Diffusion-离散扩散-202107-D3PM01:在离散状态空间的结构化去噪扩散模型(离散扩散模型的总源头论文之一)
摘要
Denoising diffusion probabilistic models (DDPMs) [19] have shown impressive results on image and waveform generation in continuous state spaces.
去噪扩散概率模型(DDPMs)[19] 在连续状态空间中的图像和波形生成任务上已经展现出令人瞩目的效果。
Here, we introduce Discrete Denoising Diffusion Probabilistic Models (D3PMs), diffusionlike generative models for discrete data that generalize the multinomial diffusion model of Hoogeboom et al. [20], by going beyond corruption processes with uniform transition probabilities.
在此,我们提出离散去噪扩散概率模型(Discrete Denoising Diffusion Probabilistic Models / D3PMs),这是一类面向离散数据的、类似扩散的生成模型;它通过突破具有均匀转移概率的损坏过程,将 Hoogeboom 等人 [20] 的多项式扩散模型加以推广。
This includes
- corruption with transition matrices that mimic Gaussian kernels in continuous space,
- matrices based on nearest neighbors in embedding space,
- and matrices that introduce absorbing states.
这包括:
- 使用在连续空间中模拟高斯核的转移矩阵进行损坏、
- 基于嵌入空间中最近邻的矩阵进行损坏,
- 以及引入吸收状态的矩阵进行损坏。
The third allows us to draw a connection between diffusion models and autoregressive and mask-based generative models.
第三种方式使我们能够建立扩散模型与自回归生成模型以及基于掩码的生成模型之间的联系。
We show that the choice of transition matrix is an important design decision that leads to improved results in image and text domains.
我们表明,转移矩阵的选择是一项重要的设计决策,它能够在图像和文本领域带来更优的结果。
We also introduce a new loss function that combines the variational lower bound with an auxiliary cross entropy loss.
我们还引入了一种新的损失函数,将变分下界与辅助交叉熵损失结合起来。
For text, this model class achieves strong results on character-level text generation while scaling to large vocabularies on LM1B.
在文本任务上,这一类模型在字符级文本生成方面取得了强劲的结果,同时还能在 LM1B 上扩展到大规模词表。
On the image dataset CIFAR-10, our models approach the sample quality and exceed the log-likelihood of the continuous-space DDPM model.
在图像数据集 CIFAR-10 上,我们的模型在样本质量上接近连续空间 DDPM 模型,并且在对数似然上超过了该模型。
1 引言
生成建模是机器学习中的一个核心问题,既可用于评估我们捕捉自然数据集统计特性的能力,也可用于需要生成图像、文本和语音波形等高维数据的下游应用。
随着诸如GANs [15, 4],VAEs [25, 35], 大型自回归神经网络模型 [51, 50, 52], 标准化流 [34, 12, 24, 32],以及其他方法的开发,取得了大量进展,每种方法在样本质量、采样速度、对数似然以及训练稳定性方面都有各自的权衡取舍。
最近,扩散模型[43]已成为图像 [19,46]和音频[7,26]生成领域的一个引人注目的替代方案,在较少的推理步数下,实现了与GANs相当的样本质量以及与自回归模型相当的对数似然。
扩散模型是一种参数化的马尔可夫链,训练用于逆转一个预定义的前向过程,该过程是一个随机过程,旨在将训练数据逐步破坏为纯噪声。
扩散模型使用一个与最大似然和分数匹配密切相关的稳定目标进行训练[21, 53],并且通过采用并行迭代细化[30, 45, 47,44],其采样速度比自回归模型更快。
Although diffusion models have been proposed in both discrete and continuous state spaces [43], most recent work has focused on Gaussian diffusion processes that operate in continuous state spaces (e.g. for real-valued image and waveform data).
尽管扩散模型已经在离散和连续状态空间中均有提出 [43],但近期的大多数研究主要聚焦于在连续状态空间中运行的高斯扩散过程(例如用于实值图像和波形数据)。
Diffusion models with discrete state spaces have been explored for text and image segmentation domains [20], but they have not yet been demonstrated as a competitive model class for large scale text or image generation.
具有离散状态空间的扩散模型已经在文本和图像分割领域得到探索 [20],但它们尚未被证明是在大规模文本或图像生成任务中具有竞争力的一类模型。
第002/33页

图 1:应用于量化瑞士卷数据的 D3PM 前向过程与(学习得到的)反向过程。每个点表示一个二维类别变量。
- 上:均匀、离散化高斯以及吸收状态 D3PM 模型的前向过程样本,以及对应的转移矩阵 Q。
- 下:学习得到的离散化高斯反向过程的样本。

Figure 1 前向过程(第一行图片)解释【比较三种不同的前向“破坏机制”】
Figure 1 的第一行展示的是 D3PM 的前向过程,也就是论文里记作 q(xt∣xt−1)q(x_t \mid x_{t-1})q(xt∣xt−1) 的部分。你可以把它理解成:从原始离散数据出发,按照某种预设的“加噪/破坏规则”,一步步把有结构的数据变得越来越混乱。
下面我按第一行从左到右详细解释。
1.1. 最左边:data sample at t=0
这张图表示 初始数据样本,也就是 ( t=0 ) 时的数据。
图中是一个 quantized swiss roll(量化后的瑞士卷)。
“swiss roll”本来是二维空间里一种螺旋状分布;“quantized”表示它已经被离散化了,所以图上的每个点不是连续实数点,而是落在离散网格上的类别状态。
这张图想说明:
- 每个小点对应一个 二维类别变量。
- 在 ( t=0 ) 时,数据具有非常明显的结构:点组成了清晰的螺旋形。
- 颜色只是帮助观察位置或类别变化,不是这里最核心的部分。
- 这一列是整个前向扩散过程的起点:原始、有信息、低熵的数据分布。
1.2. 左侧公式:q(xt∣xt−1)q(x_t \mid x_{t-1})q(xt∣xt−1)(forward process)
这一行左边的公式说明:前向过程是一个 马尔可夫链。
意思是:
- 当前时刻 xtx_txt 只依赖前一个时刻 xt−1x_{t-1}xt−1;
- 每一步都按照某个固定的转移规则,把数据再“扰动”一点。
在离散扩散模型里,这种扰动不是往连续值里加高斯噪声,而是:
- 把某个离散状态以一定概率变成另一个离散状态;
- 这个“变成谁”的规则由 转移矩阵 QQQ 决定。
所以,第一行的核心就是在比较三种不同的前向“破坏机制”。
1.3. 虚线框里的三列:三种不同的前向扩散方式
虚线框表示:从同一个初始数据出发,使用三种不同的转移矩阵 (Q),在中间时刻 ( t=T/2 ) 会得到不同的破坏结果。
这三列分别是:
- uniform (t = T/2)
- Gaussian (t = T/2)
- absorbing (t = T/2)
每一列下面那个小方块就是对应的 转移矩阵 (Q) 的可视化。
1.3.1 第一列:uniform (t = T/2)
这表示使用 均匀转移 的前向过程。
所谓 uniform,是指:
- 一个点在每一步都有较均匀的概率跳到其他类别状态;
- 不太考虑“原来在哪里”以及“跳到哪里更近”。
也就是说,它的破坏方式比较“无差别”。
在 ( t=T/2 ) 时:
- 原本清晰的瑞士卷形状已经被严重打散;
- 点散布得很开,结构保留很少;
- 看起来接近随机噪声。
为什么会这样?因为 uniform 转移对局部结构不友好:
- 原本相邻的状态不一定还会转到相邻状态;
- 数据的几何结构很快被抹掉。
下面的小矩阵 (Q)
- 对角线比较明显,表示“保持原状态”仍有一定概率;
- 但除对角线外,其它位置也普遍有概率质量;
- 这说明一个状态可以较广泛地跳到很多其他状态。
这相当于一种“全局随机替换”:
- 不是局部模糊,
- 而是更像把原始类别随机改成别的类别。
1.3.2 第二列:Gaussian (t = T/2)
这表示使用 离散化高斯转移 的前向过程。
这是论文非常想强调的一种设计。
在连续空间的 DDPM 中,前向过程通常是加高斯噪声;
而在离散空间里,不能直接“加连续噪声”,于是作者构造了一个离散版本,使得:
- 一个状态更可能转移到“附近”的状态;
- 转得越远,概率越小。
也就是:让离散状态转移矩阵模仿连续空间里的高斯核。
在 ( t=T/2 ) 时:
- 瑞士卷结构仍然大体可见;
- 点云变厚、变模糊了,但没有完全散掉;
- 整体形状仍保留了不少局部几何信息。
为什么会这样?因为 Gaussian 型转移是“局部扰动”:
- 原本某点只会更倾向于跑到邻近类别;
- 所以整体结构不会像 uniform 那样迅速崩坏。
下面的小矩阵 (Q)
- 主对角线附近有一条比较宽的亮带;
- 离对角线越远,亮度越弱。
这正对应“离原状态越近,转移概率越大;越远越小”。
它像在离散网格上做“模糊”而不是“乱洗牌”:
- 不会突然跳到很远的位置,
- 而是像局部扩散一样慢慢把图形糊开。
这张图其实在视觉上直接传达了作者的一个核心观点:转移矩阵 (Q) 的设计非常重要。
Gaussian 型前向过程比 uniform 更能保留数据结构,因此:
- 逆过程更容易学习;
- 最终生成效果通常也更好。
1.3.3 第三列:absorbing (t = T/2)
这表示使用 吸收状态(absorbing state) 的前向过程。
所谓吸收状态,就是设定一个特殊状态:
- 一旦某个变量转移到这个状态,
- 后续就会一直留在那里,或者说被“吸收”。
在文本里,这很像把 token 替换成一个特殊符号,例如 [MASK]。
所以这种机制和 mask-based generative models 的联系很强。
在 ( t=T/2 ) 时:
- 原始瑞士卷的一部分仍然保留;
- 但有很多点已经“塌缩”到了图中的某个固定位置或固定类别上;
- 图里底部那条横向排列的点,就体现了大量状态被吸收到同一个特殊状态。
也就是说,数据不是被“扩散到四处”,而是有一部分被统一替换成同一个吸收类别。
为什么会这样?因为 absorbing 的破坏机制不是“把状态改成任意别的状态”,而是:
- 以一定概率把状态送到一个特殊类别;
- 这个特殊类别相当于“终点”或“mask”。
下面的小矩阵 (Q)会体现出:
- 大多数状态都有概率流向那个特殊吸收状态;
- 吸收状态本身对应的行/列具有特殊结构。
它不是“加模糊噪声”,也不是“随机乱跳”,而是:
- 逐步把信息擦掉,
- 擦掉后的内容统一变成一个占位符。
1.4. 第一行整体想表达什么
第一行的核心不是单纯展示三张图,而是在说明:
- D3PM 的前向过程由转移矩阵 (Q) 定义,不同的 (Q) 就对应不同的“加噪方式”。
- 不同前向过程会破坏数据的方式完全不同
- uniform:快速打乱全局结构;
- Gaussian:局部扩散,保留几何邻近关系;
- absorbing:把一部分信息替换成统一的特殊状态。
- 在离散扩散模型里,前向过程不是唯一固定的,这和经典连续 DDPM 有点不同。连续 DDPM 通常默认高斯噪声结构,而这里作者强调:
- 在离散空间中,前向扩散过程的设计空间更大,
- 而且这种设计会显著影响模型效果。
- 为什么 Gaussian 和 absorbing 特别重要
- Gaussian 型离散转移:说明可以在离散空间里模拟连续高斯扩散的思想;
- absorbing 型转移:说明扩散模型可以和 mask 生成模型建立联系。
这两点都是 D3PM 相比早期离散扩散模型的重要拓展。
1.4. 用一句话概括Figure 1第一行
第一行是在展示:同一份离散数据,在三种不同的前向扩散规则下,会以三种不同方式被“破坏”——要么被均匀打散、要么被局部模糊、要么被吸收到一个特殊状态;而这些差异正是 D3PM 设计的关键。
Our aim in this work is to improve and extend discrete diffusion models by using a more structured categorical corruption process to shape data generation, as illustrated in Figure 1.
我们的目标是通过使用一种更具结构性的类别腐蚀过程来改进并扩展离散扩散模型,以塑造数据生成过程,如图 1 所示。
Our models do not require relaxing or embedding discrete data (including images) into continuous spaces, and can embed structure or domain knowledge into the transition matrices used by the forward process.
我们的模型不需要将离散数据(包括图像)松弛或嵌入到连续空间中,并且能够将结构信息或领域知识嵌入到前向过程中所使用的转移矩阵中。
We achieve significantly improved results by taking advantage of this flexibility.
我们正是利用这种灵活性,取得了显著改进的结果。
We develop structured corruption processes appropriate for text data, using similarity between tokens to enable gradual corruption and denoising.
我们为文本数据设计了合适的结构化腐蚀过程,利用 token 之间的相似性来实现渐进式的腐蚀与去噪。
Expanding further, we also explore corruption processes that insert [MASK] tokens, which let us draw parallels to autoregressive and mask-based generative models.
进一步地,我们还探索了插入 [MASK] token 的腐蚀过程,这使我们能够将该模型与自回归生成模型和基于掩码的生成模型进行类比。
Finally, we study discrete diffusion models for quantized images, taking inspiration from the locality exploited by continuous diffusion models.
最后,我们研究了面向量化图像的离散扩散模型,从连续扩散模型所利用的局部性中获得启发。
This leads to a particular choice of discrete corruption process that diffuses preferentially to more similar states and leads to much better results in the image domain.
这引出了对离散腐蚀过程的一种特定选择:优先向更相似的状态扩散,从而在图像领域取得了更好的结果。
Overall, we make a number of technical and conceptual contributions.
总体而言,我们做出了一系列技术性和概念性的贡献。
Beyond designing several new structured diffusion models, we introduce a new auxiliary loss which stabilizes training of D3PMs and a family of noise schedules based on mutual information that lead to improved performance.
除了设计了若干新的结构化扩散模型之外,我们还提出了一种新的辅助损失,用于稳定 D3PM 的训练;同时提出了一类基于互信息的噪声调度方案,从而带来了更优的性能。
We strongly outperform various non-autoregressive baselines for text generation on character-level text generation, and successfully scale discrete diffusion models to large vocabularies and long sequence lengths.
在字符级文本生成任务上,我们相较于多种非自回归基线方法取得了显著更强的效果,并成功将离散扩散模型扩展到了大词表和长序列长度的场景。
We also achieve strong results on the image dataset CIFAR-10, approaching or exceeding the Gaussian diffusion model from Ho et al. [19] on log-likelihoods and sample quality.
我们还在图像数据集 CIFAR-10 上取得了强有力的结果,在对数似然和样本质量方面接近或超过了 Ho 等人 [19] 提出的高斯扩散模型。
2 背景:扩散模型
扩散模型 [43] 是一种潜变量生成模型,其特征在于包含一个前向马尔可夫过程和一个反向马尔可夫过程。
- 前向马尔可夫过程
q(x1:T∣x0)=∏t=1Tq(xt∣xt−1) q(x_{1:T}\mid x_0)=\prod_{t=1}^{T} q(x_t\mid x_{t-1}) q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
将数据 x0∼q(x0)x_0 \sim q(x_0)x0∼q(x0) 逐步扰动为一系列噪声不断增加的潜变量x1:T=x1,x2,…,xTx_{1:T}=x_1,x_2,\ldots,x_Tx1:T=x1,x2,…,xT。 - 反向马尔可夫过程(学习得到的)
pθ(x0:T)=p(xT)∏t=1Tpθ(xt−1∣xt) p_\theta(x_{0:T})=p(x_T)\prod_{t=1}^{T} p_\theta(x_{t-1}\mid x_t) pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)
会逐步对这些潜变量进行去噪,使其朝向数据分布靠近。例如,对于连续数据,前向过程通常会加入高斯噪声,而反向过程则学习将其去除。
为了优化生成模型pθ(x0)p_\theta(x_0)pθ(x0)以拟合数据分布q(x0)q(x_0)q(x0),我们通常优化负对数似然的一个变分上界:
Lvb=Eq(x0)[DKL[q(xT∣x0)∥p(xT)]⏟LT+∑t=2TEq(xt∣x0)[DKL[q(xt−1∣xt,x0)∥pθ(xt−1∣xt)]⏟Lt−1]−Eq(x1∣x0)[logpθ(x0∣x1)]⏟L0](1) L_{\mathrm{vb}}=\mathbb{E}_{q(x_0)}\left[ \begin{aligned} &\underbrace{D_{\mathrm{KL}}[q(x_T\mid x_0)\|p(x_T)]}_{L_T}\\[8pt] &+\sum_{t=2}^{T}\mathbb{E}_{q(x_t\mid x_0)} \left[ \underbrace{D_{\mathrm{KL}}[q(x_{t-1}\mid x_t,x_0)\|p_{\theta}(x_{t-1}\mid x_t)]}_{L_{t-1}} \right]\\[8pt] &-\underbrace{\mathbb{E}_{q(x_1\mid x_0)}[\log p_{\theta}(x_0\mid x_1)]}_{L_0} \end{aligned} \right] \tag{1} Lvb=Eq(x0) LT DKL[q(xT∣x0)∥p(xT)]+t=2∑TEq(xt∣x0) Lt−1 DKL[q(xt−1∣xt,x0)∥pθ(xt−1∣xt)] −L0 Eq(x1∣x0)[logpθ(x0∣x1)] (1)
第003/33页
当时间步数 TTT 趋于无穷大时,前向过程和反向过程都具有相同的函数形式 [13]^{[13]}[13],这使得我们可以使用与前向过程相同分布族中的一个学习得到的反向过程。
此外,对于前向过程的若干种选择,当 t→∞t \to \inftyt→∞ 时,分布 q(xt∣x0)q(x_t \mid x_0)q(xt∣x0) 会收敛到一个平稳分布 π(x)\pi(x)π(x),且该分布与 x0x_0x0 的取值无关。
当时间步数 TTT 足够大,并且我们选择 π(x)\pi(x)π(x) 作为先验 p(xT)p(x_T)p(xT) 时,我们可以保证式 (1)(1)(1) 中的 LTL_TLT 项将逼近于 000,而不受数据分布 q(x0)q(x_0)q(x0) 的影响。(或者,也可以使用一个学习得到的先验 pθ(xT)p_\theta(x_T)pθ(xT)。)
尽管在理论上 q(xt∣xt−1)q(x_t \mid x_{t-1})q(xt∣xt−1) 可以是任意形式,但当 q(xt∣xt−1)q(x_t \mid x_{t-1})q(xt∣xt−1) 满足以下条件时,就可以高效地训练 pθp_\thetapθ:
-
它允许在任意时间步 ttt 下,从 q(xt∣x0)q(x_t \mid x_0)q(xt∣x0) 中高效采样 xtx_txt,从而使我们能够随机采样时间步,并通过随机梯度下降分别优化每一个 Lt−1L_{t-1}Lt−1 项;
-
它具有一个可处理的前向过程后验 q(xt−1∣xt,x0)q(x_{t-1} \mid x_t, x_0)q(xt−1∣xt,x0) 表达式,这使我们能够计算式 (1)(1)(1) 中 Lt−1L_{t-1}Lt−1 项所包含的 KL 散度。
近期大多数关于连续空间的工作 [19],[44],[7],[30][19], [44], [7], [30][19],[44],[7],[30] 将前向分布和反向分布分别定义为
q(xt∣xt−1)=N(xt∣1−βtxt−1,βtI) q(x_t \mid x_{t-1}) = \mathcal{N}(x_t \mid \sqrt{1-\beta_t}x_{t-1}, \beta_t I) q(xt∣xt−1)=N(xt∣1−βtxt−1,βtI)
和
pθ(xt−1∣xt)=N(xt−1∣μθ(xt,t),Σθ(xt,t)). p_\theta(x_{t-1} \mid x_t) = \mathcal{N}(x_{t-1} \mid \mu_\theta(x_t, t), \Sigma_\theta(x_t, t)). pθ(xt−1∣xt)=N(xt−1∣μθ(xt,t),Σθ(xt,t)).
上述性质在这些高斯扩散模型中都成立:前向过程 q(xt∣x0)q(x_t \mid x_0)q(xt∣x0) 会收敛到一个平稳分布,这促使我们选择
p(xT)=N(xT∣0,I), p(x_T) = \mathcal{N}(x_T \mid 0, I), p(xT)=N(xT∣0,I),
并且,q(xt∣x0)q(x_t \mid x_0)q(xt∣x0) 和 q(xt−1∣xt,x0)q(x_{t-1} \mid x_t, x_0)q(xt−1∣xt,x0) 都是可处理的高斯分布,因此其 KL 散度可以被解析地计算出来。
3 离散状态空间的扩散模型
Diffusion models with discrete state spaces were first introduced by Sohl-Dickstein et al. [43], who considered a diffusion process over binary random variables.
离散状态空间上的扩散模型最早由 Sohl-Dickstein 等人 [43] 提出,他们考虑了二元随机变量上的扩散过程。
Hoogeboom et al. [20] extended the model class to categorical random variables with transition matrices characterized by uniform transition probabilities. In their supplementary material, Song et al. [44] also derived this extension, although no experiments were performed with this model class.
Hoogeboom 等人 [20] 将这一模型类别扩展到了分类随机变量,其转移矩阵由均匀转移概率表征。在其补充材料中,Song 等人 [44] 也推导了这一扩展,尽管并未用这一模型类别开展实验。
Here, we briefly describe a more general framework for diffusion with categorical random variables which includes these models as special cases.
这里,我们简要描述一个关于分类随机变量扩散的更一般框架,这些模型都可视为该框架的特殊情形。
For scalar discrete random variables with KKK categories xt,xt−1∈1,...,Kx _ { t } , x _ { t - 1 } \in { 1 , . . . , K }xt,xt−1∈1,...,K the forward transition probabilities can be represented by matrices:
对于具有 KKK 个类别的标量离散随机变量,设 xt,xt−1∈1,…,Kx_t, x_{t-1} \in 1, \ldots, Kxt,xt−1∈1,…,K,其前向转移概率可以表示为矩阵:
[Qt]ij=q(xt=j∣xt−1=i) [Q_t]_{ij} = q(x_t = j \mid x_{t-1} = i) [Qt]ij=q(xt=j∣xt−1=i)
Denoting the one-hot version of xxx with the row vector x\mathbf{x}x , we can write
将 xxx 的 one-hot 版本记为行向量 x\mathbf{x}x,则可写为:
q(xt∣xt−1)=Cat(xt;p=xt−1Qt),(2) q(x_t \mid x_{t-1}) = \mathrm{Cat}(x_t; p = \mathbf{x}_{t-1} Q_t), \tag{2} q(xt∣xt−1)=Cat(xt;p=xt−1Qt),(2)
其中
- Cat(x;p)\mathrm{Cat}(x; p)Cat(x;p) 表示定义在 one-hot 行向量 x\mathbf{x}x 上的分类分布,其概率由行向量 ppp 给出,
- 而 xt−1Qt\mathbf{x}_{t-1}Q_txt−1Qt 应理解为行向量与矩阵的乘积。我们假设 QtQ_tQt 独立地作用于图像中的每个像素或序列中的每个 token,并且 qqq 也在这些更高维度上进行因子分解;因此,我们用单个元素的形式来书写 q(xt∣xt−1)q(x_t \mid x_{t-1})q(xt∣xt−1)。从 x0x_0x0 出发,我们得到在时刻 t−1t-1t−1 的如下 ttt 步边缘分布与后验分布:
q(xt∣x0)=Cat(xt;p=x0Q‾t),其中Q‾t=Q1Q2…Qt q(x_t \mid x_0) = \mathrm{Cat}(x_t; p = \mathbf{x}_0 \overline{Q}_t), \qquad \text{其中} \qquad \overline{Q}_t = Q_1 Q_2 \ldots Q_t q(xt∣x0)=Cat(xt;p=x0Qt),其中Qt=Q1Q2…Qt
q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt−1∣x0)q(xt∣x0)=Cat(xt−1;p=xtQt⊤⊙x0Q‾t−1x0Q‾txt⊤).(3) q(x_{t-1} \mid x_t, x_0) = \frac{q(x_t \mid x_{t-1}, x_0)q(x_{t-1} \mid x_0)}{q(x_t \mid x_0)} =\mathrm{Cat} \left( x_{t-1}; p= \frac{\mathbf{x}_t Q_t^\top \odot \mathbf{x}_0 \overline{Q}_{t-1}} {\mathbf{x}_0 \overline{Q}_t \mathbf{x}_t^\top} \right). \tag{3} q(xt−1∣xt,x0)=q(xt∣x0)q(xt∣xt−1,x0)q(xt−1∣x0)=Cat(xt−1;p=x0Qtxt⊤xtQt⊤⊙x0Qt−1).(3)
注意,由于前向过程的马尔可夫性质,
q(xt∣xt−1,x0)=q(xt∣xt−1). q(x_t \mid x_{t-1}, x_0) = q(x_t \mid x_{t-1}). q(xt∣xt−1,x0)=q(xt∣xt−1).
假设反向过程 pθ(xt∣xt−1)p_\theta(x_t \mid x_{t-1})pθ(xt∣xt−1) 也在图像或序列元素上条件独立地进行因子分解,则 qqq 与 pθp_\thetapθ 之间的 KL 散度可以通过对每个随机变量的所有可能取值直接求和来计算;因此我们满足第 2 节中讨论的准则 1 和准则 2。
根据 QtQ_tQt 的具体形式,累积乘积 Q‾t\overline{Q}_tQt 往往可以闭式计算,或者简单地对所有 ttt 预先计算好。然而,当 KKK 和 TTT 都很大时,这可能代价过高。在附录 A.4 中,我们讨论了如何在这种情况下仍然高效地计算 Q‾t\overline{Q}_tQt,从而使该框架能够扩展到更多类别。
在下一节中,我们将讨论马尔可夫转移矩阵 QtQ_tQt 及其对应平稳分布的选择。
从这里开始,我们将这类具有离散状态空间的扩散模型统称为离散去噪扩散概率模型(Discrete Denoising Diffusion Probabilistic Models,D3PMs)。
第004/33页
3.1 前向过程的马尔可夫转移矩阵选择
上述描述的 D3PM 框架的一个优势在于,可以通过选择 QtQ_tQt 来控制数据腐化与去噪过程;这与连续扩散形成了鲜明对比,因为后者中只有加性高斯噪声受到了广泛关注。
除了为了保持概率质量而要求 QtQ_tQt 的各行和为 1 之外,选择 QtQ_tQt 时唯一的另一个约束是:当 ttt 变大时,Q‾t=Q1Q2⋯Qt\overline{Q}_t = Q_1 Q_2 \cdots Q_tQt=Q1Q2⋯Qt的各行必须收敛到一个已知的平稳分布[3],而这一点可以在对 QtQ_tQt 施加最少限制的情况下得到保证(见附录 A.1)。
我们认为,对于大多数真实世界中的离散数据,包括图像和文本,在转移矩阵 QtQ_tQt 中加入与领域相关的结构是合理的,这可以作为控制前向腐化过程以及可学习的反向去噪过程的一种方式。
下面,我们将简要讨论先前工作 [20] 中研究过的均匀转移矩阵,以及我们针对图像与文本数据集实验所探索的一组结构化转移矩阵;关于每一种矩阵类型的更多细节,见附录 A.2。
我们还指出,这组矩阵并非穷尽性的,在 D3PM 框架内还可以使用许多其他转移矩阵。
均匀型/Uniform(附录 A.2.1)。Sohl-Dickstein 等人 [43] 针对二元随机变量考虑了一个简单的 2×22 \times 22×2 转移矩阵。Hoogeboom 等人 [20] 随后将其扩展到分类变量,提出转移矩阵Qt=(1−βt)I+βt/K;11⊤,βt∈[0,1]Q_t = (1 - \beta_t) I + \beta_t / K ; \mathbf{1}\mathbf{1}^\top, \quad \beta_t \in [0,1]Qt=(1−βt)I+βt/K;11⊤,βt∈[0,1]。由于该转移矩阵是双随机的,且各元素都严格为正,因此其平稳分布是均匀分布。由于转移到任意其他状态的概率是均匀的,在本文中我们等价地将这一离散扩散实例称为 D3PM-uniform。
吸收状态型/Absorbing state(附录 A.2.2)。受到 BERT [11] 的成功以及近年来文本领域条件掩码语言模型(Conditional Masked Language Models, CMLMs)工作的启发,我们考虑一种带有吸收状态(称为 [MASK])的转移矩阵,使得每个 token 要么保持不变,要么以某个概率 βt\beta_tβt 转移到 [MASK]。这并不像均匀扩散那样对类别之间施加特定关系,但仍然允许将被腐化的 token 与原始 token 区分开来。此外,其平稳分布并非均匀分布,而是将全部概率质量集中在 [MASK] token 上。对于图像,我们复用灰色像素作为 [MASK] 吸收 token。
离散化高斯型/Discretized Gaussian(附录 A.2.3)。对于有序数据,我们不再均匀地转移到任意其他状态,而是提出通过使用离散化的、截断的高斯分布来模拟连续空间扩散模型。我们选择一种归一化方式,使得该转移矩阵是双随机的,从而得到均匀的平稳分布。该转移矩阵会以更高概率在更相似的状态之间进行转移,因此非常适合于图像这类量化的有序数据。
Token 嵌入距离型/Token embedding distance (附录 A.2.4)。文本数据并不具有有序结构,但其中仍然可能存在有趣的语义关系。例如,在字符级词表中,元音之间可能彼此更相似,而不是与辅音相似。为了展示 D3PM 框架的通用性,我们探索利用嵌入空间中的相似性来引导前向过程,并构造一个双随机转移矩阵,使得具有相似嵌入的 token 之间更频繁地发生转移,同时保持均匀的平稳分布。
对于均匀扩散和吸收状态扩散,累积乘积Q‾t\overline{Q}_tQt 可以闭式计算(见附录 A.4.1);其余情况则可以预先计算。
3.2 噪声调度
我们考虑前向过程噪声调度的几种不同选择。
- 对于离散化高斯扩散,我们探索在将其离散化之前,使高斯分布的方差线性增加。(注意,对 QtQ_tQt 使用线性调度,会导致 Q‾t\overline{Q}_tQt 中累积噪声的量呈非线性变化)。
- 对于均匀扩散,我们采用余弦调度,该调度将发生转移的累积概率设为余弦函数,这一方法由 Nichol 和 Dhariwal [30] 提出,并由 Hoogeboom 等人 [20] 适配到离散情形。
- 对于一般形式的一组转移矩阵 QtQ_tQt(例如基于 token 嵌入的那一类),先前提出的调度方式可能无法直接适用。我们考虑将 xtx_txt 与 x0x_0x0 之间的互信息线性插值到 0,即I(xt;x0)≈(1−tT)H(x0).I(x_t; x_0) \approx \left(1 - \frac{t}{T}\right) H(x_0).I(xt;x0)≈(1−Tt)H(x0).
有趣的是,对于吸收状态 D3PM 这一特例,该调度恰好退化为 Sohl-Dickstein 等人 [43] 针对伯努利扩散过程提出的(T−t+1)−1(T - t + 1)^{-1}(T−t+1)−1 调度。更多细节见附录 A.7。
第005/33页
3.3 反向过程的参数化
虽然可以直接使用神经网络 nnθ(xt)\mathrm{nn}_\theta(x_t)nnθ(xt) 来预测 pθ(xt−1∣xt)p_\theta(x_{t-1}\mid x_t)pθ(xt−1∣xt) 的 logits,但我们遵循 Ho 等人 [19] 和 Hoogeboom 等人 [20] 的做法,重点使用神经网络 nnθ(xt)\mathrm{nn}_\theta(x_t)nnθ(xt) 来预测分布 p~θ(x~0∣xt)\tilde{p}_\theta(\tilde{x}_0\mid x_t)p~θ(x~0∣xt) 的 logits,并将其与 q(xt−1∣xt,x0)q(x_{t-1}\mid x_t, x_0)q(xt−1∣xt,x0) 以及对 x0x_0x0 的 one-hot 表示的求和相结合,从而得到如下参数化形式:
pθ(xt−1∣xt)∝∑x~0q(xt−1,xt∣x~0)p~θ(x~0∣xt).(4) p_\theta(x_{t-1}\mid x_t)\propto \sum_{\tilde{x}_0} q(x_{t-1},x_t\mid \tilde{x}_0)\tilde{p}_\theta(\tilde{x}_0\mid x_t). \tag{4} pθ(xt−1∣xt)∝x~0∑q(xt−1,xt∣x~0)p~θ(x~0∣xt).(4)
我们注意到,在这种 x0x_0x0-参数化(x0\scriptstyle { \pmb x } _ { 0 }x0 -parameterization ) 下,如果 p~θ(x~0∣xt)\tilde{p}_\theta(\tilde{x}_0\mid x_t)p~θ(x~0∣xt) 将其全部概率质量都放在原始值 x0x_0x0 上,那么 DKL[q(xt−1∣xt,x0),∣,pθ(xt−1∣xt)]D_{\mathrm{KL}}\big[q(x_{t-1}\mid x_t,x_0),|,p_\theta(x_{t-1}\mid x_t)\big]DKL[q(xt−1∣xt,x0),∣,pθ(xt−1∣xt)] 将为 0。
q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt−1∣x0)q(xt∣x0)=Cat(xt−1;p=xtQt⊤⊙x0Q‾t−1x0Q‾txt⊤).(3) q(x_{t-1} \mid x_t, x_0) = \frac{q(x_t \mid x_{t-1}, x_0)q(x_{t-1} \mid x_0)}{q(x_t \mid x_0)} =\mathrm{Cat} \left( x_{t-1}; p= \frac{\mathbf{x}_t Q_t^\top \odot \mathbf{x}_0 \overline{Q}_{t-1}} {\mathbf{x}_0 \overline{Q}_t \mathbf{x}_t^\top} \right). \tag{3} q(xt−1∣xt,x0)=q(xt∣x0)q(xt∣xt−1,x0)q(xt−1∣x0)=Cat(xt−1;p=x0Qtxt⊤xtQt⊤⊙x0Qt−1).(3)
式 (3) 中对 q(xt−1∣xt,x0)q(x_{t-1}\mid x_t,x_0)q(xt−1∣xt,x0) 的分解也为这种参数化提供了动机。
根据式 (3),在给定状态 xtx_txt 时,最优反向过程只会考虑转移到那些满足 q(xt∣xt−1)q(x_t\mid x_{t-1})q(xt∣xt−1) 非零的状态。
因此,QtQ_tQt 的稀疏模式决定了 pθ(xt−1∣xt)p_\theta(x_{t-1}\mid x_t)pθ(xt−1∣xt) 中理想反向转移概率的稀疏模式。
式 (4) 中的参数化会自动确保,所学习到的反向概率分布 pθ(xt−1∣xt)p_\theta(x_{t-1}\mid x_t)pθ(xt−1∣xt) 具有由马尔可夫转移矩阵 QtQ_tQt 的选择所规定的正确稀疏模式。
该参数化还使我们能够一次执行 kkk 步推断,即预测
pθ(xt−k∣xt)=∑q(xt−k,xt∣x~0)p~θ(x~0∣xt). p_\theta(x_{t-k}\mid x_t)=\sum q(x_{t-k},x_t\mid \tilde{x}_0)\tilde{p}_\theta(\tilde{x}_0\mid x_t). pθ(xt−k∣xt)=∑q(xt−k,xt∣x~0)p~θ(x~0∣xt).
最后,在对有序离散数据建模时,除了直接用神经网络输出去预测 p~θ(x~0∣xt)\tilde{p}_\theta(\tilde{x}_0\mid x_t)p~θ(x~0∣xt) 的 logits 之外,另一种选择是使用截断的离散化 Logistic 分布来对概率进行建模(见附录 A.8)。这会为反向模型提供额外的有序归纳偏置,并提升图像上的 FID 和对数似然分数。
3.4 损失函数
虽然由Sohl‑Dickstein等 [43] 引入的原始扩散模型是用(1)的负变分下界 LvbL _ { \mathrm { v b } }Lvb 优化的,但最近的扩散模型采用了不同的优化目标。例如,Ho等 [19] 推导出一种简化损失函数 (Lsimple)( L _ { \mathrm { s i m p l e } } )(Lsimple) ,对负变分下界进行了重新加权;而Nichol和Dhariwal [30] 探索了一种混合损失
Lhybrid = Lsimple+λLvbL _ { \mathrm { h y b r i d } } ~ = ~ L _ { \mathrm { s i m p l e } } + \lambda L _ { \mathrm { v b } }Lhybrid = Lsimple+λLvb (使用一个项来学习预测均值,另一个项来学习预测方差)。受这些近期工作的启发,我们为逆向过程参数化引入了辅助去噪目标,鼓励在每个时间步 x0\scriptstyle { \mathbf { { \mathit { x } } } } _ { 0 }x0 对数据 δx0\mathbf { \delta x } _ { 0 }δx0 做出良好的预测。我们将此目标与负变分下界相结合,得出以下替代损失函数:
Lλ=Lvb+λEq(x0)Eq(xt∣x0)[−logp~θ(x0∣xt)].(5) L _ {\lambda} = L _ {\mathrm {v b}} + \lambda \mathbb {E} _ {q (\boldsymbol {x} _ {0})} \mathbb {E} _ {q (\boldsymbol {x} _ {t} | \boldsymbol {x} _ {0})} [ - \log \widetilde {p} _ {\theta} (\boldsymbol {x} _ {0} | \boldsymbol {x} _ {t}) ]. \tag {5} Lλ=Lvb+λEq(x0)Eq(xt∣x0)[−logp θ(x0∣xt)].(5)
请注意,辅助损失与交叉熵项 L0L _ { 0 }L0 在(1)式中的 t = 1t ~ = ~ 1t = 1 处相一致。此外,由于 pθ(xt−1∣xt)p _ { \theta } ( \pmb { x } _ { t - 1 } | \pmb { x } _ { t } )pθ(xt−1∣xt) 的 x⃗0\scriptstyle { \mathbf { { \vec { x } } } } _ { 0 }x0 参数化,当p~θ(x~0∣xt)\widetilde { p } _ { \theta } ( \widetilde { \pmb { x } } _ { 0 } | \pmb { x } _ { t } )p θ(x 0∣xt) 的所有概率质量都集中于数据点 x0\scriptstyle { \mathbf { { \mathit { x } } } } _ { 0 }x0 时,辅助损失项和 LvbL _ { \mathrm { v b } }Lvb 中的 ∣DKL[q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt)]| D _ { \mathrm { K L } } [ q ( \pmb { x } _ { t - 1 } | \pmb { x } _ { t } , \pmb { x } _ { 0 } ) | | p _ { \theta } ( \pmb { x } _ { t - 1 } | \pmb { x } _ { t } ) ]∣DKL[q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt)] 都会被精确最小化。我们发现,使用此损失进行训练可提升图像样本的质量。
4 与现有文本概率模型的关联
在本节中,我们将详细阐述D3PM框架与几种现有概率和语言建模方法之间有趣的关联。
BERT是单步扩散模型:一种可能的D3PM转移矩阵是均匀转移矩阵与[MASK]词元处吸收态的组合(即 Q=α1emT+β11T/K+(1−α−β)I,\begin{array} { r } { \pmb { Q } = \alpha \mathbb { 1 } e _ { m } ^ { T } + \beta \mathbb { 1 } \mathbb { 1 } ^ { T } / K + ( 1 - \alpha - \beta ) \boldsymbol { I } , } \end{array}Q=α1emT+β11T/K+(1−α−β)I, ,其中 eme _ { m }em 是 [MASK]词元上的独热向量)。对于一步扩散过程,其中 q(x1∣x0)q ( \pmb { x } _ { 1 } | \pmb { x } _ { 0 } )q(x1∣x0) 将 10%1 0 \%10% 的词元替换为 [MASK] ,并将 5%5 \%5% 均匀随机替换,这精确地导向了BERT去噪目标,即 Lvb−LT=−Eq(x1∣x0)[logpθ(x0∣x1)]=LBERTL _ { v b } - L _ { T } = - \mathbb { E } _ { q ( \pmb { x } _ { 1 } | \pmb { x } _ { 0 } ) } [ \log p _ { \theta } ( \pmb { x } _ { 0 } | \pmb { x } _ { 1 } ) ] = L _ { B E R T }Lvb−LT=−Eq(x1∣x0)[logpθ(x0∣x1)]=LBERT ,因为 LTL _ { T }LT 是一个独立于 θ\thetaθ 的常数(假设先验固定)。
自回归模型是(离散的)扩散模型:考虑一个扩散过程,它确定性地逐个掩码长度为
N=TN = TN=T : q([xt]i∣x0)=[x0]iq ( [ \pmb { x } _ { t } ] _ { i } \mid \pmb { x } _ { 0 } ) = [ \pmb { x } _ { 0 } ] _ { i }q([xt]i∣x0)=[x0]i if iii <的序列中的词元。
第006/33页
N−tN - tN−t 否则 [掩码]。这是一个确定性的前向过程,因此 q(xt−1∣xt,x0)q ( \pmb { x } _ { t - 1 } | \pmb { x } _ { t } , \pmb { x } _ { 0 } )q(xt−1∣xt,x0) 是关于 ΔXt\mathbf { \Delta } _ { \mathbf { \mathcal { X } } _ { t } }ΔXt 序列上少一个掩码的狄拉克分布: q([xt−1]i∣xt,x0)=δ[xt]iq ( [ \pmb { x } _ { t - 1 } ] _ { i } | \pmb { x } _ { t } , \pmb { x } _ { 0 } ) = \delta _ { [ \pmb { x } _ { t } ] _ { i } }q([xt−1]i∣xt,x0)=δ[xt]i 如果 i≠T−ti \neq T - ti=T−t 否则 δ[x0]i∘\delta _ { [ { \pmb x } _ { 0 } ] _ { i } \circ }δ[x0]i∘ 虽然这个过程并非独立应用于每个词元,但可以重构为在积空间 [0...N]×V[ 0 . . . N ] \times \mathcal { V }[0...N]×V 上独立应用的扩散过程,其中每个词元都标记了其在序列中的位置, ν\nuν 是词表,而 QQQ 是一个 N×∣V∣×N×∣V∣N \times | \mathcal { V } | \times N \times | \mathcal { V } |N×∣V∣×N×∣V∣ 稀疏矩阵。
因为除了位置 i=T−ti = T - ti=T−t 的词元外,所有词元的后验分布都是确定的,所以对于其他所有位置,KL散度DKL(q([xt−1]j∣xt,x0)∣∣ pθ([xt−1]j∣xt))D _ { K L } \big ( q ( [ \pmb { x } _ { t - 1 } ] _ { j } | \pmb { x } _ { t } , \pmb { x } _ { 0 } ) \big | \big | \ p _ { \theta } \big ( [ \pmb { x } _ { t - 1 } ] _ { j } | \pmb { x } _ { t } \big ) \big )DKL(q([xt−1]j∣xt,x0) pθ([xt−1]j∣xt)) ∣∣ pθ([xt−1]j∣xt))| | \ p _ { \theta } ( [ { \pmb x } _ { t - 1 } ] _ { j } | { \pmb x } _ { t } ) )∣∣ pθ([xt−1]j∣xt)) 为零。唯一不满足此情况的词元是位置 i的词元,对于该词元DKL(q([xt−1]i∣xt,x0)D _ { K L } ( q ( [ \pmb { x } _ { t - 1 } ] _ { i } | \pmb { x } _ { t } , \pmb { x } _ { 0 } )DKL(q([xt−1]i∣xt,x0) ∣∣pθ([xt−1]i∣xt))=−logpθ([x0]i∣xt),| | p _ { \theta } ( [ { \pmb x } _ { t - 1 } ] _ { i } | { \pmb x } _ { t } ) ) = - \log p _ { \theta } ( [ { \pmb x } _ { 0 } ] _ { i } | { \pmb x } _ { t } ) ,∣∣pθ([xt−1]i∣xt))=−logpθ([x0]i∣xt), ,它是自回归模型的标准交叉熵损失函数。
(生成式)掩码语言模型(MLMs)是扩散模型:生成式掩码语言模型([14], [54])是一种生成模型,它从一系列 [掩码]词元中生成文本。它们通常的训练方式是采样一个序列 x0\scriptstyle { \mathbf { { \mathit { x } } } } _ { 0 }x0 ,根据某个附表掩码 kkk 词元,并学习在给定上下文的情况下预测被掩码的词元。事实证明,一个基于D3PM吸收态([掩码])的模型,使用通常的ELBO目标函数和3.3节中的 x0\scriptstyle { \mathbf { { \mathit { x } } } } _ { 0 }x0 参数化进行训练,可以简化为该MLM目标函数的一个加权版本(详细推导见附录A.3)。
5 文本生成
在文本方面,我们在两个数据集上进行生成实验:text8——一个从英文维基百科提取的字符级数据集,以及十亿词数据集(LM1B)——一个大规模、经过句子随机重排的英文数据集。对于两者,我们基于Hoogeboom等的工作训练了一个D3PM均匀模型(D3PM uniform)和一个对词元施加掩码的模型(D3PM吸收)。我们还考虑了一个在词嵌入空间中均匀地向最近邻进行转移的模型(D3PMNN)。我们遵循Hoogeboom等的设定并使用 T=1000T = 1 0 0 0T=1000 个时间步,但由于第3.3节的参数化方式,我们也能够在更少的时间步下进行评估。
5.1 text8上的字符级生成
text8是一个字符级的文本数据集,由一个包含27个词元的小词表组成:字母’a’到’z’以及’_'空白符词元。我们遵循惯例,将text8以长度为256的片段进行训练和评估,不做任何预处理 [20]∘[ 2 0 ] _ { \circ }[20]∘ 。对于最近邻D3PM,我们在字符空间中的最近邻图见附录B.2.1。D3PM均匀模型采用了来自Hoogeboom等的余弦调度进行训练 [20] (消融实验见附录B.2.1),而D3PM吸收模型和D3PM NN模型则采用了互信息调度进行训练。
表 1:text8上的定量结果。负对数似然是针对整个测试集报告的。采样时间是指生成一个长度为256的单例所需的时间。结果报告基于两个随机种子。除非特别说明,所有模型均为标准的12层Transformer。 †TransformerXL是一个24层的Transformer,使用784的上下文窗口。 ‡结果报告[20]基于运行官方仓库代码得出。
| 模型 | 模型步数 | 负对数似然(比特/字符)(↓) | 采样时间(秒)(↓) |
| 离散流 [49] (8×3层) | - | 1.23 | 0.16 |
| Argmax耦合流 [20] | - | 1.80 | 0.40 ± 0.03 |
| 逆自回归流/自回归流 [57]‡ | - | 1.88 | 0.04 ± 0.0004 |
| 多项式扩散(D3PM均匀)[20] | 1000 | ≤1.72 | 26.6 ± 2.2 |
| D3PM均匀 [20] (我们的) | 1000 | ≤1.61 ± 0.02 | 3.6 ± 0.4 |
| D3PM神经网络 (Lvb)(我们的) | 1000 | ≤1.59 ± 0.03 | 3.1474 ± 0.0002 |
| D3PM掩码 (Lλ=0.01) (我们的) | 1000 | ≤1.45 ± 0.02 | 3.4 ± 0.3 |
| D3PM均匀 [20] (我们的) | 256 | ≤1.68 ± 0.01 | 0.5801 ± 0.0001 |
| D3PM神经网络 (Lvb)(ours) | 256 | ≤1.64 ± 0.02 | 0.813 ± 0.002 |
| D3PM吸收态 (Lλ=0.01) (我们的) | 256 | ≤1.47 ± 0.03 | 0.598 ± 0.002 |
| Transformer解码器 (我们的) | 256 | 1.23 | 0.3570 ± 0.0002 |
| Transformer解码器 [1] | 256 | 1.18 | - |
| Transformer XL [10]† | 256 | 1.08 | - |
| D3PM均匀 [20] (我们) | 20 | ≤1.79 ± 0.03 | 0.0771 ± 0.0005 |
| D3PM神经网络 (Lvb)(我们的) | 20 | ≤1.75 ± 0.02 | 0.1110 ± 0.0001 |
| D3PM吸收态 (Lλ=0.01) (我们的) | 20 | ≤1.56 ± 0.04 | 0.0785 ± 0.0003 |
第007/33页
图2:左侧:LM1B困惑度与采样迭代次数关系。右侧:使用训练好的D3PM吸收模型为LM1B实现(顶部)生成新句子和(底部)重建受损示例。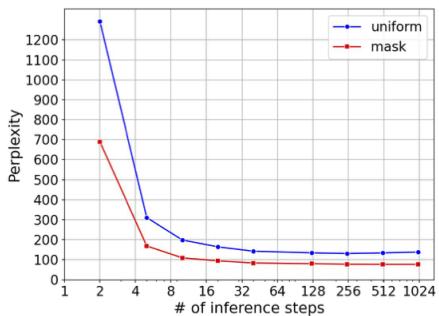
t=128t = 1 2 8t=128 [MASK][MASK][MASK][MASK][MASK][MASK]…
t = 25t \ = \ 2 5t = 25 In response [MAsK] the demands ,[MAsK] [MAsK]y Workers union said [MAsK] backflow fund [MAsK]s would face further
t t = 0 \textup { \ t { t } } = \textup { \textsf { 0 } } t t = 0
Original:Caterpillar is eager to expand in Asia ,where it trails local competitors such as Komatsu Ltd
Corrupted:Caterpillar is eager to expand in[MAsK],[MAsK] it [MASK] s local competitors such as Komatsu Ltd
Reconstructed:Caterpillar is eager to expand in China ,where it faces local competitors such as Komatsu Ltd
表 2:LM1B 上的定量结果。困惑度报告基于测试集。结果基于两个随机种子报告。所有模型均具有上下文窗口长度 128 和 12 层,除非另有说明。†Transformer XL 是一个 24 层的 Transformer。 ‡为可读性进行了四舍五入,详见附录 B.2.2。
| 指标: | 困惑度(↓) | 采样时间‡(s)(↓) | ||||
| 推理步数: | 1000 | 128 | 64 | 1000 | 128 | 64 |
| D3PM均匀 | 137.9 ± 2.1 | 145.0 ± 1.2 | 1.82 | 0.21 | 0.08 | |
| D3PM神经网络 | 149.5 ± 1.3 | 158.6 ± 2.2 | 160.4 ± 1.2 | 21.29 | 6.69 | 5.88 |
| D3PM吸收 | 76.9 ± 2.3 | 80.1 ± 1.2 | 83.6 ± 6.1 | 1.90 | 0.19 | 0.10 |
| Transformer(本模型) | - | 43.6 | - | - | 0.26 | - |
| Transformer XL [10]† | - | 21.8 | - | - | - | - |
表1显示,对于D3PM,D3PM吸收模型表现最佳,超越了均匀模型和NN扩散模型。我们通过超参数调优改进了 [20] 的基线结果,我们的均匀模型和NN模型的结果在所有推理步数(低至20步)上都优于Hoogeboom等 [20]的结果。我们发现 Lλ=0.01L _ { \lambda = 0 . 0 1 }Lλ=0.01 对D3PM吸收模型效果最佳,而 LvbL _ { \mathrm { v b } }Lvb 对D3PM均匀模型更好。我们的模型优于除了一个模型(离散流模型 [49] ,遗憾的是没有开源实现)之外的所有非自回归基线,并且也比除了一个方法(IAF/SCF模型[57])之外的所有方法更快。它也比相同大小的自回归Transformer快了近20倍。我们还在附录B.2.1中包含了一个推理时间随迭代次数变化的图表。使用掩码吸收token的D3PM模型是目前表现最佳的模型,这证明了在去噪自编码器中使用掩码的合理性。最近邻扩散仅略优于一个D3PM‑均匀模型:这对我们来说是一个令人惊讶的负面结果,表明并非所有结构概念都具有意义。
5.2 LM1B上的文本生成
使用离散扩散模型进行大规模文本数据集和大词表的文本生成此前尚未得到展示。我们包含LM1B的结果作为概念验证,表明这些模型确实可以扩展(如附录A.4所述),并且D3PM吸收模型继续表现优异。所有模型均在长度为128的打包序列上训练和评估,使用大小为8192的SentencePiece4 词表。
表2包含在LM1B上的实验结果。总体而言,掩码扩散(D3PM吸收态)表现相对较好,接近同尺寸可比自回归模型的表现,且能缩放至远更少的步数,而均匀扩散的表现则显著更差。我们发现,出乎意料的是,D3PM NN模型在对数似然方面表现不如均匀模型(尽管它展现出独特的定性行为)。这表明词嵌入相似度在扩散过程中可能并非一种有意义的局部性。我们发现 Lλ=0.01L _ { \lambda = 0 . 0 1 }Lλ=0.01 损失对于掩码吸收模型效果最佳,但降低了其他模型的表现。我们注意到图2中困惑度惊人的缩放能力,仅用10个推理步数就取得了强劲结果。我们还展示了来自我们模型的样本以及来自损坏样本的补全结果。
第008/33页
表3:图像数据集CIFAR‑10上的Inception分数(IS)、Frechet Inception距离(FID)和负对数似然(NLL)。NLL在测试集上以每维比特数报告。我们的结果报告为平均值与标准差,通过使用不同随机种子训练五个模型获得。
| 模型 | IS (↑) | FID (↓) | NLL (↓) |
| Sparse Transformer [9] | 2.80 | ||
| NCSN [45] | 8.87 ± 0.12 | 25.32 | |
| NCSNv2 [46] | 8.40 ± 0.07 | 10.87 | |
| StyleGAN2 + ADA [22] | 9.74 ± 0.05 | 3.26 | |
| 扩散模型(原版),Lvb [43] | ≤ 5.40 | ||
| DDPM Lvb [19] | 7.67 ± 0.13 | 13.51 | ≤ 3.70 |
| DDPM Lsimple [19] | 9.46 ± 0.11 | 3.17 | ≤ 3.75 |
| 改进版DDPM Lvb [30] | 11.47 | ≤ 2.94 | |
| 改进版DDPM Lsimple [30] | 2.90 | ≤ 3.37 | |
| DDPM++连续 [47] | 2.92 | 2.99 | |
| NCSN++连续 [47] | 9.89 | 2.20 | |
| D3PM均匀 Lvb | 5.99 ± 0.14 | 51.27 ± 2.15 | ≤ 5.08 ± 0.02 |
| D3PM吸收 Lvb | 6.26 ± 0.10 | 41.28 ± 0.65 | ≤ 4.83 ± 0.02 |
| D3PM吸收λ=0.001 | 6.78 ± 0.08 | 30.97 ± 0.64 | ≤ 4.40 ± 0.02 |
| D3PM高斯Lvb | 7.75 ± 0.13 | 15.30 ± 0.55 | ≤ 3.966 ± 0.005 |
| D3PM高斯λ=0.001 | 8.54 ± 0.12 | 8.34 ± 0.10 | ≤ 3.975 ± 0.006 |
| D3PM高斯+逻辑Lλ=0.001 | 8.56 ± 0.10 | 7.34 ± 0.19 | ≤ 3.435 ± 0.007 |
6 图像生成
我们在无条件图像生成任务上评估了几种D3PM模型的表现,数据集为CIFAR‑10[27]。我们遵循Ho等[19],并对所有模型使用 T=1000T = 1 0 0 0T=1000 时间步,并验证所有模型的前向过程在 TTT 步内收敛至平稳分布,产生的每维比特数最多为 LT≈10−5L _ { T } \approx 1 0 ^ { - 5 }LT≈10−5 。我们训练了三个不同转移矩阵版本的D3PM:具有均匀转移概率的双随机矩阵(D3PM均匀)[20],转移矩阵(其吸收态位于R、G和B值为128处)(D3PM吸收态),以及双随机离散化高斯转移矩阵(D3PM高斯)。对于D3PM均匀模型,我们尝试了线性 βt\beta _ { t }βt 调度以及 [20], 中提出的余弦调度,其中余弦调度产生了最佳结果。对于D3PM吸收态,我们使用 βt=(T−t+1)−1\beta _ { t } = ( T - t + 1 ) ^ { - 1 }βt=(T−t+1)−1 调度,同样在[43],中提出,该调度对应于随时间线性增加处于吸收态的概率。对于D3PM高斯,我们使用与 [19]中相同的线性调度。更多实验设置细节参见附录 B.1∘\mathrm { { B . 1 } _ { \circ } }B.1∘
表3显示,对于使用 LvbL _ { \mathrm { v b } }Lvb 目标训练的D3PM模型,D3PM高斯在所有指标上均优于D3PM吸收态和均匀:Inception分数(IS)、弗雷歇Inception距离(FID)和负对数似然(NLL)。均匀和吸收态D3PM模型的IS分数相当,而D3PM吸收模型的FID分数和NLL略好一些。

图 3:左图:渐进采样于 t=1000t = 1 0 0 0t=1000 ,900,800,…,0,分别对应D3PM吸收态(顶部)和D3PM高斯 +^ ++ 逻辑(底部),训练时使用 LλL _ { \lambda }Lλ 损失于CIFAR‑10数据集。这些样本是精心挑选的。右图:D3PM高斯 +^ ++ 逻辑模型生成的(未经精心挑选)样本。
第009/33页
我们使用(5)式中的替代损失函数 LλL _ { \lambda }Lλ 训练了D3PM吸收态和D3PM高斯,并发现λ=0.001\lambda = 0 . 0 0 1λ=0.001 效果最佳。我们还尝试了更大的 λ\lambdaλ 值以及仅使用(5)式中辅助去噪项训练的模型。尽管这在训练早期带来了更快的性能提升,但对于较大的 λ\lambdaλ ,NLL在更高值处趋于平稳,FID甚至再次开始上升。结果表明,使用 LλL _ { \lambda }Lλ 训练的模型显著优于使用 LvbL _ { \mathrm { v b } }Lvb 训练的对应模型。性能提升的一个解释是,交叉熵项产生的梯度噪声随时间步 ttt 的变化较小,这与 LvbL _ { \mathrm { v b } }Lvb 中 Lt−1L _ { t - 1 }Lt−1 项在较小 ttt 时幅度的剧烈变化形成对比,正如Nichol和Dhariwal [30] 所展示的。最后,我们将基于 LλL _ { \lambda }Lλ 训练的D3PM高斯与逆向过程分布 pθp _ { \theta }pθ 的截断逻辑斯蒂参数化 (x~0∣xt)( \widetilde { \pmb x } _ { 0 } | \pmb x _ { t } )(x 0∣xt) )(D3PM高斯 +˙\dot { + }+˙ 逻辑斯蒂)相结合,获得了最佳结果。图3展示了我们最佳模型(D3PM高斯 +^ ++ 逻辑斯蒂)以及D3PM吸收模型的样本。
7 相关工作
扩散生成模型最初由 Sohl‑Dickstein等 [43] 提出,近期因其在图像和波形生成 [19, 7]上的优异表现而重新获得关注。近期工作提出了对扩散模型训练的改进,包括ELBO的重要性采样、更好的噪声调度[30] 以及隐式扩散模型[44]。多项工作也将扩散模型与分数匹配[53, 21, 45], 联系起来,从而在连续时间极限[47]下改进了采样算法。
虽然大多数工作关注的是连续扩散模型,但离散类扩散模型已在 [43] 中被描述,并应用于[20]的文本生成和图像分割数据。部分工作[31,29]处理离散数据的方法是将其嵌入连续空间并利用高斯扩散,但尚未将此应用于文本。Seff等 [42] 也考虑了使用类扩散的马尔可夫损坏过程生成离散结构化对象。
对于文本,去噪自编码器在表示学习[2,11]领域历史悠久,近期也作为生成模型 [54]出现。它们与我们的吸收态扩散变体(针对特定附表与转移矩阵,见第4节)非常相似,尽管我们的框架允许我们计算对数似然并尝试替代转移矩阵。其他工作则考虑了通过插入和删除[16,37],、掩码[14],以及迭代精化序列对齐 [5,38]来实现非自回归翻译和语音转录。
8 讨论
我们提出了D3PMs,这是一类通过定义新型离散损坏过程来改进离散数据扩散模型的模型。相较于离散扩散模型的先前工作,我们取得了强有力的实证结果,甚至在图像生成的对数似然方面超越了连续扩散模型的性能。尽管这些结果令人鼓舞,但一个局限性在于——与许多其他非自回归生成模型的研究一样——我们的模型在文本生成方面仍逊色于强大的自回归模型,如Transformer XL,而在图像质量方面,连续扩散模型仍能产生更强的结果。我们期望D3PMs能进一步受益于连续扩散模型的快速发展 [47,30]∘[ 4 7 , 3 0 ] _ { \circ }[47,30]∘ 。例如,D3PM的替代损失的进一步研究可以借鉴 [19], 中使用的加权 LsimpleL _ { \mathrm { s i m p l e } }Lsimple 目标,或Nichol和Dhariwal [30]中的重采样变分下界。此外,正如Nichol和Dhariwal [30]中所讨论的,D3PM可能受益于增加时间步数量和更优化的噪声调度。另一个局限源于我们所使用的评估指标(这些指标是生成模型评估的标准)。Inception分数和Frechet Inception距离基于在特定数据分布上训练过的神经网络,这并不能代表所有用例,并且专注于平均质量指标可能无法准确反映这些生成模型在广泛应用场景下的性能。这带来了负面社会影响的风险,即进展不成比例地惠及部分人群。展望未来,我们对D3PM框架内涌现的可能性空间感到兴奋。我们已经成功地利用了为离散数据定义离散损坏过程所带来的灵活性,但我们相信
第010/33页
还有更多可能性可以利用更丰富的结构形式来定义更强大的离散扩散模型。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)