基于沁恒CH32V407的卷积神经网络手写数字AI识别
本文在沁恒CH32V407上实现了基于人工智能框架TensorFlow Lite Micro(TFLM)的手写数字识别。以前在树莓派上部署过AI模型,但是在MCU上跑AI作者只能算初学者。这里对学习过程做一些记录,目前先实现了比较简单的手写数字识别,后续还会持续更新。
一、前期的准备工作
在MCU上跑AI,最常见的框架是TensorFlow Lite Micro(TFLM)。这里简要科普一下,TensorFlow的框架大致有三种,移动端的称作TensorFlow Lite(TFLite),主要面向手机和树莓派一类,MCU这种资源紧凑的设备则使用TensorFlow Lite Micro(TFLM)。
在MCU上跑TFLM,AI模型的推理如果没有硬件加速,会跑得很慢。MCU加速AI推理的方式主要有两种,一种是使用支持向量计算的内核,比如CH32V407的青稞RISC-V内核,另一种则是通过集成NPU单元来加速处理,比如STM32N6。
工程的准备是先从github上克隆TensorFlow的官方仓库tflite-micro,提取例程模板,然后把模板移植到CH32V407的工程里。提取和移植网上有很多资料可以参考,这里就不展开了。
需要注意的是,要充分利用CH32V407的向量加速,就需要使用适配青稞V3V内核的AI推理算子库。因为算子库里包含AI推理过程中使用的许多基本操作,比如卷积、池化、全连接等等,使用适配的算子库才能充分利用青稞RISC-V内核的向量加速和并行处理功能,从而提升AI模型的推理速度。
算子库不用重复造轮子,github上有现成的,添加到工程里,替换原始工程的相应文件,处理编译依赖就行。
二、手写数字识别的系统框架和实战
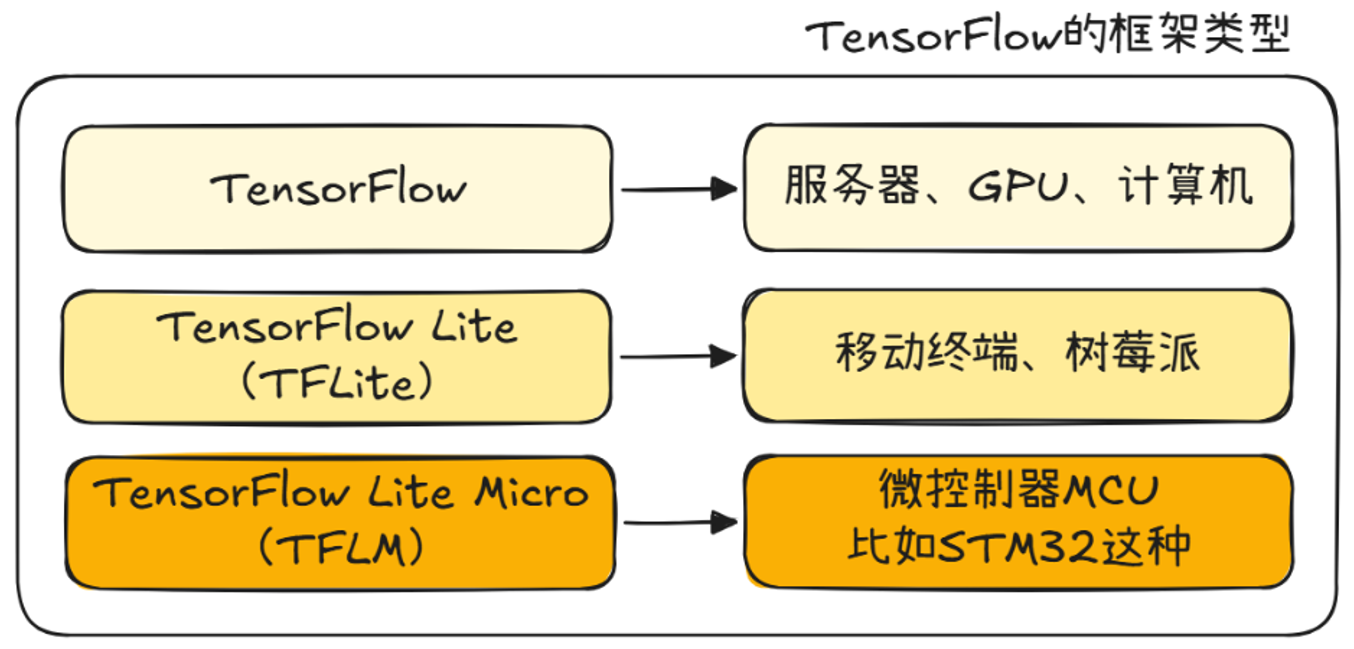
手写数字的图像捕获使用OV5640摄像头模组,用CH32V407自带的DVP接口获取图像。图像捕获后,经过缩放、灰度处理和归一化,输入神经网络,通过TensorFlow Lite Micro框架执行AI推理,将推理结果和原始图像合并后,用LCD显示屏输出。系统框架如下。
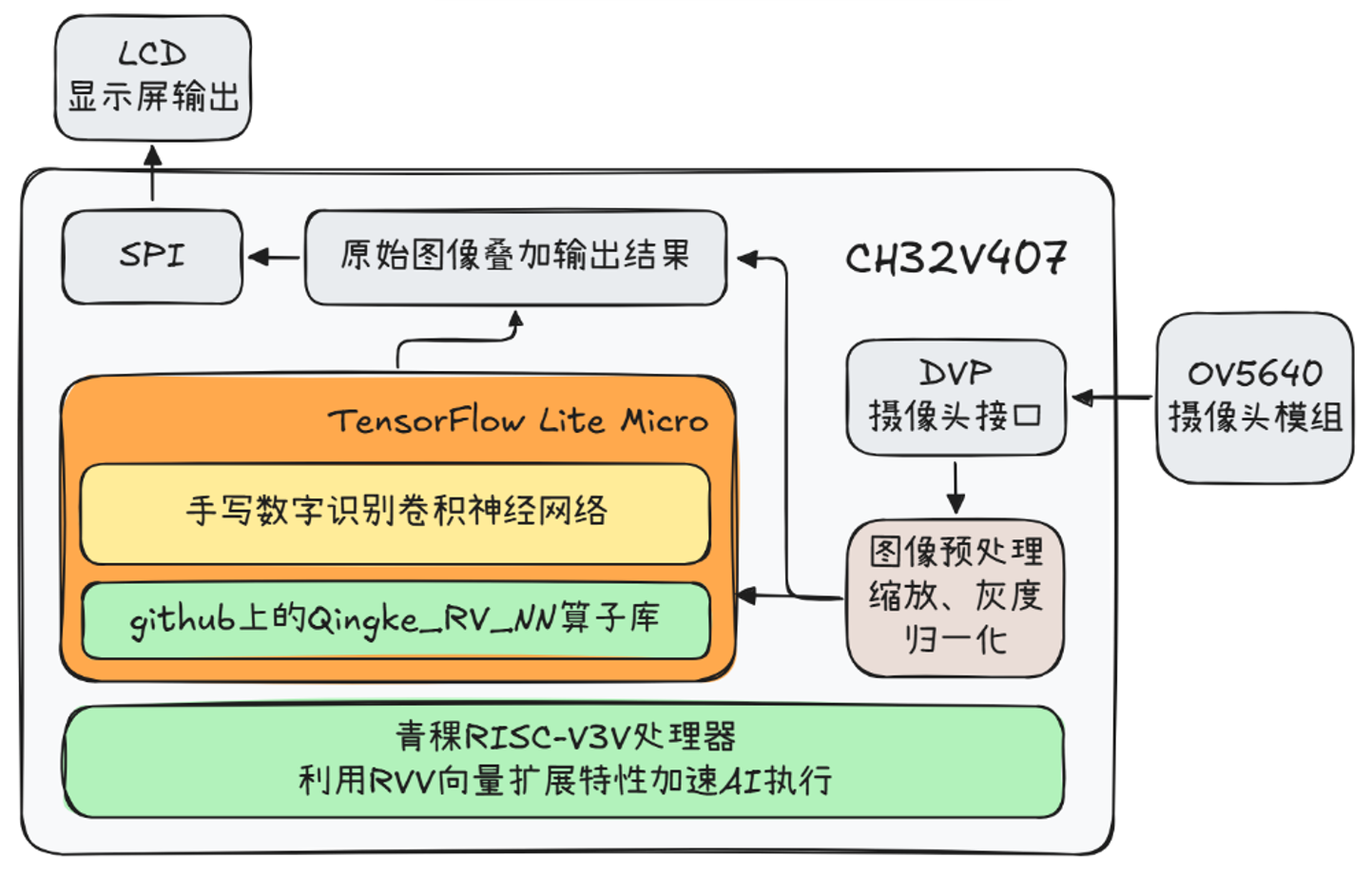
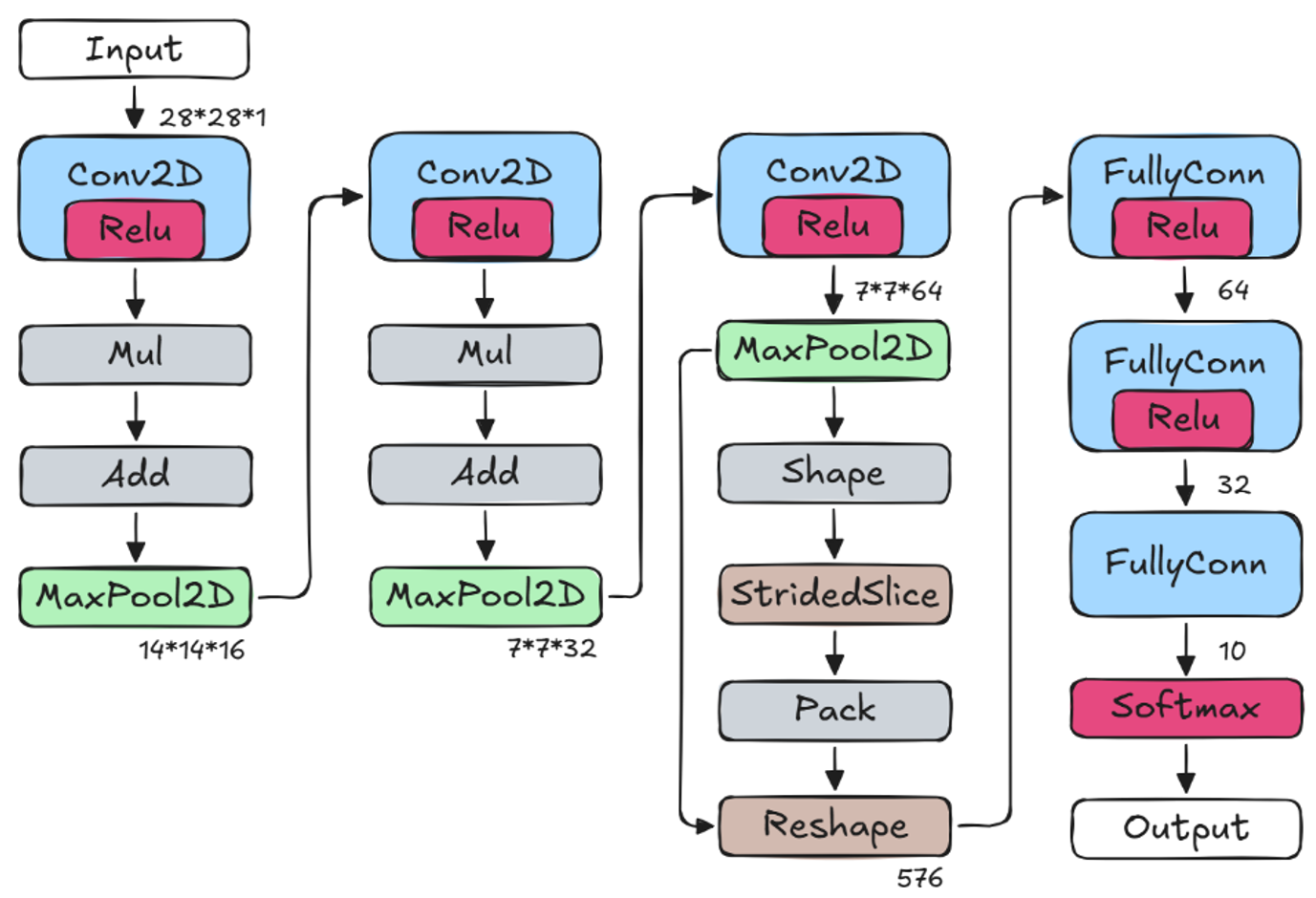
识别数字的卷积神经网络需要提前在电脑上训练好。训练用的数据集是现成的MNIST数据集,由于数据集使用的是28*28分辨率的图片,所以输入数据的尺寸也是28*28,这里给出我设计的一个神经网络模型。需要说明一下,手写数字识别不一定要用卷积这种运算量比较大的操作,这里用卷积是想充分发挥MCU的加速特性。
模型直接在电脑上用TensorFlow训练并量化。所谓量化,就是把模型使用的参数从浮点型转换为整形,同时压缩参数总量,从而降低计算量,方便MCU推理。这里选用INT8量化方式,量化后将模型转换成TFLM上使用的C语言数组备用。
在CH32V407上部署训练好的模型,核心操作是将AI模型的C数组更新到工程的mnist_model_data.h文件中,再去main.cc文件,找到tflite::MicroMutableOpResolver,注册模型用到的卷积和池化等操作。上图中涉及的Conv2D、MaxPool2D、Shape…都要注册。需要注意的是,TFLM只支持TensorFlow操作的子集,设计模型时要避免使用不支持的操作。
系统运行时,从DVP摄像头获取图像,对图像进行预处理,具体包括缩放、灰度转换和归一化,最终得到28*28尺寸的一维数组,调用process_mnist_optimized()将数组输入模型,再通过interpreter->Invoke()执行推理,原始图像和推理结果通过LCD屏幕显示。附效果图一张。

测试了有无并行计算加速的状态下,CH32V407每秒可执行上述卷积神经网络推理的次数,有向量加速的情况下,速度提升了14倍。数据如下。
|
/ |
不使用向量扩展 | 使用向量扩展加速 |
|---|---|---|
| 每秒执行次数 基于前述卷积神经网络 |
小于2次 |
约23次 (性能提升14倍) |
上述对比中,CH32V407的向量扩展对于加速AI推理的效果还是不错的。但同时还需要说明一下,神经网络的类型、层数和结构对推理效率的影响很大。我换用网上别人的模型,实测CH32V407每秒可推理超过150次,而且效果也不错。
P.S.
由于图像处理中也有一些量比较大的数据操作,我寻思可能也会使用向量指令。看了下工程编译的.lst文件,发现果然如此。比如下面这个RGB转灰度的操作:
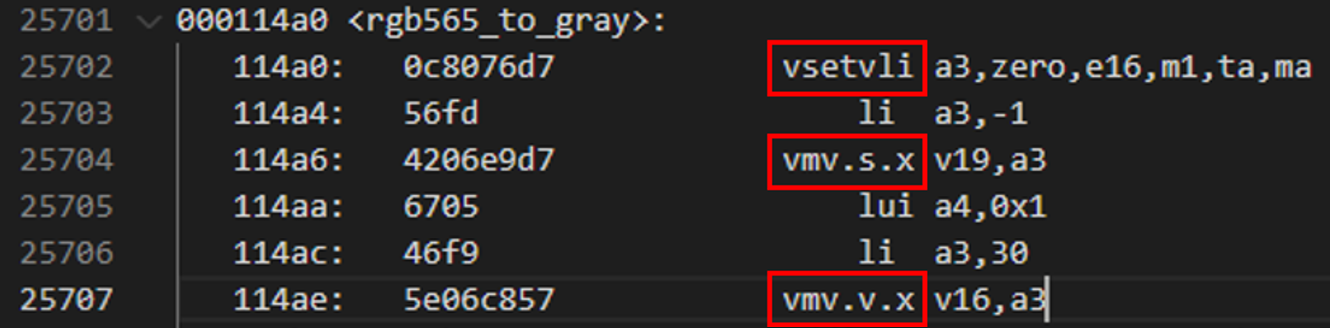
这说明CH32V407的向量扩展对于图像处理也有一定的提升。
后面考虑再尝试一下物体类型识别,会写文更新。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)