大数据分析与挖掘实战第二版
一、项目概述
1.1 项目背景
本系统是一个基于 Streamlit 构建的数据挖掘综合实验平台,旨在为数据科学学习提供一个交互式、可视化的实验环境。系统集成了 Python 基础知识、NumPy、Pandas、Matplotlib、数据预处理、机器学习、集成学习和深度学习等八大章节的代码实验。
1.2 核心功能
| 功能模块 | 功能描述 |
|---|---|
| 多语言支持 | 支持中文、英文、藏语、维吾尔语、蒙古语、朝鲜语6种语言 |
| 代码运行 | 在线执行Python代码,实时显示输出结果 |
| 变量查看 | 自动捕获并展示代码运行后的内存变量 |
| 图表生成 | 自动识别并显示Matplotlib生成的图表 |
| AI智学助手 | 内置智能问答系统,解答数据科学相关问题 |
| 批量运行 | 同时运行多个实验,对比执行结果 |
| 结果对比 | 对比不同实验生成的变量数据 |
1.3 技术栈
# 核心依赖库
import streamlit as st # Web应用框架
import pandas as pd # 数据处理
import numpy as np # 数值计算
import matplotlib.pyplot as plt # 数据可视化二、系统架构设计
2.1 整体架构图

2.2 目录结构
三、核心功能实现详解
3.1 多语言系统
系统内置了6种语言的翻译字典,支持界面动态切换。
# 多语言翻译字典结构示例
TRANSLATIONS = {
'zh': { # 中文
'app_title': '数据挖掘综合实验平台',
'student': '学生: ',
'run_result': '🚀 运行结果',
# ... 更多翻译键值对
},
'en': { # 英文
'app_title': 'Data Mining Experimental Platform',
'student': 'Student: Li Jinling',
# ... 更多翻译
},
# 'bo': 藏语, 'ug': 维吾尔语, 'mn': 蒙古语, 'ko': 朝鲜语
}
# 获取翻译文本的函数
def get_text(key):
lang = st.session_state.get('language', 'zh') # 获取当前语言
if lang in TRANSLATIONS:
return TRANSLATIONS[lang].get(key, TRANSLATIONS['zh'][key])
return TRANSLATIONS['zh'][key]功能说明:
-
使用
st.session_state存储当前选择的语言 -
通过
get_text()函数动态获取对应语言的文本 -
支持6种语言的界面切换
3.2 章节与实验配置映射
系统将8大章节与对应的实验文件进行结构化配置。
# ====== 获取当前文件所在目录 ======
current_dir = os.path.dirname(os.path.abspath(__file__))
# ====== 定义各章节的文件映射 ======
chapters_config = {
"✨ 第 1 章 Python 基础知识": {
"icon": "🐍",
"folder": "第 1 章 Python 基础知识",
"files": {
"1.3 基础数据类型": "1.3.py",
"1.4 序列索引与切片": "1.4.py",
"1.5.1 列表操作": "1.5.1.py",
"1.5.2 元组操作": "1.5.2.py",
"1.5.3 字符串操作": "1.5.3.py",
"1.6 字典操作": "1.6.py",
"1.7 条件语句": "1.7.py",
"1.8 循环语句": "1.8.py",
"1.9 函数定义": "1.9.py"
}
},
"🔮 第 2 章 NumPy": {
"icon": "🔢",
"folder": "第 2 章 Numpy",
"files": {
"2.1 数组创建": "2.1.py",
"2.2 数组运算": "2.2.py",
"2.3 索引与切片": "2.3.py",
"2.4 数组形状操作": "2.4.py",
"2.5 随机数生成": "2.5.py",
"2.6 统计分析": "2.6.py",
"2.7 矩阵运算": "2.7.py",
"2.8 数组排序": "2.8.py",
"2.9 数组保存与加载": "2.9.py",
"2.10 高级索引": "2.10.py"
}
},
"📊 第 3 章 Pandas": {
"icon": "📊",
"folder": "第 3 章 Pandas",
"files": {
"3.2.1 Series 创建": "3.2.1.py",
"3.2.2 DataFrame 创建": "3.2.2.py",
"3.2.3 数据查看": "3.2.3.py",
"3.2.4 数据筛选": "3.2.4.py",
"3.2.5 数据操作": "3.2.5.py",
"3.3 数据读取与写入": "3.3.py",
"3.4 数据清洗": "3.4.py"
}
},
"📈 第 4 章 Matplotlib": {
"icon": "📈",
"folder": "第 4 章 Matplotlib",
"files": {
"4.2.1 散点图": "4.2.1.py",
"4.1.2 线性图": "4.1.2.py",
"4.1.3 曲线图": "4.1.3.py",
"4.1.4 折线图": "4.1.4.py",
"4.2.2-4.2.6 综合绘图": "4.2.2~4.2.6.py",
"4.2.7 子图布局": "4.2.7.py"
}
},
"🧹 第 5 章 数据预处理": {
"icon": "🧹",
"folder": "第 5 章 数据预处理与特征工程",
"files": {
"5.1 缺失值处理": "5.1.py",
"5.2.1 数据标准化": "5.2.1.py",
"5.2.2 数据归一化": "5.2.2.py",
"5.3.1 数据编码": "5.3.1.py",
"5.3.2-5.4 特征选择": "5.3.2-5.4.py",
"5.5.1 PCA 降维": "5.5.1.py",
"5.5.2 PCA 可视化": "5.5.2.py",
"5.7.1 数据不平衡处理": "5.7.1.py",
"5.7.2 SMOTE": "5.7.2.py",
"5.8.1 特征提取": "5.8.1.py",
"5.8.2 特征构造": "5.8.2.py",
"5.9 特征工程综合": "5.9.py",
"5.10.1 特征重要性": "5.10.1.py",
"5.10.2 特征选择综合": "5.10.2.py"
}
},
"🤖 第 6 章 机器学习": {
"icon": "🤖",
"folder": "第 6 章 机器学习与实现",
"files": {
"6.1 线性回归": "6.1.py",
"6.2 逻辑回归": "6.2.py",
"6.3.3 KNN 分类": "6.3.3.py",
"6.3.4 KNN 回归": "6.3.4.py",
"6.4 决策树": "6.4.py",
"6.5.1 K-Means": "6.5.1.py",
"6.5.2 SVM 回归": "6.5.2.py",
"6.6.3 朴素贝叶斯": "6.6.3.py"
}
},
"🎯 第 7 章 集成学习": {
"icon": "🎯",
"folder": "第 7 章 集成学习与实现",
"files": {
"7.2.3 Bagging (1)": "7.2.3 Bagging算法的应用举例(1).py",
"7.2.3 Bagging (2)": "7.2.3 Bagging算法的应用举例(2).py",
"7.3.3 随机森林 (1)": "7.3.3 Python随机森林算法的应用举例(1).py",
"7.3.3 随机森林 (2)": "7.3.3 Python随机森林算法的应用举例(2).py",
"7.5.3 AdaBoost (1)": "7.5.3 AdaBoost算法的应用举例(1).py",
"7.5.3 AdaBoost (2)": "7.5.3 AdaBoost算法的应用举例(2).py",
"7.6.3 GBDT (1)": "7.6.3 GBDT算法的应用举例(1).py",
"7.6.3 GBDT (2)": "7.6.3 GBDT算法的应用举例(2).py",
"7.7.3 XGBoost (1)": "7.7.3 XGBOOST算法的应用举例(1).py",
"7.7.3 XGBoost (2)": "7.7.3 XGBOOST算法的应用举例(2).py"
}
},
"🧠 第 8 章 深度学习": {
"icon": "🧠",
"folder": "第 8 章 深度学习与实现",
"files": {
"8.3.3 TensorFlow 基础": "8.3.3 tensorflow案例.py",
"8.4.2 MLP-MNIST": "8.4.2-MLP-MNIST案例.py",
"8.4.3 MLP-MPG 分类": "8.4.3-MLP-MPG分类问题.py",
"8.5.4 CNN-Cifar10": "8.5.4-CNN-Cifar10案例.py",
"8.6.3 RNN-IMDB": "8.6.3-RNN-IMDB案例.py"
}
}
}
3.3 智能文件查找引擎
系统能够智能查找实验脚本文件,支持多种匹配策略。
def find_file(filename, folder_hint=None):
"""智能查找文件,支持模糊匹配"""
# 1. 定义搜索路径列表
search_paths = [current_dir, os.path.join(current_dir, "数据")]
# 2. 添加各章节文件夹路径
for chapter_name, config in chapters_config.items():
folder = config.get("folder", chapter_name)
# 移除图标前缀
for prefix in ("✨ ", "🔮 ", "📊 "):
if folder.startswith(prefix):
folder = folder[2:]
break
path = os.path.join(current_dir, folder)
if path not in search_paths and os.path.isdir(path):
search_paths.append(path)
# 3. 精确匹配
for path in search_paths:
full_path = os.path.join(path, filename)
if os.path.exists(full_path):
return full_path
# 4. 模糊匹配(忽略空格和括号差异)
for path in search_paths:
for file in os.listdir(path):
norm_file = file.replace(" ", "").replace("(", "(").replace(")", ")")
norm_filename = filename.replace(" ", "").replace("(", "(").replace(")", ")")
if norm_file == norm_filename:
return os.path.join(path, file)
# 5. 递归搜索
for root, dirs, files in os.walk(current_dir):
for file in files:
if file == filename:
return os.path.join(root, file)
return None3.4 Python代码安全执行引擎
核心执行引擎,负责运行Python代码并捕获输出、变量和图表。
def execute_python_code(code, filename, file_dir, exp_name):
"""安全执行Python代码,捕获输出、变量和图表"""
output_buffer = io.StringIO() # 捕获控制台输出
original_cwd = os.getcwd() # 保存原始工作目录
# 切换工作目录到脚本所在文件夹
if file_dir and os.path.exists(file_dir):
os.chdir(file_dir)
# 记录执行前的图片文件
before_images = set()
if file_dir:
for f in os.listdir(file_dir):
if f.endswith(('.png', '.jpg', '.jpeg')):
before_images.add(f)
# 清空Matplotlib图形
plt.clf()
plt.close('all')
# 准备执行环境
exec_globals = {
'np': np, 'pd': pd, 'plt': plt, # 常用库
'os': os, 'sys': sys, # 系统库
'__name__': '__main__'
}
# 重定向标准输出
old_stdout, old_stderr = sys.stdout, sys.stderr
sys.stdout = output_buffer
sys.stderr = output_buffer
try:
# 执行用户代码
exec(code, exec_globals)
output = output_buffer.getvalue()
# 检测新生成的图片
generated_images = []
if file_dir:
after_images = set(os.listdir(file_dir))
new_images = after_images - before_images
for img in new_images:
if img.endswith(('.png', '.jpg', '.jpeg')):
generated_images.append(os.path.join(file_dir, img))
# 捕获Matplotlib图形对象
figures = []
all_figs = [plt.figure(i) for i in plt.get_fignums()]
for fig in all_figs:
if fig and fig.get_axes():
figures.append(fig)
# 提取内存变量
variables = {}
exclude_names = {'np', 'pd', 'plt', 'os', 'sys', '__name__'}
for key, value in exec_globals.items():
if key.startswith('_') or callable(value):
continue
if key in exclude_names:
continue
variables[key] = value
return output, None, variables, generated_images, figures
except Exception as e:
error_msg = f"执行出错:\n{str(e)}\n\n{traceback.format_exc()}"
return output_buffer.getvalue(), error_msg, {}, [], []
finally:
# 恢复标准输出和工作目录
sys.stdout, sys.stderr = old_stdout, old_stderr
os.chdir(original_cwd)执行流程图:
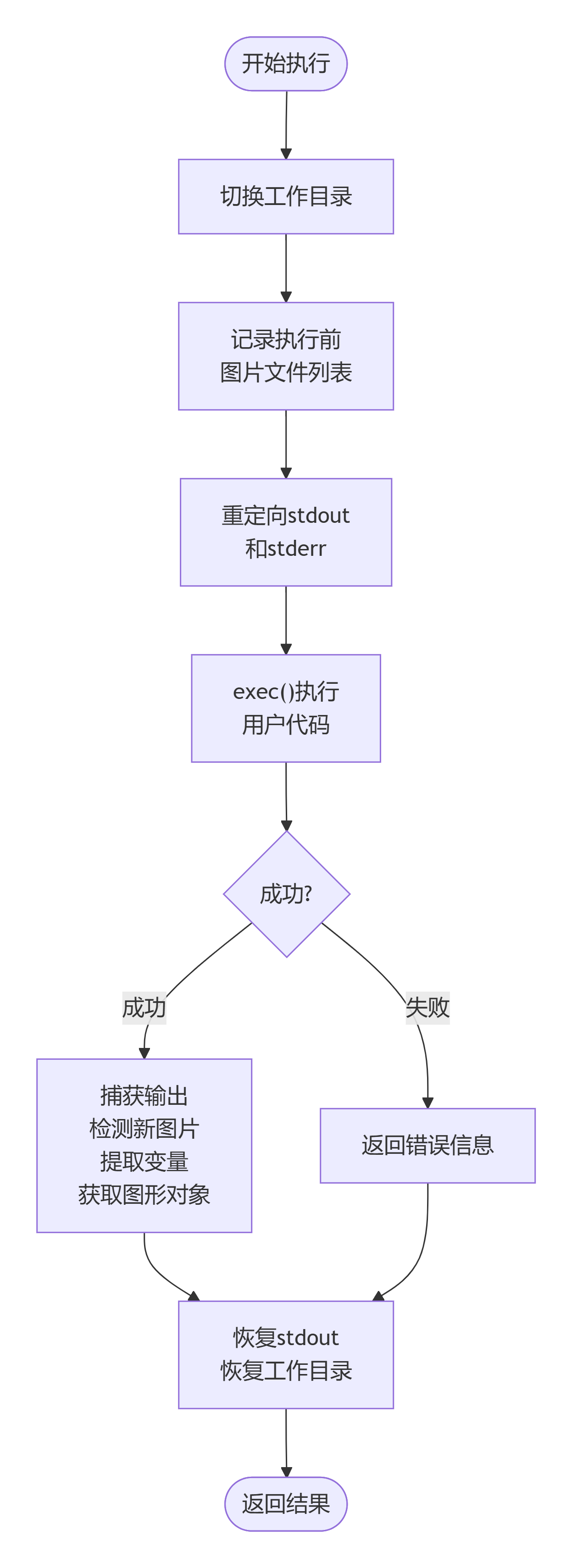
3.5 AI智学助手
内置智能问答系统,能够回答数据科学相关问题。
def ai_response(question, language='zh'):
"""AI助手响应函数,基于关键词匹配"""
q = question.lower()
# 数据挖掘相关问题
if any(k in q for k in ['数据挖掘', 'data mining', '什么是数据挖掘']):
return """📊 **数据挖掘详解**
数据挖掘是从大量数据中提取隐含的、未知的、潜在有用信息和知识的过程。
**核心任务**:分类、回归、聚类、关联规则、异常检测
**经典流程**:业务理解→数据理解→数据准备→建模→评估→部署"""
# Python相关问题
elif any(k in q for k in ['python', '编程', '代码']):
if any(k in q for k in ['循环', 'for', 'while']):
return """🔄 **Python 循环语句**
```python
for i in range(5):
print(i)
while count < 5:
print(count)
count += 1
```"""
# 机器学习相关问题
elif any(k in q for k in ['机器学习', 'machine learning']):
if any(k in q for k in ['聚类', 'kmeans']):
return """🎯 **K-Means聚类**
```python
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
labels = kmeans.fit_predict(X)
```"""
# Pandas相关问题
elif any(k in q for k in ['pandas', 'csv', 'excel']):
return """📊 **Pandas**
```python
import pandas as pd
df = pd.read_csv('file.csv')
df.head(), df.info()
df[df['age'] > 18]
df.groupby('category').mean()
```"""
# Matplotlib相关问题
elif any(k in q for k in ['matplotlib', '绘图', '散点图']):
return """📈 **Matplotlib**
```python
import matplotlib.pyplot as plt
plt.scatter(x, y)
plt.plot(x, y)
plt.bar(categories, values)
plt.show()
```"""
# 默认响应
else:
return f"""💡 关于「{question[:50]}...」
我擅长回答:数据挖掘、Python、机器学习、数据可视化、数据清洗等问题。"""3.6 批量运行功能
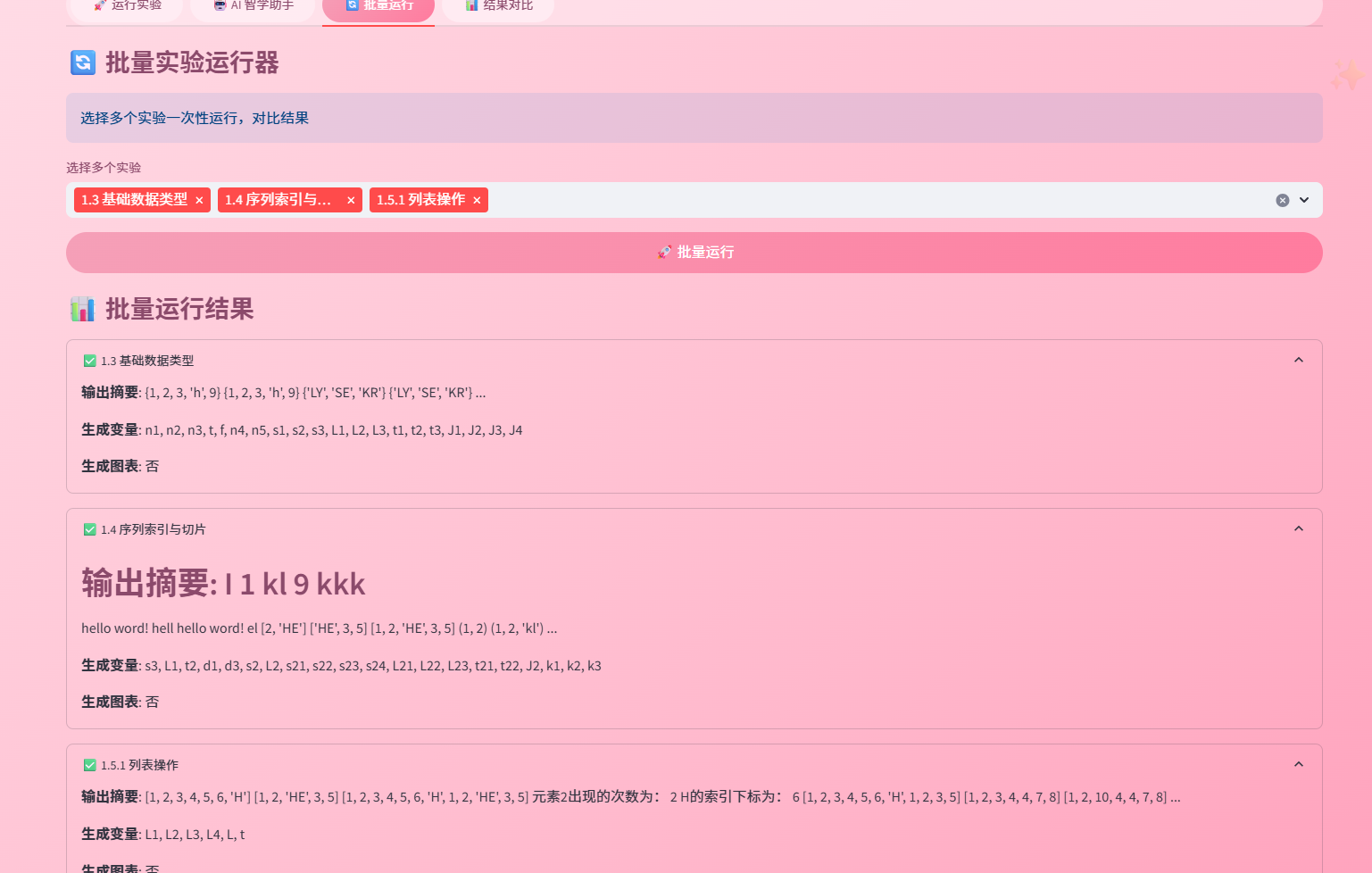
支持同时运行多个实验,适合对比分析。
# 批量运行核心代码
with batch_tab:
# 多选实验
selected_batch = st.multiselect(
get_text('select_multiple'),
all_exps,
default=all_exps[:3]
)
if st.button("🚀 批量运行"):
results = {}
progress_bar = st.progress(0) # 进度条
status_text = st.empty() # 状态文本
for i, exp_name in enumerate(selected_batch):
status_text.text(f"正在运行: {exp_name}")
# 获取实验代码
exp_file = current_config["files"][exp_name]
exp_code, exp_path = read_file_content(exp_file, folder_hint)
# 执行代码
output, error, variables, images, figures = execute_python_code(
exp_code, exp_path, exp_dir, exp_name
)
# 存储结果
results[exp_name] = {
'success': error is None,
'output': output[:500],
'variables': list(variables.keys()),
'has_charts': len(images) + len(figures) > 0
}
# 更新进度
progress_bar.progress((i + 1) / len(selected_batch))
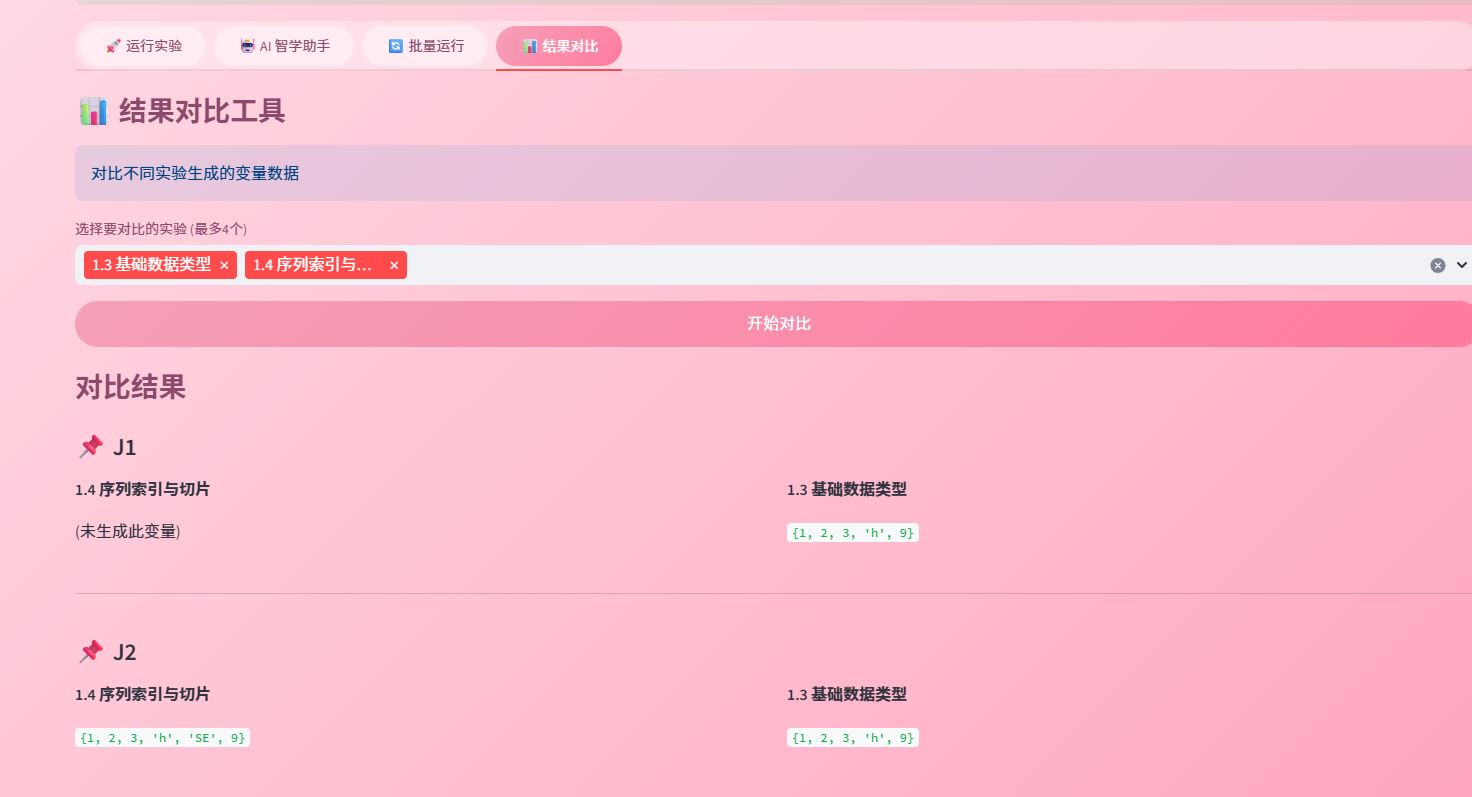
st.session_state.batch_results = results3.7 结果对比功能
对比不同实验生成的变量,帮助理解算法差异。
# 结果对比核心代码
with compare_tab:
# 选择要对比的实验
exps_to_compare = st.multiselect(
"选择要对比的实验 (最多4个)",
all_exps,
max_selections=4
)
if exps_to_compare and st.button("开始对比"):
compare_results = {}
for exp_name in exps_to_compare:
# 执行实验代码
# ... 执行逻辑 ...
compare_results[exp_name] = {
'success': error is None,
'variables': variables,
'has_charts': has_charts
}
# 提取所有变量名
all_vars = set()
for data in compare_results.values():
if data['success']:
all_vars.update(data['variables'].keys())
# 并排对比显示
for var_name in sorted(all_vars):
cols = st.columns(len(compare_results))
for col, (exp_name, data) in zip(cols, compare_results.items()):
with col:
st.markdown(f"**{exp_name}**")
var_value = data['variables'].get(var_name)
# 根据类型显示变量内容
if isinstance(var_value, pd.DataFrame):
st.dataframe(var_value.head(5))
elif isinstance(var_value, np.ndarray):
st.write(f"形状: {var_value.shape}")四、界面设计
4.1 CSS样式设计
系统采用了粉色主题和玻璃态卡片效果:
st.markdown("""
<style>
/* 粉色渐变背景 */
.stApp {
background: linear-gradient(135deg, #ffe4ec 0%, #ffd0dd 30%, #ffb8cc 70%, #ffa3bd 100%);
background-attachment: fixed;
}
/* 玻璃卡片效果 */
.glass-card {
background: rgba(255, 245, 248, 0.92);
backdrop-filter: blur(15px);
border-radius: 28px;
padding: 28px;
margin: 20px 0;
border: 1px solid rgba(255, 200, 213, 0.8);
box-shadow: 0 8px 32px rgba(255, 105, 140, 0.2);
transition: all 0.3s ease;
}
.glass-card:hover {
transform: translateY(-3px);
box-shadow: 0 12px 40px rgba(255, 105, 140, 0.3);
}
/* 按钮粉色主题 */
.stButton > button {
background: linear-gradient(135deg, #f5a0b8, #ff7b9e);
color: white !important;
border-radius: 50px;
padding: 10px 24px;
font-weight: 600;
border: none;
}
/* 输出框样式 */
.output-box {
background: rgba(50, 30, 40, 0.95);
border-left: 4px solid #ff7b9e;
padding: 20px;
border-radius: 16px;
font-family: monospace;
color: #ffc0d0;
}
/* 动画效果 */
@keyframes float {
0%, 100% { transform: translateY(0px) rotate(0deg); }
50% { transform: translateY(-20px) rotate(10deg); }
}
</style>
""", unsafe_allow_html=True)4.2 页面布局
# 页面配置
st.set_page_config(
page_title="数据挖掘综合实验平台 | 李金灵",
layout='wide',
page_icon="🌸"
)
# 主标签页布局
main_tab, ai_tab, batch_tab, compare_tab = st.tabs([
"🚀 运行实验", # Tab 0: 代码运行
"🤖 AI 智学助手", # Tab 1: AI问答
"🔄 批量运行", # Tab 2: 批量执行
"📊 结果对比" # Tab 3: 结果对比
])五、使用说明
5.1 启动方式
# 在终端中运行
streamlit run xxx.py5.2 操作流程
-
选择语言:在左侧边栏点击对应语言的按钮
-
选择章节:从下拉菜单中选择要学习的章节
-
选择实验:从下拉菜单中选择具体的实验项目
-
运行代码:点击"运行代码"按钮查看执行结果
-
查看结果:系统自动显示输出、变量和图表
5.3 功能入口说明
| 入口位置 | 功能 | 说明 |
|---|---|---|
| 侧边栏 | 语言切换 | 6种语言即时切换 |
| 主界面 | 章节/实验选择 | 8大章节50+实验 |
| Tab 0 | 运行实验 | 执行代码、查看结果 |
| Tab 1 | AI助手 | 智能问答 |
| Tab 2 | 批量运行 | 多实验同时执行 |
| Tab 3 | 结果对比 | 实验结果并排对比 |
六、功能截图
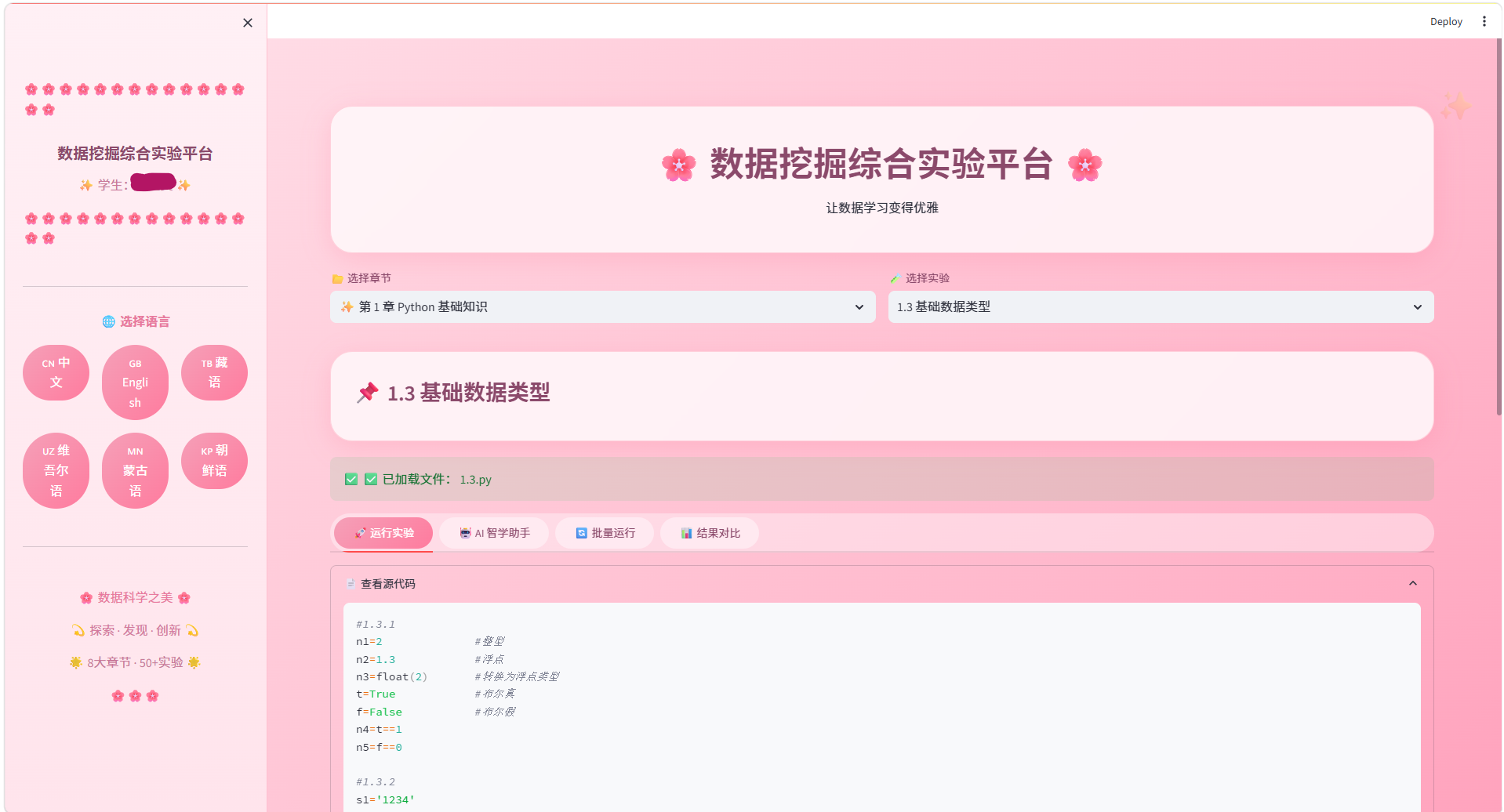
6.2 多语言切换截图

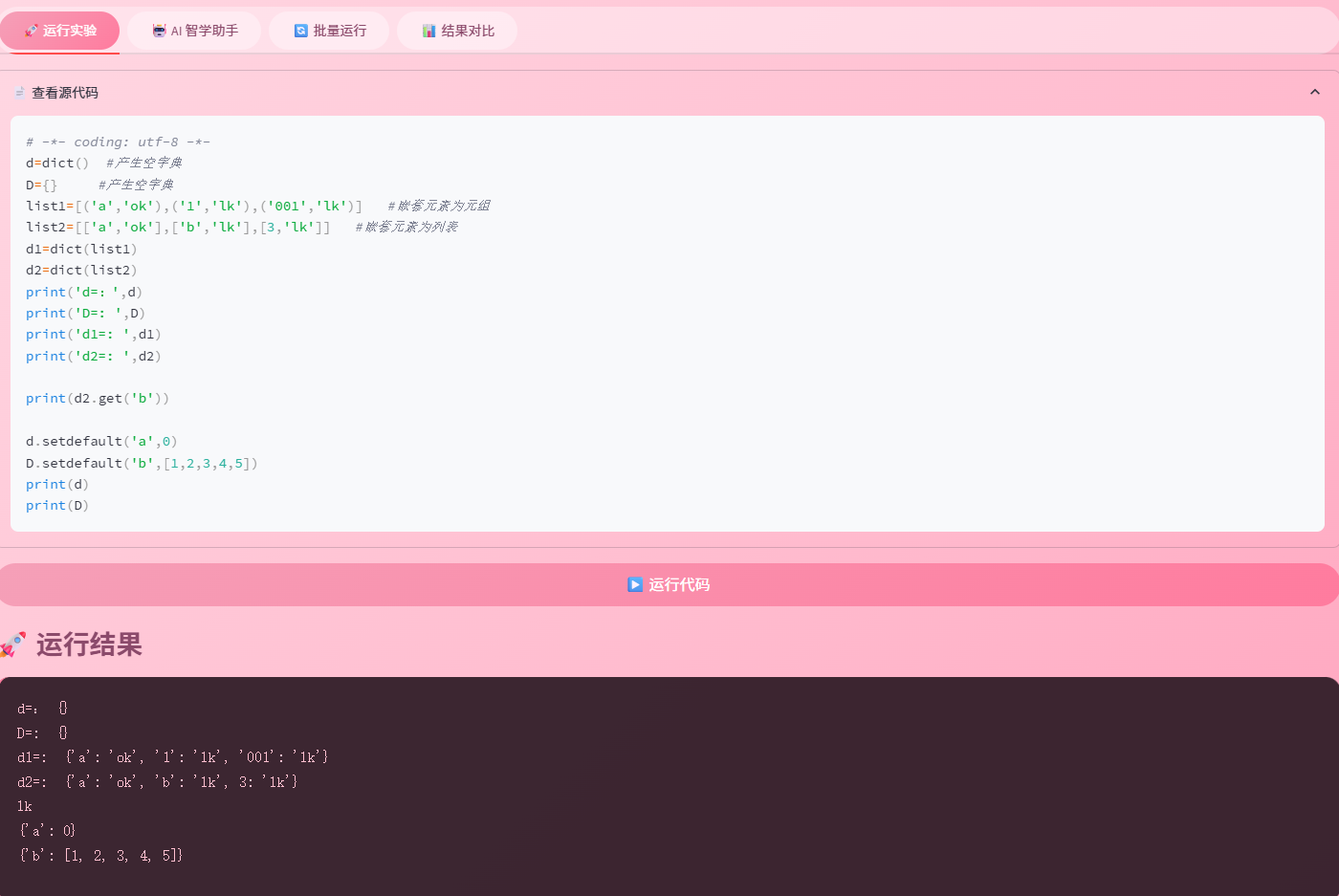
6.3 代码运行结果截图
6.4 AI智学助手截图
6.5 批量运行截图
6.6 结果对比截图
6.7 功能实现视频
1-8章数据挖掘分析第二版
七、总结
本系统实现了以下核心功能:
-
实验代码管理:支持8大章节50+实验脚本的组织和管理
-
代码安全执行:隔离执行环境,捕获输出、变量和图表
-
多语言国际化:6种语言界面动态切换
-
AI智能问答:内置数据科学知识库,提供学习辅助
-
批量运行:支持多实验并行执行,提高效率
-
结果对比:实验结果并排对比,便于分析理解

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)