Diffusion-离散扩散-202310-SEDD01:Discrete Diffusion Modeling
摘要
尽管扩散模型在许多生成建模任务中取得了突破性表现,但在自然语言等离散数据域上却表现不佳。关键在于,标准扩散模型依赖于成熟的分数匹配理论,但将该理论推广到离散结构的尝试并未取得同样的实证收益。在本工作中,我们通过提出分数熵来弥合这一差距:这是一种新颖的损失函数,它能自然地将分数匹配扩展到离散空间,无缝集成以构建离散扩散模型,并显著提升性能。在实验中,我们在标准语言建模任务上测试了我们的分数熵离散扩散模型 (SEDD)。对于相似的模型规模,SEDD击败了现有的语言扩散范式(将困惑度降低了 25−75%2 5 \mathrm { - } 7 5 \%25−75% ),并且可与自回归模型竞争,特别是在性能上超越了GPT‑2。此外,与自回归模型相比,SEDD无需采用温度缩放等分布退火技术即可生成忠实文本(其生成困惑度比未退火的GPT‑2高出约8 ×\times× ),能够在计算和质量之间权衡(以 32×3 2 \times32× 次更少的网络评估获得相似的质量),并支持可控填充(能与核采样质量相匹配,同时支持除从左到右提示外的其他策略)。
1. 引言
深度学习最近的许多进展都围绕生成建模展开。在此过程中,模型学习如何从非结构化数据生成新颖样本。凭借现代神经网络的强大能力,这些“生成式人工智能”系统发展出了无与伦比的能力,例如仅凭文本生成图像(Ramesh etal., 2022)以及回答复杂问题(Brownetal.,2020)。
1斯坦福大学 2Pika Labs。通讯作者:Aaron Lou <<< aaronlou@stanford.edu>。论文收录于 41st\mathit { 4 1 } ^ { s t }41st 国际机器学习会议,维也纳,奥地利。PMLR 235,2024年。版权归作者所有。
任何深度生成模型的关键部分是概率建模技术。对于诸如自然语言之类的离散数据,自回归建模(Yule,1971)——可以说是最简单的建模类型,因为它源自概率链式法则——几十年来一直是唯一有竞争力的方法。尽管现代自回归Transformer已经取得了惊人的成果(Vaswaniet al., 2017年; Radford etal., 2019),但仍存在局限。例如,对代币的顺序采样速度慢,难以控制,并且在没有分布退火技术(如核采样)的情况下通常会退化(Holtzman et al.,2019)
为缓解这些问题,研究人员已寻求替代方法来生成文本数据。特别是受到它们在图像域的成功启发,许多工作将扩散模型(Sohl‑Dickstein等人, 2015年;Ho等人,2020年; Song等人, 2021c)扩展到语言域(Li等人,2022年; Austin等人, 2021年)。然而,尽管付出了相当大的努力,目前尚无此类方法能与自回归建模媲美,因为它们似然不具竞争力,采样速度较慢,且若不依赖于繁重的退火和经验性调整,就无法生成可媲美的样本。
在我们的工作中,我们通过引入分数熵离散扩散模型(SEDD)来挑战自回归模型长期以来占据的主导地位。SEDD利用数据分布的比值参数化了一个反向离散扩散过程。这一过程通过分数熵来学习——这是一种新颖的损失,类似于标准扩散模型中的分数匹配(Hyv¨arinen, 2005;Song与Ermon, 2019),并带来了多项实证优势:
- 在核心语言建模任务上,SEDD显著优于所有现有的语言扩散模型(Li等人, 2022年;Austin等人, 2021年;Gulrajani与Hashimoto,2023年; He等人,2022年),并与同规模的自回归模型具有竞争力(在其零样本困惑度任务上超越了GPT‑2(Radford等人, 2019年))。
- SEDD 能生成高质量的无条件样本,并允许用户自然地权衡计算量与质量。在衡量来自相似规模模型的无条件和未退火样本的生成困惑度(由大型模型给出)时,SEDD 的表现优于
第002/30页
GPT‑2的性能提升了 6−8×6 { - } 8 \times6−8× 倍,并且能以 32×3 2 \times32× 次更少的函数评估达到同等性能。
- 通过直接参数化概率比率,SEDD具有高度可控性。特别是,无需专门的训练即可从任意位置提示SEDD。无论是标准(从左到右)还是填充生成,SEDD的表现都优于语言扩散模型,并与采用核采样的自回归模型相当(依据MAUVE分数衡量(Pillutla等人, 2021年))。
2. 预备知识
2.1. 离散扩散过程
我们将建模在一个有限支撑集上的概率分布
X={1,…,N}∘\mathcal { X } = \{ 1 , \ldots , N \} _ { \circ }X={1,…,N}∘ 。由于支撑集是离散的,请注意我们的概率分布可以用概率质量向量 p∈RN\boldsymbol { p } \in \mathbb { R } ^ { N }p∈RN 来表示,这些向量为正且总和为1。为了定义一个离散扩散过程,我们依据一个由线性常微分方程给出的连续时间马尔可夫过程(Campbell等人,2022年;Anderson,2012年),演化一族分布 pt∈RN\boldsymbol { p } _ { t } \in \mathbb { R } ^ { N }pt∈RN 。
dptdt=Qtptp0≈pd a t a(1) \frac {d p _ {t}}{d t} = Q _ {t} p _ {t} \quad p _ {0} \approx p _ {\text {d a t a}} \tag {1} dtdpt=Qtptp0≈pd a t a(1)
此处, QtQ _ { t }Qt 是扩散矩阵 RN×N\mathbb { R } ^ { N \times N }RN×N ,具有非负的非对角线元素和列总和为零(因此速率 dptdt\begin{array} { c } { { d p _ { t } } } \\ { { d t } } \end{array}dptdt 总和为0,意味着ptp _ { t }pt 不增加或减少总质量)。通常, QtQ _ { t }Qt 是简单的(例如一个简单的标量因子 Qt = σ(t)Q)Q _ { t } ~ = ~ \sigma ( t ) Q )Qt = σ(t)Q) ),因此ptp _ { t }pt 趋近于一个极限分布 pbasep _ { \mathrm { b a s e } }pbase ,当 t→∞t \to \inftyt→∞ 时。
可以通过采用小的 Δt\Delta tΔt 欧拉步并随机采样产生的转移来模拟这个过程。具体而言,样本由来自 QtQ _ { t }Qt 列的转移密度定义:
p(xt+Δt=y∣xt=x)=δxy+Qt(y,x)Δt+O(Δt2)(2) p (x _ {t + \Delta t} = y | x _ {t} = x) = \delta_ {x y} + Q _ {t} (y, x) \Delta t + O (\Delta t ^ {2}) (2) p(xt+Δt=y∣xt=x)=δxy+Qt(y,x)Δt+O(Δt2)(2)
最后,这个过程有一个众所周知的逆转(Kelly, 1980;Sun 等人, 2023)由另一个扩散矩阵 QtQ _ { t }Qt 给出:
dpT−tdt=Q‾T−tpT−tQ‾t(y,x)=pt(y)pt(x)Qt(x,y)Qˉt(x,x)=−∑y≠xQˉt(y,x)(3) \begin{array}{l} \frac {d p _ {T - t}}{d t} = \overline {{Q}} _ {T - t} p _ {T - t} \quad \overline {{Q}} _ {t} (y, x) = \frac {p _ {t} (y)}{p _ {t} (x)} Q _ {t} (x, y) \\ \bar {Q} _ {t} (x, x) = - \sum_ {y \neq x} \bar {Q} _ {t} (y, x) \quad (3) \\ \end{array} dtdpT−t=QT−tpT−tQt(y,x)=pt(x)pt(y)Qt(x,y)Qˉt(x,x)=−∑y=xQˉt(y,x)(3)
此逆向过程类似于典型扩散过程在 Rn\mathbb { R } ^ { n }Rn 上的时间逆转,其中比值 pt(y)pt(x)\begin{array} { r } { p _ { t } ( y ) } \\ { p _ { t } ( x ) } \end{array}pt(y)pt(x) (统称为具体分数(Meng等人,2022))推广了典型的分数函数 ∇xlogpt\nabla _ { \boldsymbol { x } } \log \boldsymbol { p _ { t } }∇xlogpt ∇x\nabla _ { x }∇x (Song与Ermon,2019) 1
2.2. 离散扩散模型
离散扩散模型的进球是,通过学习比值 pt(y)pt(x)\begin{array} { c } { { p _ { t } ( y ) } } \\ { { p _ { t } ( x ) } } \end{array}pt(y)pt(x) 构建前述的逆向过程。与连续扩散的情况不同(该情况已基本围绕分数匹配(Hyv¨arinen,2005)给出的理论框架稳定下来,仅存在微小的缩放变化),目前存在许多相互竞争的方法来学习离散扩散模型。尤其,这些方法往往产生混杂的实证结果,这促使我们有必要对其进行重新审视。
均值预测。 Austin 等人 (2021); Campbell 等人(2022) 没有直接参数化比率 pt(y)pt(x)\begin{array} { c } { { p _ { t } ( y ) } } \\ { { p _ { t } ( x ) } } \end{array}pt(y)pt(x) , 而是遵循 Ho 等人(2020) 的策略来学习反向密度 p0∣t∘p _ { 0 | t _ { \circ } }p0∣t∘ 。这实际上以一种迂回的方式恢复了比率 pt(y)pt(x)\begin{array} { r } { p _ { t } ( y ) } \\ { p _ { t } ( x ) } \end{array}pt(y)pt(x) (如我们的定理 4.2所示),但带来了一些缺点。首先,学习 p0∣tp _ { 0 | t }p0∣t 本质上更困难,因为它是一个密度(而非一个通用值)。此外,该目标在连续时间下会失效,必须进行近似(Campbell 等人,2022)。因此,这个框架在实证上表现大多不佳。
比率匹配。 最初由Hyv¨arinen(2007)提出,并在 Sun等人 (2023)中得到扩充,比率匹配通过最大似然训练学习每个维度的边缘概率。然而,这种设置偏离了标准的分数匹配,需要专门且昂贵的网络架构 (Chen 与Duvenaud,2019)。因此,其性能往往不如均值预测。
具体分数匹配。 Meng 等人(2022) 对分数匹配中标准的 Fisher 散度进行了泛化,通过具体分数匹配进行学习 ∣Sθ(x,t)≈[pt(y)]‾y≠x\displaystyle | _ { S \theta } ( x , t ) \overline { { \approx \left[ p _ { t } ( y ) \right] } } _ { y \neq x }∣Sθ(x,t)≈[pt(y)]y=x pt(x) y̸=x :
LCSM=12Ex∼pt[∑y≠x(sθ(xt,t)y−pt(y)pt(x))2](4) \mathcal {L} _ {\mathrm {C S M}} = \frac {1}{2} \mathbb {E} _ {x \sim p _ {t}} \left[ \sum_ {y \neq x} \left(s _ {\theta} \left(x _ {t}, t\right) _ {y} - \frac {p _ {t} (y)}{p _ {t} (x)}\right) ^ {2} \right] \tag {4} LCSM=21Ex∼pt y=x∑(sθ(xt,t)y−pt(x)pt(y))2 (4)
遗憾的是, ℓ2\ell ^ { 2 }ℓ2 损失与以下事实不兼容: pt(y)pt(x)p _ { t } ( y ) p _ { t } ( x )pt(y)pt(x) 必须为正。具体来说,它未能充分惩罚负值或零值,从而导致发散行为。尽管理论上前景看好,但具体分数匹配在实践中遇到困难(详见附录D)。
3. 分数熵离散扩散模型
在本节中,我们将介绍分数熵。类似于具体分数匹配,我们学习收集到的具体分数
sθ(x,t)≈[pt(y)pt(x)]y≠x(sθ:X×RR∣X∣)∘\begin{array} { r } { s _ { \theta } ( x , t ) \approx [ \frac { p _ { t } ( y ) } { p _ { t } ( x ) } ] _ { y \ne x } ( s _ { \theta } : \mathcal { X } \times \mathbb { R } \mathbb { R } ^ { | \mathcal { X } | ) _ { \circ } } } \end{array}sθ(x,t)≈[pt(x)pt(y)]y=x(sθ:X×RR∣X∣)∘ 。我们设计了分数熵损失,以纳入这些比值为正且在离散扩散下演变的事实。
第003/30页
定义 3.1. 对于分布 ppp 、权重 wxy≥0w _ { x y } \geq 0wxy≥0 和分数网络 sθ(x)ys _ { \theta } ( x ) _ { y }sθ(x)y ,其分数熵 LSE\mathcal { L } _ { \mathrm { S E } }LSE 为
Ex∼p[∑y≠xwxy(sθ(x)y−p(y)p(x)logsθ(x)y+K(p(y)p(x)))](5) \mathbb {E} _ {x \sim p} \left[ \sum_ {y \neq x} w _ {x y} \left(s _ {\theta} (x) _ {y} - \frac {p (y)}{p (x)} \log s _ {\theta} (x) _ {y} + K \left(\frac {p (y)}{p (x)}\right)\right) \right] \tag {5} Ex∼p y=x∑wxy(sθ(x)y−p(x)p(y)logsθ(x)y+K(p(x)p(y))) (5)
其中 K(a)=a(loga−1)K ( a ) = a ( \log a - 1 )K(a)=a(loga−1) 是一个归一化常数函数,确保LSE≥0∘\mathcal { L } _ { \mathrm { S E } } \geq 0 _ { \circ }LSE≥0∘
备注。分数熵并非基于Fisher散度,而是基于Bregman散度 DF(s(x)y,p(y))D _ { F } \left( s ( x ) _ { y } , { p ( y ) } \right)DF(s(x)y,p(y)) ,其中 F=−logF = - \logF=−log 是凸函数。因此,分数熵是非负、对称且凸的。它还将标准交叉熵推广到一般的正值(而非单纯形值的概率),这也是其名称的灵感来源。权重 wxyw _ { x y }wxy 主要用于将分数熵与扩散模型结合时。
虽然这个表达式比标准分数匹配的变体更复杂,但它满足了离散扩散训练目标的几个期望属性:
3.1. 分数熵特性
首先,分数熵是一个合适的损失函数,能够恢复真实的具体分数。
命题 3.2 (分数熵的一致性)。假设 ppp 是完全支撑的且 wxy>0∘w _ { x y } > 0 _ { \circ }wxy>0∘ 当样本数量和模型容量趋近于 ∞\infty∞ 时,最小化方程5的最优θ∗\theta ^ { * }θ∗ 满足 sθ∗(x∗s _ { \theta ^ { * } } ( x _ { * }sθ∗(x∗
Π=Πp(x)p(y){ \bf \Pi } = { \bf \Pi } _ { p ( x ) } ^ { p ( y ) }Π=Πp(x)p(y) 对于所有对 x,yx , yx,y 此外, )LSE) _ { \mathscr { L } _ { \mathrm { S E } } })LSE 在 H^∗\mathcal { \hat { H } } ^ { * }H^∗ 处将是0 。
其次,分数熵通过重新缩放有问题的梯度直接改进了具体分数匹配。对于权重
w ΛγSU=1 ∇sθ(x)yLSE=1sθ(x)y∇sθ(x)yLCSM‾,\begin{array} { r } { \mathrm { \Lambda } _ { \gamma _ { S U } } = 1 \ \nabla _ { s _ { \theta } ( x ) _ { y } } \mathcal { L } _ { \mathrm { S E } } = \frac { 1 } { s _ { \theta } ( x ) _ { y } } \nabla _ { s _ { \theta } ( x ) _ { y } } \mathcal { L } _ { \overline { { \mathrm { C S M } } } , } } \end{array}ΛγSU=1 ∇sθ(x)yLSE=sθ(x)y1∇sθ(x)yLCSM, , 因此每对(x,y)y )y) 的梯度信号被缩放了一个因子 sθ(x)ys _ { \theta } ( x ) _ { y }sθ(x)y 作为归一化分量。因此,这形成了一个天然的对数障碍,保持了我们的 sθ≥0∘s _ { \theta } \geq 0 _ { \circ }sθ≥0∘
第三,与具体分数匹配类似,分数熵可以通过移除未知的 p(y)p(x)\begin{array} { c } { p ( y ) } \\ { p ( x ) } \end{array}p(y)p(x) 项来变得计算上易于处理。有两种替代形式,第一种类似于隐式分数匹配损失(Hyv¨arinen,2005):
命题3.3(隐式分数熵)。 LSE\mathcal { L } _ { \mathrm { S E } }LSE 在除去一个与 θ\thetaθ 无关的常数后,等于隐式分数熵
LISE=Ex∼p[∑y≠xwxysθ(x)y−wyxlogsθ(y)x](6) \mathcal {L} _ {\mathrm {I S E}} = \mathbb {E} _ {x \sim p} \left[ \sum_ {y \neq x} w _ {x y} s _ {\theta} (x) _ {y} - w _ {y x} \log s _ {\theta} (y) _ {x} \right] \tag {6} LISE=Ex∼p y=x∑wxysθ(x)y−wyxlogsθ(y)x (6)
遗憾的是,蒙特卡洛估计需要采样一个 xxx 并评估 sθ(y)xs _ { \theta } ( y ) _ { x }sθ(y)x 对于所有其他 y∘y _ { \circ }y∘ 。在高
维度下,这是难以处理的,这意味着我们必须采样 yyy 均匀分布,但这引入了额外的方差,类似于Hutchinson迹估计器(Hutchinson, 1989)在切片分数匹配(Song等人,2019)中引入的方差。因此,隐式分数熵在大规模任务中是不切实际的。取而代之,我们采用一种去噪分数匹配损失(Vincent, 2011)版本的分数熵:
定理3.4(去噪分数熵)。假设 ppp 是通过转移核 p(⋅∣⋅)p ( \cdot | \cdot )p(⋅∣⋅) 对基础密度 p0p _ { 0 }p0 的扰动,即 p(x)=∑x0p(x∣x0)p0(x0)c\begin{array} { r } { p ( x ) = \sum _ { x _ { 0 } } p ( x | x _ { 0 } ) p _ { 0 } ( x _ { 0 } ) \mathfrak { c } } \end{array}p(x)=∑x0p(x∣x0)p0(x0)c 。分数熵 LSE\mathcal { L } _ { \mathrm { S E } }LSE 等价于(在除去一个与 θ\thetaθ 无关的常数后) 去噪分数熵 LDSE\mathcal { L } _ { \mathrm { D S E } }LDSE :
Ex0∼p0x∼p(⋅∣x0)[∑y≠xwxy(sθ(x)y−p(y∣x0)p(x∣x0)logsθ(x)y)](7) \underset { \begin{array}{c} x _ {0} \sim p _ {0} \\ x \sim p (\cdot | x _ {0}) \end{array} } {\mathbb {E}} \left[ \sum_ {y \neq x} w _ {x y} \left(s _ {\theta} (x) _ {y} - \frac {p (y \mid x _ {0})}{p (x \mid x _ {0})} \log s _ {\theta} (x) _ {y}\right) \right] \tag {7} x0∼p0x∼p(⋅∣x0)E y=x∑wxy(sθ(x)y−p(x∣x0)p(y∣x0)logsθ(x)y) (7)
LDSE\mathcal { L } _ { \mathrm { D S E } }LDSE 是可扩展的,因为蒙特卡洛采样只需要评估一个sθ(x)s _ { \theta } ( x )sθ(x) ,这就能给出所有的 sθ(x)y,s _ { \theta } ( x ) _ { y } ,sθ(x)y, ,而由 x0x _ { 0 }x0 引入的方差是可管理的。此外,它对离散扩散尤其有吸引力,因为中间的 ptp _ { t }pt 都是基础密度 p0p _ { 0 }p0 的扰动(源自方程1和2),使得我们可以利用扩散转移密度 pt∣0(⋅∣x0)p _ { t | 0 } ( \cdot | x _ { 0 } )pt∣0(⋅∣x0) 来训练
3.2. 分数熵离散扩散的似然界
第四,分数熵可用于定义一个证据下界,用于基于似然的训练与评估。
定义3.5. 对于我们的时变分数网络 sθ(⋅,t)s _ { \theta } ( \cdot , t )sθ(⋅,t) ,参数化反向矩阵是通过替换方程3中的真实分数得到的。因此,我们的参数化密度 ptθp _ { t } ^ { \theta }ptθ 满足以下微分方程:
dpT−tθdt=Q‾T−tθpT−tθpTθ=pbase≈pT(8) \frac {d p _ {T - t} ^ {\theta}}{d t} = \overline {{Q}} _ {T - t} ^ {\theta} p _ {T - t} ^ {\theta} \quad p _ {T} ^ {\theta} = p _ {\mathrm {b a s e}} \approx p _ {T} \qquad (8) dtdpT−tθ=QT−tθpT−tθpTθ=pbase≈pT(8)
数据点的对数似然可以利用基于 Dynkin 公式的证据下界来限定(Hanson,2007),该公式在Campbell 等人(2022)中针对离散扩散模型推导出来。有趣的是,其形式为我们的去噪分数熵损失,由前向扩散加权:
定理3.6(似然训练与评估). 对于上述定义的扩散和前向概率,
$$
- \log p _ {0} ^ {\theta} \left(x _ {0}\right) \leq \mathcal {L} _ {\mathrm {D W D S E}} \left(x _ {0}\right) + D _ {K L} \left(p _ {T \mid 0} (\cdot | x _ {0}) | p _ {\text {b a s e}}\right) \tag {9}
$$
其中 LDWDSE(x0)\mathcal { L } _ { \mathrm { D W D S E } } ( x _ { 0 } )LDWDSE(x0) 的扩散加权去噪分数熵是针对数据点x0x _ { 0 }x0
第004/30页
∫0TExt∼pt∣0(⋅∣x0)∑y≠xtQt(xt,y)(sθ(xt,t)y−pt∣0(y∣x0)pt∣0(xt∣x0)logsθ(xt,t)y+K(pt∣0(y∣x0)pt∣0(xt∣x0)))dt(10) \begin{array}{l} \int_ {0} ^ {T} \mathbb {E} _ {x _ {t} \sim p _ {t | 0} (\cdot | x _ {0})} \sum_ {y \neq x _ {t}} Q _ {t} (x _ {t}, y) \left(s _ {\theta} (x _ {t}, t) _ {y} - \right. \\ \left. \frac {p _ {t | 0} (y \mid x _ {0})}{p _ {t | 0} \left(x _ {t} \mid x _ {0}\right)} \log s _ {\theta} \left(x _ {t}, t\right) _ {y} + K \left(\frac {p _ {t | 0} (y \mid x _ {0})}{p _ {t | 0} \left(x _ {t} \mid x _ {0}\right)}\right)\right) d t \tag {10} \\ \end{array} ∫0TExt∼pt∣0(⋅∣x0)∑y=xtQt(xt,y)(sθ(xt,t)y−pt∣0(xt∣x0)pt∣0(y∣x0)logsθ(xt,t)y+K(pt∣0(xt∣x0)pt∣0(y∣x0)))dt(10)
关键在于,这一结果使我们能够直接基于其似然值(以及相关的困惑度分数)来建模,这是语言建模任务的核心度量标准。特别是,我们可以训练和评估一个上界。
备注。 DWDSE(以及其隐式版本)可以从Benton 等人 (2022)的通用框架中推导出来,假设了一种具体分数参数化。特别是,其隐式版本与Campbell 等人(2022)提出的似然损失一致。
3.3. 实际实现
第五, 分数熵可以扩展到高维任务。
在实践中, 我们的状态会分解为序列 X=\begin{array} { r l } { \mathcal { X } } & { { } = } \end{array}X= {1,…,n}d\{ 1 , \ldots , n \} ^ { d }{1,…,n}d 以形成序列x = x1 . . . xd (例如 se-代币序列或图像像素值序列)。作为一种通用 QtQ _ { t }Qt 的指数规模,我们转而选择一种稀疏结构化矩阵,该矩阵通过矩阵 Qttok{ Q } _ { t } ^ { \mathrm { t o k } }Qttok 独立扰动代币。具体来说, QtQ _ { t }Qt 的非零元素由以下公式给出
Qt(x1…xi…xd,x1…x^i…xd)=Qttok(xi,x^i)(11) Q _ {t} \left(x ^ {1} \dots x ^ {i} \dots x ^ {d}, x ^ {1} \dots \widehat {x} ^ {i} \dots x ^ {d}\right) = Q _ {t} ^ {\operatorname {t o k}} \left(x ^ {i}, \widehat {x} ^ {i}\right) \tag {11} Qt(x1…xi…xd,x1…x i…xd)=Qttok(xi,x i)(11)
由于 LDWDSE\mathcal { L } _ { \mathrm { D W D S E } }LDWDSE 通过 Qt(x,y)Q _ { t } ( x , y )Qt(x,y) 加权损失,这种代币级别的转移 QtQ _ { t }Qt 使得大多数比率无关紧要。具体来说,我们只需建模所有汉明距离为1的序列之间的比率,因此我们可以将我们的分数网络sθ(⋅,t):{1,…,n}d→Rd×ns _ { \theta } ( \cdot , t ) : \{ 1 , \dots , n \} ^ { d } \to \mathbb { R } ^ { d \times n }sθ(⋅,t):{1,…,n}d→Rd×n 构建为序列到序列映射:
(sθ(x1…xi…xd,t))i,x^i≈pt(x1…x^i…xd)pt(x1…xi…xd)(12) \left(s _ {\theta} \left(x ^ {1} \dots x ^ {i} \dots x ^ {d}, t\right)\right) _ {i, \widehat {x} ^ {i}} \approx \frac {p _ {t} \left(x ^ {1} \dots \widehat {x} ^ {i} \dots x ^ {d}\right)}{p _ {t} \left(x ^ {1} \dots x ^ {i} \dots x ^ {d}\right)} \tag {12} (sθ(x1…xi…xd,t))i,x i≈pt(x1…xi…xd)pt(x1…x i…xd)(12)
为了完整计算 LDWDSE,我们只需计算前向转移 pt∣0seq(⋅∣⋅)∘p _ { t | 0 } ^ { \mathrm { s e q } } ( \cdot | \cdot ) _ { \circ }pt∣0seq(⋅∣⋅)∘ 幸运的是,由于每个代币被独立扰动,此过程可以分解:
pt∣0seq(x^∣x)=∏i=1dpt∣0tok(x^i∣xi)(13) p _ {t | 0} ^ {\mathrm {s e q}} (\widehat {\mathbf {x}} | \mathbf {x}) = \prod_ {i = 1} ^ {d} p _ {t | 0} ^ {\mathrm {t o k}} \left(\widehat {x} ^ {i} \mid x ^ {i}\right) \tag {13} pt∣0seq(x ∣x)=i=1∏dpt∣0tok(x i∣xi)(13)
对于每个 pt∣0tok(⋅∣⋅)p _ { t | 0 } ^ { \mathrm { t o k } } ( \cdot | \cdot )pt∣0tok(⋅∣⋅) ,我们采用先前讨论的策略,并为噪声水平 σ\sigmaσ 和固定的过渡参数 QtokQ ^ { \mathrm { t o k } }Qtok 设置 Qttok=σ(t)QtokQ _ { t } ^ { \mathrm { t o k } } = \sigma ( t ) Q ^ { \mathrm { t o k } }Qttok=σ(t)Qtok 。这避免了数值积分,因为如果我们将 σ(t)\sigma ( t )σ(t) 定义为累积噪声 ∫0tσ‾(s)ds.\begin{array} { r } { \int _ { 0 } ^ { t } \overline { { \sigma } } ( s ) d s . } \end{array}∫0tσ(s)ds. ,则有:
pt∣0tok(⋅∣x)=x- t h c o l u m n o fexp(σˉ(t)Qtok)(14) p _ {t | 0} ^ {\mathrm {t o k}} (\cdot | x) = x \text {- t h c o l u m n o f} \exp (\bar {\sigma} (t) Q ^ {\mathrm {t o k}}) \tag {14} pt∣0tok(⋅∣x)=x- t h c o l u m n o fexp(σˉ(t)Qtok)(14)
存在一些实际后果,导致大多数 QtokQ ^ { \mathrm { t o k } }Qtok 无法用于大规模实验(例如GPT‑2任务, n=50257)n = 5 0 2 5 7 )n=50257) )。特别是,无法存储所有边权重 Qtok(i,j)Q _ { \mathrm { t o k } } ( i , j )Qtok(i,j) ,因为这需要约20GB GPU内存且访问速度极慢。此外,必须能够计算列 exp(σ(t)⋅Qtok)\exp ( \sigma ( t ) \cdot Q ^ { \mathrm { t o k } } )exp(σ(t)⋅Qtok) 以获取过渡比率,但此过程必须避免矩阵‑矩阵乘法,同样无法存储在内存中。
为避免这些问题,我们遵循先前工作(Austinetal.,2021;Campbell等人, 2022),并采用两种具有特色结构的标准矩阵。它们分别源于考虑全连接图结构以及引入MASK吸收态(类似于BERT语言建模范式(Devlin et al.,2019)):
Qu n i f o r m=[1−N1…111−N…1⋮⋮⋱⋮11…1−N](15) Q ^ {\text {u n i f o r m}} = \left[ \begin{array}{c c c c} 1 - N & 1 & \dots & 1 \\ 1 & 1 - N & \dots & 1 \\ \vdots & \vdots & \ddots & \vdots \\ 1 & 1 & \dots & 1 - N \end{array} \right] \tag {15} Qu n i f o r m= 1−N1⋮111−N⋮1……⋱…11⋮1−N (15)
Qa b s o r b=[−10…000−1…00⋮⋮⋱⋮⋮00…−1011…10](16) Q ^ {\text {a b s o r b}} = \left[ \begin{array}{c c c c c} - 1 & 0 & \dots & 0 & 0 \\ 0 & - 1 & \dots & 0 & 0 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & \dots & - 1 & 0 \\ 1 & 1 & \dots & 1 & 0 \end{array} \right] \tag {16} Qa b s o r b= −10⋮010−1⋮01……⋱……00⋮−1100⋮00 (16)
借助如此结构化的 QQQ ,能够快速且低成本地计算出LDWDSE中的所有数值。因此,我们的训练迭代速度与标准自回归训练大致相当,内存使用量也相近。具体而言,我们的训练算法详述于算法1中。
4. 使用具体分数模拟反向扩散过程
给定我们的分数 sθs _ { \theta }sθ ,我们现在推导出模拟反向扩散过程路径 xt=xt1xt2…xtd∼pt\mathbf { x } _ { t } = x _ { t } ^ { 1 } x _ { t } ^ { 2 } \dots x _ { t } ^ { d } \sim p _ { t }xt=xt1xt2…xtd∼pt 的各种策略。值得注意的是,我们从 sθs _ { \theta }sθ 作为 ptp _ { t }pt 的近似比值获得的额外信息可用于增强采样过程。
4.1. 时间反转策略
为了模拟定义3.5中的扩散过程,有人可能会尝试使用方程2中的欧拉策略。然而,正如Campbell 等人(2022)所指出的,这种方法效率低下,因为 QtseqQ _ { t } ^ { \mathrm { s e q } }Qtseq 的结构只允许每一步修改一个位置。一种自然的替代方案是使用 τ⋅\tau \cdotτ⋅ ‑跳跃(Gillespie,2001),它在每个位置上同时执行欧拉步。具体而言,给定序列 xt\left. \mathbf { x } _ { t } \right.xt ,我们通过从相应的概率中(独立地)采样每个token来构建 xt−Δt\mathbf { x } _ { t - \Delta t }xt−Δt 每个token 1xt−Δti1 x _ { t - \Delta t } ^ { i }1xt−Δti (独立地)从相应的概率中
δxti(xt−Δti)+ΔtQttok(xti,xt−Δti)sθ(xt,t)i,xt−Δti(17) \delta_ {x _ {t} ^ {i}} (x _ {t - \Delta t} ^ {i}) + \Delta t Q _ {t} ^ {\mathrm {t o k}} (x _ {t} ^ {i}, x _ {t - \Delta t} ^ {i}) s _ {\theta} (\mathbf {x} _ {t}, t) _ {i, x _ {t - \Delta t} ^ {i}} \quad (1 7) δxti(xt−Δti)+ΔtQttok(xti,xt−Δti)sθ(xt,t)i,xt−Δti(17)
第005/30页
虽然 τ⋅\tau \cdotτ⋅ ‑跳跃是一种可行的模拟策略,但它忽略了我们的 sθs _ { \theta }sθ 近似真实具体分数这一事实。具体而言,已知所有 pt(y)pt(x)\begin{array} { r } { p _ { t } ( y ) } \\ { p _ { t } ( x ) } \end{array}pt(y)pt(x) 可实现最优去噪,类似于 Tweedie 定理(Efron,2011):
定理 4.1 (离散 Tweedie 定理). 假设 ptp _ { t }pt 遵循扩散ODE dpt=Qpt∘d p _ { t } = Q p _ { t \circ }dpt=Qpt∘ 。那么真实去噪器为
p0∣t(x0∣xt)=(exp(−tQ)[pt(i)pt(xt)]i=1N)x0exp(tQ)(xt,x0)(18) p _ {0 \mid t} \left(x _ {0} \mid x _ {t}\right) = \left(\exp (- t Q) \left[ \frac {p _ {t} (i)}{p _ {t} \left(x _ {t}\right)} \right] _ {i = 1} ^ {N}\right) _ {x _ {0}} \exp (t Q) \left(x _ {t}, x _ {0}\right) \tag {18} p0∣t(x0∣xt)=(exp(−tQ)[pt(xt)pt(i)]i=1N)x0exp(tQ)(xt,x0)(18)
遗憾的是,我们并不知道所有的比率(只知道汉明距离为1的序列间的比率)。然而,我们可以利用这一直觉来构建一个 τ\tauτ ‑leaping 的Tweedie去噪器类比。具体而言,我们将令牌转移概率(针对 xt−Δti)x _ { t - \Delta t } ^ { i } )xt−Δti) )替换为以下值
(exp(−σtΔtQ)sθ(xt,t)i)xt−Δtiexp(σtΔtQ)(xti,xt−Δti)(19) \left(\exp \left(- \sigma_ {t} ^ {\Delta t} Q\right) s _ {\theta} \left(\mathbf {x} _ {t}, t\right) _ {i}\right) _ {x _ {t - \Delta t} ^ {i}} \exp \left(\sigma_ {t} ^ {\Delta t} Q\right) \left(x _ {t} ^ {i}, x _ {t - \Delta t} ^ {i}\right) \tag {19} (exp(−σtΔtQ)sθ(xt,t)i)xt−Δtiexp(σtΔtQ)(xti,xt−Δti)(19)
w h e r eσtΔt=(σˉ(t)−σˉ(t−Δt))(20) \text {w h e r e} \sigma_ {t} ^ {\Delta t} = (\bar {\sigma} (t) - \bar {\sigma} (t - \Delta t)) \tag {20} w h e r eσtΔt=(σˉ(t)−σˉ(t−Δt))(20)
这推广了该定理,但强制了tau‑leaping独立性条件,并且实际上是最优的:
定理 4.2 (Tweedie τ⋅\tau \cdotτ⋅ ‑leaping). 令 pt−Δtttweedie(xt−Δt∣xt)p _ { t - \Delta t t } ^ { \mathrm { t w e e d i e } } ( \mathbf { x } _ { t - \Delta t } \vert \mathbf { x } _ { t } )pt−Δtttweedie(xt−Δt∣xt) 为由方程19定义的令牌更新规则的概率。假设 sθs _ { \theta }sθ 已被完美学习,则对于所有 τ\tauτ -leaping策略(即令牌转换被独立且同时应用),这能最小化与真实逆向 的KL散度。
这些仿真算法在算法2中统一呈现。
4.2. 任意提示与填充
我们的具体分数也可用于实现对生成过程的更精细控制。这是因为我们所建模的是概率的函数,允许我们通过贝叶斯规则纳入条件信息。具体而言,我们考虑填充问题
pt(xΩ∣xΩ‾=y)Ωu n f i l l e d i n c i e sΩ‾f i l l e d(21) p _ {t} \left(\mathbf {x} ^ {\Omega} \mid \mathbf {x} ^ {\overline {{\Omega}}} = \mathbf {y}\right) \quad \Omega \text {u n f i l l e d i n c i e s} \quad \overline {{\Omega}} \text {f i l l e d} \tag {21} pt(xΩ∣xΩ=y)Ωu n f i l l e d i n c i e sΩf i l l e d(21)
例如,标准的自回归条件生成将满足 Ω={1,2,…,c}\Omega = \{ 1 , 2 , \ldots , c \}Ω={1,2,…,c} 和 Ω={c+1,c+2…d}.\Omega = \{ c + 1 , c + 2 \ldots d \} .Ω={c+1,c+2…d}. ,。根据贝叶斯规则,条件分数可以从无条件分数精确恢复。
pt(xΩ=z′∣xΩ‾=y)pt(xΩ=z∣xΩ‾=y)=pt(x=z′⊕Ωy)pt(x=z⊕Ωy)(22) \frac {p _ {t} \left(\mathbf {x} ^ {\Omega} = \mathbf {z} ^ {\prime} \mid \mathbf {x} ^ {\overline {{\Omega}}} = \mathbf {y}\right)}{p _ {t} \left(\mathbf {x} ^ {\Omega} = \mathbf {z} \mid \mathbf {x} ^ {\overline {{\Omega}}} = \mathbf {y}\right)} = \frac {p _ {t} \left(\mathbf {x} = \mathbf {z} ^ {\prime} \oplus_ {\Omega} \mathbf {y}\right)}{p _ {t} \left(\mathbf {x} = \mathbf {z} \oplus_ {\Omega} \mathbf {y}\right)} \tag {22} pt(xΩ=z∣xΩ=y)pt(xΩ=z′∣xΩ=y)=pt(x=z⊕Ωy)pt(x=z′⊕Ωy)(22)
其中 ⊕Ω\oplus _ { \Omega }⊕Ω 沿 Ω\OmegaΩ 和 Ω\OmegaΩ 进行拼接。由于无条件与条件分数一致,我们可以使用我们的 sθs _ { \theta }sθ (通过无条件学习获得)进行条件采样(给定任意 Ω\OmegaΩ )。对于一个 τ\tauτ 跳步更新规则(方程 17 或19),只需通过改变在 Ω处的值来修改。其具体伪代码在算法 3中给出。
5. 实验
我们现在通过实验验证我们的分数熵离散扩散(SEDD)模型在各种语言建模任务上的表现。我们同时测量困惑度(即似然估计能力)和生成质量,发现我们的方法在两方面都表现得相当好。
5.1. 模型与训练设置
我们的核心模型基于扩散Transformer架构(Peebles& Xie, 2023),它将时间条件融入标准仅编码器Transformer架构(Vaswani et al., 2017;Devlin etal.,2019),但我们进行了一些细微修改,例如采用旋转位置编码(Su et al.,2021)。
我们构建了SEDD Absorb和SEDD Uniform,它们分别对应矩阵 Quniform 和 QabsorbQ ^ { \mathrm { a b s o r b } }Qabsorb 。我们测试了几何噪声调度(在 10−51 0 ^ { - 5 }10−5 和20之间插值),以及对数线性噪声调度(总噪声 σ(t)\sigma ( t )σ(t) 对应的代币更改数对于两种跃迁大约为 td ),这有助于提升SEDD Absorb的困惑度。除此之外,我们没有系统地探索噪声调度或替代的损失权重设定,尽管这些方法很可能能改善生成质量。
训练时,我们采用句子打包来创建统一长度的区块以供模型处理,这在语言建模任务中通常是标准做法。此规则的唯一例外是我们对text8的实验,它随机采样连续子序列以匹配先前工作(Austinet al.,2021)(尽管我们发现这并未显著改变结果)。我们同样匹配了先前工作的架构超参数(包括层数、隐藏维度、注意力头数等…),尽管我们的模型由于时间条件比典型的Transformer参数稍多( ≈5−10%\approx 5 - 1 0 \%≈5−10% )。我们也使用与先前工作相同的分词器(否则可能成为产生伪影的来源)以及相同的数据分割。
5.2. 语言建模对比
我们首先通过在三个常见数据集上,针对多种规模的核心语言建模(本质上是基于似然的建模)来评估我们的模型。
5.2.1. TEXT 8 数据集
我们比较了 text8 数据集,这是一个小型字符级语言建模任务。我们遵循Austin 等人(2021)的网络超参数和数据集划分方式,并与采用类似模型规模的 方法 进行比较。
我们在表2中报告了每字符比特数(BPC)。SEDD超越了其他非自回归模型,仅被自回归Transformer和离散流(该模型
第006/30页
表1:多种数据集上的↓零样本无条件困惑度。对于固定规模,最佳困惑度以粗体标出。我们的Radford etal.,2019)在多数任务上优于GPT‑2,并完全超越了先前的Austin et al.,2021;Gulrajani与Hashimoto,2023)。
| Size | 模型 | LAMBADA | WikiText2 | PTB | WikiText103 | 1BW |
| 小型 | GPT-2 | 45.04 | 42.43 | 138.43 | 41.60 | 75.20 |
| SEDD Absorb | ≤50.92 | ≤41.84 | ≤114.24 | ≤40.62 | ≤79.29 | |
| SEDD Uniform | ≤65.40 | ≤50.27 | ≤140.12 | ≤49.60 | ≤101.37 | |
| D3PM | ≤93.47 | ≤77.28 | ≤200.82 | ≤75.16 | ≤138.92 | |
| PLAID | ≤57.28 | ≤51.80 | ≤142.60 | ≤50.86 | ≤91.12 | |
| 普通 | GPT-2 | 35.66 | 31.80 | 123.14 | 31.39 | 55.72 |
| SEDD Absorb | ≤42.77 | ≤31.04 | ≤87.12 | ≤29.98 | ≤61.19 | |
| SEDD Uniform | ≤51.28 | ≤38.93 | ≤102.28 | ≤36.81 | ≤79.12 |
表2:text8上的每字符比特数。我们的SEDD模型取得了总体第二好的结果(非自回归模型中最优),仅以微弱差距落后于自回归模型以及一种使用自回归模型作为骨干的离散流模型。SEDD也显著改进了先前的离散扩散模型D3PM(Austinet al.,2021) 。
| Type | 方法 | BPC (↓) |
| 自回归骨干网络 | IAF/SCF | 1.88 |
| AR Argmax Flow | 1.39 | |
| 离散流 | 1.23 | |
| 自回归 | 1.23 | |
| 非自回归 | Mult. Diffusion | ≤ 1.72 |
| MAC | ≤ 1.40 | |
| BFN | ≤ 1.41 | |
| D3PM Uniform | ≤ 1.61 | |
| D3PM Absorb | ≤ 1.45 | |
| Ours (NAR) | SEDD Uniform | ≤ 1.47 |
| SEDD Absorb | ≤ 1.39 |
融合了自回归基础分布)(Tran等人,2019)。此外,尽管两者都基于相同的离散扩散原理构建,但SEDD相较于D3PM(Austin等人, 2021)有显著提升。
5.2.2. ONE BILLION WORDS数据集
我们也在One Billion Words数据集上测试了SEDD,这是一个规模更适中、更贴近现实世界的数据集。我们遵循Heetal.(2022)的分词、训练和模型规模配置。具体而言,我们的基线模型规模大致与GPT‑2 Small相当。遵循Heet al.(2022),我们主要与其他语言扩散模型进行比较,但我们也训练了一个标准的自回归Transformer作为基准。
我们在表3中报告困惑度值。我们的SEDD模型以50-75%更低的困惑度(特别是相对于D3PM)优于所有其他扩散语言建模方案。此外,SEDD与自回归模型的困惑度差值在1 以内,很可能匹配,因为我们只报告了上界。
表3:在One Billion Words数据集上的测试困惑度。自回归结果是精确似然,而扩散结果是上界。SEDD在匹配自回归基准的同时,超越了所有其他离散扩散模型(至少高出 2×)2 \times )2×) )。
| Type | 方法 | 困惑度(↓) |
| 自回归 | Transformer | 31.98 |
| 扩散 | D3PM Absorb | ≤77.50 |
| Diffusion-LM | ≤118.62 | |
| BERT-Mouth | ≤142.89 | |
| DiffusionBert | ≤63.78 | |
| Ours(扩散) | SEDD Uniform | ≤40.25 |
| SEDD Absorb | ≤32.79 |
5.2.3. GPT‑2 零样本任务
最后,我们将SEDD与GPT‑2(Radford等人,2019)进行比较。我们在OpenWebText上进行训练,因为原始的WebText数据集尚未公开(这是典型做法,在实践中不会显著影响结果)(Gokaslan &Cohen, 2019),并在LAMBADA、WikiText2、PTB、WikiText103和One Billion Words数据集(这些是所有测量困惑度的GPT‑2零样本任务)上进行测试。我们重新计算了除1BW外所有数据集的基线似然,因为我们在公共实现中遇到了意外行为。我们的似然计算方式与原设置不同,因为我们无条件评估(即不使用滑动窗口),这导致结果高于最初报告的值。
我们的结果呈现在表1中。我们的 SEDD Absorb 在两种规模下的大部分零样本任务上都超越了 GPT‑2。据我们所知,这是首次有非自回归语言模型在困惑度方面与现代、规模合理且知名的自回归模型相匹敌。我们还与最具竞争力的连续扩散基线(Gulrajani与Hashimoto,2023)和离散扩散基线(Austin et al.,2021)进行了对比,观察到对两者均有大幅提升。
第007/30页
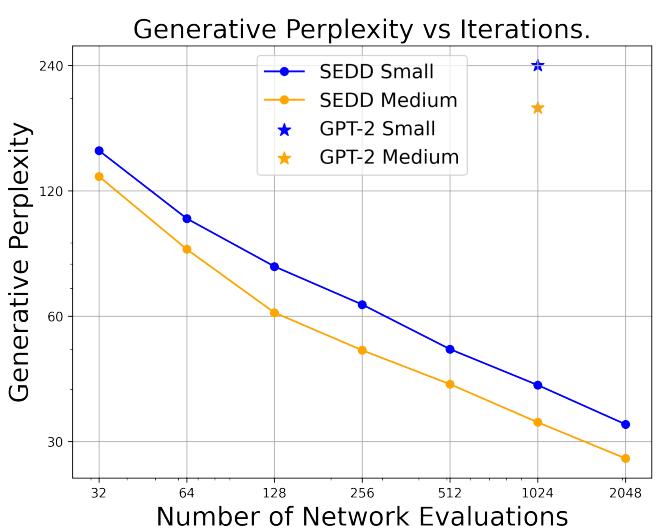
图1:无条件生成文本的质量评估。我们通过解析生成序列的困惑度来比较SEDD和GPT‑2。我们的SEDD模型始终优于GPT‑2,在 32×3 2 \times32× 加速和 6−8×6 { - } 8 \times6−8× 改进之间根据所选步长进行插值。生成文本反映了这一改进的生成能力,因为我们的样本在连贯性上远胜。更多样本和消融分析可参见附录D.3
(a) 生成困惑度 (↓) 与采样迭代次数。
(b) 生成文本(小型模型)
| S GPT-2 | 请愿人Fredericks表示,这是一个“包含趣味俱乐部聚会场所”的招聘平台。其旁边是一家大麻啤酒花店。其他人则允许3B Entertainment |
| N GPT-2 | 被滥用,无论是通过优步、量化冲动的更高阶现实还是无大众瘫痪运动,但最可耻且普遍的例子是僵局 |
| S SEDD S | 正如Jeff Romer最近写道:“经济现已陷入困境——64%的家庭财富和80%的财富因政府紧缩政策而流向信用卡”。 |
| M SEDD M | Wyman曾担任计算机科学教练,后在2010年于纽约州北部加入美国特勤局工作。若无许可证,特勤局将不得不 |
5.3. 语言生成比较
使用我们训练好的模型,我们在生成质量方面与先前工作进行比较。特别是,我们将 GPT‑2 与我们的 SEDD Absorb在多种规模下进行比较。SEDD Uniform 的结果见附录D。
5.3.1. 无条件生成
我们首先比较GPT‑2与SEDD的无条件样本质量。由于大多数语言指标旨在比较条件生成(Pillutla等人,2021),我们转而衡量采样序列的生成困惑度(使用GPT‑2 large模型进行评估)。这是一个简单且常用的指标(Han等人,2022;Dieleman等人,2022),但容易被简单的分布退火方法“破解”。因此,我们比较分析性采样生成(即无温度缩放)。
对于SEDD,我们模拟使用32至2048步数,这能以最小误差近似学习分布,适用于大量步数(序列长度为1024)。我们的结果(包括测量的生成困惑度和部分样本)如图1所示。SEDD在 32×3 2 \times32× 较少网络评估的情况下达到GPT‑2质量,并在使用完整的2048步数时表现优于 6−8×6 { - } 8 \times6−8× 。此外,SEDD在采样步数与生成困惑度之间形成了一条可预测的对数线性帕累托前沿。然而,由于KV缓存的存在,每次网络评估都有不同,这引入了成本效益权衡,我们将在第6节进一步讨论。
5.3.2. 填充式条件生成
最后,我们展示了SEDD的条件生成能力。我们基于固定量的输入文本(来自WebText数据集)生成样本,并比较它们的MAUVE分数(Pillutla等人,2021)对于SEDD,我们考虑两种提示策略:给定开头的标准生成,以及使用开头和结尾进行填充,尽管显然还存在更多采样策略(其中几种在表4中可视化展示)。
我们与GPT‑2和SSD‑LM(Han等人,2022)进行比较,后者是为此任务构建的一个竞争性语言扩散模型(所有模型均为普通规模)。有趣的是,两个基线方法的关键组件都是分布退火:自回归模型的核采样(Holtzman等人,2019)(它裁剪了令牌概率)以及扩散模型的阈值化(Li等人,2022;Lou与Ermon,2023)(它约束生成,禁止在低概率空间中生成路径)。由于为SEDD引入类似的退火方法超出了本文范围,我们与经过退火和未经退火的基线样本进行比较。
我们的实验结果见表5。SEDD与两个基线的最佳配置相比极具竞争力,事实上在使用标准提示时优于两者。这一点相当值得注意,因为SEDD不使用分布退火,也没有将左到右提示作为架构上的归纳偏置进行显式编码(而GPT‑2和SSD‑LM是专门为类似自回归的生成而训练的)。
第008/30页
表 4:条件性生成文本。提示代币以蓝色标出。我们的模型能够生成有意义的文本,无论提示代币位于开头、结尾、中间,甚至是分散的。更多样本见附录D.3。
| 琴弓和箭是一种传统的武器,能让攻击者在一米或两米范围内攻击目标。它们的射程远超人类步行距离,且可以发射…… |
| …跳伞是一项有趣的运动这让我感到无比滑稽。我想我可能花了太多钱,但它本来可能非常棒!虽然跳伞给我们带来锻炼和乐趣,水肺潜水是一种体能锻炼的行为,… |
| …没有人预料到结果会比去年一边倒的认可要好得多。近90%的结果被调查为“独立”,这对全国范围内的学校儿童来说是一个令人鼓舞的成果。 |
| …结果显示唐纳德·特朗普和希拉里·克林顿在38个州的总票数低于全国票数的1%。某种程度上,正是唐纳德·特朗普和希拉里·克林顿会加班加点让人们为此投票… |
表5:条件生成文本的评估。SEDD使用标准提示超越了GPT‑2和SSD‑LM。SEDD还提供了更大的灵活性(能够进行填充生成并保持相当的性能),并且不需要分布退火技术以获得良好的生成结果。
| 方法 | 退火 | Mauve (↑) |
| GPT-2 | Nucleus-0.95 | 0.955 |
| None | 0.802 | |
| SSD-LM | Logit阈值-0.95 | 0.919 |
| None | 0.312 | |
| SEDD标准 | None | 0.957 |
| SEDD填充 | None | 0.942 |
6. 相关工作
离散扩散模型。 大多数离散扩散工作遵循D3PM (Austin etal.,2021) 设定的框架,该框架模仿“均值预测” (Ho et al., 2020)。这些离散扩散方法目前主要应用于语言以外的领域。
(例如图像),可能是由于实证方面的挑战。尽管如此,一些工作在语言方面已展现出强大的性能,特别是在序列到序列任务和更高效的生成方面 (Zheng等人,2023;Chen等人,2023; Ye等人, 2023)。值得注意的是,在这些工作中,离散扩散在减少网络评估方面往往比连续扩散更具优势。
SEDD 与先前工作的对比。SEDD 是一种专注于分数匹配的离散扩散模型,这是连续扩散的关键要素(Song与Ermon,2019;Ho 等人,2020)。许多此类工作也对焦于逆转离散扩散过程(Campbell 等人,2022;Benton 等人,2022;Sun 等人,2023),因此分数熵自然与先前训练目标相关。然而,SEDD 专注于一个原则性、可扩展且高性能的目标(即去噪分数熵),弥补了先前工作中的不足。具体来说,先前方法要么使用隐式分数熵的等效形式进行训练(该形式难以处理且方差高),要么提出替代损失函数,但存在其他问题。这些关键差异使得在语言任务上取得了显著改进,而先前的离散扩散模型在这些任务上明显表现不佳。
此外,SEDD 取得的结果(在困惑度和生成方面)甚至优于连续扩散模型(且无需依赖经验驱动的启发式方法)。这是理想的,因为离散数据理应需要一种新颖的方法。未来工作可以借鉴连续扩散的经验设计,进一步提升性能。
最后,SEDD向自回归模型提出了挑战,在困惑度(优于GPT‑2)和生成质量(优于核采样)方面取得了具有竞争力的表现。虽然与现代大语言模型相比仍有较大差距,但我们相信未来的研究工作可以以SEDD为基础,弥合这一差距。
SEDD 与自回归采样迭代次数对比。SEDD 和自回归模型由于为标准的仅解码器Transformer模型引入了KV缓存,其采样流程存在显著差异。具体而言,这使得推理代码变得复杂(因为每次网络传递都从标准的全批量前向传播变为其他形式),并且牺牲了
第009/30页
速度以换取内存。例如,在我们的(已知)未经优化的代码库和现有的Hugging Face Transformers库(Wolf等人,2020)中,我们观察到,SEDD在使用约100步时与自回归推理时间相当,但通过移除KV缓存内存,可以将批量大小大致增加 4−6倍。未来的工作有望减少最优生成所需的步数(类似于标准扩散中的现有研究(Song等人, 2021a)),从而改善这种权衡。
7. 结论
我们介绍了分数熵离散扩散(SEDD)模型,这是一种由具体分数参数化的离散扩散模型,并能通过我们新颖的分数熵损失高效训练。SEDD在困惑度和质量上超越了以往的语言扩散模型,并与自回归模型媲美。我们希望未来的工作能在我们的框架基础上,定义现代自回归语言建模范式的替代方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)