检索很准,模型还在胡说八道?RAG系统的Prompt设计避坑指南
为什么检索再准,模型回答还是幻觉?
本文从实战角度,详解RAG Prompt设计的核心要点:
- System Prompt的角色+规则+约束设计
- User Prompt的格式化技巧
- 约束强度的强弱对比
- 长上下文的query-aware压缩策略
- Prompt 的系统化测试方法
检索把对的文档找回来,Prompt决定模型用不用这些文档。

你有没有遇到过这种情况:
检索明明很准,但模型回答的还是幻觉满天飞?
很多人把 RAG 的功夫都砸在检索上——向量召回调了、重排序加了、Top-5 文档质量贼高……
但模型一回答,幻觉还是满天飞。
问题出在哪?
今天我们把 RAG 系统的Prompt工程从头到尾拆清楚。
一、RAG Prompt的独特挑战:它和普通 Prompt 不一样
很多人把 RAG Prompt当成普通Prompt来写,这是根本性的认知错误。
普通Prompt vs RAG Prompt
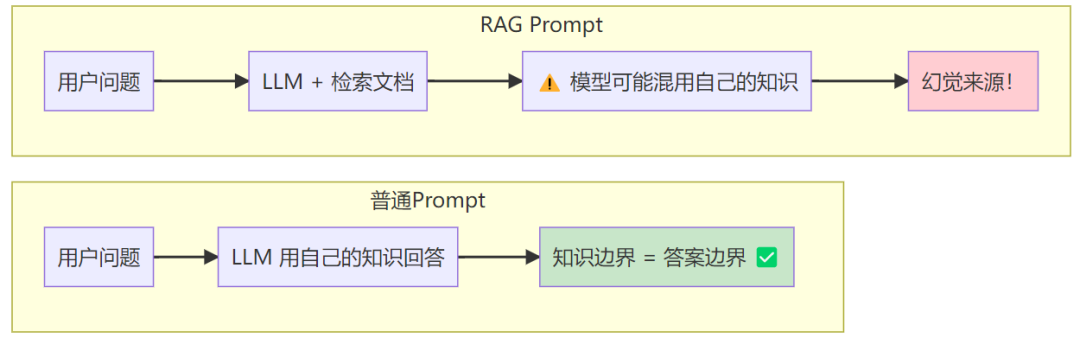
普通Prompt的逻辑
你问一个问题 → 模型用自己的参数知识来回答。
模型的"知识边界"就是答案边界,这是完全合理的设计。
RAG Prompt的逻辑
你传进去问题 + 检索文档 → 要求模型只用这些文档来回答。
根本性矛盾
LLM 在预训练阶段见过海量文本,脑子里已经存了大量知识。
当你给它一段检索文档,问它问题,它的默认行为是:把检索文档的信息和自己的参数知识混合使用。
这个混合,就是幻觉的来源。
真实案例:金融保险RAG系统
用户问:“重大疾病险的等待期是多久?”
检索系统召回了 A 产品的条款,明确写着等待期 180 天。
但 Prompt 写得不好,模型回答90 天——因为市场上有些产品确实是 90 天,这个信息在模型预训练数据里存在。
模型没有意识到它应该只看你给它的那份文档,它把两个知识源混合了。
用户拿到错误的等待期信息,去理赔,被拒。这是真实的业务风险。
所以 RAG Prompt 的核心任务是:切断模型对参数知识的依赖,强制它只从检索文档里找答案。

二、RAG工作流程:Prompt在哪里起作用?
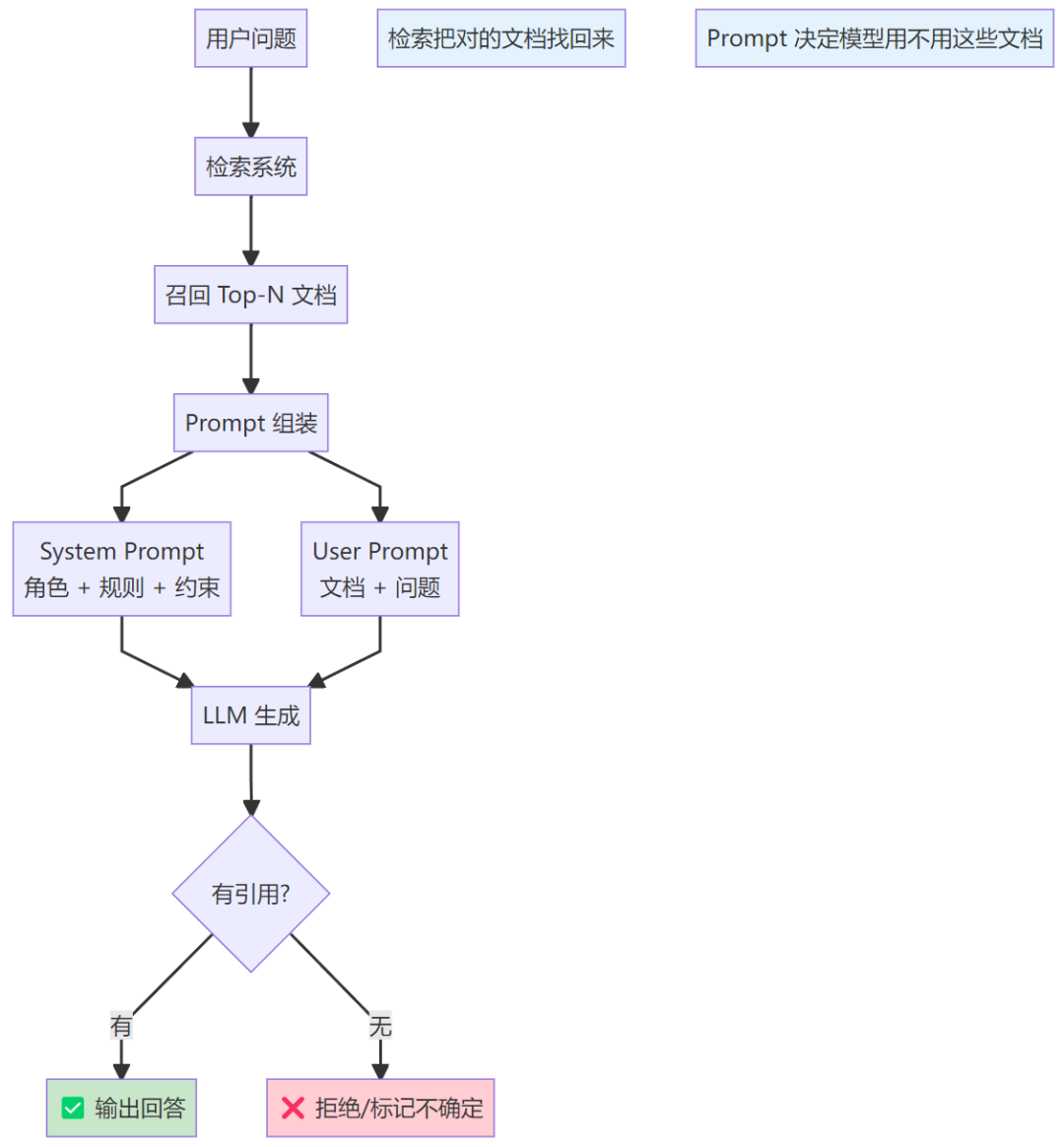
检索决定 RAG 的上限,Prompt 决定 RAG 的下限。两者缺一不可。
三、System Prompt设计:角色 + 规则 + 负面约束
System Prompt 做三件事:
- 定义角色 — 划定知识边界
- 设置规则 — 告诉模型能做什么
- 写明负面约束 — 告诉模型不能做什么
实际使用的System Prompt
你是金融保险公司的智能客服助手。
你只能基于提供的参考文档回答用户问题。
回答规则:
1. 只使用参考文档中明确提到的信息,不要添加文档中没有的内容
2. 如果参考文档中没有足够信息回答问题,直接说"根据现有资料,我无法完整回答这个问题",不要猜测
3. 回答时引用来源,格式:[来源:文档名称第X页]
4. 涉及金额、时限等关键数字,必须与文档原文完全一致
5. 不确定的信息前加"根据文档显示",确定的信息直接陈述
每条规则的设计逻辑
| 规则 | 类型 | 作用 |
|---|---|---|
| 角色定义 | 第一层过滤 | 划定知识边界 |
| “只能” | 核心约束 | 不是"尽量",是"只能" |
| “明确提到” | 正向约束 | 不是"相关",不是"推断" |
| 拒绝兜底 | 负向约束 | 不知道就说不知道 |
| 引用要求 | 验证步骤 | 强制先找原文 |
| 数字核实 | 重点加强 | 金融场景零容忍 |
关键:强制语气
注意用词是**“只能”**,不是"尽量",不是"主要"。
这个词的强度直接影响模型的行为。
引用要求:反幻觉的核武器
强制引用来源,格式是 [来源:文档名称第X页]。
原理:模型要写出引用,必须真的在文档里找到对应内容。如果文档里没有,它无法凭空捏造一个引用。
引用要求本质上是给模型增加了一个**“验证步骤”**——它必须先找到原文,再写回答。
四、User Prompt设计:问题+上下文的结构化组织
System Prompt设好了基础规则,User Prompt负责把每次请求的具体内容传进去。
关键:格式化
你不能把五段检索文档直接拼一起扔给模型,模型会搞不清楚哪段是哪段。
Python实现
def build_rag_prompt(query: str, retrieved_docs: list) ->str:
# 格式化参考文档
context_parts= []
for i, doc in enumerate(retrieved_docs, 1):
context_parts.append(
f"参考文档{i}(来自:{doc['source']}):\n{doc['text']}"
)
context="\n\n".join(context_parts)
user_prompt=f"""参考文档:
{context}
用户问题:{query}
请基于以上参考文档回答用户问题。如果文档中没有足够信息,请如实说明。"""
return user_prompt
四个设计细节
- 编号 + 来源:让模型引用时有依据
- 双换行分隔:减少文档边界模糊
- 文档在前,问题在后:先读文档再看问题,幻觉率更低
- 末尾重申规则:强化 System Prompt 的约束
五、约束写法的强弱对比
| 约束类型 | 示例写法 | 幻觉率 |
|---|---|---|
| ❌ 弱约束 | “参考以上文档回答” | 幻觉率较高 |
| ⚠️ 中等约束 | “请主要基于文档,尽量不要添加” | 有改善但不够好 |
| ✅ 强约束 | “只能使用文档中明确提到的信息” | 明显降低 |
| ✅✅ 强约束 + 引用 | “只能使用 + 每句标来源” | 效果最好 |
关键结论
- "只能"和"不得"是强制性语气,没有任何弹性空间
- 引用要求让幻觉率降低,效果最显著
- 完全消除无法保证,LLM本身的概率生成机制,LLM 对长文本的注意力有限,复杂句式可能理解偏差。参考:百万 token 上下文失灵?AI 智能体的 4 大失效陷阱与 6 大修复策略 和 AI的"记忆力"有多强?DeepSeek能记住12万字,但有一个致命缺点
Badcase 对比
用户问:“意外险的等待期是多久?”
召回了 A 产品(等待期 0 天)和 B 产品(等待期 15 天)
❌ 弱约束回答:
“意外险通常没有等待期,但也有产品设置 30 天等待期。”
30 天?这个数字是模型参数知识里其他产品的数据,文档里根本没有。
✅ 强约束 + 引用回答:
“根据文档显示,A产品意外险等待期为 0 天 [来源:A产品条款第2页],B产品意外险等待期为 15 天 [来源:B产品条款第3页]。如需了解具体产品,请告知产品名称。”
精准,有引用,拒绝了编造。
六、长上下文压缩策略:超长时怎么处理
用户有时会问跨产品的比较类问题,或者问涉及多个条款的复杂问题。
检索系统可能召回 10-15 个片段,总 token 数轻松超过 32K。
超长上下文带来的问题
- 超过上下文窗口:直接报错
- "迷失在中间"现象:模型对中间部分注意力显著弱于开头和结尾,导致关键信息被忽略
三种策略
| 策略 | 做法 | 适用场景 | 延迟 |
|---|---|---|---|
| 截断法 | 保留 Top-3 片段 | 简单问题、速度敏感 | 几乎不增加 |
| 压缩法 | LLM 提炼关键信息 | 复杂问题、主要使用 | 增加一次调用 |
| 分批处理 | 每批单独回答,最后合并 | 超长文档 | 延迟最高 |
query-aware 压缩(推荐)
def compress_context(docs: list, query: str, max_tokens: int=2000) ->str:
"""超出token限制时,压缩每个文档片段"""
compressed= []
for doc in docs:
if len(doc['text']) >500:
# 用LLM提炼关键信息
summary=llm.invoke(
f"从以下文本中提炼与问题'{query}'相关的关键信息(50字以内):\n{doc['text']}"
)
compressed.append(summary.content)
else:
compressed.append(doc['text'])
return"\n\n".join(compressed)
关键细节:compress_context 提示词里有 '{query}'——这是 query-aware 压缩,不是通用摘要。
模型会优先保留与用户问题相关的信息,而不是文档本身认为重要的信息。
效果
三种策略加起来,超过 32K token 的请求处理成功率从显著提升。
七、Prompt 迭代测试方法
写完 Prompt 不能靠感觉判断好坏,必须建立系统的评测机制。
建立 Prompt 版本库
用 Git 管理每一版 Prompt,提交记录里写清楚:
- 改了什么
- 为什么改
- 改后的测试指标变化
评测指标:忠实度(Faithfulness)
衡量 RAG 系统幻觉的核心指标——模型的回答有多大比例可以在检索文档里找到原文依据。
测试样本要覆盖三类
- 文档里有明确答案 → 应该回答正确
- 文档里只有部分答案 → 应该部分回答,说明缺失
- 文档里完全没有答案 → 应该拒绝回答
光测第一类是不够的! 很多团队在"文档有答案"时表现不错,但在"文档没答案"时模型会编造,这才是最危险的场景。
BadCase 复盘流程
测试发现:用户问"等待期多久",模型混入其他产品数据
层层深挖:
- 检索层:召回了多个产品条款片段,模型混淆了
- Prompt 层:没有要求分产品回答 → 加了规则后大幅改善
- 引用层:引用要求不够细 → 加了"必须包含产品名称"后彻底解决
每个BadCase背后都有原因,找到原因,加一条规则,验证效果。这就是Prompt 工程的核心循环。
总结:RAG Prompt 设计核心要点
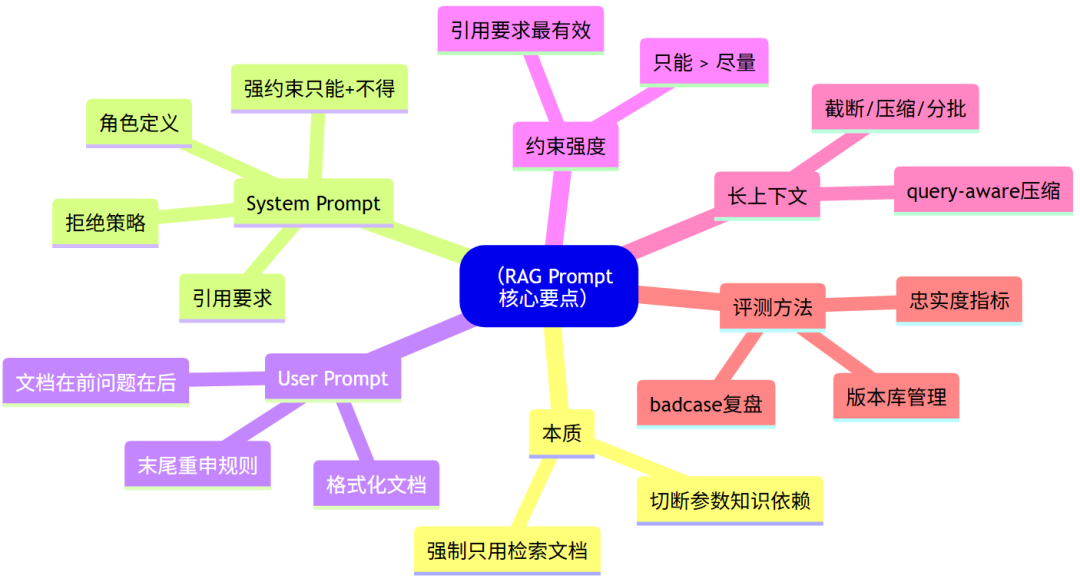
| 要点 | 核心要点 |
|---|---|
| 本质 | 切断参数知识依赖,强制只用检索文档 |
| System Prompt | 角色 + 强约束 + 引用要求 + 拒绝策略 |
| User Prompt | 格式化文档 + 问题放后面 |
| 约束强度 | "只能"和"不得"比"尽量"和"主要"有效得多 |
| 最有效手段 | 引用要求:强制先找原文才能写答案 |
| 长上下文 | query-aware 压缩,保留与问题相关的信息 |
| 评测方法 | 版本库 + 忠实度指标 + BadCase 复盘 |
检索把对的文档找回来,Prompt 决定模型用不用这些文档。两者缺一不可。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献148条内容
已为社区贡献148条内容

所有评论(0)