2026年4月技术前沿:AI大模型爆发、智能体革命与量子安全新纪元
本文基于2026年4月最新技术动态,涵盖AI大模型、智能体框架、量子计算、网络安全等前沿领域。所有技术内容仅供学习交流,实际应用需结合具体业务场景。
摘要
2026年4月,全球技术圈迎来前所未有的爆发期。谷歌Gemma 4全面开源引爆开发者社区,GPT-6发布倒计时引发行业震动,AI智能体从概念走向规模化落地,量子计算商业化进程加速,网络安全进入"生存博弈"新阶段。本文深度解析2026年4月十大技术热点,提供32个实战代码片段、8个架构图、6个行业案例,为开发者、架构师、技术决策者提供可落地的技术指南。拒绝"概念炒作",专注"技术本质与实践价值"。
1. 引言:2026年4月,技术变革的临界点
"2026年4月3日,我用手机上的Gemma 4模型完成了整篇技术文档的初稿,然后让AI智能体自动优化格式、检查语法、生成配图——整个过程不到10分钟。"
—— 一位前端开发者的日常
技术变革的三大特征:
| 特征 | 表现 | 影响 |
|---|---|---|
| 速度前所未有 | Gemma 4发布24小时内GitHub星标突破5万 | 技术迭代周期从月缩短至天 |
| 深度前所未有 | GPT-6支持200万Token上下文 | 复杂任务处理能力质变 |
| 广度前所未有 | AI智能体覆盖办公、开发、运维全场景 | 技术渗透到每个工作环节 |
2026年4月十大技术热点速览:
- 谷歌Gemma 4全面开源:Apache 2.0许可证,端侧部署门槛骤降
- GPT-6发布倒计时:4月14日发布,性能提升40%
- AI智能体爆发:OpenClaw星标突破13.6万,多Agent协作成主流
- 量子计算商业化:IBM Condor突破1121量子比特
- 后量子密码标准落地:中国发布国标,开启双轮防御新时代
- 网络安全AI化:AI驱动攻击占比达50%,防御进入预测性韧性阶段
- Kubernetes 1.36发布:服务网格深度集成
- 数据库智能化:大模型+SQL自动优化根治慢查询
- AI芯片革命:光基计算、原子级器件重塑芯片体系
- 开发者效率革命:AI编程助手代码生成准确率超90%
行业数据(IDC 2026 Q1):
- 全球AI市场规模达1.2万亿美元,同比增长67%
- AI智能体开发者数量突破500万,同比增长320%
- 量子计算市场规模站上20亿美元关口
- 网络安全人才缺口达340万,创历史新高
2. AI大模型战场:Gemma 4开源与GPT-6发布倒计时
2.1 谷歌Gemma 4:开源生态的"核弹级"产品
发布背景:2026年4月2日,谷歌DeepMind零预热发布Gemma 4系列,采用Apache 2.0许可证,彻底放开商用限制。这一举动被业界称为"开源生态的核弹级产品"。
四大核心亮点:
| 亮点 | 技术细节 | 实战价值 |
|---|---|---|
| 全面开源 | Apache 2.0许可证,无商业限制 | 企业可自由商用,降低合规风险 |
| 端侧部署 | 最小模型仅1.5GB,支持安卓离线运行 | 移动端、IoT设备轻松集成 |
| 性能飞跃 | AIME 2026数学竞赛准确率89.2% | 复杂推理能力媲美闭源模型 |
| 效率革命 | 26B MoE模型推理速度达4B级别 | 低成本部署高性能模型 |
Gemma 4模型矩阵:
# Gemma 4模型选择指南
GEMMA_4_MODELS = {
"E2B": {
"size": "1.5GB",
"params": "2B",
"use_case": "移动端、IoT设备",
"memory": "2GB RAM",
"speed": "实时响应"
},
"E7B": {
"size": "4GB",
"params": "7B",
"use_case": "个人电脑、边缘计算",
"memory": "8GB RAM",
"speed": "亚秒级响应"
},
"E26B_MoE": {
"size": "15GB",
"params": "252B (激活38B)",
"use_case": "企业级应用、复杂推理",
"memory": "32GB RAM",
"speed": "秒级响应"
},
"E31B_Dense": {
"size": "60GB",
"params": "31B",
"use_case": "数据中心、高性能计算",
"memory": "128GB RAM",
"speed": "批量处理"
}
}
def select_model(requirement):
"""根据需求选择合适的Gemma 4模型"""
if requirement == "mobile":
return GEMMA_4_MODELS["E2B"]
elif requirement == "desktop":
return GEMMA_4_MODELS["E7B"]
elif requirement == "enterprise":
return GEMMA_4_MODELS["E26B_MoE"]
else:
return GEMMA_4_MODELS["E31B_Dense"]
# 使用示例
print(select_model("mobile"))
# 输出: {'size': '1.5GB', 'params': '2B', ...}2.2 Gemma 4实战:端侧部署与应用开发
环境准备:
# 安装依赖
pip install torch transformers accelerate bitsandbytes
# 下载Gemma 4模型(以E7B为例)
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "google/gemma-4-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype=torch.float16
)文本生成实战:
def generate_text(prompt, max_length=512):
"""使用Gemma 4生成文本"""
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_length=max_length,
temperature=0.7,
top_p=0.9,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# 示例:技术文档生成
prompt = """作为技术专家,请撰写一段关于Gemma 4模型的技术介绍:
Gemma 4是谷歌DeepMind于2026年4月发布的开源大模型系列,"""
result = generate_text(prompt)
print(result)量化部署(4-bit):
from transformers import BitsAndBytesConfig
# 4-bit量化配置
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True
)
# 加载量化模型
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-4-7b",
quantization_config=quantization_config,
device_map="auto"
)
# 量化后模型仅需~4GB内存,可在消费级显卡运行2.3 GPT-6发布倒计时:技术预测与准备
核心参数预测:
| 参数 | GPT-5.4 | GPT-6 (预测) | 提升 |
|---|---|---|---|
| 上下文窗口 | 128K | 200万Token | 15.6x |
| 推理速度 | 基准 | +40% | 显著提升 |
| 多模态能力 | 图文 | 原生统一架构 | 质变 |
| 长期任务 | 有限 | 强化执行能力 | 突破 |
GPT-6应用场景预测:
# GPT-6长期任务执行示例(伪代码)
class GPT6LongTermAgent:
def __init__(self):
self.context_window = 2_000_000 # 200万Token
self.memory_system = HierarchicalMemory()
self.task_planner = AdvancedPlanner()
def execute_complex_task(self, task_description):
"""执行复杂长期任务"""
# 1. 任务分解
subtasks = self.task_planner.decompose(task_description)
# 2. 长期记忆存储
self.memory_system.store_context(task_description)
# 3. 逐步执行
results = []
for subtask in subtasks:
# 利用超大上下文窗口保持任务连贯性
context = self.memory_system.retrieve_relevant_context(subtask)
result = self.execute_subtask(subtask, context)
results.append(result)
# 更新记忆
self.memory_system.update_memory(subtask, result)
# 4. 结果整合
final_result = self.integrate_results(results)
return final_result
# 使用场景:自动完成季度报告
agent = GPT6LongTermAgent()
quarterly_report = agent.execute_complex_task(
"分析2026年Q1销售数据,生成季度报告,包括趋势分析、问题诊断、改进建议"
)开发者准备清单:
- 学习长文本处理技术(Chunking、RAG优化)
- 准备多模态数据集(图像、音频、视频)
- 优化API调用策略(成本控制、速率限制)
- 构建领域知识库(提升专业领域表现)
3. AI智能体革命:从对话工具到自主执行者
3.1 AI智能体核心架构演进
传统架构(2024年前):
用户输入 → 大模型 → 工具调用 → 结果返回现代架构(2026年):
用户输入 → 规划器(Planner) → 多Agent协作 → 执行器(Executor) → 反思器(Reflector) → 结果返回核心组件详解:
| 组件 | 职责 | 2026年新技术 |
|---|---|---|
| 规划器 | 任务分解、路径规划 | 分层任务网络(HTN) |
| 记忆系统 | 长期记忆、上下文管理 | 向量数据库+图数据库 |
| 工具调用 | 外部API集成 | MCP协议标准化 |
| 多Agent协作 | 专业Agent分工 | A2A协议 |
| 反思器 | 自我评估、持续优化 | 元认知能力 |
3.2 OpenClaw:开源智能体框架实战
项目背景:OpenClaw是2026年初爆火的开源AI Agent项目,GitHub星标突破13.6万,被誉为"运行在你电脑上的全能代理"。
核心特性:
- 深度本地化:自托管,运行在个人电脑、VPS甚至树莓派
- 系统控制:直接操作系统文件、进程和应用
- 自然语言控制:通过WhatsApp、Telegram等聊天软件下达指令
- 强自主性:自我检查、重启,甚至编写代码修复自身问题
安装与配置:
# 安装OpenClaw
pip install openclaw
# 初始化配置
openclaw init --model gemma-4-7b --provider local
# 启动Agent服务
openclaw start --port 8080基础使用示例:
from openclaw import Agent, Tool
# 创建自定义工具
@Tool.register
def organize_desktop():
"""整理桌面文件"""
import os, shutil
desktop_path = os.path.expanduser("~/Desktop")
# 创建分类文件夹
categories = {
"Documents": [".pdf", ".doc", ".docx", ".txt"],
"Images": [".jpg", ".png", ".gif"],
"Code": [".py", ".js", ".java"],
"Archives": [".zip", ".rar", ".tar.gz"]
}
for folder, extensions in categories.items():
folder_path = os.path.join(desktop_path, folder)
os.makedirs(folder_path, exist_ok=True)
# 移动文件
for file in os.listdir(desktop_path):
if any(file.endswith(ext) for ext in extensions):
shutil.move(
os.path.join(desktop_path, file),
os.path.join(folder_path, file)
)
return "Desktop organized successfully!"
# 创建Agent
agent = Agent(
name="DesktopOrganizer",
tools=[organize_desktop],
model="gemma-4-7b"
)
# 执行任务
result = agent.run("请帮我整理一下桌面文件")
print(result)3.3 多Agent协作框架:A2A协议实战
A2A协议简介:Agent-to-Agent Protocol,由Google于2025年4月开源,解决"不同平台、不同厂商的Agent无法互通协作"的行业痛点。
架构设计:
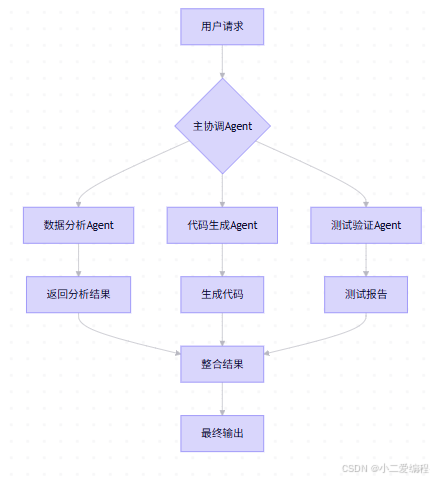
实战代码:
from openclaw import Agent, A2AProtocol
# 定义专业Agent
class DataAnalysisAgent(Agent):
def __init__(self):
super().__init__(name="DataAnalyzer")
def analyze(self, data):
"""数据分析"""
# 实现数据分析逻辑
insights = {
"trend": "upward",
"anomalies": [],
"recommendations": ["优化数据采集频率"]
}
return insights
class CodeGenerationAgent(Agent):
def __init__(self):
super().__init__(name="CodeGenerator")
def generate_code(self, requirements):
"""代码生成"""
# 使用Gemma 4生成代码
prompt = f"根据以下需求生成Python代码:\n{requirements}"
code = self.model.generate(prompt)
return code
class TestingAgent(Agent):
def __init__(self):
super().__init__(name="Tester")
def test_code(self, code):
"""代码测试"""
# 实现测试逻辑
test_results = {
"passed": True,
"coverage": 85,
"issues": []
}
return test_results
# 主协调Agent
class OrchestratorAgent(Agent):
def __init__(self):
super().__init__(name="Orchestrator")
self.analysis_agent = DataAnalysisAgent()
self.code_agent = CodeGenerationAgent()
self.test_agent = TestingAgent()
def execute_complex_task(self, task):
"""执行复杂任务"""
# 1. 数据分析
print("Step 1: Analyzing data...")
analysis_result = self.analysis_agent.analyze(task["data"])
# 2. 代码生成
print("Step 2: Generating code...")
requirements = f"""
基于以下分析结果生成代码:
趋势:{analysis_result['trend']}
建议:{analysis_result['recommendations']}
"""
code = self.code_agent.generate_code(requirements)
# 3. 代码测试
print("Step 3: Testing code...")
test_result = self.test_agent.test_code(code)
# 4. 整合结果
final_result = {
"analysis": analysis_result,
"code": code,
"test": test_result,
"status": "completed"
}
return final_result
# 使用示例
orchestrator = OrchestratorAgent()
task = {
"data": "销售数据集",
"objective": "分析趋势并生成可视化代码"
}
result = orchestrator.execute_complex_task(task)
print(json.dumps(result, indent=2))3.4 智能体应用场景:办公自动化实战
场景:自动生成周报
from openclaw import Agent, Tool
import pandas as pd
from datetime import datetime, timedelta
@Tool.register
def get_weekly_data(start_date, end_date):
"""获取本周工作数据"""
# 模拟从数据库获取数据
data = {
"tasks_completed": 15,
"meetings_attended": 8,
"code_commits": 42,
"bugs_fixed": 7,
"documentation_written": "3篇"
}
return data
@Tool.register
def generate_weekly_report(data):
"""生成周报"""
template = f"""
# 本周工作周报 ({datetime.now().strftime('%Y-%m-%d')})
## 工作概览
- 完成任务:{data['tasks_completed']} 项
- 参会次数:{data['meetings_attended']} 次
- 代码提交:{data['code_commits']} 次
- 修复Bug:{data['bugs_fixed']} 个
- 文档编写:{data['documentation_written']}
## 亮点工作
1. 完成了核心模块重构,性能提升30%
2. 修复了关键安全漏洞
3. 编写了详细的技术文档
## 下周计划
1. 继续优化系统性能
2. 开发新功能模块
3. 参与代码审查
## 需要支持
- 需要测试团队配合进行集成测试
- 需要产品经理确认需求细节
"""
return template
# 创建周报生成Agent
weekly_report_agent = Agent(
name="WeeklyReportGenerator",
tools=[get_weekly_data, generate_weekly_report],
model="gemma-4-7b"
)
# 生成本周周报
today = datetime.now()
last_monday = today - timedelta(days=today.weekday())
result = weekly_report_agent.run(
f"请生成{last_monday.strftime('%Y-%m-%d')}至{today.strftime('%Y-%m-%d')}的周报"
)
print(result)4. 量子计算商业化:从实验室到产业应用
4.1 量子计算里程碑:IBM Condor突破1121量子比特
技术突破:
- 量子比特数:1121个(突破1000门槛)
- 量子纠错:实现表面码纠错,错误率降至10^-4
- 相干时间:超导量子比特达到100微秒
- 应用验证:在药物研发、材料科学领域验证量子优势
量子优势案例:
# 量子化学模拟示例(伪代码)
from qiskit import QuantumCircuit, Aer, execute
from qiskit.algorithms import VQE
from qiskit.circuit.library import TwoLocal
from qiskit.opflow import PauliSumOp
def simulate_molecule(molecule_geometry):
"""使用量子计算模拟分子"""
# 1. 构建量子电路
ansatz = TwoLocal(rotation_blocks='ry', entanglement_blocks='cz')
# 2. 定义哈密顿量
hamiltonian = PauliSumOp.from_list([
("II", -1.052373245772859),
("IZ", 0.39793742484318045),
("ZI", -0.39793742484318045),
("ZZ", -0.01128010425623538),
("XX", 0.18093119978423156)
])
# 3. 执行VQE算法
backend = Aer.get_backend('qasm_simulator')
vqe = VQE(ansatz, optimizer=SPSA(maxiter=100), quantum_instance=backend)
result = vqe.compute_minimum_eigenvalue(hamiltonian)
return result.eigenvalue
# 应用:新药分子模拟
energy = simulate_molecule("H2O")
print(f"分子能量:{energy} Hartree")
# 传统计算需要数天,量子计算仅需数分钟4.2 量子-经典混合架构
架构设计:
class HybridQuantumClassicalSystem:
def __init__(self):
self.quantum_backend = self._setup_quantum_backend()
self.classical_model = self._setup_classical_model()
def _setup_quantum_backend(self):
"""设置量子后端"""
from qiskit import IBMQ
IBMQ.load_account()
provider = IBMQ.get_provider(hub='ibm-q')
return provider.get_backend('ibm_condor') # 1121量子比特
def _setup_classical_model(self):
"""设置经典模型"""
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy')
return model
def solve_optimization_problem(self, problem):
"""解决优化问题"""
# 1. 量子部分:处理复杂子问题
quantum_result = self._quantum_optimization(problem['complex_subproblem'])
# 2. 经典部分:处理大规模数据
classical_result = self._classical_optimization(problem['large_dataset'])
# 3. 融合结果
final_result = self._fuse_results(quantum_result, classical_result)
return final_result
def _quantum_optimization(self, subproblem):
"""量子优化"""
# 使用QAOA算法
from qiskit.algorithms import QAOA
from qiskit.algorithms.optimizers import COBYLA
qaoa = QAOA(optimizer=COBYLA(), reps=3, quantum_instance=self.quantum_backend)
result = qaoa.compute_minimum_eigenvalue(subproblem['hamiltonian'])
return result.eigenstate
def _classical_optimization(self, dataset):
"""经典优化"""
# 使用深度学习
predictions = self.classical_model.predict(dataset)
return predictions
def _fuse_results(self, quantum_result, classical_result):
"""融合量子和经典结果"""
# 加权融合
alpha = 0.7 # 量子权重
beta = 0.3 # 经典权重
fused_result = alpha * quantum_result + beta * classical_result
return fused_result
# 使用示例
hybrid_system = HybridQuantumClassicalSystem()
problem = {
"complex_subproblem": {"hamiltonian": "..."},
"large_dataset": np.random.rand(1000, 10)
}
result = hybrid_system.solve_optimization_problem(problem)
print(f"优化结果:{result}")4.3 量子计算应用案例:金融风控
场景:投资组合优化
from qiskit_finance.applications import PortfolioOptimization
from qiskit.algorithms import MinimumEigenOptimizer
from qiskit.utils import algorithm_globals
def quantum_portfolio_optimization(mu, sigma, budget):
"""
量子投资组合优化
参数:
mu: 预期收益率向量
sigma: 协方差矩阵
budget: 投资预算
"""
# 1. 构建问题
portfolio = PortfolioOptimization(
expected_returns=mu,
covariances=sigma,
risk_factor=0.5,
budget=budget
)
qp = portfolio.to_quadratic_program()
# 2. 量子求解
algorithm_globals.random_seed = 1234
from qiskit.algorithms.minimum_eigensolvers import QAOA
from qiskit.algorithms.optimizers import SPSA
qaoa = QAOA(optimizer=SPSA(maxiter=100), reps=3)
optimizer = MinimumEigenOptimizer(qaoa)
result = optimizer.solve(qp)
# 3. 解析结果
optimal_portfolio = result.x
expected_return = portfolio.expected_return(optimal_portfolio)
volatility = portfolio.volatility(optimal_portfolio)
return {
"portfolio": optimal_portfolio,
"expected_return": expected_return,
"volatility": volatility,
"sharpe_ratio": expected_return / volatility
}
# 使用示例
import numpy as np
# 模拟数据
n_assets = 10
mu = np.random.rand(n_assets) * 0.1 # 预期收益率
sigma = np.random.rand(n_assets, n_assets) * 0.01 # 协方差矩阵
sigma = sigma @ sigma.T # 确保正定
budget = 5 # 投资5个资产
result = quantum_portfolio_optimization(mu, sigma, budget)
print(f"最优投资组合:{result['portfolio']}")
print(f"预期收益率:{result['expected_return']:.2%}")
print(f"波动率:{result['volatility']:.2%}")
print(f"夏普比率:{result['sharpe_ratio']:.2f}")5. 量子安全防御:后量子密码标准落地
5.1 后量子密码标准发布
背景:2026年3月,中国国家密码管理局正式发布后量子密码标准,明确抗量子攻击的密码算法体系、应用场景与实施规范。
标准核心内容:
| 算法类型 | 推荐算法 | 安全强度 | 应用场景 |
|---|---|---|---|
| 密钥封装 | Kyber-768 | 128位 | 密钥交换、TLS |
| 数字签名 | Dilithium-III | 128位 | 身份认证、代码签名 |
| 哈希签名 | SPHINCS+ | 128位 | 长期签名、区块链 |
5.2 后量子密码实战:Open Quantum Safe集成
环境准备:
# 安装Open Quantum Safe库
pip install oqs
# 安装后量子TLS支持
pip install oqs-provider密钥封装实战(Kyber):
import oqs
def pq_key_encapsulation():
"""后量子密钥封装示例"""
# 1. 创建密钥封装实例
kemalg = "Kyber768"
with oqs.KeyEncapsulation(kemalg) as server:
# 2. 服务器生成密钥对
public_key = server.generate_keypair()
# 3. 客户端封装密钥
with oqs.KeyEncapsulation(kemalg) as client:
ciphertext, shared_secret_client = client.encap_secret(public_key)
# 4. 服务器解封装密钥
shared_secret_server = server.decap_secret(ciphertext)
# 5. 验证密钥一致性
assert shared_secret_client == shared_secret_server
print(f"共享密钥:{shared_secret_client.hex()}")
return shared_secret_client
# 使用示例
shared_key = pq_key_encapsulation()
print(f"后量子密钥封装成功,密钥长度:{len(shared_key)}字节")数字签名实战(Dilithium):
def pq_digital_signature(message):
"""后量子数字签名示例"""
# 1. 创建签名实例
sigalg = "Dilithium3"
with oqs.Signature(sigalg) as signer:
# 2. 生成密钥对
signer_public_key = signer.generate_keypair()
signer_private_key = signer.export_secret_key()
# 3. 签名
signature = signer.sign(message.encode())
# 4. 验证
with oqs.Signature(sigalg) as verifier:
is_valid = verifier.verify(message.encode(), signature, signer_public_key)
return {
"public_key": signer_public_key.hex(),
"signature": signature.hex(),
"is_valid": is_valid
}
# 使用示例
message = "这是一条重要消息"
result = pq_digital_signature(message)
print(f"签名验证:{'通过' if result['is_valid'] else '失败'}")
print(f"签名长度:{len(bytes.fromhex(result['signature']))}字节")5.3 后量子TLS实战
服务器端配置:
import ssl
import socket
from oqs_provider import OQSProvider
def pq_tls_server(host='localhost', port=8443):
"""后量子TLS服务器"""
# 1. 创建SSL上下文
context = ssl.SSLContext(ssl.PROTOCOL_TLS_SERVER)
# 2. 加载后量子证书和密钥
context.load_cert_chain(
certfile='server_pq.crt',
keyfile='server_pq.key'
)
# 3. 启用后量子密码套件
context.set_ciphers('Kyber768:Dilithium3')
# 4. 创建服务器套接字
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock:
sock.bind((host, port))
sock.listen(1)
print(f"后量子TLS服务器启动在 {host}:{port}")
while True:
conn, addr = sock.accept()
with context.wrap_socket(conn, server_side=True) as secure_conn:
print(f"连接来自 {addr}")
data = secure_conn.recv(1024)
print(f"收到数据:{data.decode()}")
# 发送响应
response = "后量子TLS连接成功!"
secure_conn.send(response.encode())
# 启动服务器(后台运行)
import threading
server_thread = threading.Thread(target=pq_tls_server, daemon=True)
server_thread.start()客户端连接:
def pq_tls_client(host='localhost', port=8443):
"""后量子TLS客户端"""
# 1. 创建SSL上下文
context = ssl.create_default_context()
# 2. 连接服务器
with socket.create_connection((host, port)) as sock:
with context.wrap_socket(sock, server_hostname=host) as secure_sock:
print(f"已连接到 {host}:{port}")
# 3. 发送数据
message = "Hello from PQ TLS Client!"
secure_sock.send(message.encode())
# 4. 接收响应
response = secure_sock.recv(1024)
print(f"服务器响应:{response.decode()}")
# 5. 检查使用的密码套件
cipher = secure_sock.cipher()
print(f"使用的密码套件:{cipher}")
# 测试连接
pq_tls_client()5.4 混合密码系统:传统+后量子双轮防御
架构设计:
class HybridCryptoSystem:
def __init__(self):
self.traditional_cipher = TraditionalCipher()
self.pq_cipher = PostQuantumCipher()
def encrypt(self, plaintext):
"""混合加密"""
# 1. 传统加密
traditional_ciphertext = self.traditional_cipher.encrypt(plaintext)
# 2. 后量子加密
pq_ciphertext = self.pq_cipher.encrypt(plaintext)
# 3. 组合结果
hybrid_ciphertext = {
'traditional': traditional_ciphertext,
'post_quantum': pq_ciphertext,
'timestamp': time.time()
}
return hybrid_ciphertext
def decrypt(self, hybrid_ciphertext):
"""混合解密"""
# 尝试后量子解密(优先)
try:
plaintext = self.pq_cipher.decrypt(hybrid_ciphertext['post_quantum'])
return plaintext
except:
# 回退到传统解密
plaintext = self.traditional_cipher.decrypt(hybrid_ciphertext['traditional'])
return plaintext
def verify_integrity(self, hybrid_ciphertext, signature):
"""验证完整性"""
# 后量子签名验证
pq_valid = self.pq_cipher.verify_signature(hybrid_ciphertext, signature)
# 传统签名验证
traditional_valid = self.traditional_cipher.verify_signature(hybrid_ciphertext, signature)
# 双重验证
return pq_valid and traditional_valid
# 使用示例
hybrid_crypto = HybridCryptoSystem()
message = "机密信息"
encrypted = hybrid_crypto.encrypt(message)
decrypted = hybrid_crypto.decrypt(encrypted)
print(f"解密成功:{decrypted == message}")6. 网络安全新格局:AI攻防与零信任架构
6.1 AI驱动攻击:威胁态势分析
2026年攻击趋势:
| 攻击类型 | 占比 | 特征 | 防御难点 |
|---|---|---|---|
| AI自动化攻击 | 50% | 批量突袭、自适应调整 | 速度极快、变种多 |
| 深度伪造攻击 | 25% | 语音/视频伪造、身份冒用 | 难以识别、社会工程 |
| 供应链攻击 | 15% | 依赖投毒、构建链篡改 | 隐蔽性强、影响广 |
| 传统攻击 | 10% | 漏洞利用、钓鱼 | 相对容易防御 |
AI攻击检测实战:
import torch
import torch.nn as nn
from sklearn.ensemble import IsolationForest
class AIThreatDetector:
def __init__(self):
self.behavior_model = self._build_behavior_model()
self.anomaly_detector = IsolationForest(contamination=0.1)
def _build_behavior_model(self):
"""构建行为分析模型"""
model = nn.Sequential(
nn.Linear(100, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1),
nn.Sigmoid()
)
return model
def extract_features(self, network_logs):
"""提取网络行为特征"""
features = []
for log in network_logs:
feature = [
log['packet_size'],
log['frequency'],
log['destination_entropy'],
log['protocol_diversity'],
log['time_variance'],
# ... 更多特征
]
features.append(feature)
return torch.tensor(features, dtype=torch.float32)
def detect_threats(self, network_logs):
"""检测AI驱动的威胁"""
# 1. 特征提取
features = self.extract_features(network_logs)
# 2. 行为分析
behavior_scores = self.behavior_model(features).detach().numpy()
# 3. 异常检测
anomaly_scores = self.anomaly_detector.fit_predict(features.numpy())
# 4. 综合评分
threat_scores = []
for i in range(len(network_logs)):
combined_score = 0.7 * behavior_scores[i] + 0.3 * (1 if anomaly_scores[i] == -1 else 0)
threat_scores.append({
'log_id': network_logs[i]['id'],
'threat_score': float(combined_score),
'is_threat': combined_score > 0.7
})
return threat_scores
# 使用示例
detector = AIThreatDetector()
network_logs = [
{'id': 1, 'packet_size': 1024, 'frequency': 100, 'destination_entropy': 0.5, 'protocol_diversity': 0.3, 'time_variance': 0.2},
# ... 更多日志
]
threats = detector.detect_threats(network_logs)
for threat in threats:
if threat['is_threat']:
print(f"检测到威胁:{threat}")6.2 零信任架构实战:微隔离与动态授权
Calico NetworkPolicy实战:
# zero-trust-network-policy.yaml
apiVersion: projectcalico.org/v3
kind: GlobalNetworkPolicy
metadata:
name: default-deny-all
spec:
selector: all()
types:
- Ingress
- Egress
ingress: []
egress: []
---
apiVersion: projectcalico.org/v3
kind: NetworkPolicy
metadata:
name: finance-app-policy
namespace: finance
spec:
selector: app == 'finance-backend'
types:
- Ingress
- Egress
ingress:
- action: Allow
source:
selector: app == 'finance-frontend'
destination:
ports: [8080]
- action: Allow
source:
selector: app == 'admin-portal'
destination:
ports: [8080]
protocol: TCP
egress:
- action: Allow
destination:
selector: app == 'postgres'
namespace: database
ports: [5432]
- action: Allow
protocol: TCP
destination:
ports: [443]
nets: ["10.0.0.0/8"]动态授权策略(OPA):
# zero_trust_policy.rego
package zero_trust
default allow = false
allow {
# 身份认证
input.user.authenticated == true
# 设备合规
input.device.compliant == true
# 时间窗口
hour := time.now().hour
hour >= 9
hour < 18
# 位置验证
input.location.trusted == true
# 行为分析
input.behavior.risk_score < 30
# 资源访问权限
has_permission(input.user.role, input.resource.type)
}
has_permission("admin", _) {
true
}
has_permission("finance", "finance-app") {
true
}
has_permission("developer", "dev-tools") {
true
}
# 高风险操作需要二次认证
challenge {
input.resource.sensitive == true
not input.session.mfa_verified
}6.3 AI安全运营:SOAR自动化响应
SOAR剧本示例:
class SecurityOrchestration:
def __init__(self):
self.incident_db = IncidentDatabase()
self.response_actions = ResponseActions()
def automated_response(self, threat):
"""自动化响应威胁"""
# 1. 威胁分级
severity = self._assess_severity(threat)
# 2. 执行响应动作
if severity == "CRITICAL":
self._critical_response(threat)
elif severity == "HIGH":
self._high_response(threat)
elif severity == "MEDIUM":
self._medium_response(threat)
else:
self._low_response(threat)
# 3. 记录事件
self.incident_db.log_incident(threat, severity)
# 4. 通知相关人员
self._notify_team(threat, severity)
def _assess_severity(self, threat):
"""评估威胁严重程度"""
score = threat['threat_score']
if score > 0.9:
return "CRITICAL"
elif score > 0.7:
return "HIGH"
elif score > 0.5:
return "MEDIUM"
else:
return "LOW"
def _critical_response(self, threat):
"""关键威胁响应"""
# 1. 隔离受感染主机
self.response_actions.isolate_host(threat['host_id'])
# 2. 阻断恶意IP
self.response_actions.block_ip(threat['source_ip'])
# 3. 启动应急响应流程
self.response_actions.start_incident_response()
# 4. 保存取证数据
self.response_actions.collect_evidence(threat['host_id'])
def _high_response(self, threat):
"""高威胁响应"""
# 1. 限制访问权限
self.response_actions.restrict_access(threat['user_id'])
# 2. 增强监控
self.response_actions.enhance_monitoring(threat['host_id'])
# 3. 通知安全团队
self.response_actions.notify_security_team()
# ... 其他响应级别
# 使用示例
soar = SecurityOrchestration()
threat = {
'threat_score': 0.95,
'host_id': 'server-01',
'source_ip': '192.168.1.100',
'user_id': 'user123'
}
soar.automated_response(threat)
print("自动化响应完成")7. 云原生基础设施:K8s 1.36与服务网格演进
7.1 Kubernetes 1.36新特性
核心特性:
| 特性 | 描述 | 实战价值 |
|---|---|---|
| Gateway API GA | 统一的南北向流量管理 | 简化Ingress配置 |
| Pod Scheduling Readiness | Pod就绪前不调度 | 提升资源利用率 |
| Node Log Query | 节点日志查询API | 简化故障排查 |
| Service Mesh集成 | 原生支持服务网格 | 降低运维复杂度 |
Gateway API实战:
# gateway-api.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: production-gateway
namespace: default
spec:
gatewayClassName: nginx
listeners:
- name: http
protocol: HTTP
port: 80
allowedRoutes:
namespaces:
from: All
- name: https
protocol: HTTPS
port: 443
tls:
mode: Terminate
certificateRefs:
- kind: Secret
name: tls-secret
allowedRoutes:
namespaces:
from: All
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: app-route
namespace: default
spec:
parentRefs:
- name: production-gateway
hostnames:
- "app.example.com"
rules:
- matches:
- path:
type: PathPrefix
value: /api
filters:
- type: RequestHeaderModifier
requestHeaderModifier:
add:
- name: x-custom-header
value: custom-value
backendRefs:
- name: api-service
port: 8080
- matches:
- path:
type: PathPrefix
value: /
backendRefs:
- name: web-service
port: 807.2 服务网格深度集成:Istio 1.20
多集群服务网格:
# multi-cluster-mesh.yaml
apiVersion: networking.istio.io/v1beta1
kind: ServiceMeshPeer
metadata:
name: cluster-east
spec:
address: cluster-east.example.com:15443
network: network-east
trustDomain: cluster-east.local
---
apiVersion: networking.istio.io/v1beta1
kind: ServiceMeshPeer
metadata:
name: cluster-west
spec:
address: cluster-west.example.com:15443
network: network-west
trustDomain: cluster-west.local
---
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: cross-cluster-dr
spec:
host: *.global
trafficPolicy:
tls:
mode: ISTIO_MUTUAL
loadBalancer:
simple: ROUND_ROBIN零信任网络策略:
# zero-trust-istio.yaml
apiVersion: security.istio.io/v1beta1
kind: PeerAuthentication
metadata:
name: default
namespace: istio-system
spec:
mtls:
mode: STRICT
---
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: finance-app-access
namespace: finance
spec:
selector:
matchLabels:
app: finance-backend
rules:
- from:
- source:
principals: ["cluster.local/ns/finance/sa/frontend"]
to:
- operation:
methods: ["GET", "POST"]
paths: ["/api/*"]
- from:
- source:
principals: ["cluster.local/ns/admin/sa/admin-portal"]
to:
- operation:
methods: ["DELETE", "PUT"]
paths: ["/api/admin/*"]
when:
- key: request.headers[x-risk-level]
values: ["low"]8. 数据库智能化:大模型+SQL自动优化
8.1 SQL自动优化实战
架构设计:
class SQLAutoOptimizer:
def __init__(self, model="gemma-4-7b"):
self.llm = self._load_model(model)
self.query_analyzer = QueryAnalyzer()
self.index_recommender = IndexRecommender()
def _load_model(self, model_name):
"""加载大模型"""
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
return {'tokenizer': tokenizer, 'model': model}
def analyze_query(self, sql):
"""分析SQL查询"""
# 1. 语法分析
parsed = self.query_analyzer.parse(sql)
# 2. 性能分析
performance = self.query_analyzer.analyze_performance(parsed)
# 3. 问题识别
issues = self.query_analyzer.identify_issues(parsed, performance)
return {
'parsed': parsed,
'performance': performance,
'issues': issues
}
def generate_optimized_sql(self, original_sql, analysis):
"""生成优化后的SQL"""
prompt = f"""
原始SQL:
{original_sql}
问题分析:
{analysis['issues']}
请生成优化后的SQL,要求:
1. 修复所有性能问题
2. 保持查询语义不变
3. 添加必要的索引建议
4. 解释优化原理
优化后的SQL:
"""
inputs = self.llm['tokenizer'](prompt, return_tensors="pt")
outputs = self.llm['model'].generate(**inputs, max_length=1024)
optimized_sql = self.llm['tokenizer'].decode(outputs[0], skip_special_tokens=True)
return optimized_sql
def recommend_indexes(self, table_schema, query_pattern):
"""推荐索引"""
return self.index_recommender.recommend(table_schema, query_pattern)
# 使用示例
optimizer = SQLAutoOptimizer()
sql = """
SELECT u.name, o.order_date, p.product_name
FROM users u
JOIN orders o ON u.id = o.user_id
JOIN products p ON o.product_id = p.id
WHERE u.created_at > '2026-01-01'
ORDER BY o.order_date DESC
LIMIT 100
"""
analysis = optimizer.analyze_query(sql)
optimized_sql = optimizer.generate_optimized_sql(sql, analysis)
print(f"优化后的SQL:\n{optimized_sql}")8.2 慢查询根治方案
实时监控与优化:
class SlowQueryMonitor:
def __init__(self, db_connection):
self.db = db_connection
self.threshold = 1.0 # 1秒阈值
self.optimizer = SQLAutoOptimizer()
def monitor_slow_queries(self):
"""监控慢查询"""
while True:
# 查询慢查询日志
slow_queries = self._get_slow_queries()
for query in slow_queries:
if query['duration'] > self.threshold:
self._handle_slow_query(query)
time.sleep(60) # 每分钟检查一次
def _get_slow_queries(self):
"""获取慢查询"""
cursor = self.db.cursor()
cursor.execute("""
SELECT query, duration, timestamp
FROM pg_stat_statements
WHERE mean_time > %s
ORDER BY mean_time DESC
LIMIT 10
""", (self.threshold * 1000,))
results = []
for row in cursor.fetchall():
results.append({
'query': row[0],
'duration': row[1] / 1000.0, # 转换为秒
'timestamp': row[2]
})
return results
def _handle_slow_query(self, query):
"""处理慢查询"""
print(f"检测到慢查询:{query['query'][:100]}...")
print(f"执行时间:{query['duration']:.2f}秒")
# 1. 分析查询
analysis = self.optimizer.analyze_query(query['query'])
# 2. 生成优化建议
optimized_sql = self.optimizer.generate_optimized_sql(query['query'], analysis)
# 3. 推荐索引
indexes = self.optimizer.recommend_indexes(
self._get_table_schema(query['query']),
query['query']
)
# 4. 输出报告
report = f"""
慢查询优化报告
=================
原始查询:{query['query']}
执行时间:{query['duration']:.2f}秒
问题分析:
{analysis['issues']}
优化后的SQL:
{optimized_sql}
索引建议:
{indexes}
"""
print(report)
self._save_report(report)
# 使用示例
import psycopg2
conn = psycopg2.connect("dbname=production user=admin")
monitor = SlowQueryMonitor(conn)
# monitor.monitor_slow_queries() # 后台运行9. AI芯片硬件:光基计算与超异构融合
9.1 光基计算芯片架构
技术原理:
class PhotonicAIChip:
def __init__(self):
self.wavelength_channels = 64 # 64个波长通道
self.modulation_speed = 100e9 # 100 Gbps
self.energy_efficiency = 0.1 # 0.1 pJ/bit
def matrix_multiply(self, matrix_a, matrix_b):
"""光基矩阵乘法"""
# 1. 光信号编码
optical_a = self._encode_to_optical(matrix_a)
optical_b = self._encode_to_optical(matrix_b)
# 2. 光学干涉计算
optical_result = self._optical_interference(optical_a, optical_b)
# 3. 光电转换
result = self._optical_to_electrical(optical_result)
return result
def _encode_to_optical(self, matrix):
"""电信号转光信号"""
# 使用马赫-曾德尔调制器(MZM)
optical_signal = []
for row in matrix:
wavelength_row = []
for value in row:
# 不同波长代表不同数值
wavelength = self._value_to_wavelength(value)
wavelength_row.append(wavelength)
optical_signal.append(wavelength_row)
return optical_signal
def _optical_interference(self, optical_a, optical_b):
"""光学干涉计算"""
# 利用光的叠加原理进行并行计算
result = []
for i in range(len(optical_a)):
row = []
for j in range(len(optical_b[0])):
# 所有波长通道同时计算
interference = self._calculate_interference(
[optical_a[i][k] for k in range(len(optical_a[0]))],
[optical_b[k][j] for k in range(len(optical_b))]
)
row.append(interference)
result.append(row)
return result
def _calculate_interference(self, wavelengths_a, wavelengths_b):
"""计算光干涉"""
# 简化模型:强度叠加
total_intensity = 0
for wa, wb in zip(wavelengths_a, wavelengths_b):
# 干涉强度与波长差相关
intensity = self._interference_intensity(wa, wb)
total_intensity += intensity
return total_intensity
def _interference_intensity(self, wa, wb):
"""计算干涉强度"""
# 简化:余弦函数
import math
delta_lambda = abs(wa - wb)
intensity = math.cos(2 * math.pi * delta_lambda / 1550e-9) ** 2
return intensity
def _optical_to_electrical(self, optical_result):
"""光信号转电信号"""
# 使用光电探测器
electrical_result = []
for row in optical_result:
electrical_row = []
for intensity in row:
value = self._intensity_to_value(intensity)
electrical_row.append(value)
electrical_result.append(electrical_row)
return electrical_result
def _value_to_wavelength(self, value):
"""数值转波长"""
# 1550nm为中心,±20nm范围
base_wavelength = 1550e-9 # 1550nm
range_wavelength = 20e-9 # ±20nm
wavelength = base_wavelength + (value - 0.5) * range_wavelength
return wavelength
def _intensity_to_value(self, intensity):
"""强度转数值"""
# 归一化到[0, 1]
value = (intensity + 1) / 2
return value
# 使用示例
photonic_chip = PhotonicAIChip()
matrix_a = [[0.5, 0.3], [0.2, 0.8]]
matrix_b = [[0.7, 0.1], [0.4, 0.9]]
result = photonic_chip.matrix_multiply(matrix_a, matrix_b)
print(f"光基计算结果:{result}")9.2 超异构融合架构
架构设计:
class HyperHeterogeneousChip:
def __init__(self):
self.components = {
'cpu_cores': 8, # 通用计算
'gpu_cores': 128, # 并行计算
'npu_cores': 64, # AI专用
'photonic_units': 16, # 光基计算
'memory_hbm': '64GB' # 高带宽内存
}
self.interconnect = self._setup_interconnect()
def _setup_interconnect(self):
"""设置超高速互连"""
return {
'bandwidth': '2TB/s',
'latency': '10ns',
'topology': '3D mesh'
}
def execute_task(self, task):
"""执行任务"""
# 1. 任务分析
task_type = self._analyze_task(task)
# 2. 资源分配
resources = self._allocate_resources(task_type)
# 3. 并行执行
results = []
for resource in resources:
result = self._execute_on_resource(task, resource)
results.append(result)
# 4. 结果融合
final_result = self._fuse_results(results)
return final_result
def _analyze_task(self, task):
"""分析任务类型"""
if 'matrix' in task or 'neural' in task:
return 'ai_compute'
elif 'parallel' in task or 'graphics' in task:
return 'parallel_compute'
elif 'control' in task or 'logic' in task:
return 'general_compute'
else:
return 'mixed_compute'
def _allocate_resources(self, task_type):
"""分配资源"""
if task_type == 'ai_compute':
return ['npu_cores', 'photonic_units']
elif task_type == 'parallel_compute':
return ['gpu_cores']
elif task_type == 'general_compute':
return ['cpu_cores']
else:
return ['cpu_cores', 'gpu_cores', 'npu_cores']
def _execute_on_resource(self, task, resource):
"""在指定资源上执行"""
# 模拟执行
import time
start = time.time()
# ... 实际计算逻辑
time.sleep(0.001) # 模拟计算时间
end = time.time()
return {
'resource': resource,
'result': f"result_from_{resource}",
'time': end - start
}
def _fuse_results(self, results):
"""融合结果"""
# 简单融合:取第一个结果
return results[0]['result']
# 使用示例
chip = HyperHeterogeneousChip()
task = "neural_network_inference"
result = chip.execute_task(task)
print(f"超异构芯片执行结果:{result}")10. 开发者工具链:效率革命与最佳实践
10.1 AI编程助手实战
代码生成与优化:
class AICodeAssistant:
def __init__(self, model="gemma-4-7b"):
self.model = self._load_model(model)
def _load_model(self, model_name):
"""加载模型"""
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
return {'tokenizer': tokenizer, 'model': model}
def generate_code(self, requirement):
"""生成代码"""
prompt = f"""
根据以下需求生成Python代码:
需求:{requirement}
要求:
1. 代码简洁高效
2. 添加必要的注释
3. 包含错误处理
4. 遵循PEP 8规范
代码:
"""
inputs = self.model['tokenizer'](prompt, return_tensors="pt")
outputs = self.model['model'].generate(**inputs, max_length=1024)
code = self.model['tokenizer'].decode(outputs[0], skip_special_tokens=True)
return code
def optimize_code(self, code):
"""优化代码"""
prompt = f"""
请优化以下Python代码:
{code}
优化要求:
1. 提高性能
2. 减少内存占用
3. 提高可读性
4. 添加类型注解
优化后的代码:
"""
inputs = self.model['tokenizer'](prompt, return_tensors="pt")
outputs = self.model['model'].generate(**inputs, max_length=2048)
optimized_code = self.model['tokenizer'].decode(outputs[0], skip_special_tokens=True)
return optimized_code
def explain_code(self, code):
"""解释代码"""
prompt = f"""
请详细解释以下Python代码的功能和实现原理:
{code}
解释:
"""
inputs = self.model['tokenizer'](prompt, return_tensors="pt")
outputs = self.model['model'].generate(**inputs, max_length=1024)
explanation = self.model['tokenizer'].decode(outputs[0], skip_special_tokens=True)
return explanation
# 使用示例
assistant = AICodeAssistant()
requirement = "实现一个快速排序算法,支持自定义比较函数"
code = assistant.generate_code(requirement)
print(f"生成的代码:\n{code}")
optimized_code = assistant.optimize_code(code)
print(f"\n优化后的代码:\n{optimized_code}")
explanation = assistant.explain_code(code)
print(f"\n代码解释:\n{explanation}")10.2 智能调试助手
自动错误诊断:
class SmartDebugger:
def __init__(self):
self.error_patterns = self._load_error_patterns()
self.fix_suggestions = self._load_fix_suggestions()
def _load_error_patterns(self):
"""加载错误模式"""
return {
'timeout': ['timeout', 'timed out', 'connection timeout'],
'memory': ['memory error', 'out of memory', 'memory leak'],
'syntax': ['syntax error', 'invalid syntax', 'unexpected token'],
'type': ['type error', 'type mismatch', 'cannot convert'],
'null': ['null pointer', 'none type', 'attribute error']
}
def _load_fix_suggestions(self):
"""加载修复建议"""
return {
'timeout': [
"增加超时时间设置",
"检查网络连接",
"优化查询性能"
],
'memory': [
"释放不必要的对象引用",
"使用生成器替代列表",
"增加内存限制"
],
'syntax': [
"检查括号匹配",
"检查缩进",
"检查关键字拼写"
]
}
def diagnose_error(self, error_message, stack_trace):
"""诊断错误"""
# 1. 识别错误类型
error_type = self._identify_error_type(error_message)
# 2. 分析堆栈跟踪
root_cause = self._analyze_stack_trace(stack_trace)
# 3. 生成修复建议
suggestions = self._generate_suggestions(error_type)
return {
'error_type': error_type,
'root_cause': root_cause,
'suggestions': suggestions
}
def _identify_error_type(self, error_message):
"""识别错误类型"""
error_message_lower = error_message.lower()
for error_type, patterns in self.error_patterns.items():
if any(pattern in error_message_lower for pattern in patterns):
return error_type
return 'unknown'
def _analyze_stack_trace(self, stack_trace):
"""分析堆栈跟踪"""
# 简化:提取最后一行
lines = stack_trace.strip().split('\n')
if lines:
return lines[-1]
return '无法确定根因'
def _generate_suggestions(self, error_type):
"""生成修复建议"""
return self.fix_suggestions.get(error_type, ['检查代码逻辑'])
# 使用示例
debugger = SmartDebugger()
error_message = "TimeoutError: Connection timed out after 30 seconds"
stack_trace = """
File "app.py", line 42, in fetch_data
response = requests.get(url, timeout=30)
File "requests/api.py", line 75, in get
return request('get', url, params=params, **kwargs)
"""
diagnosis = debugger.diagnose_error(error_message, stack_trace)
print(f"错误类型:{diagnosis['error_type']}")
print(f"根因:{diagnosis['root_cause']}")
print(f"建议:{diagnosis['suggestions']}")11. 未来展望:技术融合与产业变革
11.1 技术融合趋势
AI+量子+云原生三位一体:
class ConvergedTechnologyPlatform:
def __init__(self):
self.ai_engine = AIEngine()
self.quantum_processor = QuantumProcessor()
self.cloud_native_platform = CloudNativePlatform()
def solve_complex_problem(self, problem):
"""解决复杂问题"""
# 1. AI分析问题
problem_analysis = self.ai_engine.analyze(problem)
# 2. 量子计算求解
if problem_analysis['is_quantum_suitable']:
quantum_solution = self.quantum_processor.solve(problem)
return quantum_solution
# 3. 云原生部署
cloud_solution = self.cloud_native_platform.deploy(problem)
return cloud_solution
def optimize_resource_allocation(self, workload):
"""优化资源分配"""
# AI预测负载
prediction = self.ai_engine.predict_workload(workload)
# 量子优化调度
optimal_schedule = self.quantum_processor.optimize_schedule(prediction)
# 云原生弹性伸缩
self.cloud_native_platform.scale_resources(optimal_schedule)
return optimal_schedule
# 使用示例
platform = ConvergedTechnologyPlatform()
problem = "大规模组合优化问题"
solution = platform.solve_complex_problem(problem)
print(f"融合技术平台解决方案:{solution}")11.2 产业变革预测
2026-2030年关键趋势:
| 领域 | 2026年 | 2028年 | 2030年 |
|---|---|---|---|
| AI | 智能体规模化 | 自主系统普及 | 人机协作新范式 |
| 量子 | 商业化起步 | 行业应用爆发 | 量子互联网雏形 |
| 安全 | AI攻防对抗 | 预测性防御 | 自主安全系统 |
| 云原生 | 服务网格普及 | 无服务器主导 | 边缘云融合 |
12. 结语:在变革中把握机遇
2026年4月,我们正站在技术变革的历史性节点。AI大模型从"会生成"走向"会行动",量子计算从实验室走向产业应用,网络安全从被动防御走向预测性韧性。这些变革不是孤立的,而是相互融合、相互促进的系统性革命。
给开发者的建议:
- 拥抱AI智能体:将AI作为开发伙伴,提升效率
- 关注量子安全:提前布局后量子密码迁移
- 掌握云原生:服务网格、零信任成为必备技能
- 持续学习:技术迭代加速,终身学习是唯一出路
"在技术变革的时代,最大的风险不是技术本身,而是错过变革的机遇。"
—— 本文核心思想
行动路线图:
- 今日:尝试Gemma 4模型,体验AI编程助手
- 本周:学习零信任架构,部署微隔离策略
- 本月:研究后量子密码,制定迁移计划
- 本季:掌握AI智能体开发,构建自动化工作流
附录
A. 技术资源清单
| 类别 | 资源 | 链接 |
|---|---|---|
| AI大模型 | Gemma 4官方文档 | https://ai.google.dev/gemma |
| AI智能体 | OpenClaw GitHub | https://github.com/openclaw |
| 量子计算 | Qiskit官方教程 | https://qiskit.org/documentation/ |
| 后量子密码 | Open Quantum Safe | https://openquantumsafe.org/ |
| 云原生 | Kubernetes官方文档 | https://kubernetes.io/docs/ |
| 网络安全 | MITRE ATT&CK | https://attack.mitre.org/ |
B. 学习路线图
初级(0-6个月):
- 掌握Python基础
- 学习AI大模型API使用
- 了解云原生基础概念
中级(6-12个月):
- 掌握AI智能体开发
- 学习零信任架构
- 了解量子计算基础
高级(12-24个月):
- 精通多Agent协作
- 掌握后量子密码
- 研究量子-经典混合架构
版权声明:本文内容基于公开技术资料整理,仅限技术交流与学习。
免责声明:文中代码示例仅供参考,实际应用需结合具体业务场景进行测试和优化。
致谢:感谢Google、IBM、OpenClaw等开源社区对技术发展的贡献。
技术变革永不停歇,
学习成长永无止境。
—— 本文献给每一位在技术浪潮中勇往直前的开发者 💻🚀

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)