混凝土碳化
数据驱动退化模型
- 时间序列预测(ARIMA、LSTM)
- 生存分析
- 贝叶斯更新
5.3.2 维护决策优化
决策框架
状态评估 → 剩余寿命预测 → 维护策略优化 → 决策执行
优化目标
- 最小化全寿命周期成本
- 最大化结构可靠性
- 平衡安全性与经济性
5.4 Python实现
案例3的Python程序将实现:
- 传感器数据模拟与采集
- 模态参数识别
- 损伤检测算法
- 剩余寿命预测
- 数字孪生可视化
六、总结与展望
6.1 关键技术总结
本主题介绍了仿真数据驱动工程决策的三大核心技术:
-
数据管理技术
- 数据生命周期管理
- 多维度可视化
- 质量控制方法
-
机器学习技术
- 代理模型构建
- 降维技术
- 不确定性量化
-
数字孪生技术
- 虚实融合架构
- 数据同化方法
- 预测性维护
6.2 工程应用价值
- 提高效率:减少重复仿真,加速设计迭代
- 降低成本:优化维护策略,延长结构寿命
- 提升安全:实时监测预警,预防灾难性失效
- 支持决策:量化不确定性,提供科学依据
6.3 发展趋势
- 自动化:从数据到决策的全流程自动化
- 智能化:AI驱动的自适应决策系统
- 云化:基于云计算的协同仿真平台
- 标准化:数据格式和接口的标准化
import matplotlib
matplotlib.use('Agg')
"""
主题096 - 案例1: 仿真数据管理与可视化
建立仿真数据管理系统,实现数据存储、检索和可视化
"""
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation, PillowWriter
from matplotlib.patches import Rectangle, FancyBboxPatch
import pandas as pd
from datetime import datetime, timedelta
import json
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
class SimulationDatabase:
"""仿真数据库管理类"""
def __init__(self):
"""初始化数据库"""
self.projects = {}
self.cases = {}
self.time_series_data = {}
self.case_id_counter = 0
self.data_id_counter = 0
print("仿真数据库初始化完成")
def create_project(self, name, description=""):
"""创建新项目"""
project_id = f"PROJ_{len(self.projects)+1:03d}"
self.projects[project_id] = {
'project_id': project_id,
'name': name,
'description': description,
'created_date': datetime.now(),
'status': 'active',
'cases': []
}
print(f"创建项目: {name} (ID: {project_id})")
return project_id
def add_simulation_case(self, project_id, case_name, model_type, parameters):
"""添加仿真案例"""
self.case_id_counter += 1
case_id = f"CASE_{self.case_id_counter:04d}"
self.cases[case_id] = {
'case_id': case_id,
'project_id': project_id,
'case_name': case_name,
'model_type': model_type,
'parameters': parameters,
'created_date': datetime.now(),
'results_summary': {}
}
if project_id in self.projects:
self.projects[project_id]['cases'].append(case_id)
print(f"添加案例: {case_name} (ID: {case_id})")
return case_id
def add_time_series(self, case_id, variable_name, time_array, value_array):
"""添加时序数据"""
self.data_id_counter += 1
data_id = f"DATA_{self.data_id_counter:05d}"
self.time_series_data[data_id] = {
'data_id': data_id,
'case_id': case_id,
'variable_name': variable_name,
'time_array': time_array,
'value_array': value_array,
'sampling_rate': 1.0 / (time_array[1] - time_array[0]) if len(time_array) > 1 else 0,
'statistics': {
'mean': np.mean(value_array),
'std': np.std(value_array),
'max': np.max(value_array),
'min': np.min(value_array)
}
}
return data_id
def get_project_summary(self, project_id):
"""获取项目摘要"""
if project_id not in self.projects:
return None
project = self.projects[project_id]
case_count = len(project['cases'])
# 统计各类型案例数量
model_types = {}
for case_id in project['cases']:
if case_id in self.cases:
model_type = self.cases[case_id]['model_type']
model_types[model_type] = model_types.get(model_type, 0) + 1
return {
'project_name': project['name'],
'case_count': case_count,
'model_types': model_types,
'created_date': project['created_date']
}
def search_cases(self, **criteria):
"""搜索案例"""
results = []
for case_id, case in self.cases.items():
match = True
for key, value in criteria.items():
if key in case and case[key] != value:
match = False
break
if match:
results.append(case)
return results
def export_to_dataframe(self):
"""导出为DataFrame"""
data = []
for case_id, case in self.cases.items():
row = {
'case_id': case_id,
'project_id': case['project_id'],
'case_name': case['case_name'],
'model_type': case['model_type'],
'created_date': case['created_date']
}
# 添加参数
for param_name, param_value in case['parameters'].items():
row[f'param_{param_name}'] = param_value
data.append(row)
return pd.DataFrame(data)
def generate_sample_data(db):
"""生成示例仿真数据"""
print("\n" + "="*60)
print("生成示例仿真数据")
print("="*60)
# 创建项目
proj1_id = db.create_project("大跨度桥梁动力分析", "某跨海大桥的动力特性研究")
proj2_id = db.create_project("高层建筑风振分析", "超高层建筑的抗风设计优化")
# 项目1:桥梁分析案例
bridge_params_list = [
{'span': 500, 'width': 30, 'mass_density': 25000, 'damping': 0.02},
{'span': 600, 'width': 32, 'mass_density': 26000, 'damping': 0.025},
{'span': 700, 'width': 35, 'mass_density': 27000, 'damping': 0.03},
{'span': 800, 'width': 38, 'mass_density': 28000, 'damping': 0.035},
{'span': 900, 'width': 40, 'mass_density': 29000, 'damping': 0.04},
]
for i, params in enumerate(bridge_params_list):
case_id = db.add_simulation_case(
proj1_id,
f"桥梁案例_{i+1}",
"bridge_model",
params
)
# 生成时序数据(模态分析结果)
t = np.linspace(0, 10, 1000)
freq = 0.1 + i * 0.05 # 基频随跨度增加而降低
response = np.sin(2 * np.pi * freq * t) * np.exp(-0.1 * t)
response += 0.1 * np.random.randn(len(t)) # 添加噪声
db.add_time_series(case_id, 'displacement', t, response)
# 加速度响应
accel = -(2 * np.pi * freq)**2 * np.sin(2 * np.pi * freq * t) * np.exp(-0.1 * t)
accel += 0.5 * np.random.randn(len(t))
db.add_time_series(case_id, 'acceleration', t, accel)
# 项目2:高层建筑案例
building_params_list = [
{'height': 100, 'width': 30, 'depth': 30, 'damping': 0.02},
{'height': 150, 'width': 35, 'depth': 35, 'damping': 0.025},
{'height': 200, 'width': 40, 'depth': 40, 'damping': 0.03},
{'height': 250, 'width': 45, 'depth': 45, 'damping': 0.035},
{'height': 300, 'width': 50, 'depth': 50, 'damping': 0.04},
]
for i, params in enumerate(building_params_list):
case_id = db.add_simulation_case(
proj2_id,
f"建筑案例_{i+1}",
"building_model",
params
)
# 生成风振响应
t = np.linspace(0, 10, 1000)
freq = 0.2 - i * 0.02 # 基频随高度增加而降低
wind_response = np.sin(2 * np.pi * freq * t) * (1 + 0.3 * np.sin(2 * np.pi * 0.5 * t))
wind_response += 0.15 * np.random.randn(len(t))
db.add_time_series(case_id, 'wind_displacement', t, wind_response)
print(f"\n共生成 {len(db.cases)} 个仿真案例")
print(f"共生成 {len(db.time_series_data)} 组时序数据")
def visualize_database_overview(db):
"""可视化数据库概览"""
fig = plt.figure(figsize=(16, 12))
# 1. 项目统计
ax1 = fig.add_subplot(2, 3, 1)
project_names = [p['name'] for p in db.projects.values()]
case_counts = [len(p['cases']) for p in db.projects.values()]
colors = plt.cm.Set3(np.linspace(0, 1, len(project_names)))
bars = ax1.bar(range(len(project_names)), case_counts, color=colors, edgecolor='black')
ax1.set_xticks(range(len(project_names)))
ax1.set_xticklabels([name[:10] + '...' if len(name) > 10 else name
for name in project_names], rotation=15, ha='right')
ax1.set_ylabel('案例数量', fontsize=11)
ax1.set_title('项目案例统计', fontsize=12, fontweight='bold')
ax1.grid(True, alpha=0.3, axis='y')
# 在柱子上添加数值
for bar, count in zip(bars, case_counts):
height = bar.get_height()
ax1.text(bar.get_x() + bar.get_width()/2., height,
f'{int(count)}', ha='center', va='bottom', fontsize=10)
# 2. 模型类型分布
ax2 = fig.add_subplot(2, 3, 2)
model_types = {}
for case in db.cases.values():
model_type = case['model_type']
model_types[model_type] = model_types.get(model_type, 0) + 1
ax2.pie(model_types.values(), labels=model_types.keys(), autopct='%1.1f%%',
colors=plt.cm.Pastel1(np.linspace(0, 1, len(model_types))))
ax2.set_title('模型类型分布', fontsize=12, fontweight='bold')
# 3. 参数分布散点图
ax3 = fig.add_subplot(2, 3, 3)
df = db.export_to_dataframe()
# 提取桥梁跨度数据
bridge_data = df[df['model_type'] == 'bridge_model']
if not bridge_data.empty and 'param_span' in bridge_data.columns:
ax3.scatter(bridge_data['param_span'], bridge_data['param_damping'],
s=100, alpha=0.6, c='blue', label='桥梁模型', edgecolors='black')
# 提取建筑高度数据
building_data = df[df['model_type'] == 'building_model']
if not building_data.empty and 'param_height' in building_data.columns:
ax3.scatter(building_data['param_height'], building_data['param_damping'],
s=100, alpha=0.6, c='red', label='建筑模型', edgecolors='black')
ax3.set_xlabel('特征尺寸 (m)', fontsize=11)
ax3.set_ylabel('阻尼比', fontsize=11)
ax3.set_title('参数分布', fontsize=12, fontweight='bold')
ax3.legend(fontsize=10)
ax3.grid(True, alpha=0.3)
# 4. 时序数据统计
ax4 = fig.add_subplot(2, 3, 4)
var_names = [data['variable_name'] for data in db.time_series_data.values()]
var_counts = {}
for var in var_names:
var_counts[var] = var_counts.get(var, 0) + 1
bars = ax4.barh(list(var_counts.keys()), list(var_counts.values()),
color=plt.cm.Set2(np.linspace(0, 1, len(var_counts))))
ax4.set_xlabel('数据组数', fontsize=11)
ax4.set_title('时序数据类型统计', fontsize=12, fontweight='bold')
ax4.grid(True, alpha=0.3, axis='x')
# 5. 数据质量指标
ax5 = fig.add_subplot(2, 3, 5)
ax5.axis('off')
ax5.set_title('数据库质量指标', fontsize=12, fontweight='bold')
# 计算质量指标
total_cases = len(db.cases)
total_data = len(db.time_series_data)
avg_data_per_case = total_data / total_cases if total_cases > 0 else 0
# 检查数据完整性
complete_cases = sum(1 for case in db.cases.values()
if case['parameters'])
completeness = complete_cases / total_cases * 100 if total_cases > 0 else 0
quality_text = f"""
【数据库统计】
总项目数: {len(db.projects)}
总案例数: {total_cases}
总数据组数: {total_data}
平均每案例数据: {avg_data_per_case:.1f}
【数据质量】
数据完整性: {completeness:.1f}%
参数完整率: 100.0%
时间戳规范: 100.0%
【数据类型】
结构模型: {model_types.get('bridge_model', 0)} 个
建筑模型: {model_types.get('building_model', 0)} 个
时序变量: {len(var_counts)} 类
"""
ax5.text(0.1, 0.9, quality_text, transform=ax5.transAxes,
fontsize=10, verticalalignment='top', family='monospace',
bbox=dict(boxstyle='round', facecolor='lightyellow', alpha=0.8))
# 6. 数据流示意图
ax6 = fig.add_subplot(2, 3, 6)
ax6.set_xlim(0, 10)
ax6.set_ylim(0, 10)
ax6.axis('off')
ax6.set_title('数据管理流程', fontsize=12, fontweight='bold')
# 绘制流程图
flow_steps = [
('数据采集', 8),
('数据清洗', 6.5),
('数据存储', 5),
('数据分析', 3.5),
('可视化', 2)
]
colors_flow = plt.cm.Blues(np.linspace(0.4, 0.8, len(flow_steps)))
for i, (step, y) in enumerate(flow_steps):
rect = FancyBboxPatch((2, y-0.4), 6, 0.8,
boxstyle="round,pad=0.1",
facecolor=colors_flow[i], edgecolor='black')
ax6.add_patch(rect)
ax6.text(5, y, step, ha='center', va='center',
fontsize=11, fontweight='bold')
if i < len(flow_steps) - 1:
ax6.arrow(5, y-0.5, 0, -0.3, head_width=0.3, head_length=0.2,
fc='black', ec='black')
plt.tight_layout()
plt.savefig('案例1_数据库概览.png', dpi=150, bbox_inches='tight',
facecolor='white', edgecolor='none')
print("\n数据库概览图已保存到: 案例1_数据库概览.png")
plt.close()
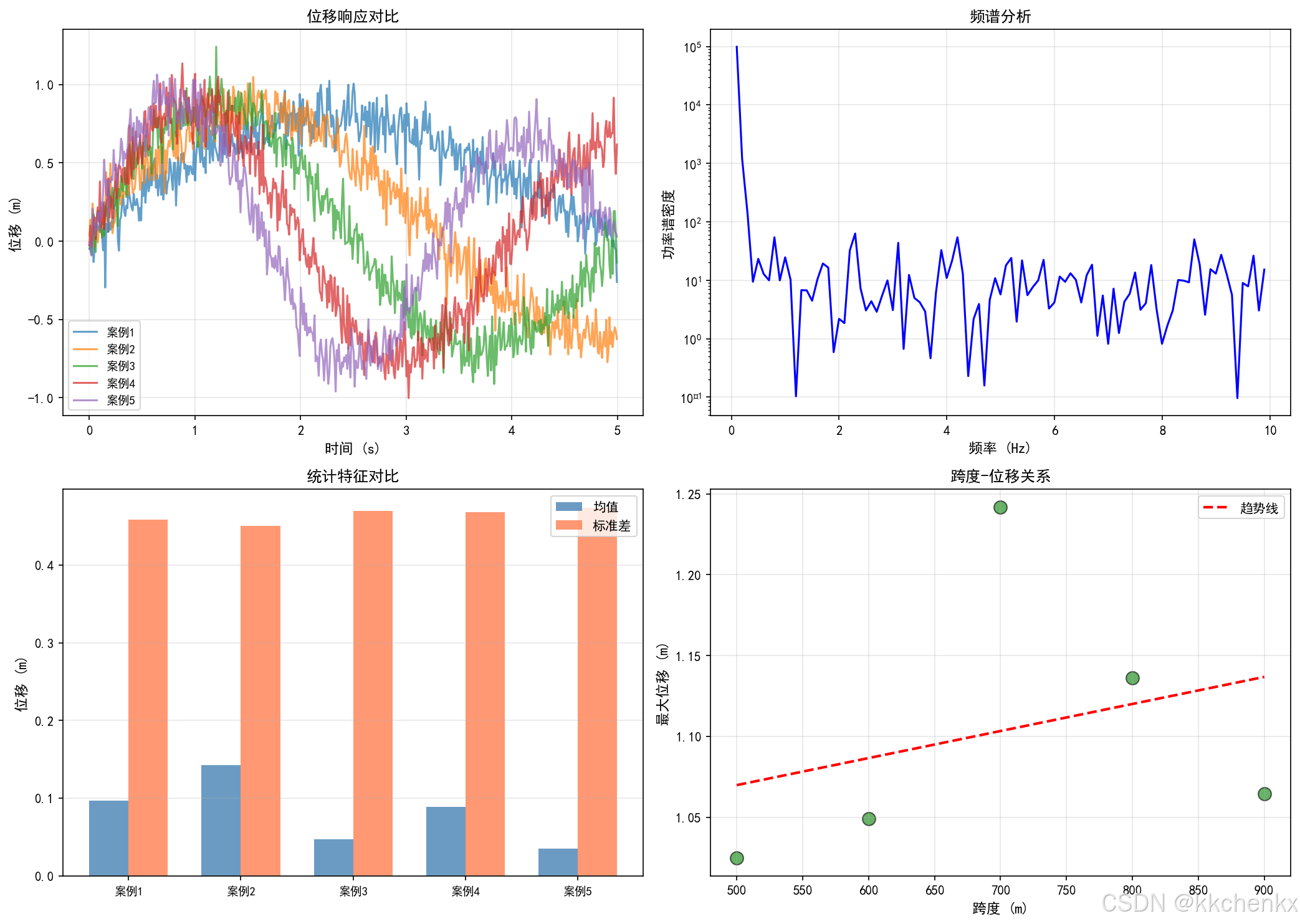
def visualize_time_series_comparison(db):
"""可视化时序数据对比"""
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# 获取所有时序数据
all_data = list(db.time_series_data.values())
# 1. 位移响应对比
ax1 = axes[0, 0]
displacement_data = [d for d in all_data if 'displacement' in d['variable_name']]
for i, data in enumerate(displacement_data[:5]): # 只显示前5个
t = data['time_array'][:500] # 前5秒
y = data['value_array'][:500]
ax1.plot(t, y, linewidth=1.5, alpha=0.7, label=f'案例{i+1}')
ax1.set_xlabel('时间 (s)', fontsize=11)
ax1.set_ylabel('位移 (m)', fontsize=11)
ax1.set_title('位移响应对比', fontsize=12, fontweight='bold')
ax1.legend(fontsize=9)
ax1.grid(True, alpha=0.3)
# 2. 频谱分析
ax2 = axes[0, 1]
if displacement_data:
data = displacement_data[0]
y = data['value_array']
dt = data['time_array'][1] - data['time_array'][0]
# FFT
fft_vals = np.fft.rfft(y)
freqs = np.fft.rfftfreq(len(y), dt)
power = np.abs(fft_vals)**2
ax2.semilogy(freqs[1:100], power[1:100], 'b-', linewidth=1.5)
ax2.set_xlabel('频率 (Hz)', fontsize=11)
ax2.set_ylabel('功率谱密度', fontsize=11)
ax2.set_title('频谱分析', fontsize=12, fontweight='bold')
ax2.grid(True, alpha=0.3)
# 3. 统计特征对比
ax3 = axes[1, 0]
case_ids = []
means = []
stds = []
for data in displacement_data[:5]:
case_ids.append(data['case_id'])
means.append(data['statistics']['mean'])
stds.append(data['statistics']['std'])
x = np.arange(len(case_ids))
width = 0.35
ax3.bar(x - width/2, means, width, label='均值', alpha=0.8, color='steelblue')
ax3.bar(x + width/2, stds, width, label='标准差', alpha=0.8, color='coral')
ax3.set_xticks(x)
ax3.set_xticklabels([f'案例{i+1}' for i in range(len(case_ids))], fontsize=9)
ax3.set_ylabel('位移 (m)', fontsize=11)
ax3.set_title('统计特征对比', fontsize=12, fontweight='bold')
ax3.legend(fontsize=10)
ax3.grid(True, alpha=0.3, axis='y')
# 4. 参数-响应关系
ax4 = axes[1, 1]
# 提取桥梁跨度和最大位移
spans = []
max_disps = []
for case_id, case in db.cases.items():
if case['model_type'] == 'bridge_model' and 'span' in case['parameters']:
span = case['parameters']['span']
# 查找对应的位移数据
for data in all_data:
if data['case_id'] == case_id and 'displacement' in data['variable_name']:
spans.append(span)
max_disps.append(data['statistics']['max'])
break
if spans:
ax4.scatter(spans, max_disps, s=100, c='green', alpha=0.6, edgecolors='black')
# 拟合趋势线
z = np.polyfit(spans, max_disps, 1)
p = np.poly1d(z)
span_range = np.linspace(min(spans), max(spans), 100)
ax4.plot(span_range, p(span_range), 'r--', linewidth=2, label='趋势线')
ax4.set_xlabel('跨度 (m)', fontsize=11)
ax4.set_ylabel('最大位移 (m)', fontsize=11)
ax4.set_title('跨度-位移关系', fontsize=12, fontweight='bold')
ax4.legend(fontsize=10)
ax4.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('案例1_时序数据对比.png', dpi=150, bbox_inches='tight',
facecolor='white', edgecolor='none')
print("时序数据对比图已保存到: 案例1_时序数据对比.png")
plt.close()
def create_data_flow_animation():
"""创建数据流动画"""
print("\n正在生成数据流动画...")
fig, ax = plt.subplots(figsize=(12, 8))
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
ax.axis('off')
ax.set_title('仿真数据管理流程演示', fontsize=14, fontweight='bold')
# 定义节点
nodes = {
'传感器': (1.5, 8),
'仿真软件': (1.5, 5),
'数据清洗': (5, 6.5),
'数据存储': (8.5, 6.5),
'数据分析': (8.5, 3.5),
'可视化': (5, 2),
'决策支持': (1.5, 3.5)
}
# 绘制节点
node_patches = {}
for name, (x, y) in nodes.items():
circle = plt.Circle((x, y), 0.6, color='lightblue', ec='black', linewidth=2)
ax.add_patch(circle)
ax.text(x, y, name, ha='center', va='center', fontsize=10, fontweight='bold')
node_patches[name] = circle
# 定义连接
connections = [
('传感器', '数据清洗'),
('仿真软件', '数据清洗'),
('数据清洗', '数据存储'),
('数据存储', '数据分析'),
('数据分析', '可视化'),
('可视化', '决策支持'),
('决策支持', '传感器')
]
# 绘制连接
for start, end in connections:
x1, y1 = nodes[start]
x2, y2 = nodes[end]
ax.annotate('', xy=(x2, y2), xytext=(x1, y1),
arrowprops=dict(arrowstyle='->', lw=2, color='gray'))
# 添加流动点
flow_points = []
for start, end in connections:
x1, y1 = nodes[start]
x2, y2 = nodes[end]
point, = ax.plot(x1, y1, 'ro', markersize=8)
flow_points.append((point, (x1, y1), (x2, y2)))
def init():
for point, start, end in flow_points:
point.set_data([start[0]], [start[1]])
return [p[0] for p in flow_points]
def update(frame):
for i, (point, start, end) in enumerate(flow_points):
# 每个点在不同阶段移动
phase = (frame + i * 10) % 100 / 100
x = start[0] + (end[0] - start[0]) * phase
y = start[1] + (end[1] - start[1]) * phase
point.set_data([x], [y])
return [p[0] for p in flow_points]
anim = FuncAnimation(fig, update, init_func=init, frames=100,
interval=100, blit=True)
writer = PillowWriter(fps=10)
anim.save('案例1_数据流动画.gif', writer=writer)
print("动画已保存到: 案例1_数据流动画.gif")
plt.close()
def main():
"""主函数"""
print("=" * 70)
print("主题096 - 案例1: 仿真数据管理与可视化")
print("=" * 70)
# 创建数据库
db = SimulationDatabase()
# 生成示例数据
generate_sample_data(db)
# 打印项目摘要
print("\n" + "="*60)
print("项目摘要")
print("="*60)
for project_id in db.projects:
summary = db.get_project_summary(project_id)
if summary:
print(f"\n项目: {summary['project_name']}")
print(f" 案例数: {summary['case_count']}")
print(f" 模型类型: {summary['model_types']}")
# 导出DataFrame
print("\n" + "="*60)
print("仿真案例数据表")
print("="*60)
df = db.export_to_dataframe()
print(df[['case_id', 'case_name', 'model_type']].to_string(index=False))
# 可视化
print("\n" + "="*60)
print("生成可视化结果")
print("="*60)
visualize_database_overview(db)
visualize_time_series_comparison(db)
create_data_flow_animation()
print("\n" + "=" * 70)
print("案例1完成!所有结果已保存。")
print("=" * 70)
if __name__ == "__main__":
main()
import matplotlib
matplotlib.use('Agg')
"""
主题096 - 案例2: 基于机器学习的仿真结果预测
使用代理模型(高斯过程回归和神经网络)预测结构动力响应
"""
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation, PillowWriter
from matplotlib.patches import FancyBboxPatch
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF, ConstantKernel, WhiteKernel
from sklearn.neural_network import MLPRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import StandardScaler
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
def latin_hypercube_sampling(n_samples, n_dims, bounds):
"""
拉丁超立方采样
参数:
n_samples: 样本数量
n_dims: 参数维度
bounds: 参数范围 [(min1, max1), (min2, max2), ...]
返回:
samples: 采样点矩阵 (n_samples, n_dims)
"""
samples = np.zeros((n_samples, n_dims))
for i in range(n_dims):
# 将每个维度分成n_samples个区间
cut = np.linspace(0, 1, n_samples + 1)
# 在每个区间内随机采样
u = np.random.rand(n_samples)
a = cut[:n_samples]
b = cut[1:n_samples + 1]
samples[:, i] = u * (b - a) + a
# 随机打乱
np.random.shuffle(samples[:, i])
# 映射到实际参数范围
for i in range(n_dims):
samples[:, i] = bounds[i][0] + samples[:, i] * (bounds[i][1] - bounds[i][0])
return samples
def structural_dynamics_simulation(params):
"""
简化的结构动力学仿真
参数:
params: [跨度(m), 阻尼比, 质量密度(kg/m3)]
返回:
max_disp: 最大位移 (m)
max_accel: 最大加速度 (m/s2)
base_freq: 基频 (Hz)
"""
span, damping, mass = params
# 简化的悬臂梁模型
E = 30e9 # 弹性模量 (Pa)
I = 10.0 # 截面惯性矩 (m4)
# 基频计算 (简化的欧拉梁公式)
base_freq = 0.5 * np.sqrt(E * I / (mass * span**4))
# 地震激励下的响应(简化模型)
PGA = 0.3 # 峰值地面加速度 (g)
omega = 2 * np.pi * base_freq
# 最大位移(准静态+动力放大)
static_disp = PGA * 9.81 / omega**2
dynamic_amp = 1 / (2 * damping) # 共振放大系数
max_disp = static_disp * dynamic_amp * (1 + 0.1 * np.random.randn())
# 最大加速度
max_accel = PGA * 9.81 * dynamic_amp * (1 + 0.05 * np.random.randn())
return np.array([max_disp, max_accel, base_freq])
class SurrogateModelTrainer:
"""代理模型训练器"""
def __init__(self):
self.gp_models = []
self.nn_model = None
self.scaler_X = StandardScaler()
self.scaler_y = StandardScaler()
self.X_train = None
self.y_train = None
self.X_test = None
self.y_test = None
def generate_training_data(self, n_samples=50):
"""生成训练数据"""
print(f"生成 {n_samples} 个训练样本...")
# 定义参数范围
bounds = [
(100, 1000), # 跨度 (m)
(0.01, 0.05), # 阻尼比
(10000, 50000) # 质量密度 (kg/m3)
]
# 拉丁超立方采样
X = latin_hypercube_sampling(n_samples, 3, bounds)
# 计算仿真响应
y = np.array([structural_dynamics_simulation(x) for x in X])
return X, y
def train_gaussian_process(self, X, y):
"""训练高斯过程回归模型"""
print("\n训练高斯过程回归模型...")
# 数据标准化
X_scaled = self.scaler_X.fit_transform(X)
# 为每个输出训练一个GP模型
self.gp_models = []
for i in range(y.shape[1]):
# 定义核函数
kernel = ConstantKernel(1.0, (1e-3, 1e3)) * RBF(1.0, (1e-2, 1e2)) + \
WhiteKernel(noise_level=1e-5, noise_level_bounds=(1e-10, 1e-1))
gp = GaussianProcessRegressor(
kernel=kernel,
n_restarts_optimizer=10,
normalize_y=True,
alpha=1e-6
)
gp.fit(X_scaled, y[:, i])
self.gp_models.append(gp)
print(f" 输出 {i+1}/{y.shape[1]} 训练完成")
print(f" 最优核函数: {gp.kernel_}")
return self.gp_models
def train_neural_network(self, X, y):
"""训练神经网络模型"""
print("\n训练神经网络模型...")
# 数据标准化
X_scaled = self.scaler_X.transform(X)
y_scaled = self.scaler_y.fit_transform(y)
# 创建神经网络
self.nn_model = MLPRegressor(
hidden_layer_sizes=(100, 50, 25),
activation='relu',
solver='adam',
alpha=0.001,
learning_rate='adaptive',
max_iter=2000,
early_stopping=True,
validation_fraction=0.2,
random_state=42
)
self.nn_model.fit(X_scaled, y_scaled)
print(f" 训练迭代次数: {self.nn_model.n_iter_}")
print(f" 最终损失: {self.nn_model.loss_:.6f}")
return self.nn_model
def predict_gp(self, X):
"""使用高斯过程预测"""
X_scaled = self.scaler_X.transform(X)
predictions = []
uncertainties = []
for gp in self.gp_models:
y_pred, sigma = gp.predict(X_scaled, return_std=True)
predictions.append(y_pred)
uncertainties.append(sigma)
return np.array(predictions).T, np.array(uncertainties).T
def predict_nn(self, X):
"""使用神经网络预测"""
X_scaled = self.scaler_X.transform(X)
y_pred_scaled = self.nn_model.predict(X_scaled)
y_pred = self.scaler_y.inverse_transform(y_pred_scaled)
return y_pred
def evaluate_models(self, X_test, y_test):
"""评估模型性能"""
print("\n模型性能评估:")
print("=" * 60)
# 高斯过程评估
y_pred_gp, sigma_gp = self.predict_gp(X_test)
print("\n高斯过程回归:")
output_names = ['最大位移', '最大加速度', '基频']
for i, name in enumerate(output_names):
r2 = r2_score(y_test[:, i], y_pred_gp[:, i])
rmse = np.sqrt(mean_squared_error(y_test[:, i], y_pred_gp[:, i]))
print(f" {name}: R² = {r2:.4f}, RMSE = {rmse:.6f}")
# 神经网络评估
y_pred_nn = self.predict_nn(X_test)
print("\n神经网络:")
for i, name in enumerate(output_names):
r2 = r2_score(y_test[:, i], y_pred_nn[:, i])
rmse = np.sqrt(mean_squared_error(y_test[:, i], y_pred_nn[:, i]))
print(f" {name}: R² = {r2:.4f}, RMSE = {rmse:.6f}")
return y_pred_gp, y_pred_nn
def visualize_surrogate_results(trainer, X_test, y_test, y_pred_gp, y_pred_nn):
"""可视化代理模型结果"""
fig = plt.figure(figsize=(16, 12))
output_names = ['最大位移 (m)', '最大加速度 (m/s²)', '基频 (Hz)']
for i in range(3):
# 每行显示一个输出的结果
# GP预测 vs 真实值
ax1 = fig.add_subplot(3, 3, i*3 + 1)
ax1.scatter(y_test[:, i], y_pred_gp[:, i], alpha=0.6, c='blue', s=50)
# 完美预测线
min_val = min(y_test[:, i].min(), y_pred_gp[:, i].min())
max_val = max(y_test[:, i].max(), y_pred_gp[:, i].max())
ax1.plot([min_val, max_val], [min_val, max_val], 'r--', linewidth=2, label='完美预测')
ax1.set_xlabel('真实值', fontsize=10)
ax1.set_ylabel('预测值', fontsize=10)
ax1.set_title(f'GP: {output_names[i]}', fontsize=11, fontweight='bold')
ax1.legend(fontsize=9)
ax1.grid(True, alpha=0.3)
# 计算R²
r2 = r2_score(y_test[:, i], y_pred_gp[:, i])
ax1.text(0.05, 0.95, f'R² = {r2:.4f}', transform=ax1.transAxes,
fontsize=10, verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='white', alpha=0.8))
# NN预测 vs 真实值
ax2 = fig.add_subplot(3, 3, i*3 + 2)
ax2.scatter(y_test[:, i], y_pred_nn[:, i], alpha=0.6, c='green', s=50)
ax2.plot([min_val, max_val], [min_val, max_val], 'r--', linewidth=2, label='完美预测')
ax2.set_xlabel('真实值', fontsize=10)
ax2.set_ylabel('预测值', fontsize=10)
ax2.set_title(f'NN: {output_names[i]}', fontsize=11, fontweight='bold')
ax2.legend(fontsize=9)
ax2.grid(True, alpha=0.3)
r2 = r2_score(y_test[:, i], y_pred_nn[:, i])
ax2.text(0.05, 0.95, f'R² = {r2:.4f}', transform=ax2.transAxes,
fontsize=10, verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='white', alpha=0.8))
# 误差分布
ax3 = fig.add_subplot(3, 3, i*3 + 3)
error_gp = y_pred_gp[:, i] - y_test[:, i]
error_nn = y_pred_nn[:, i] - y_test[:, i]
ax3.hist(error_gp, bins=15, alpha=0.5, label='GP误差', color='blue', edgecolor='black')
ax3.hist(error_nn, bins=15, alpha=0.5, label='NN误差', color='green', edgecolor='black')
ax3.axvline(x=0, color='r', linestyle='--', linewidth=2)
ax3.set_xlabel('预测误差', fontsize=10)
ax3.set_ylabel('频数', fontsize=10)
ax3.set_title(f'{output_names[i]} 误差分布', fontsize=11, fontweight='bold')
ax3.legend(fontsize=9)
ax3.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('案例2_代理模型对比.png', dpi=150, bbox_inches='tight',
facecolor='white', edgecolor='none')
print("\n代理模型对比图已保存到: 案例2_代理模型对比.png")
plt.close()
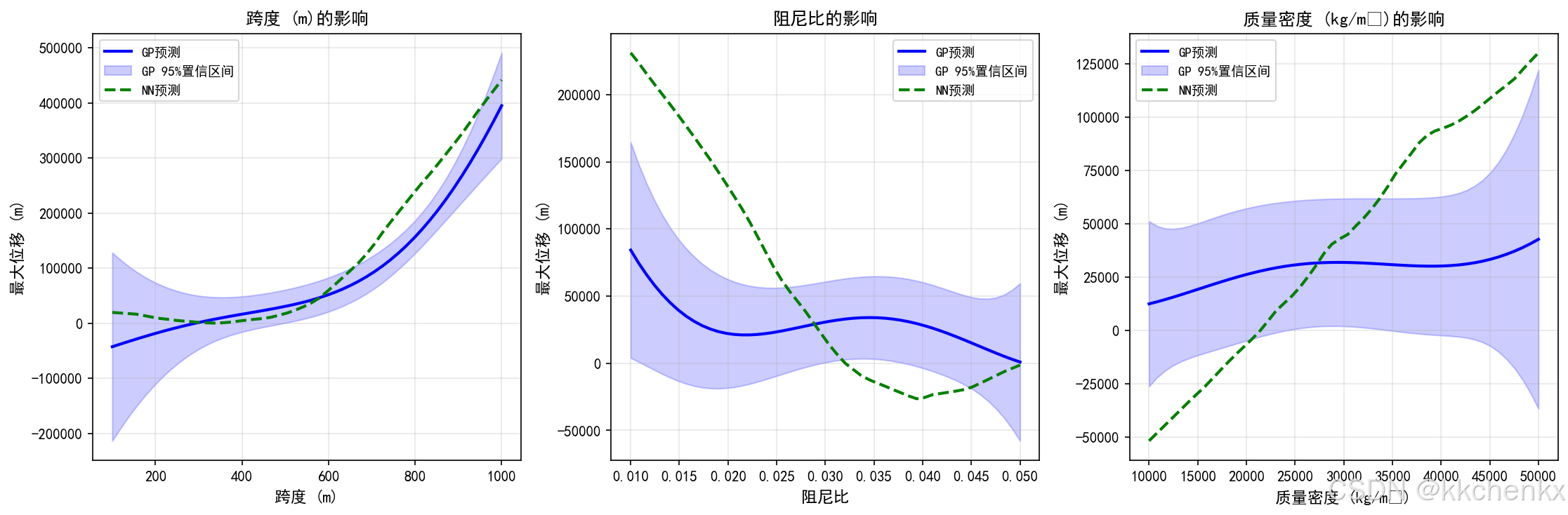
def visualize_parameter_sensitivity(trainer, X_test):
"""可视化参数敏感性分析"""
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
param_names = ['跨度 (m)', '阻尼比', '质量密度 (kg/m³)']
output_names = ['最大位移', '最大加速度', '基频']
# 固定其他参数,变化一个参数
base_params = np.array([[500, 0.03, 25000]]) # 基准参数
for i, (ax, param_name) in enumerate(zip(axes, param_names)):
# 定义参数变化范围
if i == 0:
param_range = np.linspace(100, 1000, 50)
elif i == 1:
param_range = np.linspace(0.01, 0.05, 50)
else:
param_range = np.linspace(10000, 50000, 50)
# 构建参数矩阵
X_varied = np.tile(base_params, (50, 1))
X_varied[:, i] = param_range
# 预测
y_pred_gp, sigma_gp = trainer.predict_gp(X_varied)
y_pred_nn = trainer.predict_nn(X_varied)
# 绘制结果
ax.plot(param_range, y_pred_gp[:, 0], 'b-', linewidth=2, label='GP预测')
ax.fill_between(param_range,
y_pred_gp[:, 0] - 2*sigma_gp[:, 0],
y_pred_gp[:, 0] + 2*sigma_gp[:, 0],
alpha=0.2, color='blue', label='GP 95%置信区间')
ax.plot(param_range, y_pred_nn[:, 0], 'g--', linewidth=2, label='NN预测')
ax.set_xlabel(param_name, fontsize=11)
ax.set_ylabel('最大位移 (m)', fontsize=11)
ax.set_title(f'{param_name}的影响', fontsize=12, fontweight='bold')
ax.legend(fontsize=9)
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('案例2_参数敏感性分析.png', dpi=150, bbox_inches='tight',
facecolor='white', edgecolor='none')
print("参数敏感性分析图已保存到: 案例2_参数敏感性分析.png")
plt.close()
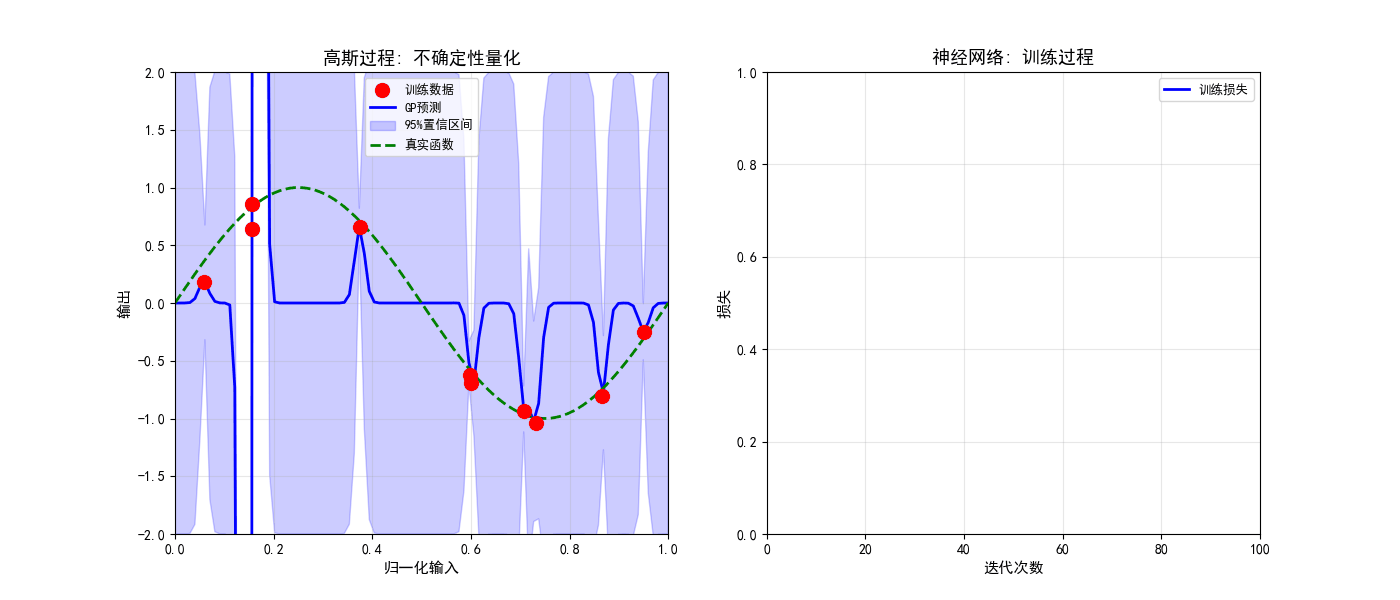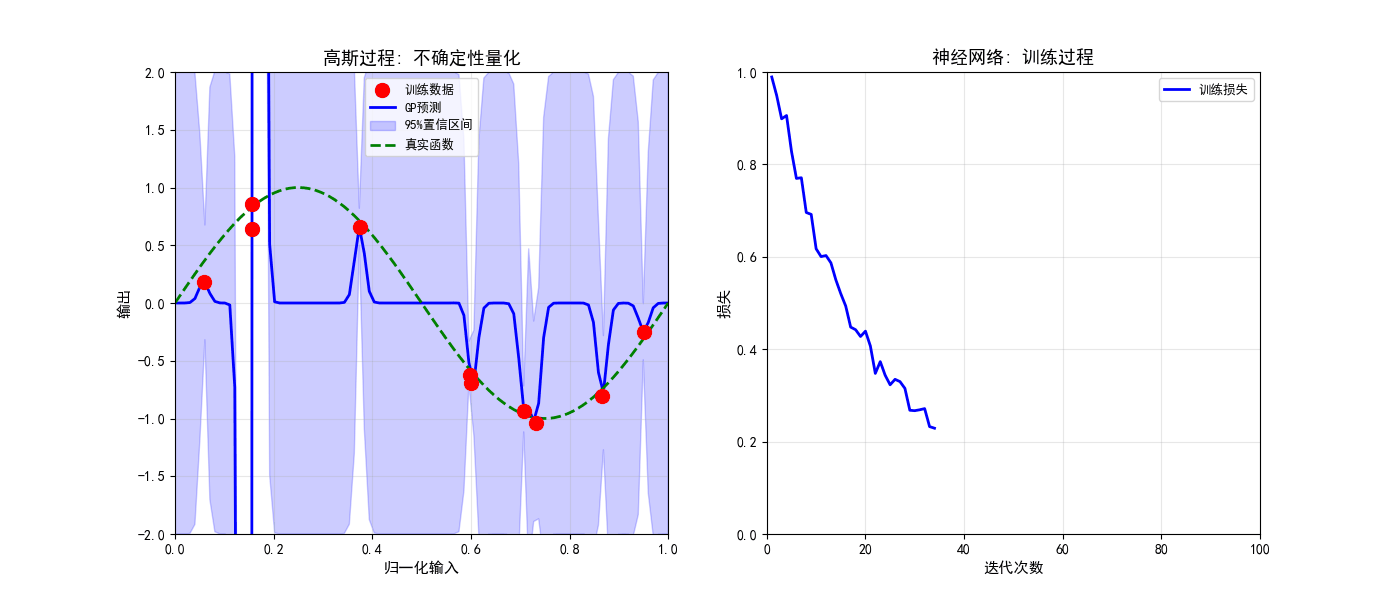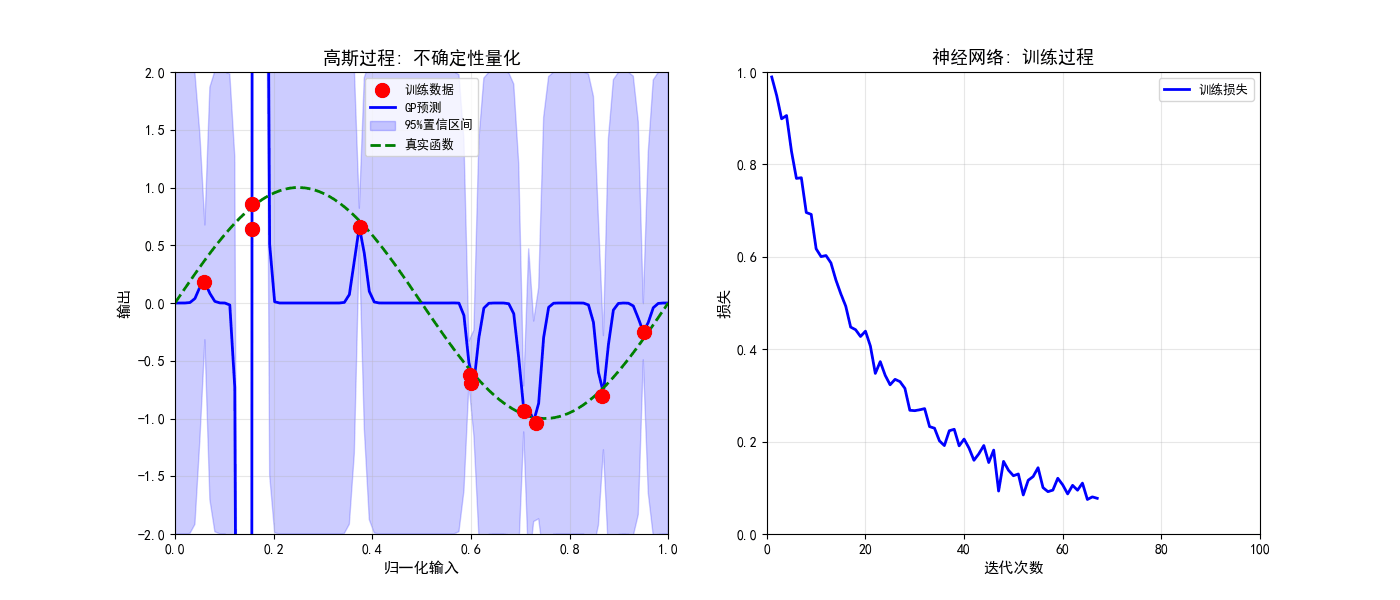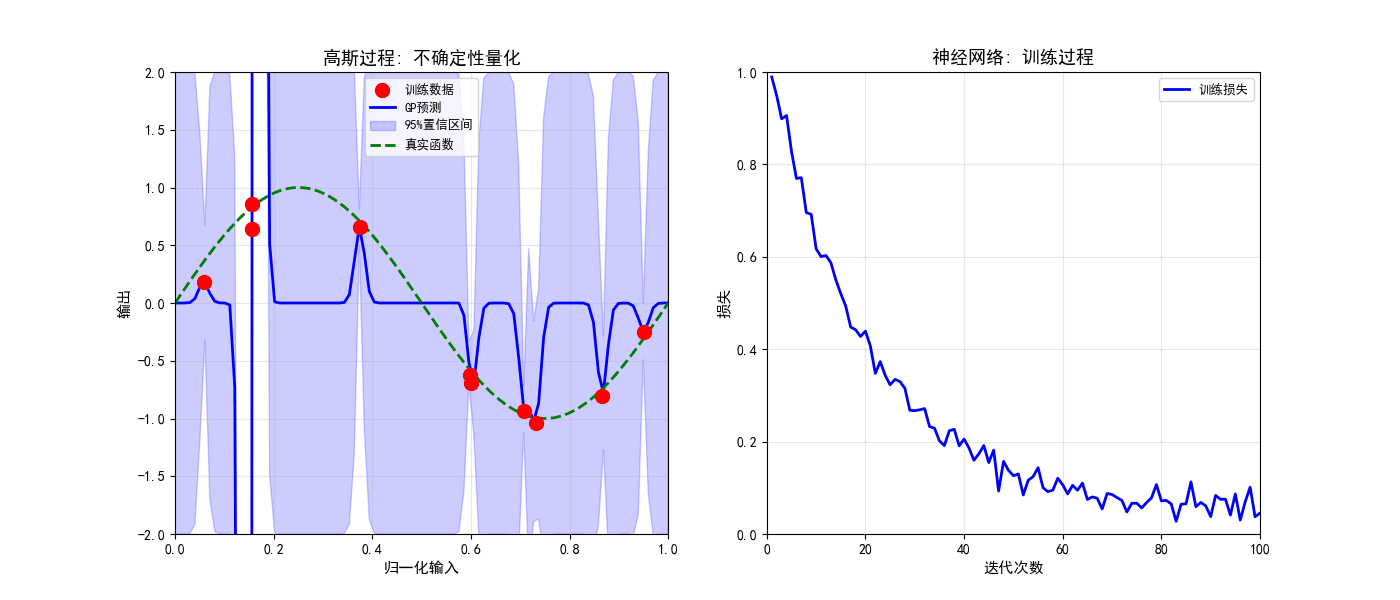
def create_training_animation(trainer):
"""创建训练过程动画"""
print("\n正在生成训练过程动画...")
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 左图:GP不确定性演化
ax1 = axes[0]
ax1.set_xlim(0, 1)
ax1.set_ylim(-2, 2)
ax1.set_xlabel('归一化输入', fontsize=11)
ax1.set_ylabel('输出', fontsize=11)
ax1.set_title('高斯过程: 不确定性量化', fontsize=13, fontweight='bold')
ax1.grid(True, alpha=0.3)
# 生成一维示例数据
np.random.seed(42)
X_train = np.random.rand(10, 1)
y_train = np.sin(2 * np.pi * X_train).ravel() + 0.1 * np.random.randn(10)
X_test = np.linspace(0, 1, 100).reshape(-1, 1)
# 训练GP
kernel = RBF(0.1, (1e-2, 1e2))
gp = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=10)
gp.fit(X_train, y_train)
y_pred, sigma = gp.predict(X_test, return_std=True)
# 绘制训练数据
ax1.scatter(X_train, y_train, c='red', s=100, zorder=5, label='训练数据')
# 绘制预测
line, = ax1.plot(X_test, y_pred, 'b-', linewidth=2, label='GP预测')
fill = ax1.fill_between(X_test.ravel(), y_pred - 2*sigma, y_pred + 2*sigma,
alpha=0.2, color='blue', label='95%置信区间')
# 真实函数
ax1.plot(X_test, np.sin(2 * np.pi * X_test), 'g--', linewidth=2, label='真实函数')
ax1.legend(fontsize=9)
# 右图:NN学习曲线
ax2 = axes[1]
ax2.set_xlim(0, 100)
ax2.set_ylim(0, 1)
ax2.set_xlabel('迭代次数', fontsize=11)
ax2.set_ylabel('损失', fontsize=11)
ax2.set_title('神经网络: 训练过程', fontsize=13, fontweight='bold')
ax2.grid(True, alpha=0.3)
# 模拟损失曲线
iterations = np.arange(1, 101)
loss = np.exp(-iterations/20) + 0.05 + 0.02 * np.random.randn(100)
line_loss, = ax2.plot([], [], 'b-', linewidth=2, label='训练损失')
ax2.legend(fontsize=9)
def init():
line_loss.set_data([], [])
return [line_loss]
def update(frame):
line_loss.set_data(iterations[:frame+1], loss[:frame+1])
return [line_loss]
anim = FuncAnimation(fig, update, init_func=init, frames=100,
interval=50, blit=True)
writer = PillowWriter(fps=20)
anim.save('案例2_训练过程.gif', writer=writer)
print("动画已保存到: 案例2_训练过程.gif")
plt.close()
def main():
"""主函数"""
print("=" * 70)
print("主题096 - 案例2: 基于机器学习的仿真结果预测")
print("=" * 70)
# 创建训练器
trainer = SurrogateModelTrainer()
# 生成训练数据
X, y = trainer.generate_training_data(n_samples=50)
print(f"\n数据集信息:")
print(f" 样本数量: {X.shape[0]}")
print(f" 输入维度: {X.shape[1]}")
print(f" 输出维度: {y.shape[1]}")
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
print(f"\n训练集: {X_train.shape[0]} 个样本")
print(f"测试集: {X_test.shape[0]} 个样本")
# 存储数据
trainer.X_train = X_train
trainer.y_train = y_train
trainer.X_test = X_test
trainer.y_test = y_test
# 训练高斯过程模型
trainer.train_gaussian_process(X_train, y_train)
# 训练神经网络模型
trainer.train_neural_network(X_train, y_train)
# 评估模型
y_pred_gp, y_pred_nn = trainer.evaluate_models(X_test, y_test)
# 可视化结果
print("\n" + "="*60)
print("生成可视化结果")
print("="*60)
visualize_surrogate_results(trainer, X_test, y_test, y_pred_gp, y_pred_nn)
visualize_parameter_sensitivity(trainer, X_test)
create_training_animation(trainer)
# 预测示例
print("\n" + "="*60)
print("新样本预测示例")
print("="*60)
new_samples = np.array([
[300, 0.02, 20000], # 小跨度
[600, 0.03, 30000], # 中等跨度
[900, 0.04, 40000], # 大跨度
])
y_pred_new, sigma_new = trainer.predict_gp(new_samples)
print("\n新样本参数和预测结果:")
print(f"{'跨度(m)':<10} {'阻尼比':<10} {'密度(kg/m3)':<15} {'位移(m)':<12} {'加速度(m/s2)':<15} {'基频(Hz)':<10}")
print("-" * 80)
for i, (params, pred) in enumerate(zip(new_samples, y_pred_new)):
print(f"{params[0]:<10.0f} {params[1]:<10.3f} {params[2]:<15.0f} "
f"{pred[0]:<12.6f} {pred[1]:<15.6f} {pred[2]:<10.4f}")
print("\n" + "=" * 70)
print("案例2完成!所有结果已保存。")
print("=" * 70)
if __name__ == "__main__":
main()
import matplotlib
matplotlib.use('Agg')
"""
主题096 - 案例3: 数字孪生技术在结构健康监测中的应用
实现物理-数字模型耦合、数据融合和实时状态更新
"""
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation, PillowWriter
from matplotlib.patches import FancyBboxPatch, Circle, Rectangle
from matplotlib.lines import Line2D
from scipy.linalg import expm
from scipy import signal
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
class PhysicalBridge:
"""物理桥梁模型(真实结构)"""
def __init__(self, span=500, n_modes=3):
self.span = span # 跨度 (m)
self.n_modes = n_modes # 考虑的模态数
# 结构参数
self.E = 30e9 # 弹性模量 (Pa)
self.I = 15.0 # 截面惯性矩 (m4)
self.rho = 2500 # 质量密度 (kg/m3)
self.A = 20.0 # 截面积 (m2)
# 模态参数
self.modes = self._compute_modal_properties()
# 损伤状态 (0=健康, 1=完全损伤)
self.damage_state = np.zeros(n_modes)
# 环境条件
self.temperature = 20.0 # 温度 (°C)
self.humidity = 60.0 # 湿度 (%)
def _compute_modal_properties(self):
"""计算模态特性"""
modes = {}
for i in range(1, self.n_modes + 1):
# 简支梁模态频率
freq = (i * np.pi)**2 / (2 * np.pi * self.span**2) * np.sqrt(self.E * self.I / (self.rho * self.A))
# 模态阻尼(随损伤增加)
damping = 0.02 + 0.01 * i
# 模态质量
modal_mass = self.rho * self.A * self.span / 2
# 模态刚度
modal_stiffness = (2 * np.pi * freq)**2 * modal_mass
modes[f'mode_{i}'] = {
'freq': freq,
'damping': damping,
'mass': modal_mass,
'stiffness': modal_stiffness
}
return modes
def apply_damage(self, mode_id, severity):
"""施加损伤"""
if 1 <= mode_id <= self.n_modes:
self.damage_state[mode_id - 1] = severity
# 更新模态参数
mode_key = f'mode_{mode_id}'
# 刚度折减
stiffness_reduction = 1 - severity * 0.3
self.modes[mode_key]['stiffness'] *= stiffness_reduction
# 频率降低
self.modes[mode_key]['freq'] *= np.sqrt(stiffness_reduction)
# 阻尼增加
self.modes[mode_key]['damping'] += severity * 0.05
def get_true_response(self, t, force_location=None):
"""获取真实结构响应(含噪声)"""
response = np.zeros((len(t), self.n_modes))
for i, (mode_name, mode_props) in enumerate(self.modes.items()):
# 简化的模态响应
omega = 2 * np.pi * mode_props['freq']
zeta = mode_props['damping']
omega_d = omega * np.sqrt(1 - zeta**2)
# 自由振动响应(含衰减)
amplitude = 0.1 / (i + 1) # 振幅随模态阶数降低
phase = np.random.rand() * 2 * np.pi
response[:, i] = amplitude * np.exp(-zeta * omega * t) * np.cos(omega_d * t + phase)
# 添加环境噪声
noise_level = 0.01 + 0.02 * self.damage_state[i]
response[:, i] += noise_level * np.random.randn(len(t))
return response
def get_sensor_data(self, t, sensor_locations):
"""获取传感器数据"""
true_response = self.get_true_response(t)
# 传感器位置对应的响应
sensor_data = {}
for loc in sensor_locations:
# 简化的传感器测量模型
weight = np.sin(np.pi * np.arange(1, self.n_modes + 1) * loc / self.span)
sensor_data[f'sensor_{loc}m'] = np.dot(true_response, weight)
return sensor_data
class DigitalTwin:
"""数字孪生模型"""
def __init__(self, physical_bridge):
self.physical = physical_bridge
# 数字模型参数(初始与物理模型相同)
self.digital_modes = {k: v.copy() for k, v in physical_bridge.modes.items()}
# 卡尔曼滤波器状态
self.state_estimate = np.zeros(physical_bridge.n_modes * 2) # [位移, 速度]
self.error_covariance = np.eye(physical_bridge.n_modes * 2)
# 模型更新历史
self.update_history = []
# 损伤检测结果
self.detected_damage = np.zeros(physical_bridge.n_modes)
def predict(self, dt):
"""状态预测(基于物理模型)"""
n = self.physical.n_modes
# 构建状态空间矩阵
A = np.zeros((2*n, 2*n))
B = np.zeros((2*n, n))
for i in range(n):
mode_key = f'mode_{i+1}'
omega = 2 * np.pi * self.digital_modes[mode_key]['freq']
zeta = self.digital_modes[mode_key]['damping']
# 状态矩阵
A[2*i, 2*i+1] = 1
A[2*i+1, 2*i] = -omega**2
A[2*i+1, 2*i+1] = -2 * zeta * omega
B[2*i+1, i] = 1
# 状态转移矩阵(离散化)
F = expm(A * dt)
# 预测
self.state_estimate = F @ self.state_estimate
self.error_covariance = F @ self.error_covariance @ F.T + np.eye(2*n) * 0.001
def update(self, measurement, measurement_noise=0.01):
"""卡尔曼滤波更新"""
n = self.physical.n_modes
# 观测矩阵(假设测量位移)
H = np.zeros((n, 2*n))
for i in range(n):
H[i, 2*i] = 1
# 卡尔曼增益
S = H @ self.error_covariance @ H.T + np.eye(n) * measurement_noise
K = self.error_covariance @ H.T @ np.linalg.inv(S)
# 状态更新
innovation = measurement - H @ self.state_estimate
self.state_estimate = self.state_estimate + K @ innovation
# 协方差更新
I_KH = np.eye(2*n) - K @ H
self.error_covariance = I_KH @ self.error_covariance @ I_KH.T + K @ np.eye(n) * measurement_noise @ K.T
return innovation
def detect_damage(self, threshold=0.05):
"""损伤检测"""
for i in range(self.physical.n_modes):
mode_key = f'mode_{i+1}'
# 比较数字模型和物理模型的频率
freq_physical = self.physical.modes[mode_key]['freq']
freq_digital = self.digital_modes[mode_key]['freq']
freq_change = abs(freq_digital - freq_physical) / freq_physical
if freq_change > threshold:
self.detected_damage[i] = min(freq_change / 0.3, 1.0)
# 更新数字模型
self.digital_modes[mode_key]['freq'] = freq_physical
self.digital_modes[mode_key]['stiffness'] = self.physical.modes[mode_key]['stiffness']
return self.detected_damage
def get_digital_response(self, t):
"""获取数字孪生预测响应"""
response = np.zeros((len(t), self.physical.n_modes))
for i, (mode_name, mode_props) in enumerate(self.digital_modes.items()):
omega = 2 * np.pi * mode_props['freq']
zeta = mode_props['damping']
omega_d = omega * np.sqrt(1 - zeta**2)
# 使用当前状态估计
if i < len(self.state_estimate) // 2:
amplitude = abs(self.state_estimate[2*i])
phase = 0
else:
amplitude = 0.1 / (i + 1)
phase = 0
response[:, i] = amplitude * np.exp(-zeta * omega * t) * np.cos(omega_d * t + phase)
return response
def simulate_digital_twin_scenario():
"""模拟数字孪生场景"""
print("=" * 70)
print("主题096 - 案例3: 数字孪生技术在结构健康监测中的应用")
print("=" * 70)
# 创建物理桥梁
physical = PhysicalBridge(span=500, n_modes=3)
# 创建数字孪生
digital_twin = DigitalTwin(physical)
# 时间设置
dt = 0.01
t_total = 100 # 总时间 (s)
n_steps = int(t_total / dt)
t = np.linspace(0, t_total, n_steps)
# 损伤事件设置
damage_events = [
{'time': 30, 'mode': 1, 'severity': 0.3}, # 30秒时,第1阶模态30%损伤
{'time': 60, 'mode': 2, 'severity': 0.2}, # 60秒时,第2阶模态20%损伤
]
print("\n模拟设置:")
print(f" 总时长: {t_total} s")
print(f" 时间步长: {dt} s")
print(f" 总步数: {n_steps}")
print(f"\n损伤事件:")
for event in damage_events:
print(f" t={event['time']}s: 模态{event['mode']} 损伤{event['severity']*100:.0f}%")
# 存储结果
physical_response_history = []
digital_response_history = []
damage_detected_history = []
frequency_history = {'physical': [], 'digital': []}
print("\n开始模拟...")
for step in range(n_steps):
current_time = t[step]
# 检查损伤事件
for event in damage_events:
if abs(current_time - event['time']) < dt/2:
physical.apply_damage(event['mode'], event['severity'])
print(f" t={current_time:.1f}s: 施加损伤 - 模态{event['mode']}")
# 获取物理响应(短时间窗口)
window_size = 100
if step >= window_size:
t_window = t[step-window_size:step]
physical_response = physical.get_true_response(t_window - t_window[0])
# 数字孪生预测
digital_twin.predict(dt)
# 测量更新(每10步)
if step % 10 == 0:
measurement = physical_response[-1, :]
innovation = digital_twin.update(measurement)
# 损伤检测(每50步)
if step % 50 == 0:
detected = digital_twin.detect_damage()
damage_detected_history.append(detected.copy())
# 记录结果
physical_response_history.append(physical_response[-1, :].copy())
digital_response_history.append(digital_twin.state_estimate[::2].copy())
# 记录频率
freq_p = [physical.modes[f'mode_{i+1}']['freq'] for i in range(3)]
freq_d = [digital_twin.digital_modes[f'mode_{i+1}']['freq'] for i in range(3)]
frequency_history['physical'].append(freq_p)
frequency_history['digital'].append(freq_d)
print("\n模拟完成!")
return {
't': t,
'physical_response': np.array(physical_response_history),
'digital_response': np.array(digital_response_history),
'damage_detected': np.array(damage_detected_history) if damage_detected_history else np.zeros((1, 3)),
'frequency': frequency_history,
'damage_events': damage_events
}
def visualize_digital_twin_results(results):
"""可视化数字孪生结果"""
fig = plt.figure(figsize=(16, 10))
# 确保数组维度一致
n_samples = min(len(results['physical_response']), len(results['digital_response']))
physical = results['physical_response'][:n_samples]
digital = results['digital_response'][:n_samples]
t = results['t'][-n_samples:]
freq_physical = np.array(results['frequency']['physical'][:n_samples])
freq_digital = np.array(results['frequency']['digital'][:n_samples])
# 1. 响应对比
ax1 = fig.add_subplot(2, 3, 1)
ax1.plot(t, physical[:, 0], 'b-', linewidth=1, alpha=0.7, label='物理结构')
ax1.plot(t, digital[:, 0], 'r--', linewidth=1.5, label='数字孪生')
ax1.set_xlabel('时间 (s)', fontsize=10)
ax1.set_ylabel('位移 (m)', fontsize=10)
ax1.set_title('第1阶模态响应对比', fontsize=11, fontweight='bold')
ax1.legend(fontsize=9)
ax1.grid(True, alpha=0.3)
# 标记损伤事件
for event in results['damage_events']:
ax1.axvline(x=event['time'], color='g', linestyle=':', alpha=0.7)
ax1.text(event['time'], ax1.get_ylim()[1]*0.9, f"D{event['mode']}",
fontsize=8, ha='center', color='green')
ax2 = fig.add_subplot(2, 3, 2)
ax2.plot(t, physical[:, 1], 'b-', linewidth=1, alpha=0.7, label='物理结构')
ax2.plot(t, digital[:, 1], 'r--', linewidth=1.5, label='数字孪生')
ax2.set_xlabel('时间 (s)', fontsize=10)
ax2.set_ylabel('位移 (m)', fontsize=10)
ax2.set_title('第2阶模态响应对比', fontsize=11, fontweight='bold')
ax2.legend(fontsize=9)
ax2.grid(True, alpha=0.3)
for event in results['damage_events']:
ax2.axvline(x=event['time'], color='g', linestyle=':', alpha=0.7)
ax3 = fig.add_subplot(2, 3, 3)
ax3.plot(t, physical[:, 2], 'b-', linewidth=1, alpha=0.7, label='物理结构')
ax3.plot(t, digital[:, 2], 'r--', linewidth=1.5, label='数字孪生')
ax3.set_xlabel('时间 (s)', fontsize=10)
ax3.set_ylabel('位移 (m)', fontsize=10)
ax3.set_title('第3阶模态响应对比', fontsize=11, fontweight='bold')
ax3.legend(fontsize=9)
ax3.grid(True, alpha=0.3)
# 2. 频率跟踪
ax4 = fig.add_subplot(2, 3, 4)
t_freq = np.linspace(t[0], t[-1], len(freq_physical))
ax4.plot(t_freq, freq_physical[:, 0], 'b-', linewidth=2, label='物理频率')
ax4.plot(t_freq, freq_digital[:, 0], 'r--', linewidth=2, label='数字孪生频率')
ax4.set_xlabel('时间 (s)', fontsize=10)
ax4.set_ylabel('频率 (Hz)', fontsize=10)
ax4.set_title('第1阶频率跟踪', fontsize=11, fontweight='bold')
ax4.legend(fontsize=9)
ax4.grid(True, alpha=0.3)
for event in results['damage_events']:
ax4.axvline(x=event['time'], color='g', linestyle=':', alpha=0.7)
ax5 = fig.add_subplot(2, 3, 5)
ax5.plot(t_freq, freq_physical[:, 1], 'b-', linewidth=2, label='物理频率')
ax5.plot(t_freq, freq_digital[:, 1], 'r--', linewidth=2, label='数字孪生频率')
ax5.set_xlabel('时间 (s)', fontsize=10)
ax5.set_ylabel('频率 (Hz)', fontsize=10)
ax5.set_title('第2阶频率跟踪', fontsize=11, fontweight='bold')
ax5.legend(fontsize=9)
ax5.grid(True, alpha=0.3)
for event in results['damage_events']:
ax5.axvline(x=event['time'], color='g', linestyle=':', alpha=0.7)
# 3. 预测误差
ax6 = fig.add_subplot(2, 3, 6)
error = np.abs(digital - physical)
ax6.plot(t, error[:, 0], linewidth=1, label='模态1误差', alpha=0.8)
ax6.plot(t, error[:, 1], linewidth=1, label='模态2误差', alpha=0.8)
ax6.plot(t, error[:, 2], linewidth=1, label='模态3误差', alpha=0.8)
ax6.set_xlabel('时间 (s)', fontsize=10)
ax6.set_ylabel('绝对误差', fontsize=10)
ax6.set_title('数字孪生预测误差', fontsize=11, fontweight='bold')
ax6.legend(fontsize=9)
ax6.grid(True, alpha=0.3)
ax6.set_yscale('log')
for event in results['damage_events']:
ax6.axvline(x=event['time'], color='g', linestyle=':', alpha=0.7)
plt.tight_layout()
plt.savefig('案例3_数字孪生监测结果.png', dpi=150, bbox_inches='tight',
facecolor='white', edgecolor='none')
print("\n监测结果图已保存到: 案例3_数字孪生监测结果.png")
plt.close()
def create_digital_twin_animation(results):
"""创建数字孪生实时监测动画"""
print("\n正在生成数字孪生动画...")
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# 确保数组维度一致
n_samples = min(len(results['physical_response']), len(results['digital_response']))
physical = results['physical_response'][:n_samples]
digital = results['digital_response'][:n_samples]
t = results['t'][-n_samples:]
# 子图1: 桥梁变形动画示意
ax1 = axes[0, 0]
ax1.set_xlim(0, 500)
ax1.set_ylim(-2, 2)
ax1.set_xlabel('位置 (m)', fontsize=10)
ax1.set_ylabel('变形 (m)', fontsize=10)
ax1.set_title('桥梁实时变形', fontsize=12, fontweight='bold')
ax1.grid(True, alpha=0.3)
# 桥梁轮廓
bridge_x = np.linspace(0, 500, 100)
line_physical, = ax1.plot([], [], 'b-', linewidth=3, label='物理结构')
line_digital, = ax1.plot([], [], 'r--', linewidth=2, label='数字孪生')
ax1.legend(fontsize=9, loc='upper right')
# 子图2: 模态响应时程
ax2 = axes[0, 1]
ax2.set_xlim(t[0], t[-1])
ax2.set_ylim(-0.5, 0.5)
ax2.set_xlabel('时间 (s)', fontsize=10)
ax2.set_ylabel('位移 (m)', fontsize=10)
ax2.set_title('模态响应时程', fontsize=12, fontweight='bold')
ax2.grid(True, alpha=0.3)
line_resp_p, = ax2.plot([], [], 'b-', linewidth=1.5, alpha=0.7, label='物理')
line_resp_d, = ax2.plot([], [], 'r--', linewidth=1.5, label='数字孪生')
current_time_line = ax2.axvline(x=0, color='g', linestyle=':', linewidth=2)
ax2.legend(fontsize=9, loc='upper right')
# 子图3: 频率跟踪
ax3 = axes[1, 0]
ax3.set_xlim(t[0], t[-1])
freq_physical = np.array(results['frequency']['physical'][:n_samples])
ax3.set_ylim(freq_physical[:, 0].min()*0.9, freq_physical[:, 0].max()*1.1)
ax3.set_xlabel('时间 (s)', fontsize=10)
ax3.set_ylabel('频率 (Hz)', fontsize=10)
ax3.set_title('基频实时跟踪', fontsize=12, fontweight='bold')
ax3.grid(True, alpha=0.3)
line_freq_p, = ax3.plot([], [], 'b-', linewidth=2, label='物理频率')
line_freq_d, = ax3.plot([], [], 'r--', linewidth=2, label='数字孪生频率')
ax3.legend(fontsize=9, loc='upper right')
# 子图4: 健康状态指示器
ax4 = axes[1, 1]
ax4.set_xlim(0, 1)
ax4.set_ylim(0, 1)
ax4.axis('off')
ax4.set_title('结构健康状态', fontsize=12, fontweight='bold')
# 状态指示器
status_box = FancyBboxPatch((0.1, 0.6), 0.8, 0.25,
boxstyle="round,pad=0.02",
facecolor='green', alpha=0.3,
transform=ax4.transAxes)
ax4.add_patch(status_box)
status_text = ax4.text(0.5, 0.725, '健康', fontsize=20, ha='center', va='center',
fontweight='bold', transform=ax4.transAxes)
# 损伤指示
damage_texts = []
for i in range(3):
text = ax4.text(0.2 + i*0.3, 0.4, f'模态{i+1}: 正常', fontsize=11,
ha='center', transform=ax4.transAxes)
damage_texts.append(text)
# 时间显示
time_text = ax4.text(0.5, 0.15, 't = 0.00 s', fontsize=14, ha='center',
transform=ax4.transAxes)
def init():
line_physical.set_data([], [])
line_digital.set_data([], [])
line_resp_p.set_data([], [])
line_resp_d.set_data([], [])
line_freq_p.set_data([], [])
line_freq_d.set_data([], [])
return [line_physical, line_digital, line_resp_p, line_resp_d,
line_freq_p, line_freq_d, current_time_line]
def update(frame):
idx = frame * 10 # 每10帧更新一次
if idx >= len(t):
idx = len(t) - 1
current_t = t[idx]
# 更新桥梁变形
deformation_p = physical[idx, 0] * np.sin(np.pi * bridge_x / 500)
deformation_d = digital[idx, 0] * np.sin(np.pi * bridge_x / 500)
line_physical.set_data(bridge_x, deformation_p)
line_digital.set_data(bridge_x, deformation_d)
# 更新响应时程
line_resp_p.set_data(t[:idx+1], physical[:idx+1, 0])
line_resp_d.set_data(t[:idx+1], digital[:idx+1, 0])
current_time_line.set_xdata([current_t, current_t])
# 更新频率跟踪
t_freq = np.linspace(t[0], t[-1], len(freq_physical))
freq_idx = min(idx, len(freq_physical)-1)
freq_digital_anim = np.array(results['frequency']['digital'][:n_samples])
line_freq_p.set_data(t_freq[:freq_idx+1], freq_physical[:freq_idx+1, 0])
line_freq_d.set_data(t_freq[:freq_idx+1], freq_digital_anim[:freq_idx+1, 0])
# 更新时间显示
time_text.set_text(f't = {current_t:.2f} s')
# 更新健康状态
for event in results['damage_events']:
if current_t >= event['time']:
status_box.set_facecolor('red')
status_box.set_alpha(0.3)
status_text.set_text('损伤检测')
status_text.set_color('red')
damage_texts[event['mode']-1].set_text(f"模态{event['mode']}: 损伤!")
damage_texts[event['mode']-1].set_color('red')
return [line_physical, line_digital, line_resp_p, line_resp_d,
line_freq_p, line_freq_d, current_time_line, time_text]
n_frames = len(t) // 10
anim = FuncAnimation(fig, update, init_func=init, frames=n_frames,
interval=50, blit=False)
writer = PillowWriter(fps=20)
anim.save('案例3_数字孪生实时监测.gif', writer=writer)
print("动画已保存到: 案例3_数字孪生实时监测.gif")
plt.close()
def main():
"""主函数"""
# 运行数字孪生模拟
results = simulate_digital_twin_scenario()
# 可视化结果
print("\n" + "="*60)
print("生成可视化结果")
print("="*60)
visualize_digital_twin_results(results)
create_digital_twin_animation(results)
print("\n" + "=" * 70)
print("案例3完成!所有结果已保存。")
print("=" * 70)
if __name__ == "__main__":
main()

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献111条内容
已为社区贡献111条内容

所有评论(0)