YOLOv8数据集构建+训练过程+结果分析与验证
目录
1数据集构建
我们先下载一个数据集标注工具
打开vscode在激活yolo环境之后下载此插件
pip install labelimg安装完之后,启动 labelimg ,输入
labelimg输入之后会弹出abelimg的程序
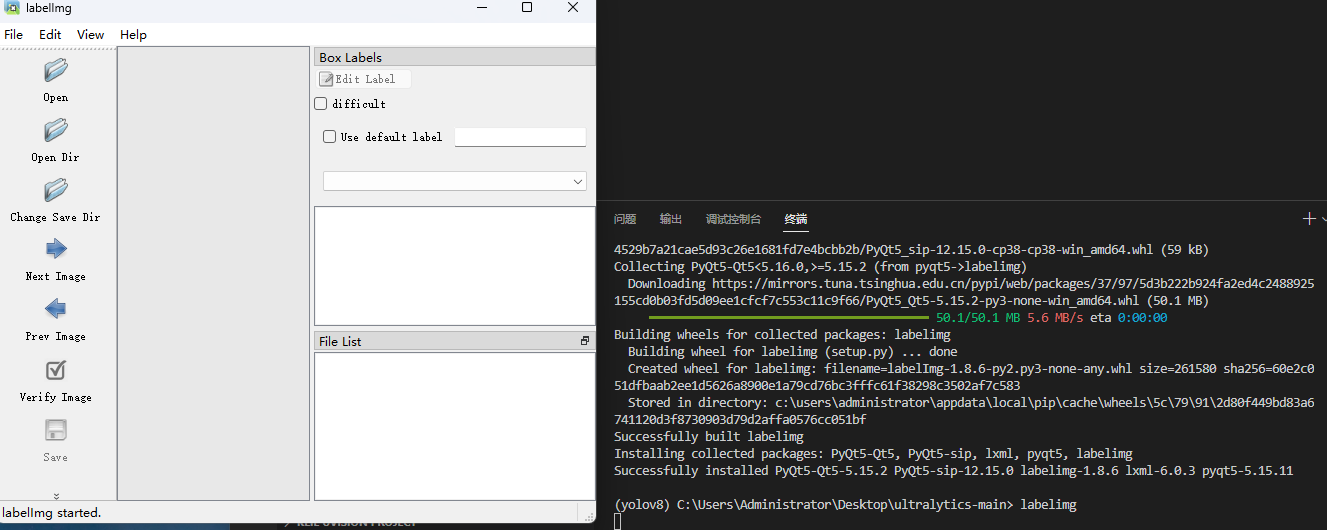
但是abelimg面临的问题是我们需要手动标注,会比较麻烦,因此我们选择更方便的方式,自己从网络上下载开源数据集--电线杆绝缘子缺陷检测
创建新的文件夹,在文件夹里面加进去训练集 验证集
这里我们先明确一下这两个是什么?
1.1训练集是什么
🎓 训练集 (Training Set) - “课本与习题”
-
核心作用:教模型认识什么是缺陷。
-
工作方式:你把带有标注框的图片(比如告诉模型“这个是绝缘子,那个是闪络”)喂给它。模型通过不断“做习题”(计算损失Loss)和“对答案”(反向传播)来调整自己的参数,学习如何从图片中提取特征、定位和分类目标。
-
你的情况:你用来训练的图片(比如之前推断出的约900-1400张)就是训练集。模型75轮的迭代,主要就是在这个数据集上完成的。
1.2验证集是什么
📝 验证集 (Validation Set) - “模拟考试”
-
核心作用:客观评估模型的表现,并监控训练过程。
-
工作方式:这部分图片模型从未在训练中见过。每完成一轮(或几轮)学习,我们就让模型在验证集上“考一次试”。通过计算它在验证集上的精确率(P)、召回率(R)、mAP等指标,我们才能知道模型是真的学会了,还是仅仅把训练集的题目背下来了(过拟合)。
-
你的情况:你那601张验证集图片就是“模拟考卷”。你看到的
mAP50=0.872、各类别的P、R值,都是模型在验证集这个“模拟考”中取得的真实成绩。
1.3 测试集又是什么
测试集就是“最终大考”,用来评估模型训练好之后的真实泛化能力。
它的核心原则是:模型在训练过程中,绝对不能“看到”或“接触”到测试集中的任何一张图片,就像学生在期末考试前,绝对不能提前看到考题一样。

1.4 产生的txt文件表示什么
但是我们又注意到lables文件夹里面全是txt文件,这又是什么呢?
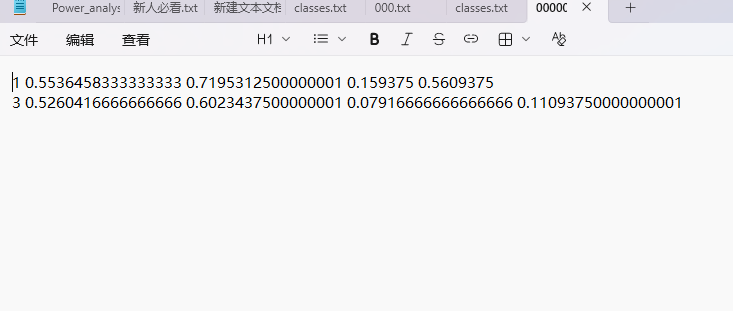
这些TXT文件并不是普通的文本,而是一种特定格式的坐标数据。每行代表图片中的一个目标(比如一个缺陷),格式如下:
<class_id> <x_center> <y_center> <width> <height>
-
<class_id>: 目标的类别编号,例如0代表daitu,1代表mingren。 -
<x_center> <y_center>: 目标中心点的位置,相对于图片的宽度和高度进行归一化后得到的坐标。 -
<width> <height>: 目标边界框的宽度和高度,同样是相对于图片的宽度和高度进行归一化后的值。
为什么不用其他格式(如JSON、XML)?
TXT格式简单、轻量,解析速度极快。对于YOLO这种需要每秒处理成百上千张图片的训练任务来说,速度至关重要。相比之下,JSON或XML这种结构化文件会增加不必要的解析开销。
文件之间的“一一对应”关系
这是最关键的一点。假设你的数据集里有一张名为 image_001.jpg 的图片,那么它的“答案”文件必须命名为 image_001.txt,并且放在labels文件夹下对应的子目录(train 或 val)中。
2 进行训练
创建yaml文件,输入以下内容
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ...]
path: bvn # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Classes
names:
0: flashover
1: insulator
2: lose
3: damaged在终端里面输入以下内容
yolo task=detect mode=train model=./yolov8n.pt data=yolo-bvn.yaml epochs=75 workers=1 batch=16
Deepseek表示好一点的显卡可以增加workers和batch大小
出现以下表示开始训练
3对结果进行简单分析
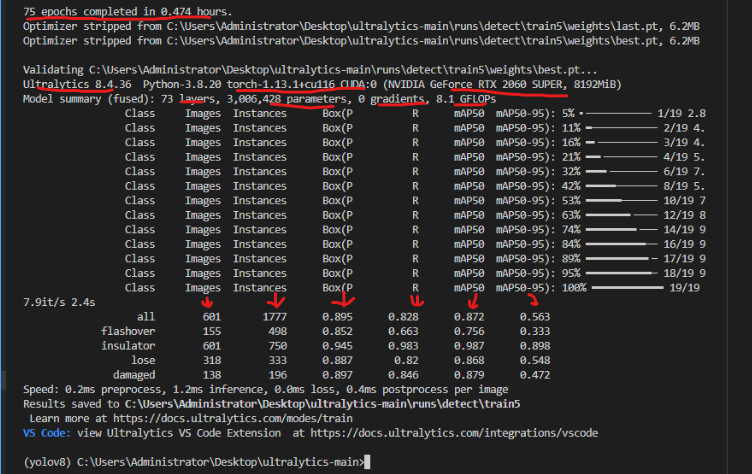
3.1验证集性能详解
整体性能(all类别)
| 指标 | 数值 | 含义 | 评价 |
|---|---|---|---|
| Images | 601 | 验证集图片数量 | 说明你的1500张图中约40%用于验证 |
| Instances | 1777 | 验证集中的标注目标总数 | 平均每张图约3个缺陷 |
| Box(P) | 0.895 | 精确率 = 89.5% | 优秀!预测为正样本中有89.5%是对的 |
| R | 0.828 | 召回率 = 82.8% | 良好!82.8%的真实缺陷被检出 |
| mAP50 | 0.872 | IoU=0.5时的平均精度 | 87.2%,非常好的成绩 |
| mAP50-95 | 0.563 | 严格阈值下的平均精度 | 56.3%,这是正常范围 |
各类别性能分析
你的数据集有 4个类别(从输出看是4类):
| 类别 | Images | Instances | P(精确率) | R(召回率) | mAP50 | mAP50-95 | 问题分析 |
|---|---|---|---|---|---|---|---|
| flashover | 155 | 498 | 0.852 | 0.663 | 0.756 | 0.333 | ⚠️ 召回率偏低,漏检较多 |
| insulator | 601 | 750 | 0.945 | 0.983 | 0.987 | 0.898 | ✅ 表现完美,检测非常准确 |
| lose | 318 | 333 | 0.887 | 0.820 | 0.868 | 0.548 | ✅ 表现良好 |
| damaged | 138 | 196 | 0.897 | 0.846 | 0.879 | 0.472 | ✅ 表现良好 |
3.2关键发现与建议
1. insulator(绝缘子)表现完美
-
mAP50高达 98.7%,几乎零错误
-
说明该类缺陷特征非常明显,模型学得很好
2. flashover(闪络)需要重点关注 ⚠️
-
召回率仅66.3%,意味着超过1/3的闪络缺陷被漏检
-
可能原因:
-
训练样本不足(只有155张图包含该类)
-
闪络缺陷特征不明显或变化多样
-
标注可能存在遗漏
-

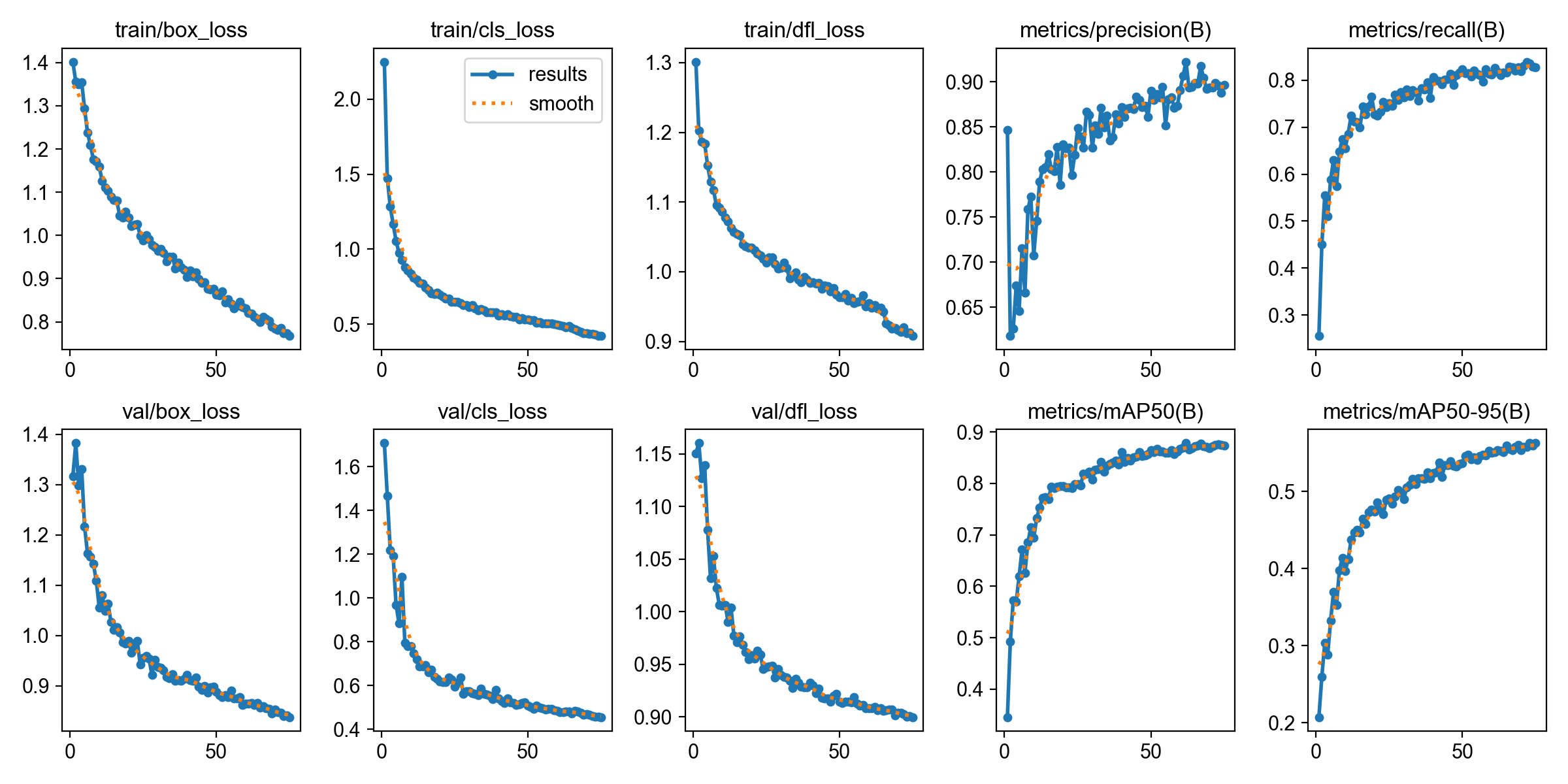
我们打开train5文件夹,可以查到结果保存的数据,可以观测出精度的变化
4借助测试集进行分析
启动了yolo之后,在CMD输入以下命令,包括-要选择的最佳模型-检测的图片地址-保存的位置
yolo detect predict model=runs/detect/train5/weights/best.pt source="C:\Users\Administrator\Desktop\ultralytics-main\datasets\bvn\images\test" save=True project=my_detect_results name=detection_results运行结束之后有如下结果!
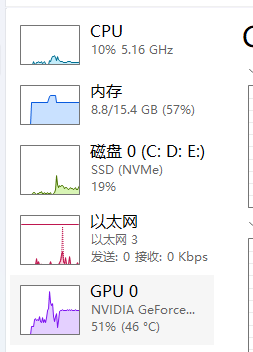
观测电脑处理性能 可见进行模型检测主要还是依赖GPU和内存
打开my_detect_results文件夹,观察训练好的图片


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)