Harness Engineering实践,如何驾驭AI这匹野马
随着 Harness Engineering(驾驭工程) 这个词开始在 2026 年频繁刷屏,很多人的第一反应恐怕又是:“看,又一个试图收割智商税的黑话(Jargon)出现了。” 的确,教科书里的 Software Engineering 优雅如诗,现实中却是群魔乱舞;Clean Code 的守则详尽如法典,却挡不住大家在“屎山
”上精雕细琢。
概念与落地之间,隔着一条名为“平庸”的巨大鸿沟。
这一次,我不打算再堆砌苍白的定义,而是带你潜入一个边缘云实战项目的深水区。我们要聊的不是玄学,而是如何在落地 Harness Engineering 的过程中,把 AI 研发从“碰运气”的 Vibe Coding,驯化为一门过程可控、结果可信的系统性工程学科。
1.我们的武器库:工具与范式
在进入代码深水区之前,有必要先检阅一下本次实战所依赖的“重型装备”。在这个 AI 原生软件工程(AI-Native SE)的爆发年,我们不再是在 IDE 里单打独斗,而是在一套严密的工具链约束下进行“工业化生产”。
1.1 OpenCode:AI 编程界的“Linux”
作为 2026 年开发者生态的当红炸子鸡,OpenCode 凭借 125K+ Star 的战绩确立了其 AI Coding Agent 的霸主地位。它的迷人之处在于其“不妥协”的开源精神:不绑定任何模型厂商,通吃主流 MaaS 平台,且完美向下兼容 Claude Code 生态。在本项目中,它是我们的“首席执行官”,负责调动后端的 Glm-4.7 模型将逻辑转化为具体的二进制生产力。
安装和使用请参考:https://opencode.ai/docs/zh-cn/
1.2 SDD:是真理还是教条?
SDD(Spec-Driven Development,规格驱动开发) 提出了一个极具挑衅性的口号:“文档即真理,代码只是副产品”。 它的逻辑是:通过高度结构化的功能定义,强迫人类与 AI 在落子编码前达成“逻辑共振”,从而降伏那些由于理解偏差导致的 Bug。虽然亚马逊的 Kiro 已经将这套流程推向了极致,但我必须在此提前打个响指——我并不完全认同“文档即真理”这种激进的教条,在后文中,我会撕开这个优雅幻觉下的工程真相。
1.3 OpenSpec:连接意图与现实的铁轨
如果说 OpenCode 是引擎,那么 OpenSpec 就是铺就通往结果的铁轨。在 2026 年,它已成为 AI 原生开发的事实标准。 它绝非一份躺在目录里落灰的 PDF,而是一套将“人的模糊意图”硬化为“机器可执行约束”的规约协议。它构建了一个标准化的桥梁,贯穿了从 需求调研 (Explore) 到 方案提案 (Proposal),再到 自动化实现 (Implementation) 的全生命周期。
更多OpenSpec的内容可以参考:https://github.com/Fission-AI/OpenSpec/blob/main/docs/getting-started.md
如下图所示,只需一行 openspec init,我们便在项目根目录下构筑了一套钢铁般的工程约束。
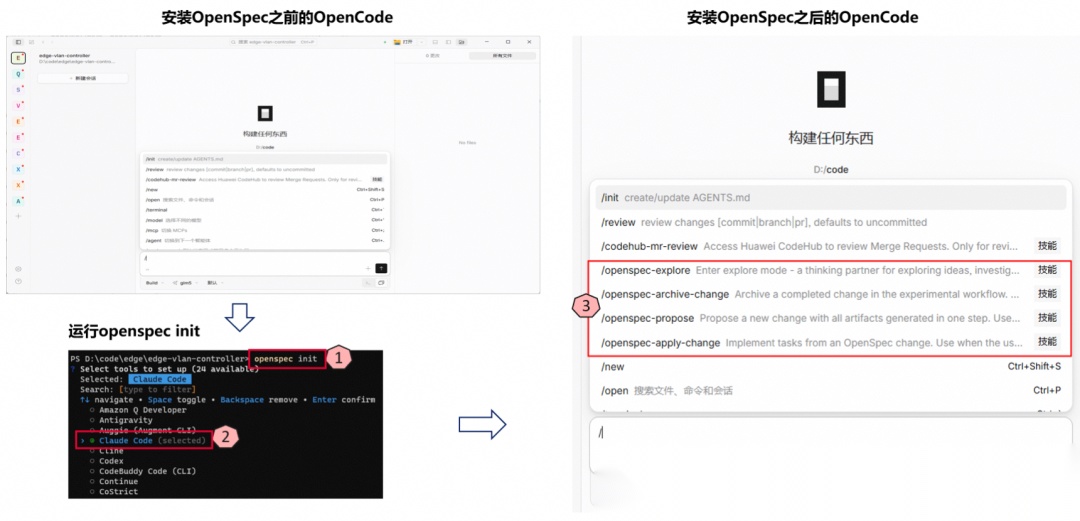
1.4 Harness Engineering:给 AI 狂飙的马力套上“缰绳”
Harness,直译为“挽具”。
想象一下,你面对的是一匹拥有无穷爆发力的烈马,如果没有缰绳、马鞍和踏板,它只会在旷野中横冲直撞,甚至把你掀翻在地。在 AI 时代,模型算力就是这匹“马”,而 Harness Engineering 就是你亲手打造的那套精密的控制系统。
在工程语境下,Harness 是你为 AI 搭建的整套数字化结界:它是那份规定“非请勿入”的架构约束,是那组时刻盯着逻辑漏洞的自动化校验脚本,是动态扩容的上下文管理器,也是出故障时能实现自愈的隔离沙箱。
OpenAI 曾在那篇轰动业内的《Harness Engineering 实践》中透露:其核心要义可以凝练为三根支柱:过程可控、结果可信、反馈闭环。
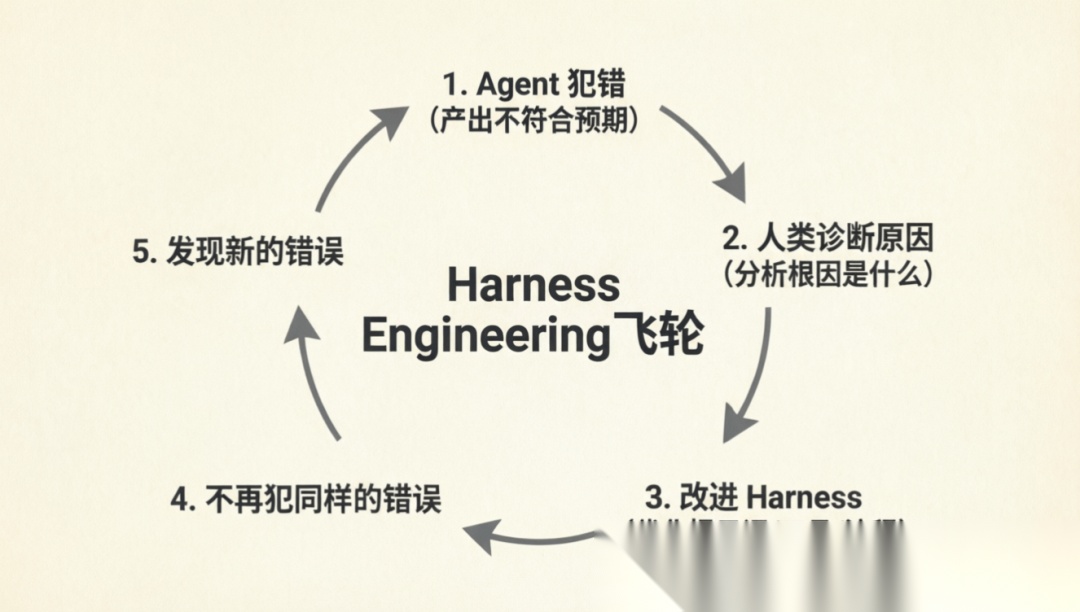
1. 过程可控:终结 Vibe Coding 的玄学为了降伏那种“全靠感觉、随缘生成”的随机性,我们必须给 AI 注入高度结构化的外部干预。这正是 SDD 以及 AWS Kiro 诞生的初衷——用确定的输入,换取确定的逻辑。
2. 结果可信:以测试为终局类似于“AI 版的 TDD”。在 AI 还没落下第一行代码前,我们就先构建出完备的测试用例和模拟运行环境。当绿灯亮起的那一刻,功能的一致性不再需要靠人类肉眼复核,而是由数学逻辑背书。
3. 反馈闭环:在磨合中进化构建 Harness 的初期往往是痛苦的“慢”,因为你要像搞精益生产一样,对 AI 每一个不符合预期的输出进行“追溯闭环”。该补规则补规则,该加约束加约束。这种初期的“慢”,是为了后续飞轮转起来后的“极速自演进”。
Harness Engineering 正在粗暴地重定义“程序员”这个职业。
OpenAI 的工程师们说得足够露骨:他们的工作性质已经发生了基因突变。他们不再是代码的搬运工,而是“代码工厂”的设计师。 他们的战场变成了:定义架构约束、构建反馈闭环、维护文档系统、监控质量指标。
一个顶级的 Harness Engineer,其价值在于不断优化那套精密的控制旋钮。一旦自动化飞轮转过临界点,他的杠杆率将彻底碾压任何所谓的手写代码天才——因为他设计的每一条规则、每一个机制,都会在未来的千万次 Agent 运行中,产生永恒的复利。
- 需求设计:从“模糊意图”到“钢铁蓝图”
======================
实战项目背景:边缘云网络平面控制服务。 核心目标:通过 Netconf 协议自动化配置交换机与服务器,实现边缘租户 Underlay 网络的物理隔离。
2.0 任务拆分:确定性的作战序列
不管传统软件工程还是Agentic软件工程,我们都不会“一步到位”,也拒绝“走一步看一步”。出于可控的SDD实现要求,必须将宏大的愿景拆解为原子化的、具有依赖关系的 User Stories (US)。这不仅是为了给 AI 指路,更是为了构建一个可追踪的项目进度闭环。
| 阶段 | 优先级 | US编号 | 核心内容 | 依赖关系 |
|---|---|---|---|---|
| 1. 基础架构 | P0 | US-1: COLA 4.0 骨架搭建 | 项目初始化 | 无 |
| US-2: 核心领域 Spec 定义 | 领域建模 | US-1 | ||
| 2. 通信适配 | P1 | US-3: Netconf 驱动集成 | Netconf实现 | US-1 |
| US-4: 站点初始化规格实现 | 站点初始化 | US-3 | ||
| 3. 业务核心 | P2 | US-5: 租户网络平面创建 | 分配 VLAN/VNI | US-2, US-4 |
| US-6: 裸机实例网络配置 | 将裸机物理网卡接入对应的租户平面。 | US-5 | ||
| 4. 生命周期 | P3 | US-7: 租户平面销毁与回收 | 实现配置的反向清理逻辑;释放占 | US-5 |
| US-8: 配置一致性巡检 | 定期比对物理设备 | US-3, US-5 |
2.1 需求探索(Explore):一场深度的“灵魂拷问”
在使用OpenSpec进行需求探索的时候,我们只需要在/openspec-explore命令后加上简单的需求描述即可,针对上面的任务拆分,首先我们要搭建项目的基础框架,此处我想在搭建框架之外,再实现一些基础功能,实际是把US-1和US-2合并了,因此我输入了如下的prompt:
/openspec-explore 创建一个新微服务管理租户在边缘云的underlay网络,通过租户网络平面实现租户间网络隔离,该服务通过Netconf协议统一管理边缘云站点的交换机配置,支持站点初始化、租户网络平面创建/删除、裸机实例网络配置等核心功能。现在先搭建应用框架,要求使用COLA四层架构,Maven,JDK21,SpringBoot3
OpenSpec 随后给我的反馈令人惊喜。在探索模式下,它会发起一连串极具专业深度的互动澄清。这不仅是在对齐需求,更是在用大模型海量的网络领域知识(Underlay 知识库)为我查漏补缺。
这些“灵魂拷问”覆盖了从业务逻辑,领域建模到应用架构的全维度:
1、业务领域深挖:涉及到具体的租户网络隔离实现逻辑。
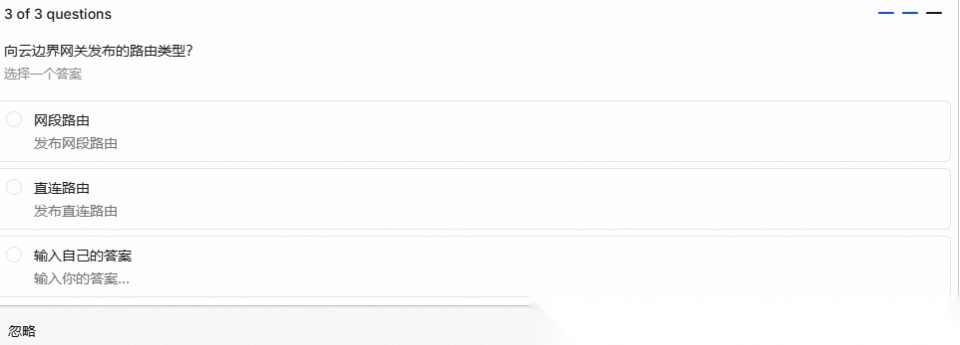
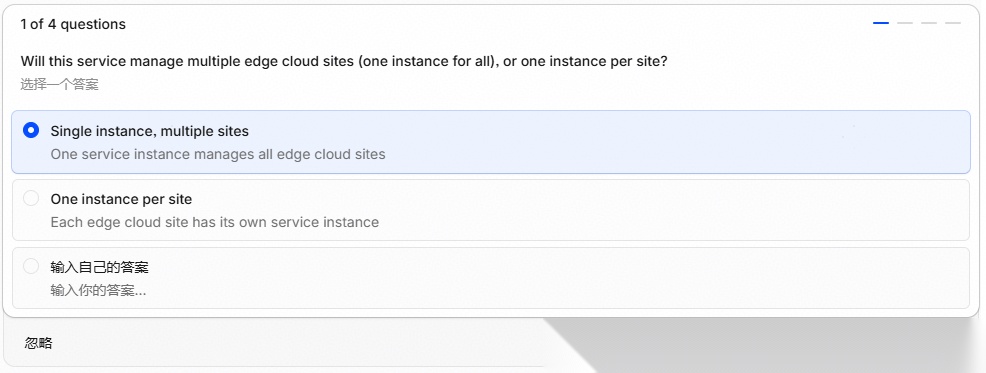
2、部署拓扑与管理半径:厘清服务与边缘站点的映射关系
3、驱动层适配:针对不同厂商交换机的适配策略
4、架构选型决策:关于 COLA 架构中 Layer-first 与 Feature-first 的权衡这是一个让我欣慰的问题,经过这么多年对COLA的持续经营,COLA已经变成大模型的背景知识,关于Layer-first和Feature-first之间的权衡的确是个关键问题。大部分情况会选Layer-frist,简单一点。
2.2 创建提案(Proposal):纠偏 AI 的“教条主义”
需求澄清后,通过 openspec-proposal 生成的变动清单(包含 proposal.md, design.md, tasks.md)就是我们即将实施的工程蓝图。
作为 Harness Engineer,此时必须开启严苛的 Spec Review 模式。 AI 有时会陷入某种“模式教条”。例如在本项目中,AI 过于推崇 DDD 中的 Value Object(值对象),甚至将所有的业务 ID 都建模成了 VO。
这显然增加了不必要的复杂度。我果断下达指令:“取消 ID 的 VO 建模,回归简单类型。”
AI 随即根据反馈自动更新了所有设计文档和任务列表。这种 “人类设定约束 -> AI 调整蓝图 -> 人类最终确认” 的迭代过程,确保了生成的任务列表(tasks.md)精准且不跑偏。
以下是最终确定的部分 tasks.md 片段。这份结构化清单不仅是 AI 的行动指南,更是我们拒绝“黑盒式开发”、实现过程可控的关键武器:
## 1. Project Setup- [] 1.1 Create Maven project with Spring Boot 3 parent, JDK 21- [] 1.2 Configure COLA layer package structure (adapter, app, domain, infrastructure)- [] 1.3 Add dependencies: Spring Web, Spring Data JPA, PostgreSQL driver, Liquibase- [] 1.4 Configure application.yml with database connection and Liquibase- [] 1.5 Create main Spring Boot application class## 2. Domain Layer - Value Objects- [] 2.1 Create Vlan value object with validation (100-4000)- [] 2.2 Create Vrf value object with naming convention (VRF001-VRF999)- [] 2.3 Create Vendor enum (HUAWEI, H3C)- [] 2.4 Create status enums (SiteStatus, TenantStatus, ServerStatus, SwitchStatus)- [] 2.5 Create domain eceptions (VrfEhaustedEception, VlanEhaustedEception, etc.)## 3. Domain Layer - Entities- [] 3.1 Create Site entity (id: String, name, switches, status)- [] 3.2 Create Switch entity (id: String, siteId: String, ipAddress, vendor, credentials, role, status)- [] 3.3 Create Tenant entity (id: String, siteId: String, vrf: Vrf, status)- [] 3.4 Create NetworkPlane entity (id: String, tenantId: String, vlan: Vlan, cidr)- [] 3.5 Create Server entity (id: String, networkPlaneId: String, switchId: String, portName, status)
有了这份钢铁般坚实的任务清单,代码实现阶段将不再是“猜谜游戏”,而是一场精准的“外科手术”。
- 代码实现:警惕 AI 的“草稿陷阱”
=====================
当 proposal 阶段的规格、设计与任务清单(Spec, Design, Tasks)最终对齐了我们的预期,便可以祭出 openspec-apply 命令,开启自动化的“火力全开”模式。
但在这一阶段,作为 Harness Engineer,你必须保持清醒的审视:目前的 AI 在实现层更像是一个“唯结果论”的平庸程序员。 它能极其高效地跑通逻辑分支,却对代码的可读性、复用性以及架构的优雅感缺乏“灵魂级”的感知。它给你的感觉更像是为了赶进度而拼命堆砌功能,丝毫不考虑未来的维护成本。
因此,在 Harness Engineering 的范式下,我们必须达成一个共识:AI 生成的代码绝非“成品”,而是一份高完成度的“草稿”。
从“草稿”到“作品”:重构即升华
在“古法编程”时代,资深开发者往往也会写两遍代码:第一遍快速实现功能(草稿),第二遍进行精细重构(成品)。那些更合理的抽象、更清晰的表达、更健壮的扩展性,往往不是起笔时就能想透的,而是在认知迭代的推敲中打磨出来的。 AI 帮我们省去了第一步的体力活,但它也顺便丢给我们一堆需要“手术刀式重构”的半成品。
**案例 A:逻辑平铺与组合方法模式 (CMP)**本项目中最复杂的用例是“创建租户平面”。AI 最初生成的代码虽然功能达标且能跑通测试,但数个业务步骤全部塞在一个大方法里,读起来像是一篇毫无段落的流水账。
我采用结构化思维,利用 CMP (Composed Method Pattern,组合方法模式) 对其进行了二次重构。重构后的逻辑如同一份清晰的业务清单:
public CreateTenantPlaneResp createTenantPlane(String siteId, CreateTenantPlaneReq req) { // 准备上下文环境,包含站点ID和请求信息 Context ctx = prepareContext(siteId, req); try { // 步骤1:保存network信息,状态为pending networkGateway.save(ctx.getNetwork()); vlanifGateway.save(ctx.getVlanif()); // 步骤2:在核心交换机上创建VLAN接口并绑定VRF createVlanifAndBindVrfOnCoreSwitches(ctx.getCoreSwitches(), ctx.getVlanif(), ctx.getVlanId()); // 步骤3:在核心交换机上发布路由信息 publishRoutesOnCoreSwitches(ctx.getCoreSwitches(), ctx.getVrf().getName(), ctx.getCidrs()); // 步骤4:在核心下联端口上允许VLAN通过 switchConfigService.allowVlanOnPorts(ctx.getCoreSwitches(), ctx.getSite().getSiteId(), PortRole.DOWNLINK, ctx.getVlanId()); // 步骤5:在TOR上联端口上允许VLAN通过 switchConfigService.allowVlanOnPorts(ctx.getTorSwitches(), ctx.getSite().getSiteId(), PortRole.UPLINK, ctx.getVlanId()); // 步骤6:在核心交换机上创建租户BGP配置 createTenantBgpConfigOnCoreSwitches( ); // 步骤7:设置网络状态为激活状态并保存 networkGateway.updateStatus(ctx.getNetwork().getId(), NetworkStatus.ACTIVE, ""); return new CreateTenantPlaneResp() .setId(ctx.getNetwork().getId()) .setVrfId(ctx.getVrf().getId()) .setVlanifId(ctx.getVlanif().getId()); } catch (Exception e) { log.error("Create tenant plane failed, rolling back. networkId={}", ctx.getNetwork().getId(), e); // 回滚配置,将上下文中的配置信息恢复到之前的状态 rollbackConfig(ctx); // 保存失败信息,将请求、异常和上下文信息保存到失败记录中 saveFail(req, e, ctx); throw new VlanException("Create tenant plane failed: " + e.getMessage()); } }
案例 B:逻辑散落与领域能力下沉
AI 经常会将业务逻辑散落在应用层(Application Layer),导致领域对象变得“贫血”。例如“从 CIDR 推断 Gateway IP”的逻辑,AI 最初是直接写在 Service 里的。我将其下沉到了 Cidr 领域对象中:
// 领域能力下沉:让对象自己“说话” public String getGatewayIp( ) { IPAddress addr = new IPAddressString(this.cidr).getAddress(); if (addr == null) { throw NetworkErrorDefine.INVALID_IP_FORMAT.render("Invalid CIDR format: " + this.cidr).toVlanException(); } return addr.toSequentialRange().getLower().increment(1).toString(); }
3.2 将重构逻辑“硬化”为规则
发现 AI 的“偷懒”倾向后,真正高阶的 Harness Engineer 不会满足于只改这一次代码,而是会尝试将这种审美偏好提炼为 Agent 的约束规则 (Rules)。
例如,你可以将“单方法长度禁止超过 30 行”设定为 Linter 规则。一旦 AI 生成了臃肿的长方法,检查工具会直接报错,并倒逼 AI 自动进行 CMP 重构,直至达标。
这就是 Harness Engineering 的精髓:发现问题,不要只修补结果,要通过优化“挽具(Harness)”来闭环解决它。
虽然我们可以设定重重规则,但现阶段我们仍需扮演好“导师”的角色。积极 Review,确保 AI 的每一次拆分和抽象都符合人类的架构品味。 总而言之,你要做的是工厂的设计师,而不是被工厂吞噬的零件。
3.3 架构治理:拒绝“软性祈求”,拥抱“物理拦截”
OpenAI 的 Harness Engineering 实践中,有一个振聋发聩的观点:架构约束不靠 Prompt,靠 Linter。
很多开发者试图通过写一长串 Prompt 来规约 AI:“请注意,模块 A 绝对不能调用模块 B。” 这种做法在实战中往往极其脆弱,原因有二:
- 注意力稀释(Attention Dilution):随着任务复杂度的爆炸,Prompt 会变得臃肿不堪。Agent 在处理核心逻辑时,往往会“选择性忽略”这些边缘化的文字约束。
- 软约束 vs 硬拦截:Prompt 只是建议,而 Linter 是物理法则。当 Agent 违反架构规则时,Linter 的直接报错是一种“硬碰撞”。Agent 在面对报错时,会由于“失败驱动”而被迫进入自修复路径,直到代码完全符合规则。这种“报错-修正”的闭环,比任何苦口婆心的 Prompt 都有效得多。
实践案例:用 ArchUnit “硬化” COLA 架构
以本项目为例,我们要捍卫 COLA 四层架构的纯净性,确保 Domain 层是绝对的核心,不向 Infrastructure 或 App 层产生任何逆向依赖。
我们没有在 Prompt 里反复唠叨,而是直接编写了一份 ArchUnit 测试用例。这份代码就是我们架在代码仓上的“高压线”:
class ColaArchitectureTest { @ArchTest static final ArchRule domain_should_not_depend_on_other_layers = noClasses() .that().resideInAPackage("..domain..") .should().dependOnClassesThat() .resideInAnyPackage("..adapter..", "..app..", "..infrastructure..") .because("Domain layer should be the core and not depend on other layers");}
这种机械硬约束的力量在于:Agent 无论如何挣扎,只要代码不达标,Pipeline 就无法通过。同样,对于方法长度超过 30 行、圈复杂度过高等质量红线,我们全部将其硬化为 CodeCheck 的 Linter 规则。
在 Harness Engineering 的世界里,我们不相信 Agent 的“自觉”,我们只相信制度化的“拦截”。 这种从“请按规则写”到“不按规则写就报错”的范式转变,才是让 AI 研发从 Vibe Coding 走向精密工程的必经之路。
- 迭代阵痛:当“真理”遭遇变化
=================
在 AI 的精准辅助下,我们确实消解了大量不确定性,但需求变更这一“工程宿命”依然如期而至。
在本项目的“租户平面创建”阶段,底层逻辑发生了漂移:BGP 配置改为在创建 VRF 时预置,无需在平面创建时二次执行。修复这处变更在代码层面只需删除一行代码:
// 步骤6:在核心交换机上创建租户BGP配置createTenantBgpConfigOnCoreSwitches( );
然而,这一行代码的删除,却瞬间让之前的 create-tenant-plane 文档沦为刻舟求剑的废纸。AI 并不能豁免人类数十年来的工程宿命:文档落后于代码,是软件热力学第二定律式的必然。
这正是我质疑 SDD(规格驱动开发)核心逻辑的根源。SDD 宣称“文档即真理,代码是副产品”,但在复杂的工程演进面前,这不过是一个脆弱且优雅的幻觉。SDD 在初期确实能为 AI 提供结构化的导航,但若据此宣称“自然语言编程时代已至”,无异于指着一张精美的地图说我们已经征服了群山。
记住:代码从未骗人,而文档时刻在撒谎。
4.1 捍卫代码的 SSOT 权
在 Harness Engineering 的体系中,我始终坚持代码才是唯一的 SSOT(Single Source Of Truth,单事实来源)。
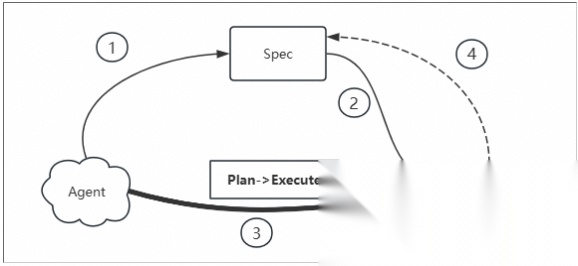
如上图所示,Spec 与 Code 的关系必须被重新定义:Spec 只是辅助,而非主导;是阶段性的过程,而非终极的目的。 针对不同场景,我认为应采取灵活的Spec策略:
- 善用 Spec(初始化阶段):在项目冷启动或涉及重大架构变更时,结构化的 Spec 是对齐 AI 认知的最高效手段,也是团队 Review MR 背景的最佳凭证。
- 绕过 Spec(修补阶段):进入迭代中后期,对于局部的逻辑微调,应直接通过 Agent 的 Plan -> Execute 模式操作代码仓。即在“Plan 模式”下与 AI 讨论设计,在“Build 模式”下直接降维打击,执行代码变更。
- 丢弃 Spec(维护阶段):不要执着于维持 Spec 与代码的强一致性。Spec 只是中间产物,太多的陈旧文档反而会稀释 AI 的注意力。 在必要时,必须果断清除过期的文件。
4.2 文档的“垃圾回收”机制
OpenAI 在其 Harness 实践中也引入了 Garbage Collection(垃圾回收) 的概念:定期清理过时的文档,防止其对 Agent 产生误导。
这与我倡导的“丢弃中间 Spec”思想不谋而合。让 AI 直接探索代码(Code Exploration)往往比让它在过时的文档堆里“考古”要高效得多。
一个优秀的 Harness Engineer 应该明白:你的目标是交付运行的软件,而不是维护一堆自我感动的文档。
- 代码审视:消减 AI 释放的“认知债”
======================
在 Agentic 时代,代码生成的边际成本已近乎为零。生产不再是瓶颈,审查才是。
面对动辄上万行的代码提交(MR),如何提升可审查性(Code Reviewability),已成为决定软件工程成败的命脉。理论上,Harness Engineering 越精密,代码质量就越高,Review 的压力就越小。但现实是:我们尚未进入“无需理解代码”的乌托邦。
AI 产出的速度远超人类消化的速度,这直接导致了“认知债”的激增。如果不加节制地接受 AI 生成的逻辑,今天飞涨的研发效率,明天就会变成无法维护的泥潭。
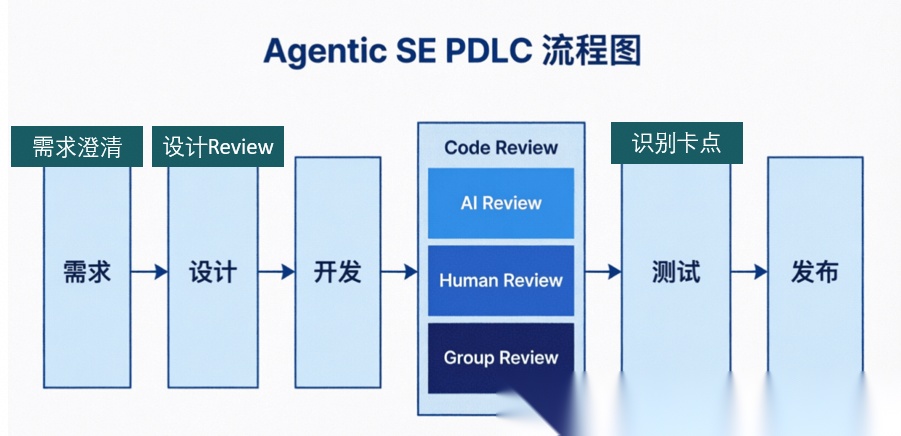
因此,在 AI 原生的 PDLC(软件开发生命周期)中,我强烈建议将战略重心向 Code Review 倾斜:
- AI Review:利用更强的模型对“平庸模型”生成的逻辑进行初步扫描。
- Human Review & Group Review:不仅仅是查 Bug,更是为了理解、重构与优化。
我们要主动通过人为的干预,去对冲 AI 快速生产带来的复杂性熵增。
- 代码测试:构建坚不可摧的“反馈结界”
=====================
软件测试,特别是自动化测试,始终是软件产业中最高耸的堡垒。即便进入了 2026 年,依然有大量的 QA 沉溺于低效的手工点选,这种模式在 Agent 时代将彻底崩塌。
这正是 OpenAI 工程师在 Harness Engineering实践 实践中发出的终极警告:“我们当前最棘手的挑战,集中在设计环境、反馈回路和控制系统方面。”
6.1 实验室级反馈:从 UT 到集成测试
在本项目中,我们的反馈闭环主要依托单元测试(UT)。但对于边缘云这种复杂系统,UT 的覆盖深度显然不足以支撑起“结果可信”。
我探索出了一套基于UT的微服务集成测试办法:利用内存中间件(In-memory DB/Kafka/Redis)以及 WireMock 模拟周边服务依赖。这种方案的优势在于,它能在不启动整套笨重环境的前提下,将集成测试也纳入 Harness 的反馈环。AI 每一行代码的变动,都能在秒级得到准生产环境的验证。
6.2 真实战场:端到端(E2E)的环境博弈
真正的工程挑战在于端到端测试的环境构建:如何用 Docker 编排真实的中间件?如何利用 Chrome DevTools 模拟用户行为?
这是一个极其残酷的平衡游戏。如果你构建的环境过于沉重,AI 的运行会变得极其耗时且易碎,导致研发过程频繁“卡壳”,原本预想的效率飞轮会瞬间卡死。
作为 Harness Engineer,我们的核心使命是为 AI 构建一套“可运行、高韧性”的执行结界。以一个前后端分离的项目为例,E2E 测试横跨页面、前端服务器与后端微服务。经过反复试错和尝试,我终于找到一个构建相对稳定的E2E测试环境的方法,这里的重点是要解决服务器端口冲突问题。为了让Agent操作浏览器,我们首先要在opencode中注册chrome-devtools-mcp工具。即我们需要在~\.config\opencode\opencode.jsonc中添加以下信息:
"mcp": { "chrome-devtools": { "type": "local", "command": ["npx", "-y", "chrome-devtools-mcp@latest"] } }
为了实现环境自愈,我们在 AGENTS.md 中硬化了如下检测与拉起规约:
### E2E Test Runtime Guard (环境自愈守则)0. **存活与冲突校验**: 禁止盲目启动。首先利用 `netstat -ano | findstr "LISTENING"` 精准探测后端(8080)与前端(3000)端口。 *若端口被无关进程占用,后端需要销毁进程重新拉起,前端可以保持不变*1. **后端防御性启动**: 若 8080 端口离线,触发冷启动序列。一次性拉起: `powershell -Command "Start-Process cmd -ArgumentList '/k cd crm-backend && mvn spring-boot:run -Dserver.port=8080 -Dmaven.wagon.http.ssl.insecure=true'"`2. **前端动态挂载**: 若 3000 端口离线,自动进入前端开发目录执行热更新模式: `powershell -Command "Start-Process cmd -ArgumentList '/k cd crm-frontend && npm run dev'"`3. **浏览器自动化执行**: 在确认双端“心跳”正常后(等待7秒),方可驱动 Chrome DevTools 协议,开启无头浏览器进行全链路回归。
这套规约的意义在于:它把原本需要人类手工排查的“环境玄学”,转化为了 Agent 可以理解并执行的标准操作程序(SOP)。当 Agent 能够自主处理端口占用、依赖下载失败、服务拉起超时等工程杂讯时,它才真正具备了在无人值守状态下大规模交付高质量代码的能力。
6.3 成本平衡:从“每改必测(全量)”到“按需召唤”
然而,现实是骨感的:运行一次完整的 E2E 测试极其昂贵(算力与时间成本)。我们必须在“测试全面性”与“测试反馈速度”之间找到那个微妙的黄金分割点。
我不希望 AI 的每一次微小改动都触发沉重的 E2E 流程,这会稀释开发的专注度。更合理的工程实践是:将环境规约封装为“可召唤的指令”。
我们将上述逻辑抽象为命令,下沉至 .opencode/commands/e2e-test.md。这样,开发者或 Agent 只有在关键里程碑节点,通过键入 \e2e-test 才能激活这套重型武器。
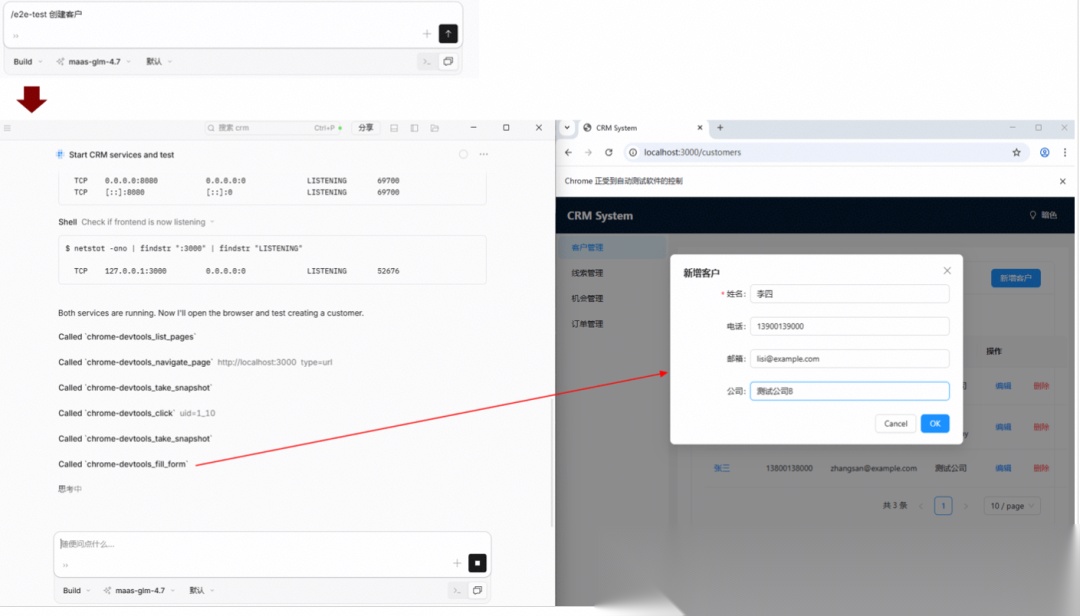
自动化环境构建与韧性测试,是软件工程最后的“无人区”。 在这里,没有现成的地图。你能否在复杂的分布式环境下,为 Agent 维持一个稳定、快速、可重复的反馈闭环,是衡量你是否真正具备“驾驭 AI 能力”的试金石。
- 结语:从“代码手艺人”到“软件工厂设计师”
========================
通过这场边缘云项目的实战洗礼,我们清晰地看到:Harness Engineering 绝非又一个转瞬即逝的黑话,而是一场正在发生的软件生产力革命。
在这个范式下,OpenCode、OpenSpec 不再是单纯的辅助工具,而是构筑新一代软件工程边界的基石。它们正将软件开发从“作坊式的手工打磨”推向“工业化的精密制造”。
然而,驾驭这股力量并非一蹴而就。回顾这段实战经历,我们沉淀下了几条关乎成败的硬核经验:
- 拒绝“黑盒”,锚定过程:通过结构化的 OpenSpec 规约和颗粒度极细的 tasks.md,我们将 AI 的产出强行锁死在预设轨道上。只有过程可控,效率才有意义。
- 以测试作为“逻辑准星”:无论是 UT 还是复杂的集成测试,它们不再仅仅是质量守门员,而是整个反馈闭环的核心。代码的公信力,应由自动化的数学逻辑背书,而非人类的疲劳肉眼。
- 构建自进化闭环:发现 AI 的偷懒或偏差后,不要只满足于修补代码。真正的 Harness Engineer 会将教训提炼为 Linter 规则或架构约束。这种“发现即闭环”的模式,是飞轮转起来的动力源。
- 警惕“认知债”,严守 Review 阵地:AI 释放了生产力,也制造了认知负担。我们必须将战略重心向 Code Review 倾斜,通过 AI 与人类的多重审视,消减快速生产带来的复杂度熵增。
- 捍卫代码的SSOT地位:Spec 是地图,Code 是领土。无论 SDD 的理念多么迷人,我们必须时刻保持清醒:代码从未骗人,而文档时刻在撒谎。 保持代码的纯净与可维护性,永远优于维护堆积如山的文档。
- 合理的上下文管理:在Context Engineering文中我们已经知道,过大的Context会导致Context Rot问题,《OpenAI Harness Engineering 实践》提到的让
AGENTS.md成为简短的指南,使用SubAgent渐进式披露更多内容,同时保证主Agent的Clean将是一个不错的方案。
Harness Engineering 的崛起,标志着软件工程正在经历一场深刻的回归——回归到其“工程化”的本质。罗马不是一天建成的,不要期望在一开始就能构建出一个功能强大完整的Harness,每个项目的环境都不一样,好的Harness Engineering都是迭代生长出来的。我们只有不断地调整、优化feedforward和feedback,才能构建出强大的Harness。
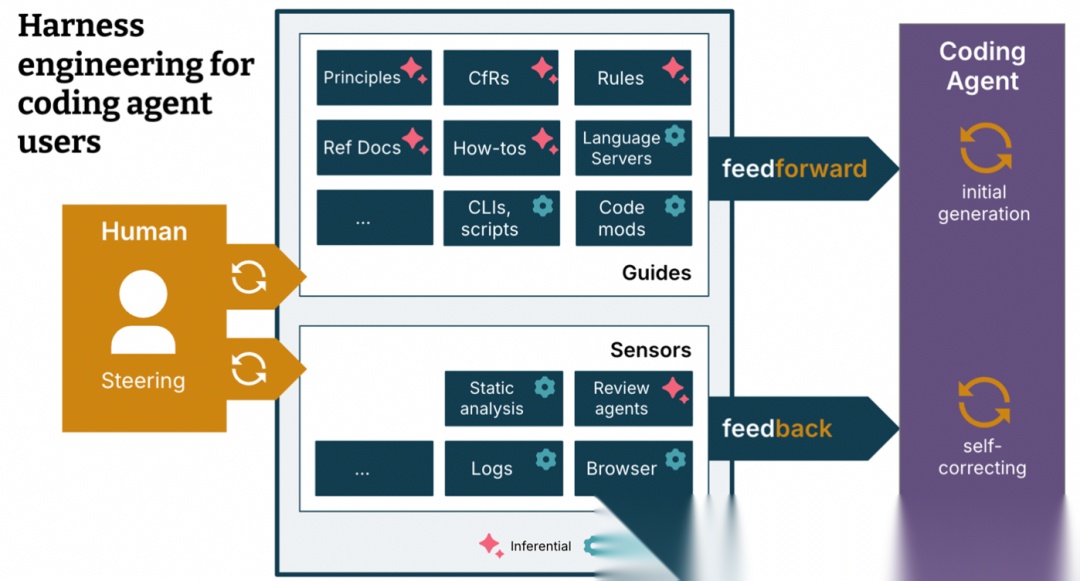
它不再寄希望于某个开发者当天的“Vibe(感觉)”或灵光现,而是建立在一套可复制、可观测、可演进的精密控制系统之上。虽然“环境构建难、测试反馈慢”这些老掉牙的幽灵依然游荡,但进化的方向已不可逆转。
未来,别再做一个单纯的“代码手艺人”,去为 AI 构建那套足够精密的“挽具”吧。
当你的 Harness 足够强大时,澎湃的 AI 算力才会真正化作你手中无坚不摧的生产力。正如 OpenAI 团队所言:一旦控制飞轮旋转起来,其杠杆率将彻底重塑软件行业的格局。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献183条内容
已为社区贡献183条内容

所有评论(0)