Dify部署与安装
1、Dify 平台基础认知
Dify 是一个开源的、面向开发者的 LLM 应用开发平台。 其目标是成为 AI 应用时代的“操作系统”或“开发框架”。它通过可视化的方式,让开发者能够像搭积木一样,快速构建、部署和管理生产级的生成式 AI 应用 。
Dify官方文档:https://docs.dify.ai/zh-hans/introduction

核心定位:面向企业级场景,解决 “数据安全、定制化、长期运维” 等问题。
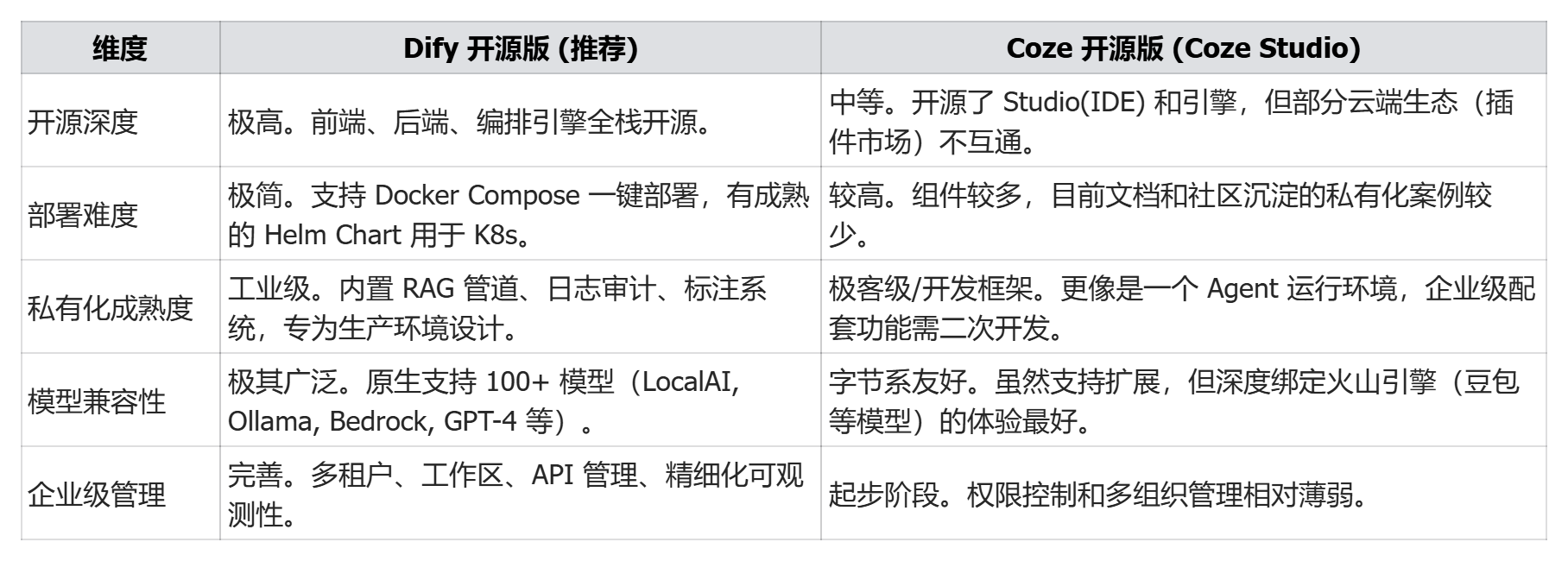
选型建议:
-
想快速做个 “功能型小工具 / 聊天机器人”→选 Coze;
-
要落地 “企业内部知识库、数据敏感的业务系统”→选 Dify。
2、Dify环境搭建
版本选择
Dify作为领先的AI应用开发平台,提供三种差异化部署方案,满足从个人开发者到大型企业的不同需求:
Dify云服务:开箱即用的SaaS方案
适合对象
个人开发者、初创团队、产品经理及各类希望快速验证 AI 应用想法的用户,无需关注底层技术细节,聚焦核心功能创新。
核心优势
即刻上手:通过 GitHub 或 Google 账号一键注册,无需信用卡,立享含 200 次免费调用的 Sandbox 计划;注册后无需复杂配置,快速进入应用搭建流程。
零部署成本:省去服务器采购、配置及维护工作,无需专业运维支持,大幅降低 AI 应用落地门槛。
数据安全保障
安全托管:用户数据安全存储于美国东部 AWS 服务器,依托 AWS 成熟的安全体系保障数据可用性与完整性。
敏感信息加密:API 密钥等敏感数据采用静态加密存储,Dify 平台无权限查看,从源头规避信息泄露风险。
隐私保护机制:应用数据经匿名化处理,严格遵循隐私保护规范,保障用户个人及业务隐私。
数据自主可控:用户可通过账户设置一键删除账户及所有关联数据,完全掌控数据生命周期。
Dify 开源部署:完全掌控,本地私有化
通过 Docker Compose 实现自托管部署,赋予用户对平台的完全控制权与数据所有权,适配深度定制与合规需求。
适合对象:对数据安全有严格要求的企业、希望进⾏⼆次开发的技术团队、以及希望深⼊学习 Dify 架构的开发者。
部署前提
硬件要求:CPU ≥ 2 核、RAM ≥ 4 GiB(处理海量数据或高并发场景建议 CPU ≥ 4 核、RAM ≥ 8 GiB)。
软件环境:已安装 Docker 20.10+ 及 Docker Compose 2.0+,确保部署环境兼容性。
核心特性
数据私有化部署:所有数据与服务均运行在用户自有服务器,完全隔绝外部访问,满足最高级别数据安全与行业合规要求。
深度定制自由:可完全访问、修改源代码,支持功能扩展、内部系统集成等个性化改造,适配复杂业务场景。
轻量化维护升级:通过
git pull同步最新代码,配合docker compose命令即可完成版本更新,无需复杂操作。技术栈透明可追溯:核心服务包含 api、worker、web 三大模块,基础组件涵盖 PostgreSQL、Redis、Weaviate 等,架构清晰,便于二次开发与问题排查。
部署开源版(基于Linux系统)
下载Dify项目压缩包
github地址:https://github.com/langgenius/dify/tree/main
当然,在今天的资料我也已经提前帮大家下载好了对应的源码包
解压源码包
解压dify-main.zip包,然后进入当前目录中找到docker文件夹
.env文件重命名
cd /root/dify-main/docker
mv .env.example .env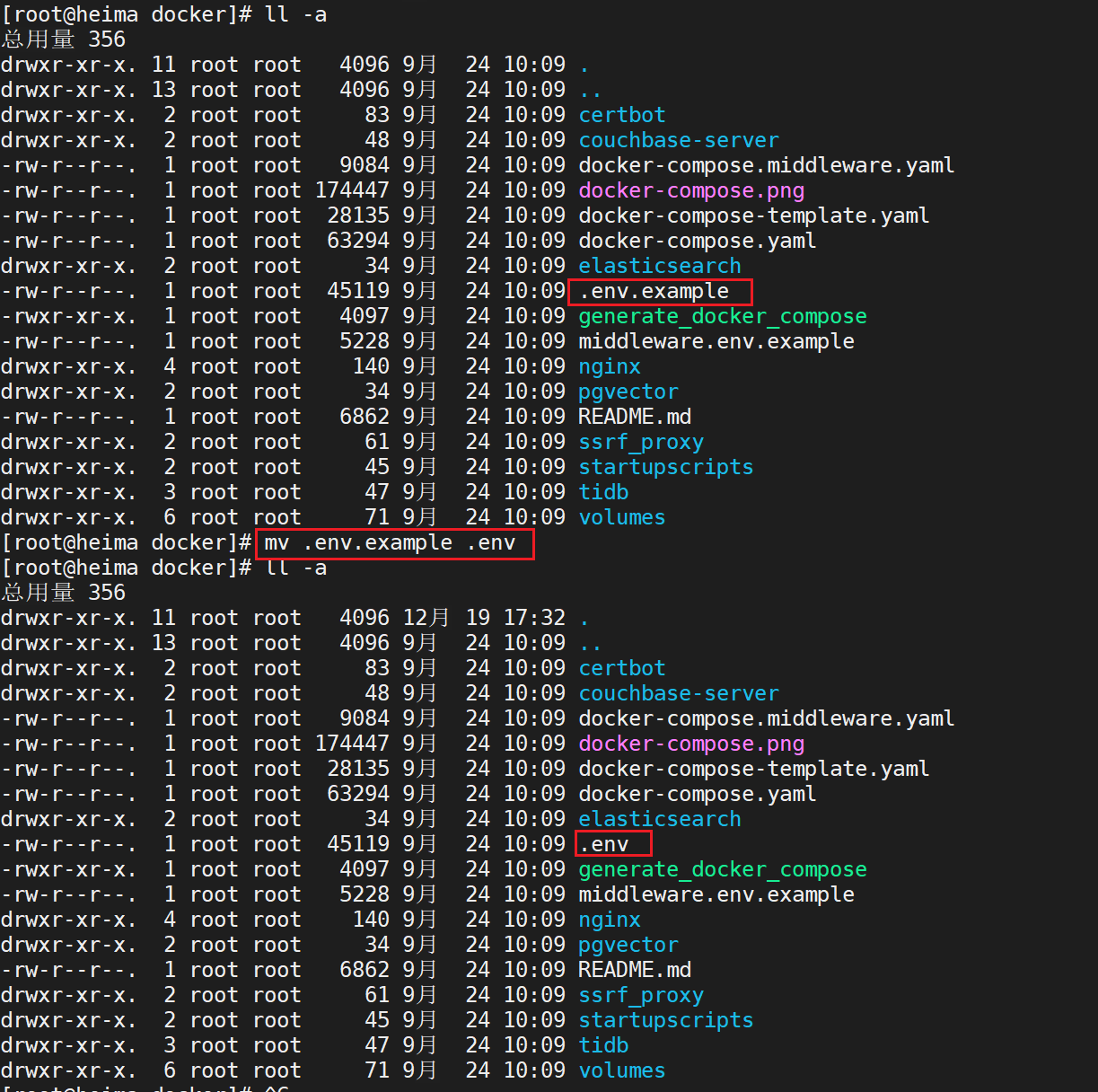
运行docker环境
docker-compose up -d下载需要等待一会,等下载完成以后,在Docker 里能看到对应的环境
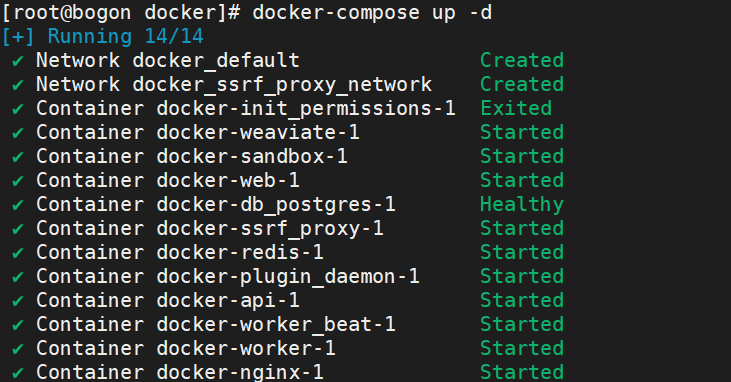
在浏览器中输入 http://192.168.194.129/install
-
首次登录需要进行注册
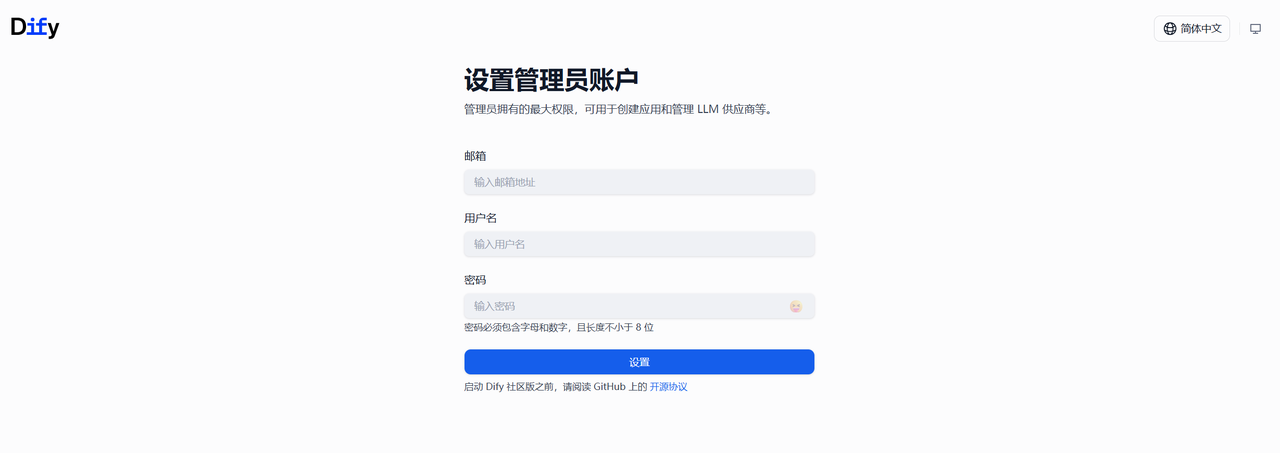
这里输入自己的邮箱和密码
- 注册之后,可以进入到主页面
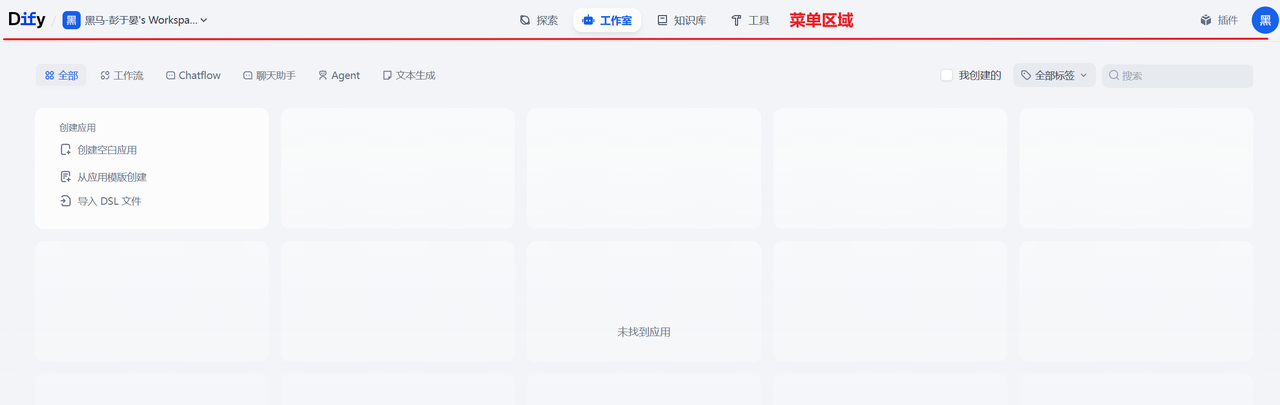
至此,Linux安装部署已经完成了,如果说你想继续深入了解Dify的具体操作,可以去网上查询相关教程。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)