山东大学软件学院创新项目实训记录 —— 基于UE与LLM的医患沟通模拟与评价系统(二)
前言
本项目研发面向医学教育的医患沟通模拟与评价系统,基于大模型实现智能交互、个性化病例模拟和评分,为医学生提供沉浸式医患沟通实训场景,解决线下标准化病人资源稀缺的问题,提升医学生医患沟通实操能力。本人负责UE5前端工作,语音输入、语音输出功能的制作、UI面板的搭建(主场景、SEGUE评分面板、聊天框等)。本周进行的工作为语音输入功能的技术方案重构、前后端联调以及UI面板的完善。
在上周的工作中,我们采用了自定义插件进行语音输入功能的实现,在这两周内,我们摆正了语音输入功能的实现方向,改用audio capture捕获声音,将其保存至本地,再由python后端读取并处理音频文件,whisper转录生成文本,实现可控、可扩展的语音转文字的功能。
一、语音输入按钮的UI集成与蓝图逻辑搭建
使用UE5内置Audio Capture插件,点击语音输入按钮开始录音,松开按钮结束录音,并将音频文件捕获保存至本地指定路径。通过自定义插件,实现功能Read File To Byte Array将音频文件(.wav)转换成二进制数组传输至python后端等待下一步处理。

#pragma once
#include "CoreMinimal.h"
#include "Kismet/BlueprintFunctionLibrary.h"
#include "MyFileLibrary.generated.h"
UCLASS()
class MYPROJECT_API UMyFileLibrary : public UBlueprintFunctionLibrary
{
GENERATED_BODY()
public:
// 这个节点可以在蓝图中直接搜索 "Read File to Byte Array"
UFUNCTION(BlueprintCallable, Category = "FileIO")
static bool ReadFileToByteArray(FString FilePath, TArray<uint8>& Data);
};
#include "MyFileLibrary.h"
#include "Misc/FileHelper.h"
bool UMyFileLibrary::ReadFileToByteArray(FString FilePath, TArray<uint8>& Data)
{
return FFileHelper::LoadFileToArray(Data, *FilePath);
}二、python后端读取音频并输出文字内容
1.接口设计与实现
后端使用FastAPI框架,定义路由/voice接收前端传来的本地路径。
@router.post("/voice")
async def voice(request_data: AudioPathRequest):
audio_path = request_data.file_path
print(f"收到请求,准备读取本地文件: {audio_path}")
if not os.path.exists(audio_path):
raise HTTPException(status_code=404, detail=f"文件不存在: {audio_path}")
try:
import soundfile as sf
data, sr = sf.read(audio_path)
print(f"soundfile 读取成功,采样率={sr}, 时长={len(data)/sr:.2f}s")
except Exception as e:
print(f"soundfile 读取失败: {e}")
try:
result = model.transcribe(audio_path, fp16=False)
return {"text": result["text"]}
except Exception as e:
print("转录报错,详细堆栈:")
traceback.print_exc()
raise HTTPException(status_code=500, detail=f"文件转录失败: {str(e)}")2.测试文件传输以及转文字效果
前端将文件地址传送至后端,在安静环境下,whisper对医学术语识别较为准确,中英文均可识别,但响应时间还有待改进。
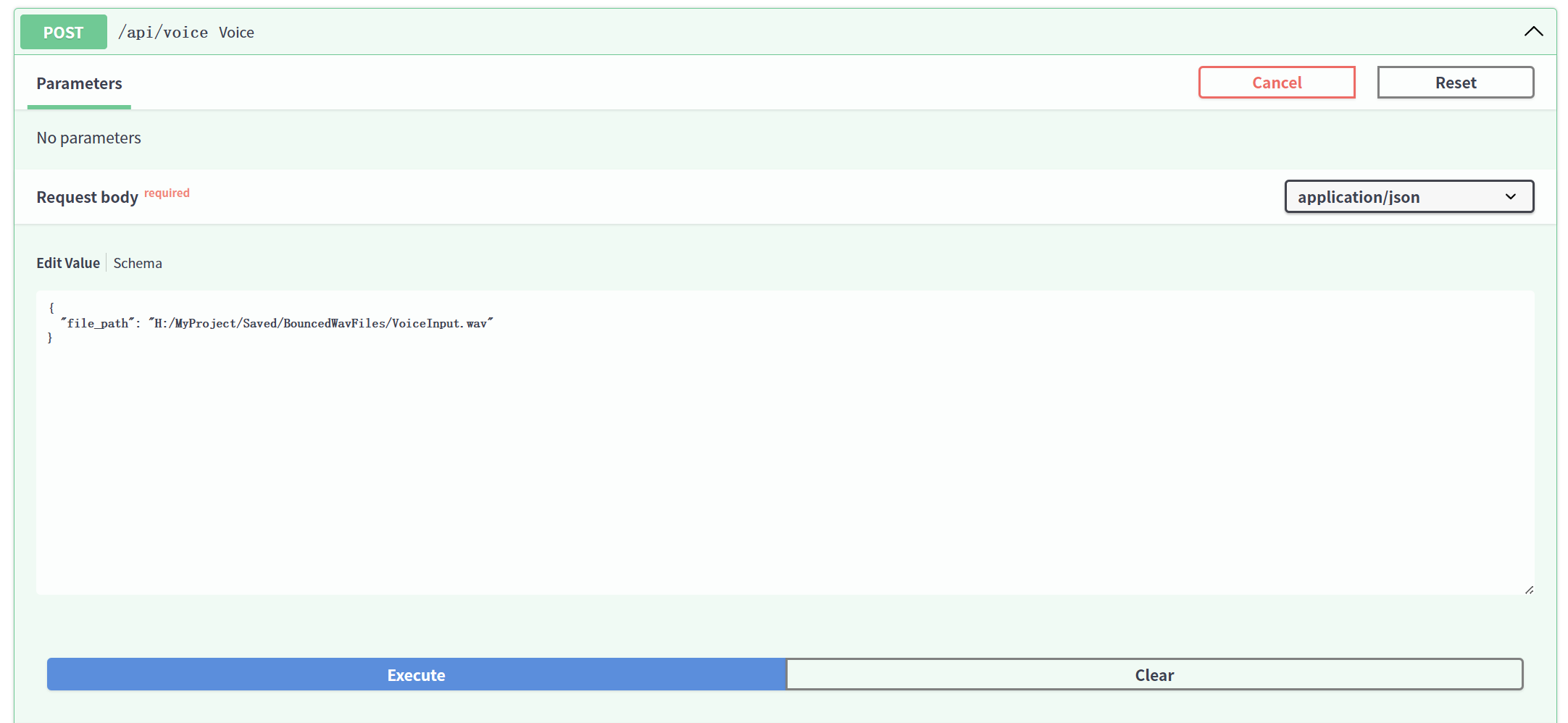
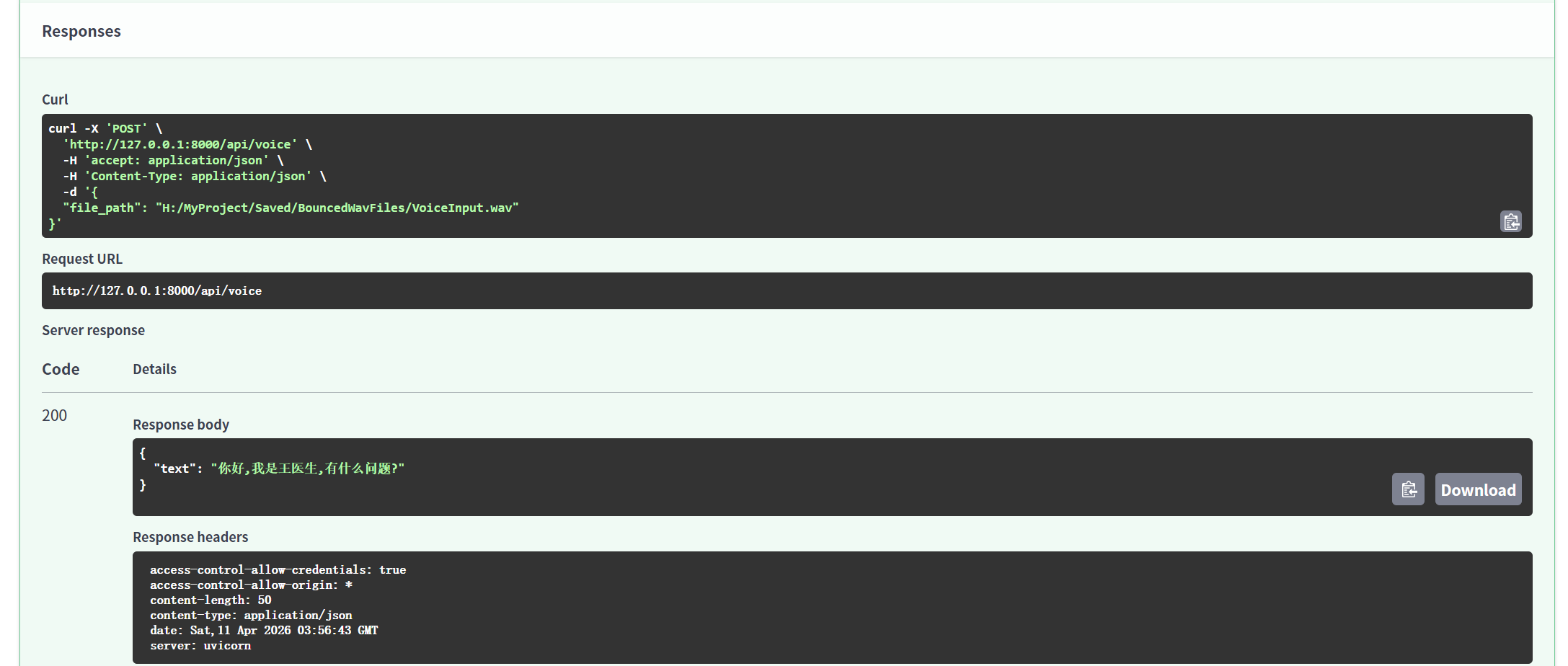
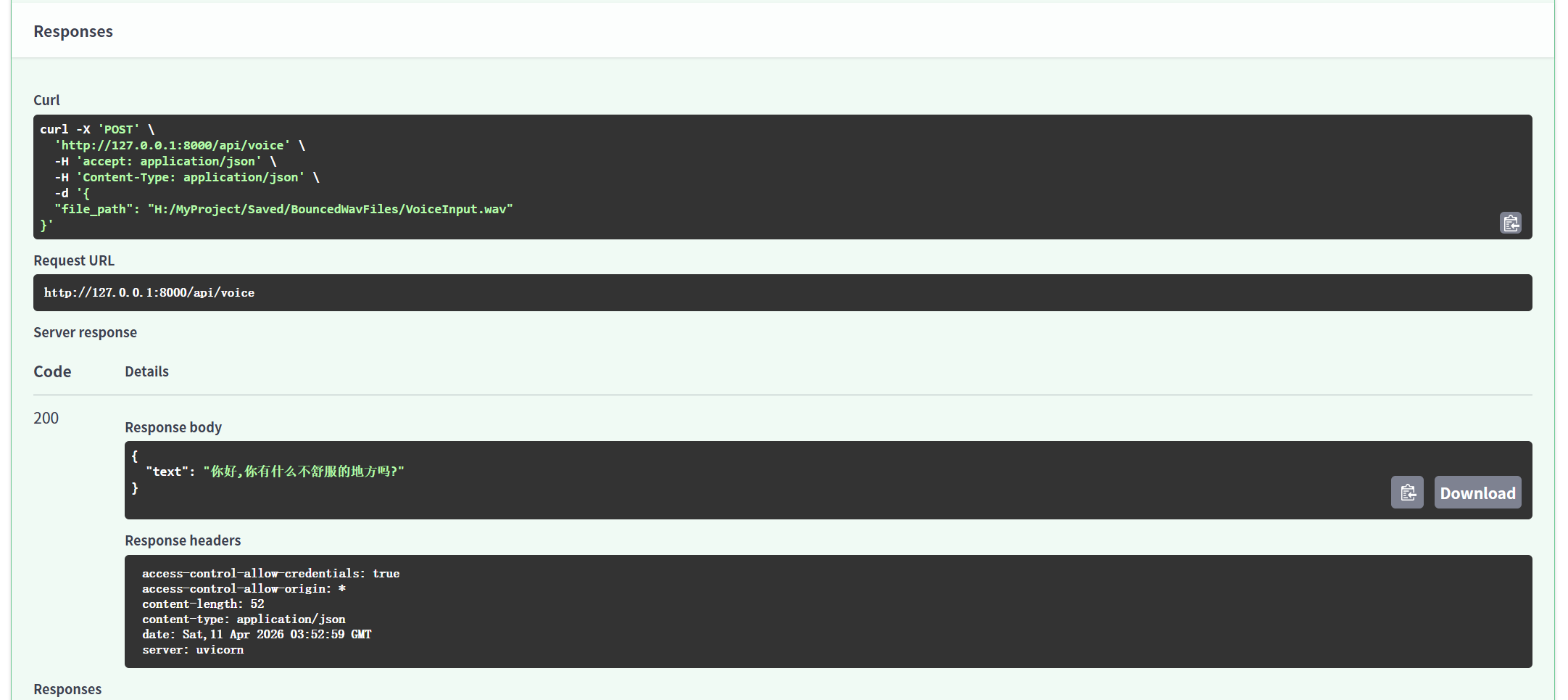
3.前后端联调中的关键问题与解决
3.1 JSON转义错误(Invalid escape)
前端通过HTTP发送路径时,后端反复返回JSON decode error,定位到路径中的反斜杠\被JSON解析器视为非法转义字符。解决方案:在前端蓝图中使用“Replace”节点将\统一替换为/,同时后端增加路径规范化函数,最终彻底解决。
3.2 Whisper无法加载音频(ffmpeg缺失)
后端日志显示subprocess.CalledProcessError,手动执行ffmpeg -version无输出。确定系统未安装ffmpeg。下载64位ffmpeg并配置环境变量,重启后端后恢复正常。此过程涉及多个版本的尝试(静态编译版、conda安装),最终选用gyan.dev版本。
3.3 文件被占用导致读取失败
录音保存后立即发送请求,偶发PermissionError。通过前端增加200ms延迟、后端增加重试机制(3次,间隔0.1秒)双重保障,便不会出现文件被占用导致读取失败的情况。
三、UI界面全面优化
在UI层面,本周对主场景、聊天框、SEGUE评分按钮进行了系统性的优化。主场景将聊天框区域简化至横条,并附有提示词;聊天框功能得到增强:实现语音转文字和文本输入两种输入方式;右侧集中放置按钮,左侧则显示患者数字人和评分面板,提升了信息层次感。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)